
Anomaly detection in industrial applications: solution design methodology

Modern technical systems cannot operate optimally without special tools for health monitoring, fault detection, and predictive maintenance. This is the case even for relatively simple systems, such as a service elevator. As for more complex industrial systems - like a power plant or an assembly line - various tools for technical diagnostics are absolutely necessary.
Solving problems of this sort involves a broad range of statistical and machine learning anomaly detection techniques and approaches. No technique or method could be considered universal, and the choice of tools and methods is typically dictated by specifics of the particular system. Nevertheless, it is possible to formulate the methodologies and best practices that help to identify the right solution approach based on the properties of the system at hand.
In this article, we describe a solution design methodology that is based on the types and availability of the labeled data. We delineate here not only the general strategies for three types of data labeling, but also point to some hidden pitfalls which frequently pass unnoticed and may result in productivity disruptions and even project failures.
1. Prerequisites for anomaly detection in IoT
Although the patterns described here are rather general and not directly related to any particular implementation, there is still some minimal set of requirements to the overall technological context. If these requirements are not met, it hardly makes sense to even pose the problem which is being solved in this article, let alone discuss the approaches to its solution.
1.1 Data availability
The information for feature generation should reflect at least some minimal set of fundamental characteristics, which should be known to make reliable decisions on the state of the industrial system. Normally, such information comes from sensors of various types, allocated at properly chosen points. The physical nature of the characteristics measured by the sensors may vary: temperature, vibration, pressure, mechanical strain, voltage, and many other physical properties. Nevertheless, besides the mere availability of the data, a common requirement is the data adequacy, e.g. some minimal accuracy should be guaranteed.
1.2 Data continuity
Most, if not all, mathematical approaches to diagnostics of technical systems require a more-or-less regular stream of vector data where each data-point reflects the state of the system at a particular time point. Even though some mathematical techniques exist for dealing with missed data, the fraction of such missed values should be at a reasonably low level.
1.3 Connectivity of the sensors and data collection
Besides the mere registration, the primary measurements from the sensors should be aggregated at some place with reasonably small delays and represented as a vector of values for further processing. Thus, some sort of connectivity of the sensors is required, as well as the technical possibility to represent the measurement in a suitable digital form. Fortunately, in many modern industrial systems, the paradigm of the internet-of-things (IoT) is already incorporated, and these requirements are normally met.
1.4 Domain knowledge for feature engineering
In most cases, primary sensor data cannot be directly used as the features for ML-based and statistical methods, and some feature engineering phase is required. For example, the primary data might have dimensionality that is too large which hinders the application of most mathematical methods (“the curse of dimensionality”). Another example is mismatch in sensors’ bandwidth: vibration sensors (accelerometers) have the output data rate of, say, 4000 Hz while the ambient temperature sensors - only 0.1 Hz.
An adequate transformation of the primary data into feature-vectors suitable for ML-based and statistical algorithms requires a certain minimal knowledge on the sensor’s specifics, the physical meaning and the potential role of their readings in the context of the industrial system and its operational logic. Such knowledge can be in at least two forms: various types of documentation and the expertise of a client’s personnel.
1.5 Availability of historical data with proper labeling
Most mathematical approaches - both ML-based and statistical - imply a stage of “learning” from data. In industrial applications, such data are normally collected during system operation, although they could also be accumulated in the course of additional experiments. Besides the data itself, some knowledge on the system’s status (normal or faulty) corresponding to various portions of the data is necessary (data labeling). Such a correspondence is normally established by human experts, and is labor intensive.
Although one class of the situations we consider below in section 7 does not require explicit labeling, it still requires some expert knowledge to select the portions of the data with low probability of positive (faulty) data-points, e.g. by calendar periods.
2. Typical data labeling limitations
Many approaches to the diagnostics of technical systems are based on classification of the historical data available. All data-points are split into classes corresponding to at least two categories: the "normal" operation of the system and the "faulty" or abnormal operation.
Such two-class labeling is usually an expensive procedure because it requires extensive time and resources from qualified experts in the field. Moreover, some other objective limitations often exist; e.g. a lack or complete absence of the "positive" (i.e. abnormal, faulty) cases in the historical data available for the given system. Therefore, the data to be dealt with are often one-class labeled (normal-only). In some cases, no explicit labeling is available for the data to be dealt with. We consider in detail the approaches corresponding to these 3 types of labeling in sections 5, 6, and 7 below.
3. A toy model example: fuel station
To illustrate the basic ideas in this article, we will use an extra-simplified toy model of a real technical system - a fuel station. There are only two sensors in our model: a counter at the output of a fuel tank (connected by a pipeline to a single fuel dispenser) and another counter, at the output of the dispenser.
Let $x_1(t)$ and $x_2(t)$ be the increments in the readings of the two counters during the time interval $[t-T, t]$. In other words, $x_1(t)$ and $x_2(t)$ are the outflows in liters of the fuel during $T$ previous seconds as registered by the two counters at moment $t$.
The normal operation of the fuel station is described by a simple "fuel conservation law": $x_1 = x_2$. Deviation from this relationship might signify a leakage in the pipeline ($x_1 - x_2 > 0$) or some errors in the readings from one counter or both ($x_1 \ne x_2$).
The normal state of the fuel station may be geometrically represented by a one-dimensional manifold (the line $x_1=x_2$) in a two-dimensional space of all possible states ($x_1$, $x_2$) (see Fig. 1). In an ideal case of small measurement noises, the "normal" states of the fuel station (dark blue points) are at the normal manifold (the light blue line). The points corresponding to an abnormal state - fuel theft - deviate from the manifold of normal states (the two red points).
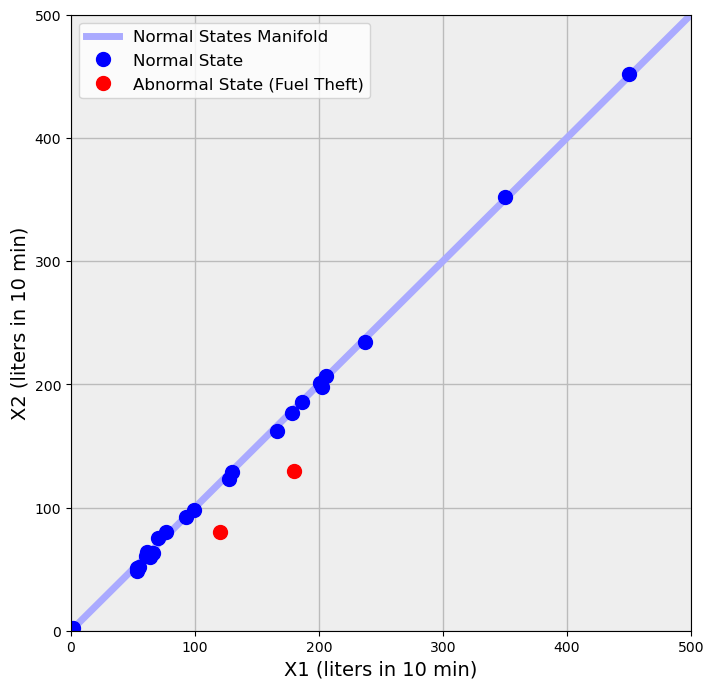
4. Notes on the terminology
4.1 "Anomaly" vs "outlier"
In academic and technical literature, the terms "anomaly" and "outlier" are often used interchangeably. In simple terms, both mean that an observation differs too much from a vast majority of others. Many mathematical methods exist for the problem of "outlier detection" [1], including methods oriented at high-dimensional data normally met in industrial applications [2]. Most of them are used in an unsupervised manner and, hence, oriented on purely formal analysis of the values of feature-vector $X = (x_1, x_2, \ldots, x_N)$.
We differentiate between the term "anomaly" and "outlier". The connotation of "anomaly" here is closer to "fault" or "potentially faulty state" of the industrial system itself, not to unusual mathematical properties of the data. This term reflects the underlying anomalous state of the system rather than formal deviation of the vector of features from the "cloud" of its historically typical values.
Suppose one applied an outlier detection algorithm to the data in Fig.1. Most such algorithms ascribe the highest outlier scores to the points with large distance to the nearest neighbors or, in simpler words, to the points deviating too much from the cloud of typical points. The outcome is shown in Fig.2: two points are now classified as outliers (green) even though they are “normal” points belonging to the normal manifold.
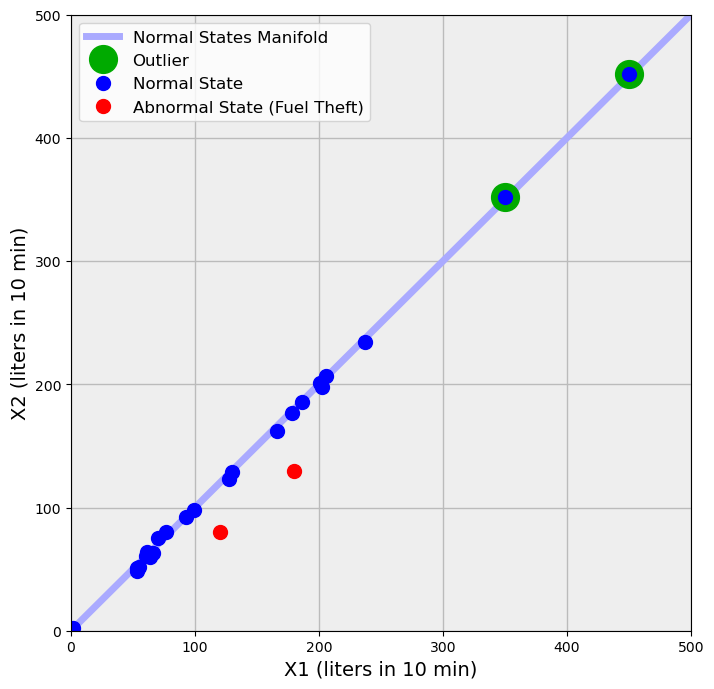
At the same time, two anomalous points (red) have not been classified as outliers: because they are too close to the cloud of typical points. Thus, “anomaly” does not necessarily mean “outlier” and vice versa.
The two points (green) marked as “outliers” really could be classified as “anomalous”, but only from the standpoint of customers’ behavior. Really, more than 350 liters of fuel was pumped out in 10 minutes in these two cases, while in most other cases this amount rarely exceeds 200 liters. Typically, drivers refuel 20-50 liters at once and, even if cars arrive continuously at peak hours, there are still natural pauses between refueling. If the pump productivity is 50 liters per minute, then the maximal amount - 500 liters in 10 minutes - could only be achieved if at least 500 liters has been refueled at once. It is really an unusual (=anomalous) situation. Nevertheless, we are focused here on the detection of anomalous states of the fuel station itself, not on customers’ behavior. From this vantage point, the two “outliers” are absolutely normal.
4.2 “Anomaly” vs “fault”
The terms “anomaly” and “fault” are often used synonymously. For example, the meaning of “anomaly detection” and “fault detection” grossly overlap in technical literature. We use the term "anomaly" in a softer and broader meaning as compared to "fault". Suppose the deviation of the system’s state from the normal manifold is already noticeable, but it is still within acceptable limits. Such a deviation of characteristics in an unwanted direction is an anomaly in our terminology, even if it is formally not a fault yet.
For example, the standard accuracy of fuel dispensers in the US is 0.3%. Suppose a newly installed dispenser had the accuracy of 0.1%. In the course of its exploitation, the accuracy gradually deteriorated from 0.1% to 0.25% and, thus, it still meets the standard. Such a deviation is not a fault yet, i.e. it does not require immediate reaction. On the other hand, it is an anomaly which still requires attention and could be an early precursor of a fault (exceeding the 0.3% error limit).
4.3 “One-class learning” vs “semi-supervised learning”
A special emphasis in this article is placed on the ML-methods dealing with a single training dataset corresponding to the normal state of the system. It is in stark contrast to the classical supervised learning on samples from two classes. To highlight the difference, some authors apply the term "semi-supervised learning" to such approaches. This terminology is potentially misleading, however, because the traditional understanding of "semi-supervised learning" implies the availability of a large fraction of unlabeled data accompanied by a small fraction of labeled data, normally split at least into two classes. Therefore, in our view, the standard term "one-class learning" is much more suitable for such situations, and is intuitively understandable. We also consider one-class learning as a supervised learning approach because only labeled cases are involved in training.
4.4 Are “one-class learning” methods supervised or unsupervised?
In the description of “one-class classification”, e.g. one-class SVM, such methods are often classified as unsupervised. Many authors refrain from classifying one-class classification approaches as either supervised or unsupervised. We still believe that such a classification is essentially context-dependent. For example, if the whole set of available data is used for learning, then it is reasonable to classify such an approach as “unsupervised”. The data-points classified as “positive” are just outliers differing from the majority of points in some respect. On the other hand, if the dataset comprises bona fide “normal” data, e.g. labeled by human experts, then the term “supervised” is more suitable here. The data-points classified as positive in this case are much more likely to be real technical anomalies in the system, not just purely mathematical curiosities. The following opinion supports this argument: “Therefore, OCC [one-class classification] is considered to be a supervised learning problem whereas outlier detection is unsupervised” [3]
5. Scenario #1: Only the data labeled as "normal" are available
This case is the most frequent in our practice: data are either initially presented in such a manner by our client, or we have had to transform the initial labeling for various reasons described in sections 6 and 7 below. It is natural to use “one-class learning” approaches in such cases. Here we consider three classes of technical systems and corresponding approaches most suitable for each class, at least as the first-choice approach.
5.1 One-class supervised learning
The term “one-class classification” might seem paradoxical at first sight. It is radically different from the traditional two-class classification described in a multitude of books and papers. Only one training sample with “normal” cases is used for one-class learning. The goal is to learn how to discriminate between the “normal” cases and all others, which are considered “abnormal”.
The “one-class classification” might seem exotic. Nevertheless, in our experience, in many if not most practical problems, it might be the most productive approach - at least as the initial first-step approach - which could then be accompanied by other methods. The idea to use one-class classification is quite trivial if only a dataset with normal data is available. But it might seem counterintuitive if one has datasets labeled by two classes or not labeled at all. Therefore, these two classes of situations are discussed in detail in sections 6 and 7.
5.2 The system is close to a “dynamical system”: Use time-series-analysis approaches
A “dynamical system” is a mathematical concept. A dynamical system is described by its vector state $X(t)$ at moment $t$. Its state in future moments $t’ > t$ is fully determined by the current state $X(t)$ and the dynamical laws, i.e. by the differential equations describing the evolution of the state-vector $X$ in time. For example, most models of classical mechanics are dynamical systems.
The mathematical apparatus of dynamical systems has proven to be adequate and useful for analysis of a broad class of real technical systems. Such systems are characterized by one or a greater number of periodic motions; for example, various rotatory machinery: turbines (wind-, gas-, steam-, hydro-), electric motors and generators, internal combustion engines, fans, compressors, pumps, etc. Another example is diagnostics of oscillatory phenomena in various technical structures like machines, buildings, bridges, etc. Before the advent of ML-technologies, such systems were analyzed by means of spectral analysis (FFT, dynamic spectra) and, later, linear autoregression-based methods. Application of ML-based methods could expand the capabilities of the classical techniques.
An essential peculiarity of dynamical systems is that their consecutive vector-states - $X(t_1), X(t_2),\ \ldots,\ X(t_N)$ - are linked by rigorous mathematical relationships. If the properties of such a system are disturbed (to incorporate an anomaly), then the relationships change. Such a change may be detected by ML-methods, provided the time-series data are transformed into a form suitable for ML-algorithms.
The procedure for data preparation is as follows:
- Firstly, obtain a vector time-series $X(t)$ corresponding to the state of the technical system in its normal operational mode.
- Secondly, transform the data for generalized autoregressive ML-based approach: for each consecutive $L$ moments of time, get the $L$ vectors $(X(t), X(t-1), \ \ldots, \ X(t-L+1))$ and reshape them into a single one-dimensional feature vector $X’(t)$ of size $L \times N$.
Here $N$ is the dimension of $X$, e.g. the number of sensors. This provides a single data-point for time $t$ represented by a vector $X’(t)$ of size $L \times N$. Repetition of this procedure for all available moments of time provides us with a training sample suitable for most ML-based and statistical methods.
5.2.1 Time-series-prediction based approaches
The general idea of such an approach is to train an ML-model to predict the next vector-value of the time series from its $L$ consecutive previous vector values [4], i.e. to learn a function $F()$ with small enough error of prognosis:
$$
\begin{aligned}
\hat{X}(t+1) &= F( X(t),\ X(t-1),\ \ldots,\ X(t-L+1) )\newline
\text{Error} &= E\left(|| \hat{X}(t+1) - X(t+1) ||\right) < \varepsilon
\end{aligned}
$$
Here, $X(t + 1)$ is the state vector of the system at time moment $t+1$; $\hat{X}(t+1)$ is the state vector predicted by the model $F()$ from $L$ previous vector-values; $||X||$ is some norm, and $E()$ is the averaging operator. Thus, such an approach assumes $L \times N$ input features and $N$ output values of the model.
In other words, one trains a model to predict the next value of the vector time series from $L$ previous values. The training sample is assumed here to correspond to the normal state of the system. For dynamical systems, such a prediction is always possible if the noise level is low enough. Then, the trained model is applied to new data, and the prediction error is analyzed. If the prediction error is at the base level - the one found during the training on the normal data - then one concludes that the system is in its normal state. If the magnitude of the prediction error is significantly higher than the base level for normal data, then one concludes that the data-generating mechanism has changed, i.e. the system is in an anomalous (=non-normal) state. Some statistical inferential procedures are normally used to make a decision on whether the increase in the prediction error is statistically significant, but the general idea is essentially the same.
5.2.2 Manifold learning approaches for time-series data
The $M = L \times N$ feature values at the input of the ML-model are assumed to be linked by some mathematical relationships when the system is in its normal state. This means that the data-points cannot be allocated arbitrarily in the M-dimensional feature space: they occupy some manifold of a lower dimensionality than $M$. Therefore, manifold learning methods are well suited here, e.g. an autoencoder with $M$ inputs and $M$ outputs. These approaches are discussed in more detail in 5.3 below.
5.2.3 Other ML-based and statistical methods can be applied to dynamical systems
The approaches we specified above by no means exclude other applicable methods suitable for one-class learning. For example, one-class SVM [5], or even neural networks with properly chosen loss function and the regularizer [6], could be used here. Nevertheless, we still put emphasis on the time-series-prediction based and manifold-learning based methods as the first choice for diagnostics of dynamical systems. It is mainly because we expect that such systems are characterized by mathematical relationships between their states at different but adjacent time moments, and the two classes of ML-approaches are capable of grasping such relationships.
5.3 The system is influenced by external poorly predictable factors: Use manifold learning methods
Many technical systems can’t be sufficiently described by dynamic laws. The state vector $X(t)$ of such systems may change drastically and unpredictably in time while the system is still in its normal state. These systems often serve some external requests and/or their state depends on external factors. The time-series-prediction based approaches described above in subsection 5.2 are hardly suitable here. It is because the approaches are oriented at learning some relationships between consecutive states of the system, but such relationships simply do not exist. If we still assume the existence of some more-or-less rigorous relationships between the components of the state vector $X(t)$, then manifold learning methods are a good first choice. This does not exclude, of course, the use of other approaches
5.3.1 The fuel station is an example of such an unpredictable system
We will illustrate the ideas using our toy model of a fuel station. This model is the simplest example of a system not well suited for methods aimed at time-series analysis. On the other hand, the normal-state is characterized by a rigorous relationship between $x_1$ and $x_2$ - the components of the state-vector $X$ - at any time moment.
When the station is in its normal state, the state vector $X=(x_1, x_2)$ may be allocated anywhere within the "normal state manifold" - the light-blue line in Fig. 1, and 2 - which is described by equation $x_1 = x_2$ of the “fuel conservation law”. The point may jump at large distances between two consecutive time-points while still remaining within the normal-state manifold. Such jumps happen due to purely external factors: arrival of particular cars at particular times and by the amount of fuel chosen for refueling by the driver.
The attempt to train a model to achieve good predictions of these poorly predictable and haphazardly changing metrics would be irrelevant to the main question: “Is the state of the system normal or not?” Or, in mathematical terms: “Is the state-point on the normal-state manifold (on the blue line of Fig.1)?”
A few more examples of such systems could be a web-server or a service elevator. Their normal state (CPU-load of the server or the electrical power consumed by the elevator) could vary broadly depending on unpredictable human decisions to visit the site or to use the elevator at a particular moment.
5.3.2 How manifold-learning based methods detect anomalies
A rough understanding of the manifold learning methods could be achieved using our toy model of a fuel station. The dimension of our feature space here is $M=2$. It coincides with the dimension $N$ of the state-vector $X$ because only one time-point is used for analysis (in contrast to the time-series based methods discussed in 5.2, where $L$ time-points are used and, therefore, $M=L \times N$).
The existence of a rigorous relationship between components $x_1$ and $x_2$ of the feature vector $X$ (fuel conservation law $x_1 = x_2$) restricts the area of possible locations of the normal points on the $(x_1, x_2)$-plane in Fig.1. This area is a 1D manifold depicted by the light-blue line. In a general case, the dimensionality of such a manifold is lower by at least 1 than the dimensionality $N$ of the feature space.
We consider here only data-driven methods, when the model of the system is not known. Therefore, we cannot derive the normal-state manifold analytically, and we have to learn it from the data itself. At least two approaches can be used here:
- Classical PCA, which is capable of grasping linear manifolds (as in this toy example); and
- Various autoencoders - a special type of neural network. The autoencoders, in contrast to PCA, are capable of learning more complex non-linear manifolds.
The idea of anomaly detection via manifold learning is straightforward:
- First, one learns the manifold corresponding to the normal state of the system from the training dataset of normal data;
- Second, one checks how far new data deviate from the learnt manifold.
If the magnitude of the deviation is about the same as observed in the training data (normal noise level), then a decision is made that the system is in its normal state. If the magnitude of the deviation is significantly higher, then a decision about the abnormality of the system state is made. Again, various statistical inferential techniques are used here to choose proper thresholds. Nevertheless, the general idea remains essentially the same.
6. Scenario #2: Both "normal" and "abnormal" labels are present in the dataset
At first glance, this situation looks like a typical supervised learning problem aimed at classification into two or a greater number of classes. A broad variety of well known statistical and ML-based tools and methods may be used here. Nevertheless, in practice we very often meet the cases when the standard two-class classification approaches are not a good choice.
6.1. The positive class (anomalous, faulty cases) is often not representative
The historically accumulated subset of "abnormal" cases for a technical system is often of much smaller size than "normal" cases. It is a natural consequence of the fact that most systems reside in their "normal" state most of the time. Such "abnormal" cases are often not representative for the whole spectrum of practically possible abnormalities. The incomplete coverage of possible abnormalities may lead to a high false negative rate. When the model meets an abnormal data-point with the combination of feature values not represented in the training sample of abnormal cases, then with an unacceptably high probability the data-point is classified as normal.
6.2 An example of the fuel station
Consider, for example, our toy model of a fuel station with, say, 6 dispensers. Suppose the subset of data-points labeled as "abnormal" includes the real faults which have happened at this station. No information about the actual localization of the faults is available, i.e. it is not known if one of the 6 dispensers is responsible, or if the common tank is responsible for the abnormal state.
Suppose the actual faults have been the following:
- Dispenser 2 had an error of +5% (i.e. counted 5% more than real outflow);
- Dispenser 5 had an error of -10%.
Each fault is represented by 1000 time-samples. Thus, the training sample of 2000 elements might seem large enough for two-class classification. However, ML-models, if trained directly in a standard supervised manner, would tend to provide inconsistent results. In this particular case, such models could ignore abnormalities at dispensers different from #2 and #5. Moreover, even at dispensers #2 and #5, errors of a different sign could also have passed unnoticed.
6.3 One-class classification is often a good choice even for two-class labeled data
The unwanted effect described above in subsections 6.1 and 6.2 arises due to the well known fact that ML-models often perform poorly when some extrapolation is needed - that is if the new data-points are from the area of the feature space not represented in the training dataset [7]. Therefore, it is often preferable to use the "one-class learning" approach first and to train a model only on the normal cases. It is necessary to bear in mind that one-class learning itself does not allow classification of the anomalies, but may still allow their isolation within some part of the system.
6.4 The positive cases are still useful for further validation
The recommendation to use a one-class learning approach as the first choice does not mean that the data-points labeled as positive (anomalous) are useless. The cases labeled as abnormal or faulty might play an important role in the validation and tuning of the model(s) obtained via a one-class learning approach. If the resultant model is really capable of discriminating between normal and abnormal cases, then the model is practically useful. Otherwise, the initial one-class learning approach requires modification or replacement.
7. Scenario #3: No labeled data are available
At first glance in this scenario, the application of supervised learning techniques does not seem suitable. In such cases, various unsupervised learning methods are usually used, e.g. approaches based on the "outlier detection" algorithms. Here we advance some counterarguments against the universality of such a straightforward approach.
Suppose the fraction of normal cases in the initial unlabeled dataset is known to be high enough, which is often the case in practice. We describe a two-step quasi-labeling procedure (7.1, 7.2), which could generate a smaller dataset having a much higher fraction of normal cases. Then, such a dataset is used for one-class supervised learning.
7.1 Weak a priori information helps to obtain a subset enriched by "normal" data-points from unlabeled data
Real cases are often associated with some weak a priori information. Such information is either directly provided by the client or can be obtained by detailed scrutiny and interviews performed by our data scientists with the client's staff. Although such information is not sufficient for reliable labeling, it could still be very helpful. It often allows us to select a smaller dataset enriched by "normal cases", i.e. having a significantly smaller fraction of anomalous cases than the whole initial dataset.
An example of such weak information could be knowledge of the time intervals in which the system is very likely to be in the normal state. For instance, in various mechanical machines, bearings are the most likely cause of failure. When a bearing is replaced by a new one, then, after some known run-in period, the bearing goes into a relatively long "useful use" period, when the probability of fault is small. If the time of the replacement is known, then it is possible to select time intervals and corresponding data-points when the system is much less likely to be in an abnormal state. This way we create a smaller dataset enriched by "normal" cases.
7.2 Further "purification" of the enriched subset
The subset obtained as described above in 7.1 can be subject to additional "purification" leading to a further reduction of the fraction of abnormal cases. The general algorithm may be described by the following steps:
- Step 1: Apply a one-class learning procedure to the enriched dataset as if it were a purely normal class. Ensure the model has not been overfitted in the course of training.
- Step 2: Apply the model trained at step 1 to the data-points from the enriched dataset one by one. This provides a ML-based forecast for each point.
- Step 3: Compute some norm of the residuals $|x_{\text{predicted}} - x_{\text{observed}}|$ from step 2 for each data-point.
- Step 4: Eliminate some fraction of the data-points having maximal values of the residuals from step 3. We expect that a noticeable fraction of abnormal points will be eliminated this way.
- Step 5: Apply the one-class learning procedure to the new “purified” dataset.
Steps 1-4 could be repeated iteratively. The data-points remaining after step 4 are a surrogate of a one-class labeled dataset. Thus, such a procedure could be named “pseudo-labeling”.
This algorithm is illustrated below by our toy model of a fuel station (see Fig.3). The true labeling is shown in Fig.3A, and it is not known to the algorithm. The unlabeled data (gray points in Fig.3B) are treated as a training sample for the normal class. A one-class learner - in this case, PCA - is applied. The manifold obtained this way - in this case, the first principal component - is shown as the gray line. Then, 20% of the points with maximal distance from the manifold (“suspicious” rosy points in Fig. 3) have been removed. The remaining points (marked as blue in Fig.3D) constitute our new dataset for one-class learning. It is easy to note that, in spite of the loss of some normal points, the remaining points in Fig.3D do not include the anomalous points (red points in Fig.3A). Thus, we have managed to obtain a new smaller dataset (blue points in Fig.3D) from unlabeled data (gray points in Fig.3B) which can be used as a one-class labeled dataset with the normal cases.
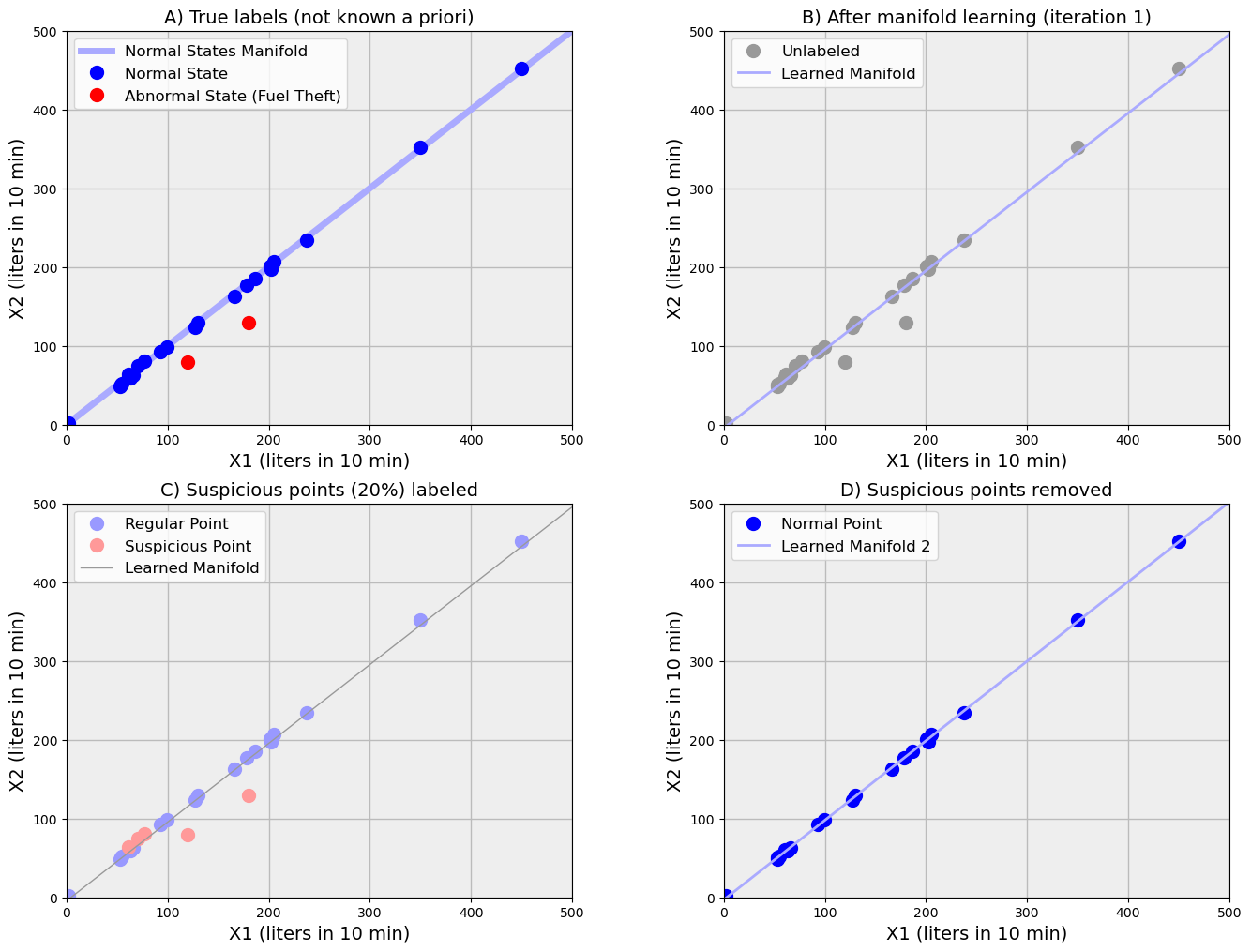
The procedure described above is not absolutely equivalent to bona fide labeling of normal cases, and there is no guarantee that abnormal cases are completely excluded. Moreover, there is often a significant loss in the number of cases left for the training. So, we name this general procedure “quasi-labeling with losses”.
The rationale behind such an approach is as follows:
We assume that the fraction of abnormal cases is small enough in the initial "enriched dataset". Then, the one-class learning procedure trained at step 1 is likely to classify a large fraction of abnormal cases as such, and only classifies (erroneously) a small fraction of normal cases as abnormal. Thus, the remaining cases are additionally enriched by normal cases (“purified”).
7.3 Use the purified dataset for one-class supervised learning
The "purified" dataset obtained, as described in 7.2, is used for one-class supervised learning. Firstly, an ML-model oriented to one-class learning is trained at this dataset. Secondly, the model is applied to the new data.
Of course, all conditions equal, the expected performance is lower for the pseudo-labeled data than in the case of bona fide labeled data (having no abnormal cases). Nevertheless, if the data are not labeled, such an approach is likely to be more productive as compared to a seemingly straightforward application of various unsupervised learning methods, e.g. "outlier detection" procedures.
7.4 Some pitfalls of the unsupervised approaches to anomaly detection
When the initial data are unlabelled, it is tempting to use a seemingly straightforward approach: to apply an unsupervised learning algorithm. Various outlier detection algorithms are often selected for this purpose. This approach seems “obvious”, and it sometimes works in practice. However, it is likely to be of lower performance than the approach described in subsections 7.1, 7.2, and 7.3. Some explanation follows.
The most fundamental distinction between unsupervised methods and supervised ones (like the approach described above in this section) is that unsupervised algorithms learn nothing from data labeling. They only utilize formal mathematical properties of the numerical data. Below we illustrate some possible pitfalls associated with the use of unsupervised methods for classification.
Consider our toy model of a fuel station. True data-points classification is shown in Fig.4A, and the same points unlabeled - as “seen” by the algorithm - are shown in Fig.4B. An unsupervised algorithm for outlier detection ascribes the highest outlier scores to the points most distant from their nearest neighbors and, thus, labels two points as outliers (green points in Fig.4C). If we follow the logic outlier=anomaly, then we come to the labeling in Fig.4D. Here, two normal points are labeled as anomalies (red), while two truly anomalous points representing fuel theft (red points in Fig.4A) are erroneously labeled as normal (blue in Fig.4D)
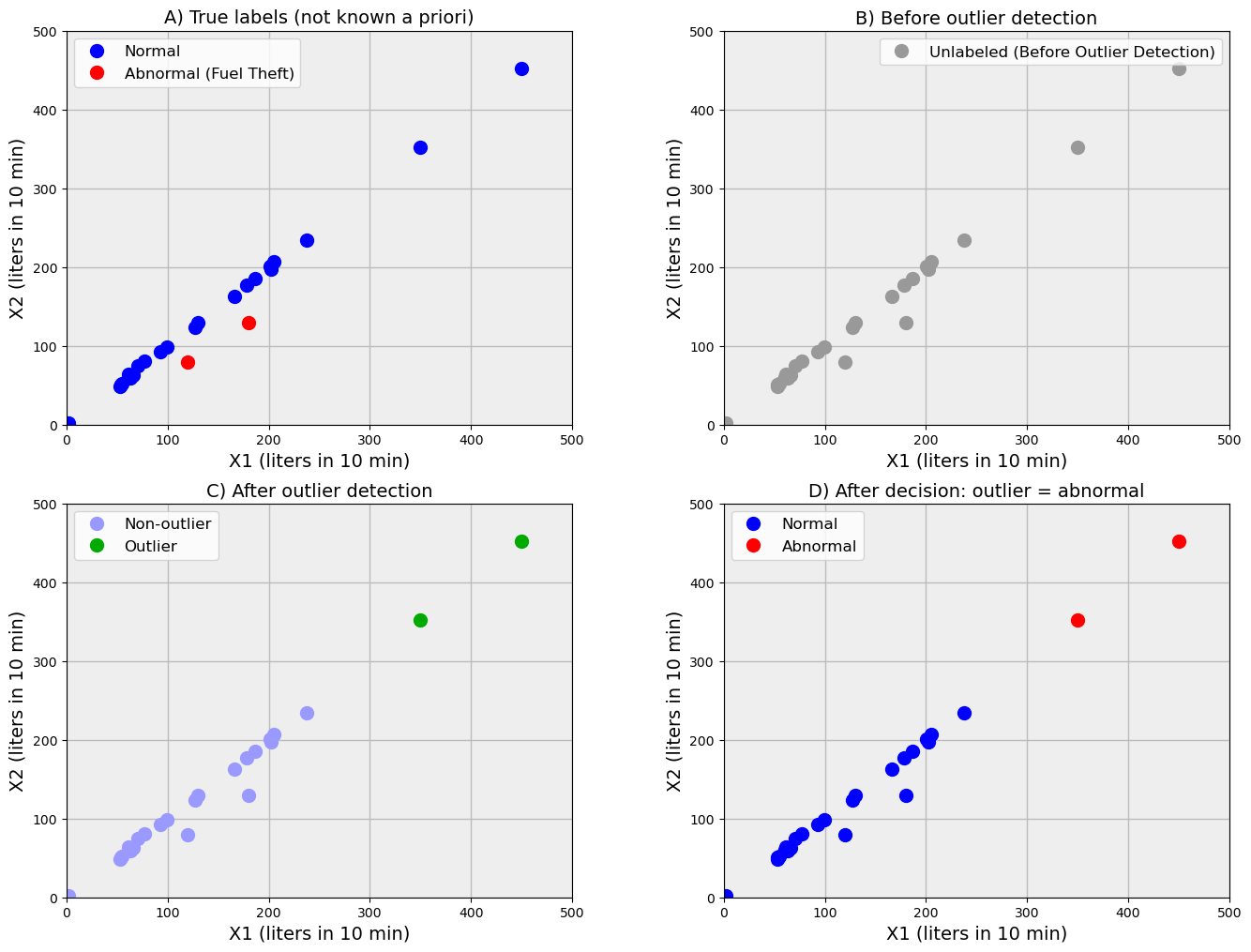
The erroneous outcome of labeling here is a direct consequence of the unsupervised nature of the outlier detection algorithm. Only formal mathematical properties of the data - large distance to the nearest neighbors - is taken into account for classification. In contrast, the approach based on quasi-labelling (7.2) provided the correct final decision. It was capable of learning the normal manifold from preprocessed, unlabeled data. Although the manifold was somewhat biased due to the presence of true anomalies, the accuracy was enough to detect the anomalies.
8. Some notes on operationalization of the recommendations and building end-to-end solutions
The concepts described above by no means pretend to cover the whole range of stages necessary for building a final end-to-end solution. The goal of this article is only to focus on counterintuitive moments and some common pitfalls associated with “self-evident” and “obvious” ways to approach the problem. Here we sketch the steps and outline some principles of implementation.
8.1 The discovery phase, exploratory data analysis, and feature engineering
The simplest approach to feature engineering is to use the raw sensors’ readings at time t as the vector of features X(t) for ML-based or statistical procedures. Besides its seeming simplicity, the method hardly has any advantages. In many situations it just cannot be used.
For example, the required bandwidth of sensors may vary several orders of magnitude: vibration sensors might require a bandwidth of 5 KHz and more, while ambient temperature and chemical sensors operate at 0.01-0.1 HZ. Another drawback is that the sensors are often characterized by a high degree of redundancy and their readings could be reduced to a much smaller dimensionality.
For example, 1000 chemical sensors on the walls of a tank for mixing ingredients may serve only one purpose: to control the homogeneity of the final product. Signals from the sensors could be replaced by a single virtual sensor corresponding to some measure of dispersion of the readings, e.g. the standard deviation. If one uses the 1000 signals per se as features, then the large dimensionality of the feature vector X(t) incurs the “curse of dimensionality” hindering most ML and statistical algorithms. Thus, some feature engineering is almost a universal prerequisite for any sane approach to real-world problems.
In our experience, achieving good results requires some delving into the domain knowledge, understanding the logic and principles underlying the operation of the system at large and the sensors in particular. This knowledge is often crucial to the success of the whole project. Therefore, our data science specialists pay special attention to this stage and interact closely with the technical specialists at the clients’ side.
Exploratory analysis of the data is also an important factor of success. The understanding of the data properties is normally useful for choosing a valid approach. The real-world data are typically not “clean”, i.e. may contain missed observations, erroneous values, or unexpected behavior requiring clarification from the client’s technical specialists.
8.2 Anomaly detection: primary and secondary analysis
The approaches and methods we outlined in this article are related mainly to the primary analysis, where some anomaly score is generated for a single new data-point. In practice, the decision is normally made on the basis of a secondary statistical analysis, where anomaly scores for a series of data-points are taken into account. These scores are compared to their normal values obtained in the training dataset via statistical inferential procedures.
The logic of such statistical inferential procedures may vary depending on the specifics of the problem. At least two broad classes of methods are normally used here:
- Firstly, the anomaly scores are compared to the scores obtained for the training dataset with normal cases. This could be done by direct use of the percentiles obtained in the training set as the alarm threshold. For example, the 99-th percentile is a reasonable threshold providing 1% probability of false alarm, the 99.9-th percentile would provide 0.1% of false alarms, etc.
- Secondly, more sophisticated statistical approaches may be used, especially if the size of the training dataset is too small. For example, 10,000 data-points are hardly enough to estimate the threshold for the probability of false alarm 0.0001 or smaller. In such cases we normally use some extrapolation of the null-distribution: a probabilistic model is fitted to the scores obtained for the training sample and the tail of the model distribution is used to calculate the probabilities of false alarm.
8.3 Multi-stage reporting of the anomalies
Besides the mere detection of anomalies, any real-world solution requires a sane procedure of their reporting. If, for example, the frequency of false alarms is too high, the alarms are likely to be ignored or even discarded by the personnel. We normally develop a multi-stage scheme for anomaly reporting. Weak anomalies, or not reliably established ones, are represented by, say, an orange color on the dashboard. The anomalies with a greater severity are depicted by red. Only severe enough anomalies are reported via e-mail or SMS messages.
Such a multistage approach to reporting anomalies reduces the frequency of the most disruptive and irritating false alarms like e-mail and SMS messages. On the other hand, the opportunity to be noticed by the human operator always exists: e.g. too many red marks on the dashboard could easily attract attention in an unobtrusive fashion.
8.4 Localization of anomalies and their classification
The approaches we considered above are data-driven, not model-based. In our toy model of a fuel station, for example, the equation of the normal manifold is not used in the algorithm, and the equation is supposed to not be known. The algorithm has to learn the manifold from the normal dataset and, then, estimate the deviation of the new data-points from the manifold (an anomaly score). Such model-agnostic methods are rather general on one hand, but their capabilities of localization and classification of anomalies are limited.
Mathematical analysis of the trained model could help to find independent groups of features, e.g. related to different subsystems or modules of the whole system. Or a priori information on such groups of sensors could exist. Then, it is usually possible to achieve coarse-grained localization of the anomaly - to point to a particular subsystem.
Sometimes even perfect localization is possible. For example, an abnormally high level of the signal from a particular accelerometer associated with a particular bearing could point directly to the faulty bearing. Unfortunately, such a decomposition of the feature space into separate groups related to particular subsystems is not always possible.
Much more detailed localization and classification of anomalies can be achieved on the basis of model-based approaches, when some equations describing the normal operation of the system are known. Then, it is often possible to formulate and solve a problem on statistical estimation of parameters and to obtain quantitative estimates of the magnitude of the anomaly(ies). In our toy model of a fuel station, for example, this would mean estimation of the errors of particular counter(s), not only detection of the anomaly. Such model-based approaches are difficult to generalize because they are usually based on utilizing specific properties of particular systems.
8.5 Recommendations on mitigation of the detected anomalies
Not all anomalies are of equal importance; some require immediate reaction, while mitigation of others could be postponed for a particular time. For example, a broken bearing in a service elevator requires immediate stopping and replacement, while a gradually mounting error of a fuel counter - which is still within the acceptable range - might be only an early warning signal. Again, a single general approach can’t be specified here as too much depends on the specifics of the particular system. The decision procedure which generates recommendations is normally developed and tuned in the course of experimentation, and with close interaction between our data scientists and our clients’ technical staff.
8.6 Applicability of the approaches to high-dimensional data
In contrast to our toy model, the dimensionality of raw sensor data in real industrial systems could be large: hundreds and even thousands of sensors is a usual situation in some application areas. At the same time, the curse of dimensionality is a fundamental factor hindering the performance of both ML-based and classical statistical methods. We can hardly propose a universal solution, however, some general approaches often help to overcome the problem.
In many cases, the technical system may be logically decomposed into a large number of much simpler “loosely coupled” subsystems. Such systems could be represented by low-dimensional models at the first step. Then, the output of the models is analyzed at the second stage. Each particular model in such a hierarchical scheme is of much lower dimension than the overall number of sensors. Such a divide-and-conquer approach is very effective in practice. On the other hand, it requires some domain knowledge, delving into the specifics of the client’s system. Therefore our data scientists normally start the project interacting closely with the technical specialists at the client’s side. We have also discussed this topic in 1.4, and 8.1. Besides the heuristic approaches to decomposition, which are mainly ad hoc ones, we also develop more regular formal procedures which help to facilitate this process.
Conclusion
We have tried to explicate some general patterns behind the wide variety of statistical and ML-based approaches used in particular cases for health monitoring and anomaly detection in technical systems. Here we have focused only on the peculiarities caused by such a factor as the type of data labeling. We analyzed three broad classes of practical situations when the data available are either "one-class labeled" (known to correspond to the normal state of the system), or two-class labeled (both normal and anomalous subsets are available), or not labeled at all. We have also pointed to the pitfalls associated with some “obvious” and “self-evident” choices of the ML-based or statistical methods in particular situations.
A counterintuitive conclusion is that approaches based on "one-class learning" may be the most suitable even if two-class labeling is available, or if the data have not been initially labeled at all. In the first situation (two classes), a seemingly obvious approach with binary classification has hidden pitfalls. In the second situation (unlabeled data), a straightforward approach with "outlier detection" methods also has serious pitfalls. We recommend using weak information and an iterative "purification" to obtain a smaller subset with a higher expected fraction of normal cases from the initially unlabeled dataset and, then, to apply "one-class learning” methods.
References
- H.Wang, M.J.Bah, M.Hammad “Progress in Outlier Detection Techniques: A Survey”, 2017, https://ieeexplore.ieee.org/document/8786096
- Srikanth Thudumu et al. “A comprehensive survey of anomaly detection techniques for high dimensional big data”, 2020, https://journalofbigdata.springeropen.com/track/pdf/10.1186/s40537-020-00320-x.pdf
- P.Perera, P.Oza, V.M. Patel “One-Class Classification: A Survey”, 2021, https://arxiv.org/abs/2101.03064
- Manish Gupta et al. “Outlier Detection for Temporal Data: A Survey”, 2014, https://www.microsoft.com/en-us/research/wp-content/uploads/2014/01/gupta14_tkde.pdf
- K.Yang, S.Kpotufe, N.Feamster “An Efficient One-Class SVM for Anomaly Detection in the Internet of Things”, 2021, https://arxiv.org/abs/2104.11146
- W.Hu, M.Wang et al. “HRN: A Holistic Approach to One Class Learning”, 2020, https://proceedings.neurips.cc/paper/2020/file/dd1970fb03877a235d530476eb727dab-Paper.pdf
- M.Salehi, et al. “A Unified Survey on Anomaly, Novelty, Open-Set, and Out-of-Distribution Detection: Solutions and Future Challenges”, 2021, https://arxiv.org/abs/2110.14051