

The e-Commerce Director for one of our client’s was concerned that reorder rates with customers were at an industry low. The root cause analysis pointed to the performance of their search order history function, which was so slow that customers couldn't find past order and quit in frustration. They needed to take immediate action and called ut to help.
When assessing the database performance regarding order search history, the response time, with the client’s Oracle SQL Server, was 2-5 seconds. Customers will not wait more than 3 seconds to retrieve information online, otherwise the customer will abandon the site without making a purchase, and have a negative experience.
The client lacked the necessary expertise internally to adequately address the problem, so they turned to us for help.
Our customer’s Oracle database performance requirements for this project were the following:
- REST API response time (95th percentile) < 150ms
- Customer response time (start of search to receiving a reply) < 3 seconds
- 2 years of order history - 120M orders, 80M order lines
- 20 days of shipments history - 5M shipments
- Update rate - 100-200K per hour (in total for all sources)
To address the above requirements, we designed an implementation using a scalable, open source Solr solution. Here is how we were able to solve the customer problem using Solr.
Order fulfillment database search basics
A typical order fulfillment database contains numerous tracking fields which can be used to extract various types of information. The queries listed below are examples of typical order record searches:
- Find an order by ID or Order No. (exact match)
- Find an order placed by a given user (exact match by user ID)
- Find an order by combination of:
- customer phone number (prefix filter)
- customer first/last name (prefix filter)
- customer email (prefix filter)
- status (exact match)
- orderPlacedDate (range filter)
- tracking number (prefix filter)
- Purchased items style (exact match)
- Purchased items color (exact match)
- Purchased items name (full text)
- Find a shipment by:
- shipmentDate (range filter)
- shipmentStatus (exact match)
- orderNo (exact match)
- orderId (exact match)
- customer phone number (prefix filter)
- customer first/last names (prefix filter)
- deliveryMethod (exact match)
- tracking number (prefix filter)
Your search engine should have the flexibility to handle all types of queries, quickly and efficiently without placing unreasonable demands on database file sizes.
To determine the most effective way to meet this requirement, we went through a 3-step progression, starting with an assessment of a conventional DB with B-tree inside, then a search engine without bitmaps and finally the utilization of a search engine with bitmap optimization.
Step 1: Why a B-tree-based index is not always a good idea
Many conventional relational databases use B-tree-based indexes to speed up the select queries. This indexed approach works well for search queries that contain a small number of attributes such as:
- Find order by ID/number.
- Find orders for a given user.
- Find orders for a given user, within a certain time range.
However, as we expand the searchable fields, the search process becomes progressively slower.
For example, let’s say we want to find orders that consist of a combination of data fields that include first name, last name, order status and phone prefix within a given time range. The database engine will normally use only the most selective index, in this case, most likely the last name. With the remaining search criteria, the database engine has to look through the additional set of results one-by-one. Such a process is laborious and time-consuming, especially if we are searching for orders in which the selective index is a common last name like “Smith” or “Johnson.”
An alternative approach is to use a compound index tailored for our specific search query, such as [lastName, firstName, Phone, orderPlacedTime]. While the utilization of a compound index will speed up the search, there is an inherent lack of flexibility. As a result, to implement a query with more searchable attributes, we have to create another index. This compounding approach rapidly becomes unmanageable because we have to build a new index for each type of query that we can potentially execute. If we want to
have a flexibility that can search any combination of fields quickly, we will have to build indexes for all these combinations. Thus, the number of indexes will grow as a factorial number of searchable fields.
The value of indexing is to speed up database read queries. However, this read performance comes at the expense of write queries. Therefore, the more indexes that are added, the slower our write performance will be.
Write speed challenges notwithstanding, it is important to understand where B-tree-based database management may still be a good choice for a search system. For example, in those instances where there is a short list of searchable fields or a low write throughput, B-tree is a viable approach.
Step 2: How a search engine (without bitmap) can help
Even though most case examples do not require a full-text search, we can still benefit from an FTS engine. We can observe that FTS and multiple criteria search processes are very similar. Therefore, engines optimized for FTS will efficiently perform multiple criteria searches.
A feature of the FTS engine, such as Lucene, is that it builds several independent inverted indexes, one per search criteria. In our case, it will build four indexes: lastName, firstName, phone, orderPlacedTime.
The FTS then iterates through these individual indices intersecting or merging results on the fly.
Let's look at an example. The table below shows eight orders in our database:
| Orders | ||
|---|---|---|
| firstname | lastname | order_id | John | Smith | 1 |
| Sally | Johnson | 2 |
| Sean | Johnson | 4,6 | Jane | Smith | 3 |
| John | Doe | 7 | Jane | Doe | 8 |
| Sally | Smith | 5 |
Let’s say that we want to find all orders placed by somebody whose first name starts with ‘J’ and last name starts with ‘S’. This task becomes easy when we obtain results from the inverted index that we built.
Looking in the firstname field, we find that order ID [1, 7] (John) and [3, 8] (Jane) belong to the person’s whose first name starts with ‘J’.
In the lastname field, we find that order ID [1, 3, 5] (Smith) belong to people whose last name starts with ‘S’.
Using some logical operations to filter the list: (([1, 7] OR [3, 8]) AND [1, 3, 5]) results in [1, 3)]. The orders from John Smith and Jane Smith fit our search criteria.
Even though this approach works, there is a better way. We can use a bitmap representation instead of the list of order_id.
Step 3: Why a search engine with bitmap optimization worked
Since we have 8 orders, we will need 8 bits to store the list. A ‘1’ in the bitmap represents the order_id. So:
- [1, 7] becomes 10000010
- [3, 8] becomes 00100001
- [1, 3, 5] becomes 10101000
The result now looks like: ((10000010 OR 00100001) AND 10101000) = 10100000. The ‘1’ in positions 1 and 3 represents order_id 1 and 3. The orders from John Smith (order_id = 1) and Jane Smith (order_id = 3) fit our search criteria.
| firstname | order_id | bitmap | lastname | order_id | bitmap | |
|---|---|---|---|---|---|---|
| John | 1,7 | 10000010 | Smith | 1,3,5 | 10101000 | |
| Jane | 3,8 | 00100001 | Johnson | 2,4,6 | 01010100 | |
| Sean | 4,6 | 00010100 | Doe | 7,8 | 00000011 | |
| Sally | 2,5 | 01001000 |
The bitmap approach is very fast due to almost instantaneous logical operations. It also is space efficient since our index is only 8-bit per term. Assuming each element is no bigger than a byte, the linked list will take 1 to 8 bytes worth of data, plus the list’s “own” overhead.
Moreover, as the number of records increases, the memory advantage of bitmap versus a linked list becomes more apparent. The memory footprint of the bitmap structure may be reduced even further by using compression algorithms. However, there is a small performance penalty due to compression/decompression computations.
Bitmaps, however, lose their memory advantage when we’re dealing with a sparse list of records. Say we have 10k records, out of which, only three match certain criteria, such as [1, 100, 9999]. If the record pointer is 32 bits, the list structure will take 3 x 32 or 96 bits. The bitmap will equal the number of records or 10k bits. File compression, namely Run Length Encoding (RLE), can help mitigate this issue due to the significant number of repeating zeros in the result.
Within the above context, let's revisit our requirements.
We need to be able to perform searches by the arbitrary combination of terms, and at the same time, keep the system flexible. An FTS engine seems like a good fit here. But not all FTS solutions can handle this equally well.
Taking what we would call a brute-force approach, if the FTS engines are so flexible and efficient, why don’t we just index every field?
It may be a legitimate approach when dealing with fairly immutable data. Unfortunately, if the data frequently changes, such as when there are order updates, the constant reindexing will take a toll on the performance.
Optimizations
If we take a closer look at the database fields, we might notice two interesting things:
- Many of the order attributes do not change that often. Fields like email, phone number or order items usually remain static after the placement of an order. On the other hand, and until order fulfillment, there will be a greater frequency of change relative to its status.
- Orders receive updates for a relatively short period. Even fast-changing attributes which have a mutable period, will settle into a relatively immutable state after which time the data fields will settle.
These two facts provide an opportunity for further optimizations in that we can split our data into two categories:
- Real-time: fast changing, orders that were recently placed, and are being actively updated.
- Historical: immutable data. The order is fulfilled, and its status does not change anymore.
Inside the real-time data set, you can split individual order attributes into two sub-categories:
- Frequently changing: such as order status
- Static: email, phone, shipping address, etc.
FTS invert indexes are great when it comes to retrieving immutable data. Thus, we can build an inverted index for the immutable fields and historical orders. That being said, what can be done with the faster-changing fields in real-time data?
What is the best way to conclude our search - B-tree or other ordered structures, or the forward index data structure? Let’s examine each option more closely.
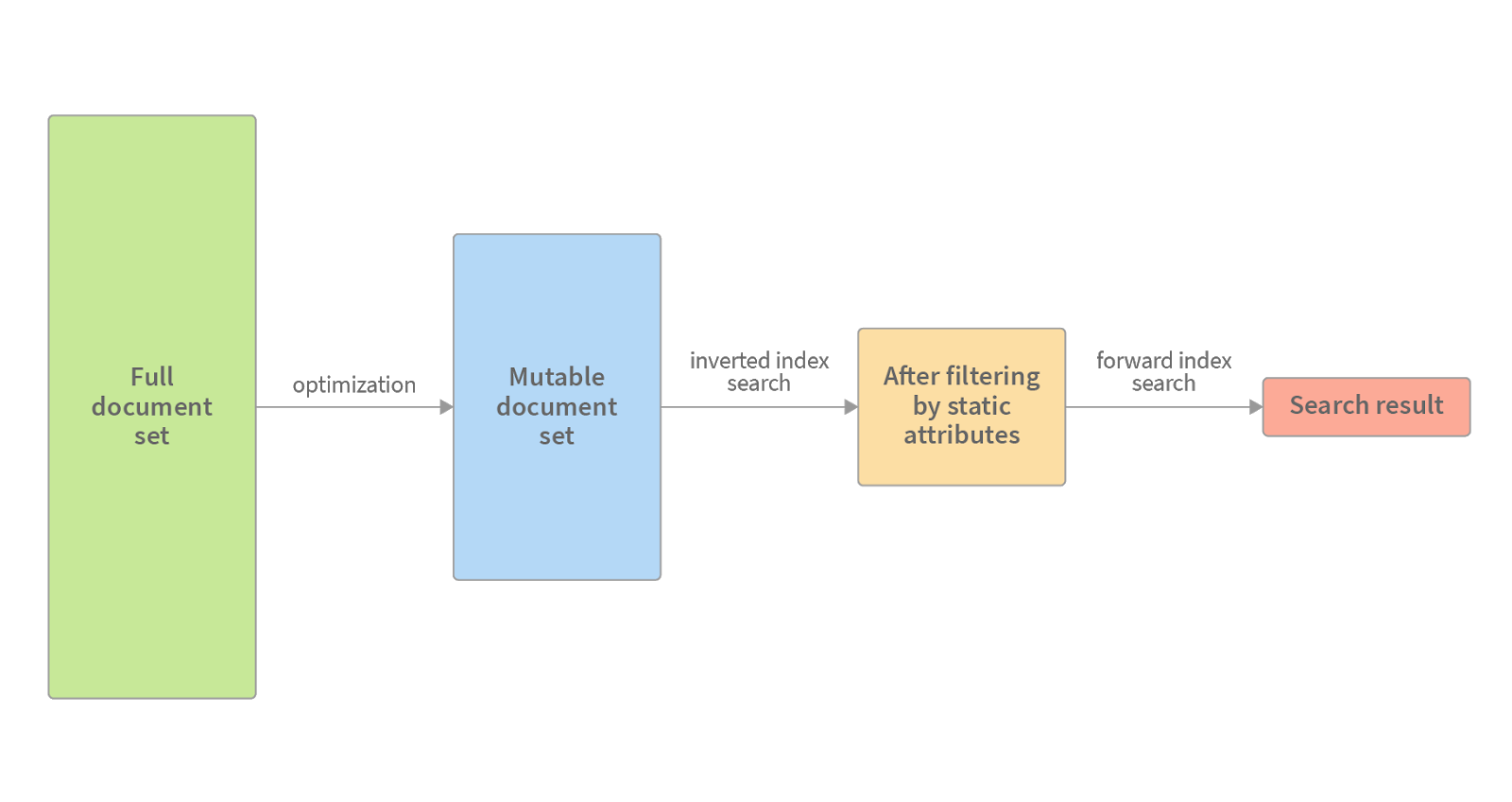
A hybrid model for mutable data indexing
While immutable data is indexed by the search engine with bitmap optimization, there are 2 options for mutable data indexing: B-Tree and Forward Index.
As the outlines below explain, both B-tree and Forward Index are in principle, good options.
B-tree
B-trees are notably good when it comes to adding and updating their nodes. It also provides sorting for the indexed field and hence log(N) search performance.
We’ve mentioned above that B-tree indexes are not very helpful with multiple attribute searches. However, since we’ve already done a pretty good job reducing the amount of dynamic data with which we will be dealing, it means that we have a relatively small, think ~300k document list.
In addition to a relatively small document list, we will perform the search utilizing the B-tree index only after all other criteria were applied thereby further reducing the document set. In the worst case scenario, while there will still be a linearly iteration through the dataset, the impact will not necessarily be significant since said dataset will be relatively small.
Forward Index
A forward index is nothing more than the “mapping” of a document into the search terms such as order_id -> status. Thus, it is very easy to maintain with add() and put() Map methods, both taking constant time to complete. The obvious price for these fast updates are longer gets. To search for the orders with a given status, we’ll have to iterate through the whole map. Not so much of an optimization, huh?
But as previously stated, we’ve already done a pretty good job reducing the amount of dynamic data, so we are again dealing with the relatively small document list. Since we will also perform a search in forward index only after the application of all other criteria, there will be a further reduction of the document set.
- OrderList, OrderDetails - 15ms (95th percentile)
- OrderSearch, OrderStatus - 76ms (95th percentile)
- Shipments - 130ms (95th percentile)
Issues such as the one discussed in this article regarding database performance are not unique to our client, almost every online retailer needs an order search function that is fast and works well. Replatforming to a scalable open source Solr solution is the most effective way to address slow search times to enhance user experience and improve reorder rates. Contact us today to learn more about our open source solutions!