

Organizations take great care to secure cloud platforms, relying on sophisticated access control systems. Multi-factor authentication, identity management, and fine-grained authorization aim to fully lock down valuable data and infrastructure. However, what if these complex safeguards unexpectedly fail? In this blog, we'll discuss the vital role of the break glass process for emergency access in IT.
Companies inevitably adopt new platforms to run tasks and store data, whether it’s a substantial transition like migrating to a public cloud or a more localized shift such as adopting HR management SaaS. Regardless of scale, the introduction of a new platform signifies a relatively isolated entity that houses valuable information, necessitating reliable user authentication, strict least-privilege permissions, and "zero trust" authorization policies. The rationale is clear–these hosted systems contain sensitive information and disruption has serious business impact. Recognizing that access control is a nontrivial problem, companies deploy or leverage existing implementations, employing a suite of specialized systems. These systems are integrated to undertake authentication and authorization, identify human and machine users, and grant limited access to the new platform.
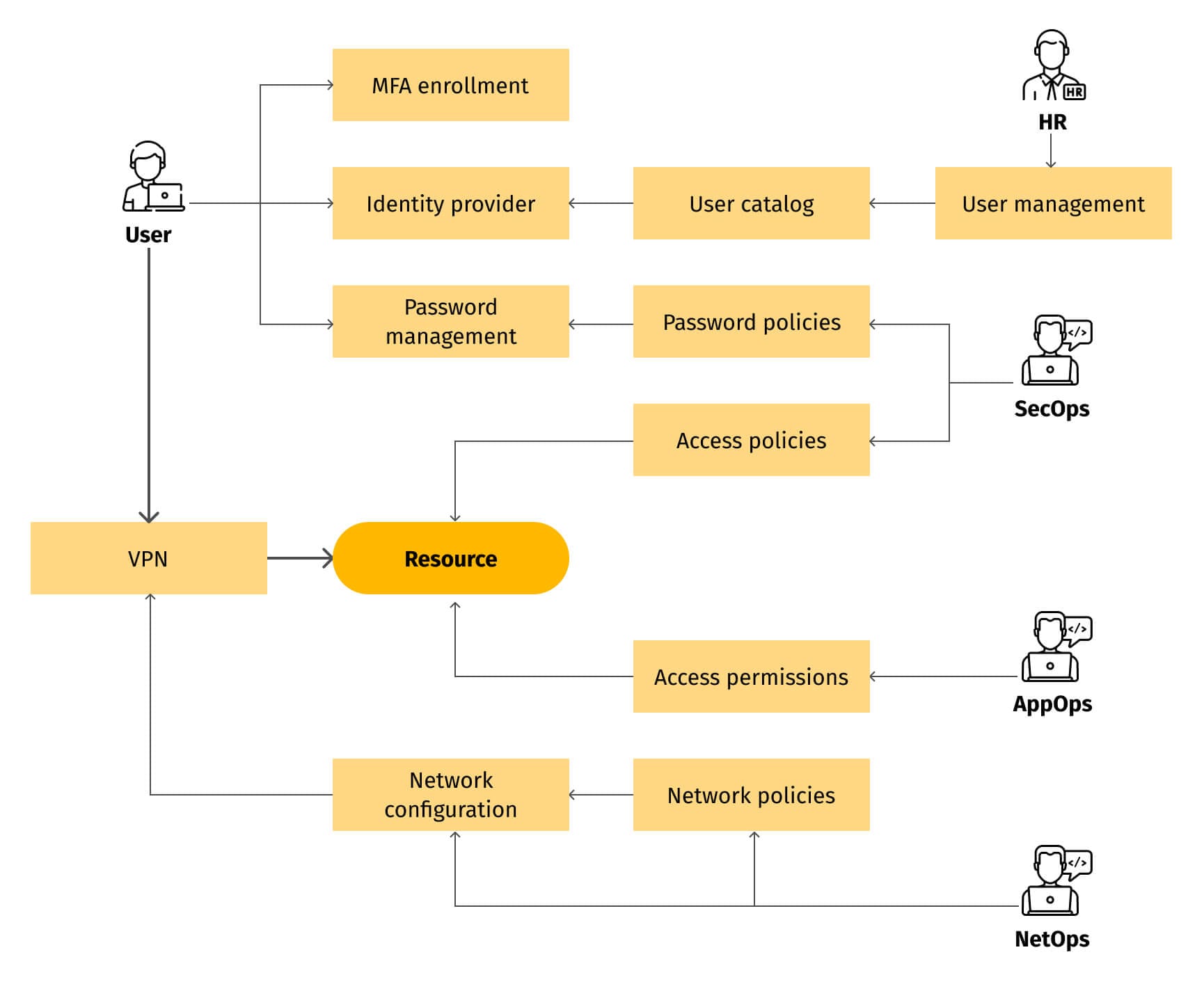
Indeed, an access control system is inherently complex, and anything complex can break. If access control fails, it brings the entire business to a halt.
Even if nothing breaks, we're not entirely safe. The access control system is designed based on specific work processes and usage patterns assumed for the target platform. Numerous assumptions have to be made, but it's impossible to foresee everything. Sometimes something unexpected happens. Often it can be ignored, but sometimes it can be an emergency that demands swift action. Yet, even if we're willing to take action, our carefully designed access control system may impede it. Failing to act could result in financial losses, harm to the business, or even more severe consequences.
Simply accepting such risks doesn't make sense. Facing rare, acute and potentially dangerous circumstances, relying on sophisticated mitigation procedures is impractical. We need to do something simple but very effective, albeit unusual or even generally prohibited—like smashing the doors in case of fire, stopping the train to prevent an accident, or just breaking the glass and pulling the alarm.
What is the break glass procedure?
The term "break glass" refers to an action, which is generally discouraged or not allowed, in a case of emergency. This concept is pretty broad, even in the context of IT. For example, HIPAA compliance mandates a process of accessing patient health information during a medical emergency. This is a rare but regularly formalized procedure for elevating information access rights. In this post, we focus specifically on emergency access to an IT service platform in uncommon scenarios not covered by existing processes. In particular, this pertains to accessing a cloud platform for control and data.
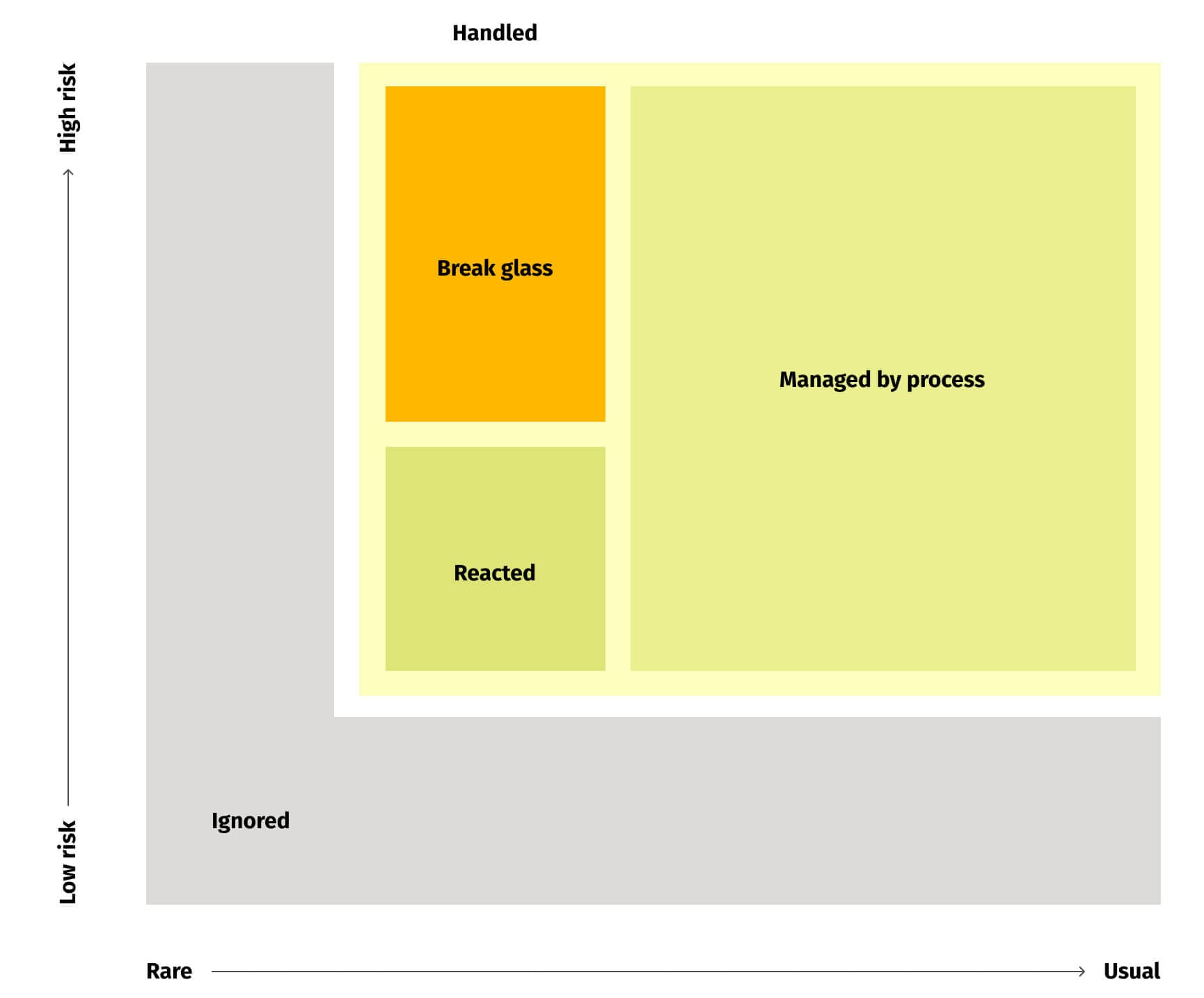
The distinctive properties of break glass procedures are:
- They apply to rare, exceptional circumstances outside normal operations.
- The circumstances are time-sensitive, and delays in action will cause significant damage.
- They address cases that aren't covered by existing processes.
Unlike privileged access management (PAM), which relies on a collection of processes for executing prescribed tasks, break glass relies on human judgment in unpredictable scenarios. PAM strictly governs routine tasks through rigid workflow controls to prevent errors. Break glass procedures intentionally bypass controls to enable decisive human action in crises. This separation isn't universal. For example, in the real world, breaking glass to activate a fire alarm is a simple prescribed action. However, in the realm of IT systems, which have smaller "state space" and numerous tools, such predictable cases are normally handled through automation rather than break glass.
True break glass scenarios involve unanticipated risks where the benefits of empowering operators to act swiftly outweigh the dangers of bypassing safeguards. Still, the decision to invoke break glass access must be weighed carefully.
Another class of cases that shouldn't trigger a break glass procedure arises from personal data regulation. For example, a user data deletion request within the scope of GDPR clearly requires an action generally discouraged: information destruction. However, it is a prescribed process, known in advance, so its execution should not leave space for human error. It must be a canned procedure, preferably automated, and safeguarded with appropriate controls to prevent accidental triggering.
In contrast, the access control system failure example from the beginning of this post is a valid case to discard some rules. When the front door lock fails, you’re left with few options—break the door or smash the window. Similarly, when standard authentication stops working, exceptional access may be the only way to regain control.
Can root credentials be used for emergency access?
One may reasonably question the need for such a lengthy discussion about system failures and the applicability of elevated access procedures when the problem domain revolves around access to the cloud infrastructure. After all, any information system has a master key, "root" credentials, or a "superadmin" that created this piece of cloud infrastructure and has unlimited powers over it. Armed with these credentials, a human operator can do anything. In a crisis scenario, why not simply unlock the vault and retrieve the sheet of paper with root credentials? True, you'll need to locate the two assigned custodians holding the vault keys, but that's a standard part of a regular PAM process. Should we look any further?
Yes, we should. For example, cloud access management guidelines emphasize that these initial root credentials should never, under any circumstances, be used for operations. Operations, even in emergencies, imply that the system will continue to function after the emergency is mitigated. Root credentials are essentially a piece of data, and once exposed to an operator or a software utility, there’s an inevitable risk of leakage in various directions. Eliminating all copies of these credentials becomes an impossible task once they're released. Would you bet that these credentials won't persist in ~/.aws/credentials file on an operator's laptop, at a VDI instance, a jump-box VM, or in the AWS_SECRET_ACCESS_KEY environment variable in a hastily crafted script? Moreover, operators, with good intentions to expedite issue resolution, may hold onto privileged credentials.
So no, you shouldn't involve the root credentials of the cloud platform, even if it's your personal cloud account.
Regulation compliance
The inadvertent retention of privileged access credentials isn't the primary concern for an organization. Worldwide, organizations face escalating scrutiny from regulators overseeing information security, sensitive data access, and even public behavior. Virtually every regulation explicitly or implicitly mandates:
- Personalized access to information systems and data.
- Access restriction based on business needs (the "least privilege" principle).
- Logging and auditing of information access.
It's clear that the use of root credentials violates all these requirements. It conceals the operator's identity under the root account, it grants the user unconstrained powers within the information system with no temporal limitations, and while access tracing may still function, its effectiveness and accuracy depend entirely on the operator holding the root credentials.
Most regulatory documents aren't written as technical specifications. They employ more generic legal language to sustain the relevance of regulations in a rapidly evolving technology landscape. However, they leave specific interpretation to auditors and state-appointed governance bodies. These oversight entities generally use common sense in interpreting regulations and compliance implementation specifics. Nevertheless, these interpretations aren't loose. For instance, an auditor may accept a scenario involving the use of root credentials for cloud infrastructure operations but it will demand an exceptionally high level of control and assurance, rendering the entire approach practically meaningless.
It's important that compliance issues aren’t left to chance. Compliance requirements are known in advance, and compliance audits occur regularly. Unaddressed compliance violations inevitably lead to damages comparable to a worst-case scenario—financial losses, business termination, or even criminal charges. Unlike an emergency incident, which one hopes may not happen, compliance violations pose a persistent threat to the organization.
In addition to imposing restrictive requirements, many regulations (GDPR being a prominent example) also demand operations continuity. Consequently, the affected organization cannot afford to wait until the issue resolves on its own. The organization is bound by the law to take action, not solely driven by direct financial losses. Therefore, upon establishing an information processing system, organizations are obligated to have a process for mitigating rare, high-impact risks of uncertain type and origin—such as a break glass procedure.
It's worth noting that the break glass process isn't a singular entity for an organization. Given that an enterprise has multiple information systems aggregated at different levels, it may need corresponding emergency procedures at each level. For example, an identity provider failure likely impacts everything, hence it should be addressed globally. But if an IAM configuration error renders a particular information system inaccessible, it should be addressed at the system level without invoking organization-level superpowers.
Some break glass implementations fall short
In many cases enterprises have emergency access methods in place, often quite elaborate and explicitly designated as "break glass". Despite this, they often share the same shortcomings that prevent these otherwise reasonable PAM methods from being suitable for "break glass" circumstances. We explore a few examples below.
Example 1: An enterprise with data access regulation
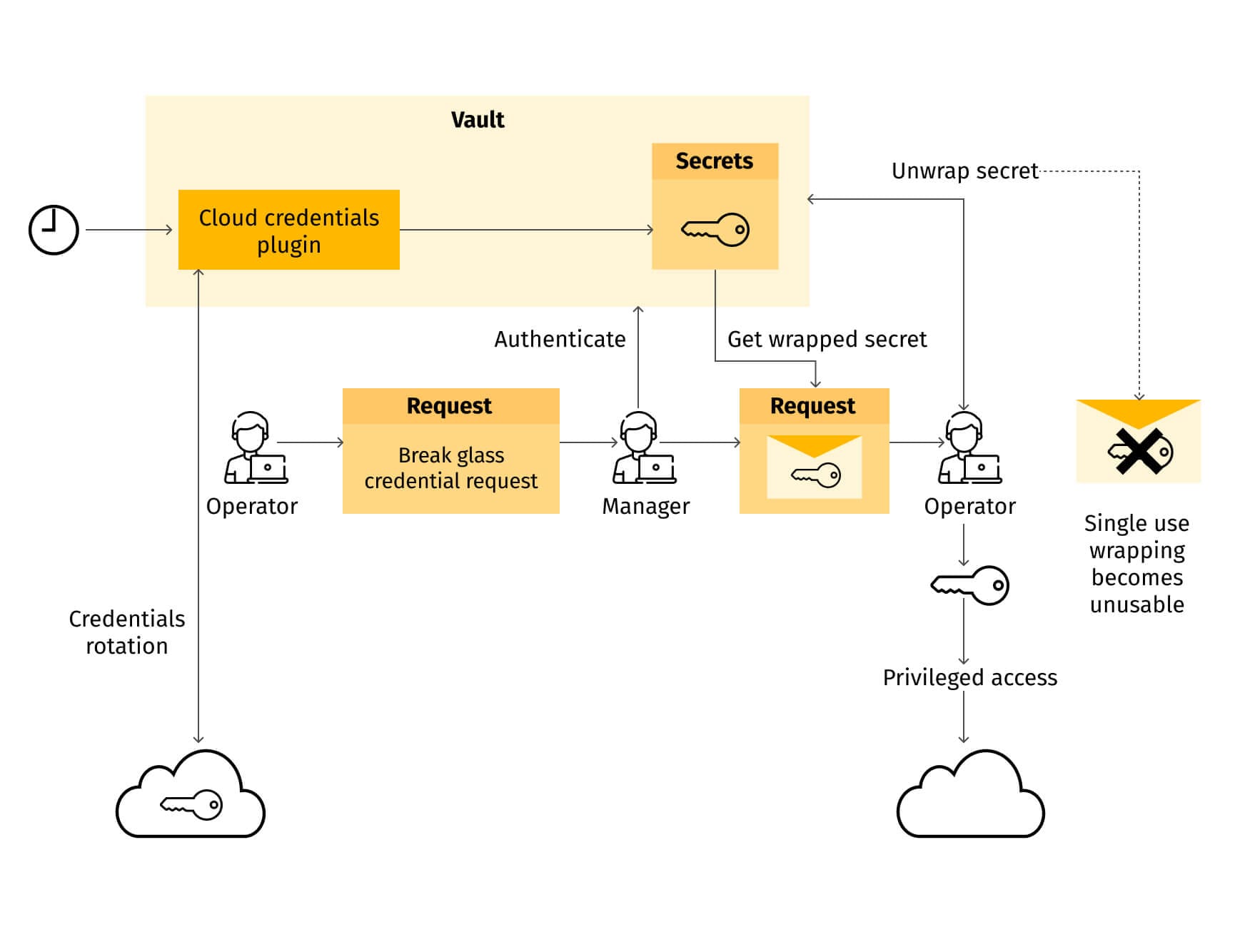
This example is typical for cloud-first organizations with mature IT departments, specifically addressing access control to enterprise AWS resources. Due to compliance policies, IAM configuration blocks operators' access to application data in production AWS accounts. For emergency cases, the organization implements a method of privileged access to AWS resources, bypassing these restrictions. The method leverages the existing identity management system, identity provider and PAM system, all of which are robust and trusted. These systems are integrated and configured to handle the approval process, credentials issuance and rotation, as well as the audit trail.
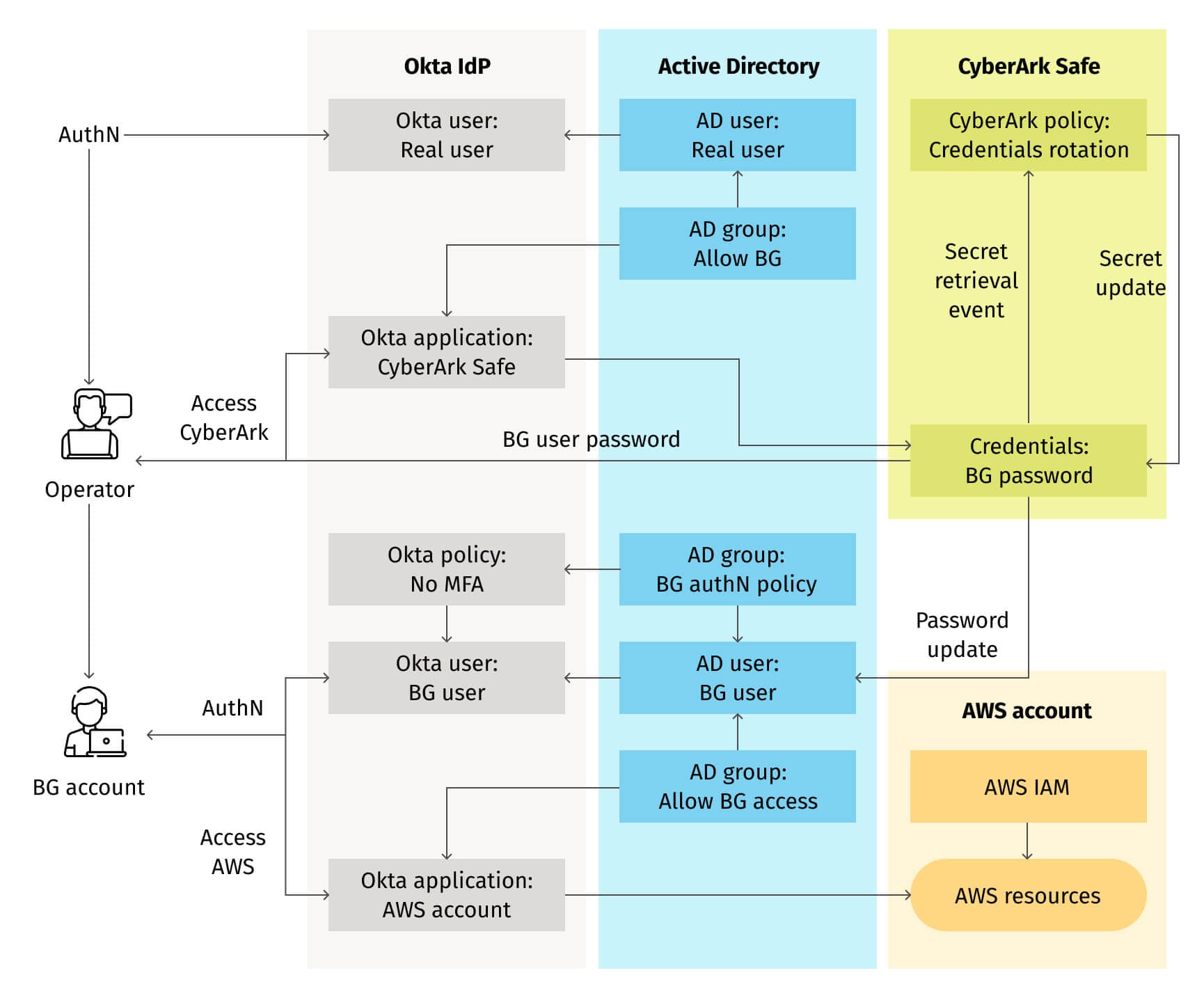
This is a well-designed PAM system, showcasing many PAM best practices. Permissions and policies are assigned through roles and groups, centrally managed in Active Directory. Strong authentication with multi-factor authentication is in place, and the credentials life cycle is automated. Each component of the entire system is among the best tools for its task. When implemented, it works, but it often fails in cases of emergency. We'll discuss why after another example.
Example 2: DIY Lambda-based automation
Another example concerns credentials rotation in AWS, following an AWS guideline, which is purely AWS-centric and doesn't depend on third-party proprietary tools.
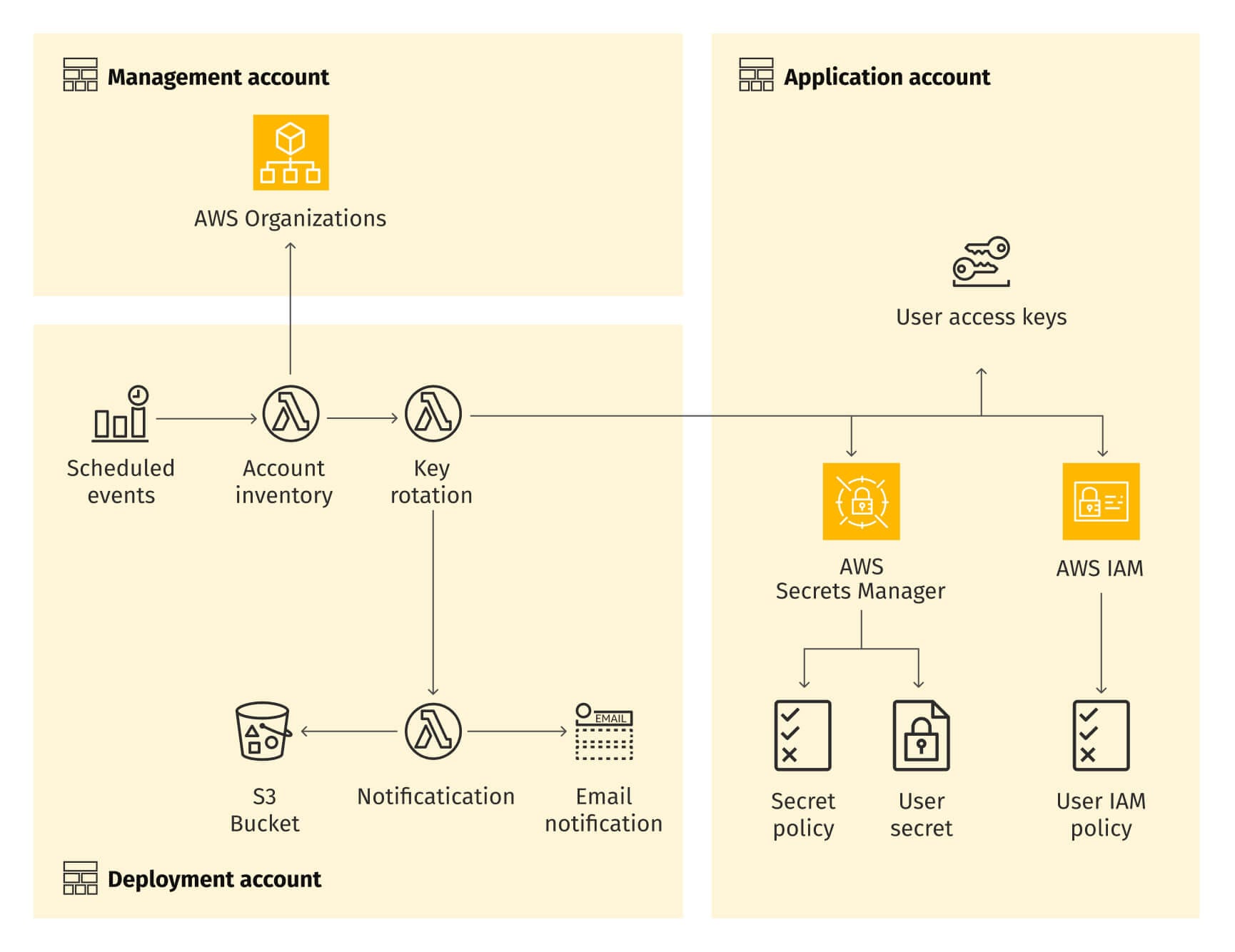
Credentials update is just one aspect of a break glass process. Even though there are already a bunch of Lambda functions, a Secret Manager instance, a few more AWS services, and half a dozen IAM policies involving cross-account access. What could go wrong? Read on to find out.
Complications
The above examples represent reasonable implementations of privileged access management (PAM). Despite their apparent soundness, they often fall short when needed most. Let's explore what they have in common.
The most evident issue is the complexity of these PAM implementations. Each process involves several separate systems, often managed by different teams. The managing team updates the system, implements new features, improves the existing functionality, and sometimes decommissions parts of it. Consequently, the underlying assumptions of the PAM process eventually break. This happens for any complex integration. Such issues are expected for actively operating business systems, usually detected during testing, and promptly addressed. If a system participates in a busy integration, the managing team has to be aware of it and handle the integration to prevent disruptions due to system changes.
However, an emergency access procedure isn't triggered daily or weekly. It may occur so infrequently that the entire team may undergo natural staff rotation before it happens again. Consequently, nobody remembers that such a procedure exists, and involves the team-managed system, until an on-call support operator gets a P0 incident, scrambles for emergency access, and finds it nonfunctional.
Even if this PAM machinery works, it often fails on the human side. A complex procedure implies a complex operator runbook. When waking up at 4 am, the operator is likely to misstep somewhere. Or the runbook documentation no longer matches the updated UI of, for instance, a credentials vault service.
Emergency access procedures are cross-functional and very rarely invoked. It sets such procedures apart from regular PAM processes. Hence, they must be very simple—both technically and process-wise, even if it means being manual, unscalable, or otherwise costly.
Requirements
A working break glass emergency access procedure should adhere to several requirements. Some of them are formal, stemming from externally imposed regulations and constraints. Others are practical, and essential for establishing a truly functional and useful process.
Formal requirements mainly come from legal regulations. Most of them have similar expectations from access control to information systems:
- Access to information systems must be personalized, meaning the identity of the accessing operator must not be obfuscated. Access permissions should be granted on a personal basis, such as an association with a specific access role.
- Access must be justified, adhering to the "need to know" rule. While a break glass procedure grants access rights beyond the operator's regular needs, it must still be adequate to the operator's responsibility in incident mitigation. It shouldn't be over-permissioned, and an operator shouldn't get root access to the whole organization infrastructure to fix IAM in a single cloud account.
- Access to information systems and their data must be audited. Given the elevated level of access, all operations, changes, and data movements should be tracked. It implies reliable and immutable logging of everything a privileged operator does.
Regulators and overseeing bodies accept the need for heightened access measures, but this doesn't imply that these measures can compromise compliance guarantees. Elevated access must be leveraged by elevated controls. It's the foundational formal requirement.
The main practical requirement is that a break glass procedure must work flawlessly 100% of the time.
- The procedure should make minimal or no assumptions about people or technology. Ideally, it should involve only the target information system platform and the operator, without relying on other teams or additional machinery. For example, it shouldn't assume that the enterprise IAM team will be online to approve requests and make changes. Neither should it assume that, for example, corporate Active Directory service works or the VPN is accessible.
- The procedure must always be available. Its facilities must be exempt from any expiration, inactivity locking, or cleanup rules.
- The procedure must be owned by an assigned team. Like any other process, the break glass procedure needs maintenance to remain operational. If it's merely a cross-department agreement, then nobody is responsible, and the procedure eventually falls apart.
- The procedure must be regularly tested, for example quarterly. It's necessary to ensure it's operational and the stakeholders are aware of it despite staff turnover.
While a break glass procedure must be highly reliable, it doesn't have to be scalable, efficient, or cheap. It doesn't need to support hundreds (or even tens) of users. It may rely on manual actions. That's fine, as long as the procedure is reproducible.
To satisfy the formal requirements mentioned earlier, a break glass procedure should implement the following constraints:
- The access method must be time-limited. If it involves credentials, they must expire. If not, they will leak, rendering none of the formal requirements feasible.
- The access method must be appropriately scoped. For example, it should apply to a specific cloud account or to a SaaS tenant rather than the entire cloud platform or service. Otherwise, it will be difficult to satisfy the "need to know" access justification requirement. However, within the scope, the method must be powerful enough to address any possible issue.
- The access method should be allocated to a single specific person at a time. For instance, a set of privileged credentials must not be shared between operators, even if they are working on the same incident. The allocation must be recorded to ensure privileged access remains personalized.
- Privileged access sessions must have detailed access logs. This should include not only who accessed what but also a detailed session log, even up to screen and keystroke recording. Since a break glass procedure provides very broad unrestricted access, detailed tracking is necessary to audit what was actually accessed and what changes were made.
- The number of break glass access methods must be limited. For example, one per product team.
Last in the list of requirements but not the least important is when a break glass procedure can be used. For example, break glass procedures can be triggered in the following scenarios:
- If an access failure blocks the regular ways to access the system, such as an identity provider (IdP) or multi-factor authentication (MFA) failure that prevents one from logging into the system, or a broken (accidentally or intentionally) access control configuration;
- If the target system requires specific access facilities, such as a VPN or AWS Systems Manager service;
- Restricted data access by human operators. A regular access configuration may completely inhibit human operator access to certain data, for example, to PII data. If a legitimate case for such access suddenly appears and it's required urgently, the organization may resort to the invocation of the break glass procedure once before implementing a regular PAM process for such a case. Although this last point is reluctantly included in the list, it's probably still the most common use case for generic elevated access.
A list of permitted use cases should accompany every break glass access method. The method must be invoked only in these cases (and in corresponding drills) and never used for anything else.
Break glass methods that work
After having spent most of this post discussing complications and examples of failures, let's outline a few methods that work. In a nutshell, the problem isn't difficult; we just need an access method for the target platform that works in any circumstances and satisfies compliance requirements.
An access method doesn't necessarily imply a set of credentials, but in many cases, it's the most straightforward way. A set of static credentials is provisioned in advance (because provisioning may fail during an incident) and stored securely. The credentials typically include a secret such as a passphrase or a key. It can also be a hardware device; it just needs to be self-sufficient, although such devices aren't widely used yet for this purpose. For a cloud computing platform, it's an "IAM account" (not to be confused with an AWS account, the primary container of all AWS resources for a user)—a static authorization entity with a static secret as a credential. So, an operator only needs this secret, a network to connect to the cloud platform, and a computer connected to the network—the minimal list of prerequisites that cannot be further reduced. Besides these basics, the break glass access methods differ in the way those static credentials are maintained.
The simplest way is fully manual:
- The credentials are split into parts, printed out on pieces of paper (or saved to a disconnected storage device such as a smart card), and stored by a few trusted custodians in safe locations.
- For reliability, several copies of each piece of the secret should be prepared and stored by different people.
- Each release of the credentials must be recorded in a physical log journal, and the releasing custodian must ensure that the credentials are revoked in the cloud platform after use.
- In turn, the auditors should check that the used credentials are actually revoked.
It's tedious, but it works. This method may be employed for higher levels of emergency access—such as emergency access to a cloud tenant encompassing all cloud resources belonging to an organization.
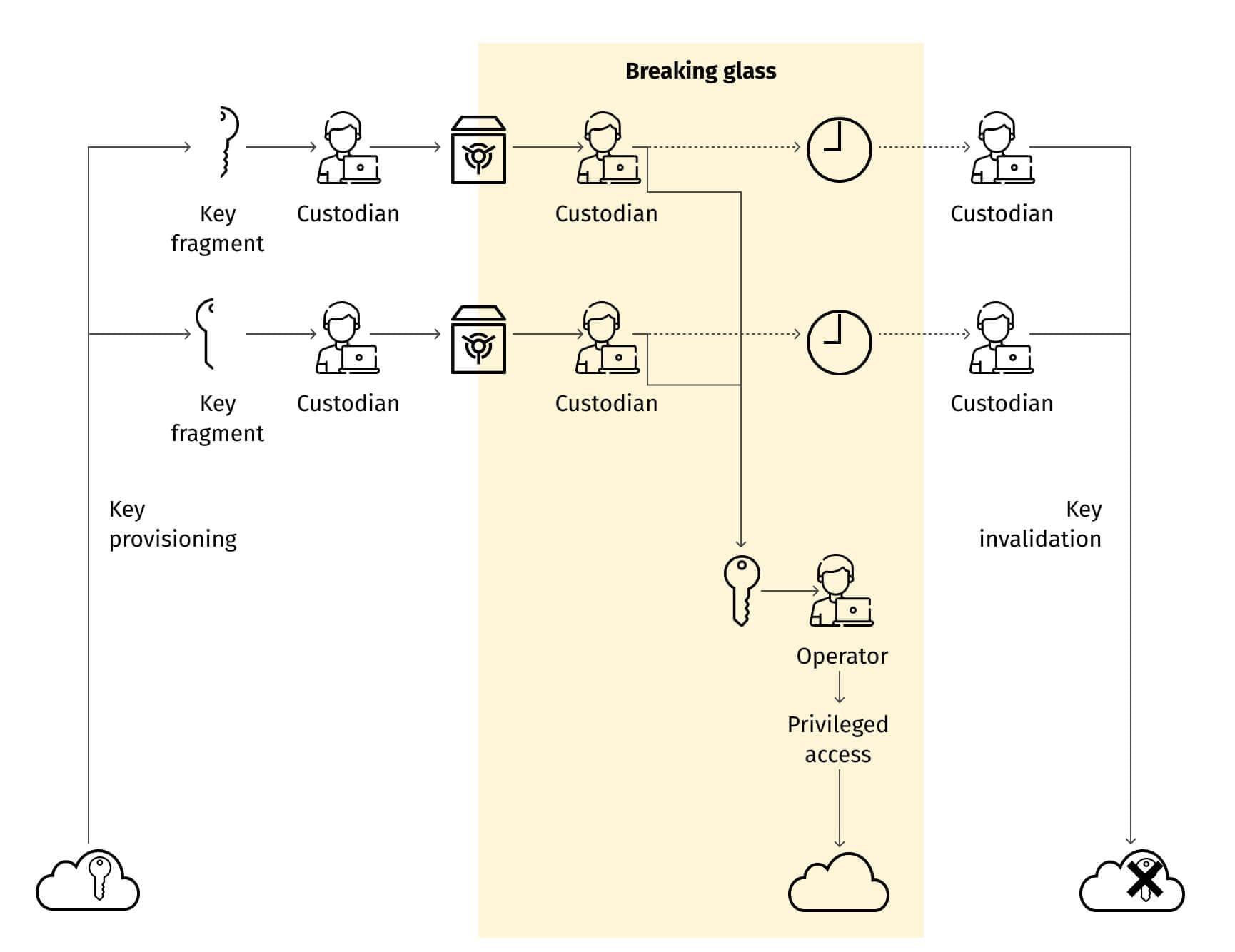
Down the stack, more things happen, and the break glass process is used more frequently, involving more people who should have access to it. At this level, limited automation is reasonable—a standalone credentials vault (or PAM) system may replace human custodians. Popular examples of such systems are CyberArk PAM and HashiCorp Vault. These digital vaults handle credentials storage, release, rotation and logging, possibly leaving only the approval process to humans. However, it's preferable to have dedicated instances of these systems specifically for break glass credentials management, primarily to minimize the attack surface around these credentials.
Last but not least, periodic drills are essential to keep the emergency access method working. Anything not in use becomes rusty and falls apart. Therefore, once the organization adopts a cloud platform, it should assign someone on the staff responsible for its operations. A break glass process should be one of the first things for that team to implement, and drills for this process should be one of the first recurring events in the team calendar.
An emergency access procedure is one of many processes an organization has to implement once it adopts a new platform service. It isn't (and shouldn't be) complex technically, but it has surprisingly many ramifications.
A few takeaways
A break glass process is a necessity. Without it, operators lack control over a distinct set of high-risk issues in the application system or shared platform. While organizations recognize this need, a common misinterpretation views break glass as a regular privileged access management (PAM) scenario. It's not, and this distinction is important. Break glass and PAM have divergent requirements and acceptable trade-offs, and they apply to different use cases.
Break glass procedures and regulations compliance aren't at odds and that's counter-intuitive. However, break glass procedure compliance demands a distinct implementation—relying on careful observability and in-process control instead of upfront restrictions.
Implementing break glass involves unique best practices, occasionally conflicting with standard IT operations patterns like denial by default, approvals in advance, and excessive automation. While these practices may seem inconvenient, deviating from them can create more problems than solutions.
A well-implemented break glass procedure creates a robust line of defense against new and unknown threats. Moreover, it addresses concerns in adjacent areas such as application reliability, regulations compliance, and the overall cost of ownership.