
Detecting anomalies in high-dimensional IoT data using hierarchical decomposition and one-class learning

Automated health monitoring, including anomaly/fault detection, is an absolutely necessary attribute of any modern industrial system. Problems of this sort are usually solved through algorithmic processing of data from a great number of physical sensors installed in various equipment. A broad range of ML-based and statistical techniques are used here. An important common parameter that defines the practical complexity and tractability of the problem is the dimensionality of the feature vector generated from the signals of the sensors.
Even a single machine in a modern industrial system may comprise thousands of sensors. The general trend of implementing the basic principles of the industry 4.0 (smart factory) paradigm in various industries leads to a steady further increase in the number of sensors and, hence, the number of parameters to be analyzed on a continuous basis. The large and ever increasing number of sensors poses a serious problem for implementation of various ML-based and statistical approaches to health monitoring of industrial systems.
While there is a great variety of methods and techniques described in ML and statistical literature, it is easy to go in the wrong direction when trying to solve problems for industrial systems with a large number of IoT sensors. The seemingly “obvious” and stereotypical solutions often lead to dead-ends or unnecessary complications when applied to such systems. Here we generalize our experience and delineate some potential pitfalls of the stereotypical approaches. We also outline quite a general methodology that helps to avoid such traps when dealing with IoT data of high dimension. The methodology rests on two major pillars: hierarchical decomposition and one-class learning. This means that we try to start health monitoring from the most elementary parts of the whole system, and we learn mainly from the healthy state of the system.
1. Solution design strategies
1.1 Hierarchical decomposition vs wide-and-flat approach
One general approach to building ML-based solutions - which we refer to as the wide-and-flat approach - assumes that all available metrics or their derivatives are lined up into a single feature vector. An extreme example of this is direct sampling of signals from all primary sensors. Normally one does not take into account the physical nature of the features and considers them as mathematical variables. The wide-and-flat approach rests on the assumption that advanced ML techniques (e.g. deep learning) are capable of extracting all essential information from such multidimensional raw data. This strategy is really attractive because it could help to avoid the tedious work of feature engineering and delving into the domain knowledge. The main limitation, in our view, is that such an approach is usually not practically feasible, especially in complex technical systems with a large number of variables to be processed. A major obstacle here is fundamentally mathematical in nature: the curse of dimensionality [1].
There is an opposite approach referred to as hierarchical decomposition or divide-and-conquer. This approach is based on treating a large system as a great number of much simpler subsystems organized according to some hierarchical principles. We normally start solving diagnostic problems at the lowest level of the hierarchy, i.e. for the most basic components equipped with sensors. We also try to take into account the physical meaning of the variables within the system. The main goal here is to include only a minimal amount of variables related to each particular component into the ML-model of this component. The ultimate objective is to replace one complex high-dimensional problem with a large number of much simpler low-dimensional problems. This, in turn, lets us eliminate or at least radically reduce the negative effects of the curse of dimensionality.
In practice, the two approaches are hardly ever used in their pure form: elements of both are typically present in real-life solutions in particular proportions. Nevertheless, in this paper we will follow a simplified line of consideration when the two are used separately. The central point is that the hierarchical methodology is preferable, provided that the hierarchical structure of a complex technical system is known and reasonably clearly specified. Our position here is adequately expressed in the following quote [2]:
“A typical plant-wide process involves a large amount of variables, using a single process monitoring model may suffer from the curse of dimensionality and complicate the subsequent fault diagnosis. In order to reduce the scale of process monitoring model, a divide-and-conquer approach is generally adopted by dividing the process variable set into several blocks/subsets …”
1.2 One-class learning vs two-class classification
A stereotypical approach to health monitoring could be to use commonly known two-class classification procedures. A broad spectrum of such methods is known. A fundamental common feature of all these approaches is that they rest on the principles of two-class supervised learning. The data are split into two groups (or, technically, labeled) - the normal observations and the anomalous ones. The objective of any such method is to learn to relate new unlabeled data to either the normal or anomalous class on the basis of some training procedure performed on the labeled dataset. Of course, the number of classes could be more than two, however, availability of training data for all classes is the essential requirement here.
The methods of supervised two-class classification are well developed, and they are practically efficient in many applications. As for the problems related to health monitoring in complex industrial systems, these approaches are not often a good choice. The major limitation here is purely practical in nature: it is often difficult or even impossible to obtain a large enough dataset properly labeled for two-class classification. And the major difficulty is to obtain a good representation of the “anomalous” class. Below we explain why.
Suppose there are 10,000 elementary subunits in a large industrial system. A fault in any of the subunits means the system at large is in a faulty (anomalous) state too. Thus, at least 10,000 types of faults are possible in the system. Suppose that 1 year of historical data is available for training, and 100 faults occurred during this period. These faults constitute only a small fraction - 1/100 (=100/10,000) - of all the potentially possible faults. A two-class oriented ML model would suffer from insufficient representation of the faulty state in the training dataset: a great fraction of the faults not represented in the training dataset would not be recognized as such by the model.
When one class is severely underrepresented, there is a powerful alternative to the two-class classification strategies known as one-class learning. There are many variants of its implementation in different settings [3]. The central idea is that a ML model is trained only on the data from the negative class representing a healthy state of the system. Fortunately, for technical system health monitoring tasks, the negative (healthy) class is usually well represented. As long as industrial systems tend to be in their healthy state most of the time (fortunately!), the use of one-class learning looks like an attractive strategy with high potential.
1.3 Supervised vs unsupervised anomaly detection
In mathematical and ML literature the term anomaly detection is mainly used as a synonym for detection of outliers. It is an umbrella term for a broad range of statistical and ML-based methods. In spite of their diversity, the methods share a common characteristic: they are essentially unsupervised. This means that the data are treated as a set of unlabeled data points, and it is assumed that some small fraction of them are anomalous, i.e. differ in some respects from the majority of normal data points. The objective of these methods is to separate such anomalous data points from the remaining normal ones.
The term anomaly here is used in a mathematical sense, where anomalies are mathematical curiosities, rather than a business/technological sense. A simple example of such an anomaly detection procedure is the 3𝞼-rule, well known from beginner statistics courses and data analysis. It is important to note that unsupervised approaches to anomaly detection do not utilize a priori knowledge about the system; they are focused on finding deviations of mathematical properties of some data points from the remaining majority.
Although the unsupervised methods of anomaly detection work well in many applications, for complex industrial systems we have strong preference for supervised approaches, particularly for the one-class-learning strategies mentioned in subsection 1.2. In contrast to unsupervised approaches, the supervised one-class-learning approaches utilize important a priori information, where particular data points represent a healthy state of the system. In other words, supervised approaches take into account some knowledge about the real state of the system, not only about the mathematical properties of the data (as in the unsupervised approaches). In practice, this results in a much better performing final solution.
1.4 Limitations of anomaly detection on the basis of time-series prediction
A popular class of approaches to anomaly detection is based on time-series prediction. The data are considered as a vector time series $X_t, t=1, 2, \ldots$. A ML model is trained to predict the current vector value $X_t$ on the basis of the previously observed $M$ values $X_{t-1}, \ldots, X_{t-M}$. Then the predicted value $\hat{X}_t$ is compared to the true observed value $X_t$. If the chosen measure of deviation - e.g. the sum of squared differences of the components - is large enough, then we consider it as a symptom of an anomaly. We assume that either a vast majority of the training data (unsupervised approaches) or all the training data (one-class supervised approaches) represent the healthy state of the system. In other words, the model is trained to predict the next datapoint in a healthy system. Therefore, we expect that prediction errors are relatively small for the healthy states, and the errors tend to increase when the system runs out of the healthy state.
These types of approaches are well studied in theoretical literature and widely used in many application areas. However, in our experience, the health status of many complex industrial systems cannot normally be estimated effectively this way. The above mentioned approaches rest on the assumption that in a healthy system its state $X_t$ at moment $t$ is linked with the states $X_{t-1}, \ldots, X_{t-M}$ at $M$ preceding moments by some functional relationship. At the same time, a great fraction of variables describing industrial systems reflect the influence of various random and poorly predictable factors and, thus, such a functional relationship simply does not exist. See our blog article, Anomaly Detection in Industrial Applications: Solution Design Methodology, for more detail on this.
Another shortcoming of the time-series-prediction-based approaches is that it exacerbates the curse of dimensionality. If the dimensionality of the vector $X_t$ describing the state of the system at particular time $t$ is, say, $N=1000$, and one uses $M=100$ lags for prediction, then the dimensionality of the resultant problem is $N \times M = 100000$. Such a radical increase in the dimensionality of the problem to be solved contradicts our general principle to minimize the dimensionality as much as possible.
2. Challenges and desirable solution capabilities
The steady advance of the Industry 4.0 (smart factory) paradigm strengthens the difficulties arising with application of the stereotypical ML-based approaches mentioned in the previous section. Therefore, we try to develop our solution design methodologies in such a way that they could deal with these sorts of challenges in the foreseeable future.
2.1 High dimensionality of the data
Large scale industrial applications - like a whole plant or an assembly line - normally utilize a large number of physical sensors with signals that need to be processed. There may be thousands of sensors in a single machine and many such machines in the whole industrial system. There is also a stable trend towards increasing the number of sensors in any particular type of industrial equipment.
The approaches vulnerable to the curse of dimensionality - like wide-and-flat feature vector formation and time-series-prediction-based anomaly detection - suffer from this trend to a great extent. Therefore, we try to build solutions that avoid these pitfalls, e.g. via decomposition of a high-dimensional problem into a great number of low-dimensional ones.
2.2 High and ever increasing data rate
Besides the high dimensionality of the data, modern industrial systems are characterized by high and continuously increasing data rates for almost all types of sensors. For example, vibrational sensors, which are ubiquitous in mechanical systems, provide data at rates of at least several thousand samples per second. Video sensors provide data at rates several orders of magnitude higher - tens of millions of samples (pixels) per second, even for a simple video camera with a moderate resolution.
The high primary data rate and its continuous growth make the wide-and-flat philosophy unpromising. For example, the idea of transmitting all the raw data to a single place like a cloud computing service for major processing might seem attractive at first glance. At the same time, however, the fast-growing rate of the data collected by IoT sensors can make such transmission the bottleneck of the whole solution. For this reason, we gravitate towards the ideas of edge computing, where preliminary data processing is performed close to the IoT sensors, e.g. using various embedded CPUs. Only then are the pre-processed data - which have much lower rates - transmitted to the cloud.
2.3 Qualitative and quantitative inhomogeneity of sensors' readings
Besides the tendency of the number of sensors and the rate of generated data to steadily increase, there is also a noticeable tendency in the growth of sensors’ diversity. The signals generated by IoT sensors in industrial systems are essentially inhomogeneous in respect to both their physical nature, data structure, and data rate. The physical nature of the values measured by different sensors could be, for example, humidity, temperature, physical strain, pressure, salinity, and hundreds and hundreds of other physical and chemical properties. For example, a special and widely used class of mechanical sensors are various vibration sensors (accelerometers). These sensors have a relatively broad bandwidth - up to tens of kilohertz and higher - and, hence, require a proportionally high sampling rate. Video- and IR- cameras represent another special class of sensors that generate high data-rate streams of 2D-images. Such qualitative and quantitative inhomogeneity of the primary signals from IoT sensors makes the wide-and-flat approaches to feature-vector generation practically infeasible. Therefore, we pay more and more attention to the underlying “physics” of the primary data and to the domain-knowledge-based feature engineering.
2.4 The necessity of fault localization
A mere decision about the detection of a fault or a pre-fault condition in the whole system hardly bears enough information for most practical applications. For example, a decision related to the occurrence of an assembly line fault or potential assembly line fault bears too little detail to resolve the problem. It is normally necessary to know the localization of the fault within the system for the lowest level of the hierarchy possible: the assembly line -> the machine -> the module of the machine -> the submodule of the module, and so on.
The wide-and-flat approach itself - with its single high-dimensional feature vector for the whole system - is hardly suitable for decisions about the localization of faults, particularly for submodules. In contrast, decomposing the whole system into a hierarchy of its components and starting the diagnostics from the most elementary ones makes localization of most faults quite a trivial task.
2.5 Interpretability of decisions
ML models, per se, typically operate like black-box decision makers. If the wide-and-flat approach is used, for example, then a single complex ML-model could classify the current state of the industrial system as “unhealthy”, but without any further possibility for a human being to understand the logical background of such a decision. In other words, such models are not “interpretable”. A general trend in modern applied ML technologies is to keep models interpretable at least to some extent [4].
In contrast, the hierarchical decomposition approach has the intrinsic ability to provide interpretable decisions. Suppose a pre-fault condition has been detected at a higher level of the hierarchy - the whole machine, for example. The resultant features (anomaly scores) from the previous level - the modules of the machine - could be easily analyzed. Suppose it has been found that the anomaly score for a particular module of the machine is too high. This means the fault is likely to be localized within this module. Then, we analyze anomaly scores from the submodules of the module, and so on, to narrow down the location of the fault.
2.6 Robustness to modifications
The structure of most industrial systems is rarely static. Modifications of the equipment itself and the sensors used for health monitoring happen quite frequently, especially in large systems. It is hardly acceptable that such an update would result in a laborious process of modifications of the health monitoring system, retraining of the whole high-dimensional model, etc.
The wide-and-flat approach, at least in its pure form, is highly vulnerable to these sorts of problems. If we use a single vector of, say, 10,000 features to train a single complex model, then adding or replacing even a single sensor would require retraining of the whole model. The hierarchical approach - although not completely immune to modifications - looks much more robust. A change in a submodule, for example, only requires retraining of a simple partial ML model corresponding to this submodule.
3. An illustrative model of an industrial system
3.1 Hierarchical nature of industrial systems
Technical systems, including large industrial ones, are created by design and, hence, they are usually organized in a natural hierarchy: something like machine -> module -> submodule -> . This hierarchy is normally specified in the technical documentation. Such an explicit hierarchical structure radically alleviates the process of decomposing the system while creating health monitoring tools.
3.2 An example model: an assembly line
For illustrative purposes we will use the following simplified model. Consider an assembly line comprising 10 working cells. Each working cell consists of 10 machines. Each machine comprises 10 modules. And each module consists of 10 submodules. Thus, at the lower level of the hierarchy, there are 10,000 submodules. Each submodule is equipped with primary physical sensors - at least with one sensor. The signals from the sensors are available for health monitoring purposes.
Each submodule could potentially experience a fault, and such a fault is equivalent to a fault of the whole assembly line via a logical cascade: a faulty submodule -> a faulty module -> a faulty machine -> a faulty working cell -> a faulty assembly line. For example, a defect in a single bearing (submodule) leads to the faulty electric motor (module), which in turn results in a faulty state of the corresponding machine, which in turn makes the corresponding working cell faulty. The first three levels are schematically shown in Fig.1
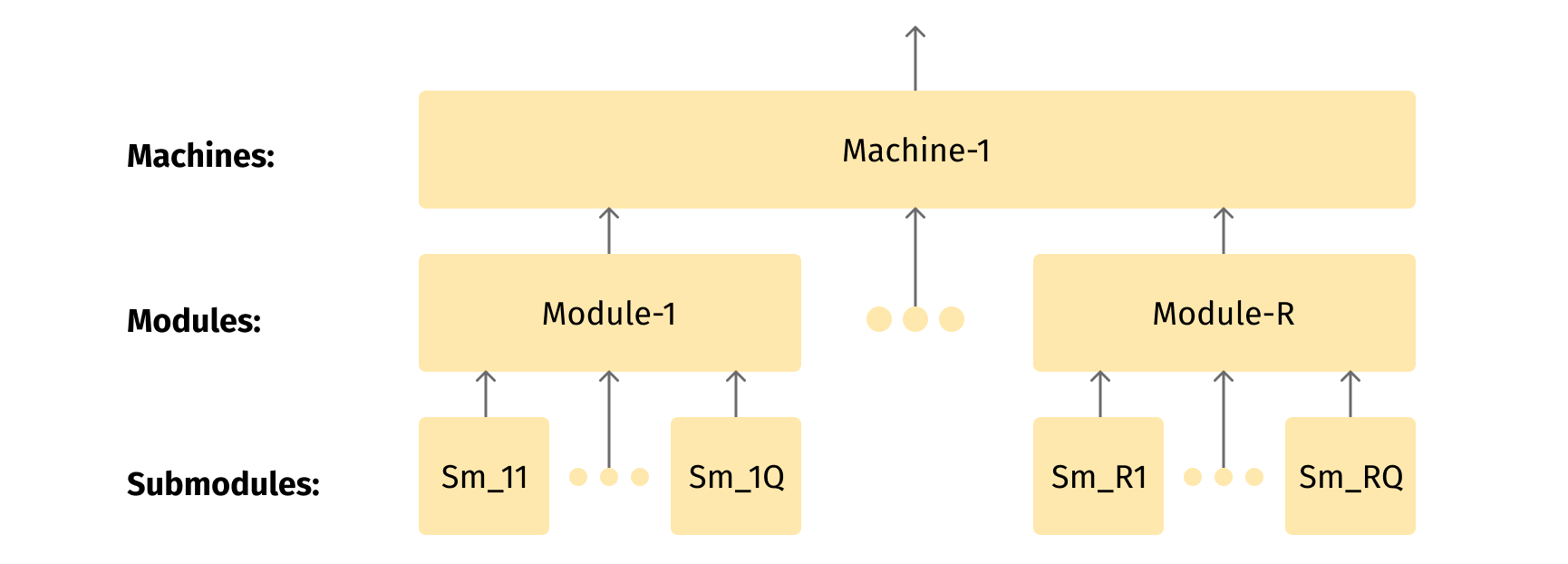
3.3 Dealing with the lowest level of the hierarchy: an example of bearings
The lowest level of hierarchy is represented by the minimal (“atomic”) units equipped with sensors. The design of the monitoring system in our approach starts from the lowest level. In our example assembly line we name such “atomic” units submodules. To illustrate the point, we consider such a submodule as a bearing. Although a bearing comprises other subunits - balls (or rolls) and two races - we still consider a bearing as the lowest level of the hierarchy. It is because the components of a bearing are not equipped with sensors and, thus, are not “visible” as separate entities by our health-monitoring system.
The bearings are ubiquitous units of various mechanical and electromechanical equipment. They are prone to a relatively fast aging process and, hence, they need to be replaced quite frequently as compared to other components. A missed fault in a single bearing could have serious consequences. For this reason, vibrational health monitoring of bearings has a long history in technology, and extensive knowledge has been accumulated here. In the next subsection we show that the use of this knowledge radically alleviates the process of feature engineering.
3.4 Take historically accumulated domain knowledge into account whenever possible
Suppose a bearing is equipped with a couple of X/Y accelerometers. Sampling of the two signals $S_x(t), S_y(t)$ requires $2N$ values where $N = 2 \times F \times T$, $F$ is the bandwidth of the signal in Hz, $T$ is the duration of the interval in seconds (Nyquist–Shannon sampling theorem). Even very moderate values $T = 1$ sec and $F = 5000$ Hz lead to the necessity to use 20,000 samples to represent a one-second-length record of the signals from a single bearing.
It is hardly practically feasible to use the raw samples as the features for ML models as this would result in too high a dimensionality of the feature vector. A practically obvious solution is to transform the signals into a small number of more informative statistics that reflect the state of the bearing at an interval of, say, 1 second. Such a pre-processing of raw signals would radically reduce the data rate and dimensionality of the feature-vector. We name such statistics derived from the raw signals primary diagnostic features.
The most difficult task here is to decide which type of raw signal transformations one should make to obtain meaningful and informative primary features. One might try to avoid delving into the domain knowledge and use some ML-based techniques for automatic feature engineering. However, while such purely data-based approaches to finding practically meaningful features could be an interesting research topic, it would be naive to expect to find a practically effective solution with reasonably low efforts. The primary diagnostic features currently used in practice have been found in decades of intensive research, due to human ingenuity and observancy, not via purely formal application of statistical or ML-based techniques to the raw data.
The use of domain knowledge for feature engineering is not necessarily a tedious and laborious task. As for the bearings, for example, one might have found a solution after a few requests to a search engine. The features described in literature are simple and easily understandable statistics: RMS, kurtosis, skewness, crest-factor, shape factor, and some others [5]. The statistics are computed from the samples of the amplitude of the resultant X,Y-vector of displacement or acceleration $A(t) = \sqrt(S_x(t)^2 + S_y(t)^2)$ by simple algorithms.
4. An outline of the solution design
Here we provide a sketchy description of the basic stages of the solution design. We actively use the terminology from our example model of an assembly line described in subsection 3.2. Thus, the hierarchical levels of the system from top to bottom are as follows: the assembly line -> working cells -> machines -> modules -> submodules. The submodules represent the lowest level of the hierarchy. In other words, submodules are the most elementary (“atomic”) subunits of the system that are equipped with IoT sensors.
4.1 Taking basic knowledge of the system into account
An essential prerequisite for our approach is that we are familiar with and take into account the hierarchical structure of the industrial system as well as the correspondence between the signals from IoT sensors and particular submodules. We do not try here to delve too deeply into the underlying “physics” of the processes within the system. It is normally enough to have information about the general relationships like “unit A is a constituent of block B”, “signal 32 comes from module Cx”, etc.
Such an approach is an essential deviation from the philosophy of the radical wide-and-flat approaches. The latter are prone to treat all the signals from IoT sensors as mathematical entities representing the whole system, and to rely exclusively on ML algorithms to ascertain the relationship between the signals and the state of the system.
4.2 Generation of primary diagnostic features from the raw signals
Firstly, we transform the raw signals from the IoT sensors to more informative statistics. In our example of the bearings, for instance, we calculate such statistics as RMS, kurtosis, crest-factor, shape-factor, etc. We try to use available domain knowledge at this step. These are our primary diagnostic features. The primary features are much more informative than the signals themselves. They are also generated at a much lower data rate than the samples of the raw signals. This step is depicted in the lower box in the diagram in Fig. 2
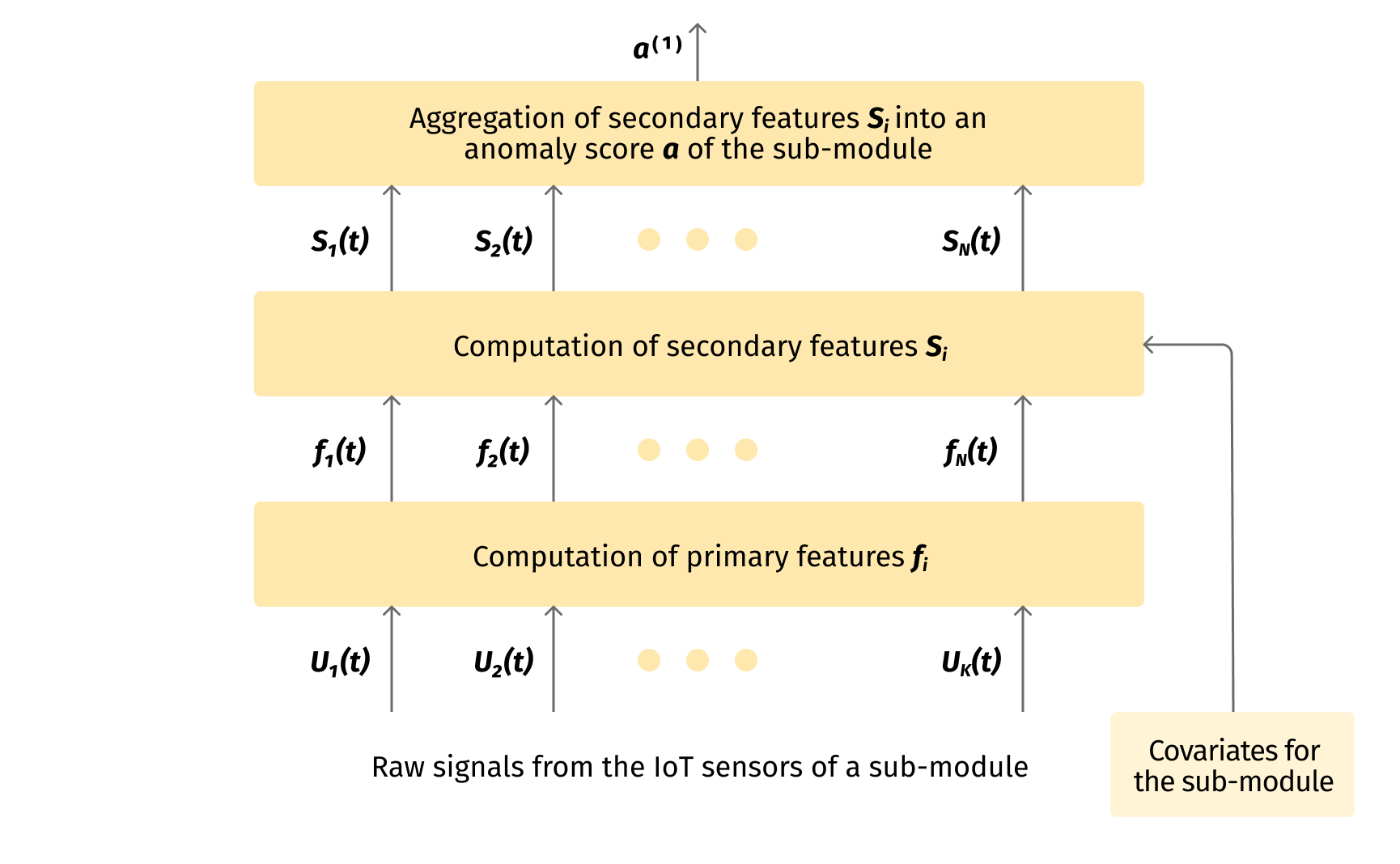
We try to construct the primary diagnostic features akin to anomaly scores: they take non-negative values only, and the greater the value, the greater the evidence that the submodule is in an unhealthy state. Some statistics, like RMS or kurtosis in the case of bearings, which take non-negative values, could be used as the primary features directly. Other statistics might require some elementary transformation, like $|T - T_opt|$, where $T$ is the actual temperature inside a chemical reactor, and $T_opt$ is the optimal temperature.
The primary features, if properly normalized, could be used immediately for diagnostic purposes. See, for example, subsection 5.6 below. It is quite a traditional approach when primary features are directly used in dashboards.
4.3 Formation of secondary features from the primary ones
The primary features are normally too volatile and may have unwanted dependencies on other variables. This can often be a serious nuisance factor for anomaly detection. For this reason, we transform each primary feature into the corresponding secondary feature. The secondary features enable anomaly detection at much higher sensitivity. It is a very important step. Here we use our ML-based approach which rests on a non-traditional application of regression for one-class learning.
At this stage we actively use the knowledge about the structure of the system and about relationships between its constituents. The goal here is to minimize the number of other features (covariates) causally affecting the given primary feature. This allows for radical reduction of the dimension of the partial ML-problems to be solved, and makes the whole ML problem practically tractable. This process is described in detail in section 5 below, and is represented in Fig.2 in the second box from the bottom.
4.4 Aggregation of the secondary features into a single anomaly score
Even a single submodule is typically characterized by several features. For a bearing, for example, we calculated the following primary features: RMS (root mean square) which measures the intensity of vibration, and several statistics describing the “heaviness of the tail” of the distribution or impulsiveness of the vibration signal, like kurtosis, crest-factor, etc. As long as we need a single anomaly score for the whole submodule, we have to use some aggregation procedure to transform several secondary features into a single anomaly score of the module as a whole. In this article we consider only the simplest aggregation procedures like averaging or logical OR. In reality, we use more complex algorithms, but this topic is outside the scope of the article. This topic is covered in more detail in section 6. This step is represented by the top box in Fig.2.
4.5 Aggregation of anomaly scores at the higher levels of hierarchy
The anomaly scores described above are sufficient to detect an anomaly in a particular submodule. Such a detection automatically resolves the problem of anomaly localization and interpretation of the decision for human beings. This is because the anomaly score is directly associated with a particular submodule. However, situations often arise when anomalies are “distributed” or “dispersed” in nature, and therefore, not easily detected at the level of individual features.
Consider the following example. Many modules of a particular machine generate moderately elevated anomaly scores because of the unhealthy state of the machine. The increase in the anomaly score of each individual submodule is not large enough to make reliable decisions (the increase is not statistically significant). In such cases, aggregating the partial anomaly scores of the individual modules into a single anomaly score for the machine as a whole often helps to detect these types of anomalies, which are not detectable otherwise. Some examples are presented in section 6. These steps of data processing are shown in Fig.3
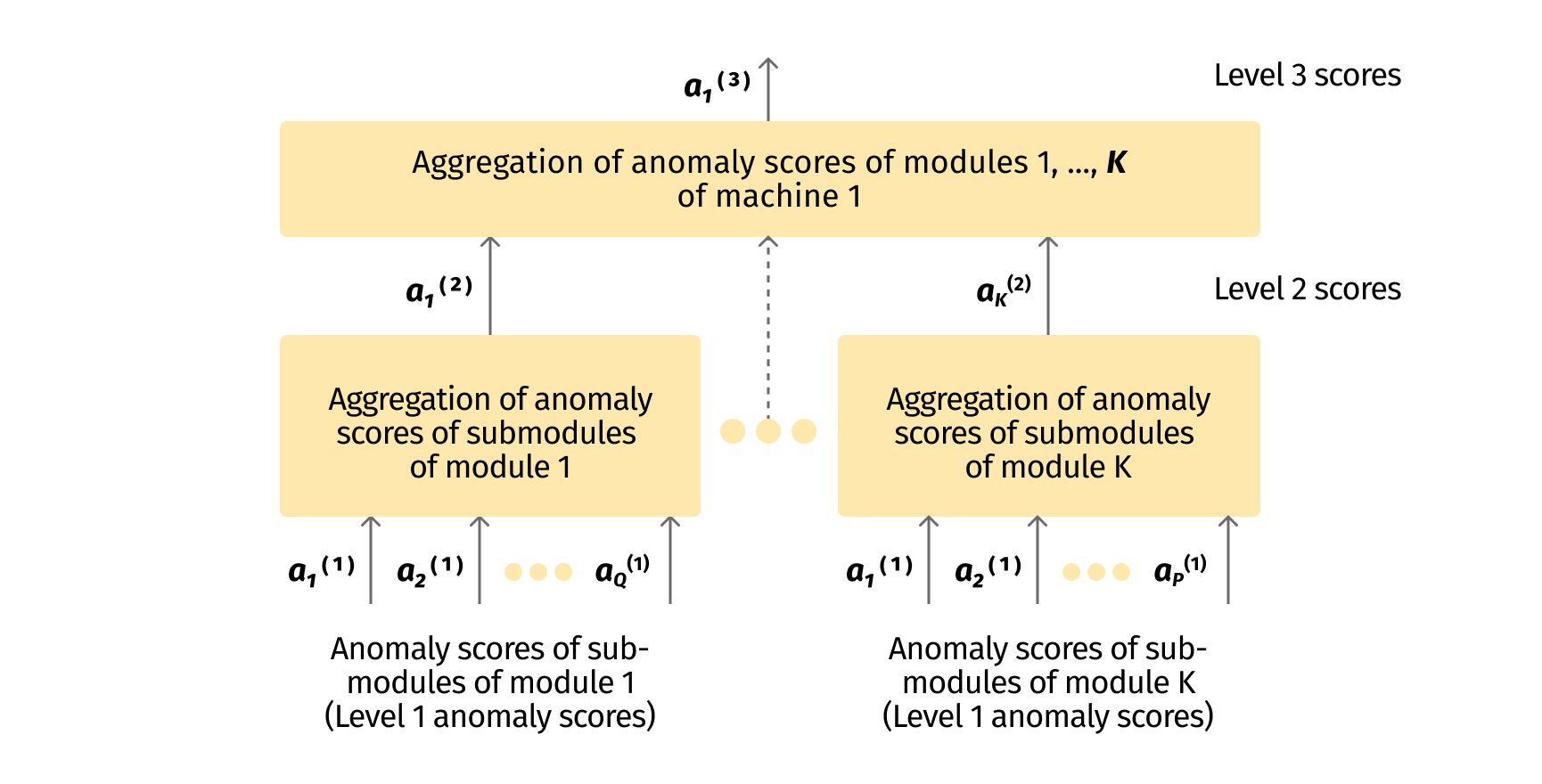
4.6 The choice of thresholds for individual decisions and alerts
The anomaly scores themselves, if properly visualized, help human beings detect anomalies, but they are not sufficient for automatic decisions. To make automatic decisions - to generate alerts, for example - we still need some formalized procedure which transforms the anomaly score (a continuous value, like 7.81) into a final binary decision (like “healthy” or “anomalous”).
We usually use the classical Neyman-Pearson criterion - i.e. we pre-specify some small probability of false positive decisions, e.g. reporting of an anomaly when the anomaly does not exist. The decision itself is performed by elementary thresholding procedure, but the choice of the threshold is not a trivial problem. We try to act in the spirit of one-class learning and utilize the training data corresponding to the healthy state of the system. In a simple case - when the training dataset is large enough - it is often sufficient to use quantiles of the feature distribution on the training dataset. Sometimes we need more sophisticated procedures, e.g. extrapolation of the tail of the density of the distribution. Again, these topics are practically important but beyond the scope of the article.
5. Dealing with the lowest level of the hierarchy
Here we provide a simplified description of a strategy we often use to solve anomaly detection problems in large systems with many IoT sensors (thousands and tens of thousands). We describe the most important part - the construction of the secondary diagnostic features for most elementary submodules as well as their aggregation into a single resultant anomaly score.
5.1 Two types of variables: primary diagnostic features and corresponding covariates
Primary diagnostic features are computed from the raw signals arriving from primary IoT sensors. These features are assumed to be constructed like anomaly scores, i.e. the greater the value, the greater the evidence of some anomaly. Simple examples are the intensity of vibration or the absolute deviation of the temperature from the optimal one.
Each primary feature is associated with a specific set of covariates. The covariates are the variables which can causally affect the values of the primary features at the healthy state of the system. The values of the primary diagnostic features themselves - without the information about the corresponding values of the covariates - may not be sufficient for reliable decisions. There is no hard and fast demarcation line between the two types of variables. A diagnostic feature could simultaneously play the role of a covariate for other features, and vice versa.
Consider, for example, the case of a bearing operating inside an electric motor. The intensity of the vibration of the bearing (as measured by the displacement or acceleration RMS value) is a simplified example of a primary diagnostic feature. The greater the value of this feature, the greater the degree of suspicion related to an anomaly. However, the intensity of vibration alone is not sufficient to make reliable diagnostic decisions. This is because the intensity of vibration of a healthy bearing depends essentially on other variables (covariates). Examples of such covariates are the rotation speed of the electric motor, the torque on the shaft (the load of the motor), or the first derivative of the rotation speed.
The attribution of particular variables to the covariates of a particular diagnostic feature requires some domain knowledge. Even if a large system is described by thousands of variables, any particular primary feature normally depends only on a relatively small number of covariates. And only variables from this small set are considered as covariates for the particular diagnostic feature. Such minimization of the number of covariates for any particular feature allows us to solve many low-dimensional inferential problems instead of solving a single problem with a high-dimensional feature vector. This, in turn, avoids the curse of high dimensionality typical of the wide-and-flat approaches.
5.2 Mathematical description of primary features and covariates
We use a non-standard regression-based approach for one-class learning. We assume that the mutual dependence between all $M$ primary features $f_i$ in the healthy state of the system can be expressed by the following expressions:
$$
f_i = F_i(f_1, \ldots, f_{i-1}, f_{i+1}, \ldots,f_M), i = 1, \ldots, M, \qquad (1)
$$
In other words, each primary feature $f_i$ is considered as a function $F_i(\cdot)$ of all other $M-1$ primary features. The functions $F_i(\cdot), i=1,\ldots,M$ are not known a priori, but they can be learnt by an ML model from the training dataset representing a healthy system, at least in principle.
For small values of $M$, one might use expressions (1) directly for training partial ML models for each feature $f_i$. Proponents of the wide-and-flat approach would try to do this even for complex systems with large values of $M$. We believe that it is essentially not a good idea - because the curse of dimensionality would hamper our workflow dramatically. Instead, we try to carry out the following very important step.
For each feature $f_i$, we select a small number of other features which affect the value of this feature causally. We name these selected features the covariates of the feature $f_i$, and we denote them as $x^{(i)}_{1}, \ldots, x^{(i)}_{M_i}$. The use of domain knowledge is crucial at this step. The mathematical representation of our features is now the following:
$$
f_i = F_i(x^{(i)}_{1}, \ldots, x^{(i)}_{M_i}), i = 1, \ldots, M, \qquad (2)
$$
The most fundamental and practically important distinction between the expressions (1) and (2) is the number of arguments of functions $F_i(\cdot)$. In the traditional baseline representation expressed by (1), the number of arguments is always $M-1$. This number may be huge, especially in large systems. In our representation expressed by (2), the number $M_i$ of covariates varies from feature to feature, but it is normally radically smaller than the number of all features $M$.
When we deal with a simple technical system, the number $M$ of features is often small. In this case, there may be no essential distinction between the traditional approach based on expression (1) and our approach based on expression (2). But the situation changes radically for complex systems where the overall number $M$ of features is large. It is very important to bear in mind the following peculiarity of technical systems:
- The number $M_i$ of causally related covariates of any particular feature $f_i$ is typically small, say, 1-10 covariates per feature. At the same time, the number $M$ of all features may be very large in a complex industrial system, say, thousands and tens of thousands. This means that our approach allows for a radical reduction of the dimensionality of the ML problems to be solved as compared to the baseline. This alleviates the curse of dimensionality and makes the problems practically tractable.
- In contrast to the traditional representation (1), the number $M_i$ of covariates in (2) typically does not depend on the complexity of the whole system, i.e. does not grow when the number $M$ of all features increases. For example, if $f_i$ reflects the intensity of vibration of a bearing. The $f_i$ depends on two covariates - the rotation speed and the torque on the shaft. Then, $M_i$ is still 2 even in a complex industrial system with tens of thousands features.
For testing purposes, we often use a parametric family of functions $F_i(\cdot)$ present in expression (2). Four such functions of two covariates each ($M_i=2$) have been randomly chosen from our test-data-generation module. Simulation of random variability has been switched off. The functions have been visualized. The results are shown in Fig.4 (surfaces in 3D space) and in Fig.5 (color maps). It is necessary to bear in mind that the covariates $x_1, x_2$ for different features $f_i$ are normally different groups of variables.
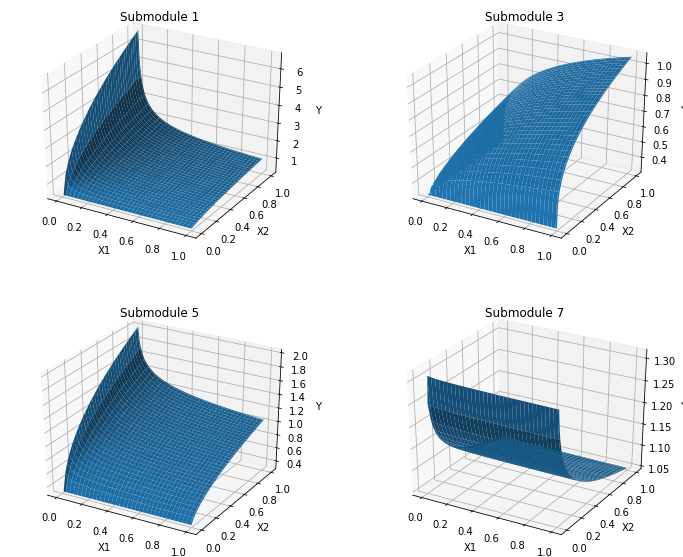
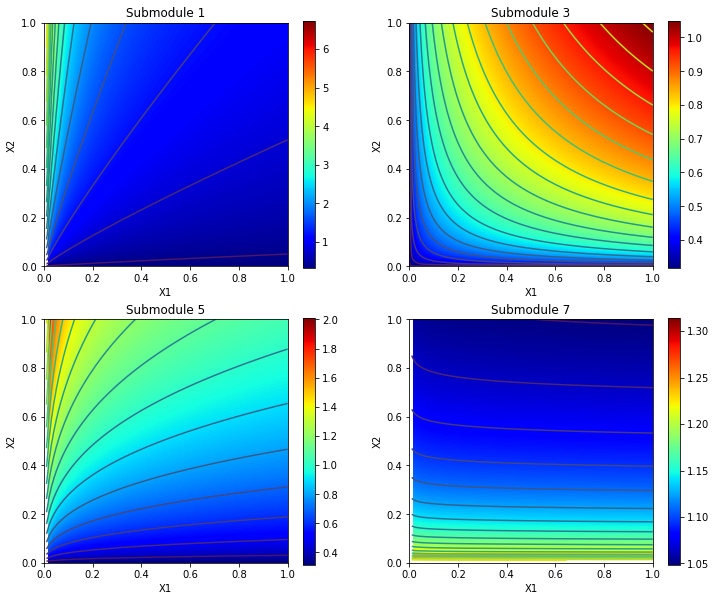
It is clearly noticeable from figures 4 and 5 that each primary feature is characterized by a specific dependence of its values on the corresponding covariates. The goal of the training process described below is to learn this dependence - the shape of the functions $F_i(x_1, x_2,...)$ - from the data collected in the healthy state of the system.
5.3 The structure of the initial data
The structure of the initial data for our approach is determined by the overall data representation by expression (2). Preparation of the data requires some domain knowledge, mainly for choosing proper covariates for each primary feature $f_i$. At this step, we try to actively use the knowledge accumulated by the technical staff of our clients as well as our own physical and technical intuition.
For our example model of an assembly line (subsection 3.2), for instance, the following fields are included into the dataset. The last four fields are specific to our particular example system while others are rather universal:
- timestamp
- feature_id
- covariate_id
- argnum
- value
- variable_name
- submodule_name
- workcell_id
- machine_id
- module_id
- submodule_id
IDs of features and covariates are always the same: these are simply IDs of our primary features.
Here, if covariate_id is equal to 0, then the value corresponds to the primary feature $f_i$ itself. Otherwise, value is the value of the covariate $x^{(i)}_k$ corresponding to the covariate_id of feature feature_id. A single datapoint is represented by $M_i + 1$ rows with the same unique combination of feature_id and timestamp. The rows represent the value $f_i$ of the feature itself and the value of the corresponding $M_i$ covariates. The field argnum determines the order of the covariate as an argument of the function $F_i(\cdot)$ in expression (2); for the features themselves we use the 0-value here.
For a bearing, for example, a single datapoint for feature “vibration_rms” with two covariates - “rotation_speed” and “torque” - is shown in Fig.6.
| timestamp | feature_id | covariate_id | argnum | value | variable_name | submodule_name |
| 2021-05-12 22:52:17.817 | 1317 | 0 | 0 | 17.1 | “vibration_rms” | “bearing_C-x-117” |
| 2021-05-12 22:52:17.817 | 1317 | 2117 | 1 | 610.0 | “rotation_speed” | “bearing_C-x-117” |
| 2021-05-12 22:52:17.817 | 1317 | 1411 | 2 | 311.3 | “torque” | “bearing_C-x-117” |
Figure 6. Representation of a single data-point in the initial dataset for primary feature vibration_rms (id=1317) with two covariates: rotation_speed (id=2117) and torque (id=1411). The feature describes the intensity (RMS) of vibration of a single bearing, namely, bearing_C-x-117.
Such a structure of the datasets is rather universal. It allows us to combine data for features with different numbers of relevant covariates as well as for subunits with different numbers of features. A great deal of important domain knowledge is incorporated into the dataset, namely, the data specify the set of technically feasible covariates for each feature and the relationship between features and submodules.
5.4 The architecture of the model
The goal of one-class learning here is to “learn” (to approximate) $M$ unknown functions $F_i(x^{(i)}_1, \ldots, x^{(i)}_{M_i}), i = 1,\ldots,M$ on the basis of the observed values $f_i$ of the primary diagnostic features and the corresponding values of the covariates $(x^{(i)}_1, \ldots, x^{(i)}_{M_i}), i = 1,\ldots,M$. It is essentially a problem of nonlinear regression analysis. The multilayer perceptron - a major workhorse in the realm of neural networks (NNs) - is a well suited ML tool for these types of problems.
It is easy to note from the general expression (2) that we essentially solve M separate regression problems - one separate problem for each primary diagnostic feature $f_i$. In principle, we could build and train M separate independent ML models. If the number M of primary features is large, such a process would be not efficient from both maintenance and computational standpoints. Therefore, we prefer another approach, described below.
Instead of building and training M simple models, we use a single large model. The architecture of this model could be named “a collection of M weakly coupled elementary models”. Every elementary model is aimed at approximation of one diagnostic feature as a function of corresponding covariates according to expression (2). The elementary models are almost independent: the inputs of all elementary models are separate inputs of the NN, the outputs of the elementary models are separate outputs of the NN. For example, for M=4 and a single hidden layer in each elementary model, the architecture might look as shown in Fig.7.
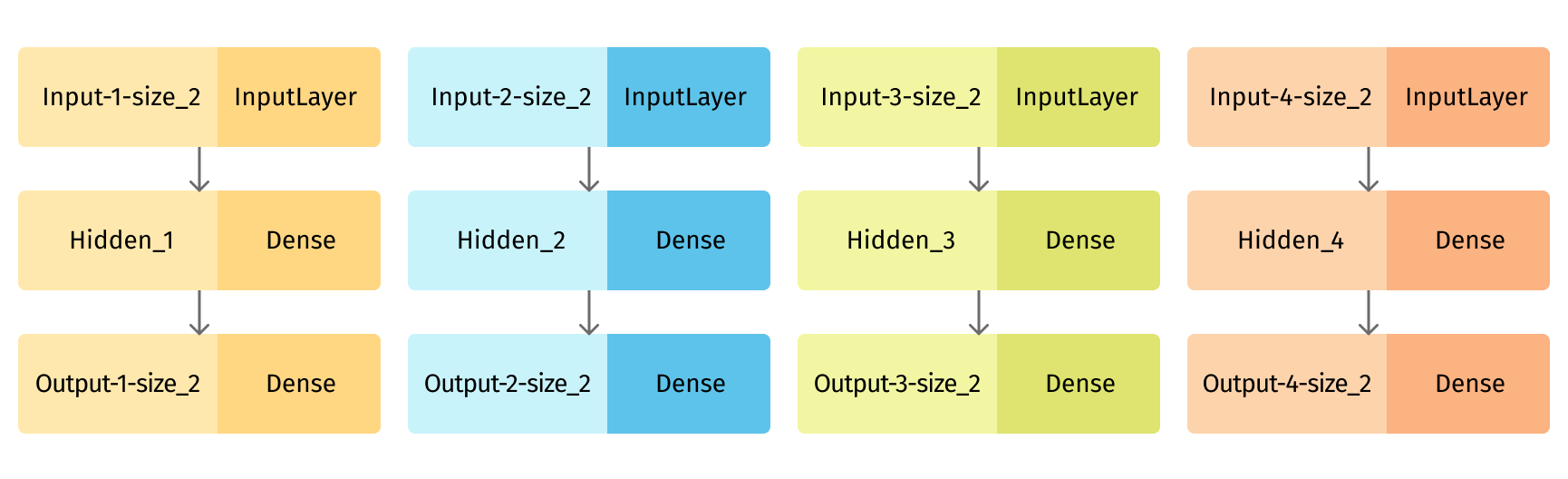
The resultant loss value of such a multi-output NN is the sum of the loss values corresponding to particular outputs. Therefore, as long as the loss values are non-negative, training of such a large NN via gradient-descent algorithms is mathematically equivalent to training each simple elementary model separately. The training algorithms used in modern ML platforms are highly optimized for both computing time and memory footprint. This efficiency makes the training of a single large model comprising $M$ elementary submodels much more efficient and easier to maintain than building and training each elementary model separately.
The ultimate goal of this model in our approach is to predict values of primary diagnostic features $f_i$ expected in a healthy state of the system. The initial data for such prediction are the observed values of the corresponding covariates $(x^{(i)}_1, \ldots, x^{(i)}_{M_i}), i = 1,\ldots,M$.
5.5 Computation of the secondary features
Primary diagnostic features $f_i$ could be of arbitrary physical dimensions. Or they could be dimensionless but take values at different scales and orders of magnitude. It is important to note that the values of primary features in a healthy state of the system can vary grossly depending on the values of the corresponding covariates. Although the primary features could be used directly for anomaly detection, their high variability and dependence on other variables can be a serious stumbling block. Here we describe an ML-based procedure which is capable of radically alleviating this shortcoming. The procedure transforms primary diagnostic features $f_i$ into corresponding secondary features $S_i$.
Firstly, the ML model described above in subsection 5.4 is trained on the data corresponding to the healthy state of the system. A new datapoint for the $i$-th primary feature is described by the observed value $f_{i}$ of the feature (as computed from the raw sensor data) and by the observed values of the corresponding covariates $x_{i,1}, \ldots, x_{i,N_i}$. Prediction of the trained model for these values of the covariates is:
$$
\hat{f}_i = \hat{F}_i(x_{i,1}, \ldots, x_{i,N_i}), i = 1, \ldots, M. \qquad (3)
$$
Here $\hat{F}_i, i=1, \ldots, M$ are the M functions describing our trained model, and $N_i$ is the number of covariates for the $i$th partial submodel. These are our estimates of the true functions $F_i(\cdot)$ in expression (2).
Then, our secondary statistics (features) $S_i$ are computed as a simple ratio of the observed values $f_i$ to the expected values $\hat{f}_i$ predicted by the ML model from the current values of the corresponding covariates:
$$
S_i = \frac{f_i}{\hat{f}_i}. \qquad (4)
$$
Consider first an ideal case where the observed values $f_i$ of the diagnostic features are deterministic functions $F_i(\cdot)$ of the corresponding covariates. Then, in the healthy state of the system, the values $S_i$ of the secondary features (4) are close to the unit value. Slight deviations of $S_i$ from 1.0 could be caused only by imperfections of our trained ML model. Then, a noticeable increase of $S_i$ in respect to the unit value could be a sign of some anomaly.
In reality, functions $F_i(x_1, \ldots, x_{N_i})$ in expression (2) are random, not deterministic. This means that the normal (healthy) values of diagnostic features cannot be predicted from the covariates exactly. Nevertheless, as long as the ML model is capable of predicting feature values $f_i$ from the covariates with a reasonably small error, the following property takes place. In a healthy state of the system, the values of our secondary features $S_i$ fluctuate around the unit value, and the range of the fluctuations is much less than that of the primary diagnostic features $f_i$.
Thus, in contrast to the primary diagnostic features $f_i$, our secondary features $S_i$ are interpretable in a unified way irrespective of the nature of the signals from the physical sensors and the algorithm used to compute the primary features. These properties of the secondary features $S_i$ are of major practical importance. We will also illustrate this point with the following computational experiment.
5.6 Properties of the secondary features
For illustration of the basic properties, we have simulated a case of 40 primary diagnostic features. We use simulated datasets here to keep our client’s data private. The functions $F_i(x_1, x_2), i = 1,\ldots,40$ of two covariates were chosen randomly from a parametric family of such functions implemented in our generator of synthetic test datasets. The randomness in the healthy state of the system was simulated via multiplicative noise. Values $f_i = F_i(x_1, x_2)$ were multiplied by a random variable obeying the chi-squared distribution with 16 degrees of freedom normalized to a unit expected value. The training dataset corresponding to the healthy state was formed of 1000 data points for each feature. The covariates $x_1, x_2$ were chosen randomly from a uniform distribution. An ML model described in 5.4 was built and trained using the standard procedures within the Keras/Tensorflow platform using Google Collaboratory notebooks.
The dataset for testing was formed in the same way as described above, but anomalies were artificially introduced into two features. The anomalies were simulated as an addition of a linearly increasing positive term to the observed value $f_i(t)$. Both anomalies start from zero value and linearly increase to some maximal value at the end of the time interval. The maximal value is much smaller for the first anomaly, which makes it more difficult to detect. Such a model of anomalies corresponds to a gradual deterioration of a module resulting in its fault. Normally, the goal of the health monitoring system is to detect such gradually developing anomalies as soon as possible.
The baseline approach we use for comparison rests on analysis of the primary features $f_i$ themselves. We normalize them first via division by the average value observed on the training dataset. As far as the features behave like anomaly scores, the approach is often used in practice, and hence, we call it the “traditional” approach. Although both the traditional approach and ours are capable of detecting anomalies, the goal of the comparison is to ascertain which approach is more sensitive, i.e. capable of detecting the gradually growing anomalies earlier.
The results of our simulation are shown in Fig.8. Values of each feature are represented by colors within the corresponding horizontal lane. The horizontal axis represents time, and the vertical axis represents the ordinal number of the feature. The maximal value of the color scale (shown to the right of the image) is chosen as the 99.75-th percentile of the corresponding feature values obtained on the training dataset (the healthy state of the system).
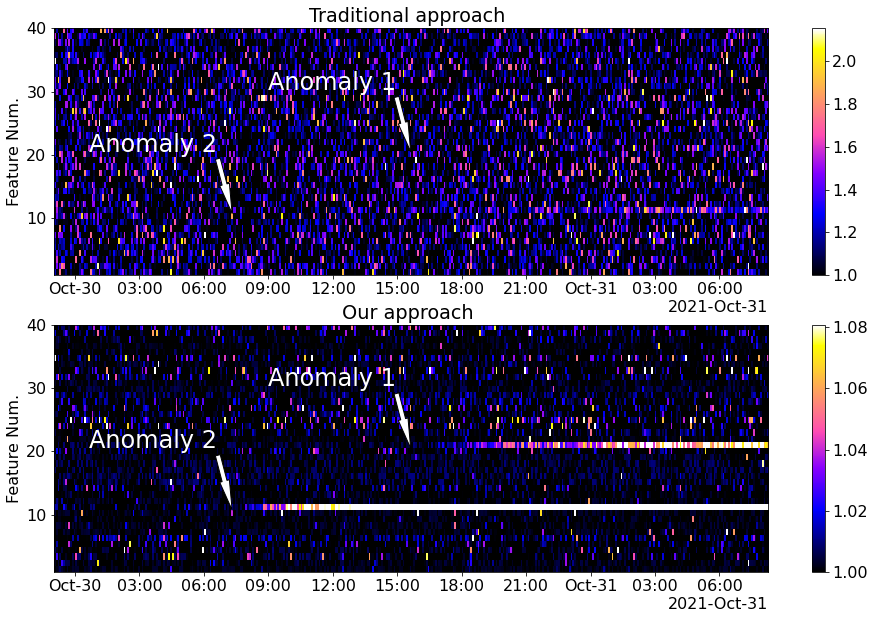
The first anomaly affects feature #20 and starts approximately at 15:00. The second anomaly affects feature #10 and starts approximately at 7:00. The starting points of the two anomalies are marked by arrows. It is clear from the comparison between the top and bottom figures that our approach outperforms the traditional one in respect to sensitivity. The weaker anomaly #1 is not detectable at all by the traditional approach (the top image), but is detectable by our approach after 5-7 hours after the beginning (the bottom image). The stronger anomaly #2 is weakly detectable by the traditional approach only at the end of the time interval, while it is clearly detectable by our approach almost from the very beginning.
To increase the sensitivity of both methods one could use averaging in a sliding window. The results for both approaches are shown in Fig.9. The sensitivity of both approaches has increased, but our approach still provides much better results.
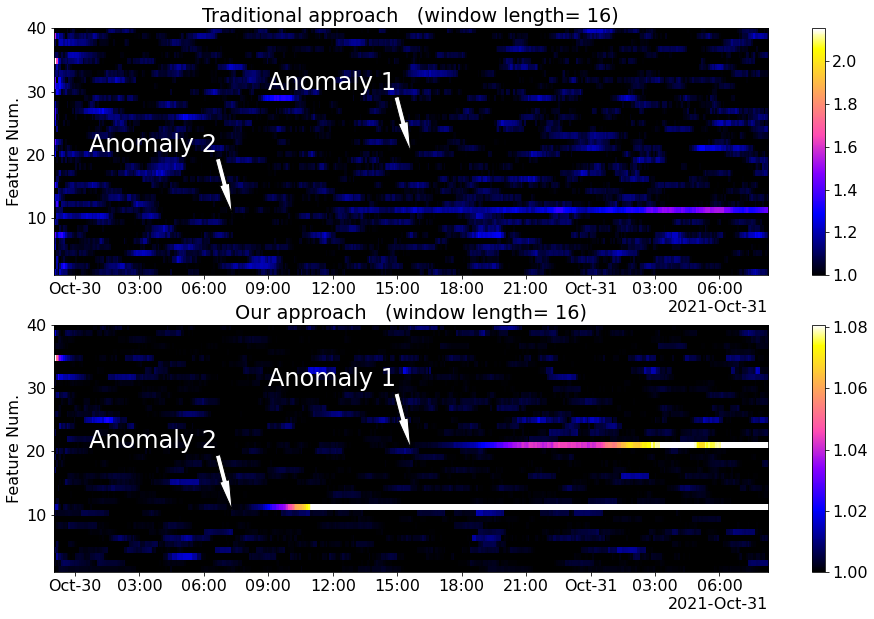
The essentially higher sensitivity of our approach is explained by the use of the normalization procedure (4), where the denominator is an ML-prediction of the value of the primary diagnostic feature. Without such a normalization - as in the traditional approach - the value of the primary diagnostic feature $f_t$ may vary drastically in a healthy state of the system. This variability is a significant nuisance factor for detection of anomalies. It is explainable by changes in covariates. In our approach, this variability is reduced significantly due to the additional normalization via our ML-based procedure (4) that takes the effect of covariates into account.
5.7 Localization of faults and interpretability of decisions for individual features
The procedure described above - if accompanied by a threshold-based decision algorithm - is capable of detecting anomalies in automatic mode. The threshold values can be chosen on the basis of the training dataset corresponding to a healthy state of the system. As long as the feature characterizes a particular submodule of the whole system, the detection of an anomaly in this particular feature is equivalent to its localization within the whole system.
The interpretation of such decisions for human beings is also quite easy. Moreover, explanations in a human-readable form can be generated automatically. Suppose, for example, a statistically significant increase in the value of a feature $S_i$ has been found. It is known that the feature corresponds to the intensity of the vibration of a particular bearing. Then, the explanation of the decision is straightforward: “The RMS of the vibration signal from the bearing X in the electric motor Y of machine Z has exceeded 2.5 times its normal level predicted by our ML-model for given values of the rotation speed and the torque at the shaft (the covariates of this feature). Such a large value of the feature has never been observed at the healthy state of the system represented by the training dataset. The estimated probability of such an event is only 10^{-5}. Therefore, we conclude that this particular bearing is in an abnormal state.”
6. Dealing with the higher levels of the hierarchy
The procedure described above in section 5 results in computation of secondary features $S_i$. They are computed on the basis of the corresponding primary features $f_i$ and predictions $\hat{f}_i$ of our ML model. Here we outline the further steps of data processing at the higher levels of hierarchy.
6.1 Aggregation at the next levels of hierarchy
In most cases we cannot limit the consideration by a single feature $S_i$, as we did in section 5. Even a single subunit at the lowest level of the hierarchy - like a bearing from our example - is often characterized by more than one feature. For instance, the state of a bearing is represented by several primary features $f_i$ computed from the vibration signal: RMS, kurtosis, crest factor, shape factor, etc. Therefore, for each elementary subunit - i.e. at the first level of hierarchy - we aggregate the corresponding secondary features $S_i$ into a single anomaly score $a$ via some aggregation function:
$$
a^{(1)}_{k} = A(S_{k,1}, \ldots, S_{k,M_k,}), \quad k = 1, \ldots, K. \qquad (5)
$$
Here and below, the upper index corresponds to the level of the hierarchy, and here the index is $(1)$ because we consider submodules - the first (the lowest) level of the hierarchy; $k$ is the index of the particular submodule; $S_{k, i}$ is the $i$th secondary feature of the $k$th submodule; $M_k$ is the number of features characterizing the $k$th submodule; $A(\cdot)$ is the aggregating function.
At the next levels of hierarchy, for each unit we aggregate the anomaly scores $a_i$ from the lower level subunits into a single anomaly score. For example, we need to compute the anomaly score $a^{(3)}_k$ of a particular ($k$th) machine. The upper index here is $(3)$ because machines are the third level of the hierarchy in our example assembly line. We aggregate anomaly scores $a^{(2)}_i, i=1,\ldots,M_k$ of the $M_k$ modules of the $k$th machine into a single anomaly score of this machine as a whole. It is because the health status of the machine logically depends on the health status of its constituents (modules), like electric motors, bearings, actuators, etc. The process is illustrated in Fig.3 above. The idea is repeated recursively at each level $L$ of the hierarchy. Thus, anomaly scores $a$ are calculated in the following way from the anomaly scores of subunits from the lower level:
$$
a^{(L)}_{k} = A(a^{(L-1)}_{k,1}, \ldots, a^{(L-1)}_{k,M_k,}), \quad k = 1, \ldots,K_{L, k}. \qquad (6)
$$
Here, the upper index $(L)$ denotes the layer number $L$ in the hierarchy; $k$ is the index of the unit at the given ($L$th) level (e.g. a machine); $a^{(L-1)}_{k,j}$ is the anomaly score of the $j$th subunit (e.g. a module of the machine) of the given ($k$th) unit; $K_{L,k}$ is the number of subunits of the $k$th unit at level $L$. See also Fig.3.
6.2 Two approaches to aggregation of anomaly scores
There are at least two general ways to aggregate secondary features $S_i$ or anomaly scores $a_i$ into a single anomaly score $a_{agg}$. The first approach is to start from making individual binary decisions for each anomaly score $a_i$ to be aggregated. This can be done via a thresholding procedure which provides healthy/anomalous binary decisions. Then, one aggregates these binary decisions by, say, a simple OR logical function. The rationale is straightforward: if at least one subunit of a particular unit is anomalous, then the whole unit is considered anomalous. And only if all subunits are healthy, then the whole unit is classified as healthy.
This problem of aggregating individual binary decisions is not as simple as it appears at first glance. It boils down to a hot topic in applied and theoretical statistics: the ”multiple comparisons problem” (a.k.a “multiple hypotheses tests”, “simultaneous statistical inference”) [6]. Suppose we make decisions in the spirit of the Neyman-Pearson criterion, i.e. we try to keep the false positive rate at a prespecified level $\alpha$, and we can calculate the threshold value for given $\alpha$. Let the desired false positive rate of the final aggregated decision be $alpha_{agg}$. The problem is how to calculate the significance levels $alpha_i$ for individual decisions made by comparing anomaly scores $a_i$ to some thresholds. It is obvious that partial significance levels $\alpha_i$ should be lower than the family-wise significance level $\alpha$, and the greater the number of scores to be aggregated, the greater the difference. However, finding exact relationships poses a serious mathematical problem because $a_i$ could be not independent statistically, and the dependence is usually not known in practice [7].
Another general approach is to start from aggregating the individual anomaly scores $a_i$ into a single anomaly score $a_agg$, and only then make a final decision on the basis of $a_agg$, e.g. via a thresholding procedure. There are examples in classical statistics when such a type of aggregation is much more efficient than the first method described above, especially for low signal-to-noise ratio. This idea is also widely used in radars and in radio science at large as “coherent integration”. Therefore, we try to build our aggregation algorithms on the basis of this general idea. In the next subsection we illustrate the superiority of the second approach to aggregation.
6.3 Quantitative comparison of the two approaches to aggregation
Here we perform a computational experiment to illustrate our main point from the previous subsection - that aggregation of anomaly scores or features is often more efficient than aggregation of individual binary decisions. We have performed statistical simulation of the two methods of aggregation. The aggregated values $a_i$ in this experiment obey chi-square distribution with 16 degrees of freedom normalized to a unit mean value. This distribution corresponds to the null hypothesis - that the system is healthy. For a healthy system we expect the secondary features $S_i$ and anomaly scores $a_i$ to be distributed around the unit value. And anomalies manifest themselves in the tendency of the values to exceed 1.0 significantly.
The quality of detection procedures and their mutual comparison is normally performed using “receiver operating characteristics” (ROC curves). The ROC curves show the dependence of the true-positive rate on the false-positive rate. The higher the curve on the plot, the better the corresponding detection procedure.
Fig.10 shows the ROC curves obtained for two different numbers of aggregated features -10 and 100 - with equivalent statistical properties. Each panel (left and right) depicts two ROC curves, which characterize the two essentially different approaches to the aggregation. The blue curve corresponds to aggregation of individual decisions, when binary decisions are made first for individual features (anomaly scores), and then, the decisions themselves are aggregated into a single final decision about the health of the whole machine. Here a simple OR scheme has been used for the aggregation. The red curve corresponds to the opposite approach, where individual features or anomaly scores are aggregated first, and only then the final decision is made on the basis of the single aggregated feature. In this illustrative example we used a simple aggregation via averaging.
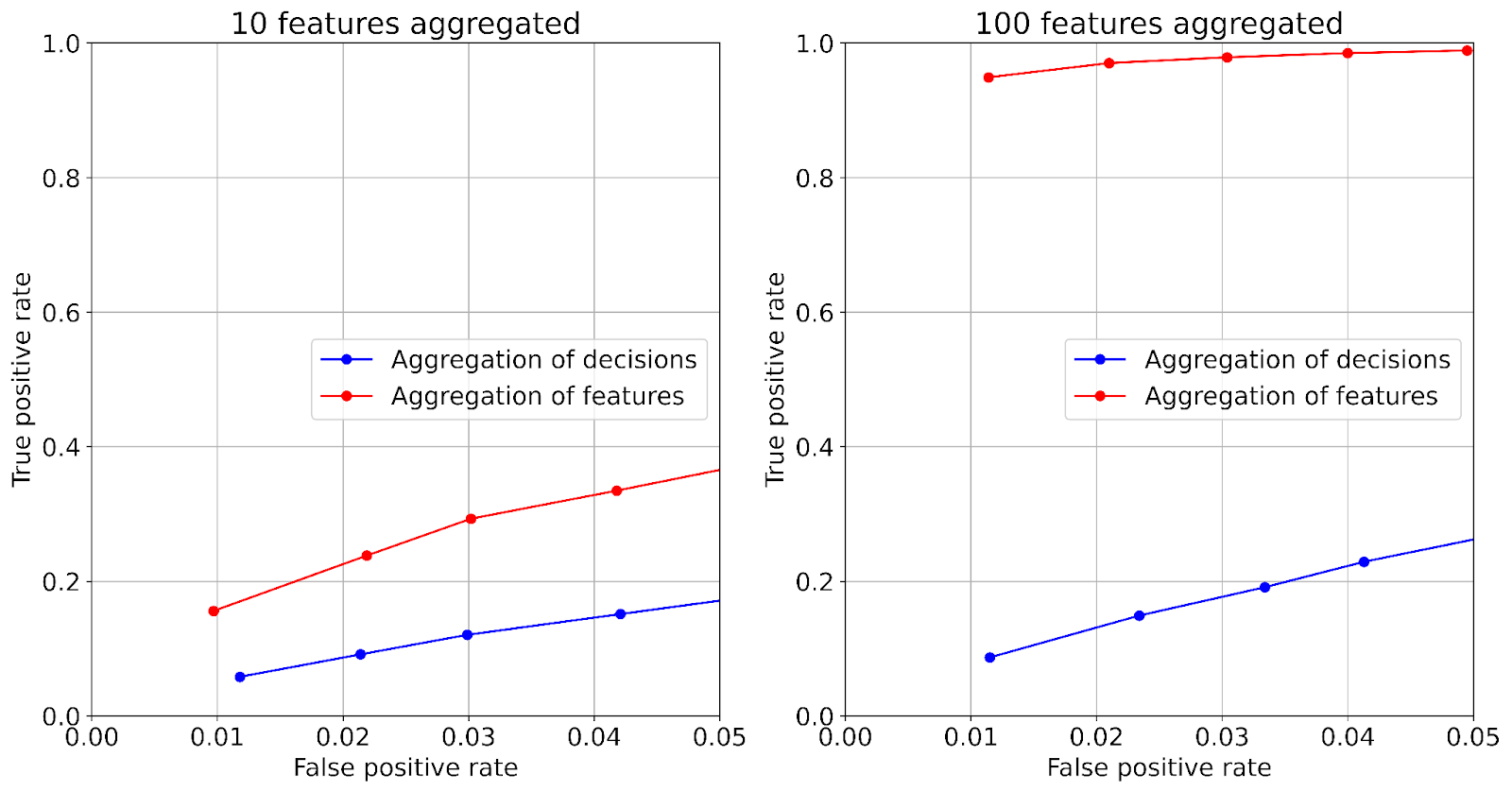
Two fundamental peculiarities are noticeable from Fig.10:
- The aggregation of features produces significantly better results than the aggregation of individual binary decisions: the red ROC-curves run higher than their blue counterparts.
- The superiority of the second approach - aggregation of features - is more pronounced when the number of aggregated features is greater: the red curve on the right image outruns the blue one to a much greater extent than on the left image.
6.4 Aggregation of anomaly scores helps to detect otherwise undetectable “dispersed anomalies”
Scenarios can occur where anomalies manifest themselves not in a single subunit, but in a great fraction of subunits simultaneously. Such “dispersed anomalies” are not rare in practice. Many individual features or anomaly scores start to deviate slightly from their healthy values, but the deviations are not statistically significant. Such a scenario could arise, for example, when the whole machine is affected by some nuisance factor. For instance, we have come across a case where a machine for precise mechanical processing was affected by parasitic vibration from a faulty cooling system nearby. Many vibrations and positioning sensors installed within the machine produced slightly elevated anomaly scores, but these changes were too small to be classified as anomalous. Only the aggregated plots helped to identify the anomaly.
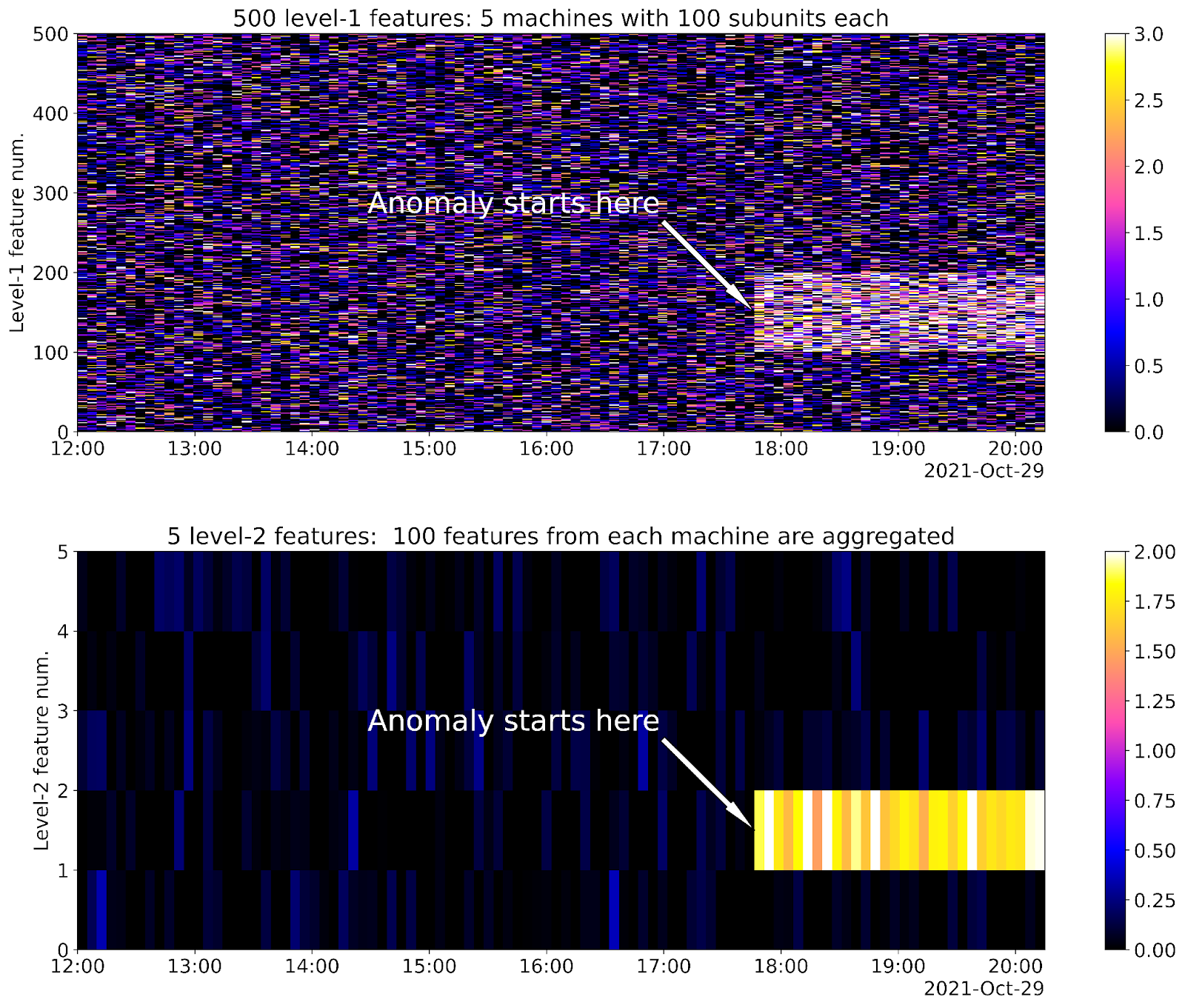
Fig.11 illustrates a case of a “dispersed anomaly” from our simulator. There are 5 machines, and each machine comprises 100 modules. Each module generates a secondary feature (anomaly score).
Consecutive values of all the 500 features are presented by horizontally arranged pixels at the top image. The values are transformed into colors according to the given colormap. Each hundred of the 500 features corresponds to a particular machine, i.e. features 1-100 characterize machine #1, features 101-200 characterize machine #2, etc. The bottom image shows 5 aggregated features characterizing the health of the machines as a whole. Here we used a simple method of aggregation via averaging. For the convenience of visual perception we extended the pixel 100-fold in vertical dimension to preserve the location at the time-feature plane. At about 17:50, machine #2 gets into an anomalous state. At this anomalous state all 100 corresponding features tend to get somewhat higher values than in the healthy state. The anomalous area is noticeable at the top (not aggregated) image, and it is very clearly seen at the bottom (aggregated) image. The increase in the contrast due to the aggregation procedure is obvious.
A more interesting case is shown in Fig.12. The only difference in respect to the previous case is that the intensity of the anomaly is much lower. The anomaly is almost not noticeable at the top image with individual, non-aggregated anomaly scores. But the anomaly is still clearly noticeable at the bottom image with aggregated features.
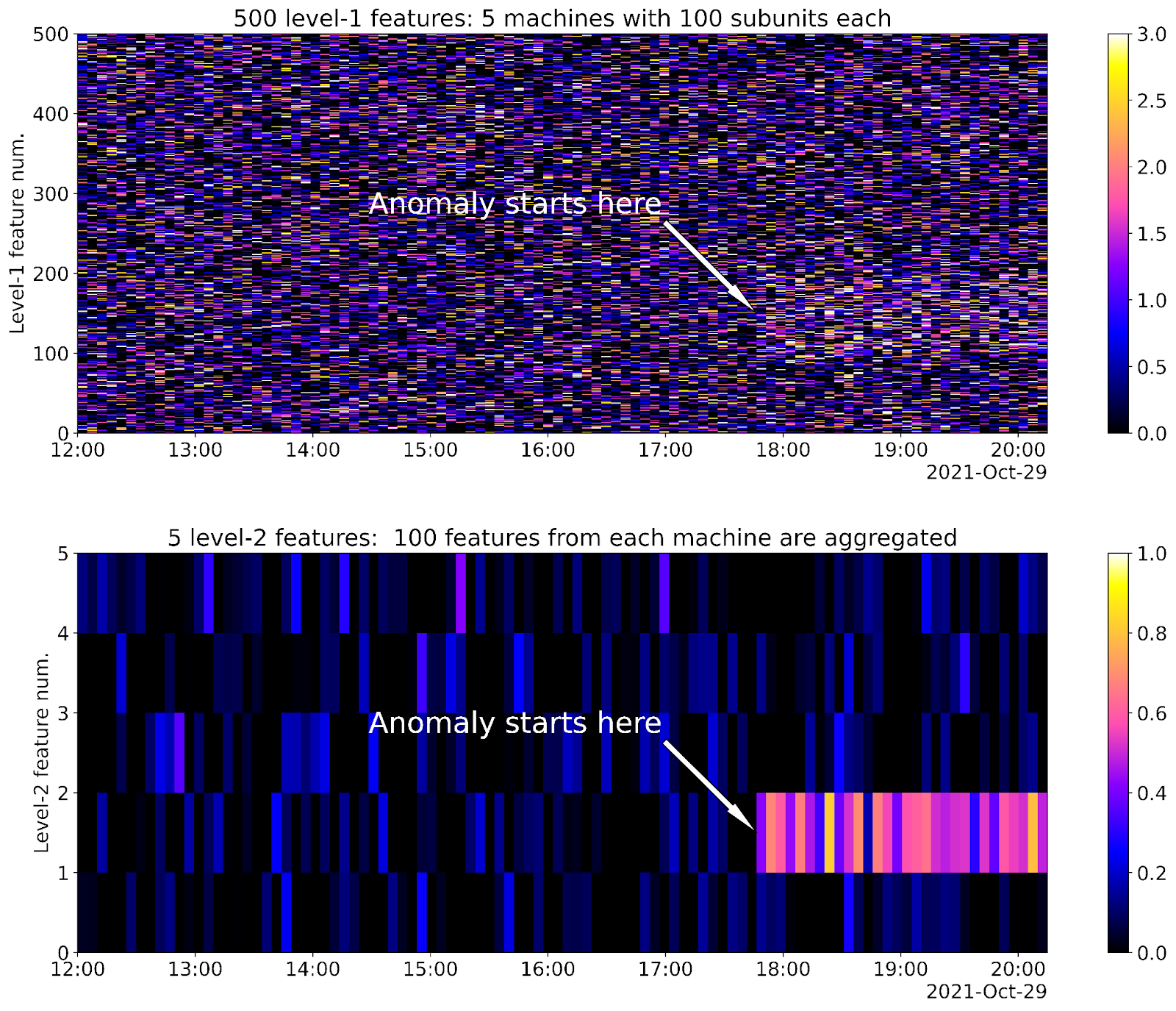
The results of the simulation shown on Fig.12 illustrate the capability of aggregated anomaly scores to detect anomalies not detectable at the level of individual anomaly scores.
7. Advantages of the methodology
7.1 Most faults could be reliably localized
A vast majority of faults originate from a failure in a single element. Suppose such elements are monitored by primary physical sensors, and anomaly scores are computed for each element. Then significant increase in the corresponding anomaly score bears unambiguous information about the localization of the fault. It is a natural consequence of the hierarchical decomposition approach used here and starting analysis from the lowest level of the hierarchy. See also subsection 5.7 for more details.
7.2 Ease of parallelization
Most of the computing resources in our approach are required for computing primary features $f_i$ and corresponding values of secondary features $S_i$ as described in section 5. It is essential here that these computations for one feature can be made independently on other features. This makes it possible to perform the computation in parallel on different CPUs.
The ML model used in our approach (subsection 5.4) is also well suited for parallelization. It consists of elementary subunits that can be trained independently. The only reason we have joined all the subunits into a single ML model is for computational efficiency. Equally reasonably, the units can be distributed between several such models and can even be trained/evaluated separately. Such computational independence of subtasks is an essential prerequisite for easy parallelization.
7.3 Interpretability of decisions
The hierarchical approach here implies that primary detection is carried out starting from the lowest level of the hierarchy, i.e. from the most elementary subunits. Most anomalies are localized within particular subunits. Therefore, when a subunit is classified as anomalous, one knows both the localization of the anomaly and the corresponding values of the primary and secondary diagnostic features $f_i$ and $S_i$. Therefore, human-readable explanations can be easily, and even automatically, generated (see subsection 5.7 for more details). The interpretability of decisions in our approach is predetermined by the mutual correspondence between the intrinsic hierarchical structure of the industrial system itself and the hierarchical structure of the decision-making algorithm we build.
7.4 Scalability of solutions
The increase in the number of elementary low-level units in the industrial system in our approach requires a proportional increase in the number of independent elementary tasks to be solved. As long as the tasks are mutually independent and can be easily run in parallel (see subsection 7.2), even a radical change in the scale of the system does not require any essential changes in the methodology. For example, if the number of units and features has increased 10 times, then we might just order 10 times more virtual CPUs in the cloud service. At the same time, the methodology and the algorithms remain essentially the same.
7.5 Robustness to modifications of the diagnosed system
Some changes, especially minor ones, occur in real complex industrial systems quite frequently. For example, a bearing has been replaced, or an additional stage of processing has been added with a corresponding device. Such changes often affect only a small fraction of the elementary subunits. A desirable trait of any technology is “small changes require small additional work”. This is not the case, for example, in the approaches oriented at a single large feature vector describing the whole system. In contrast, the methodology we describe here definitely possesses such a trait. It is because the detection of anomalies starts from the most elementary subunits and, hence, a change in a unit results in changes only in the corresponding procedures.
7.6 Matching the edge computing paradigm
Distributed computing has become a rule rather than an exception. Our clients, for example, often have strong preferences for cloud-based solutions. The paradigm of “edge computing” becomes more and more popular in the realm of distributed computing. The basic idea is quite simple, straightforward, and understandable: we try to carry out as much primary data processing near the data source as possible. This saves both the bandwidth for transmission of secondary data and the expensive computational resources of the cloud services. This also allows a reduction in latency and an increase in the reliability of the diagnostic system at large.
The hierarchical approach we describe here is well suited for implementing the principles of edge computing. Most of the computational power is required for computing the primary diagnostic features $f_i$ from the raw signals arriving from IoT sensors, and then, for computing the corresponding secondary features $S_i$. As long as both $f_i$ and $S_i$ are independent of most other features, their computation could be performed close to the source of the corresponding signals, for example, using an embedded CPU.
8. Caveats
The description of our approach in this article is rather schematic, simplified, and illustrative. Here we list some points where real implementations may differ.
8.1 The hierarchy may be not strict
The strict hierarchy in our example system - the assembly line described in subsection 3.2 - is an idealized version of reality. We used it here only for illustrative purposes. In real industrial systems the hierarchy may deviate from this idealized picture: some primary features may not correspond to the most elementary subunits. For example, an electric motor (a module of our example system) consists of 3 submodules: two bearings and the rotor. Suppose there are temperature and vibration sensors installed on the case of the motor. The sensors generate primary features $f_i$ describing parameters of the electric motor as a whole. In other words, these primary features $f_i$ are related not to the lowest level, but describe a whole unit one level up. Such imperfections of the hierarchy do not affect the workability of our approach, but can complicate subjective perception of the system.
8.2 The ML model may be more complex than described here
The ML model described in subsection 5.4 is based on independent submodels for each particular primary feature $f_i$. Sometimes, we find rather strong correlations between the prediction errors of particular primary features $f_i$. Then, we might group such strongly correlated features and use more complex submodels with more than one output: a separate output for each feature. In this case the loss function is also more complex than the standard ones because it should take the correlations into account.
Another deviation from the simple model described in 5.4 is the use of interval estimation in the model, not the point estimation as in the model we described earlier. In such an approach the model predicts not only the expected values of primary features, but also the ranges of their values corresponding to the healthy state of the system. Quantile regression is often a good choice for such types of models.
8.3 The aggregating procedures are often based on robust statistics
For simplicity, we used the simplest aggregating function here - the mean. In reality, the distribution of some primary features $f_i$ might have heavy tails, that is the values tend to take unusually high values from time to time even in a healthy system. In such cases we use more complicated averaging procedures based on robust statistics. A simple example of such robust statistics is the trimmed mean and the median.
8.4 The aggregating procedures may take correlations into account
The secondary features $S_i$ (at the lowest level of the hierarchy) and anomaly scores $a_i$ (at higher levels) can be mutually correlated. In such situations, we use aggregating procedures $A(\cdot)$ in expressions (5) and (6) more sophisticated than simple averaging. The reason is that taking the correlations into account sometimes allows for significant improvement of the properties of the aggregated anomaly scores.
Conclusion
In this paper we have described an approach to solution design for condition monitoring in complex industrial systems. Our approach rests on the following basic principles:
- Decompose a complex system into more elementary parts and start analysis from the most basic constituents;
- Split a single problem of high dimensionality into a great number of low-dimensional problems;
- Effectively utilize the data accumulated when the system was in its healthy state;
- Use the available domain knowledge whenever possible (for feature engineering, choice of relevant covariates, etc). We use non-traditional regression-based ML-models to implement these principles.
The approach helps us to achieve several goals simultaneously. Firstly, the sensitivity of anomaly detection procedures increases, and we are capable of providing earlier warning signals for predictive maintenance and more reliable detection of pre-faulty conditions. This, in turn, decreases the losses associated with unexpected faults and unplanned downtimes. Secondly, the development of the health-monitoring systems becomes simpler, faster, and cheaper. Thirdly, the maintenance cost of the final solution declines due to structural simplicity and relative independence of separate parts.
We expect that the usefulness of the approach will increase further with the advance of the philosophy and methodology of smart manufacturing, especially in complex industrial systems.
References
- S.Thudumu et al. “A comprehensive survey of anomaly detection techniques for high dimensional big data”, 2020, https://journalofbigdata.springeropen.com/track/pdf/10.1186/s40537-020-00320-x.pdf
- Y.He & I. Zeng “Double Layer Distributed Process Monitoring Based on Hierarchical Multi-Block Decomposition”, 2019, https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=8629083
- P.Perera, P.Oza, V.M. Patel “One-Class Classification: A Survey”, 2021, https://arxiv.org/abs/2101.03064
- D.V.Carvalho, E.M.Pereira, and J.S.Cardoso “Machine Learning Interpretability: A Survey on Methods and Metrics”, 2019, https://www.mdpi.com/2079-9292/8/8/832/pdf
- K.H.Hui et al. “An improved wrapper-based feature selection method for machinery fault diagnosis”, 2017, https://www.researchgate.net/publication/321958491_An_improved_wrapperbased_feature_selection_method_for_machinery_fault_diagnosis/download
- R.G.Miller Simultaneous Statistical Inference 2nd Ed, 1981, https://link.springer.com/book/10.1007/978-1-4613-8122-8
- A.Farcomen "A Review of Modern Multiple Hypothesis Testing, with particular attention to the false discovery proportion", 2008, https://pubmed.ncbi.nlm.nih.gov/17698936/