


Every business is focused on a rapid time to market and return on investment. It’s no longer enough to implement a data lake, businesses require a data platform that can provide immediately actionable insights. But building a data platform from the ground up can take a significant amount of time so Grid Dynamics has developed a Starter Kit to help companies achieve this far more quickly. This article provides a step by step guide on how to run the Starter Kit on AWS from scratch.
The Starter Kit comes as an AWS Marketplace solution or application in AWS Service Catalog
It provides six capabilities or use cases that can be deployed on top of AWS and each capability can be provisioned separately. As they are re-using the same infrastructure, if EMR is already provisioned by one of them, it doesn’t need to be provisioned again.
The potential use cases are outlined below:
- Data lake - is built on top of S3 with data catalog and data lineage available in Apache Atlas.
- Enterprise data warehouse - use case runs on top of Redshift.
- Batch analytics - use case covers typical batch processing and analytics using data lake, EDW, and jobs running on top of EMR and orchestrated by Apache Airflow.
- Stream analytics - covers the stream processing and stream analytics use cases and examples with Amazon Kinesis, Apache Spark, and pipeline orchestration with Apache Airflow.
- Data governance - provides tools for data catalog, data glossary, data lineage, data monitoring, and data quality. The data catalog, glossary, and lineage are implemented with Apache Atlas. Data monitoring and quality capabilities are implemented with the Grid Dynamics Starter Kit based on ElasticSearch, Grafana, k8s, and a number of custom applications.
- CI/CD - the platform is deployed from scratch by CloudFormation scripts and custom lambdas.
- Anomaly detection - for more information about the anomaly detection architecture and technology stack, refer to a separate article on how to add anomaly detection to your data pipelines.
- AI/ML use cases - we included two AI use cases in the Starter Kit to demonstrate end-to-end functionality. All use cases are implemented with Amazon Sagemaker and Jupyter Notebooks and use the data we prepared in the data lake and EDW. One of the use cases contains a model to detect attributes in an e-commerce product catalog, while the second implements price optimization and promotion planning. We kept the use case implementations simple for the purposes of the demo.
If you’re interested in production implementation of these use cases, please read articles about product attribution with image recognition and price and promotion optimization or reach out to us.
The data platform enables DataOps practices and is ready to integrate with external data sources. The high-level architecture of the platform is outlined in the diagram below:
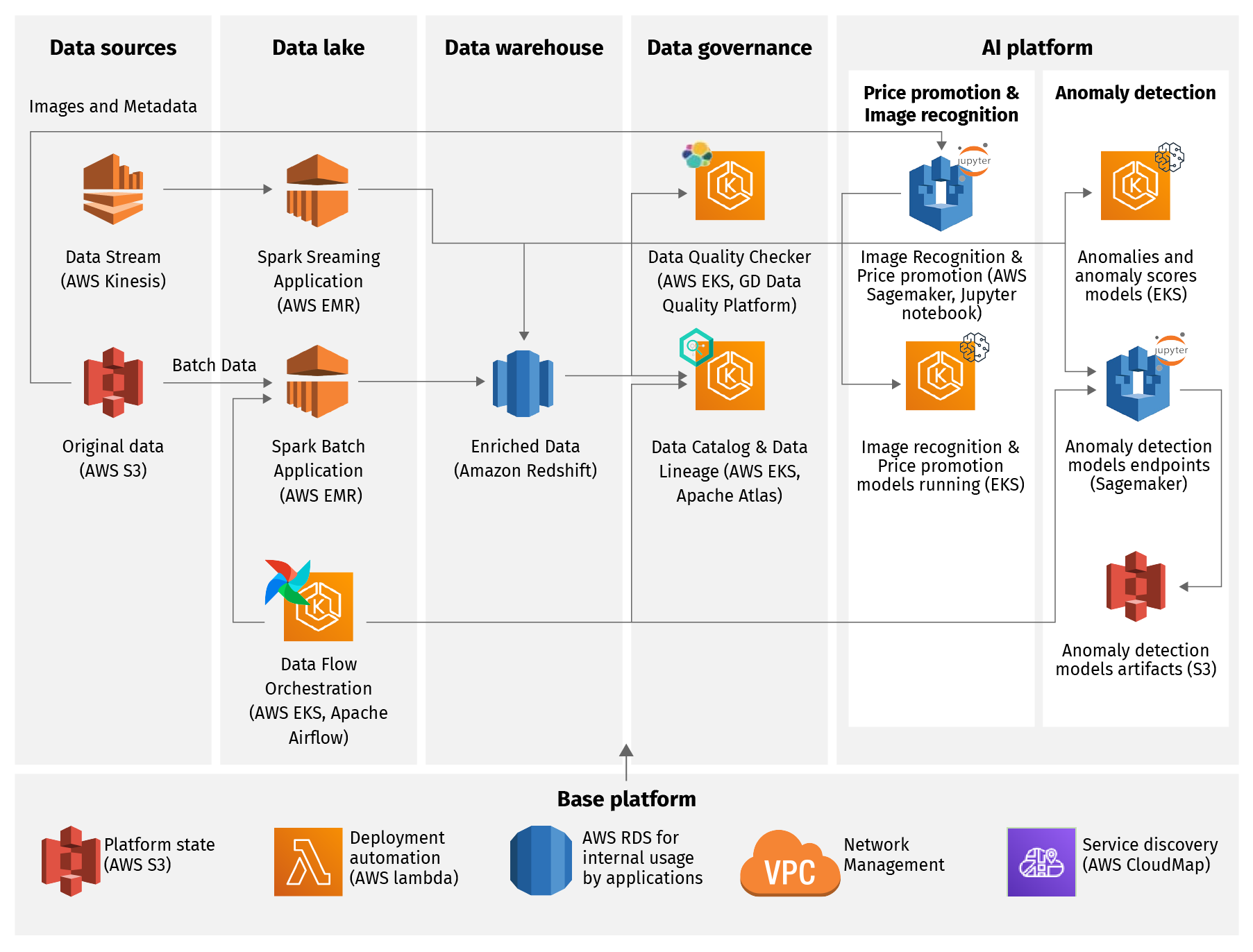
Below we will cover all the platform’s capabilities in more detail but before jumping into describing them, it’s worth mentioning that the platform is distributed as either an AWS Marketplace or Service Catalog application. The difference between Marketplace and Service Catalog is that while Marketplace applications are publicly available, Service Catalog solutions are private and can be shared with other organizations.
This article will essentially be about installation from AWS Marketplace to AWS Service Catalog. As of now there is no easy way to install Marketplace container based products directly into Service Catalog (for AMI-based there is single click functionality) so as a prerequisite, detailed instruction will be provided on how to install products to Service Catalog.
Prerequisites
In AWS Marketplace, the following list of solutions are available:
- Base platform
- Batch capability
- Streaming capability
- ML capability: Visual attributes
- ML capability: Promotion planning
All products can be added to AWS Service Catalog, instruction with screenshots is below:
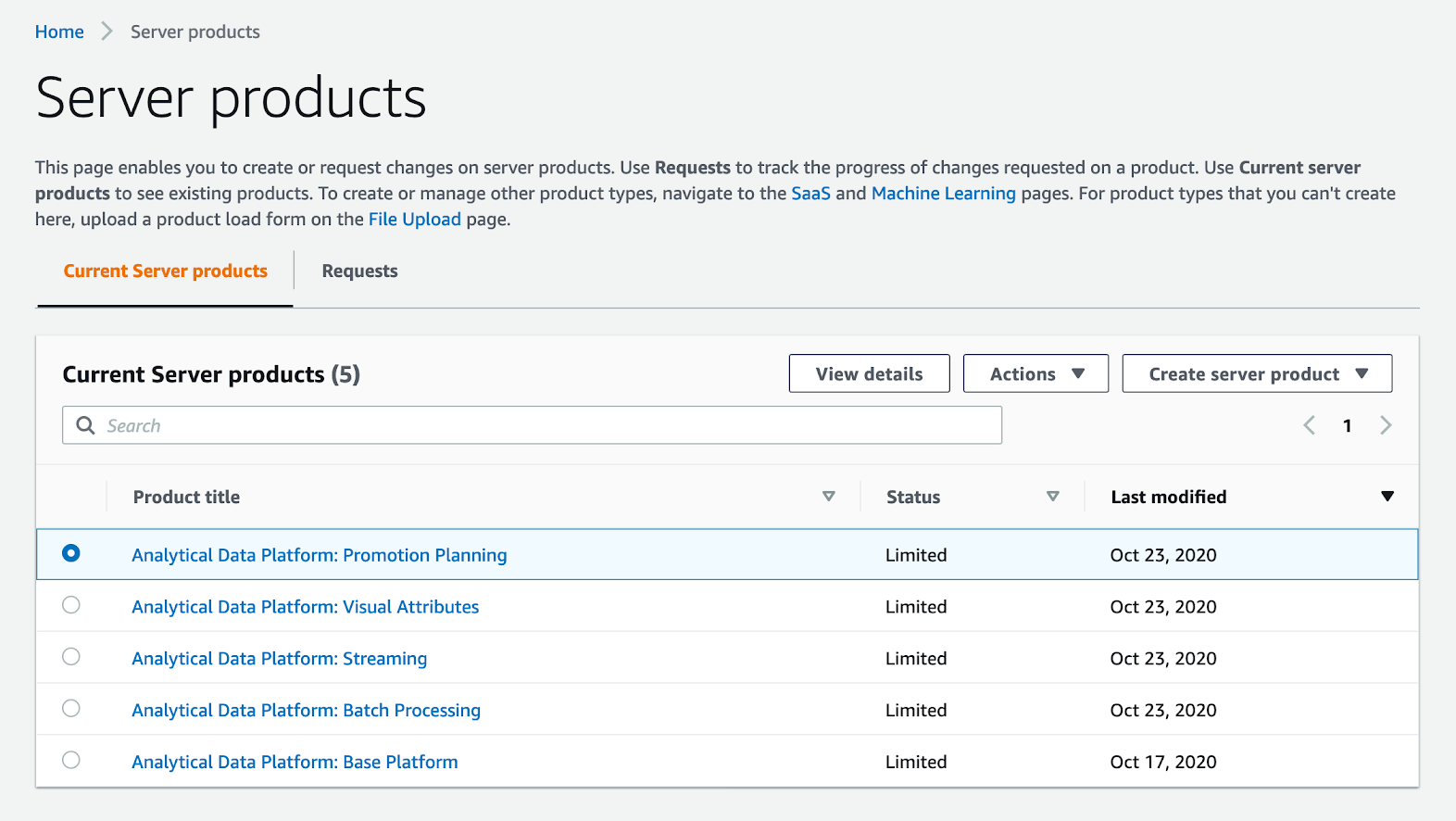
Each solution on the installation page provides a link to the S3 bucket where all CloudFormation scripts reside. All these products should be installed to Service Catalog in any order one by one:
1. Take the S3 URL to CloudFormation scripts;
2. Go to AWS Service Catalog;
3. On the left panel in the Administration section click on Products:
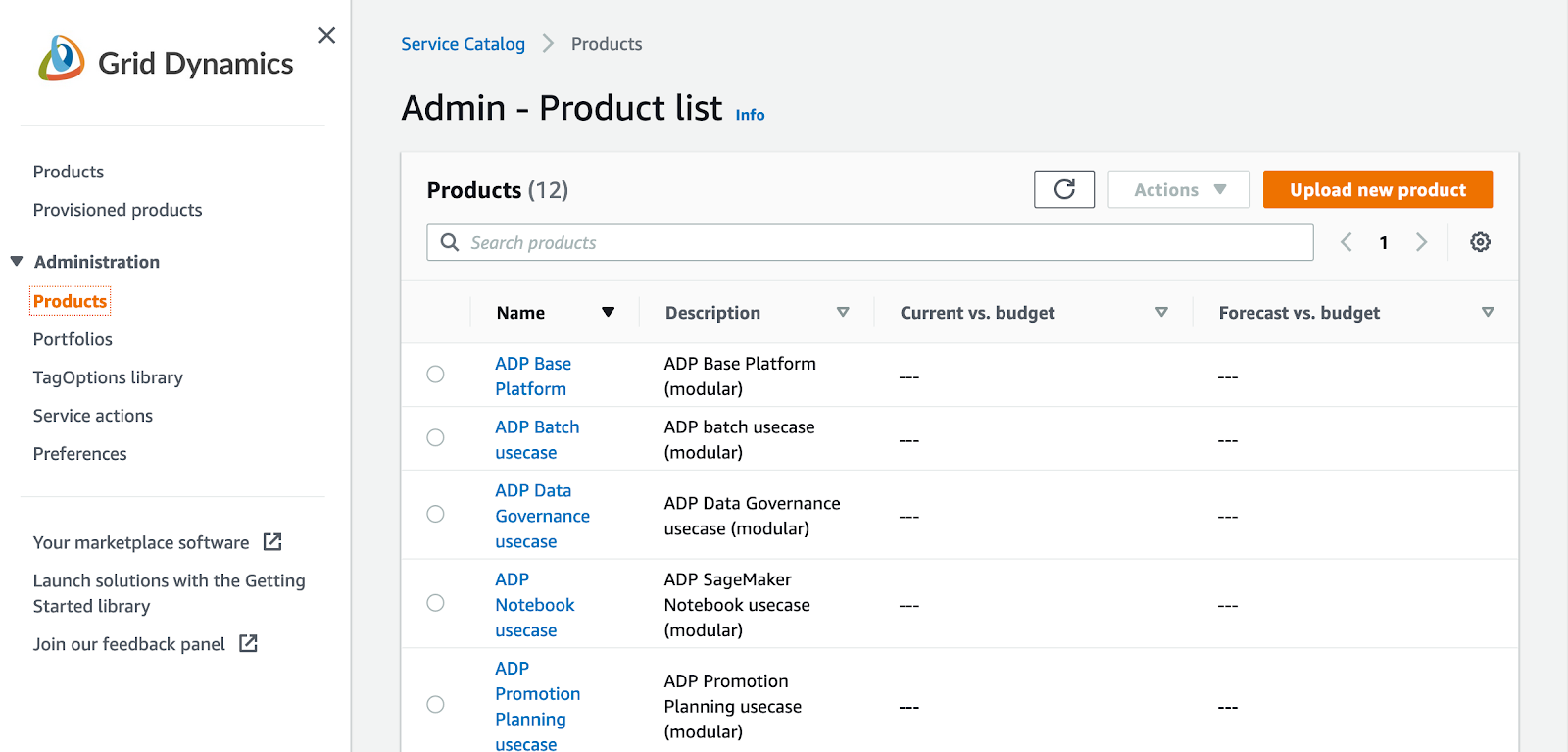
4. On the right side click to Upload new products:
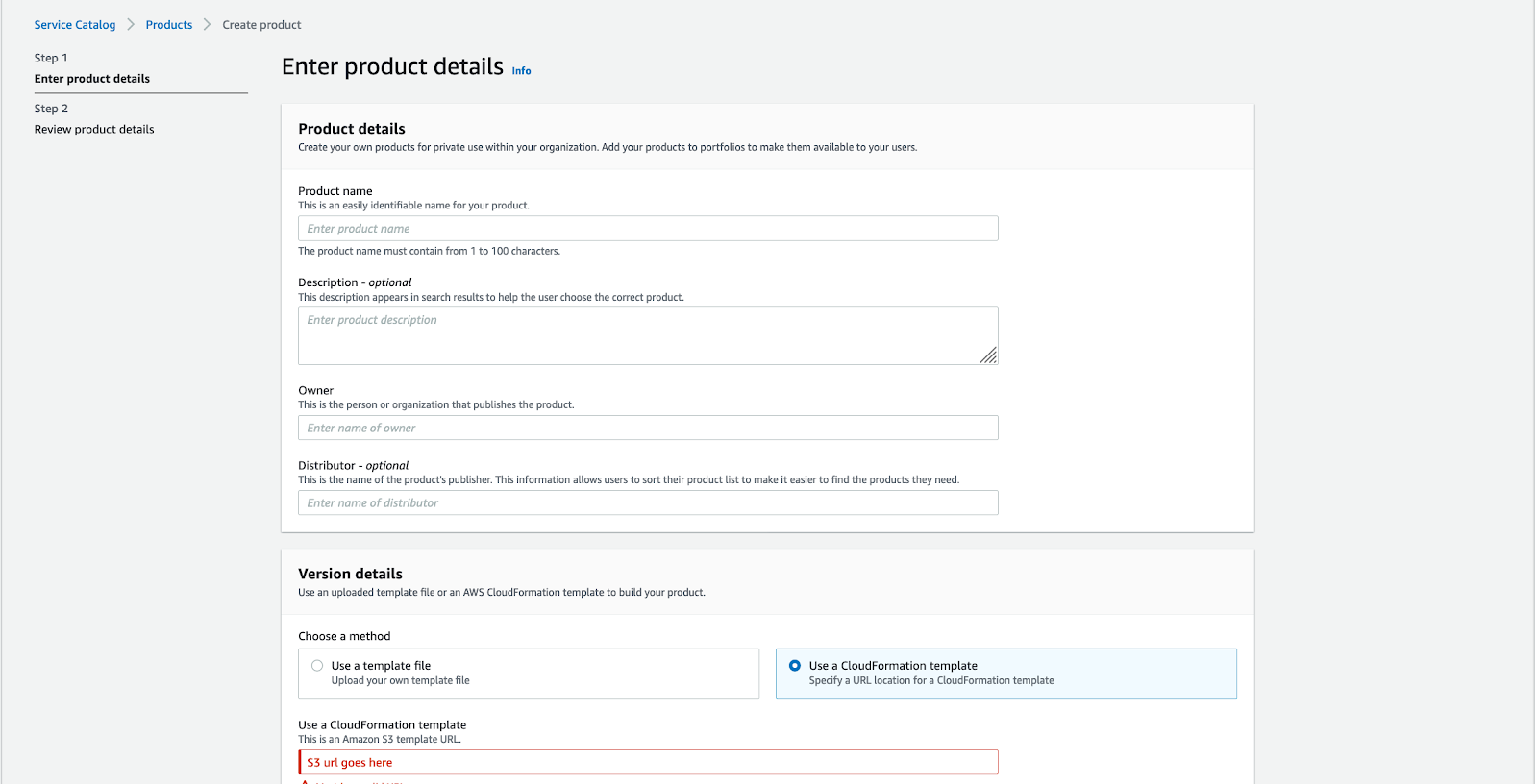
5. Enter the product name and paste the S3 URL from Marketplace;
6. You’re done, the product is now created.
Once a product is created, it should be added to a portfolio. All permissions for a product will be managed by portfolio. To create a portfolio just click on the Portfolio link on the left panel and create a new one of re-use existing. Product listing in portfolio will look like on image below:
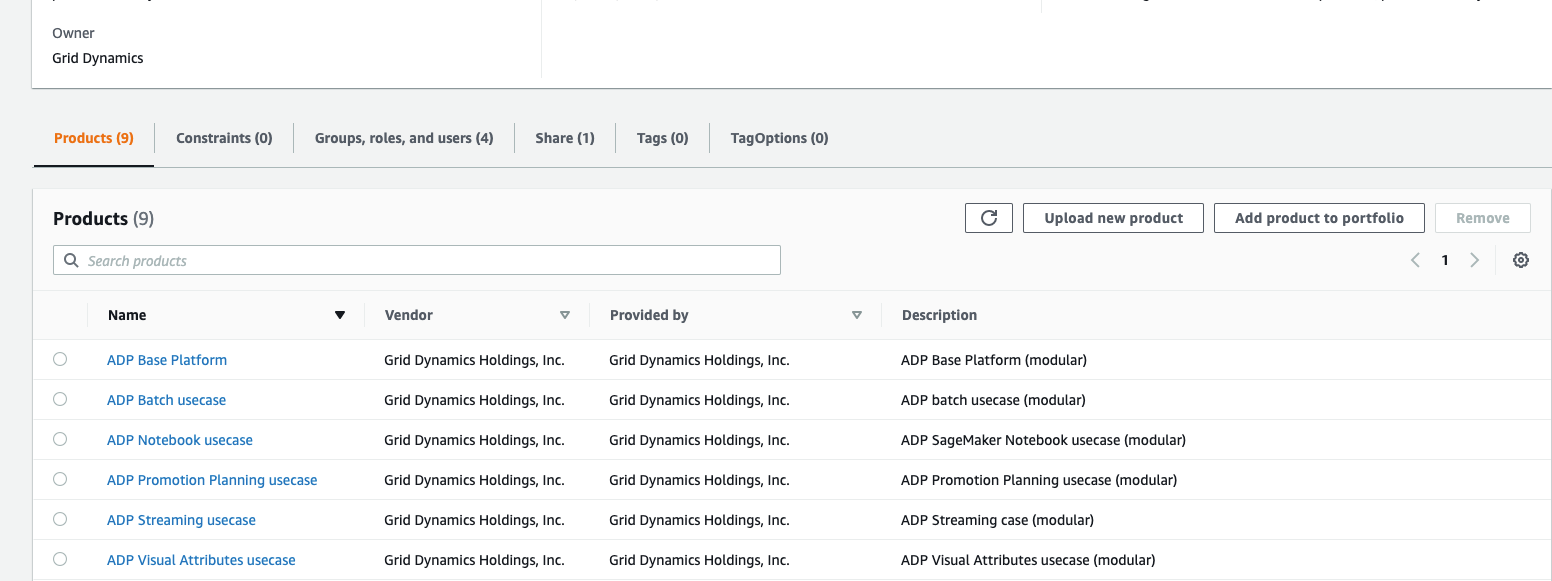
You’re done, now the final step will be to create permissions and assign to the created portfolio. There are two ways:
- Attach a group, like engineering group
- Or specific, not a root user
On the image below engineering group is attached:
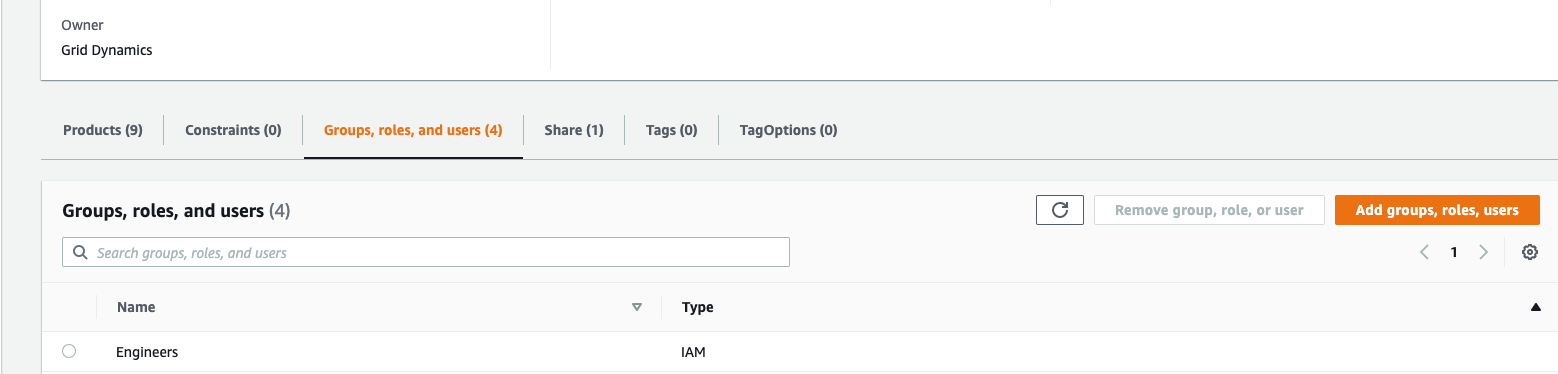
If there are no specific groups created, follow security configuration steps below:
Security configuration
- Create Engineer Policy with access to ServiceCatalog and IAM actions accessPermission policy for Engineer Group might looks like below, can be adjusted if needed:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"iam:List*",
"iam:Get*",
"iam:CreateRole",
"iam:DeleteRole",
"iam:PassRole",
"iam:CreatePolicy",
"iam:DeletePolicy",
"iam:AttachRolePolicy",
"iam:DetachRolePolicy",
"iam:DeleteRolePolicy",
"iam:PutRolePolicy",
"iam:*AccessKey*",
"iam:*SigningCertificate*",
"iam:UploadSSHPublicKey",
"iam:CreateInstanceProfile",
"iam:DeleteInstanceProfile",
"iam:AddRoleToInstanceProfile",
"iam:RemoveRoleFromInstanceProfile",
"iam:*ServiceLinkedRole",
"iam:ChangePassword",
"aws-portal:ViewBilling",
"aws-portal:ViewUsage",
"iam:CreateGroup",
"iam:DeleteGroup",
"iam:ListGroupPolicies",
"iam:UpdateGroup",
"iam:GetGroup",
"iam:RemoveUserFromGroup",
"iam:AddUserToGroup",
"iam:ListGroupsForUser",
"iam:AttachGroupPolicy",
"iam:DetachGroupPolicy",
"iam:ListAttachedGroupPolicies",
"iam:GetUserPolicy",
"iam:ListGroupsForUser",
"iam:GetGroupPolicy",
"iam:DeleteGroupPolicy",
"iam:SimulateCustomPolicy",
"iam:ListGroups",
"iam:PutGroupPolicy"
],
"Resource": "*"
},
{
"Effect": "Allow",
"NotAction": [
"iam:*",
"aws-portal:*"
],
"Resource": "*"
}
]
}
2. Create an engineer group and attach new policy to the group.
3. Create new user (engineer) for ServiceCatalog and CFN usage (do not use root user!).
4. Add a new user to engineer group.
5. Create a key pair for capability for SSH access to bastion VM.
6. Login in AWS under created user.
Warning:
The deployment template will create IAM roles that has the ability to create additional IAM roles that may or may not include administrator permissions to the customer account where it is deployed.
All further actions will be done in Service Catalog in AWS console
All security configurations are done, you can proceed to run the platform with service catalog applications looking like on the image:
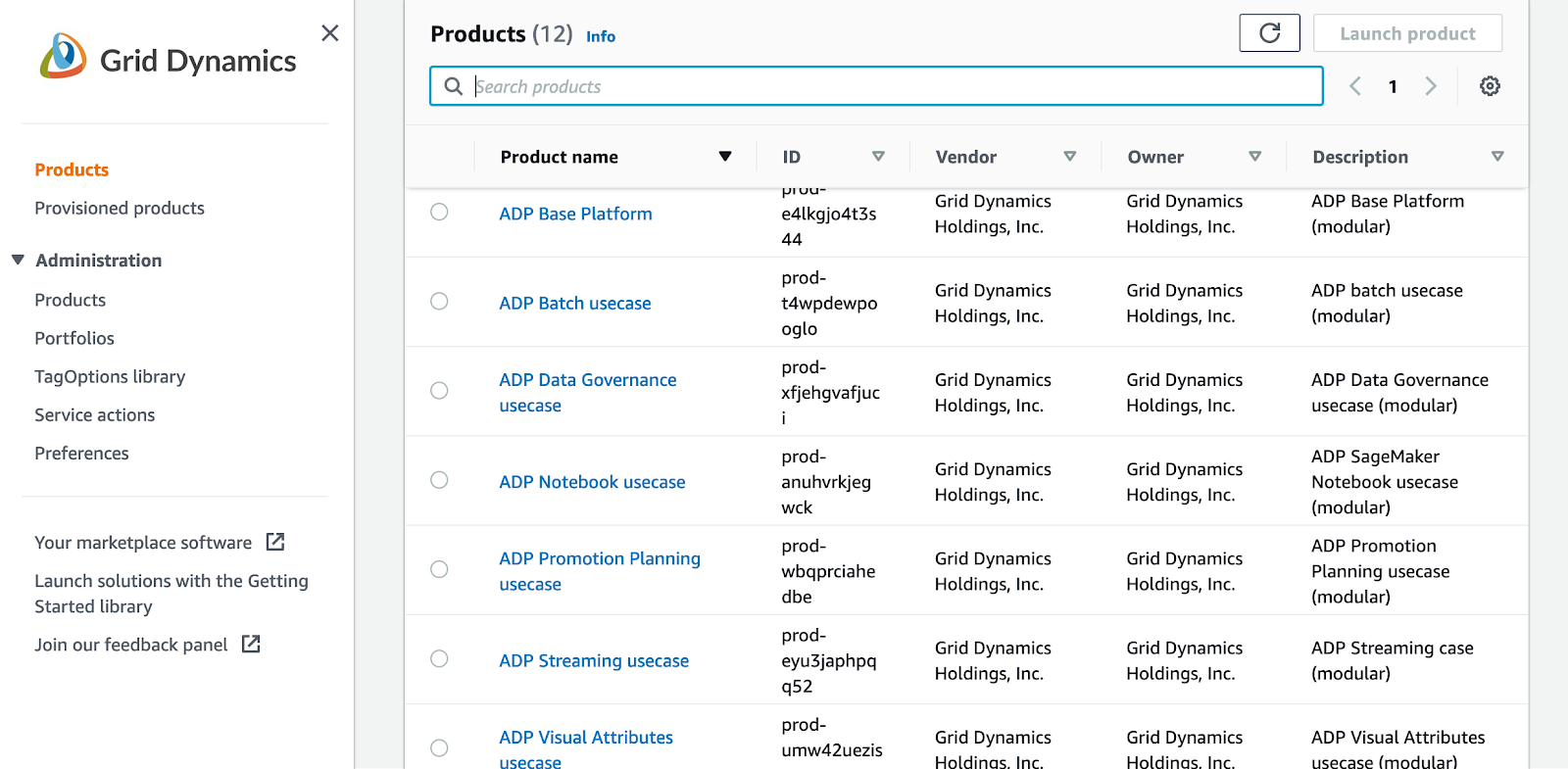
How to access platform web services?
There are several ways how to access any web service which is running in private AWS network:
- Share the same VPN network with common DNS
- AWS Private link
- Access AWS services through SSH tunneling - AWS manual
Platform has capability to expose all private web applications to a public network, but it was designed and used only for demo purpose, we highly recommend to keep all services in a private network.
Base platform
The Analytics Platform has a base platform responsible for provisioning networks, S3 buckets with CloudFormation code and Lambdas, and a common state, which is used to share common services like EMR or EKS between use cases. Once the base platform is in place any capability can be deployed in any order.
To launch the base platform, four parameters should be defined:
- Resource prefix
- SSH keys to use
- Remote access CIDR
- Availability zones - at least three should be chosen
EKS requires at least three availability zones to be present in the AWS region, so before deploying the data platform please ensure that constraint is met. Further information regarding availability zones can be found on the AWS status page.
In the example below, the resource prefix is adp-base-platform, ssh key pair is test, remote access CIDR is allowing all IP addresses, and there are three availability zones defined:
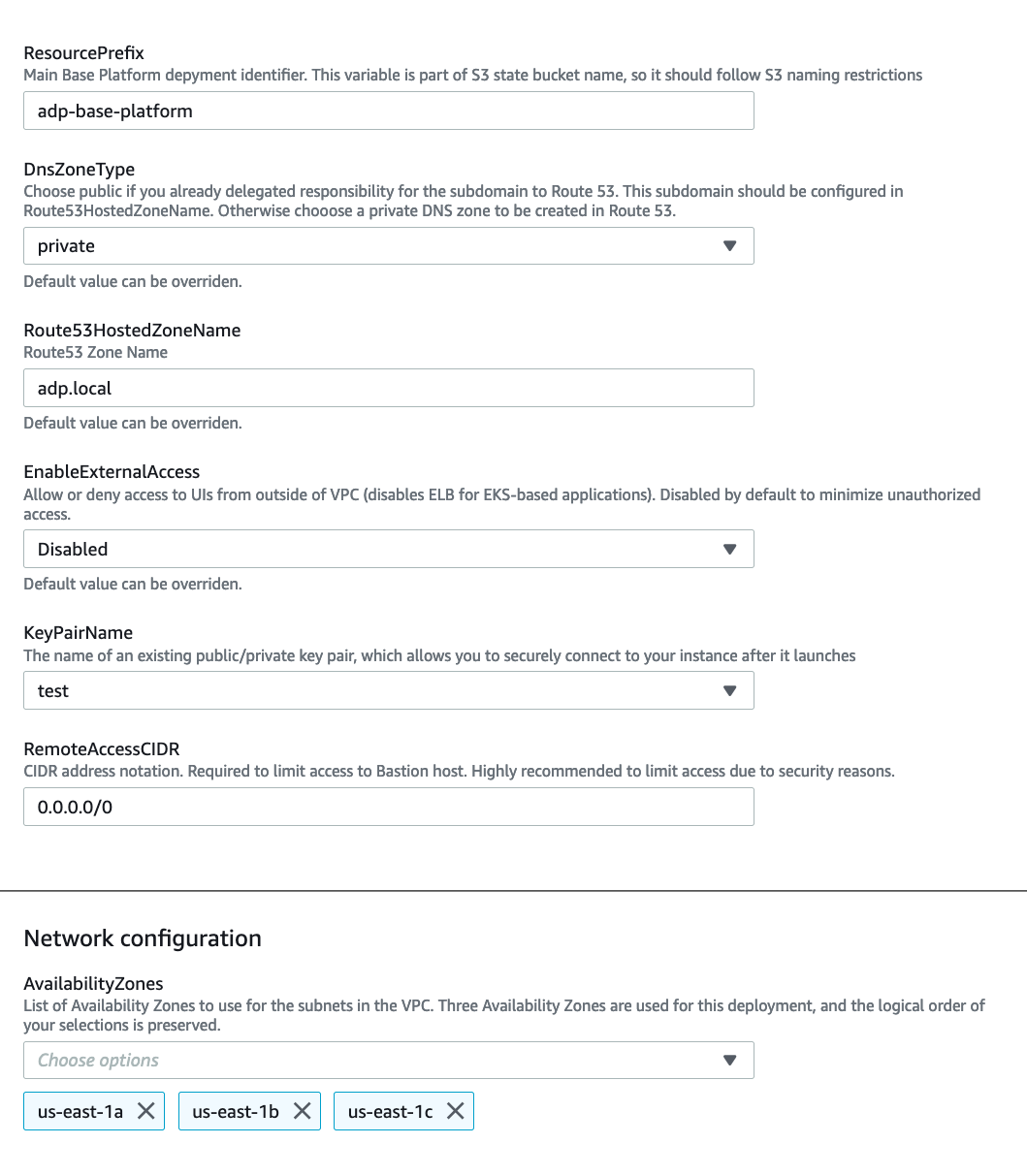
The four parameters above are enough to run the platform from scratch in any AWS account. All other parameters used in the platform can be left as is. Once the base platform starts provisioning in CloudFormation, all steps will be in progress and on completion it will look like:
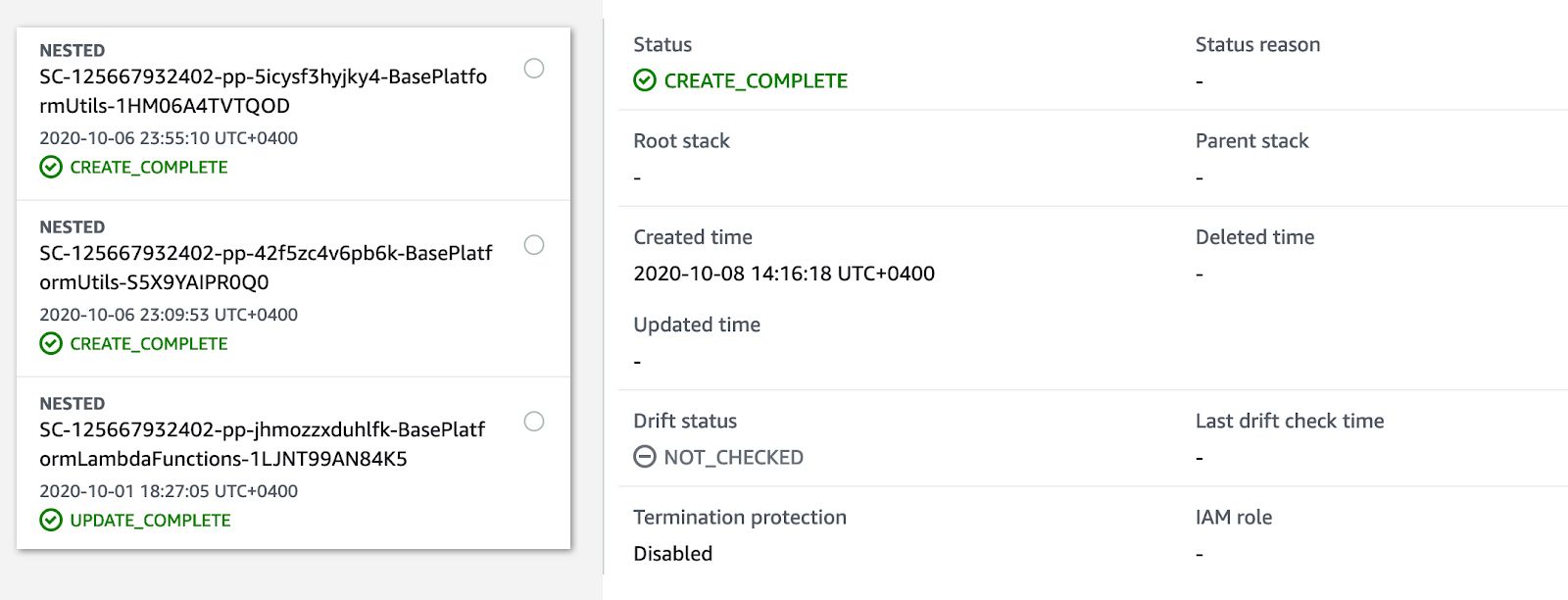
Once the base platform is up and running, any capability can be deployed on top.
Notice:
Many of our clients have base platform failing at the very beginning due to the VPC limit in AWS. Please ensure there is at least one VPC network could be created before running the base platform.
Batch analytics
Batch analytics provisions the following components: EMR for batch analytics, Apache Airflow to orchestrate the jobs, and data lake on top of S3. Batch capability can be provisioned on top of the base platform without needing to define any parameters:

BatchInputPath and ItemPropertiesInputPath are used in demo code that is running on top of the platform. Once the batch use case is up and running, demo Spark jobs can be run from the Apache Airflow UI. A link to the Apache Airflow UI will be available in CloudFormation in the deployed stack details:
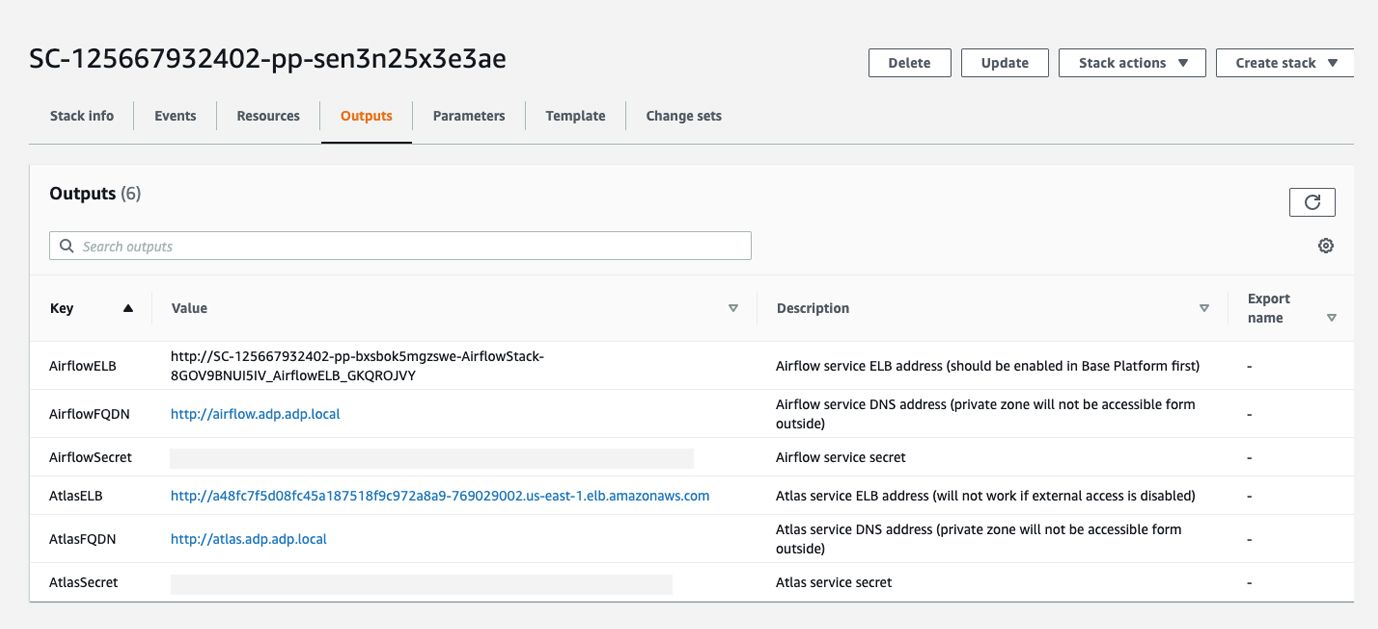
In the image above there are two Airflow URLs: one is active inside the VPN network, the other (AirflowELB) is active only if it’s enabled in batch or streaming capability. EnableExternalAccess is where it can be enabled:

We don’t recommend exposing to the public network the services, it could be used for a demo purpose for a limited time period.
Once the batch capability is up and running you can open Apache Airflow UI or EMR and check flows running. There are several batch and streaming jobs which are deployed along with capability:
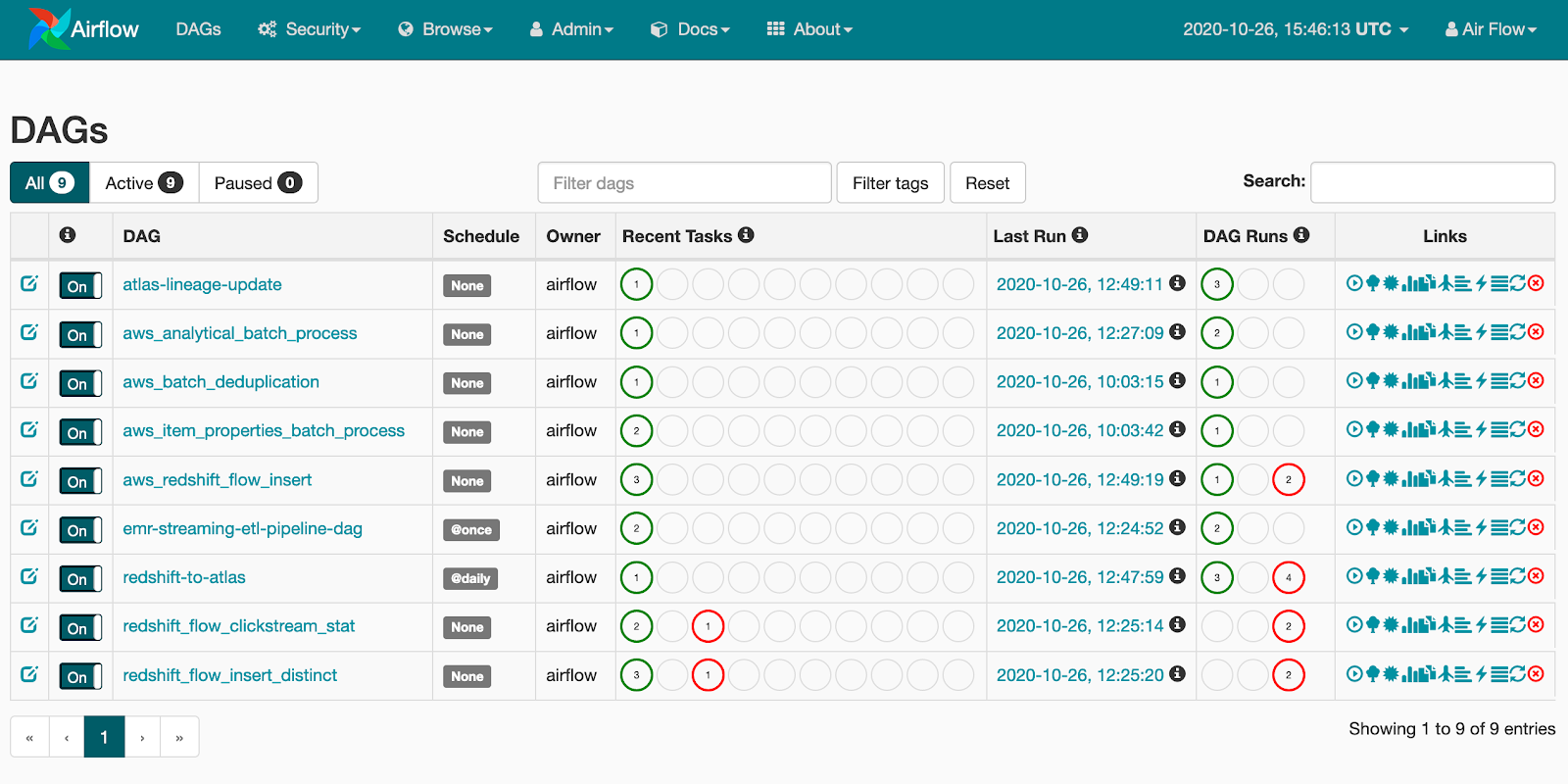
Streaming analytics
The streaming analytics capability targets real time scenarios including real time analytics and streaming fraud detection. For the streaming analytics capability EMR, Kinesis, Apache Airflow, and S3 are provisioned. There are also streaming jobs that are orchestrated by Apache Airflow and can be used for example or demo purposes. The use case can be provisioned with zero parameters specified:
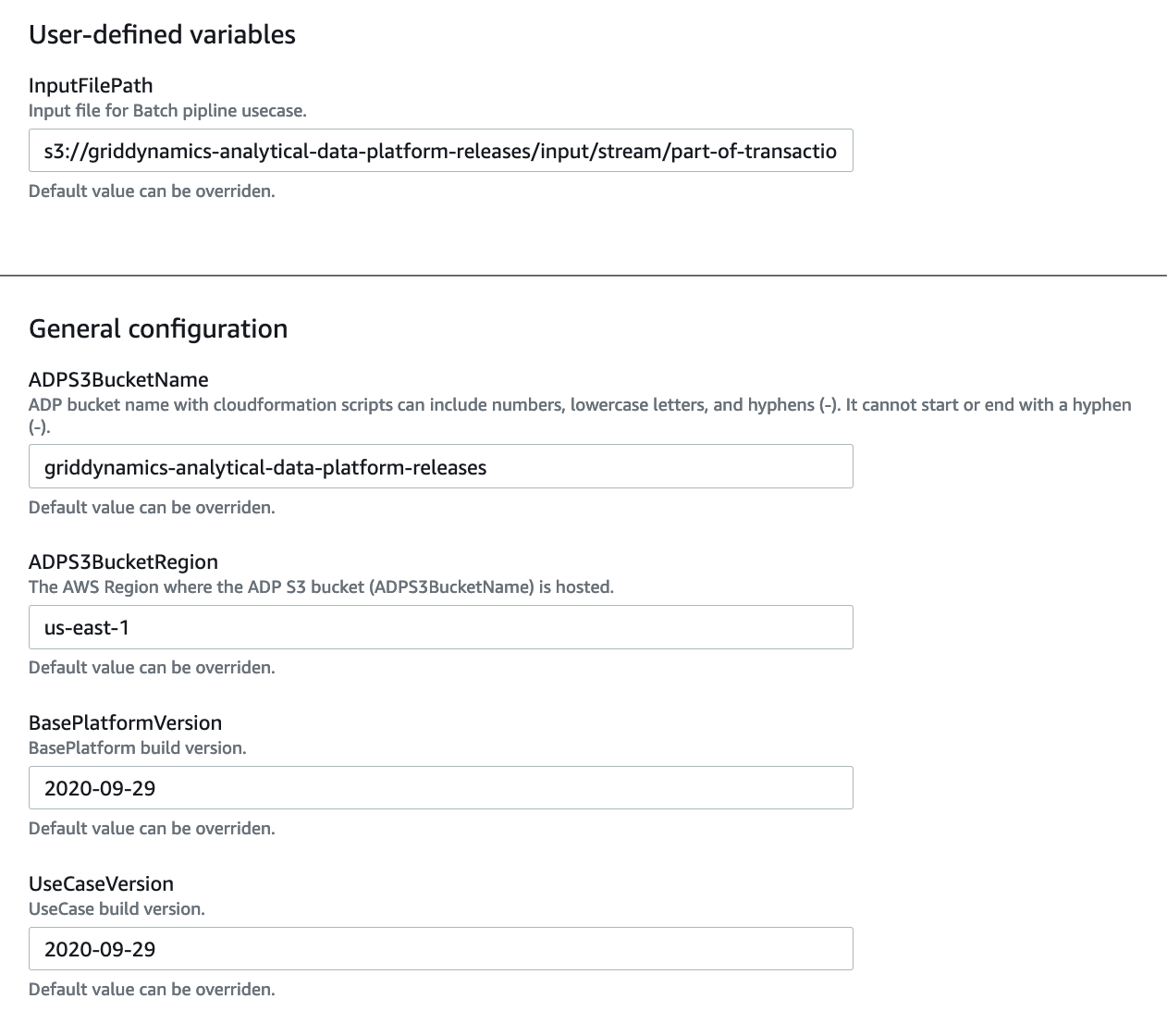
InputFilePath is used for demo applications and is available with the use case. The rest of the configurations are system ones and should be left unchanged. In addition to this, infrastructure applications are also deployed. There are several Spark batch and streaming applications along with Airflow DAGs deployed for orchestration purposes.
Enterprise data warehouse
The analytics platform leverages Redshift as an enterprise data warehouse solution. The platform doesn’t provide a dedicated capability to deploy Redshift as an independent capability - it comes with batch, streaming, or ML use cases. Typically data platforms start with data lake and batch or streaming processing before moving onto EDW. In cases where EDW needs to be deployed without batch, streaming, or ML use cases, it can be deployed directly by enabling it in the base platform:
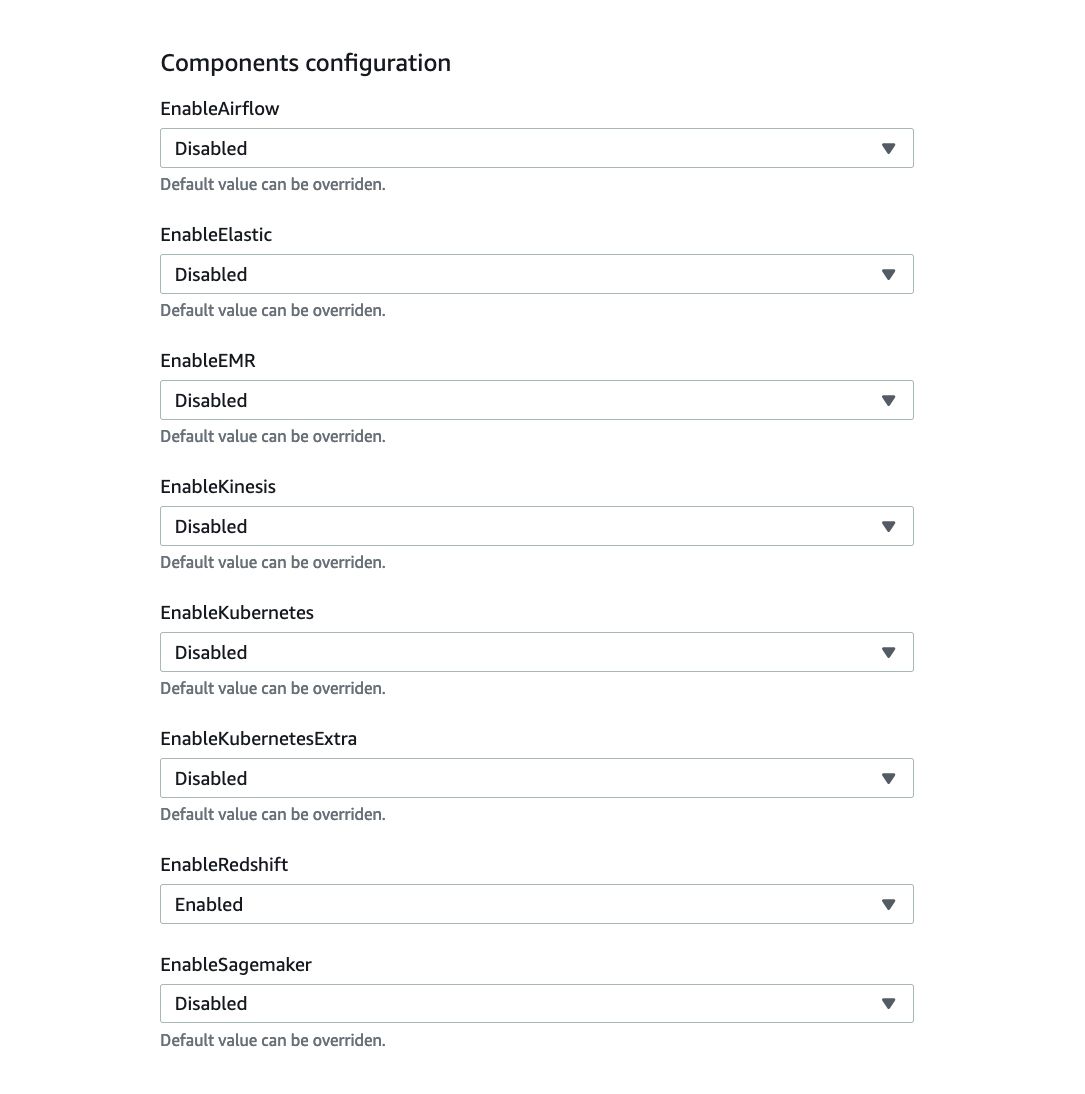
All other services are disabled and will be deployed by use cases directly.
Data governance
One of the key features of the analytics platform is data governance integration. The platform provides tooling to setup data governance in a process similar to CI/CD:
- Apache Airflow is used for workflow orchestration
- Apache Atlas is used for data catalog and data lineage
- Data quality is a custom Grid Dynamics solution
Apache Atlas builds the data catalog over all data in S3 and Redshift. Integration of Atlas and Airflow brings lineage information about all flows - Atlas provides information about what source datasets are used in the final dataset. Integration is done as a custom plugin for Airflow, which sends lineage information to Atlas where it’s visualized:
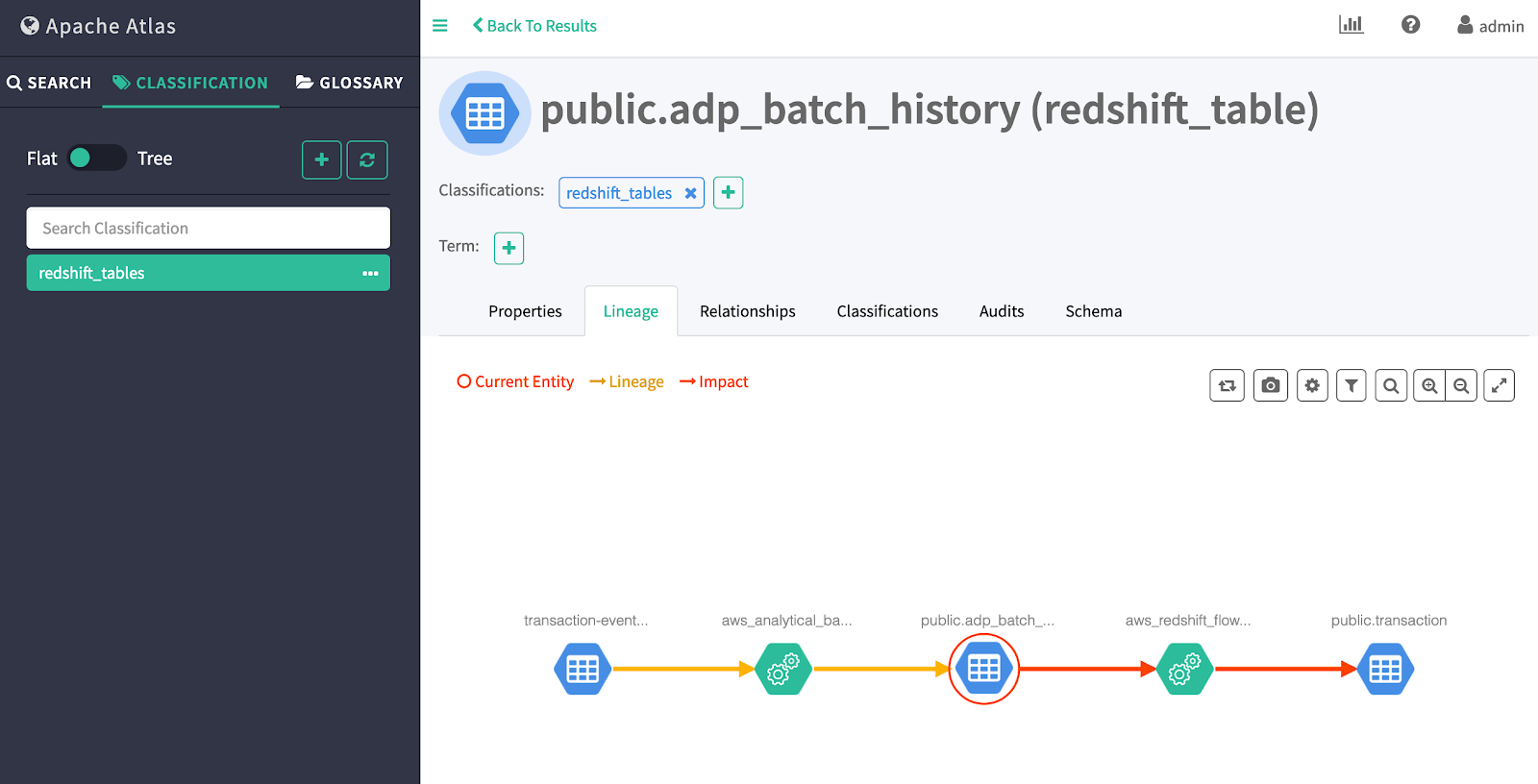
Data quality is provided by Grid Dynamics’ custom solution, which helps to:
- Run data monitoring checks
- Identify anomalies in the data
- Run complex data quality rules
- Check data in various data sources like S3, Redshift, Snowflake, Teradata, and others
- Build dashboards on top of data checks
- Send alerts
Data quality dashboard:
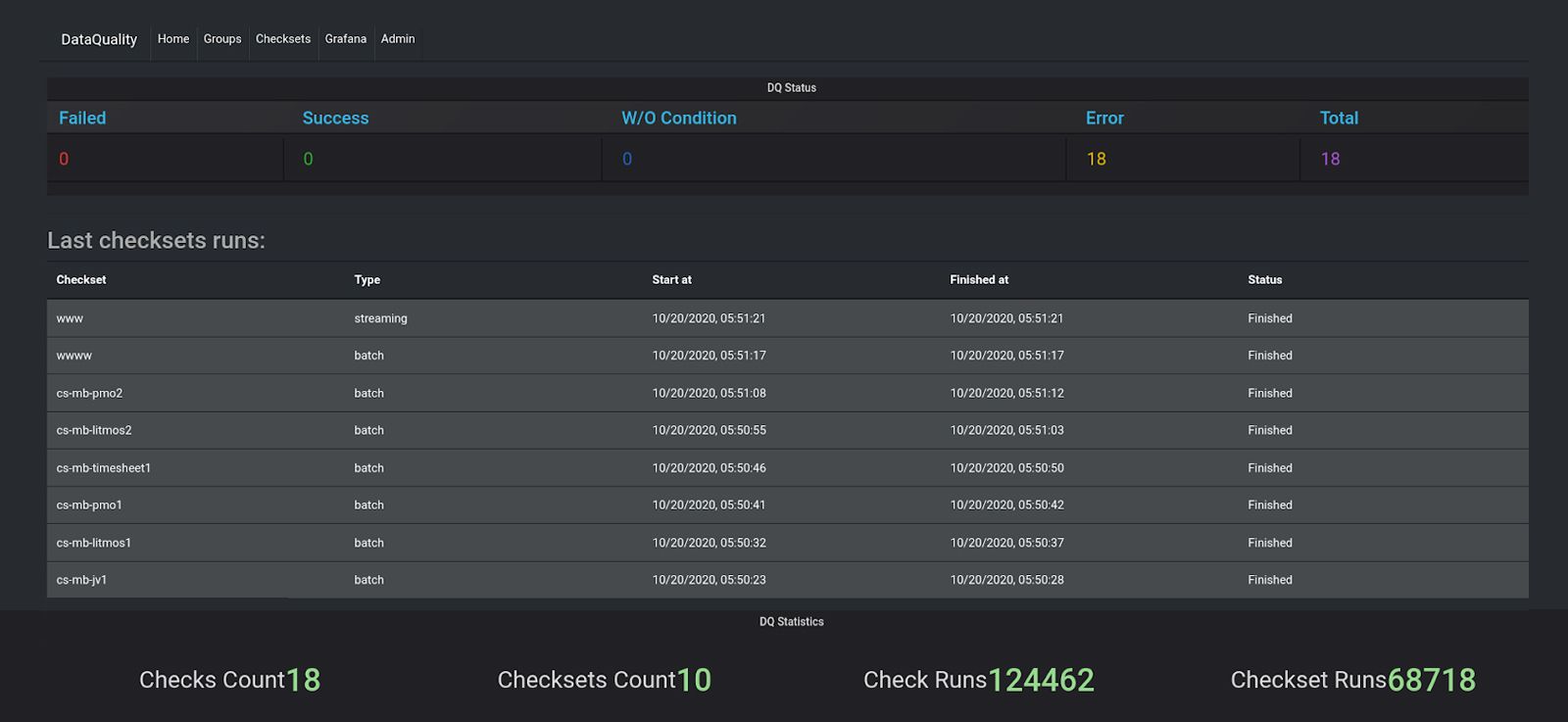
Data governance provisioning is similar to the use cases detailed above.
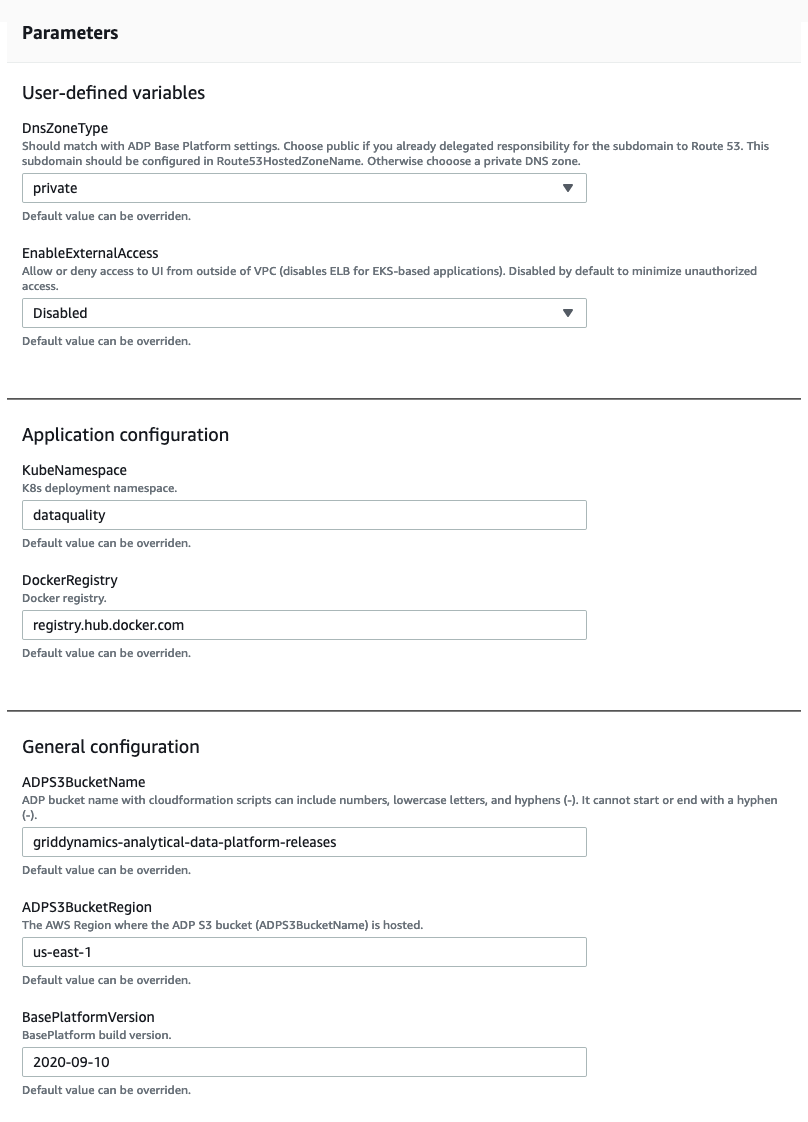
There are two user input parameters responsible for external access, which obviously should be private by default. The rest of the configuration is maintained by CloudFormation. Once the platform is up and running, it provides access to Apache Atlas and data quality only for VPN restricted networks. To enable world wide access please follow the same steps described for the promotion planning use case above.
Promotion planning
Enabling MLOps with the data platform and providing an easy way to release models to production is always a cumbersome process. To simplify ML models development and management, it is helpful to provide proper integration with the data lake and enterprise data warehouse.
There are several use cases we’ve added on top of the ML platform for demo purposes. Promotion planning is one of these. The promotion planning use case creates the ML model, which creates the discount recommendations.
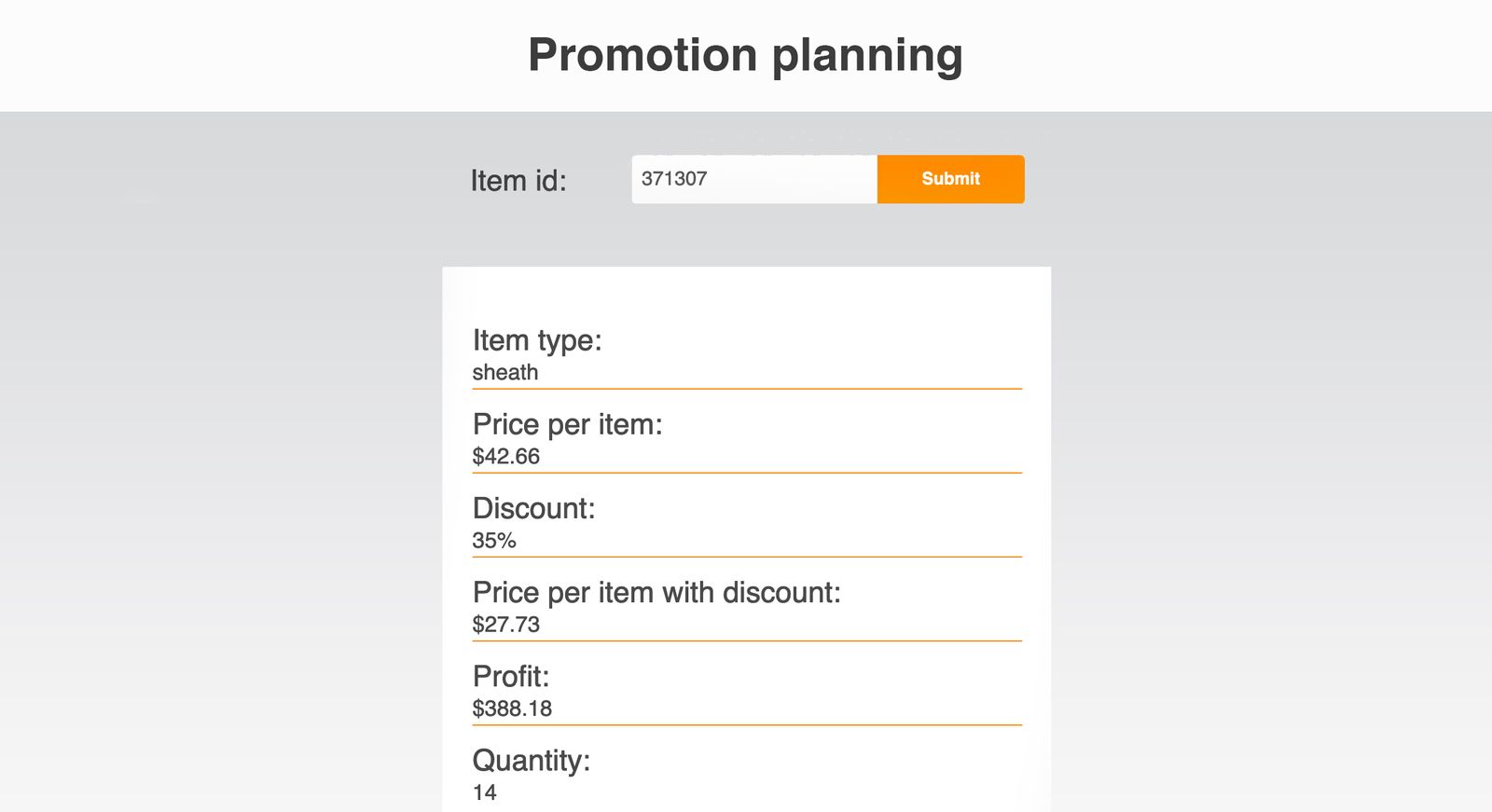
Recommendations are based on sales history information available in the data platform.
Promotion planning provisions Sagemaker, creates notebook instances, and loads an already prepared Jupyter notebook. Data required for the model is available at S3 bucket adp-rnd-ml-datasets prepared by our team. The model will be stored in a private bucket that is provisioned by CloudFormation automation. Once a model is created, it also spins up a web UI to demonstrate the recommendation in action. Capability provisioning is straightforward:
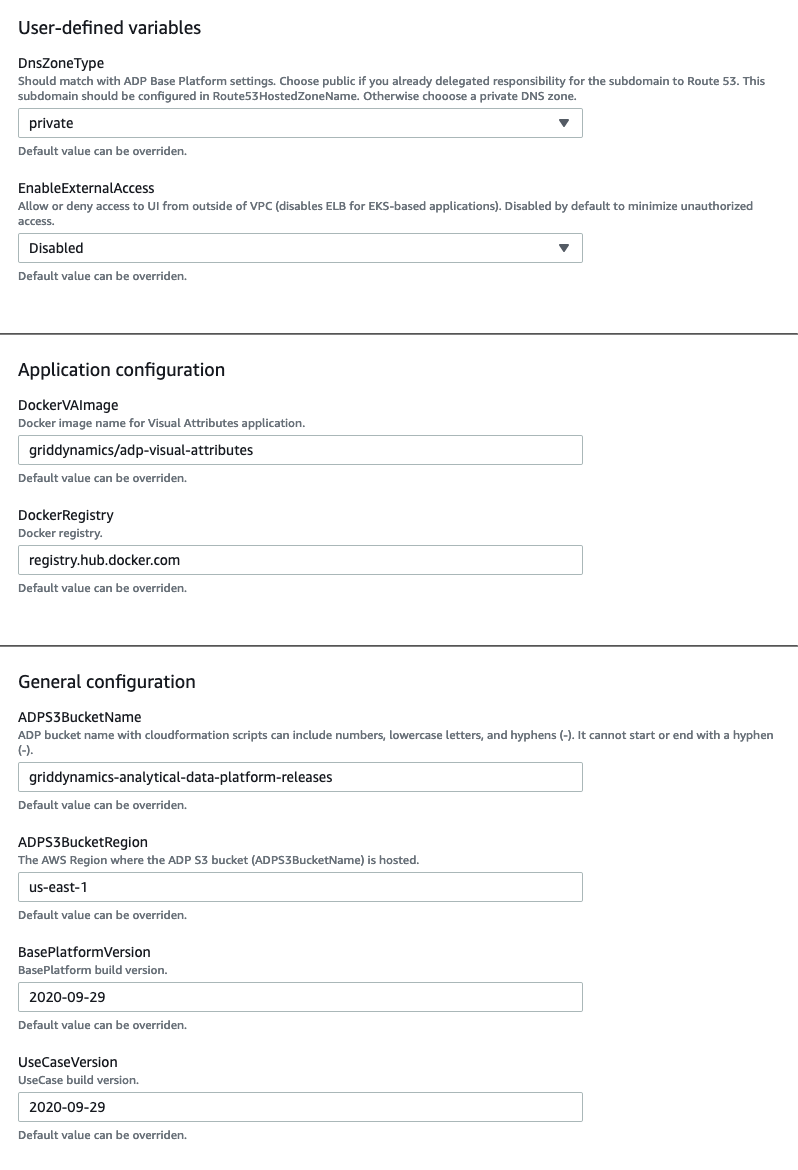
All variables are defined by CloudFormation automation. By default all components are not accessible outside a VPN. However, if needed access can be granted for the world wide internet, which can be done through the use case interface:
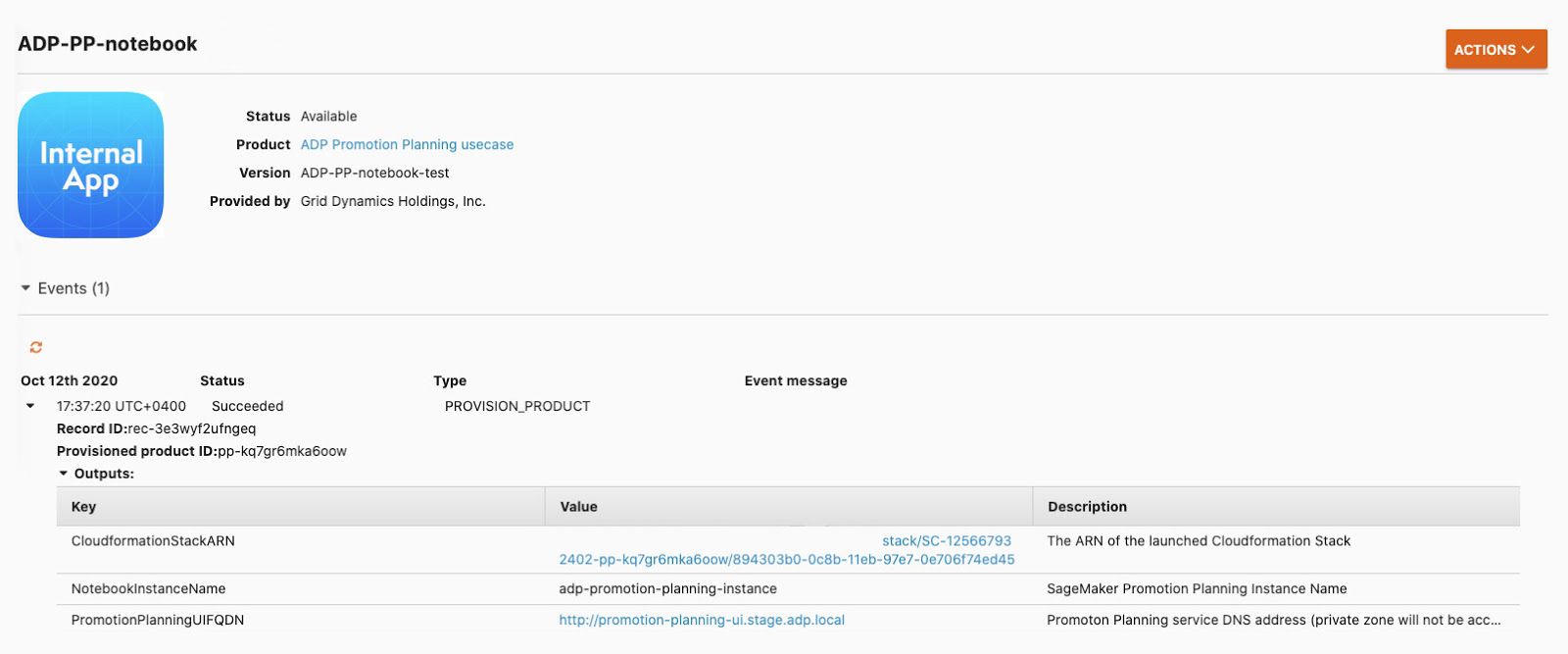
On the screenshot above, PromotionPlanningELB is an external access for everybody.
PromotionPlanningFQDN will work only with a VPN, which resolves DNS records or socks proxy. By default external access is disabled and can be turned on in the provisioned visual attributes use case.
Visual attributes
The data platform can typically be operated with all types of data including transactional, operational, and visual data such as images. The visual attributes use case gets attributes from the image:
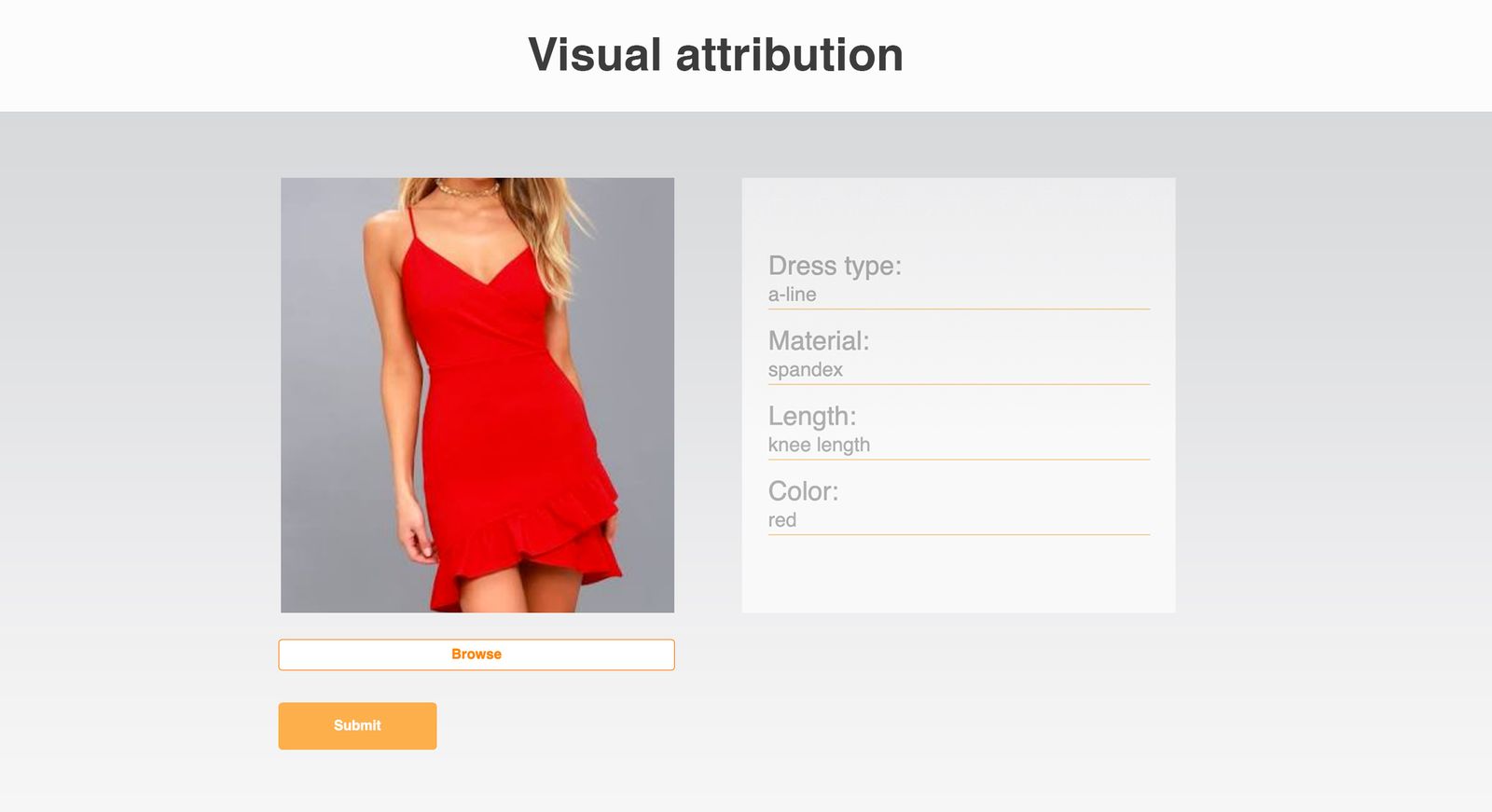
As an example we’ve taken a catalog of women's dresses and created a use case that identifies the type and color of the dress and helps to find a particular one in the catalog.
Similar to the promotion planning use case above, links to both private and public links to the user interface will be available in the provisioned product details.
Source images for the model are also in the adp-rnd-ml-datasets S3 bucket. Jupyter notebook reads data directly and creates both the ML model and REST endpoint for the UI:
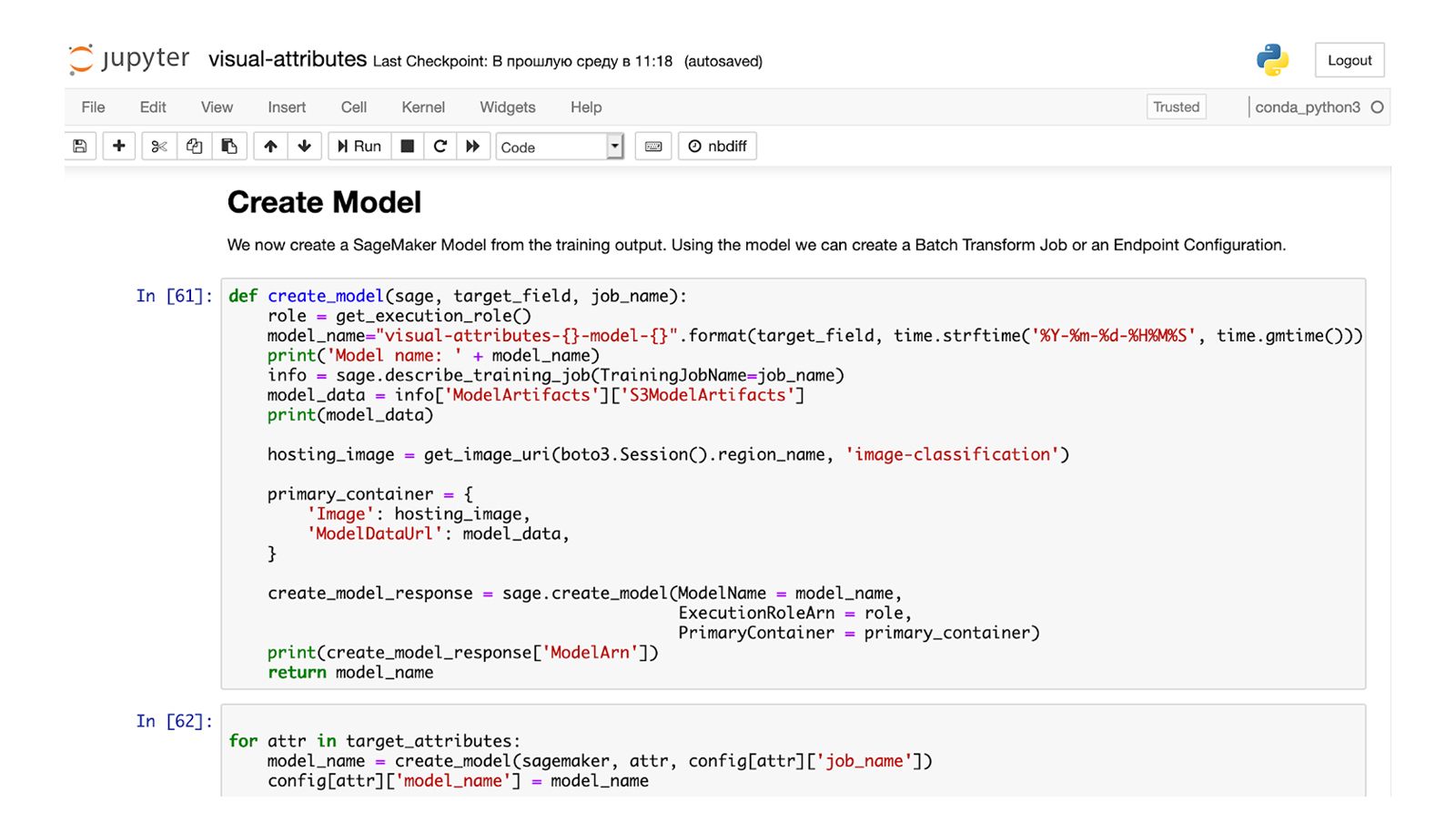
Visual attributes in Jupyter notebook are also created by CloudFormation automation. The ML engineer will just need to run the training and release process. Both visual attribute and promotion planning use cases help to understand and build the custom ML pipelines. Visual attributes provisioning works the same way:
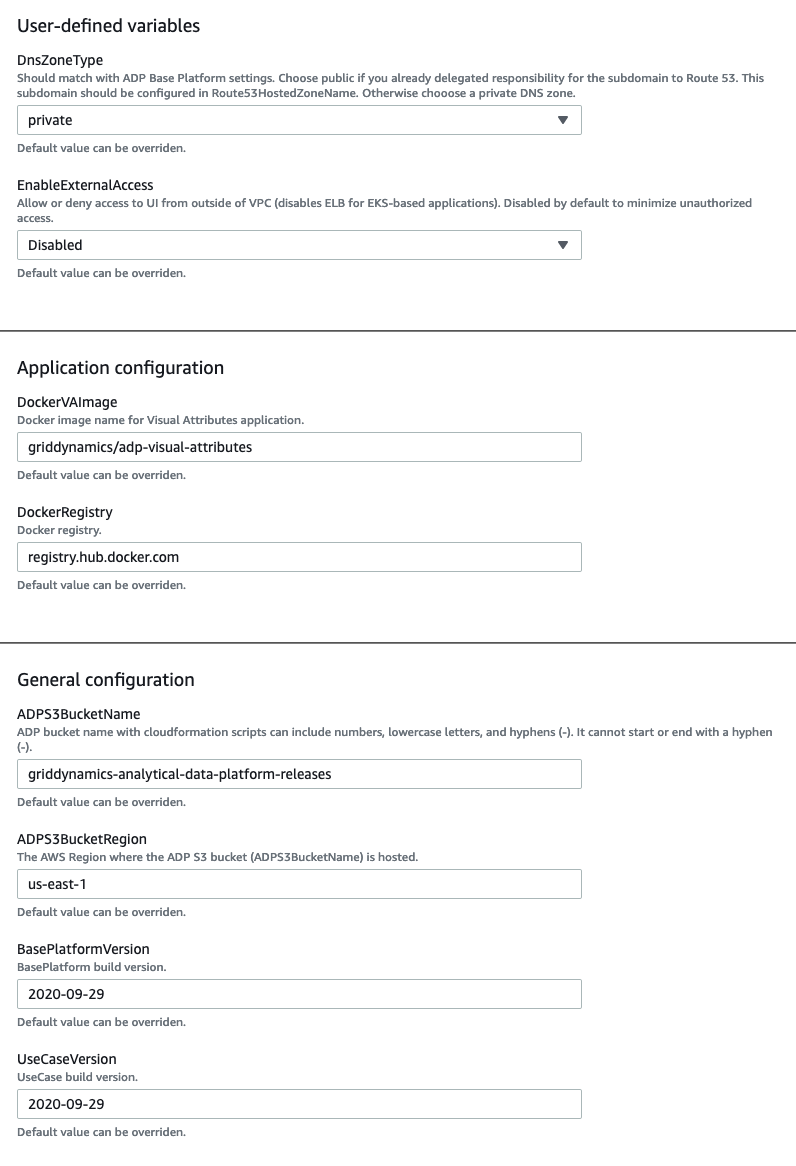
The visual attributes configuration process is the same as the promotion planning use case discussed above.
Anomaly detection
Anomaly detection capability is fully covered in a separate post.
Conclusion
Analytics Platform is a modular platform with six major capabilities, five of which are already available in the AWS Marketplace. Data governance with custom data quality solutions will be released later this year. Each of these can be deployed separately or share the same resources like EMR or Redshift. Deployment is based on the CloudFormation stack and is fully automated. It takes less than a day to deploy all capabilities however, for promotion planning and visual attributes it takes a significant amount of time to train and create the models. The platform is fully operable and ready to be integrated with external data sources.