
An application of microservice architecture to data pipelines

Building e-commerce analytics and product recommendations capabilities should start with data. And while data is abundant in the world of retail, it often comes from dispersed sources owned by either independent teams or external vendors.
That was exactly the issue that one of our large retail chain clients faced. They started by building data acquisition streams (known as ETL processes) to get all the data to the central data lake. The next step was populating the curated data warehouse, and adapting it for analytics needs. Thanks to cloud-managed ETL services, the process accelerated rapidly, and the development team added a few hundred data sources per quarter. But soon the progress slowed down. The reason behind it is quite simple: while it's easy to make a data processing pipeline in the cloud, maintaining hundreds of them simultaneously poses problems on another scale.
ETL sprawl: Understanding the situation on the ground
The company set reasonable data layout standards for its data lake early on. This decision soon bore fruit as the new data sources quickly proved their value for analytical purposes. On the downside, it put an additional burden on data ingestion, since ETL and data preparation pipelines have to maintain consistent data formats and layouts while dealing with evolving external data, a growing number of new sources, and ever-changing analytics algorithms.
The company hosts its data analytics in Microsoft Azure cloud so it has both Azure Data Factory (ADF) and Azure Databricks at its disposal. Both platforms offer decent Rapid Application Development (RAD) capabilities with rich web GUI.
ADF enables engineers to sketch an ETL pipeline in minutes and promptly deploy it to production. However, ADF data processing capabilities are quite limited, and the Azure Databricks platform helps fill the gaps. With Databricks, an ADF ETL pipeline can be extended with the arbitrary code for the Apache Spark platform, where the bulk of data processing lives. For smaller-scale data processing tasks, developers tend to use another Databricks feature – code notebooks. So in a nutshell, the system’s components are distributed like this:
- The ETL logic, data source connections and bulk data movement are in Azure Data Factory;
- Common data formats and shared data processing functions are in Spark code libraries on Azure Databricks;
- Pipeline-specific data augmentation and validation are in Databricks notebooks.
A typical data processing pipeline includes all these components, and that’s where the problem starts. While each cloud ETL platform has decent configuration management and deployment control capabilities for typical use cases, integration between platforms can be tricky. That’s the reason why the deployment of a regular data ingestion pipeline to production often becomes a multi-hour manual task.
It takes a seasoned engineer (like Brent Geller from "The Phoenix Project" novel) to upload the Spark code artifacts and code notebooks, configure them, and then connect to the ADF pipeline. They practically have to build the data processing application right in production. Needless to say that no processing is done during that time. And while it isn't as visible as an online service outage, it has a comparable impact on financial outcomes.
Besides mere operational difficulty, this approach also lacks a feature for tracking changes. If the data contains sensitive information that is subject to regulations, this may cause additional non-technical issues. And to put the cherry on top of the cake, it doesn't have any option for restoring the service in case of an accident.
It means that the change management process, from initial modification to release in production, causes bottlenecks in the development of ETL pipelines. It takes longer to add a new data source, adapt to an input format change, or fix a defect. As a result, the analytics gets more and more stale data, which in turn leads to irrelevant product recommendations and poor end-user experience.
Generalized problem: Optimizing organization performance
Data processing is often considered a specialization on its own, distinct from application software engineering. However, from a business perspective, it's just an information system controlled by software that processes data.
Organization performance can be benchmarked using the same metrics regardless of the exact product, be it an online web application or a data analytics service. The industry has a well-established set of four key metrics proposed by the DevOps Research and Assessment program (DORA): lead time for changes, deployment frequency, change failure rate, and time to restore service.In our case, lead time and deployment frequency are in the red zone, while a service recovery process doesn't exist at all. Taking that into account, the Grid Dynamics team suggested focusing on the most essential goals:
- Lead time from code change to production – within a day;
- Release frequency – on demand (multiple times per day);
- Scale-out development – O(n) cost for more data sources.
That's it – only direct improvements. Other important results such as toil reduction, sustainable quality, and service recovery process had to appear either as prerequisites or by-products.
Step 1: Developing the solution framework
How to improve feature delivery for an ensemble of hundreds of ETL pipelines? There is no definite answer. But let's come at it from a different angle: How to improve software delivery performance if the application system consists of many loosely connected components? This problem has tried and trusted solution patterns: microservice architecture paired with continuous integration and continuous delivery (CI/CD).
Microservice architecture
Microservice architecture is usually seen in the context of web services communicating over the network. But that isn't always the case. From a software development life cycle (SDLC) perspective, microservice architecture is a system design pattern where the system consists of loosely coupled components, communicating over an API, given that a component (a "service"):
- exposes its function over a stable, defined API,
- is maintained by a single team,
- is updated and released independently, at once.
The nature of the API doesn't matter. For example, in the case of ETL tasks, it may be the dataset format and location. Similarly to web services, this API has a server producing the dataset and an arbitrary number of clients using it.
Once the microservice architecture is implemented, each component is created, updated and released independently and automatically. The change management problem for a complex system with hundreds of components is reduced to SDLC management for simple monolithic services.
CI/CD
CI/CD is often confused with software build and deployment automation. While automation is important, it is not pivotal for application delivery performance. At the same time, frequent (daily) integration of changes to the shared code base and readiness of that code base for production deployment are of vital importance. Obviously, to make that work, such a shared code base must exist in the form of a single source code repository sufficient to build the application service component (single repository pattern). That said, having three repositories – one for business logic, the other for orchestration, and the third for configuration – won't do.
For faster and more efficient integration of changes, the team working with the repository should be familiar with the code itself and each other’s progress, so they can act as a single unit. It’s also crucial to have the source code in the repository that is sufficient to build a deployment artifact, which is then launched in a sandbox for testing. A lightweight change process for source code is a key prerequisite for CI. It’s because the integration happens in the source code repository and the cost of integration grows quickly (as O(t2)) over time. So there are no GitFlow and no release branches – only a single trunk branch and short-lived change branches to cope with GitHub code review limitations.
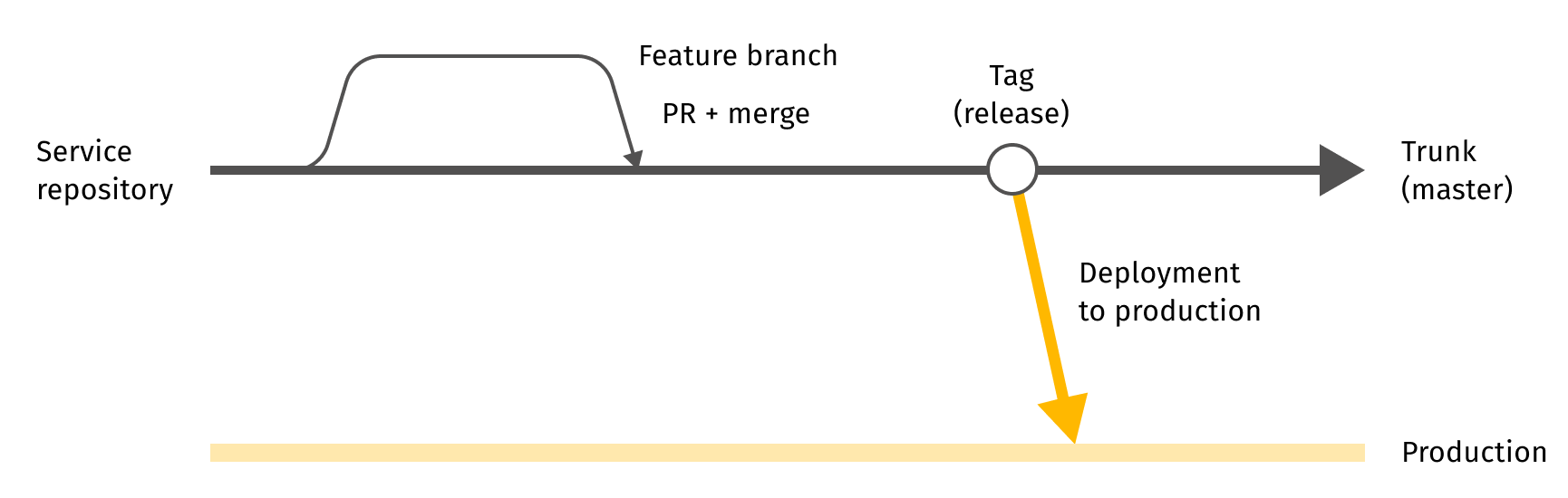
Continuous delivery, or its more powerful form, continuous deployment, requires a few more things – deployment automation being one of them. However, it depends on reproducible deployments across the necessary variety of deployment environments, from test sandbox to production. Thus, using the same immutable binary artifact, you can actually put into practice the “build once, deploy everywhere” principle. Clearly, the deployment must be testable and those tests should be automated at different levels, from simple validation of component-level constraints to integration verification.
Having the application following microservice architecture, and the change management processes following CI/CD principles, the application development team may achieve the desired goals for delivery performance and scale out the development efficiently.
Step 2: Implementing the solution
Microservices for data processing
In the context of ETL business, a microservice is a data processing pipeline that:
- produces a single cohesive data set and usually consumes a single data source;
- is updated and released at once, independently;
- is maintained by a single team.
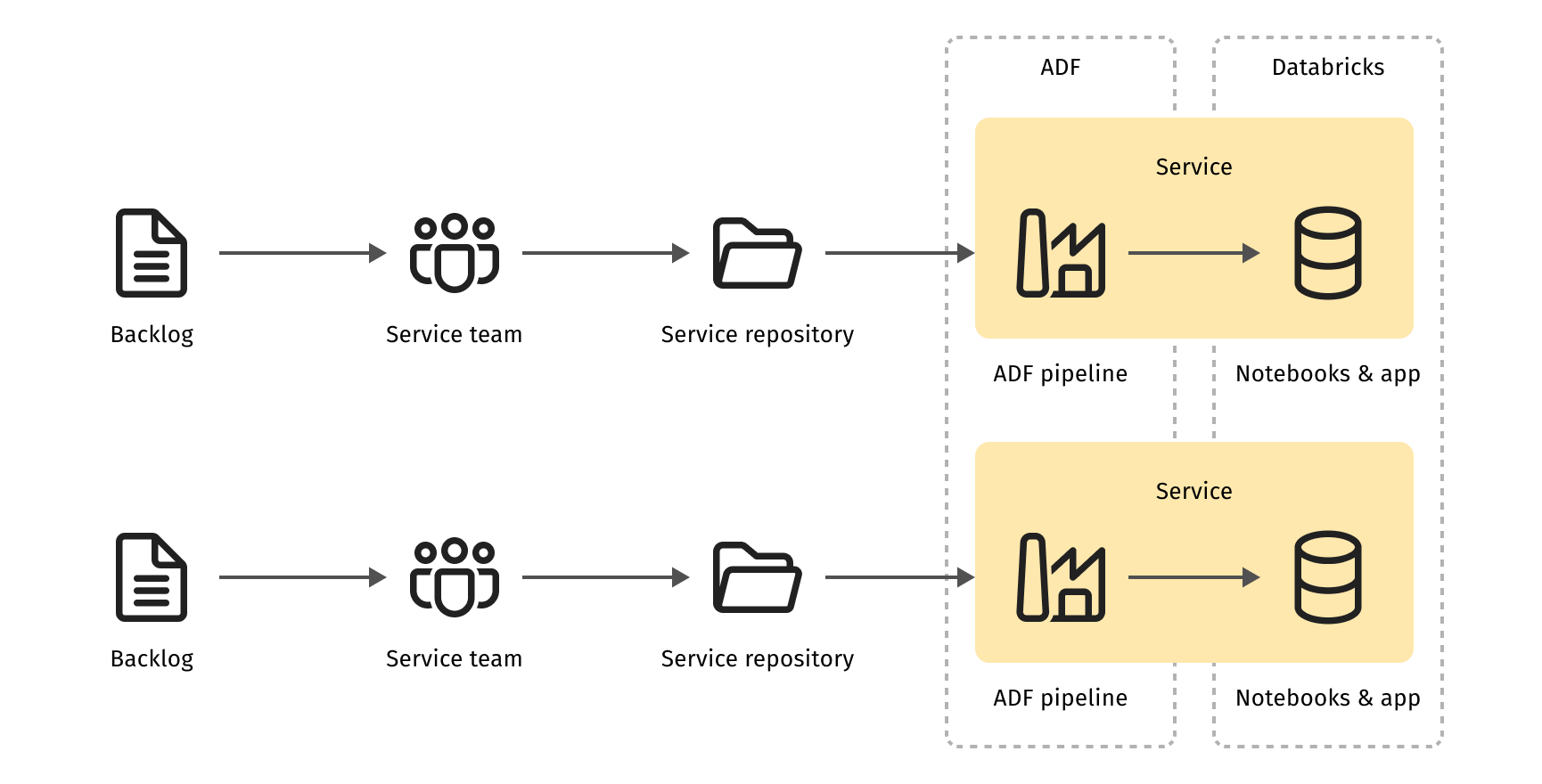
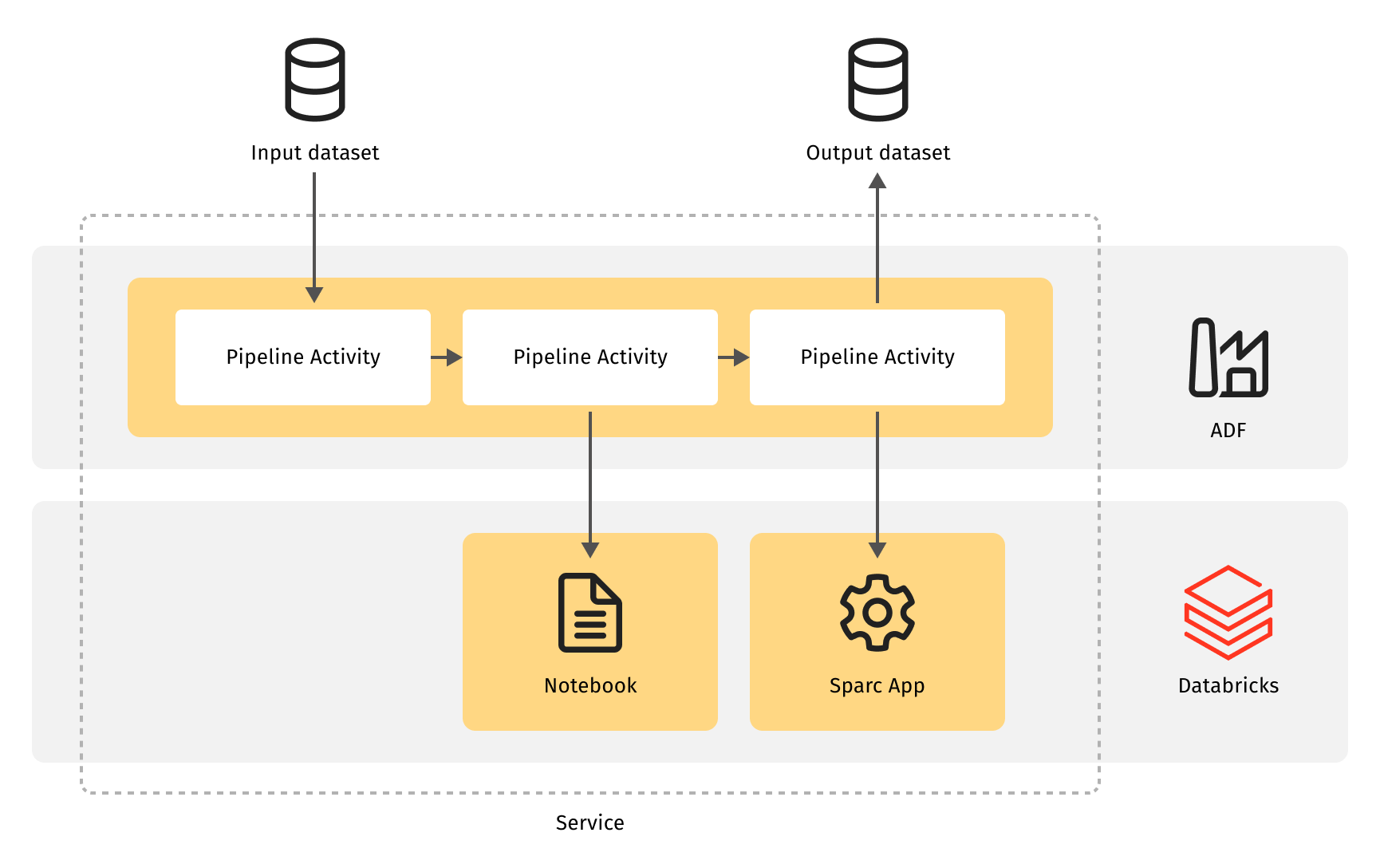
Technically an ETL microservice consists of control flow, business logic and API. The client already uses Azure Data Factories (ADF), so naturally, the control flow is implemented as an ADF Pipeline. It constitutes a sequence of ADF Activities (steps) doing specific things, such as moving data, invoking external computation, or implementing control logic. An ADF pipeline is the backbone of the data processing microservice, and it has JSON/YAML representation that can be stored in a source code repository.
In our case, the ETL processes have a substantial "transform" part – custom logic for data structure transformation, data cleansing, and validation. Shared Spark code artifacts traditionally implement the bulk of generic shared data processing logic. However, microservice architecture mandates component independence. Therefore, individual pipelines no longer share library JAR files in the Spark platform. Instead, each pipeline has its own instances of Spark libraries and configuration files. These files are deployed to Databricks Spark alongside the ETL service backbone, the ADF pipeline.
It doesn't imply that each ETL service has to have a copy of the Spark library source code. It is only necessary for application-specific Spark code. As a rule of thumb, shared kits of Spark transformations are developed for reuse.
An ETL service is a regular software component, so it leverages the library pattern. A library has its own source code repository and CI/CD (in the proper meaning of the term) pipeline for deploying the library JAR to the company's Maven repository (such as Artifactory). The other software components (such as ETL pipelines) just refer to the library JAR as a dependency in their Maven POM files, so the library file is pulled at the component build time and included in the component deployment artifact.
The client uses Databricks code notebooks to implement the specific part of ETL business logic. A "notebook" is a document combining human-readable material (text, images) and executable code. Its structure resembles a Markdown file with code blocks.
These notebooks were rarely shared, and considered to be code artifacts, hence implemented and maintained separately. Now, as a part of the data processing microservice, such notebooks rest in the same source code repository as the other service building blocks – ADF pipelines and Spark libraries. Databrick notebooks have a source code representation, which lives in the source code repository of the service.
Service API and service discovery are cornerstone features of microservice architecture. The service API is the dataset produced by the service, including the dataset location and structure. Though its mere existence is not enough to make a system emerge from a bunch of independent components, they still need something to find each other. Despite the decoupled nature of a microservice-based system, it's better to have this "something" shared, so that it can act as an exchange point for services to meet each other.
It calls for the service discovery pattern. Azure Data Factory has "Dataset" and "Linked service" logical components representing a real data set in storage. These components implement the service discovery function for ETL services.
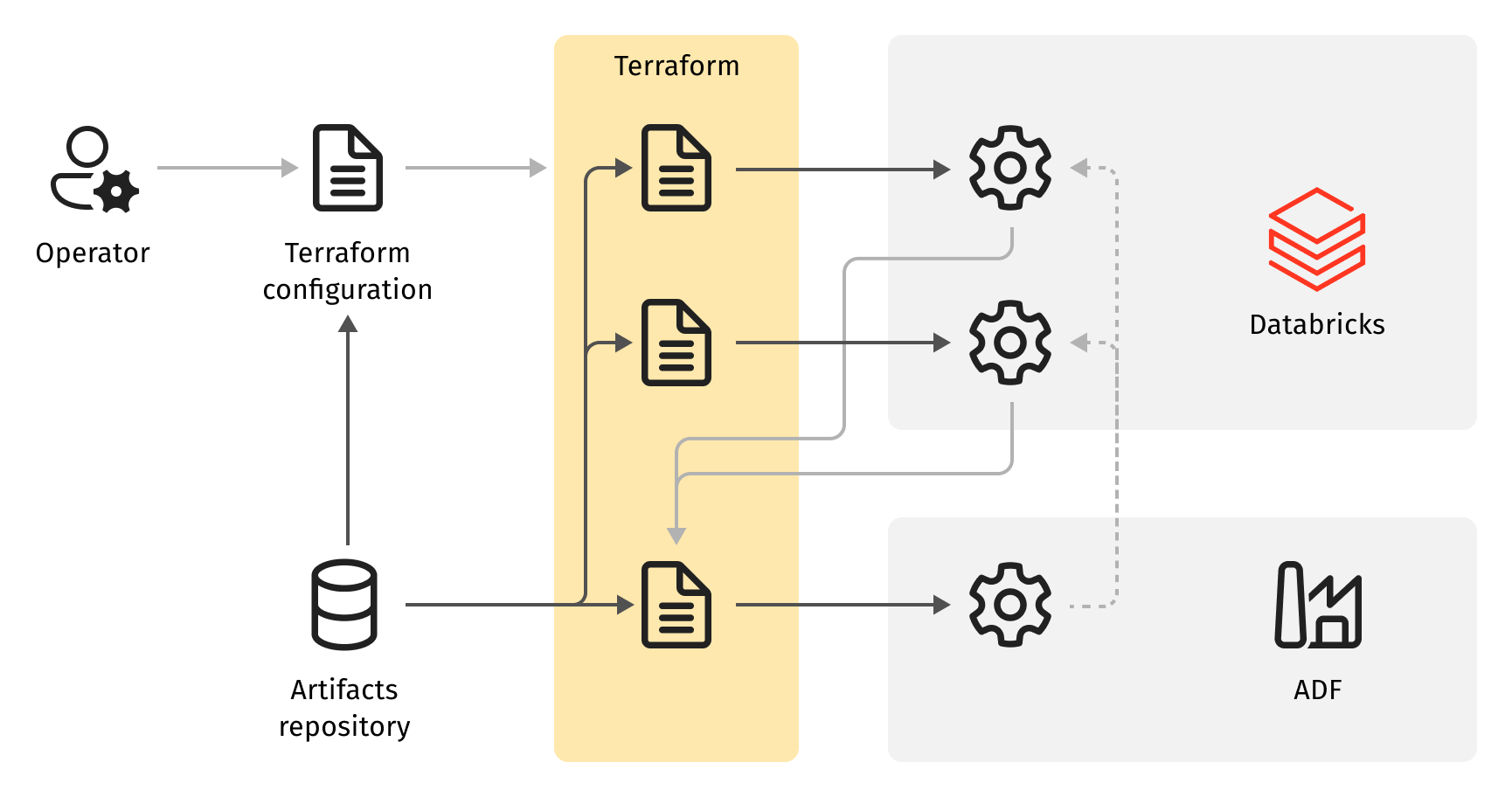
From an SDLC perspective, a microservice should be deployed atomically, and its deployment assembly should follow the single deployment artifact pattern. This deployment artifact should be a product of a single SDLC pipeline starting from a single source code repository. While at this point the source code repository content is partially known, it still lacks the integration part, something that can link its components, namely YAML (or JSON) representation of the ADF pipeline, Spark libraries as dependencies or in a source code form, and code notebook files, to the data processing pipeline.
The main integration issue is that the system’s constituent elements run on different platforms, either Azure or Databricks. Since neither of these two platforms manages the data processing pipeline end-to-end, the orchestrator pattern had to be employed to glue things together.
We chose HashiCorp Terraform as the implementation toolkit. It excels at managing API-controlled resources in different platforms, has solid support for both Azure and Databricks, and is easy to use. Terraform is a desired state configuration tool for virtually any resource that is represented by a CRUD (create, read, update and delete) API. It's controlled by code files declaring the managed resources and their relations.
At this stage, the code of a data processing microservice consists of:
- Azure Data Factory pipeline YAML/JSON;
- Databricks code notebooks files;
- Spark code libraries;
- Databricks configuration files;
- Terraform configuration that orchestrates the provisioning of the other parts and integrates them all.
From a systems design perspective, an application system comprises application components (implementing the application function of the system), and system components (implementing the runtime environment for the application components). Following microservice architecture principles, the system components are not aware of application components relying on them. Likewise, application components don't distinguish various instances of system components or, that is, different runtime environments. So the same application component can be launched in different environments using the same deployment artifacts without any change. It means that microservice architecture implies the "build once, deploy everywhere" principle. Besides convenience, this principle unlocks a few benefits:
- Testing results are transitive, so if an application deployment artifact passed quality control in a non-production deployment environment, there is a high likelihood that it will work in the production environment too.
- Promotion to production can be automated because, from a deployment perspective, the production environment is not different from any other.
The application continuous delivery or continuous deployment process also suggests microservice architecture for infrastructure components. When implementing deployment environments for applications these components follow infrastructure as a service pattern.
In the cloud, infrastructure components are usually relatively simple, combining a few cloud resources and some configuration. Thanks to Terraform, their implementation is easier as well. At this point, in addition to application services (data pipelines), we have infrastructure services (deployment environment), each in their own source code repository with a Terraform configuration for the service deployment.
CI/CD for data pipelines
In a microservice architecture, each service is self-sufficient with regard to SDLC. It means their source codes have everything necessary to build a service deployment artifact, which in the case of an ETL pipeline, is an ADF pipeline definition file, Spark libraries, code notebooks, and Terraform configuration.
There are hundreds of data processing pipelines and a bunch of new ones are added every month. In this case, the pipeline function is expressed by the ADF pipeline, Spark, and notebook code, with Terraform integration as a boilerplate piece. While this technology glues everything together, not that many data engineers are familiar with it. Due to the uniform structure of pipelines (ADF backbone plus Databricks Spark/notebook code blocks), the Terraform configurations of different ETL services are quite similar. However, the requirement of service code independence puts the burden of Terraform configuration maintenance on pipeline developers. Given the fact that there are hundreds of pipelines, it becomes a really daunting task.
Usually, code deduplication is addressed at build time. For instance, data processing services share Spark libraries by statically linking them to the service deployment artifact at its build time. However, it doesn't work in the case of integrating Terraform configuration. While a library is used as is, in immutable form, the configuration is created for the specific service, so different services have Terraform code that is similar in structure but different in content.
The case of ETL pipelines is very special as there is a large number of very similar services, which get relatively few changes once they are released. This peculiarity justifies a trade-off between toil reduction and pure-play microservice architecture. We choose the buildpack pattern to accommodate it.
Buildpack is a tool that creates an executable artifact from application source code while contributing its own code or logic to the resulting artifact. This technology was introduced a while ago by Heroku SaaS. Since then it has become an SDLC design pattern for a balanced trade-off between build reproducibility, and the ability to scale application development out in the case of many similar application components. Nowadays, buildpacks are widely used under the hood in "function as a service" computing platforms like AWS Lambda or Google Cloud Functions.
Buildpacks combine properties of translators and frameworks. The key difference from a translator (like a compiler or a build tool like Apache Maven) is that the resulting artifact is defined jointly by the application source code and the buildpack. While both contribute equally, the functional part comes from the application source code, and the boilerplate part is introduced by the buildpack. For example, a buildpack may bring its own Linux container base image, language runtime or specific code generation procedure. As it all happens at build time, the specific version of the buildpack is not defined by the application source code. Technically, this breaks the self-sufficiency of the service SDLC process. At the same time, it preserves deployment artifact immutability and the "build once, use everywhere" principle.
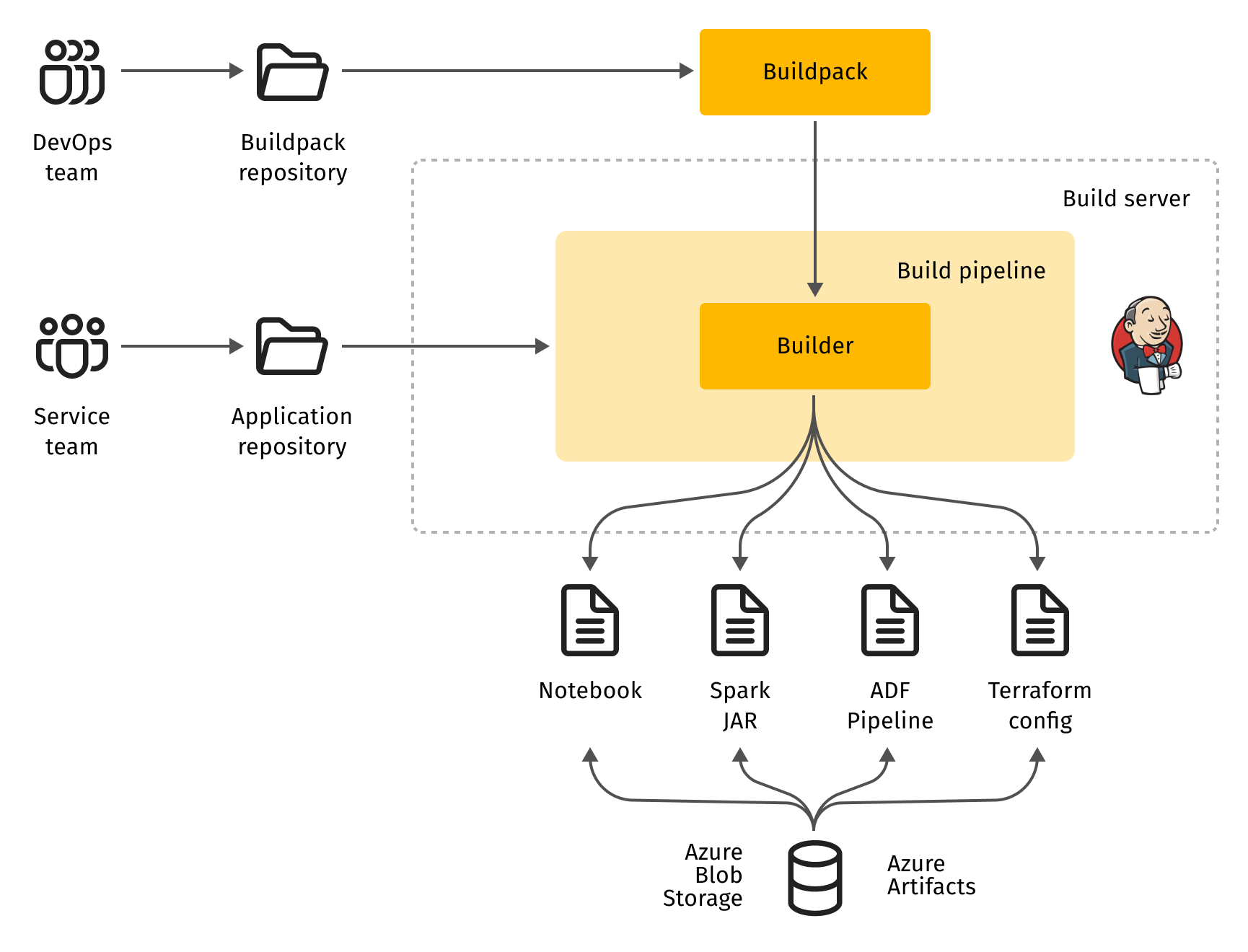
In our case, the buildpack for data processing pipelines was supposed to generate and validate the integrating Terraform configuration, relieving the application developers of creating it by themselves for each data pipeline.
Today, code generation is a well-established practice in software development. But it isn’t the case for application infrastructure. In this area, very simple scripting solutions still prevail, and "code generation" is usually replaced with text generation using generic text template processors like Python Jinja or "sed" command line utility.
A source code is a text, but a text doesn’t necessarily become a source code. A text template processor takes a template in the input, while the output is text. The templates aren't proper source code files. Template processors retain neither source code properties nor constraints during the text transformation. All they do is simply replace one string with another. If the output happens to be a valid source code file, it's just luck or sheer coincidence. Code generation tools, on the contrary, work with native abstract code representation and translate it to text only at the final stage. Thus, the output is guaranteed to be valid source code regardless of the inputs.
These days, there are a variety of options. For example, a range of Cloud Development Kits (CDK), pioneered by AWS, are available for cloud infrastructure definition languages, such as AWS CloudFormation, Kubernetes resources, etc. A good choice for Terraform is CDK for Terraform maintained by HashiCorp. This tool supports Terraform configuration code generation using popular general purpose languages such as TypeScript and Python.CDK for Terraform enables the team to create a buildpack that can read the application source files (ADF pipeline definition, Spark libraries, Databrick notebooks, configuration files) and generate the correct Terraform configuration. This configuration is packaged into the resulting build artifact, meaning that at deployment time, it's just plain Terraform.
In addition to Terraform code generation, the buildpack enriches the deployment artifact with tests. Some of them are like unit tests, which validate the generated Terraform configuration at build time. The others, e.g. the data not deleted by Terraform, are run at deployment time to check for basic yet important constraints. All of these test sets are open for extension, so the application developers are free to add specific test cases to the source code in the data processing pipeline.
At this point, an SDLC pipeline for a data processing service isn't any different from other applications on Azure. This implies that a similar build-test automation infrastructure can be used (usually Jenkins or GitHub Actions). Deployment artifacts are persisted in Azure Blob Storage. Furthermore, Terraform deployment automation is similar to the deployment automation of other applications or infrastructure components. Azure Pipelines are used as a convenient vehicle to execute deployment automation scripts in an isolated predictable environment.
Just like any declarative desired state configuration language, Terraform deployment scripts have an operational peculiarity. While developers define the configuration for the target environment, they don't specify the steps to getting to that state – these are calculated by Terraform. It may decide to modify or destroy a resource in order to complete the job. Generally, Terraform refuses to do obviously dangerous things, such as deleting application data. In addition to that, developers may further limit the scope of actions it's allowed to do with a resource.
Effectively, the developer is ultimately responsible for Terraform operational safety in all possible circumstances. This approach is heavily dependent on humans, and hence, is unreliable. To mitigate the risks, the deployment automation splits Terraform’s work into two stages, planning and application. At the planning stage, the program calculates its actions and generates a "plan". At the application stage, Terraform proceeds with making actual changes in the managed resources.
The deployment pipeline adds a validation step between planning and application. At this step, test conditions check if the necessary constraints are observed; for example, existing stateful resources holding datasets are not deleted. Buildpack can automatically generate some of the test scripts using reasonable assumptions about the ETL applications. This way, the deployment process of a data processing pipeline is safe by default. Yet, the developers still have the option to add other test scripts to the source code.
Microservice composition
As a specific interpretation of service-oriented architecture (SOA), microservice architecture possesses most of the SOA properties. For one thing, it is composable. It means that services created with this approach may be built from a combination of other services.
Data processing pipelines, as perfect functions (that is, a process translating input data to output without side effects), should also be easily composable. However, this is only partially correct. Since an ADF pipeline is the backbone of a data processing service, and ADF components (Datasets) implement service discovery, the composition of the data processing services is straightforward in many cases. For instance, pipeline chaining can work out of the box.
Fan-out (using the same data source to feed several data processing pipelines) works as long as the source dataset is "append-only", so neither source nor consuming pipelines truncate or otherwise mutate its content. Though that's a generally accepted practice, this composition pattern works just fine.
Aggregation is a totally different thing. It happens when several data pipelines contribute to the same data set. The feasibility of this pattern depends on dataset implementation support for concurrent addition. Here, the client made a foundational decision to employ the mergeable/appendable datasets using the Delta Lake format. As it has all the necessary properties, aggregation also works.
Sub-pipelines, however, are no-go. A sub-pipeline is an external data processing pipeline invoked as a step in the calling pipeline. It doesn't work because the data pipelines aren’t perfect functions – the datasets are persisted and accessed by reference, not by copy. The sub-pipeline pattern should be employed at build time, so the data service backbone is implemented as a combination of a few ADF pipelines acting as code blocks and not shared across data services at run time.
Step 3: Scaling out the development
Once the technical foundation was established, the team was ready to address one of the client’s main issues – scaling out data acquisition with additional ETL pipelines without having to expand the data engineering team. The guiding metrics were the time needed to launch a new ETL pipeline, and the time required to make a change in an existing pipeline. To launch a new data processing application, one needs to create a new source code repository, populate it with the application code, and then set up an SDLC pipeline to build, test, and deploy the application.
Code generation is an obvious option for seeding a software source code repository. There are examples of such tooling, e.g. Apache Maven Archetypes or GNU Autoconf. However, this option meant there would be an extra component for the data engineering team to maintain. Maintenance is a long-term commitment that doesn't create any direct value for the team, and is unlikely to pay off.
To tackle a problem of this kind and scale, the Grid Dynamics team resorted to the clone and update pattern. Instead of maintaining a code generation tool, it creates a simple template data pipeline service and publishes it on the company's GitHub. This way, the pipeline code repository can be cloned and modified to start a new data processing application. GitHub retains relations to the parent repositories, so boilerplate code updates in the parent template can be pulled to specific applications.
The repository README file guides developers through the initial modifications necessary to seed a new application from the template, leveraging documentation-as-code pattern. So, this template repository effectively works as a single point of entry for anyone willing to create a new data pipeline service. It removes the need to learn or to look for documentation, reducing the time to launch.
From time to time, software needs maintenance to reflect changes in the environment, such as external data format changes, runtime framework updates, security patches, etc. When there are hundreds of ETL applications, this may be a daunting task. At the same time, the similarity of these applications allowed us to unify their maintenance, which we achieved using these three methods:
- Code deduplication through leveraging shared code libraries and build-time linking.
- Boilerplate code generation using shared buildpacks.
- Pulling updates from centrally managed pipeline template code repository.
As discussed in the microservice implementation section, the existing ETL pipelines rely on common data processing functions for Apache Spark. These functions are developed separately from the ETL pipelines, assembled as versioned binary JAR files for Spark, and then distributed through the company's internal Maven repository. Applications specify exact versions of these dependencies in the application repository Maven POM file. At build time, the specified version of the Spark library JAR file is downloaded and included in the deployment artifacts. So while the library code is maintained in a single place, each data pipeline instance is reproducible, isolated and independent.
The team still occasionally has to update library versions for each data pipeline. However, the code change is minimal and it can be distributed from a central location in the application template repository (see below). A similar process could be used to share any kind of static files, such as code notebooks, static configuration files, or ADF pipeline fragments.
Besides Spark libraries, the major part of an application assembly is the runtime framework for deployment automation. However, as discussed in the SDLC implementation section, this part doesn't come from the application source code – the buildpack adds it at build time. Buildpacks are shared, and their versions are not pinned, so to update the buildpack with, for example, a new version of Terraform, one does it in a single place. Thus, when the following runs of all application build pipelines pick the updated buildpack, they will automatically support the new Terraform version. All that is left to do is to update the deployments of data application services. If continuous deployment is already achieved, the operator just needs to retrigger the SDLC pipelines, so the deployment can start automatically.
Spark libraries and runtime boilerplate code comprise data service code requiring maintenance. However, a little portion of it remains unmanaged. The application dependency update is one of those things. For example, once the Databricks platform updates its supported versions of Spark, all jobs need to pull the updated Spark libraries.
Because such an update affects the functional part of the application, it shouldn't be done in a one-click fashion. Yet, it’s possible to minimize the effort required to make those changes. Since all application code repositories on GitHub are "forks" of the application template repository, they retain the origin-clone link. Hence, some of the meaningful changes (such as dependency version updates) can be done just once and only in the template repository, and then pulled to the application code repositories (clones or "forks").
At this point, the data engineering team had a seed code for the new data application service, and established the maintenance procedure for the source code. To deliver the service to production, the next thing they need is the SDLC pipeline.
This is nothing new. Most modern build-test automation services have a feature for watching a GitHub organization (the client uses GitHub Enterprise), and setting a chain of build-test steps from a template when a new code repository is created. From the SDLC automation perspective, all these data pipeline applications are identical, which makes provisioning automation trivial and easy to implement using Jenkins (the SDLC automation server in use) stock functionality.
So here are the steps that data engineers take in order to create a new ETL pipeline:
- Clone the template data pipeline repository on GitHub.
- Update the identity of the new application in the source code.
- Push the update to GitHub.
Recalling the beginning of the story, the problem arose because the client's ETL processes used resources from different platforms – Azure (Azure Data Factory, ADF) and Databricks (Databricks Spark and Databricks Notebooks). Each platform has convenient SDLC tooling, as well as solid Rapid Application Development (RAD) facilities, that is, cloud IDEs for ADF and Databricks Notebooks respectively. Leveraging these tools, data engineers can develop a data pipeline without leaving the web GUI of the platform. In this case, the team’s task was to solve the integration part. They managed to do that, but the solution came at the cost of losing the platforms’ RAD tools.
Since in the microservice architecture, a service has (and is anchored at) a single source code repository, we had to use this GitHub repository, and not a platform-specific application logic representation for the executable code and composition. Fortunately, all three systems (ADF, Databricks and GitHub) work with Git repositories. Despite Git-hosting services (such as GitHub) claiming it to be the "server" (central point of some centralized service), Git is a peer-to-peer system. So as long as the source code file system layout eliminates conflicts between ADF and Databricks-authored inputs, changes in both cloud RAD environments can be integrated into the same GitHub repository with a little help of serverless automation. This facilitates the CI (continuous integration) part of the process. On top of that, when coupled with the automated SDLC pipeline, it propels the CD (continuous delivery) part, thus enabling full CI/CD capability.
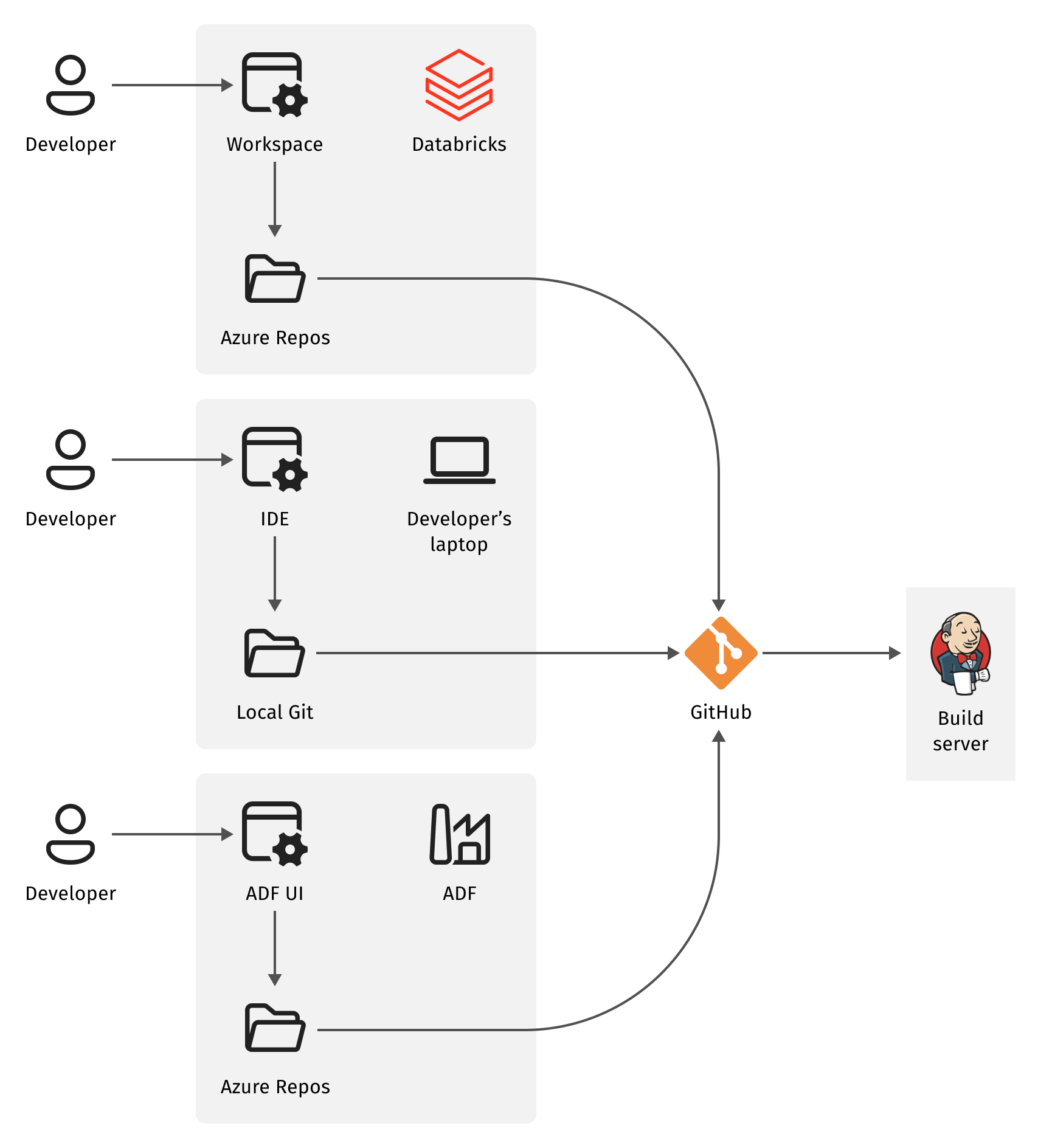
So, thanks to the microservice architecture, the automation process described above reduces the lead time for introducing changes in data processing applications to a few hours instead of weeks.
Solution applications beyond data pipelines
What's interesting about this case is that the solution is not specific to the problem facing the client. The Grid Dynamics team had to employ a few design patterns, none of which were dedicated to ETL workloads, data processing jobs, or any particular kind of application. We’ve singled out two problem properties that proved to be crucial for untangling this issue:
- the application system consists of a large number of similar components;
- component functions are independent.
That's it. These were the only things we needed to choose CI/CD as the value-delivering framework, microservice architecture as the system design pattern, and buildpack pattern for deployment artifacts assembly. That means that the solution we’ve created can be employed for any application that meets the above-mentioned criteria, whenever there is a need to scale out or speed up the application development process. Check out some of its potential use cases:
Generic process orchestration, including data processing, event processing, and business process management, is an obvious example. Typically, there are numerous orchestration workflows, which are frequently added and updated. The workflow orchestration engine usually doesn't do any actual work, but rather invokes external worker processes. These applications rely heavily on existing orchestration, computing frameworks, and cloud services. Apache AirFlow and AWS Step Functions are often seen as orchestration frameworks, while the actual work is done by cloud-managed serverless functions (such as AWS Lambda or Google Cloud Functions), map-reduce frameworks (such as Databricks Spark, Google DataProc or AWS EMR) or generic batch processing such as Kubernetes Jobs.
The solution can also be applied to implement the SDLC process for web services with a wide, albeit shallow API. It may serve numerous faces of a website, extract pre-configured custom data sets from internal data sources, or produce custom reports. An implementation may involve a serverless cloud computing service, an external API orchestration facility (such as Kong), a CDN (such as Akamai), data storage services, or a message-passing middleware.
In addition to orchestration workflows and web services, this approach can also be useful in these domains:
- Data acquisition – due to the breadth and variety of external data sources.
- IoT – due to a wide range of field device types and their generations.
- Monitoring and surveyance – due to a vast array of telemetry information and processing needs.
- Reporting – due to ever-changing requirements and growing demand for reporting capabilities in the enterprise environment.
Takeaways
Application delivery process improvement programs often fail, as they are full of conflicts, and poisoned by bespoke automation for the sake of automation. In the present case, we had a chance to do it right. Here are some of the practices that enabled us to achieve the desired outcome:
- The top-down approach to application delivery process improvement. The delivery process is essentially about communication, so a broader context is necessary. While the team of deployment automation engineers may excel at technology on the ground, when these tech solutions are applied narrowly it brings nothing but complication and confusion.
- Rely on design patterns. SDLC management (sometimes incorrectly referred to as "CI/CD") is often confused with bespoke automation of code builds and deployments. At the same time, the industry offers a great deal of comprehensible, tried-and-true solution patterns. Moreover, these patterns facilitate predictable project communication, enabling reliable planning.
- Avoid obfuscation of generic problems by trade-specific terminology. If something is called "data engineering" or "artificial intelligence", it doesn't mean that the data is not data anymore or that software becomes something fundamentally different.
As you can see, we didn't use any sophisticated new technologies. On the contrary, we leveraged the tools the client was already familiar with, which greatly reduced friction, allowing the team to work at full speed.