
Building a Visual Quality Control solution in Google Cloud using Vertex AI



The effectiveness and efficiency of quality control processes are among the top concerns for most manufacturing companies, and are also important considerations in logistics, agriculture, and other verticals. Over the last decade, visual quality control automation using computer vision has proved to be one of the most efficient solutions for reducing quality costs and defect rates. Moreover, modern computer vision models and frameworks provide an extremely versatile platform that enables the implementation of a broad range of use cases at a relatively low cost. The cost and complexity of the implementation can be reduced even further using a specialized cloud-native service for model training and edge deployment.
In this blog post, we consider the problem of defect detection in packages on assembly and sorting lines. More specifically, we present a real-time visual quality control solution that is capable of tracking multiple objects (packages) on a line, analyzing each object, and evaluating the probability of a defect or damaged parcel. The solution was implemented using Google Cloud Platform (GCP) Vertex AI platforms and GCP AutoML services, and we have made the reference implementation available in our git repository. This implementation can be used as a starting point for developing custom visual quality control pipelines.
Vertex AI for defect detection: Solution overview
Packaging defects, such as incorrect information, unclear imprints, faulty seals, and damaged parcels, are common problems in manufacturing and logistics environments. We designed a pipeline to detect various defects on the line without disrupting sorting processes. The pipeline consumes a video stream from a camera installed on a line, performs processing in four stages, and outputs an annotated video stream.
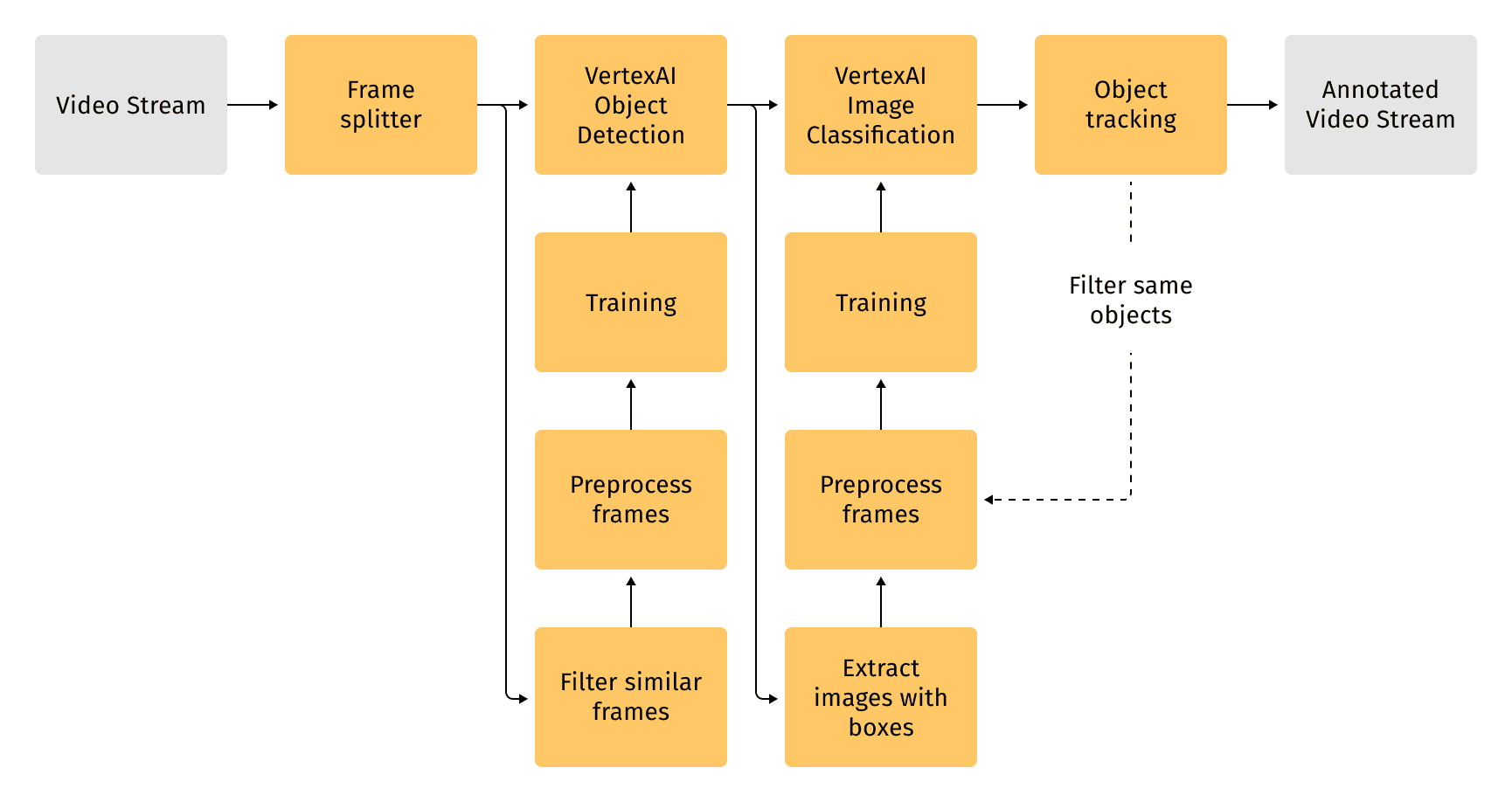
The first step in the pipeline involves preparing the video stream for analysis by parsing and selecting specific frames. The next stage uses a Vertex AI service to identify bounding boxes around parcels on the line.
When the object is identified, the anomaly detection system begins to process the frame. This involves cutting out the object using the bounding box and resizing it to a specific size. The processed image is then sent to an anomaly detection model for further analysis. In both cases, a service provided by Google Vertex AI detects parcels and identifies whether they are defective, which has proven to be effective in terms of accuracy and speed. To train the model, we used a small dataset that includes augmented examples of anomalies. The entire process, from training to inference, is referred to as the training and inference pipeline.
As a final step, we used a conventional (non-ML) computer vision algorithm to track labeled objects on the line. This approach allows for fast processing while maintaining high accuracy. The fast processing time permits the use of the model's output in real-time for monitoring purposes, in addition to automating anomaly detection processes.
Dataset overview
We used a video sample that emulates a conveyor belt with boxes moving from left to right, and some of the boxes are damaged or represent anomalous objects. This example video is 40 seconds long and contains a total of 100 objects, 4 of which are anomalous. The emulation of the process line enabled us to select the preferred number of objects to track in a single frame, the speed of the conveyor belt, and lights, among other elements.

Visual inspection AI solution implementation details
Training
As previously mentioned, we created two ML models to achieve our objectives: an object detection model and an image classification model (both of which are powered by the Google Vertex AI AutoML service). Such an approach requires very little machine learning expertise to train, and the process is very simple. One of the most important requirements of the dataset is that it contains representative examples of anomalies and regular instances. After the dataset has been prepared, the remaining procedures are completed with a minimal amount of code.
Object detection dataset preparation
An object detection dataset for the Google Vertex AI AutoML service should consist of different images, and each object in the image should have a bounding box annotation. Generally speaking, the data can include multiple object types, not just one (boxes, in our case).

Ultimately, 40 frames were available for training the object identification model. This is a modest amount, and machine learning models often need to be trained on many more examples. However, for the purposes of this blog post, the quantity of examples was sufficient to assess the cloud service's suitability for use in a real-time monitoring scenario. Additionally, VertexAI AutoML services enable the training of a model with just 10 samples of each category, and we did not experience problems training the model for our use case. Of course, the quantity of data generally has a direct impact on the model's accuracy, and it is advisable to use more examples in the training process for models that will be used in production.
The next step was to determine how to divide the dataset. Training, validation, and test sets are typically required for Vertex AI datasets, and Vertex AI automatically distributes 80% of the images for training, 10% for validation, and 10% for testing unless otherwise specified. Manual splitting, however, makes it possible to obtain more significant sets and prevent data leaks. In this instance, it is preferable to avoid having various sets of successive video frames because they are comparable. So, using a timestamp, we divided the frames as follows:
- The first part of the video is assigned to the training set;
- The second part of the video is assigned to the validation set; and
- The last part of the video is assigned to the test set.
Anomaly classification with Vertex AI AutoML
For the next phase, we once again used Vertex AI AutoML to classify anomalies in detected and tracked objects. Once the bounding box of each object is created, we used an image classification algorithm to divide the objects into two groups: normal and anomalous.
As we were working with a small dataset and focused mainly on building a prototype, not on improving the model quality, we did not try to address the problem of unbalanced classes. Usually, this problem occurs because there are many more normal examples than anomalous ones. Therefore, in a real production scenario, we advise the use of techniques for balancing classes. According to Vertex AI's documentation, their models perform at their best when there are no more than 100 times as many images for the more common label as there are for the less common label.
Next, we reused the upstream dataset that was manually annotated for object detection, which was then additionally labeled for the classification model. To connect boxes surrounding the same object in various video frames, we first ran our tracking algorithm, which is described in the next section. As a result, we had a collection of objects and their IDs, each of which had a set of bounding boxes from various frames. We then manually labeled objects as "normal" and "anomalous." The dataset was finalized by extracting the bounding boxes from the images and unifying them using basic preprocessing:
- Each object image was adjusted to the same size; and
- Padding was added as needed.
Additionally, as mentioned previously, it is important not to use the same object to both train and test the model. Otherwise, a "data leak" occurs, and a model could simply "memorize" the anomalous objects in the training dataset instead of learning general patterns and still score high on the training test (meaning that the model would continue to overfit to the training examples during training and would not perform properly when used later for previously unseen examples). To avoid this problem, a manual split in training, validation, and testing should be used, so that the same physical objects are not assigned to multiple sets.
Inference
We combined both trained models at the inference stage with an object-tracking algorithm as a middle step. The steps we used to process the video frames are as follows:
- Detect the bounding boxes of objects in a video frame.
- Using an object-tracking algorithm, link objects with the same objects in previous frames.
- Create a new object-tracking instance for any new objects that have recently entered the frame, and use the anomaly classification model to give the objects a class label (normal or anomalous).
Vertex AI models can be hosted and queried with a few lines of code by Google Cloud. On the other hand, we implemented a modified algorithm for object tracking, which will be described in detail in the following section.
Object tracking
The tracking algorithm is used to track different objects between video frames. The majority of fundamental object-tracking algorithms have their own constraints, and there are many different classical ones with varying tracking precision and frames per second (FPS) throughput. The fact that the simplest algorithms can track only a single object, while we wanted to track dozens, was the most significant restriction that prevented us from using an algorithm out of the box. To address this, we developed a higher-level tracking algorithm that can handle multiple objects while utilizing the strengths of simple classical trackers.
The developed algorithm addresses the following features of the video in our scenario:
- Each frame contains many different objects.
- New objects appear during the video.
- Objects are only partially visible at the moment they enter the frame, but most of them become fully visible in later frames.
After the object detection algorithm determines the bounding boxes for the new objects, the methodology employs a new instance of a basic tracker to track these objects. We used a distance threshold between the bounding box centroids to determine whether the detected bounding box belonged to a newly discovered object or an object that had already been tracked. This approach works because an object can not arbitrarily "jump" between frames.
In addition, if the new box were significantly larger than the bounding box of an existing object, we permitted it to be replaced. This accounts for situations in which an object has just entered the frame and is only partially visible.
Additionally, we discovered that the tracking algorithm's naive application to each individual image makes it unsuitable for real-time processing although it is quite simple and, consequently, relatively quick. We also observed that it performed admirably well with low-resolution frames. Therefore, we downscaled frames with a ratio of R = 0.4 to increase throughput by more than twice that of FPS. The final output of the pipeline is shown in the figure below.

Results
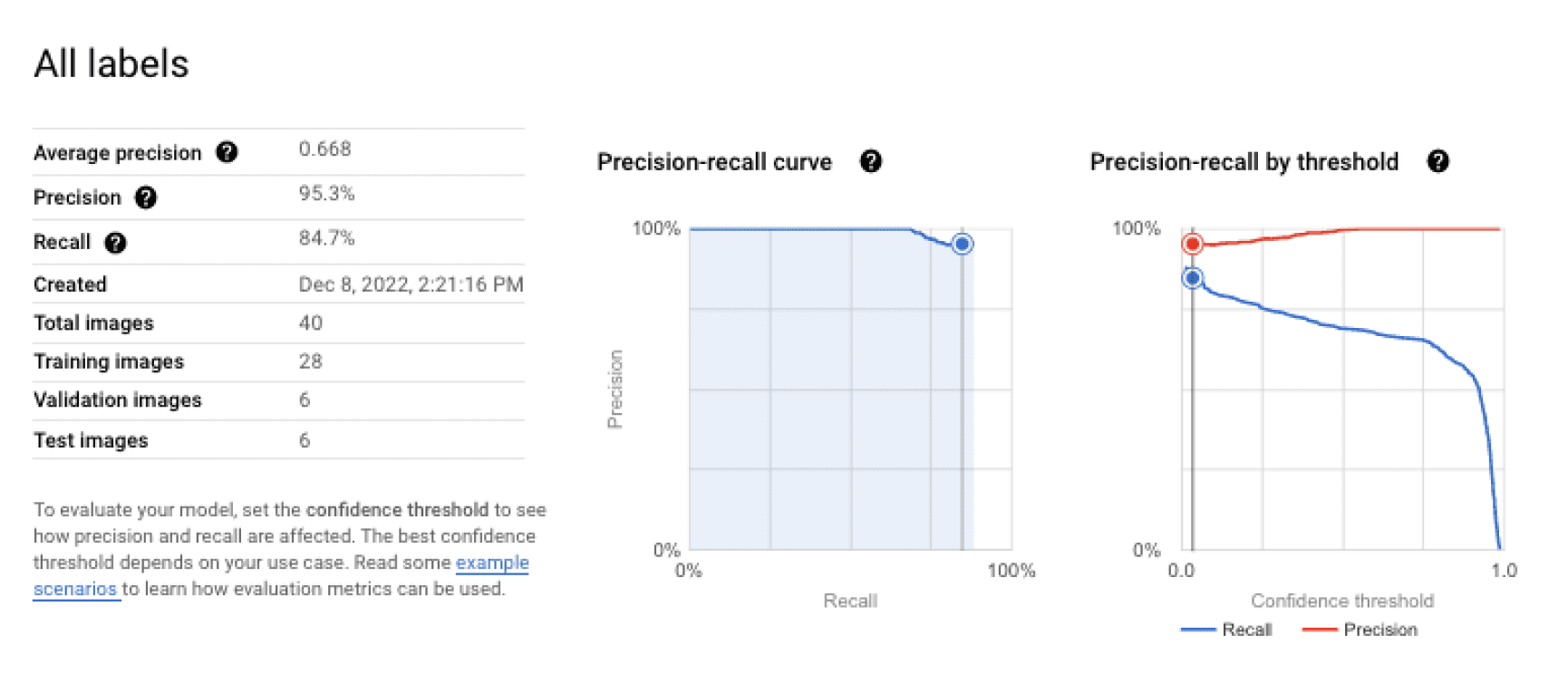
The solution is able to recognize damaged parcels in the majority of cases, and it can be used in real time to process raw video streams. For object detection, the model achieves 85% recall with 95% precision. (These metrics are automatically provided by Vertex AI.)
Next, we achieved a precision and recall score of 100% for object classification. Because the model tested only a small set of data, it must be noted that this result should not be taken as indicative of product-based solutions. We might anticipate that the results would be lower in the typical case of a real production-based scenario with a good, diverse dataset.
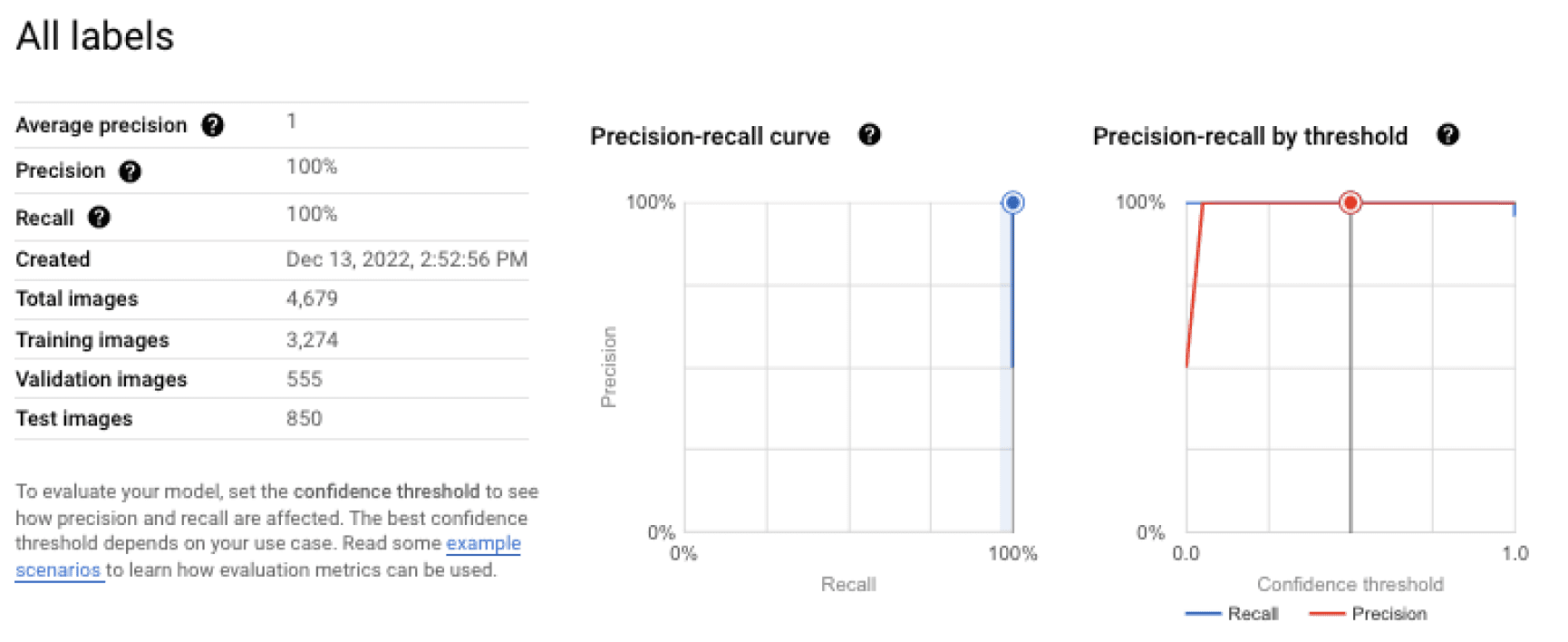
Finally, we have shown that such a pipeline can be developed with a very limited number of samples. Also, the training dataset contained about 100 different objects, of which only 4 were anomalous. Normally, model training is a continuous process that can take weeks or months. In a real situation, we would have much longer video streams and the ability to iteratively grow the dataset in order to improve the model until it reached the required quality. Nevertheless, with Vertex AI, we were able to achieve reasonable quality after the first training run (which took only a few hours), even with a very small dataset.
Visual quality control solution in GCP with Vertex AI: Conclusions
In this blog post, we explained how to create a basic visual quality control solution in GCP using a limited number of components and a small amount of data. AutoML services and data augmentation are the key ingredients of this solution, helping to reduce implementation complexity and relax data requirements. The provided reference pipeline can be used as a starting point for building production-grade solutions.