

This is the third post in a series of articles on AI/ML-based decision automation in retail price management, this time focusing on implementation and technology. The automation of pricing decisions is a challenging task that requires a software system to understand business objectives and constraints, continuously analyze multiple signals and datasets, perform experiments, and learn from experience. In this article, we discuss how such a system can be designed and implemented using machine learning and economic modeling.
Design Goals
The design of an algorithmic price management ecosystem has to account for several dimensions of complexity.
First, a pricing strategy often includes multiple elements and use cases that need to be supported by an algorithmic system. Examples of such use cases include regular pricing, promotions and markdowns, assortment planning, and flash sale events. Pricing decisions across these use cases need to be coordinated to avoid inconsistent customer experience, inventory waste, or profit losses, and decision-making processes often rely on the same fundamental capabilities, such as demand forecasting. This suggests that a price management ecosystem must have a layered and modular architecture (both in terms of technology and organization) so that the fundamental capabilities are provided as reusable services, and units of business logic can be easily added or modified.
Second, a price management solution has to achieve multiple efficiency goals and deliver business value in several areas. The main goals that influence the design of the solution include the following:
- Policy-driven optimization. One of the key advantages enabled by intelligent decision-making components is that the entire solution can be designed to optimize pricing variables using business objectives and pricing policies as inputs. This is not an easy task, because it requires the system to properly account for multiple factors and signals, such as price elasticity of demand, price perception, market competition, and cannibalization. However, modern big data ecosystems and AI technologies help to overcome many of these challenges. The benefits of objective-driven decision automation include stronger optimality guarantees by replacing guesswork with mathematical optimization, lower execution risks through forecasting and what-if analysis, lower execution costs with advanced automation, and faster time to value.
- Advanced segmentation. Price setting involves a large number of variables that can potentially be optimized. In modern retail, it is not unusual to see different pricing components of each product changed several times a day, or personalized for each customer through targeted offers. From an economics standpoint, this helps to improve profitability through micro-segmentation, which accounts for differences in price sensitivity, price awareness, and the willingness to wait or substitute. The price management ecosystem has to provide enough flexibility and capacity to make billions of such fine-grained and dynamic decisions, as well as to scale as the number of channels, formats, products, or customer increases.
- Alignment with marketing, merchandising, and inventory. Pricing decisions influence or are influenced by other activities, such as marketing campaigns and inventory replenishment. Pricing, inventory, merchandising, and marketing areas have their own goals and constraints, which are traditionally challenging to coordinate because such multidimensional optimization is technically complex and often intractable from an organizational standpoint. These goals can also vary across the retail domains; for example, the waste of fresh products is a concern in the grocery industry, and the cost of returned e-commerce items due to price comparison after the purchase is a concern in the fashion industry. An algorithmic system can be designed to address at least some of these challenges by consolidating multiple data sources and using advanced modeling to account for multiple factors and goals.
Building Blocks
The high-level design goals defined in the previous section cannot be implemented without several fundamental capabilities. These can be considered as building blocks that can be wired together into an algorithmic pricing system. Most of these blocks rely on big data, economic modeling, and machine learning in order to achieve a high level of automation and quality of decision-making.
Forecasting
One of the most basic capabilities required for many pricing and inventory use cases is the ability to forecast future demand and profits. This capability is typically implemented with a statistical model that forecasts profits as a function of various inputs, such as the forecasting date range, product attributes like size and color, past sales data and prices, intensity of marketing activities, and, finally, pricing variables for the forecasting dates, as shown in Figure 1.
Figure 1. Profit forecasting for what-if analysis and optimization.
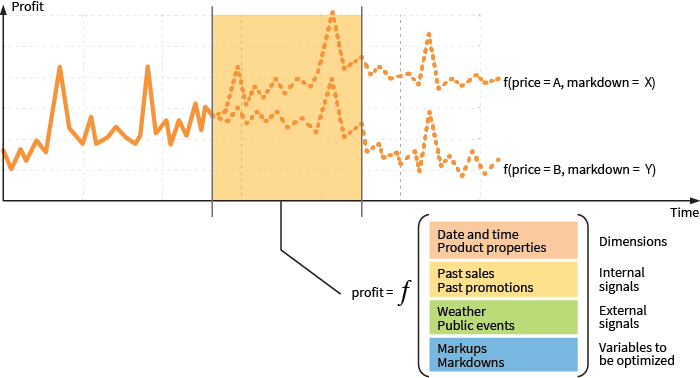
This model can be considered a generalization of the basic price elasticity analysis, and is often implemented using gradient-boosted decision trees or neural networks (i.e., models with relatively high capacity that can learn complex patterns).
Although the concept of profit forecasting is straightforward, there are many challenges in its practical implementation:
- Demand and profits are impacted by many factors, and even the models that produce accurate forecasts on average tend to miss some demand spikes. This issue can often be mitigated by extending the diversity of input signals to account for factors such as marketing activities and public events.
- A profit prediction model is valuable because it quantifies the dependency between price and profit. In practice, one product can be sold to different customers at different prices (for example, because of cart-level offers or bundles), and it sharply complicates modeling because prices turn into statistical distributions rather than fixed numbers.
- Profit forecasting for a given product relies heavily on its past sales history. However, a sufficient history is not available for new or long-tail products. This problem is typically alleviated by building models that use product attributes rather than product identities as inputs.
- Demand for a certain product depends not only on its price and discounts, but also on the prices and discounts of other products due to substitution and other cross-effects. This can make modeling and optimization intractable in some cases, unless the number of interdependent variables is reduced through clustering and grouping.
- Historical data might not have enough variability (i.e., a lack of observations with different combinations of prices, seasons, discounts, etc.) to determine how various factors influence profits. It is possible to work around this issue using dynamic experimentation, as we discuss in the next section.
Optimization
The profit model is a foundation for what-if analysis because it can be evaluated for different price values or promotion variables. Consequently, it can be paired with an optimization algorithm to search for optimal, profit-maximizing prices or promotion settings. For example, it is possible to build a component that takes the entire promotion calendar for the next few months, evaluates the profit uplift delivered by this promotion layout, and identifies promotions that should be disabled or adjusted (e.g., promotions for which the discount–volume trade-off does not break even).
A special type of optimization is opportunity finding. The basic optimization techniques are focused on finding profit-optimal pricing parameters, but some use cases require going beyond parameter tuning. Pivoting back to the promotion calendar example, the system not only needs to turn the predefined promotions on and off, but also should search for new promotion opportunities that were missed by a merchandiser. This type of optimization is often more complex and requires specialized algorithms.
Finally, optimization typically works in tandem with experimentation, so models are re-trained and re-evaluated continuously to incorporate ongoing data and feedback. In some cases, historical data simply do not have sufficient variability, and an optimization algorithm must iteratively test hypotheses in production in order to converge on the optimal solution. Methods such as multi-armed bandits can be used to efficiently minimize the necessary experimentation time and cost.
Segmentation and Differentiation
Forecasting and optimization are often supported by components that help to make more granular and differentiated pricing decisions. These components often have interfaces that produce scores and signals about products, customers, channels, or stores, which can be used by downstream optimization and decision-making logic:
- Once the promotion opportunities are identified and the offer parameters are optimized, optimal audiences for each offer can be determined by scoring individual customers according to their price sensitivity, propensity to buy a given product or brand, propensity to respond to an offer, or expected lifetime value. These signals help to maximize ROI by matching offers with customers, estimating redemption rates, and determining the optimal number of coupons. It is worth noting that these signals can be used for more than targeting: for example, some KVI scoring techniques require the identification of price sensitive customers, which can be done efficiently using propensity scoring techniques.
- Some price setting methods and use cases (e.g., introductory pricing) set the price for a given product using information about similar items. The product similarity scores can be improved by using a wide range of product data, including textual descriptions and images, and extracting attributes from the data using natural language processing and image classification algorithms.
- Pricing strategies for products are often differentiated using consumer price perception scores (i.e., the scores that quantify whether or not an item is a KVI). The KVI scores are often computed based on a comparison with bargain products and an analysis of price-sensitive shopping carts.
- Prices can be differentiated depending on a channel or store location. The differentiation strategy can be tuned using scores that account for the demographic profile of the location (e.g., median income, population density) and distances to points of interest.
Reference Architecture
The building blocks for segmentation, forecasting, and optimization must be assembled together into an algorithmic price management system. A reference architecture of such a solution typically includes several layers, as shown in Figure 2:
Figure 2. Reference solution architecture for algorithmic price management. Some dependencies are omitted for the sake of clarity.
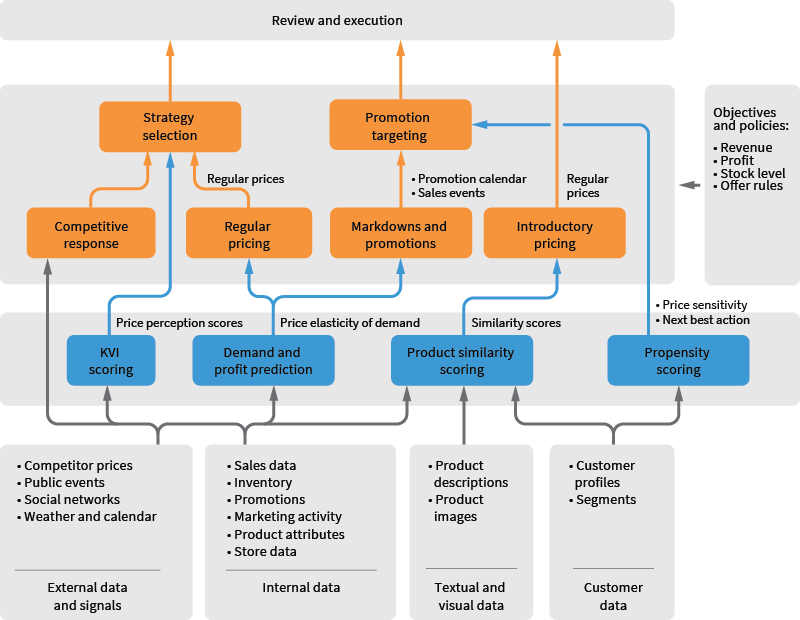
- The data collection and consolidation layer is the foundation of an algorithmic system because the range and quality of decisions made by the system is constrained by the range and quality of the data. It is often not trivial to establish this layer because data requirements for pricing decisions can go beyond the range of data provided by a typical data lake and enterprise data warehouse (EDW). For example, demand and profit modeling generally require external market-level signals, and internal transactional data are often insufficient for accurate forecasting. Even for the datasets that are typically available in a data lake, algorithmic price management can impose new requirements related to data stitching and data delivery. Typical issues include imperfect stitching of marketing and transactional data and an absence of near real-time inventory updates.
- On top of the data layer, there is a layer of statistical models that produces advanced signals and provides capabilities for what-if analysis. This layer typically hosts product attribution and similarity models, customer propensity models, and price elasticity models. These models can share the same technical infrastructure used for feature engineering, training, validation, production deployment, and scoring.
- The layer of solvers includes an array of optimization and decision-making components that optimize specific elements of the price waterfall or pricing strategy, such as regular prices, promotion calendars, and clearance sale events. This layer provides administration interfaces where merchandisers can configure pricing policies, business goals, and optimization constraints that drive the price setting processes.
- The pricing parameters produced by the solvers typically go through some sort of an anomaly detection and review process (e.g., all price changes with a magnitude exceeding a certain threshold are manually approved) and then are channeled to the digital and in-store execution systems. In practice, it is often possible to achieve very low anomaly rates such that only a small fraction of decisions require manual reviews.
The decision-making pipeline defined above is typically customized for different business units and product categories. For example, a department store might have different models and optimization policies for seasonal items (with the emphasis on inventory-constrained sale events), perishable items, and durable products.
All stages of the decision-making pipeline, including data collection, model re-training, and optimization problem solving, are executed repeatedly to keep up with the ongoing data and observed trends. This continuous re-evaluation is crucial for handling forecasting errors caused by external or unpredictable events, and a high level of automation is the key enabler of this process.
Use Cases
The reference architecture outlined in Figure 2 is able to support a range of pricing use cases, and also provides foundational capabilities for a number of assortment and inventory planning scenarios. Examples of use cases that are often implemented on top of an algorithmic platform are shown in Table 1.
Table 1. Examples of business use cases.
| Component | Use Case |
|---|---|
| Promotion Management |
|
| Price Management |
|
| Assortment Management |
|
| Inventory Management |
|
Implementation Approach
The design and development of an algorithmic ecosystem is a challenging undertaking for multiple reasons, including the wide range of pricing parameters and use cases, differences across the product categories, and the diversity of data needed for automatic decision-making. Consequently, algorithmic systems are often implemented iteratively to reduce time to value and risks. One possible approach is to structure the implementation roadmap around product categories so that models and solvers are developed for one business unit at a time. This approach makes the most sense for department stores that have multiple business units with distinct pricing strategies (e.g., apparel, grocery, home appliances). Another approach is to structure the program around the capabilities so that top priority functions, such as competitor response, are implemented first.
Conclusion
The first post in this series was about the risks and opportunities of algorithmic pricing, while the second was about pricing strategies. In this post, we explored how a price management process backed by predictive analytics and mathematical optimization offers a number of strategic advantages. These include more optimal and competitive pricing decisions, lower execution risks and loss prevention due to replacing the guesswork with forecasting, and lower operating costs because of policy-driven automation. These advantages can be achieved in a systematic way by implementing an algorithmic solution with layered and modular architecture. This provides the basic forecasting and optimization capabilities that accelerate the development of components for specific use cases. This architecture also makes it possible to share the capabilities and technical infrastructure with other areas of enterprise operations, including assortment optimization, marketing communications, and inventory planning. An enterprise can develop such a solution component by component based on its business priorities and gradually cover a full range of price management use cases across multiple business units.