
Customer churn prevention: A prescriptive solution using deep learning


Customer retention is the primary pillar for building virtually any subscription-based business, including software, video game, media, and telecom businesses. Nowadays, it is common to use advanced machine learning techniques to predict customer churn probability as accurately as possible. However, a good churn prevention solution requires more than just accuracy.
When facing a churn problem, a churn prediction without explanatory power cannot provide much business value. It is important to understand where churn is coming from and what actions should be taken to prevent it. In order to do that, let us ask some fundamental questions:
- Who will churn? We need to identify a specific user segment that we are at risk of losing.
- When will they churn? We need to predict churn probabilities for months in advance.
- Why will they churn? We need to identify potential churn drivers and triggers.
- What is the best treatment? We need to provide a framework for evaluating different treatment options.
The four “W”s are the fundamental questions that we should ask before finding a churn solution. If we know “who,” we can optimize and personalize treatment options. If we know “when,” we can optimize the time of the treatment to achieve maximum efficiency in terms of retention, incremental lifetime value, and treatment costs. If we know “why,” we can improve our product, service, or customer relationship management. If we know “what,” we can improve customer satisfaction and reduce the cost of churn prevention activities.
The ability to identify and interpret churn patterns and prescribe right treatments is as important as achieving churn prediction accuracy. In this article, we discuss how to build a solution that helps to quantify, investigate, and fight customer churn, complaints, and other issues related to customer dissatisfaction. The described approach has been successfully implemented for several clients and proved itself to be a powerful generic framework.
Solution Capabilities
From the functional perspective, the solution is designed to produce a set of scores and indicators for individual users that can be operationalized in two ways:
- First, the marketing team can slice and dice the scored users to create homogenous cohorts that can be treated in a certain way. For example, a marketing team can decide to focus the effort on customers with a very high churn probability and who are likely to churn specifically because of dissatisfaction with the quality of service. These cohorts then can be sent to the marketing automation software or other operationalization tools.
- Second, the scores can be consumed by personalization systems, such as online product recommendation engines, to make better personalized decisions with regard to individual customers.
We have found that, in many practical cases, the following scores and indicators are sufficient for supporting a wide range of churn prevention activities: churn triggers associated with a user, churn risk level, churn risk profile (survival curve), and prescribed treatments. These outputs are shown in the figure below.
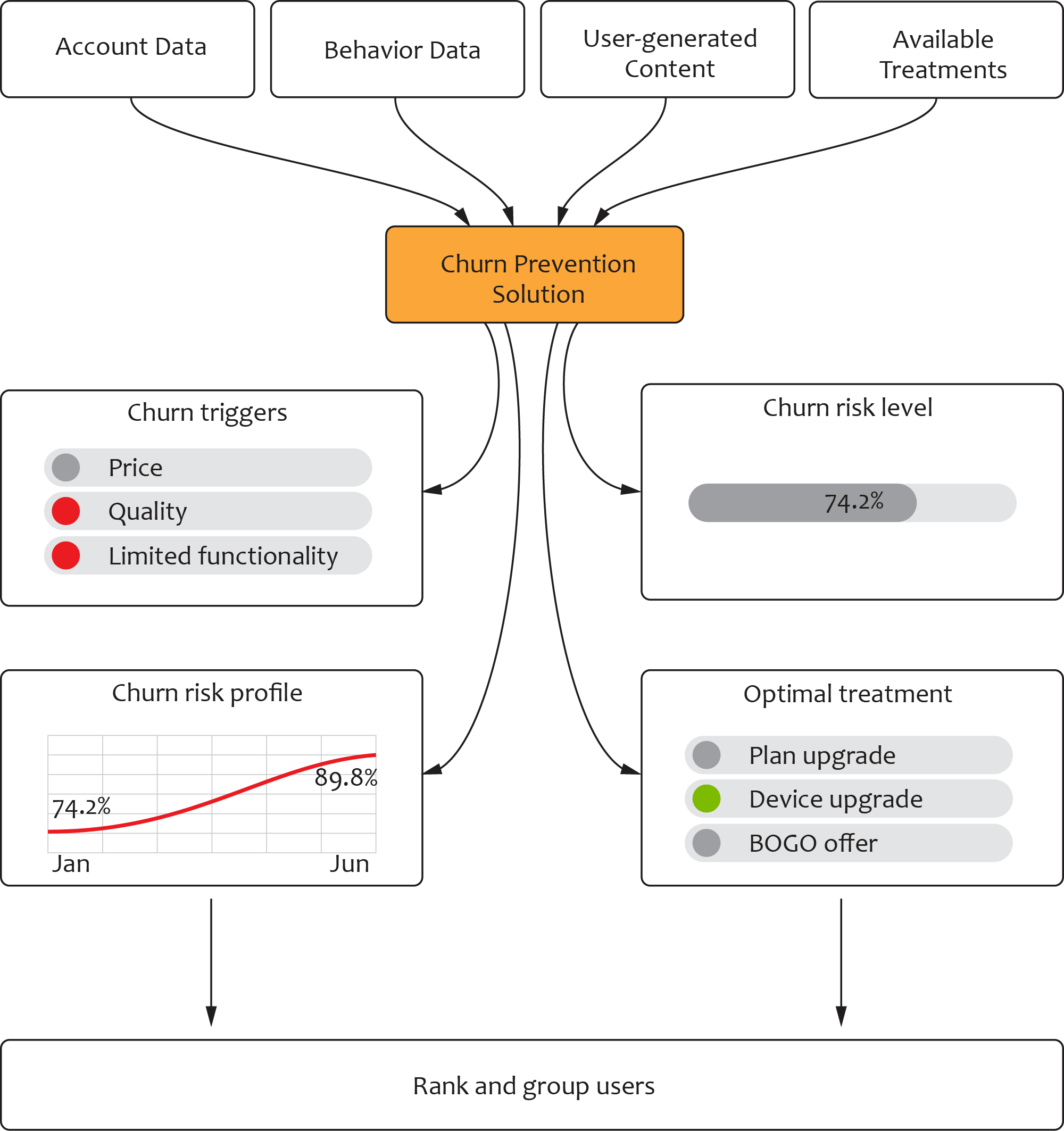
From the technical standpoint, it is important to leverage all available data sources, including well-structured account data, event sequences (such as the clickstream), user-generated content (such as product reviews and customer support call transcripts), and, finally, information about the available treatments (such as special offers or loyalty perks).
In the next section, we discuss the overall architecture of the solution that provides the above functionality as well as the design of the models and components it is assembled from.
Solution Architecture
The architecture of the solution generally accounts for both the goals we want to achieve and the data needed to achieve those goals. For the sake of illustration, let us assume the following four typical data sources:
- User-generated text, such as product reviews and call transcripts
- User account data, such as demographics and pricing plans
- User interactions, such as visiting a URL or receiving a mobile message
- Historical treatments (e.g., offers) with the corresponding user responses
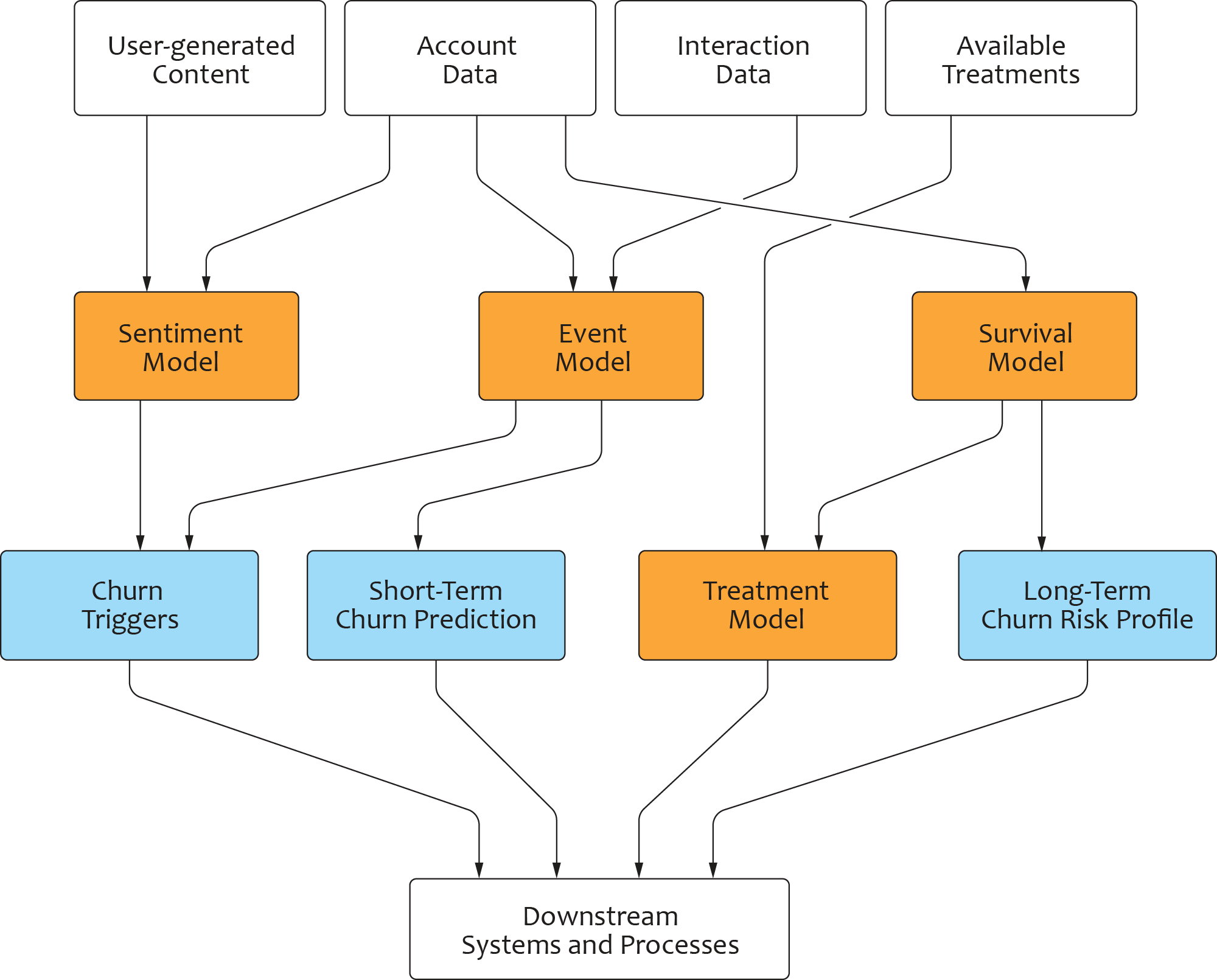
The textual data enable us to build a sentiment model for understanding customer churn reasons. The customer interactions data allow us to build an event model for churn prediction, and the offer data allow us to build a recommendation system based on customer reaction to historical offers. Hence, we created four major models to make an end-to-end churn-prediction/offer-recommendation pipeline:
- Sentiment Model. The purpose of this model is to identify meaningful churn triggers (reasons for customer churn) and churn indicators (signals of customer churn). It utilizes deep learning models for sentiment analysis and topic modelling.
- Event Model. The purpose of this model is to provide accurate short-term (e.g., one-month) churn prediction. It also uses deep learning methods, such as a self-attention transformer model.
- Survival Model. The purpose of this model is to provide a long-term (e.g., six-month) churn risk prediction. It takes the outputs from the sentiment model and event model and utilizes a binary classification to estimate the churn probability.
- Treatment Model. The purpose of this model is to provide offer recommendations based on historical offer data. It takes the outputs from the event model and survival model and utilizes uplift modeling with bias correction to determine the optimal treatment.
Let us dive into each model separately.
Sentiment Model for User-Generated Content
The sentiment model analyzes textual data and identifies churn triggers. The training data are usually taken for one month prior to the churn event in order to capture churn-related topics. However, the time window can vary across industries, as the patience of customers in their decision-making could be different.
The Bidirectional Encoder Representations from Transformers (BERT) model is typically utilized to extract negative snippets from the user-generated texts; topic modelling is utilized on the negative snippets, and it outputs a word distribution for each topic from which we can identify churn drivers and churn indicators. This process is summarized in the figure below.
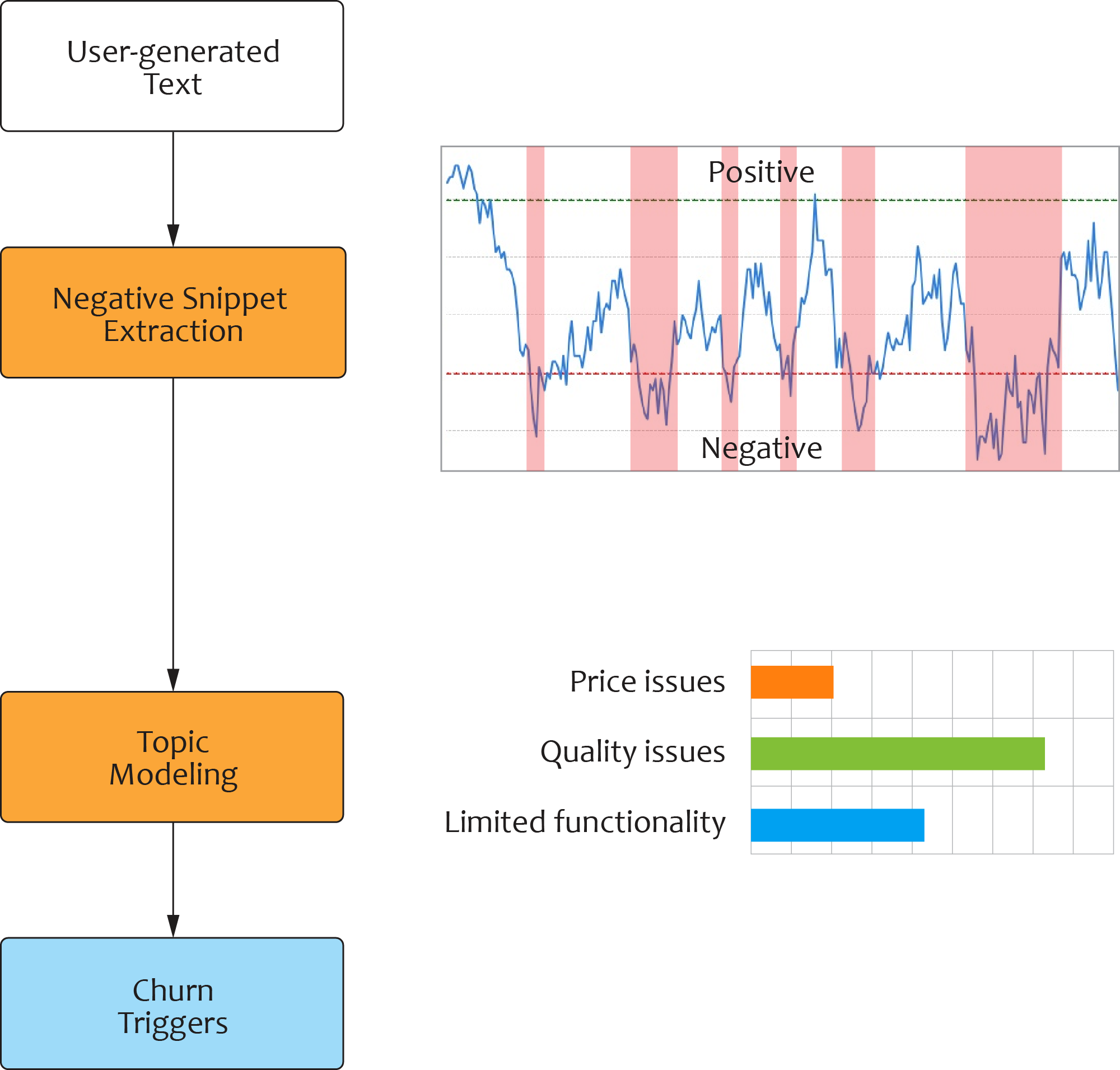
The sentiment model provides interpretative power for customer churn analytics, allowing systematic treatment and personalized treatment. For systematic treatment, we can use this model to identify groups of customers who have the same churn triggers as well as different types of treatment for different groups.
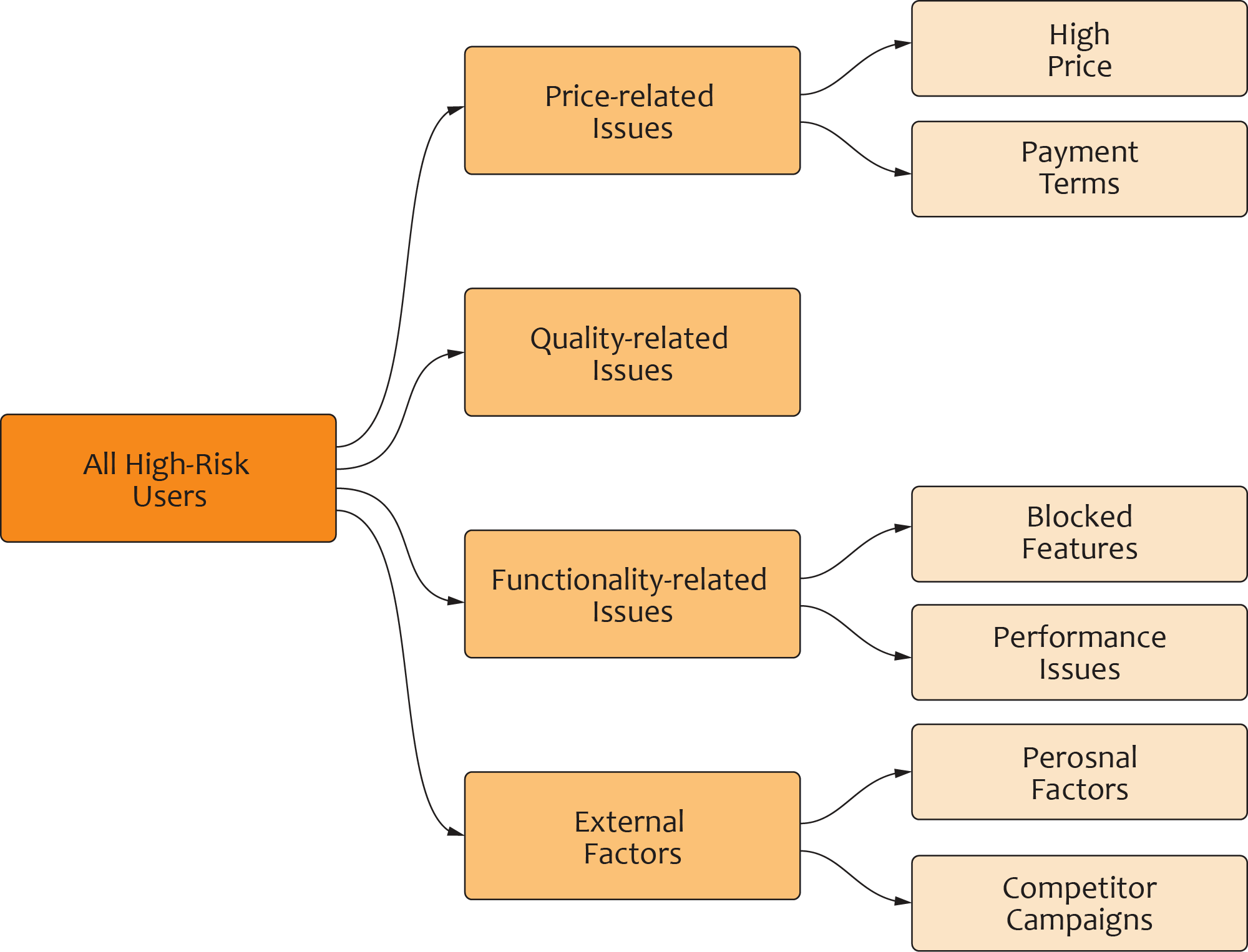
For personalized treatment, we can use this model to identify the exact churn driver for each customer and apply treatment at the account level. Comparing the two treatment approaches, personalized treatment can be more effective and can lower cost. However, it generally requires better modelling accuracy and granularity.
Event Model for Customer Journey Analysis
The event model helps to analyze customer journeys (i.e., sequences of interactions) and estimates the churn probability. We adopted the transformer model architecture of Vaswani et al. (2017), which is based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. This model has the following advantages over traditional LSTM:
- Transformer sees all words simultaneously. It was more efficient in training and inference.
- Transformer is less prone to the vanishing gradient problem.
- Transformer had better explanatory power because of its interpretable self-attention.
The limitation of the transformer model is that it can process only fixed-length sequences. In our case, we use padding zeros to ensure a fixed length.

We also use clustering to find typical interaction patterns that indicate churn. The process includes the following steps:
- First, we identify the most important and frequent events across the churn population. The total number of such event types is typically 100–1,000.
- Second, we compute the attention values associated with a predefined set of events for each sequence.
- Finally, we apply k-means clustering in the space of attention vectors to find users who have similar journeys and to analyze these clusters.
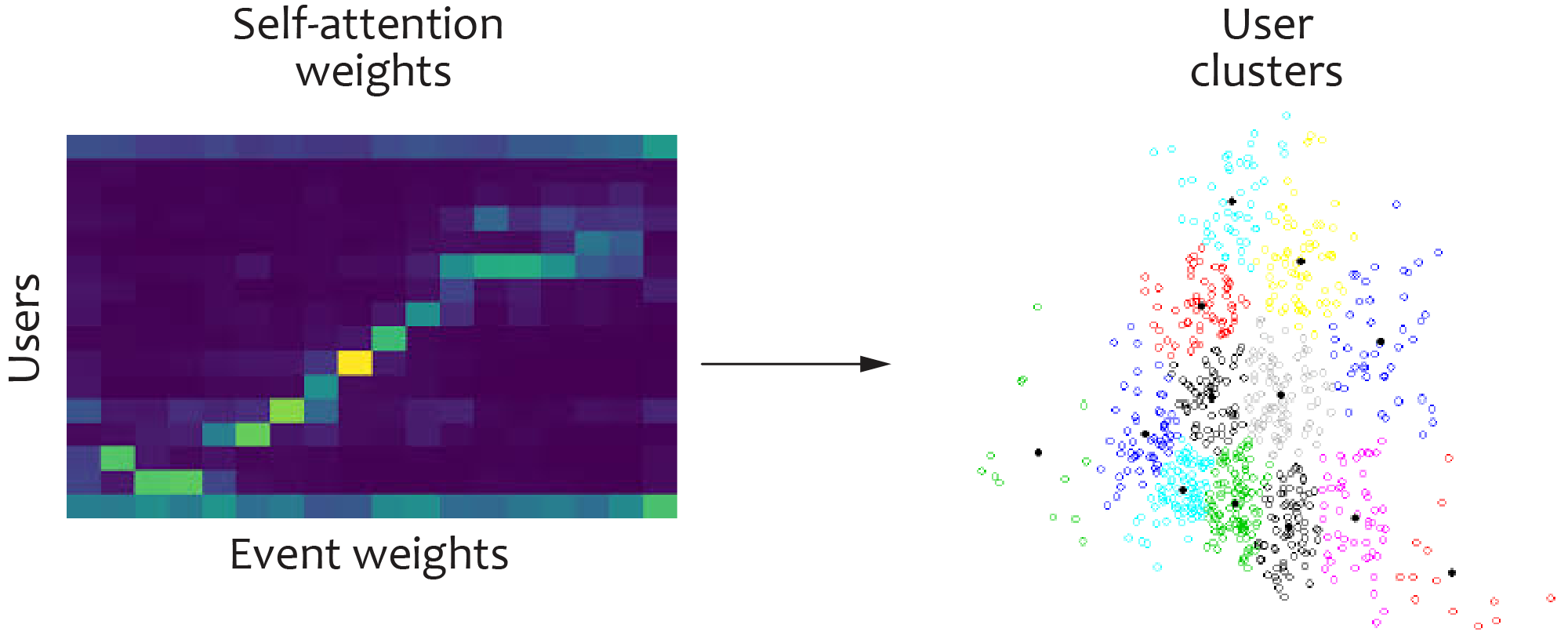
Clustering in the semantic space of attention weights provides useful insights into the behavior of churners and highlights typical patterns.
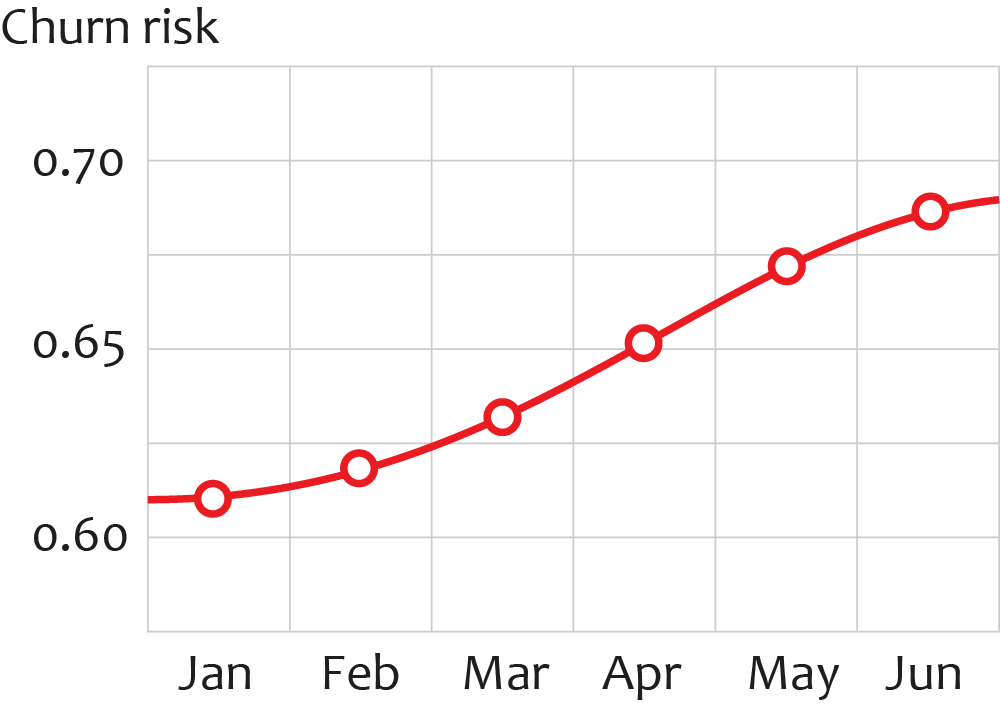
Survival Model for Risk Profiling
For the survival model, we experimented with several approaches and identified some limitations as described below:
- Cox Proportional Hazard. It is based on aggregated features, and thus it is difficult to make it recognize that features affect the churn risk differently at different time points. Also, its month-to-month predictive power drops significantly in long-term predictions.
- Accelerated Failure Time. It could model only how the features affected the mean of the time-to-event distribution, and it does not show features’ effects on probability of churn at individual time steps.
- Random Survival Forest. The deeper the trees, the smaller the significance of an individual tree’s estimation. In addition, this model is computationally expensive.
In most cases, the best model for our scenario is a binary classification model for each month using gradient-boosted decision trees. It is also common to observe that the outputs from the event model and sentiment model significantly improve the performance of the survival model when used as its input features. The output of the model is a risk profile that helps to determine the optimal treatment time.
Treatment Model for Action Prescription
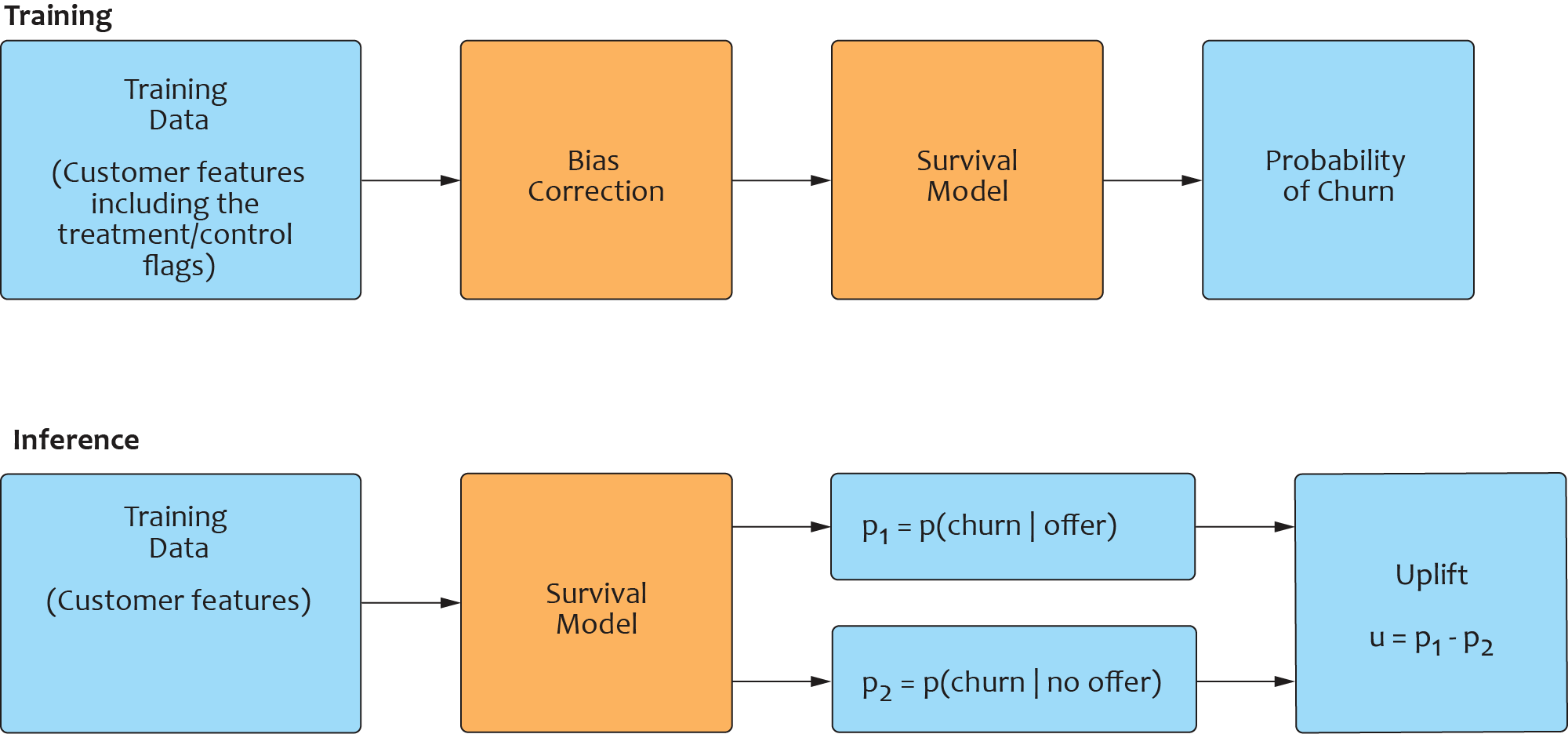
Finally, we adopted the uplift modeling approach with bias correction on sampling selection for treatment prescription. The main idea is to estimate the potential impact of treatments on churn, using the survival model described in the previous section. Using customer features and treatments, we perform the following steps:
- Train the survival model to predict churn for each group of treatments. It is usually not feasible to estimate the impact of every individual treatment (e.g., each specific offer), so we normally develop a treatment taxonomy and group similar treatments together.
- Predict the churn probability for each user-treatment combination.
- Automatically select the best treatment option after the model has outputted the treatment impact at the user level.
The biggest challenge, however, is often not the uplift estimation but the correction of the selection bias in the control and treatment groups used for model evaluation. The ideal way to obtain unbiased samples for the treatment model development is to conduct A/B tests for all treatments of interest. In practice, this approach is prohibitively expensive and time consuming, so one typically needs to deal with biased data obtained under a legacy treatment-assignment policy. In this case, we need to use statistical methods, such as propensity score matching (PSM) or the Heckman correction, to perform bias correction.
Bias correction is applied at the training stage before input is fed into the survival model. At the inference stage, we use the risk estimates to calculate the uplift value for each user and rank the offers for individual users based on the uplift value. The complete process is shown in the figure below.
Model Validation
The churn prevention suite described above is a complex solution, and it is critically important to have a solid validation methodology to ensure its quality and performance. The model validation is normally done based on the model stability, prediction accuracy, and meaningfulness of the interpretation results. The reference validation workflow includes the following steps:
- Sentiment Model. First, we check the coverage—negative snippets should be extracted from a sufficient fraction of the text samples. It is typically about 30%–40% of all samples after cleansing and denoising. Second, we check user groups with labelled churn triggers to make sure they have a significantly higher churn rate (usually a 25%–200% churn rate increase) than the full population. Last, we validate the churn labels by reviewing relevant paragraphs/negative snippets from the call transcripts.
- Event Model. First, we check the prediction accuracy of the model. The ensemble solution described above usually provides a 5%–10% higher lift score than traditional models, such as propensity scoring. Second, we check that the churn indicators show positive correlation with churn. Finally, we check that the model covers the total churn population reasonably well; we set a meaningful churn probability threshold (e.g., five times greater than the average churn rate) and ensure that a reasonably high percentage of such users is identified by the model (at least 15%).
- Survival Model. We validate that the model achieves high performance for a six-month prediction, and the inclusion of features from the sentiment and event model results improves the result.
- Treatment Model. We use several validation approaches, such as: (1) checking the lift of the churn prediction; (2) estimating the uplift accuracy at the group level by comparing observed and estimated uplift; (3) analyzing the uplift trend in deciles; and (4) comparing the average uplift between real offers and model-suggested offers.
Operationalization
The churn prevention solution helps to identify and improve upon areas where customer service was lacking. It also helps to improve the efficiency of various analytics and treatment processes, including the following:
- Systematic Treatment. Using the churn triggers and clustering outputs, business users are able to identify high-risk user groups and apply treatment at the group level.
- Personalized Treatment. Using the churn trigger output at the user level, business users are able to identify high-risk individuals and take personalized actions.
- Customer Lifetime Value (CLTV). Using churn prediction, business users are able to calculate the LTV of users and make better decisions.
- Offer Recommendations. Using offer recommendation outputs, business users are able to pick the best offer at the user level and see the churn impact between offers.
Results
The solution described in this article offers a prescriptive framework that aims to answer the four “W”s (who, when, why, what) of customer churn. The sentiment and event models offer an explanatory modelling framework on churn activities, helping business users to understand churn reasons. The survival model offers a long-term (six-month and more) churn prediction, helping business users to plan retention strategies in advance of churn events. The treatment model picks the best offers, which enables a higher level of automation.
Useful References on Churn Modeling
- Konstantin Vorontsov and Anna Potapenko. Tutorial on Probabilistic Topic Modelling: Additive Regularization for Stochastic Matrix Factorization, 2014.
- Konstantin Vorontsov et al. Big ARTM: Open Source Library for Regularized Multimodal Topic Modeling of Large Collections, 2015.
- Murat Apishev et al. Mining Ethnic Content Online with Additively Regularized Topic Models, 2016.
- Ashish Vaswani et al. Attention Is All You Need, 2017.
- Blaz Skrlj et al. Feature Importance Estimation with Self-Attention Networks, 2020.
- Denis Larocque and Hatem Ben-Ameur. A Review of Survival Trees, 2011.
- Ping Wang, Yan Li, and Chandan K. Reddy. Machine Learning for Survival Analysis: A Survey, 2019.
- Zhenyu Zhao and Totte Harinen. Uplift Modelling for Multiple Treatments with Cost Optimization, 2020.
- Robin M. Gubela et al. Conversion Uplift in E-Commerce: A Systematic Benchmark of Modeling Strategies, 2019.
- Piotr Rzepakowski and Szymon Jaroszewicz. Decision Trees for Uplift Modeling with Single and Multiple Treatments, 2011.
- Peter C. Austin. The Use of Propensity Score Methods with Survival or Time-to-Event Outcomes: Reporting Measures of Effect Similar to Those Used in Randomized Experiments, 2014.
- Hanas A. Cader and John C. Leatherman. Small Business Survival and Sample Selection Bias, 2011.
- Rui Xu. Survey of Clustering Algorithms, 2005.
- Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. “Why Should I Trust You?” Explaining the Predictions of Any Classifier, 2016.
- Wouter Verbeke et al. New Insights into Churn Prediction in the Telecommunication Sector: A Profit Driven Data Mining Approach, 2012.