
7 Advanced practices that distinguish effective mobile test automation


There are a number of technical, educational, and organizational issues that commonly lead to failure in test automation. This is confirmed by two recent surveys from 2017 and 2018, which found that only 19 percent of teams are able to implement test automation correctly on the first attempt.
There are however various options available to help organizations improve their test automation capabilities. This includes a range of courses that can help to identify education gaps and obtain vital knowledge on test automation. There are also many articles that have been written explaining how to select the best test automation tools.
But these steps alone aren’t usually sufficient. To more comprehensively address the issues that make test automation challenging, we have put together 7 technical and organizational practices that can help you succeed in test automation regardless of the tools you choose to use. We have also developed a checklist that can be used to assess your current implementation and to identify areas for improvement.
A short history of test automation
At Grid Dynamics, we’ve been doing mobile test automation for the last 7 years. We watched the emergence of Appium in 2013 and saw it become the most popular tool for mobile test automation. And we used it from the very beginning. We saw new frameworks like Espresso and XCUITest appear and observed companies developing mobile operating systems and becoming more and more interested in test automation. We also observed the dying off of other good frameworks such as Calabash and MonkeyTalks.
Over this whole period we were paying close attention to the developments in the space and are now happy to share with you the 7 most important practices you should be aware of:
- Readiness of tests to be run against the production environment
- Investment in test data management
- Working with test environments
- Using stubs, mocks, and fakes
- Looking behind the scenes
- Continuous optimization of tests and test runs
- Coverage measurements
Now let’s go through each of them in detail, discuss why each practise is important, and look at the main benefits that come with each approach. More detailed steps and recommendations can be taken from the checklist at the conclusion of this article.
Readiness of tests to be run against the production environment
The main idea here is to have tests that can be run against any level of test environment including the production infrastructure. It means the same test can be run against any environment without any required changes or using ‘ifs’ within the test procedure.

It’s not feasible to run all functional regression tests against high-level environments like production or pre-production. However, there are a lot of test scenarios that must be environment independent. Of course, we are not speaking about having different test suites for every environment - that’s not an efficient approach. But it’s still possible to have specific tests for specific environments. Why is it important? Foremost, writing tests in a way to be run against any environment is about saving time. In addition, because the production environment is always up, it always has enough data to test and is the most important target of the testing from a business perspective.
Investment in test data management (TDM)
We are pretty sure you’re already investing in TDM. But even so, our suggestion is — invest more, because it is crucial for the stability of the test automation suite. And it’s simply not possible to have success in running tests without a proper TDM solution. In fact, according to surveys, more than half of all respondents report that test data management is one of the main issues resulting in test automation failing completely.
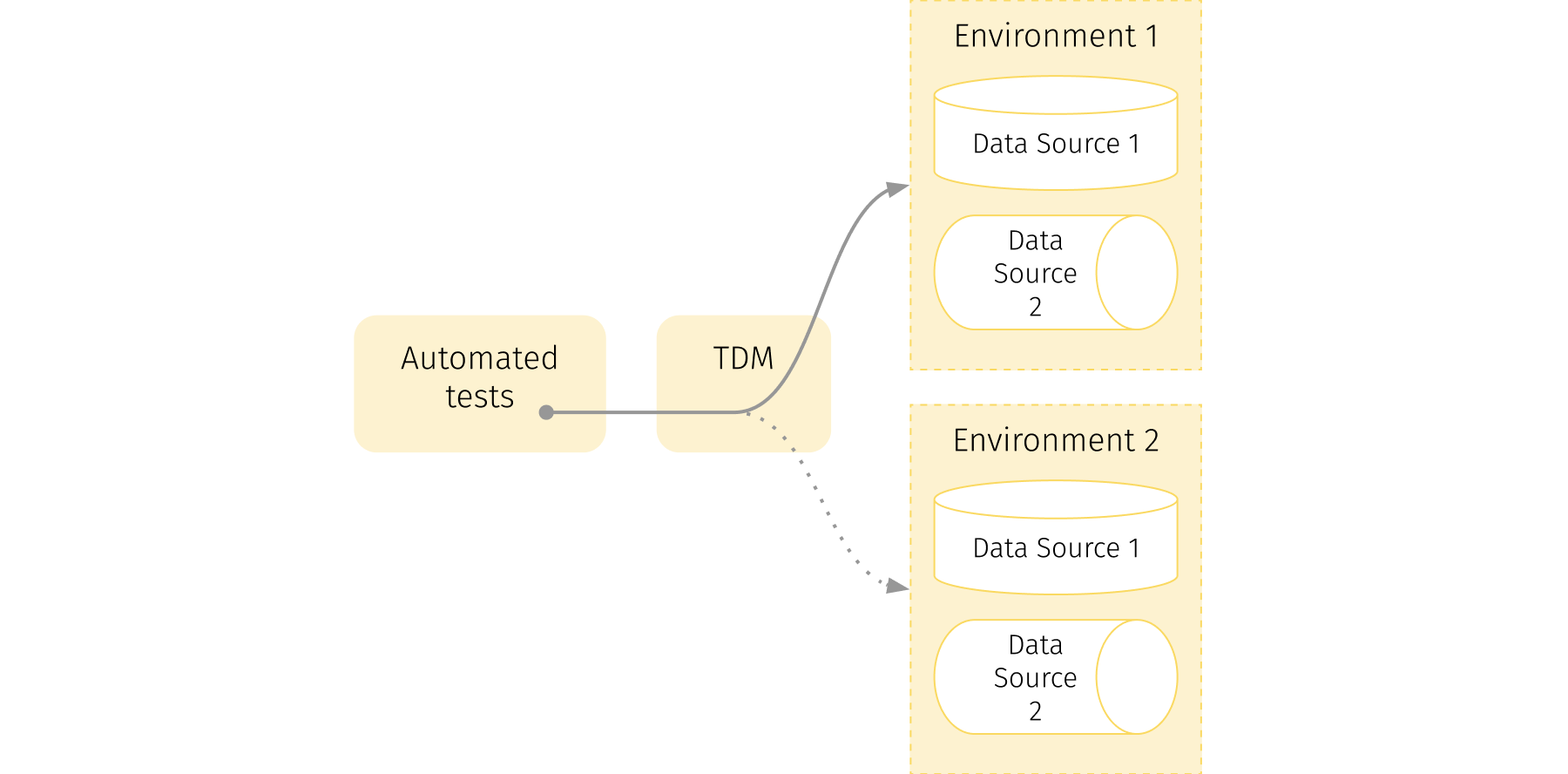
Without a proper TDM solution, it’s really hard to write stable automated tests and a large amount of time will be spent on maintenance of existing tests. In addition, finding the data for new tests can be a tricky and time-consuming activity.
To be honest, this particular topic is both very interesting and very complex. So complex that a detailed discussion of test data management is worthy of a separate dedicated article on the subject.
Proper work with test environments
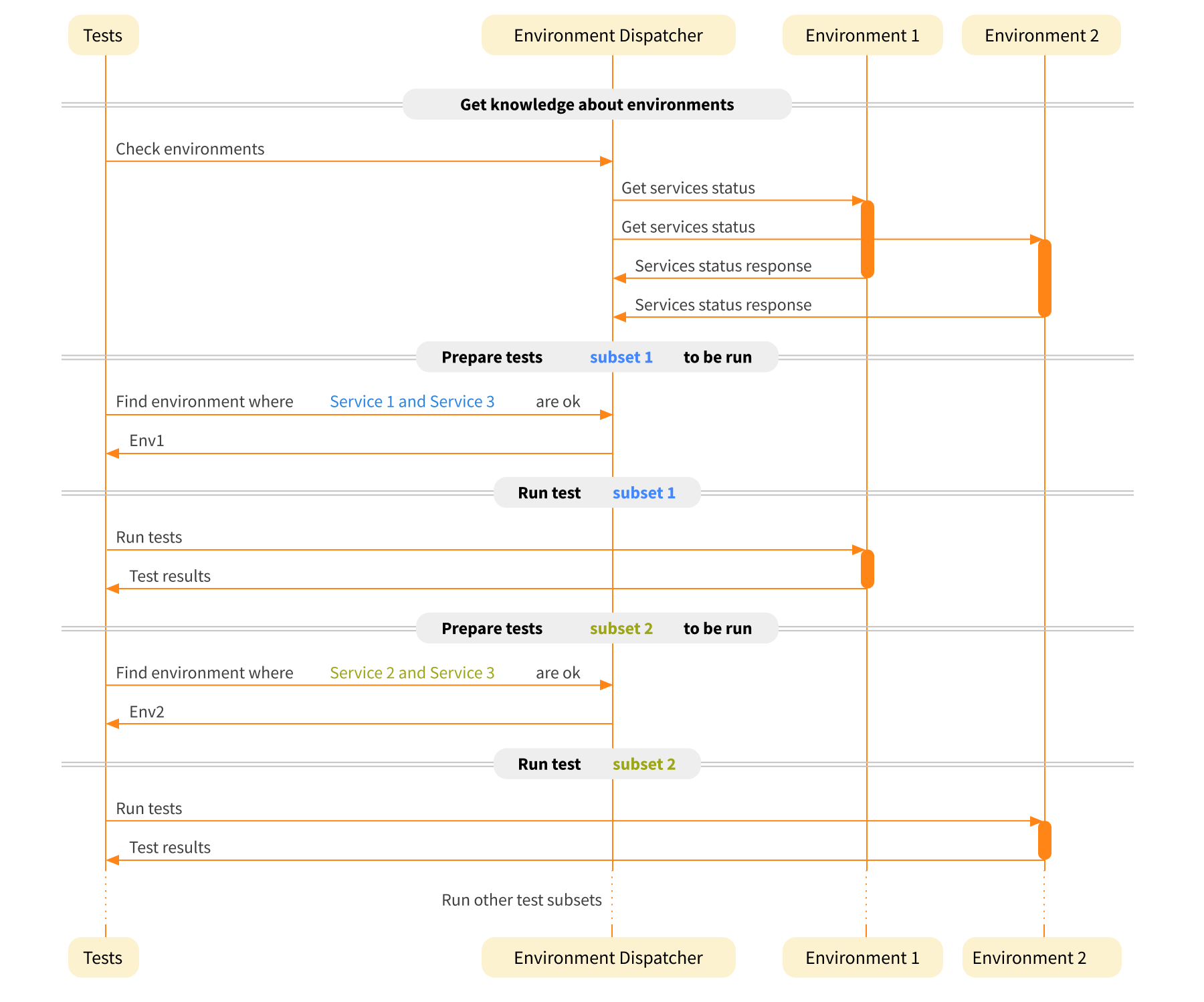
Often there are several test environments available that are best suited to different purposes. From low-level environments like Dev/QA to high-level environments like production. But no matter which environment you’re talking about, they all have something in common. Their instability. We have been doing test automation for more than ten years and have determined over that time that about 90 percent of environments have issues that negatively affect the results of automated tests. They are usually related to an absence of data, broken backend services, or incompatible versions being deployed. The remaining 10 percent of environments are either primitive ones that are easy to provision and deploy or are part of the production environment.
There are various approaches that can be taken to decrease the number of issues encountered but sometimes even this isn't enough. One of the things that we developed during our work on a large mobile automated test suite (700+ automated UI test scenarios) is a test environment dispatcher. This forms part of the test automation framework. The role of this component is to direct tests to an environment on which all services required by the test are up and running. The diagram below provides an outline of this process.
Using stubs, mocks, and fakes
Unfortunately, the runtime environment management may still not be adequate. Especially when you work with public cloud device farms. Backend services may be inaccessible from public services or the response time could be too long. In addition, sometimes your mobile application needs to connect to some 3rd party service, for instance to store crash reports. But you would like to avoid needing to gather statistics about crashes from local environments where crashes are very common during active feature development. This is a point where you would most likely use dummy services like stubs, mocks, or fakes. Stubs and mocks can help you get rid of unstable or hard to access services and emulate their work, while still having access to the main backend services of your system.
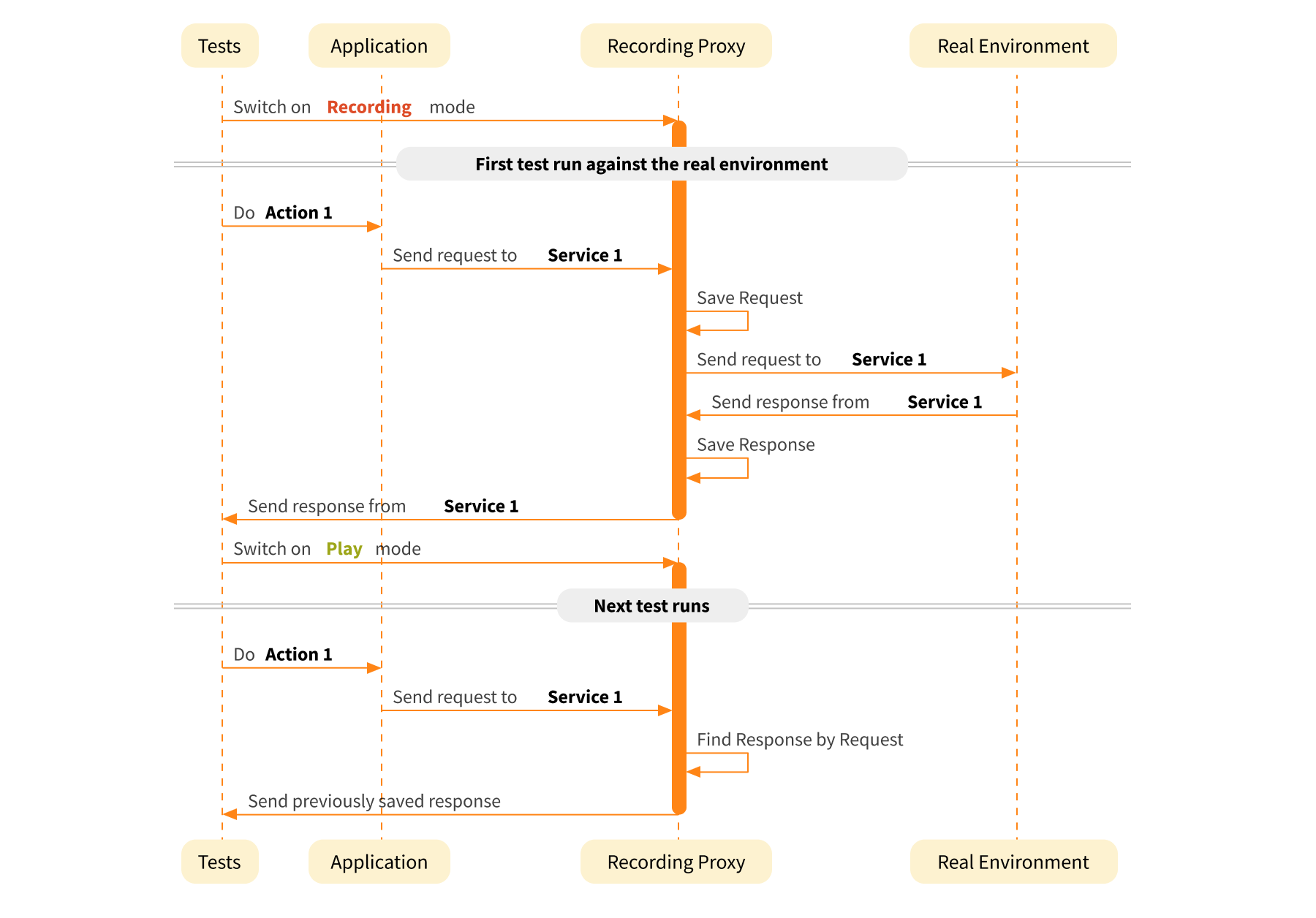
So, the next step is to eliminate the backend entirely and switch to a faked backend. The easiest way to achieve this is to use a recording proxy - once in ‘recording’ mode and then again in ‘play’ mode. Some of the services such as for secured connections can be bypassed by proxy (transparency mode). A more complex approach would be to create a fully functional faked backend, which has an internal state and generates responses according to the programmed logic. It can be helpful when you need to store a session key and then use it in the request to the service you are not going to fake. Or when you need to check whether a value has changed. For example, if you were to buy a ticket and the assertion is to check that the number of available tickets has changed. It’s not possible with a straightforward solution with a recording proxy, you need a stateful backend.
Looking behind the scenes
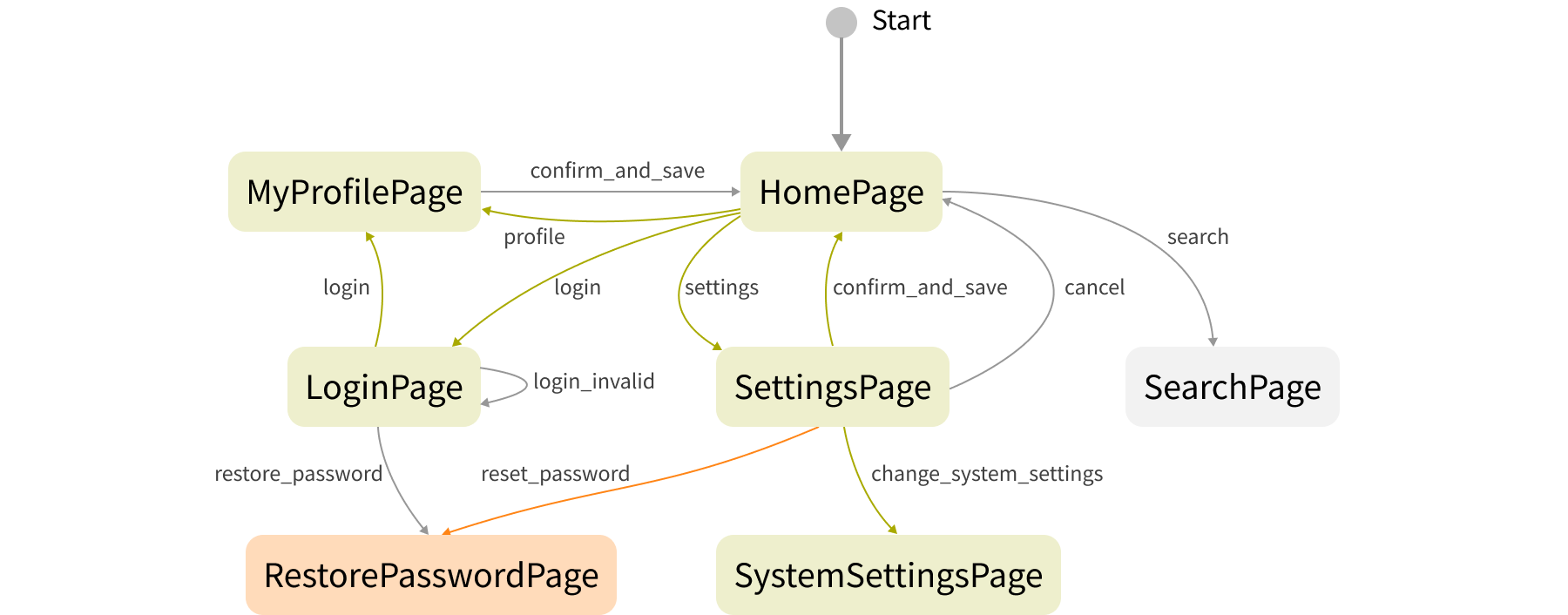
Many test engineers think that mobile testing is only about interaction with the UI elements. Certainly, the main goal is to simulate customer behavior and ensure that the application works well from the user’s point of view. However, there are many things that can improve mobile test automation that are hidden beneath the GUI.
Many of the recommendations provided here are difficult to implement without close collaboration with the development team. Usually they are ready to help and provide additional testability features or create some backdoors. We hope you have two different artifacts - ‘release’ and ‘debug’. The first artifact is the production version and the second contains all the testability tricks. You are in charge of asking developers to add special testability pages or methods (backdoors) that can be used from tests to the ‘debug’ version. But don’t forget to check they are absent in the ‘release’ version!
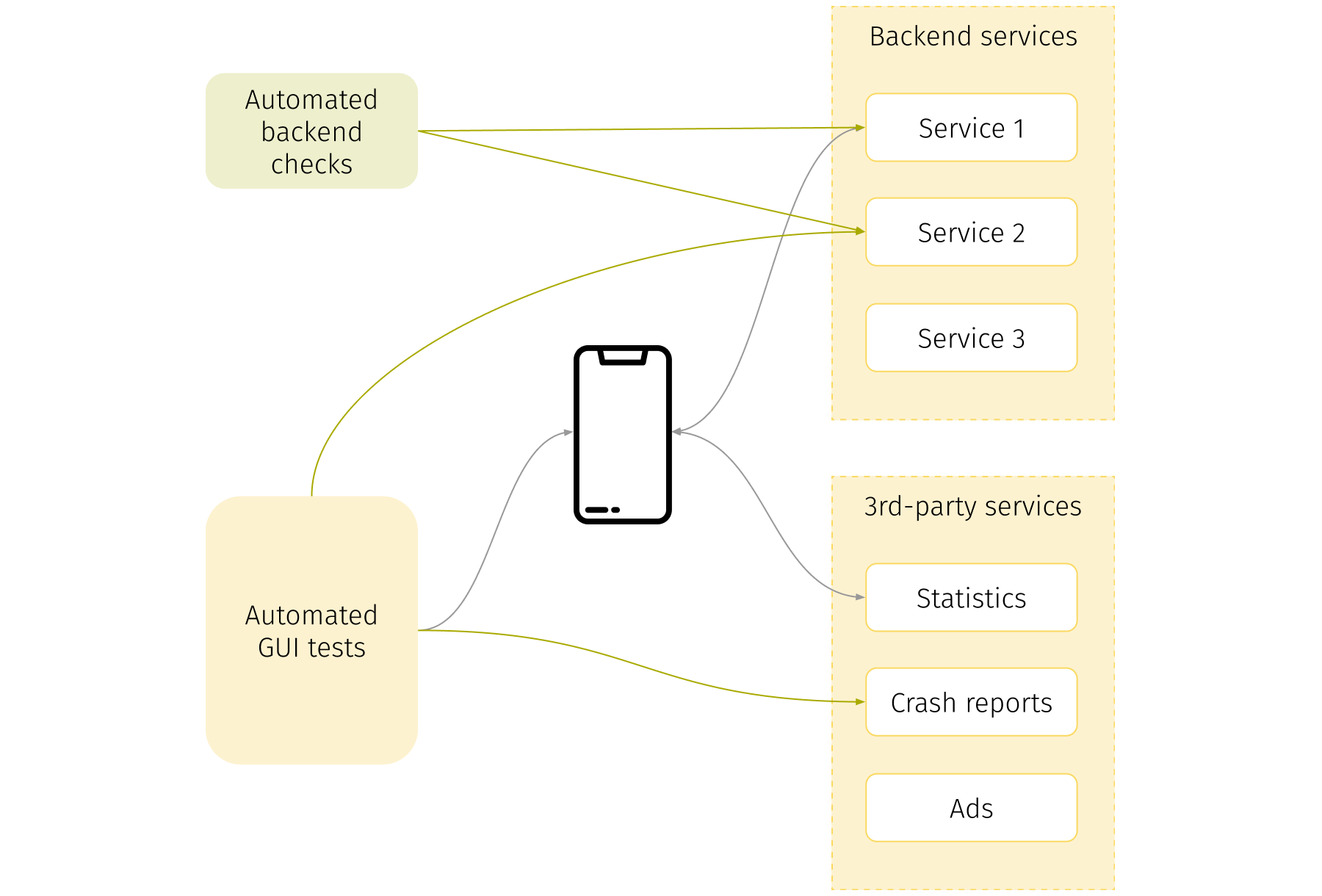
Now let’s look at the diagram above. The gray lines show the communication flows in a traditional approach. We recommend adding more communications wherever possible. Your GUI tests can directly go to backend services to speed-up some operations (e.g. to login to the system). They can also access some services like crash reports statistics and control it in runtime. Sometimes problems occur without any visual effects on the GUI.
The second useful recommendation here is to add a set of tests that will control backend services. It’s a kind of contract testing and your safety belt if you use stubbing. In addition, with these kinds of tests you can probe the environment and determine which services are working and which aren’t. It’s a prerequisite for the approach with Environment Dispatcher described in the “Proper work with test environments” section above.
Continuous optimization of tests and test runs
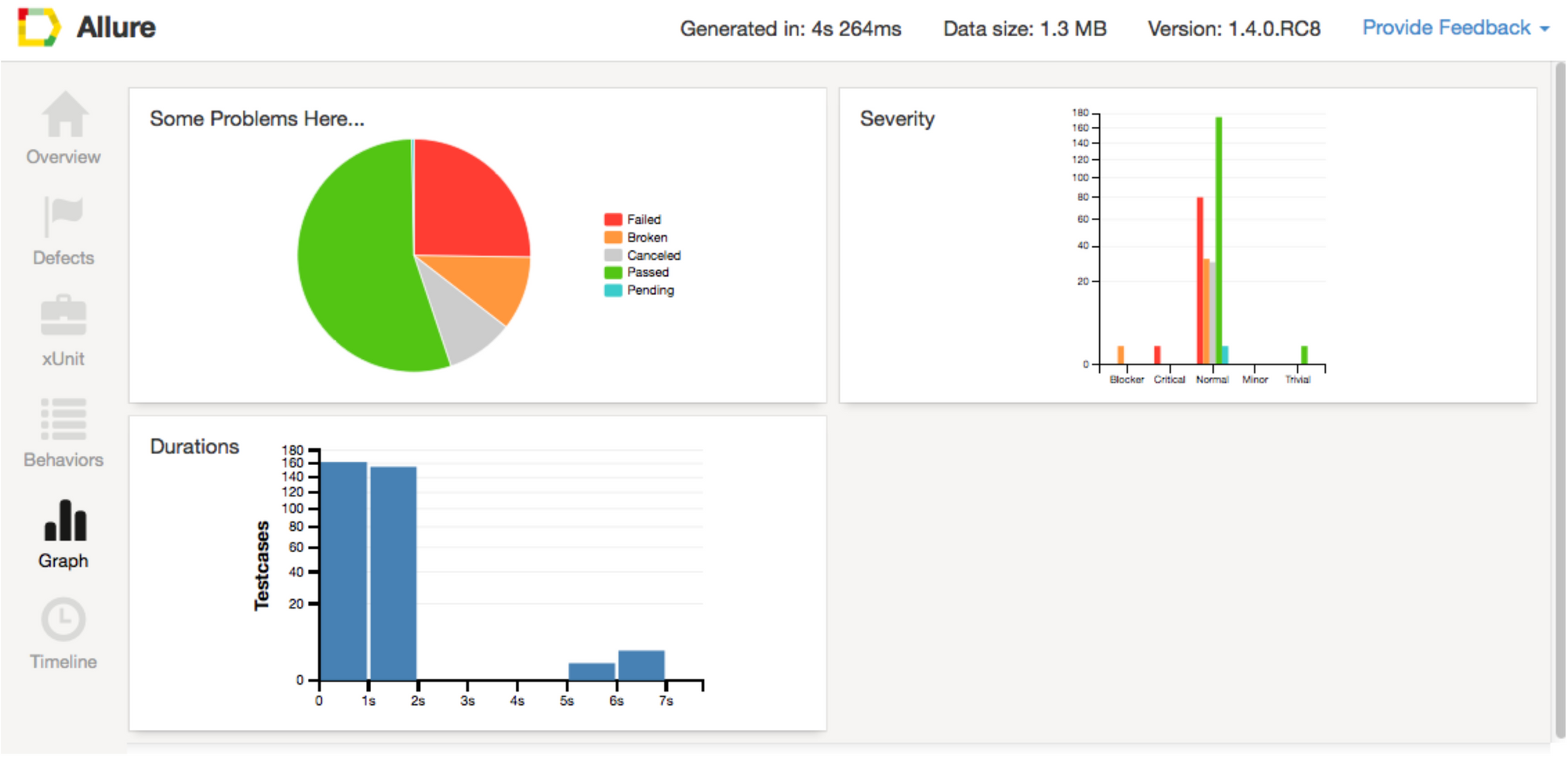
An automated test being written once usually will be altered only when it starts failing. This is the case with both test data or test framework methods. Sometimes you even know that code or test steps aren’t optimal - you use explicit delays, hardcode some data, duplicate functionality etc. These result in further problems with test support as tests can become flaky and the time required for test execution grows significantly. Similar things happen with test runs. At the beginning, they are fast and fairly stable and you don’t encounter difficulties with device management. The number of problems occurring increases as the amount of tests starts growing - more kinds of tests appear and more configurations have to be covered.
While running tests we suggest finding a balance between cloud device providers, private mobile farms and usage of emulators. General recommendations here could be to run tests as often as is rationally possible and gather a range of statistics. If you do not practice Continuous Integration - it’s time to start. The statistics and trends will help you to rework tests and the testing framework in proper time, before you get in trouble by having time-consuming, unstable, and unreliable tests. You can use allure reports, for instance, or other reporting tools to help you here.
The following test subsets must always be “green”, unless they face genuine issues in smoke tests and the production test suite. If they contain flaky tests it’s better to remove such tests from these subsets. In general, the more green tests you have in the regression test suite the more valuable the test automation is.
Coverage measurements
When you have 20 tests you may not bother about coverage metrics. You know every step of every test. You know what you test and what you don’t. When the number of tests is measured in the hundreds it’s hard to say what all these tests do without looking for the coverage map.
However, there are several coverage metrics you can gather even for quite small test suites. And first of all it’s mapping between tests and defects. It gives your developers a simple way to verify whether it has been fixed or not before committing the code.
Next, of course, are functional coverage and coverage of requirements. They are not the same as they may seem from first glance. For instance, in agile processes when you use user stories it is a good idea to tag tests with their numbers. It will help you when you investigate failures and try to find the root cause. Often it could be outdated acceptance criteria in old stories that are changed in newer ones. The coverage by functionality can help you to properly select tests when you are going to check regression in specific components or features.
For GUI tests it’s very important to gather the coverage by screens, transitions, controls, and paths. It’s an important issue in it’s own right so will be a good subject for an independent article. And such kinds of coverage metrics can help to identify coverage holes and excess tests.
Conclusion
As you can see these practices can be used not only in mobile test automation, they can also be adapted to other types of functional regression testing. When you start to use them their benefits become clear. This is especially the case in mobile test automation where test execution time can be significant and every instability in the test environment affects the number of tests.
Usually, if we estimate our test automation projects for mobile applications, they can be scored between 25 and 39 according to the attached checklist. We are ready to help to stabilize your mobile test automation using these recommendations and our extensive experience in this area.
Checklist
 Open checklist template (pdf)
Open checklist template (pdf)