
Why you need a microservices management platform and how to build it

Retailers wanting to upgrade their monolithic architecture systems to a microservices approach will need to build a management platform to truly capture its benefits. The advantages of microservices over monolithic architectures are evident: greater scalability, more customization, quicker updates, and easier testing. However, many organizations will face problems with environment stability, lack of dynamic scalability, and a loss of efficiency simply because they did not establish a proper microservices platform to support all the new services and changes.
For retailers, moving to microservices is especially important, as many bought into large monolithic software packages back when e-commerce was exclusively on desktop, but now need to be more flexible to adequately meet the expectations of their omnichannel demanding customers. Just building services and attaching them to the system will result in management, testing, stability, and implementation issues. Therefore, retailers need to invest in a microservices management platform that can support the development, deployment, management, and production operations of microservices and their application components.
The building of this platform should ideally occur during initial replatforming and the cloud migration of the first few applications. Generally speaking, the benefits of building a microservices management platform justify the investment once there are three to five services, depending on the complexity of the services in question.
In this article, we will first discuss why a microservices platform is needed, how to build one, and how to manage microservices. Then, we will describe the approach of adopting a cloud infrastructure at scale in an enterprise environment, explain the best methods of setting up a microservices platform, and provide an overview on the processes of change management and continuous delivery.
Challenges in a microservices approach without the proper support
Before we begin, we’d like to review the challenges that the release engineering, production operations, and infrastructure teams face when migrating to the cloud and microservices. The key difficulty is that such a migration dramatically increases the number of configuration points across multiple dimensions:
- Services and components become smaller, the number of them increases, and they become more interconnected.
- Development teams produce more changes and demand that they be deployed in production more frequently to enable continuous innovation.
- Infrastructure components - such as VMs, containers, and load balancers - become more lightweight and increase in number.
- Dynamic environments, auto-scaling, and self-healing lead to the increased frequency of changes to the infrastructure components.
The traditional approach to release engineering and production operations is often not ready to deal with this increase in complexity. In our experience, this approach breaks down at several weak points:
- Deployment automation: Traditionally, when a new version of an application is about to be released, the new artifacts are deployed to a set of static VMs, replacing the old ones. This process stops working when VMs become dynamic and the number of services grows, since the operations team can’t keep track of individual VMs that are running in production at any point in time. To overcome this challenge, the operations team either has to stop using the on-demand features of the cloud, or lose both efficiency and stability.
- Service endpoints and secrets configuration: Endpoints and secrets used to be configured manually for each service. This approach made sense when the number of services was small and the service endpoints were static. It doesn’t work when the number of services have grown exponentially and the service endpoints are more dynamic. As a result, the load on the release engineering team increases dramatically, and the stability of the environments suffer due to the expanded number of misconfigurations.
- Dynamic scalability and recovery from failures: When an incident in production happened or when a change was needed, the production support team used to get notified and apply a fix by either restarting their VMs and applications, or by adding or removing capacity. With an increased number of services, and the dynamic nature of VMs, such an approach would lead to a very inefficient team and a loss in stability due to long reaction times.
To efficiently adopt cloud and microservices-based architecture and deal with these new challenges, the development and operations teams need better processes and tooling. But before we dive further into the details, here’s a quick overview of the key topics we will touch on throughout the rest of the article:
- Explain how to build an infrastructure on (and select a region for) the cloud.
- Detail why Platform-as-a-Service is not as beneficial as a microservices platform in the long run.
- Compare the best technology options available for orchestrating such a platform.
- Describe what change management is, and examine why it’s so beneficial for microservices migration.
- Review the benefits that a microservices platform and change management bring.
Setting up the cloud infrastructure
Although not directly related to microservices, setting up infrastructure in the cloud properly is very important at the beginning of the migration and replatforming processes. A typical mistake that companies with a traditional approach at managing infrastructure make is onboarding a public cloud, but closing access to the cloud APIs for everyone. Instead of providing access via API, the infrastructure team continues to provide access to the cloud resources via a ticketing system or self-service UI portals, like ServiceNow or JIRA. However, such a setup removes most of the benefits that a cloud brings to the organization. Another common error is when full access is given to the development and operations teams, as this violates most company’s IT policies, and may lead to significant security, quality, and overspending issues in the future.
Fortunately, there is a middle ground where an infrastructure team sets up the base cloud infrastructure, such as projects, workspaces, networking, and firewalls, allows VM images, including OS and middleware, and provides API access to the development and operations teams. This enables easy provisioning of the cloud resources that are allowed on demand. Major cloud providers, including AWS, Google Cloud, and Microsoft Azure, provide a special mechanism to enforce various corporate policies while retaining access via API. A significant part of this mechanism is called IAM: Identity and Access Management (examples in AWS and GCP). An enterprise infrastructure team may configure policies related to accessing cloud resources, budgets, networking, firewalls, allowed base VM images, and more, using the tools that cloud providers offer. Ultimately, access to the cloud resources is split between the teams in the following way:
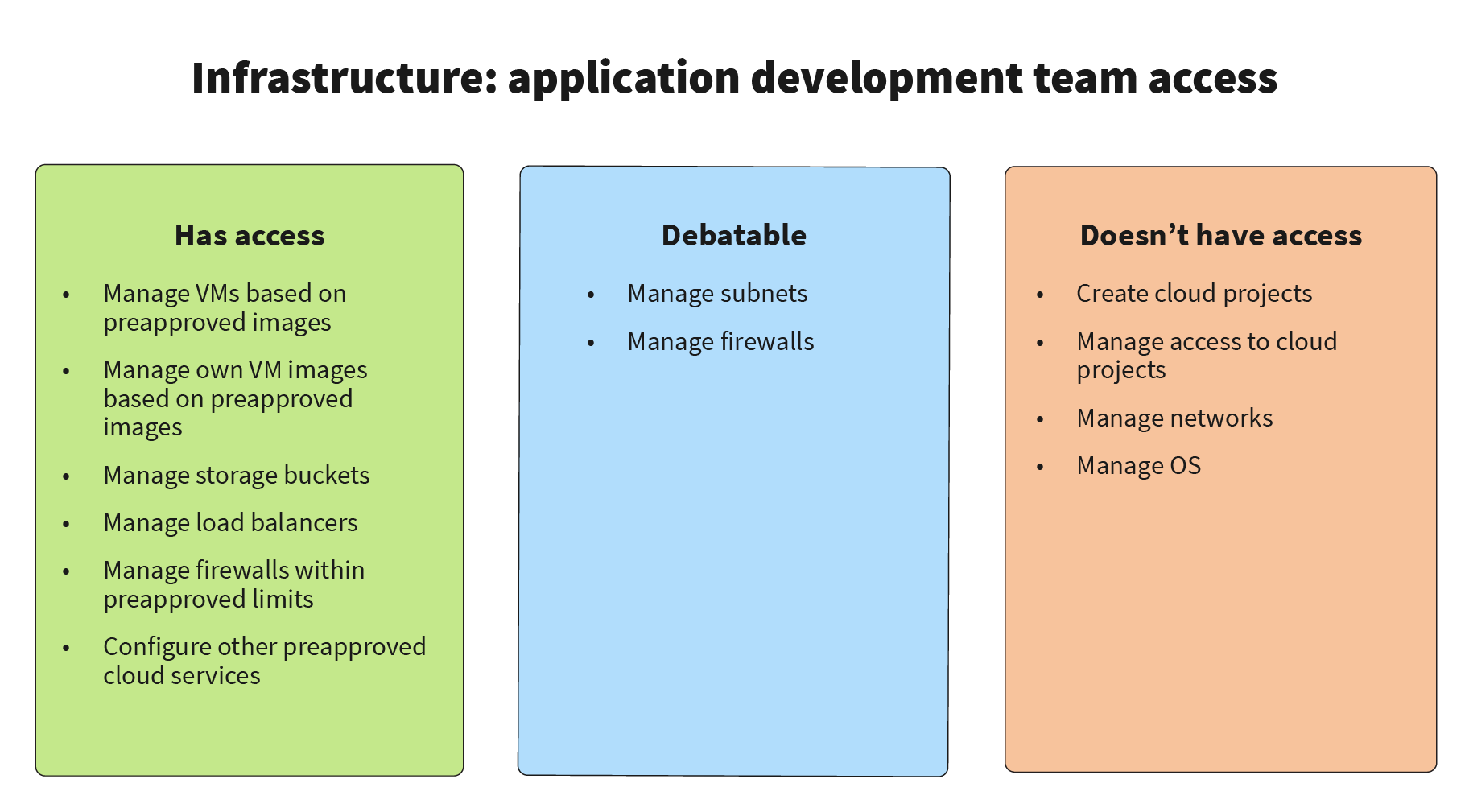
We are not going to get into the specifics of how to set up policies on various cloud providers, but feel free to reach out to us if you would like to learn more about this. It is important to note that the mileage on access may vary depending on the maturity of the development teams and the level of strictness of policies and external standards, such as PCI and HIPAA, that the company needs to comply with.
A separate important topic in properly setting up cloud infrastructure is choosing the proper regions to deploy applications. We assume that new applications and services deployed in the cloud need to integrate with the existing services deployed on premise datacenters, so network latency between the cloud and the datacenter is also a real concern. Moreover, major cloud vendors provide a number of regions across the US and around the world. In many cases, existing datacenters are geographically allocated or applications are deployed in an active-passive DR setup, where only one datacenter is active at any point in time. Due to the constraint of traveling faster than the speed-of-light, even with the best networking between cloud and private datacenters, poor geographical distribution may bring significant network latency overhead, as can be seen in this infographic:
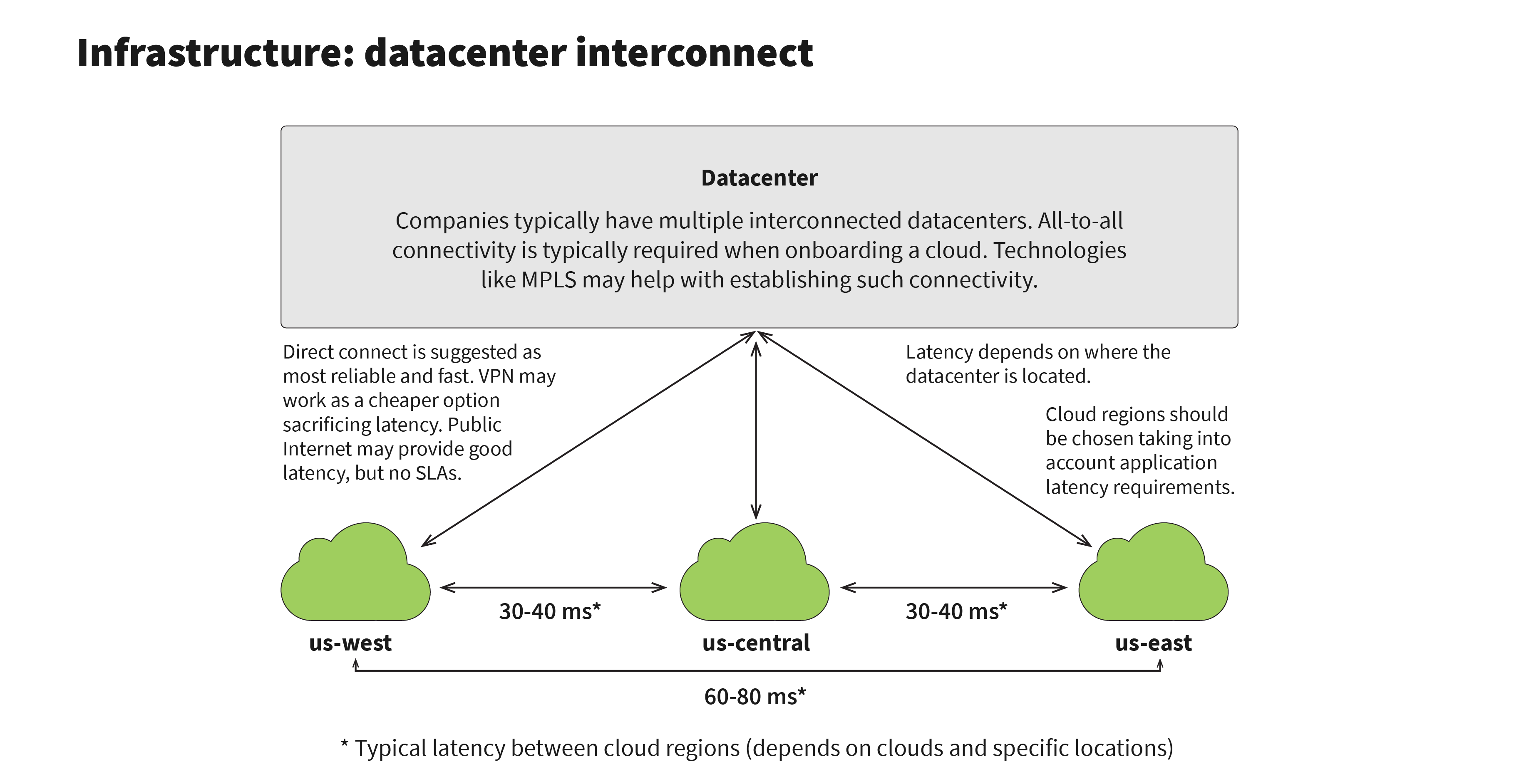
When choosing a cloud provider or regions within the provider, network latency between the cloud and the datacenter need to be tested. Latency also needs to be taken into account when choosing which applications and services should be migrated to the cloud first. As a side note, network latency overhead is one of the reasons why we don’t recommend splitting stateless application components and databases between the cloud and the datacenter. This is because database communication protocol is typically chatty, and assumes a co-located deployment with application instances.

What is a microservices platform?
A base cloud infrastructure is enough to start deploying applications. However, when designing microservices, or at least good service-oriented systems, there is a set of application-independent capabilities that are not provided by pure Infrastructure-as-a-Service. In many cases, we see that companies decide to use a Platform-as-a-Service (PaaS) to increase the efficiency of their application development and support teams. The reference architecture for such a platform can be found below:
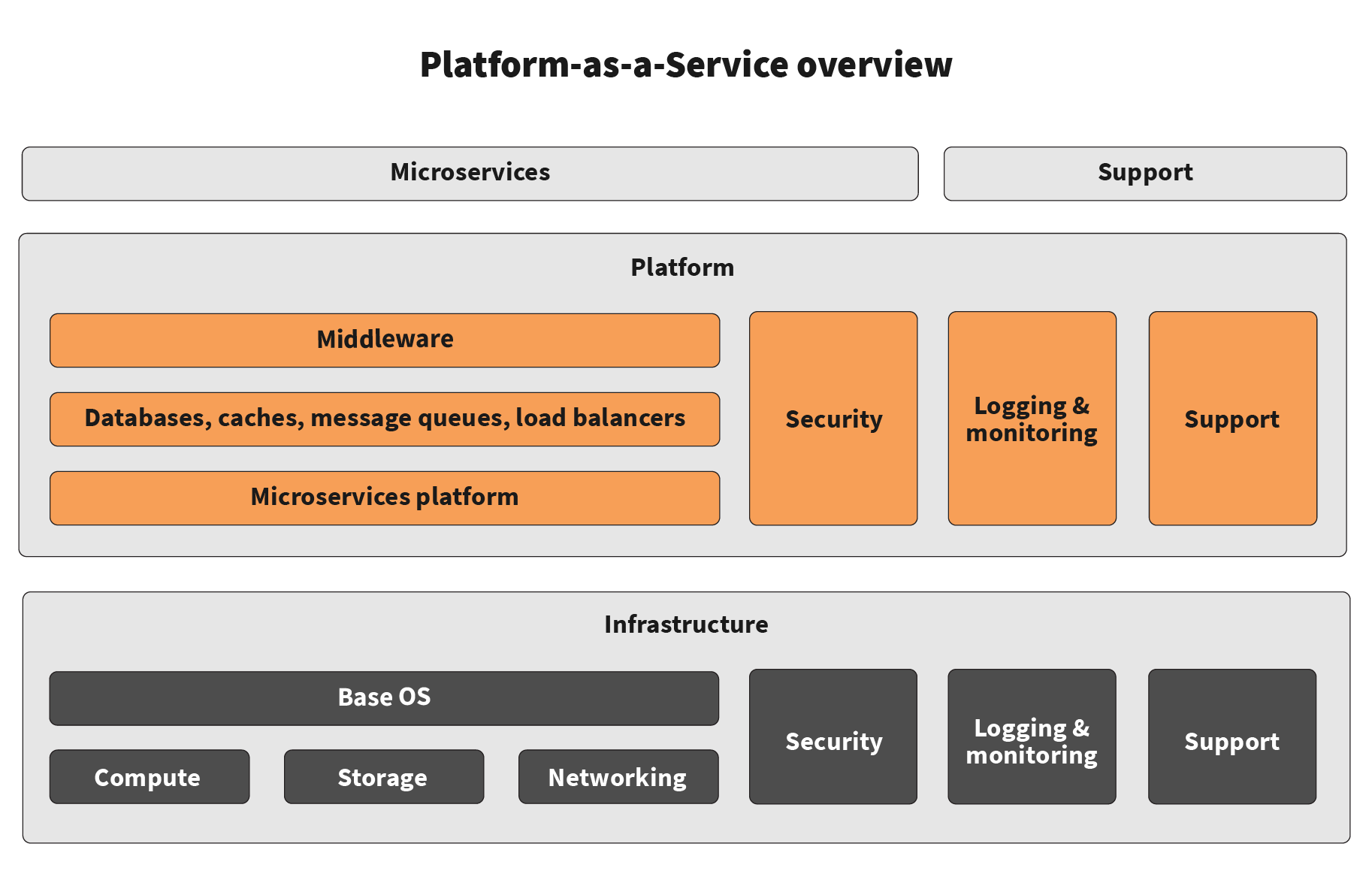
In addition to application-independent microservices management capabilities, such PaaS offerings provide a number of other services including databases, caches, messaging, and application servers. Although this sounds advantageous, PaaS technologies may soon become too restrictive, and the promised benefits will be overshadowed by the high level of customization that each application team requires, and by the increased complexity and cost of operations. While we believe that PaaS technologies are great for early experimentation and applications with low complexity, based on our experience, enterprise-wide adoption should be done only after careful analysis.
Instead of using a full-fledged Platform-as-a-Service, we recommend adopting a limited PaaS, or a microservices platform. Such a platform becomes a thin layer between the infrastructure and the application, and leaves the choice of databases, caches, message queues, application services, and other components to the applications. Instead, the platform focuses on application-independent capabilities, as shown below:
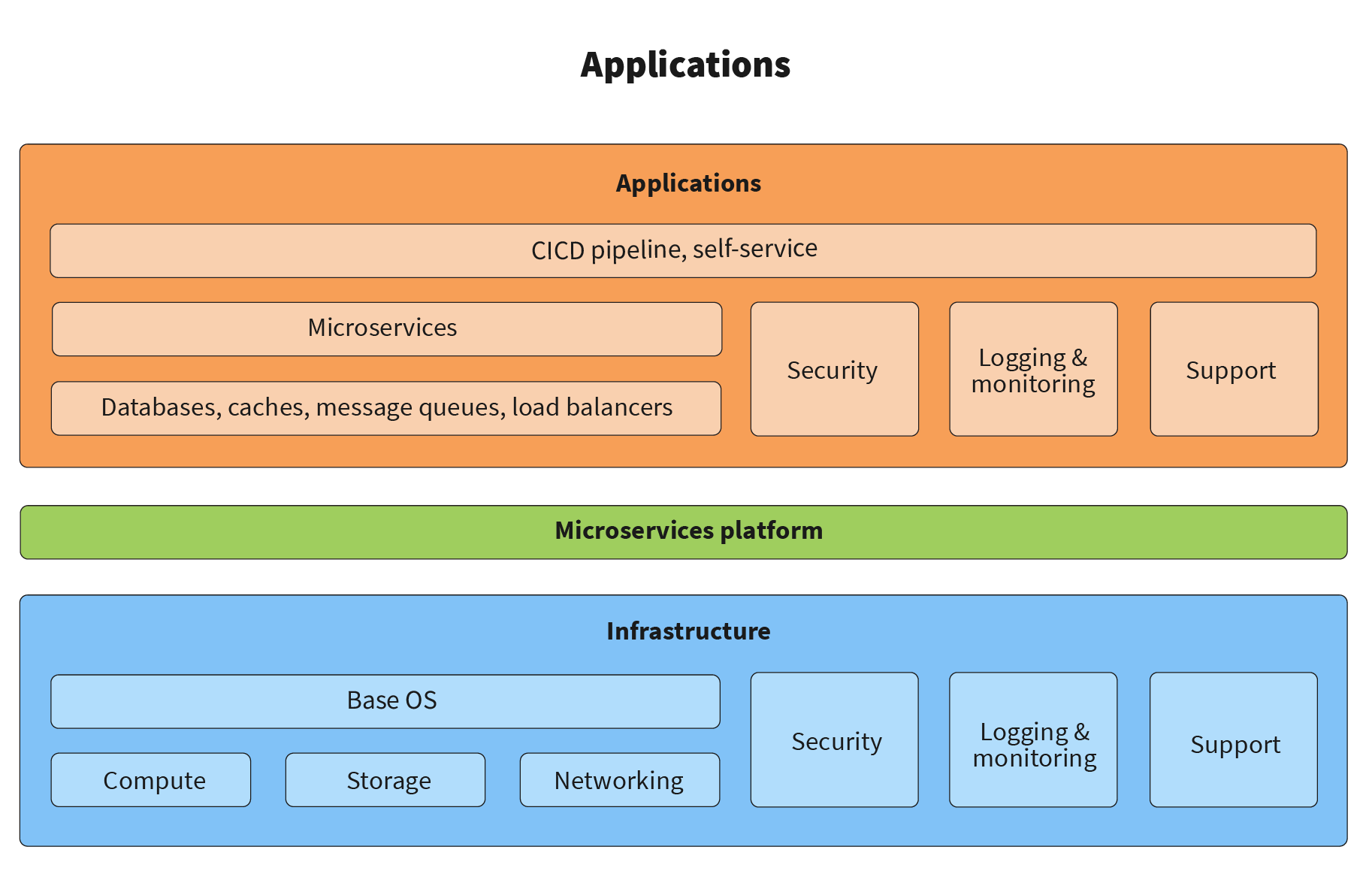
Before we get to the actual definition of a microservices platform, we would like to clarify what we mean by “microservices”. Interestingly, there is still a debate in the industry over the precise definition of what they are, and how they are different from services in a service-oriented architecture. Fortunately, the precise definition is not required for the purposes of this article, so any typical definition of a microservice will work. We are just going to make several assumptions, with the general layout of a microservice shown here:
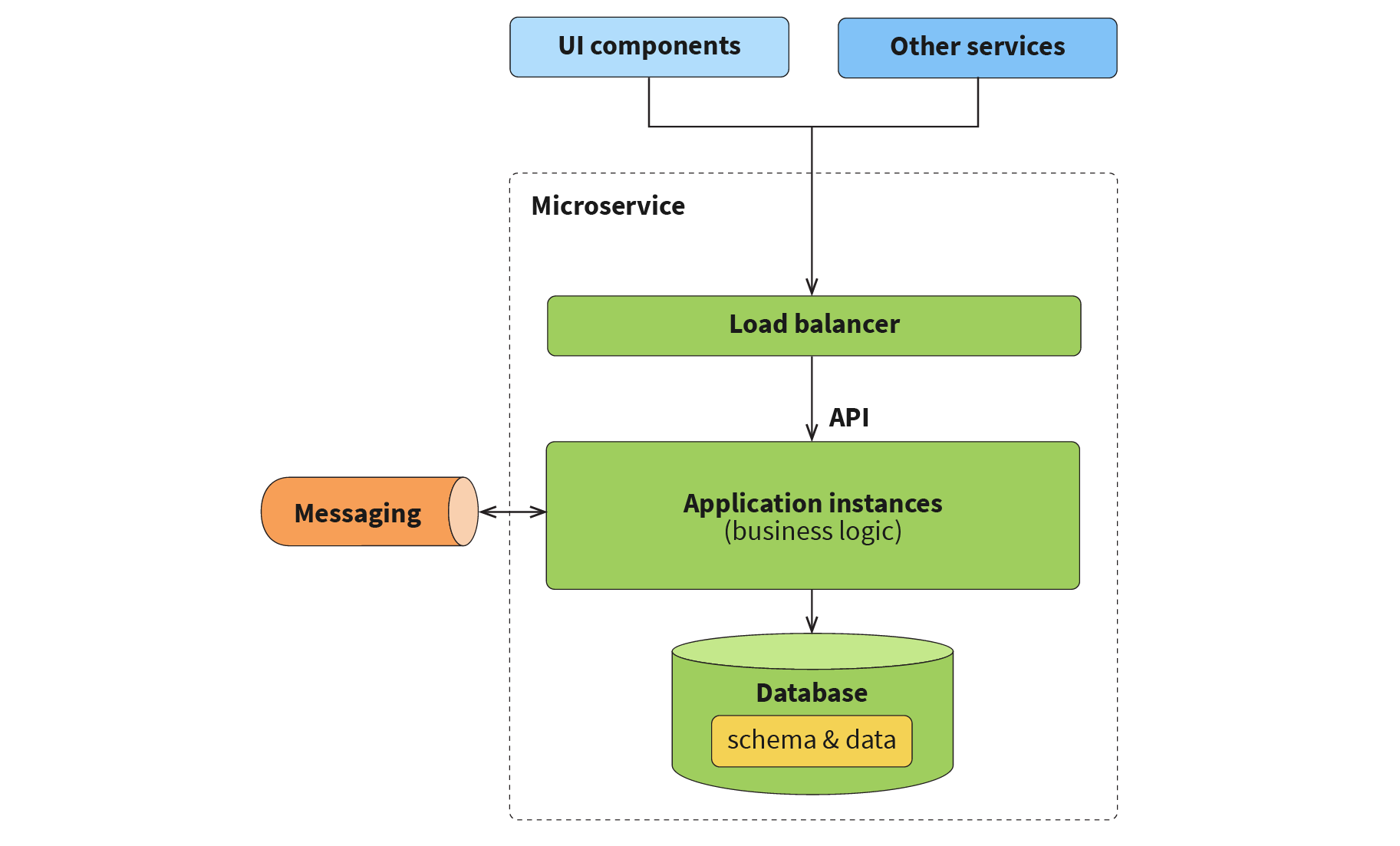
- A microservice consists of one or many components with business logic, and one or many system components including load balancers, databases, caches, message queues, etc. From a deployment and provisioning point of view, all of these components are independent deployment units.
- In some cases, a microservice may use Data-as-a-Service, or message-queue-as-a-service, but in this case, a microservice should have its own isolated container within these systems. Essentially, no two microservices can use the same schema in a database. However, two microservices may use the same topic in a message queue for integration.
- A specific case worth highlighting is that of the load balancer’s place as part of a microservice. As with a database, different microservices may share physical load balancing components, but their configuration is completely isolated from each other.
- Microservices integrate with each other over API.
Strictly speaking, taking into account the definition and assumptions above, a microservice in this case can also be an ETL or UI component. A microservices platform consists of a number of foundational capabilities that allow the efficient developing, building, deploying, and managing of such microservices, as seen in this infographic, with further explanation below:
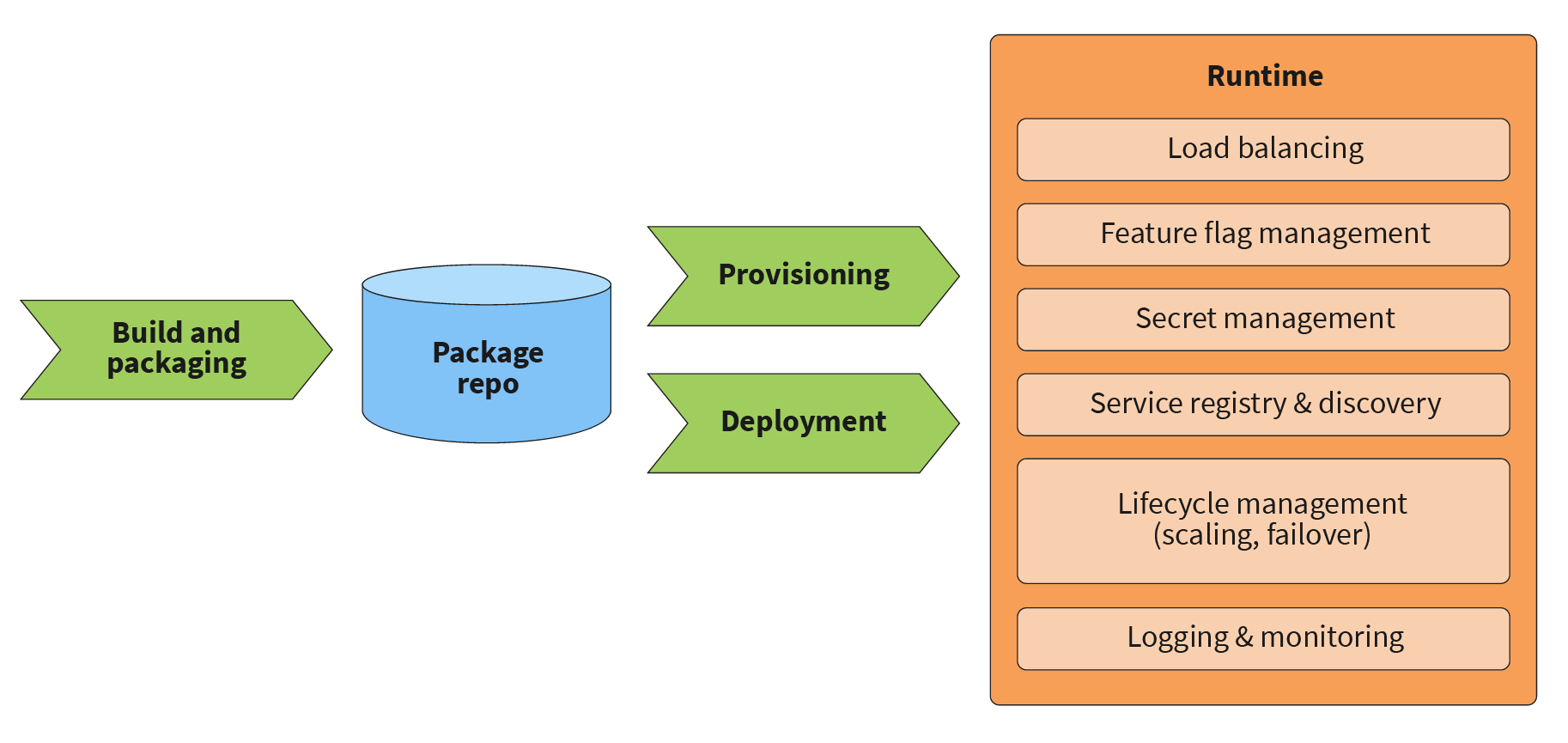
- Build and packaging creates deployable artifacts from source code during the build phase of the CI process. Several years ago, a variety of packages were possible, and the package heavily depended on the type of programming language, middleware, or component. Currently, we only recommend two options: containers or VM images.
- The package repository is similar to an artifact repository - it is the system that stores built packages in a versioned way.
- Provisioning and deployment are synonymous when using VM or container packages, as resources are provisioned during the deployment of the new versions of packages.
- The load balancing feature is self-explanatory. The choice of load balancing method for microservices is a complex topic and is out of the scope of this discussion. Modern cloud providers and microservices platforms offer a variety of options between global and local, L4 and L7, and simple and complex load balancers that support various traffic routing capabilities.
- Feature flag management is a capability that allows operations and business users to configure services in run-time. Similarly to load balancers, the approaches to feature flags management in microservices architecture are a complex topic, especially when one business feature spans multiple microservices. We hope to return to this topic at some point in the future.
- Secret management has two main duties. The first is to automatically register and configure usernames and passwords for component-to-component authentication without the involvement of support personnel. The most common example of this is providing access to the database. The second duty is to manage and configure SSL certificates for services that require SSL.
- Service registry and discovery allows microservices and system components to automatically find each others’ endpoints at runtime without the involvement of production support personnel.
- Lifecycle management is specifically related to auto-scaling and self-healing. Auto-scaling is needed to create new instances when traffic increases, and destroy unneeded ones when traffic decreases. Self-healing identifies and recreates failed service instances. Both of these features make certain assumptions about the component's internal business logic, and need to be configured correctly for each component. When done incorrectly, they may cause more harm than good - for example, auto-scaling of stateful components like databases and caches may lead to an avalanche effect and destroy a whole cluster that could overwise survive. We hope to cover this topic in detail in a future blog post.
- Last but not least, logging and monitoring are self-explanatory as well.
Some of the other features that may be a part of the microservices platform include authentication and authorization, API management, and service mesh. We will return to service mesh later in this article, and hope to cover the other two in future blog posts.
Technology options for a microservices platform implementation
The platform can be implemented with various technologies, but in practice there are two different approaches that are dictated by which method is used to package the deployment units: VM images or Docker containers. The table below provides a difference in technologies between the two options:
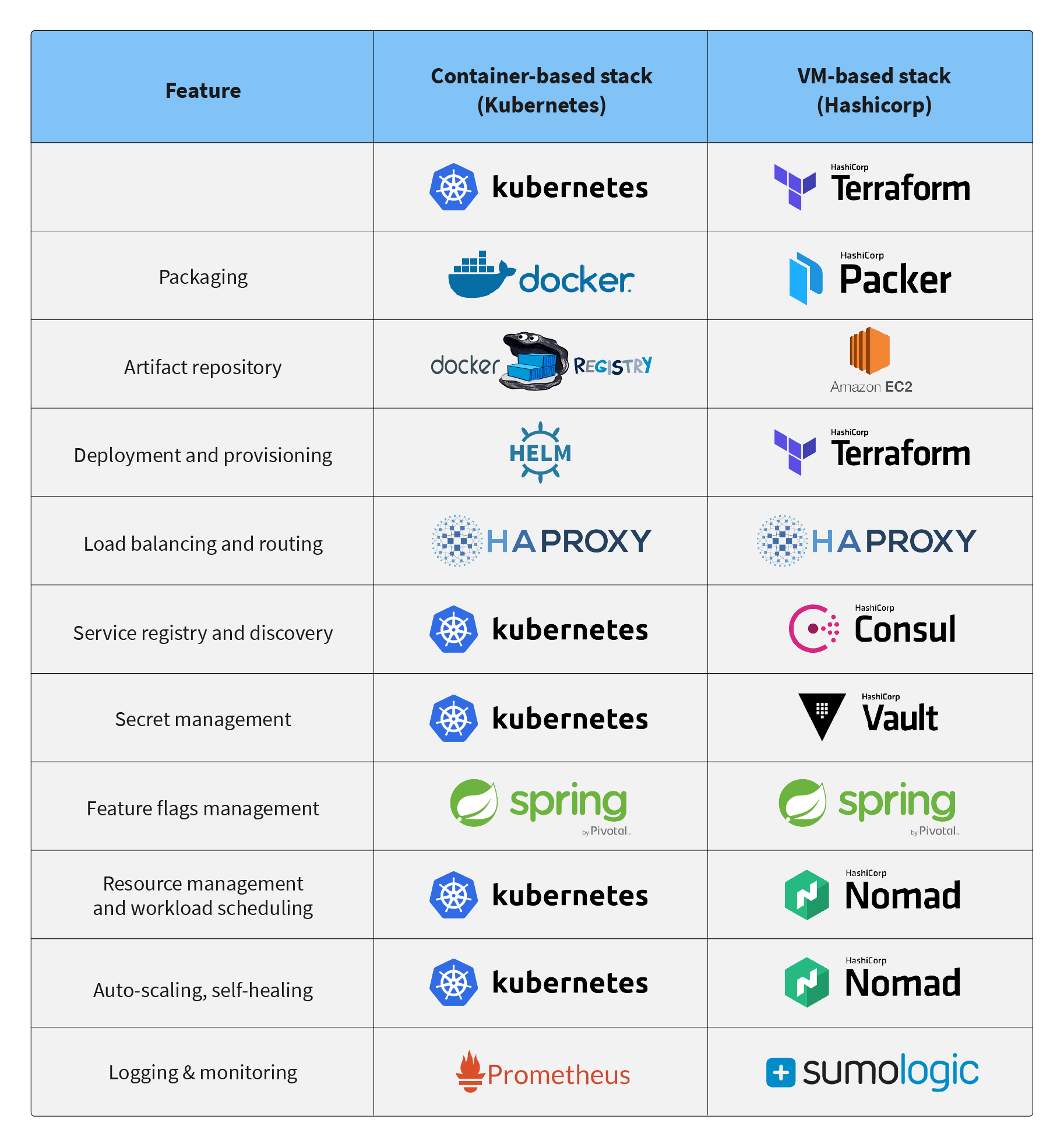
Although the two options look very different, conceptually they are very similar. We have experience working with both options, and found that everything in a container-based stack has a direct one-to-one mapping to a VM-based stack, and that it is relatively easy for developers proficient with one stack to switch to another one.
Service mesh
One feature of a microservices platform that deserves special discussion is the service mesh. A service mesh is needed for flexible traffic routing between microservices. In traditional production operations, there are two main options for upgrades: blue-green and rolling. While a rolling upgrade is easier to execute, it doesn’t allow for controlled A/B testing and canary releases, so it is often used for only small changes. When services need to be upgraded with a canary release and A/B testing, a variety of a blue-green upgrade is typically used. Performing a blue-green upgrade is easy when targeting the top-level customer-facing components and services. It gets significantly more difficult when services deep in the service mesh need to upgraded with top-level canary releases or A/B testing, as shown here:
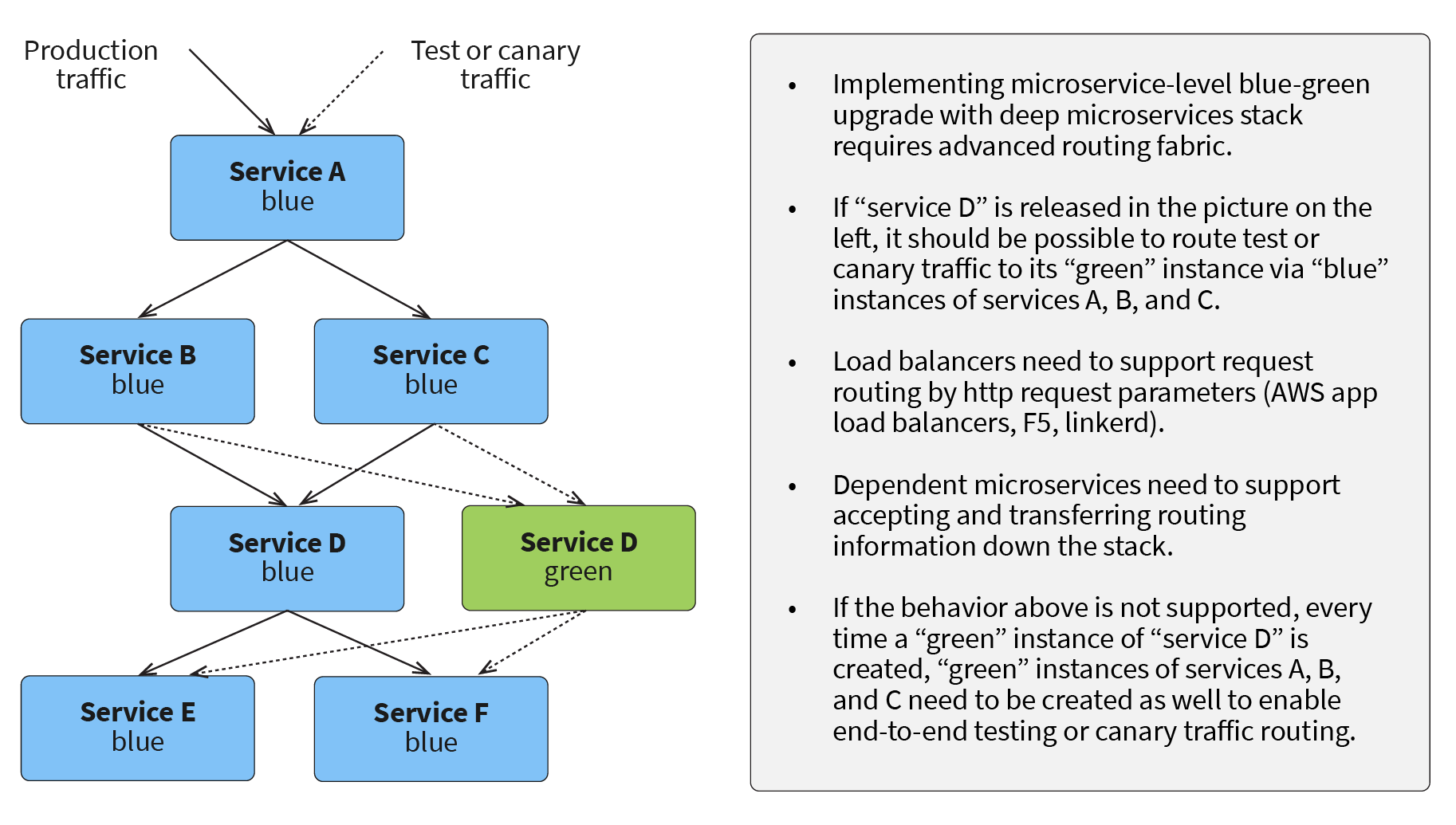
When a service mesh is properly implemented, a service or component deep in the stack can be upgraded, and requests sent to the top-level services with specific headers will be properly routed to blue or green instances of the service. This allows the executing of top-level controlled experiments, including running end-to-end tests before routing customer traffic to the new version. This enables business users to explore the new version before it is made available for the general public, and to select a small group of customers to test the new functionality before a widespread roll-out.
There are a number of technologies available today that help with implementing a service mesh. Some of the popular ones include Linkerd, Envoy, and Istio.
Change management to enable easy microservice migration
When designing new systems in the cloud, it makes sense to consider three major areas of changes:
- Application changes include adjustments in source code, deployment scripts, and respective configuration and deployment scripts of system components, such as databases, caches, middleware, etc.
- Infrastructure changes include changes in networking, security, and base images of VMs and containers.
- Environment-level configuration changes involve changes in endpoints, secrets, number of application instances, and business-level feature flags.
While the first two types typically go through a regular continuous delivery pipeline, environment-level configuration changes are often not even considered to be changes. For example, modifications in endpoints, secrets, and the scalability configuration for stateless applications do not require human intervention, and are supported by the platform taking into account preconfigured policies. Changes to feature flags should be considered in the same way as changes in data, as application business logic needs to be tested and ready to work with any allowed combination of feature flags.
Change management and continuous delivery for microservices is a separate, large topic. The format of this article doesn’t allow us to describe it in full detail, so we will just give an overview of the approach and some of its best practices:
- First, a microservices architecture assumes that it is possible to release individual services independently. Therefore, the services themselves and the CI/CD pipeline for them need to be designed in such a way that at the end of the pipeline, it is possible to make a decision to deploy a service in production. Robust service-level testing and implementation of the service mesh should help significantly in accomplishing this.
- Second, we recommend embracing the approach of immutable infrastructure. This is when the VM images or containers that are produced by the build and packaging phase of the pipeline are the atomic units of deployment, and are not changed across environments.
- To the previous point, we recommend baking all application-dependent properties and configuration into immutable deployment packages. For example, memory and garbage collection settings of a Java application should be a part of the VM image or container. Changing this configuration in production ad-hoc without testing may lead to unpredictable results. The same consideration applies to the scalability settings of stateful clustered applications. For example, changing a Zookeeper cluster from three to five nodes during production may lead to the crash of the whole cluster.
- Third, in case the infrastructure team is responsible for the base container or VM images, those images should be considered as libraries that the application teams depend on. The application build process should reference versioned libraries, and pass new application packages through the CI/CD pipeline. Ad-hoc and untested changes of the base images in production may lead to unpredictable results and instability.
- Last, but not least, when migrating to the cloud and microservices, we recommend designing the continuous delivery pipeline based on the existing top-level enterprise change management policies and compliance requirements with external standards, like PCI or HIPAA. However, we strongly recommend reconsidering existing processes and tooling, and designing new ones in a fully automated way. Ultimately, the automated CI/CD pipeline should replace the manual change management board. When all responsible parties in the change management process automate their policy and bake it into the pipeline, the pipeline will produce fully verified deployment packages with all sign-offs collected and saved to the audit log on its own. The architecture for the CI/CD pipeline can be seen here:
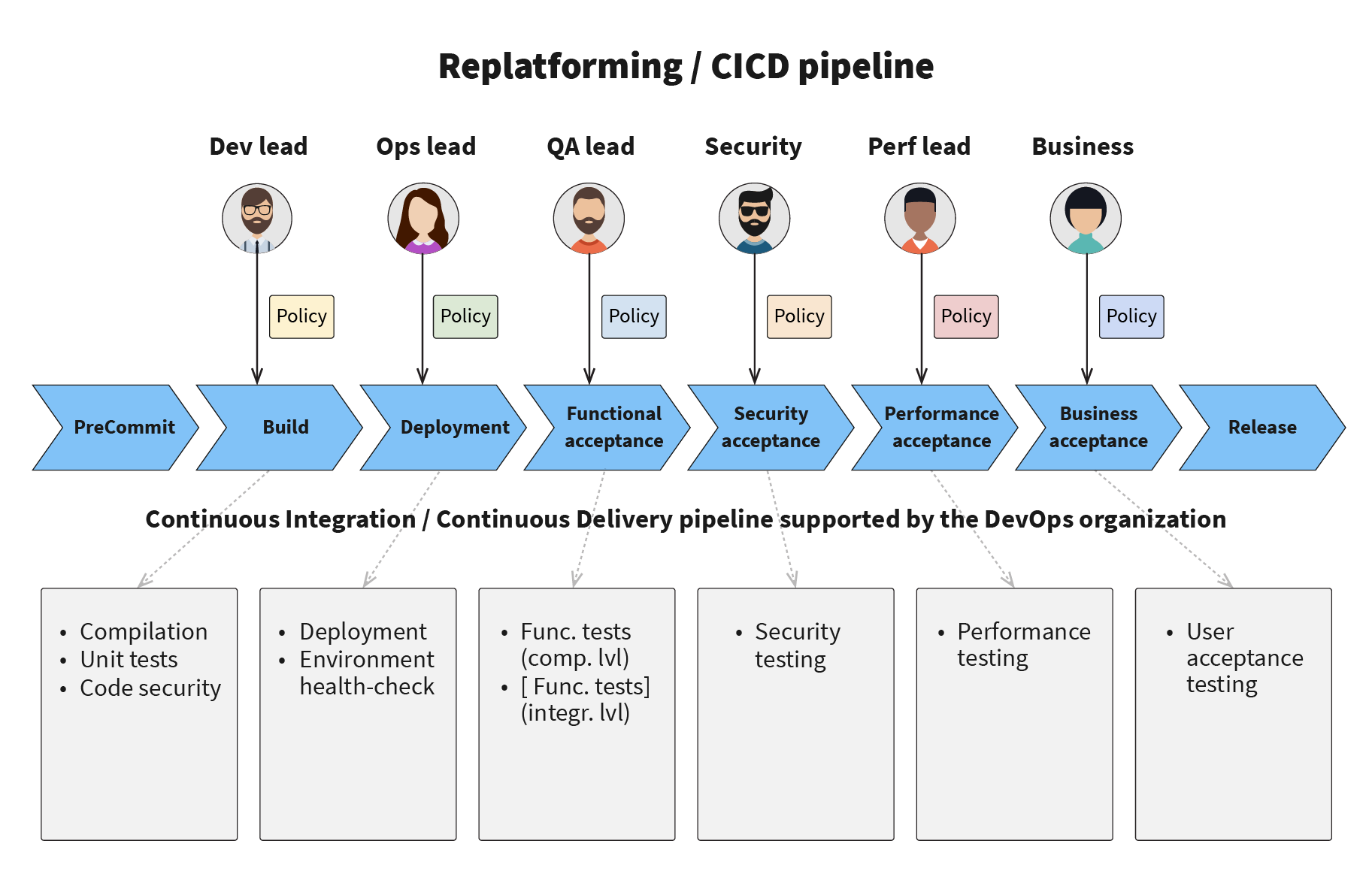
Results
In this article, we described how to build a microservices platform and design a proper change management process. By doing this, retailers can open the door to a massive migration to the cloud. A typical implementation allows the following benefits:
- Support of hundreds of services and components.
- The time it takes to get from code commits to production deployments is reduced to hours or minutes, depending on the complexity of the services and the levels of testing.
- Enablement of high throughput of changes, when individual services can be released independently.
- Increased efficiency of development, release engineering, production operations, and infrastructure teams.
- Support for thousands of engineers in application development teams.
- Maintaining and increasing the quality and the level of control over the change management process.
Additionally, the establishment of a microservices platform enables further development in replatforming, making all future processes easier.
Conclusion and next steps
Retailers all have similar issues with their monolithic black box platforms, which has pushed them towards migrating to microservices on the cloud. If this replatforming is not supported properly, the benefits of the move might not be realized. However, with the steps laid out here, migration should go smoothly and efficiently. Building a microservices platform, along with an accompanying change management process, can bring substantial benefits, as the results section listed above shows.
Of course, the topic of microservices and the building of infrastructure to support them is a broad one, and we can’t discuss every element on the subject. One of the aspects that we didn’t describe in detail in this article is the role of production operations, or Site Reliability Engineering. The microservices platform already provides some advanced capabilities for this, including auto-scaling and self-healing. We hope to return to this topic in further depth in one of our future blog posts.
In the following articles in the series, we will continue our discussion on how to replatform the rest of the services in the digital customer experience platform. These will include posts on cart and checkout, customer profiles, product information management, customer data management, and one on pricing, offers, and promotions. We will also describe how to achieve a true omnichannel experience by deploying the platform in physical stores. Look out for the upcoming articles on this blog, and if this post has sparked your interest, give us a call or leave us a comment!