
Which Enterprise Data Warehouse performs better for your workloads?


In this article, we detail the results of our performance comparison of popular cloud-based Enterprise Data Warehouses using popular benchmarks. The goal of the investigation was not to do the most comprehensive comparison of them possible, but instead to uncover usable and valuable information to help you choose the most suitable system for your needs.
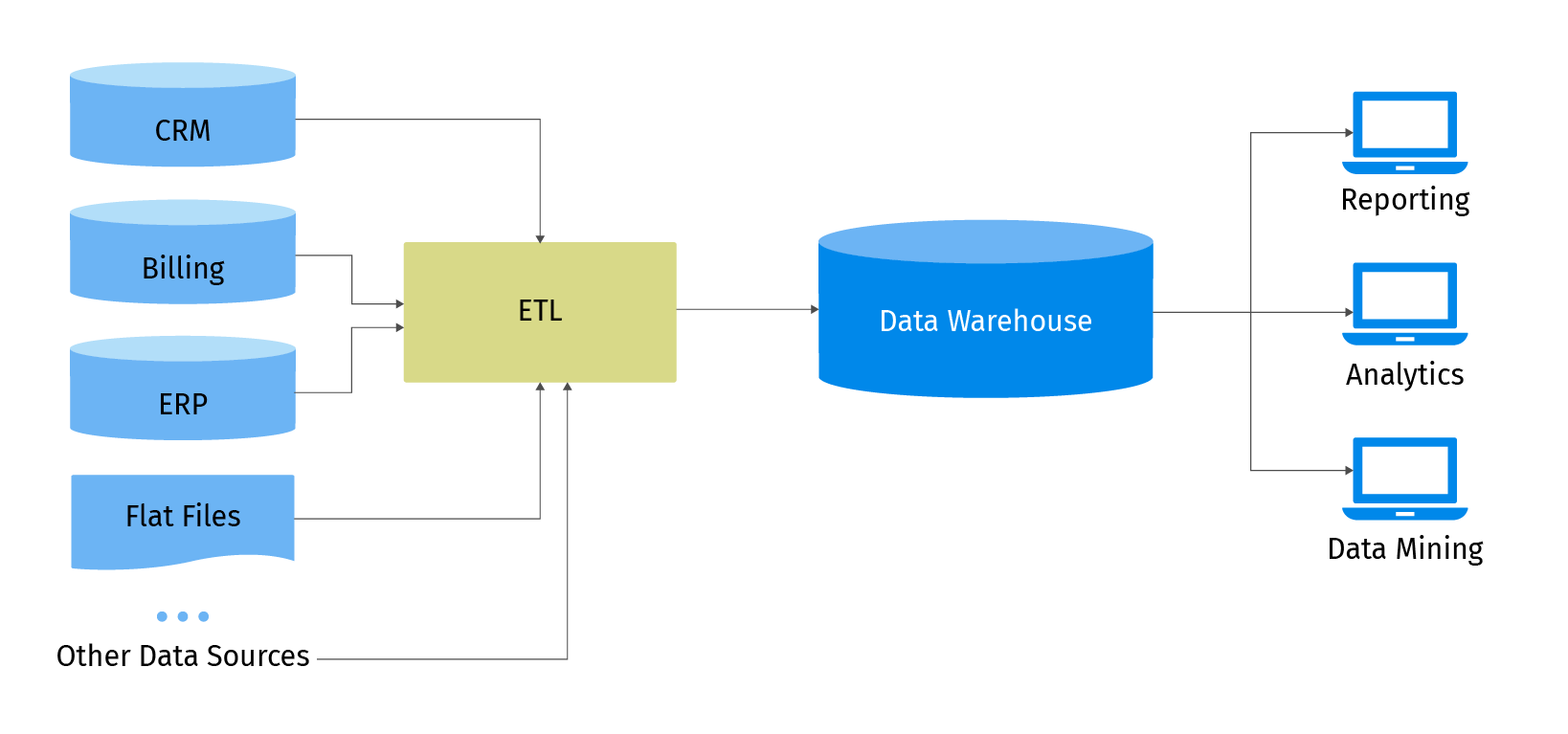
What is EDW?
Enterprise Data Warehouse (EDW) is an analytical database that collects data from different sources such as CRM, IoT, ERP, user interaction recordings, etc. It also provides an interface for data analysis.
The following provides an overview of the basic concepts:
- Structured storage - In contrast to Data Lakes, which store large amounts of unstructured data, EDW allows for a more convenient way to query data;
- Nonvolatile storage - Usually data is not updated or deleted by the end user. Sometimes non-relevant data may be cleared out during regular maintenance;.
- Subject-oriented - Data structured to reflect the business model of a particular domain.
- Time-dependent - Warehouses usually store historical data like events.
Amazon Redshift
Redshift is a cloud data warehouse that achieves efficient storage and optimum query performance through a combination of massively parallel processing, columnar data storage, and targeted data compression encoding schemes. Redshift has node-based architecture where you can configure the size and number of nodes to meet your needs. Scalability is available at any time.
The Redshift Query Engine is based on PostgreSQL 8.0.2 and has the same SQL syntax with the following supported features:
- SQL or Python(2.7) UDF;
- Stored procedures;
- Auto-compression;
- Views and materialized views;
- Querying external data;
- And many more.
However, it is important to note that Redshift doesn’t support some data types. A full list of unsupported features, data types, and functions is available here.
Redshift supports connection to the cluster through ODBC, JDBC drivers, and psql terminal-based front end tools from PostgreSQL.
Redshift architecture:
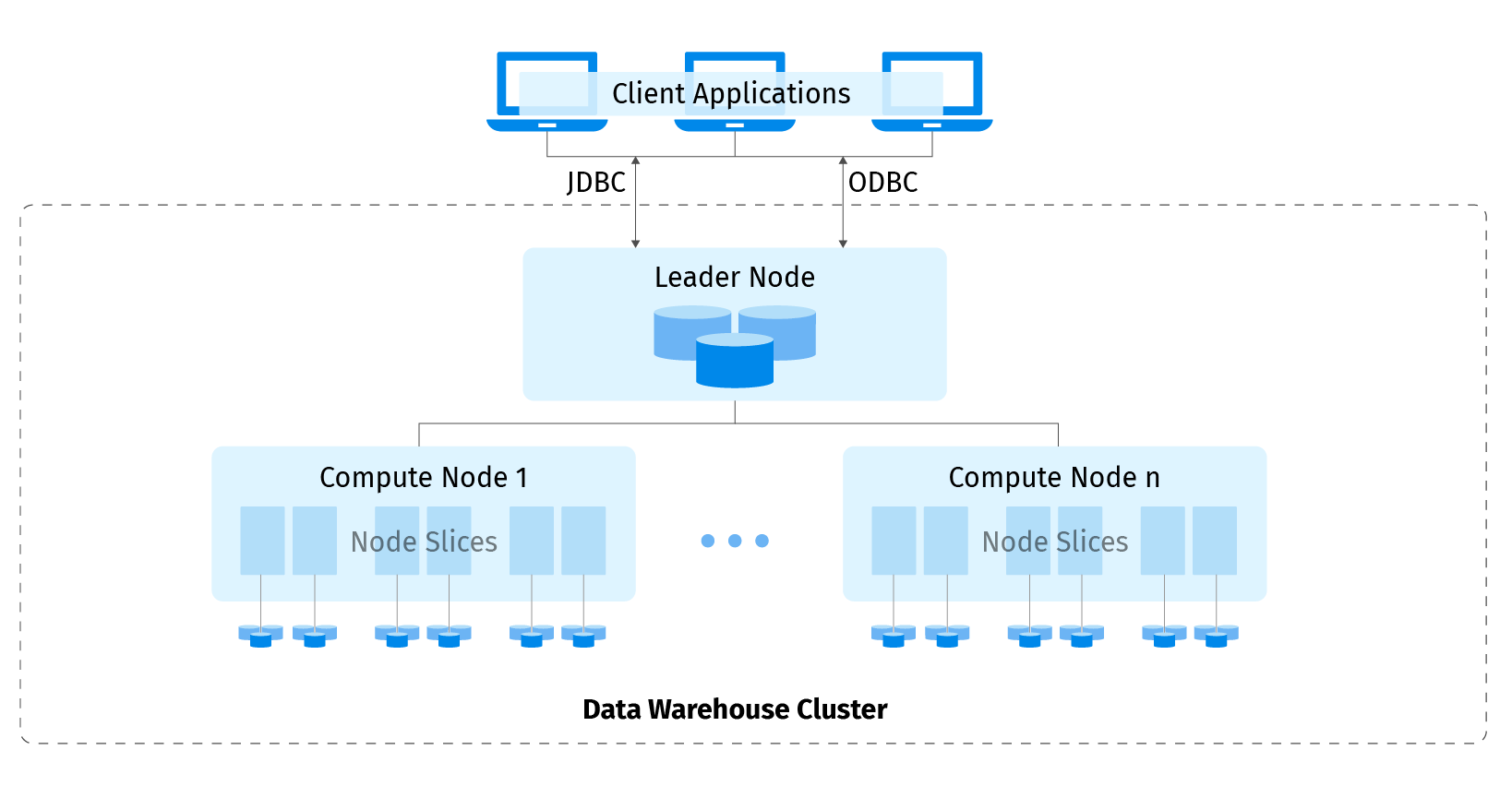
The leader node in an Amazon Redshift Cluster manages all external and internal communication. It is responsible for preparing query execution plans. Once the query execution plan is ready, the leader node distributes the query execution code on the compute nodes. In addition, it assigns data slices to each compute node.
Compute nodes in their turn are responsible for the actual execution of queries. A compute node keeps from 2 up to 32 slices. Each slice consists of a portion of memory and disk space in the compute node.
The following diagram shows a high level view of the internal components and functionality of the Amazon Redshift data warehouse:
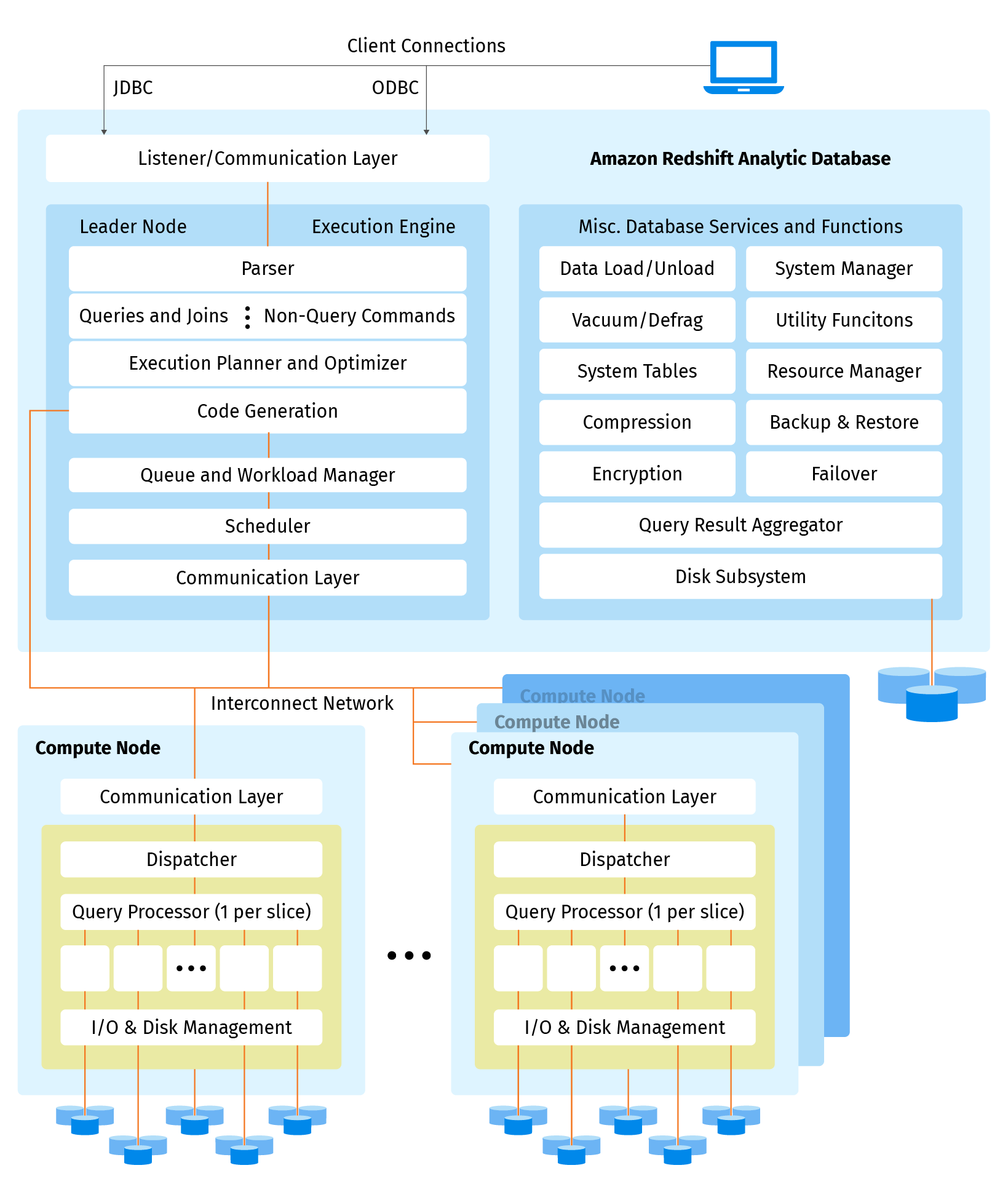
For durability purposes, Redshift maintains three copies of the data during a 1-day retention period with no additional charges. However, the period can be expanded for up to 35 days.
The architecture has the following disadvantages:
- Number of columns in the table is limited to 1600 - the lowest value compared with competing architectures.
- Number of concurrent queries is limited to 50 - the lowest value compared with competitors.
- The cluster becomes read-only during the resize operation.
- INSERT and DELETE operations heavily influence overall query performance (EDW wasn’t designed as OLTP though).
- Requires manual run of the VACUUM command for re-sorting rows and re-claiming space for better performance.
- Available space for data is limited by cluster size.
- Doesn’t support semi-structured data types.
Redshift provides a Workload Manager (WLM) that allows you to flexibly manage priorities within workloads. Automatic WLM determines the amount of resources that queries need and adjusts the concurrency based on the workload. When queries require large amounts of resources in the system, the concurrency is reduced. In contrast, manual WLM gives you the ability to specify values for query concurrency for up to 50 concurrent queries as well as memory allocation. The default concurrency for manual WLM is five queries, and memory is divided equally between all five.
The following design decisions heavily influence overall query performance:
- Sort key: determines the order in which rows in the table are stored. It enables the query optimizer to read fewer chunks of data by filtering out the majority of it.
- Distribution Styles:
- EVEN: data is stored in a round-robin fashion (used when joins are not required on the table);
- KEY: rows with matched values in specified columns are stored in the same slices (useful when the table is fairly large and used in joins);
- ALL: leader nodes maintain a full copy of the table on all computing nodes (used for small tables that don’t change often).
- Cache results: Redshift caches the results of certain types of queries in memory on the leader node for 24 hours.
- VACUUM command: re-sorts rows and reclaims space in the cluster. Used after insert or delete operations on the table.
- ANALYZE command: updates the statistical metadata for the query planner. Redshift automatically updates the metadata, but you can run it manually to make sure the metadata is updated.
Pricing of compute resources and storage is combined: you pay only for provided nodes per hour, with an unlimited number of executed queries within that time.
While running performance comparisons we noticed that Redshift provides useful information via charts on CPU utilization for each node in the cluster, the number of open connections, disk space usage, and much more. It is also worth noting that there was a case when a cluster got stuck. We were executing queries from the “inner and left join” category and noticed that the number of queued queries rose to 500. The root cause was overloading of the cluster and system queries couldn’t be executed. To overcome this issue we decreased the number of concurrent queries for all data warehouses in the specified category.
Snowflake
Snowflake is an analytic data warehouse provided as Software-as-a-Service. Ongoing maintenance, management, and tuning is all handled by Snowflake. It resides on AWS, Google Cloud Platform, or Microsoft Azure in a restricted number of available regions. Its features and services are identical across regions except for some that are newly-introduced.
The Snowflake EDW uses a new SQL database engine designed for the cloud. Queries execute on virtual warehouses, which are a cluster of compute resources. Snowflake offers a predefined size of virtual warehouses with auto-suspension and auto-resumption. To meet user concurrency needs, multi-clustered virtual warehouses are available. Resizing enables you to experiment with the most suitable performance at any time, without stopping the entire warehouse. Data is divided across nodes in the cluster.
Snowflake supports standard SQL including a subset of ANSI SQL:1999 and the SQL:2003 analytic extensions.
Supported features:
- SQL or Javascript UDF.
- Stored procedures.
- Auto-compression.
- Views, materialized views, and secure.
- Querying external data.
- And many more.
Syntax of the SQL queries is the same as in Redshift, except for the names of the particular functions. You can connect to Snowflake using Python, Spark, or Kafka connectors or JDBC, ODBC and .NET drivers or SnowSQL CLI client.
Snowflake has a unique architecture compared to its competitors:
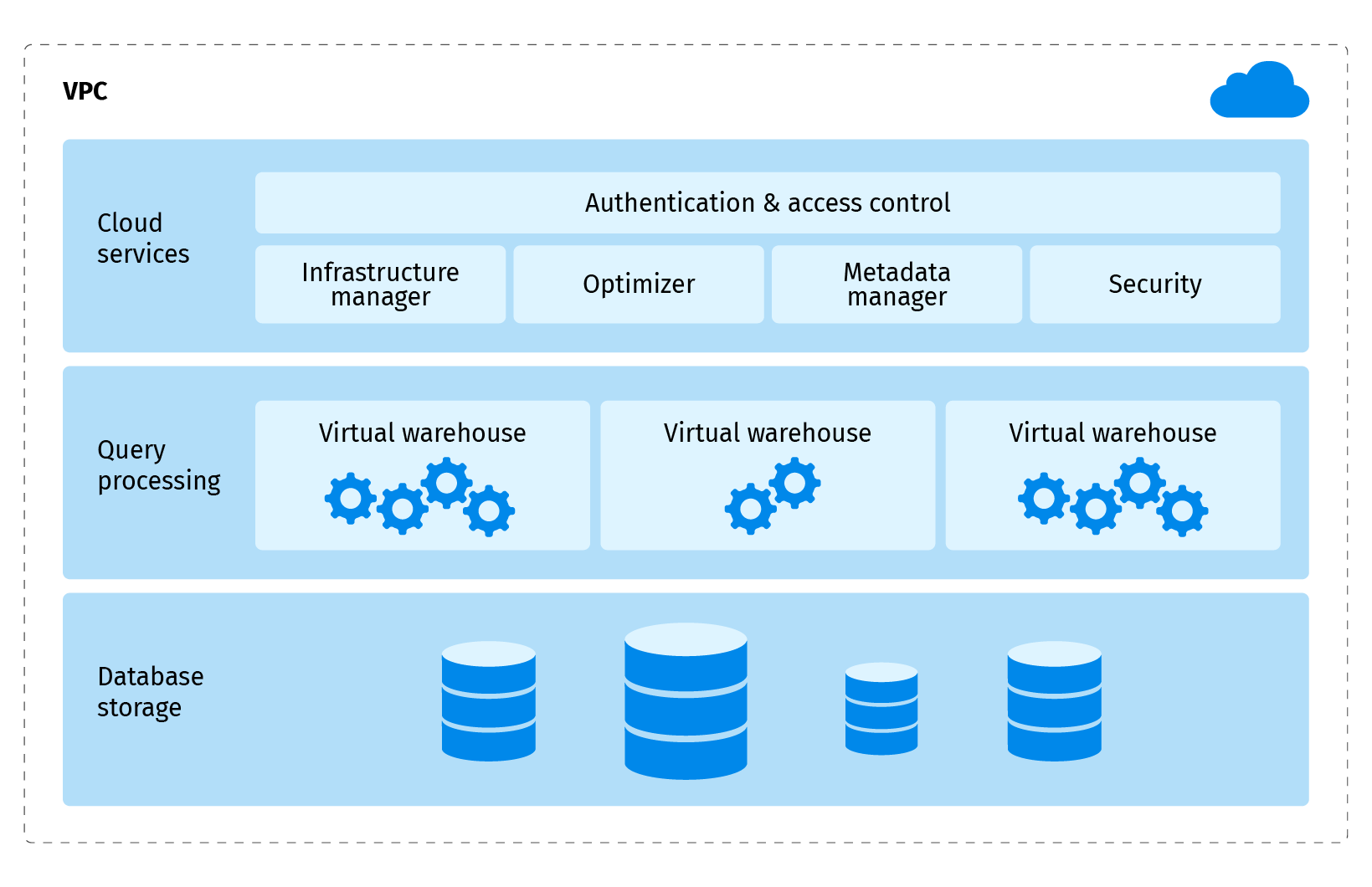
It has three main components:
- Cloud services: represents a collection of services that coordinate activities across Snowflake.
- Query processing: executes queries using virtual warehouses. You can create multiple virtual warehouses for different purposes. For example, loading data and querying data might be separated in different warehouses. The resources of each virtual warehouse are independent from each other.
- Database storage: Snowflake stores data in an internal optimized compressed columnar format in data storage that is divided into micro-partitions. Micro-partition is a unit of storage sized from 50 to 500MB of uncompressed data. It enables avoiding disproportionately-sized partitions.
The architecture provides the flexibility to adjust capacity needs cost effectively, but it does have some disadvantages. For example, the maximum concurrency limit for operations like INSERT, UPDATE, MERGE, COPY, and DELETE is 20. Other operations don’t have hard concurrency limits and are adjusted by the MAX_CONCURRENCY_LEVEL parameter. Snowflake has also introduced “credits” for calculating prices. The credit cost depends on the cloud provider and region you chose.
Snowflake offers two types of data loading - bulk and continuous. For the best performance and cost effectiveness, the official documentation recommends splitting larger files into smaller sizes of between 10 and 100MB of compressed data. Using Snowpipe you can continuously load new data from external storage within one minute if you follow the set of recommendations listed here.
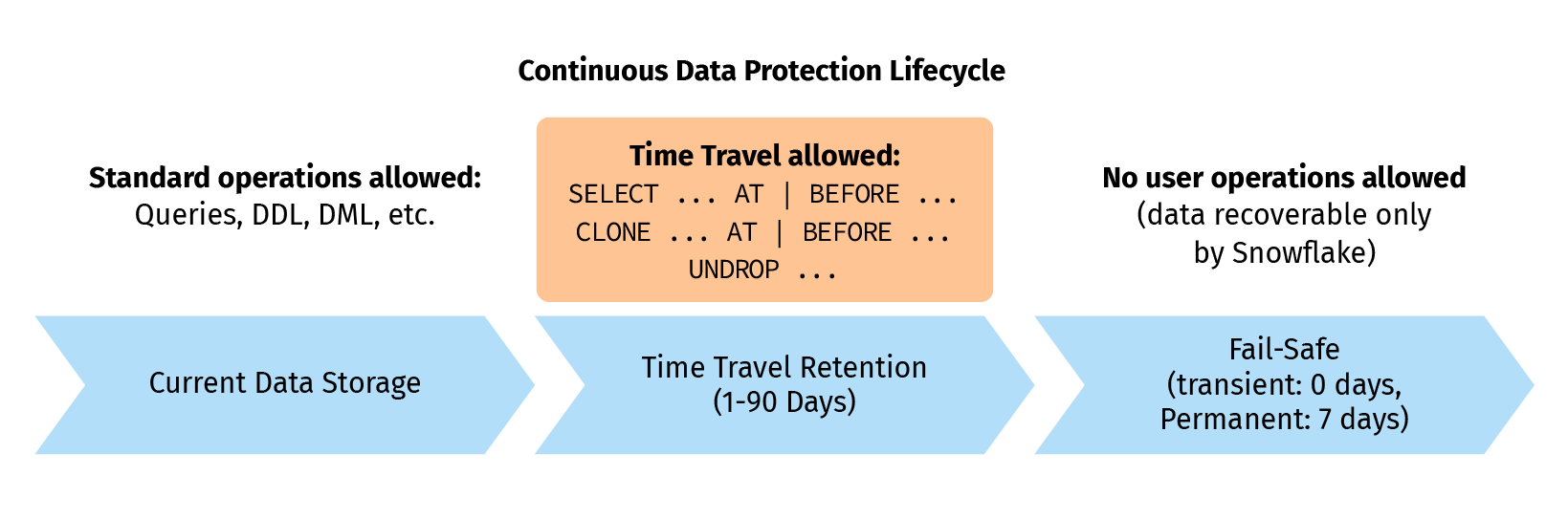
Time-Travel and Fail-Safe are Snowflake’s most unique features. Time-Travel enables you to perform actions like querying data in the past that has since been updated or deleted. You can create clones of entire tables at or before specific points in the past as well as restore tables, schemas, and databases that have been dropped. These actions are allowed for up to 90 days. Once the defined period of time has elapsed, the data is moved into Snowflake Fail-Safe and these actions can no longer be performed.
Fail Safe is a 7-day period during which historical data is recoverable by Snowflake after any system failures. No user operations are allowed here. Snowflake minimizes the amount of storage required for historical data by maintaining only the information required to restore the individual table rows that were updated or deleted. As a result, storage usage is calculated as a percentage of the table that changed. Full copies of tables are only maintained when tables are dropped or truncated.
To improve performance you can enable a clustering key that is designed to co-locate data in the same micro-partitions based on matched values in specified columns. As a result, the optimizer will read fewer micro-partitions.
Cache is divided into the following:
- Remote cache: long-term storage.
- Local disk cache: where data is stored in SSD and memory and available for queries.
- Result cache: holds the results of each query during the last 24 hours.
Pricing of storage, compute resources, and cloud services is separate. Storage fees are calculated for each 24 hour period from the time the data changed. Compute resources are billed per second, with 60 a second minimum. Usage for cloud-services is charged only if the daily consumption of cloud services exceeds 10 percent of the daily usage of the compute resources.
Snowflake provides user-friendly charts with explanations in billing terms. Query history enables you to understand overall performance of the specific queries using charts and a comfortable SQL editor. Snowflake has a poor SQL syntax compared to BigQuery. For example, there is no statement like ‘select * except (col1, col2...) from table_name’ for excluding one or more columns from the result.
It is worth noting that one of our customers faced an interesting issue: queries were failing with an internal error. This turned out to be because too many SQL variables were set. There’s nothing written about the issue in the Snowflake documentation and only Snowflake support could ultimately clarify why the queries were failing. This is why it is good practice to unset all variables at the end of a SQL query. In addition to its unique features and performance optimization options, Snowflake offers the capability to replicate data seamlessly from PostgreSQL, or other data sources, to its cloud-based data warehouse environment.
Google BigQuery
Like Snowflake, BigQuery is a serverless warehouse. You don’t have to configure clusters or think of their uptime, it’s completely self-scalable and self-manageable. All you need to do is pick the proper pricing plan.
Though BigQuery has the most limited SQL capabilities of its competitors, it supports all basic SQL constructions you might need. We didn’t need to modify queries much to adapt them to BigQuery, except those that use UNION, because BigQuery supports UNION ALL only.
Supported features:
- SQL and JavaScript UDF.
- Stored procedures.
- Views and materialized views.
- External data sources.
- Labeling tables, jobs, etc.
- And many more.
BigQuery can run queries in two modes: INTERACTIVE or BATCH. BATCH mode is used for regular applications. It means that each query is added to a queue to wait for resources. Queries that run in INTERACTIVE mode are marked as highest priority and usually start as soon as possible. It’s very handy for analysts: CLI and GCP console configured to INTERACTIVE mode by default. This feature has a limitation: you cannot run more than 100 parallel interactive queries.
BigQuery supports DML as well as INSERT, UPDATE, and DELETE operations. All DML queries are transactional, so you’ll never get partially updated tables.
BigQuery doesn’t have JDBC or ODBC interfaces. Instead, it provides libraries for most popular programming languages like: C#, Go, Java, NodeJS, PHP, Python, and Ruby. If you don’t see your language in the list, you can use the REST API directly, or check for third party tools.
BigQuery has original architecture:
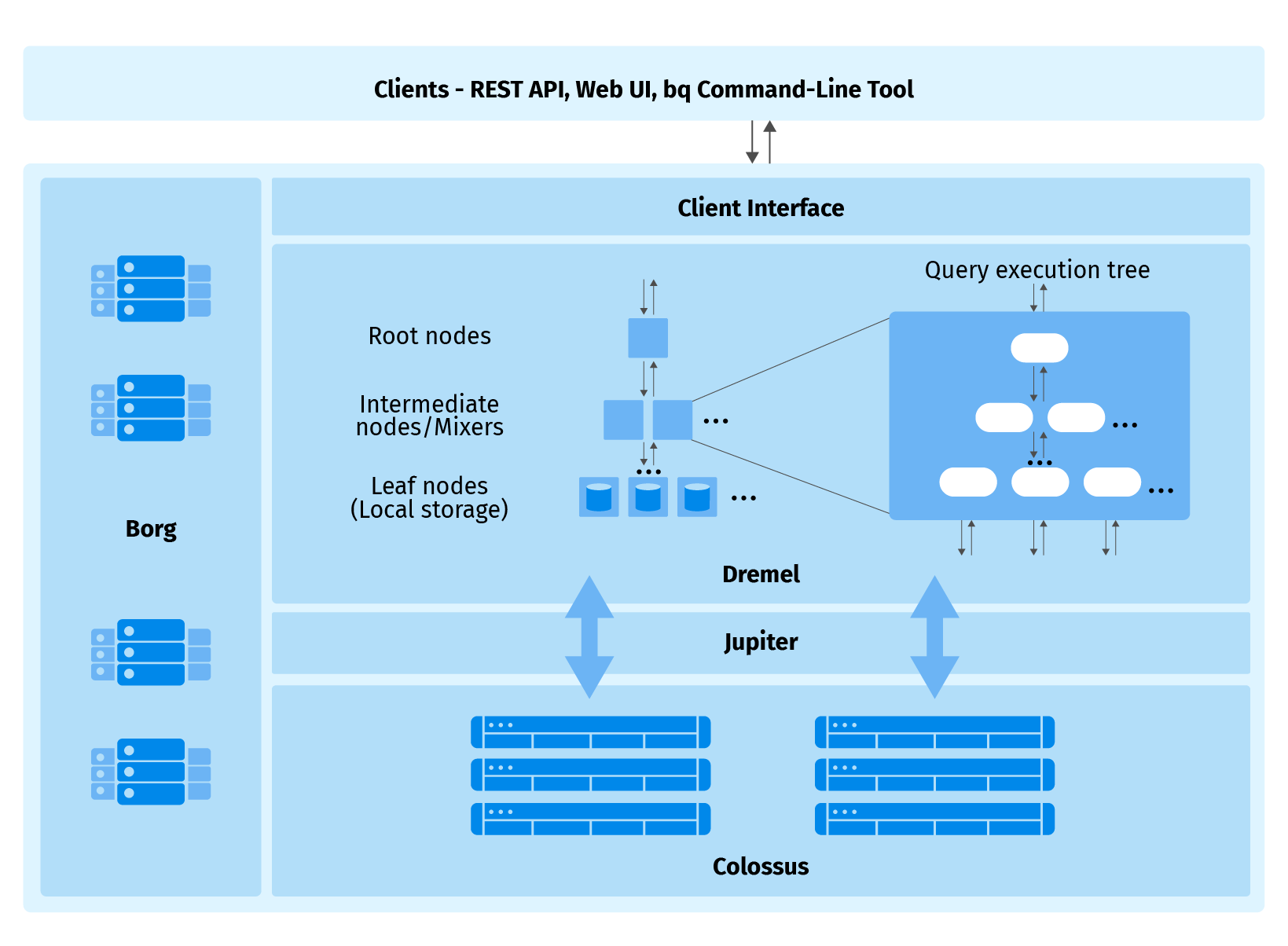
Dremel is the heart of BigQuery, it builds a query execution tree of jobs. Dremel might optimize query on the fly: stop some jobs and prepare others. Borg is a cluster manager that executes Dremel’s jobs on hardware. Colossus stores files in a columnar format named Capacitor. Jupiter provides a petabit network to gain max IO speed. This design allows for the high performance and flexibility of BigQuery jobs. You can check further details of exactly how BigQuery works here.
This design has downsides though. For example, you cannot build an execution plan before running a query. And all tree tiers are known only when the full query is completed. In our opinion, the BigQuery execution plan was not very useful.
We also noticed that BigQuery is not good at joining and grouping. Some queries like inner_join and q72 of big tables were not able to complete in 6 hours even in on-demand pricing mode. BigQuery doesn’t allow queries to run longer than 6 hours. Query q67 with ORDER BY failed because of resource limitations. In documentation you can find the one common advice to use the “LIMIT” clause with “ORDER BY”, but q67 already has it and still fails.
BigQuery pricing has its own specifics with two types of it offered by Google:
- On-demand pricing - You pay only for uncompressed terabytes that your queries read. You don’t have other limitations, like compute resources. But it’s quite expensive and unpredictable as you don’t get to know how many bytes a query will read.
- Flat rate pricing - In this plan you don’t pay for bytes read, but instead pay for compute resources. And it doesn’t matter if you use those resources or not, you always pay a fixed price. This plan reveals usage of reservation APIs that limits the amount of compute resources used. The compute resources calculation is quite simple: you can buy slots, and each slot is a dedicated worker. It’s the most useful plan for most applications.
Another type of payment is storage. But you can get a discount for tables that were not updated for 90+ days. We found BigQuery to be the most expensive EDW.
We tested both plans. In on-demand mode, queries consumed up to 10k slots. In the case of flat-rate pricing, we limited the amount of slots to 500 to be comparable in price to Amazon Redshift. Even 500 slots were more expensive, but this is the minimum purchase amount allowed.
Benchmark overview
For testing and comparing performance we decided to use the widely spread TPC-DS benchmark. TPC-DS models a data warehouse and focuses on online analytical processing tasks. The entity-relationship-diagram below shows an excerpt of the TPC-DS schema:
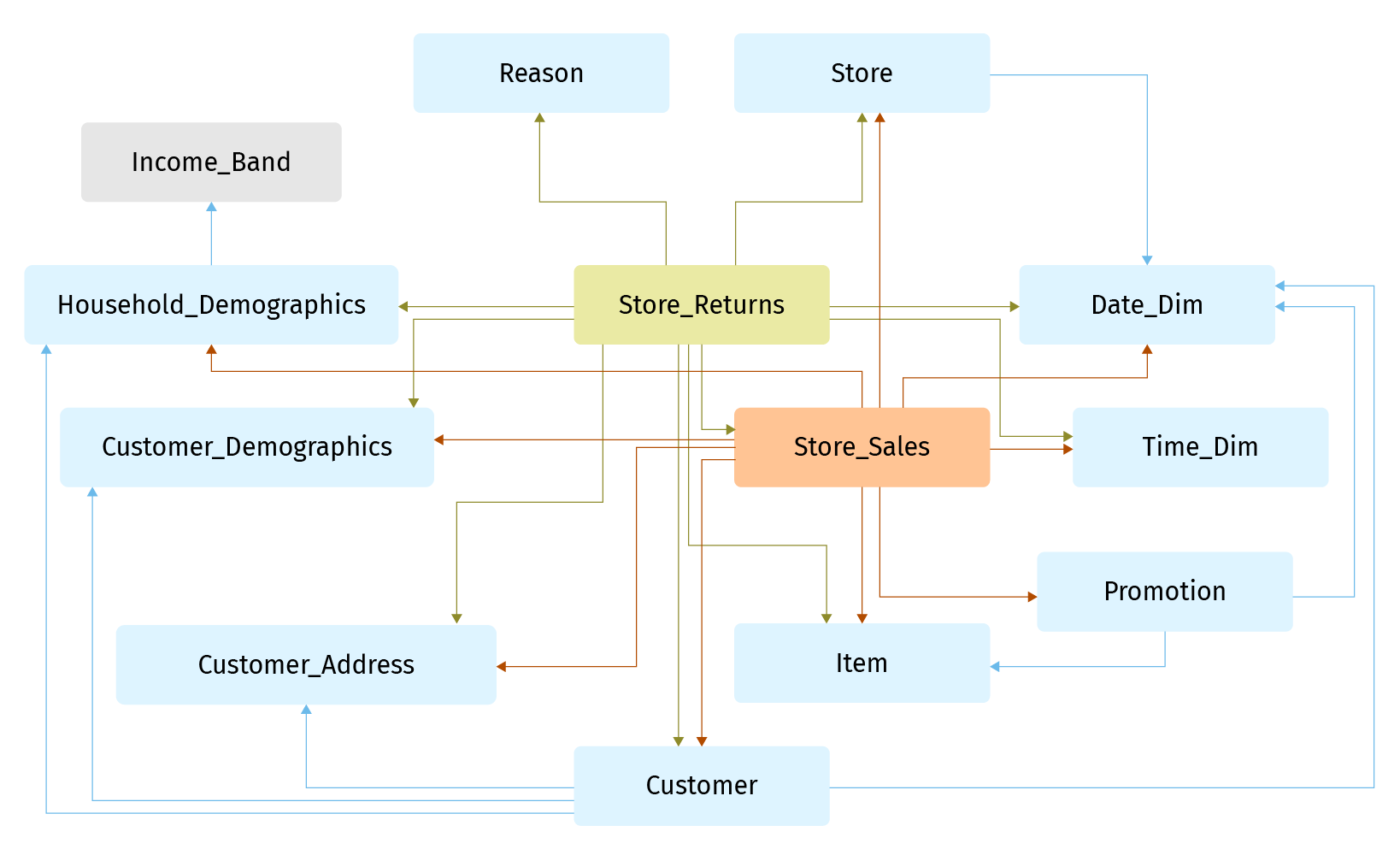
It contains the two fact tables: Store_Sales and Store_Returns as well as the associated dimension tables such as Customer and Store.
Benchmark also contains tables: Web_sales, Web_returns, Catalog_sales, and Catalog_return but relations with dimension tables are approximately the same as between Store_Returns and Store_sales.
Brief overview:
- Size: 1TB.
- Number of tables: 24.
- Number of columns: from 3 to 34.
- Max number of rows in table: about 3 billion.
A full description of the TPC-DS benchmark is available here.
TPC-DS benchmark provides 99 queries that we divided into the following categories:
- Cross join.
- Full outer join.
- Inner and left join.
- Low level.
- Middle level.
- Multiple join using the same table.
- Union and intersect.
- Where condition.
- Window function.
- Custom.
The “low level” category contains queries that have less than three joins and simple other conditions in the where clause.
The “middle level” category contains queries that have greater than two joins and many other conditions in where and group by clauses.
The “where condition” category contains queries with a lot of conditions in the “WHERE” clause. They use the wide range of available keywords like IN, EXIST, BETWEEN etc.
The custom category contains queries that we created for comparing specific cases. For example, we created a table with a long string column and populated it with around 55,000 characters. We then created a query to find specific words in that column using the LIKE keyword.
Charts with performance and billing comparison
To compare performance, we ran queries on Redshift, Snowflake, and BigQuery in parallel using 50 connections with the following configuration of the data warehouses:
| Redshift | Snowflake | BigQuery | |
| Infrastructure setup | 10-nodes cluster, dc2.large instances (2 vCPU, 15GB RAM) | 2 clusters, Medium warehouse size (4 servers per cluster) | “Unlimited” infrastructure for “on-demand” model. 500 slots for “flat-rate” model |
| Queries adjustment, performance tuning | Distribution style “ALL” for small dimension tables; “KEY” - for large fact tables. “SORT KEY” for large fact tables | “Clustering key” for large fact tables | “Batch” job type |
| Pricing | $2.5 per hour | $16 per hour | On-demand: $ 5 per TB Flat-rate: $ 20 per hour |
To demonstrate comparison results we created several charts. For better visualization we divided the query categories into two subsets.
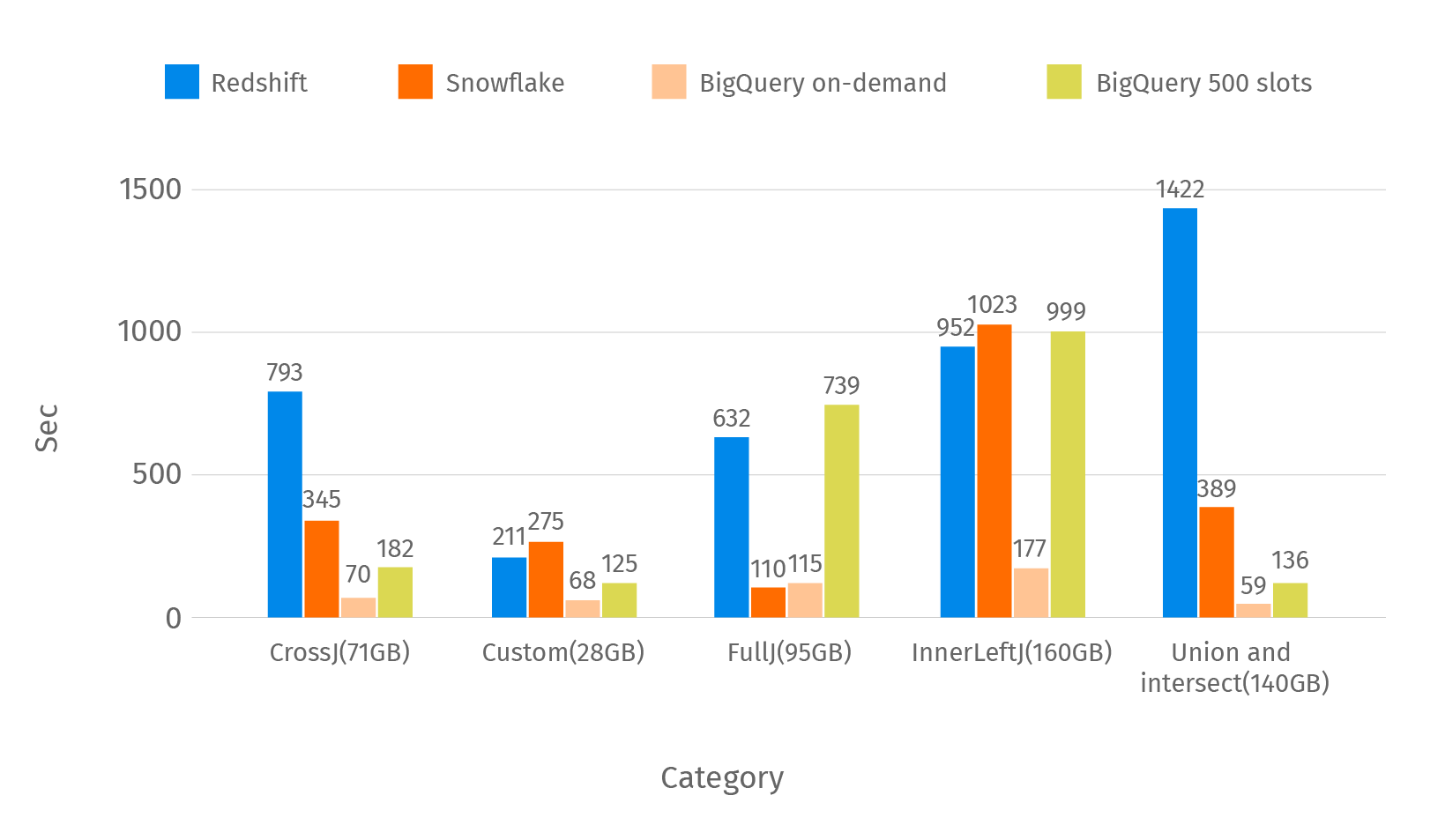
This chart shows the average time of the queries by category from the first part.
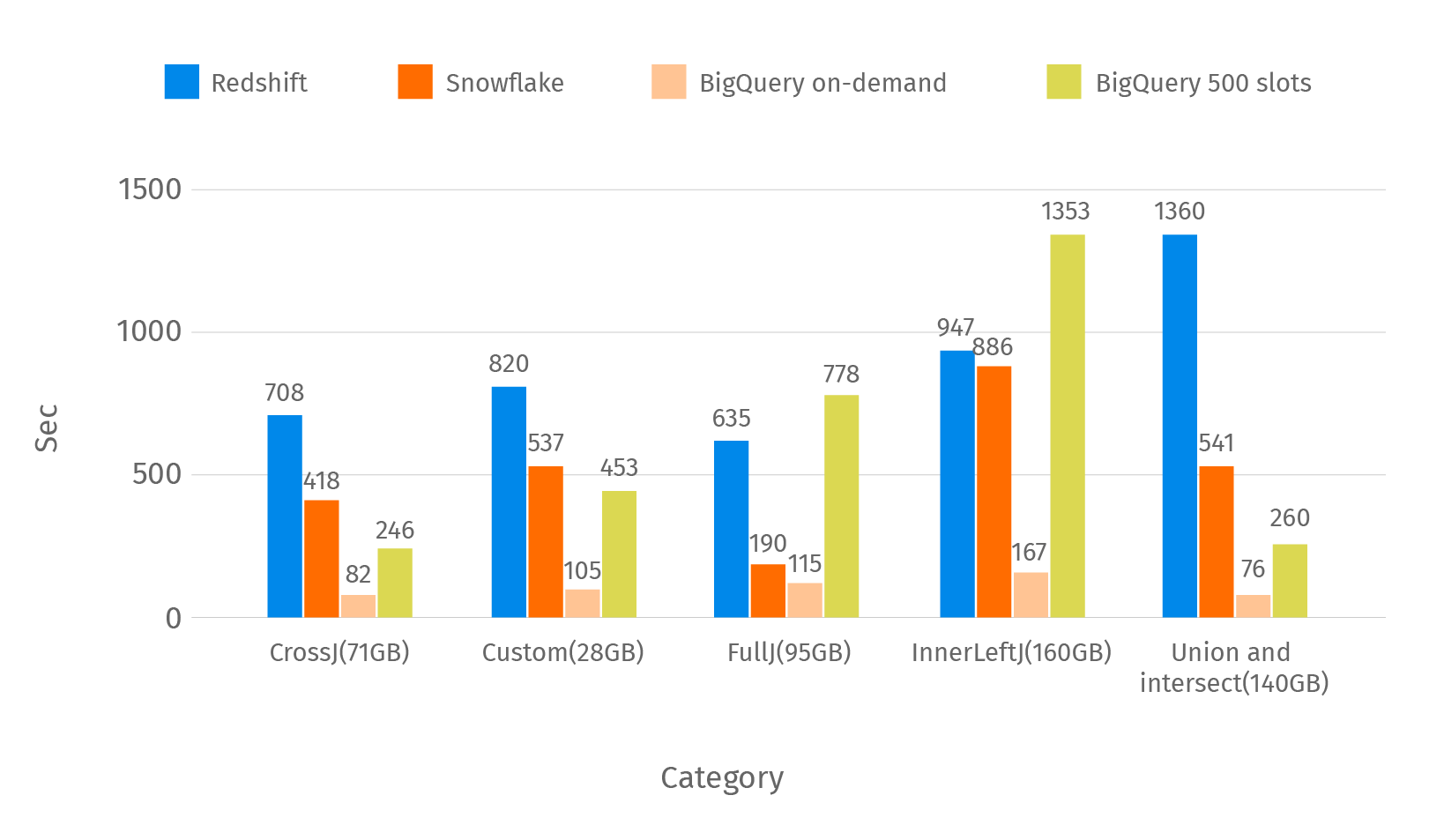
Next to the category name you can see the average size of the scanned data. On demand pricing in BigQuery gives you the ability to execute queries very quickly but charges are also high.
Here is the median time of the same categories of the queries from the first part:
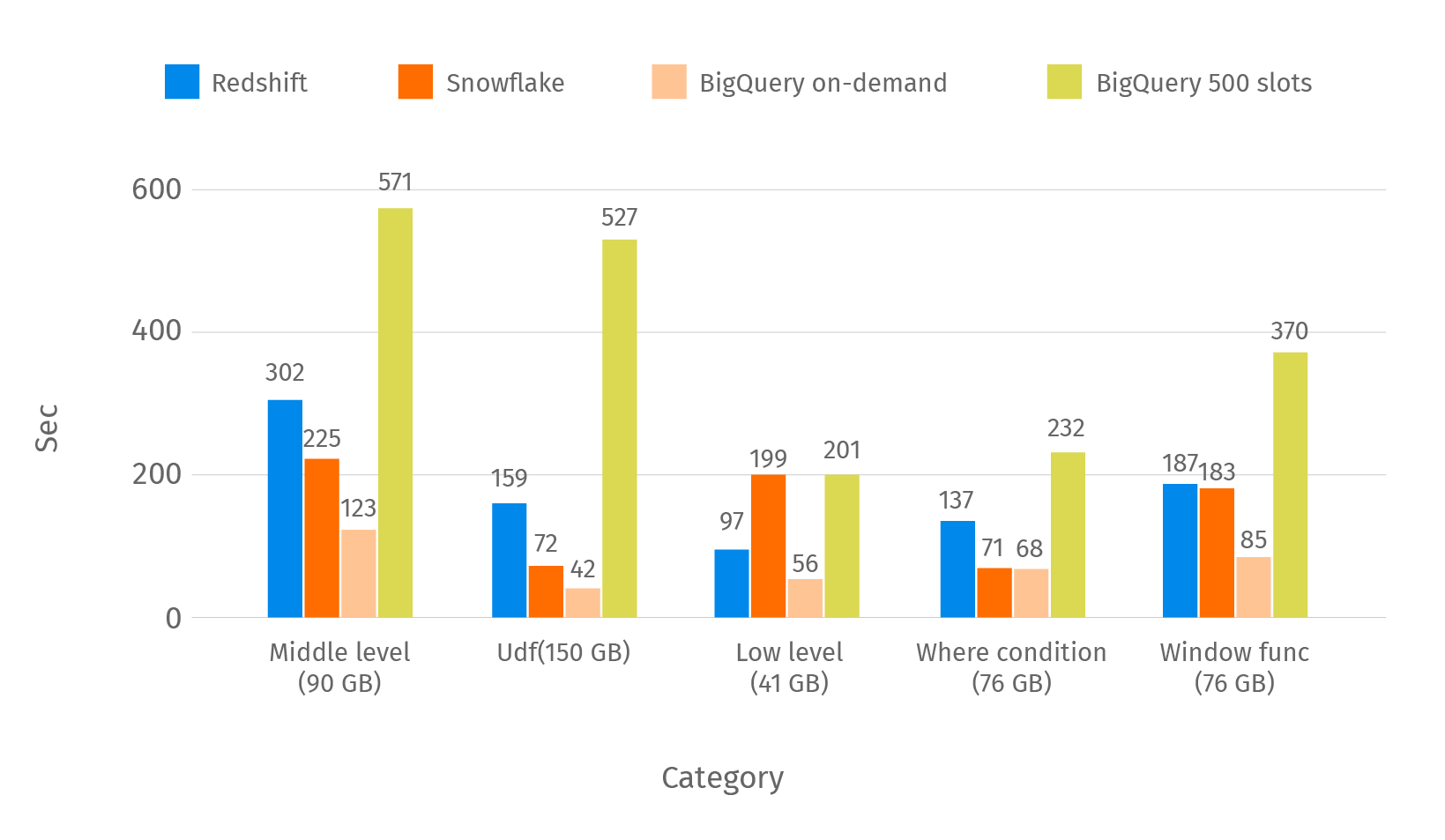
In the below chart you can see the average time of the remaining categories of the queries.
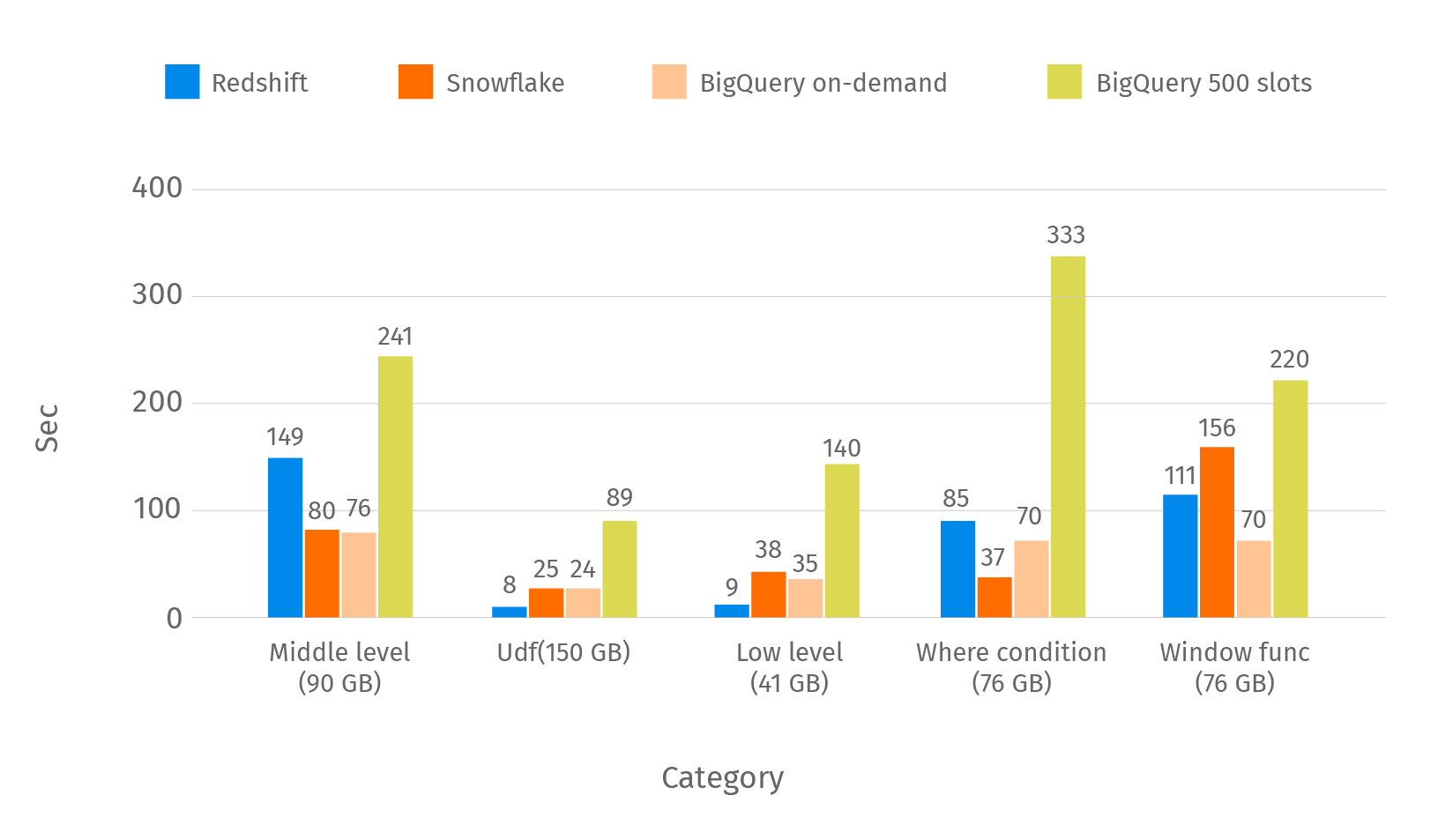
This chart shows the median time of the same categories:
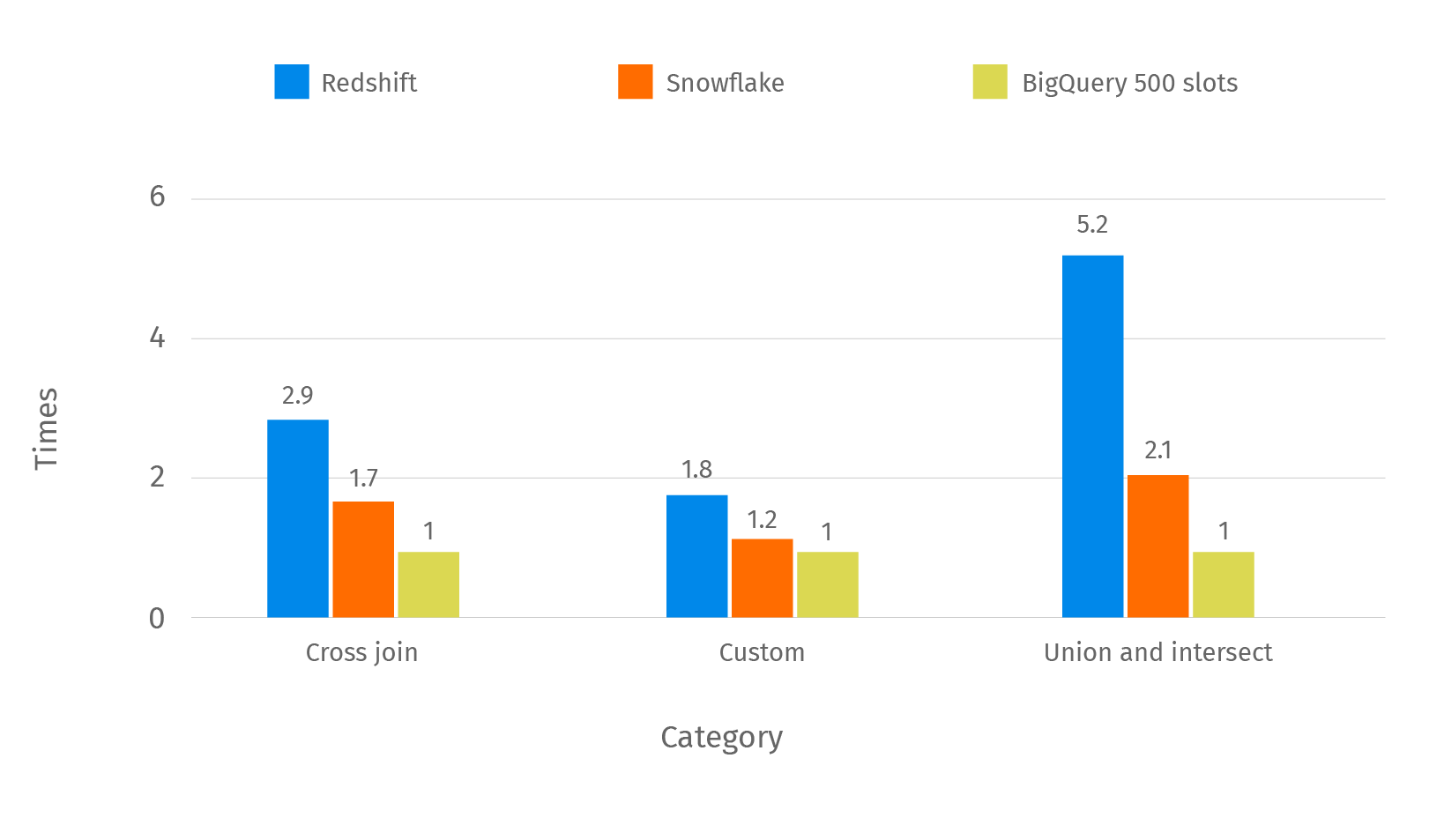
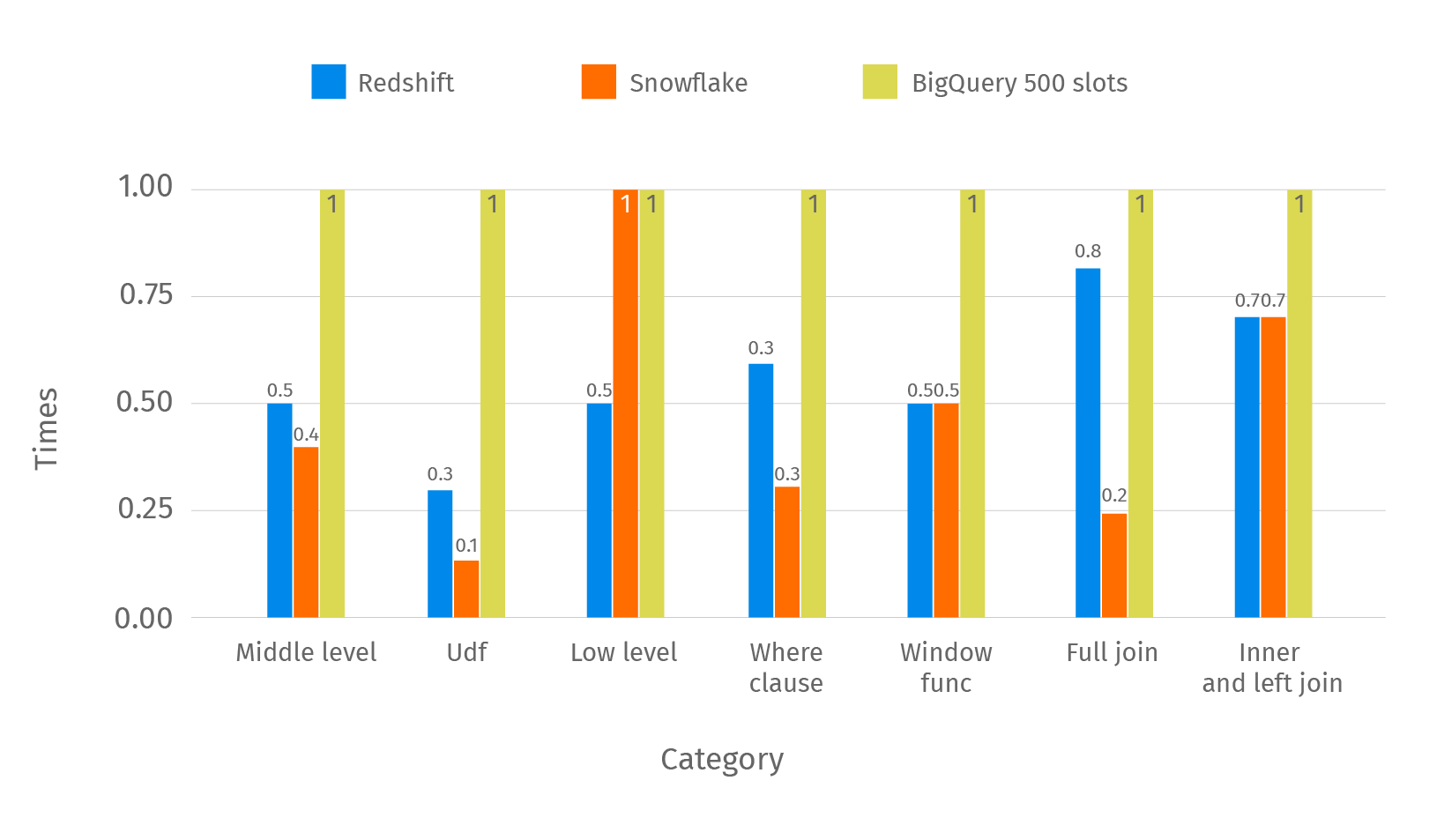
For better visualization of performance we calculated a relative comparison between Redshift, Snowflake, and BigQuery with 500 slots. For that purpose we divided Redshift/Snowflake response time by BigQuery. Results are presented in two parts. We won’t use BigQuery with an on-demand strategy of pricing in further charts in order to have a similar setup in terms of pricing. In the below chart you can see categories where BigQuery with 500 slots is faster than Redshift/Snowflake in a specified number of times.
In the chart below you can see the categories where BigQuery is slower than Redshift/Snowflake.
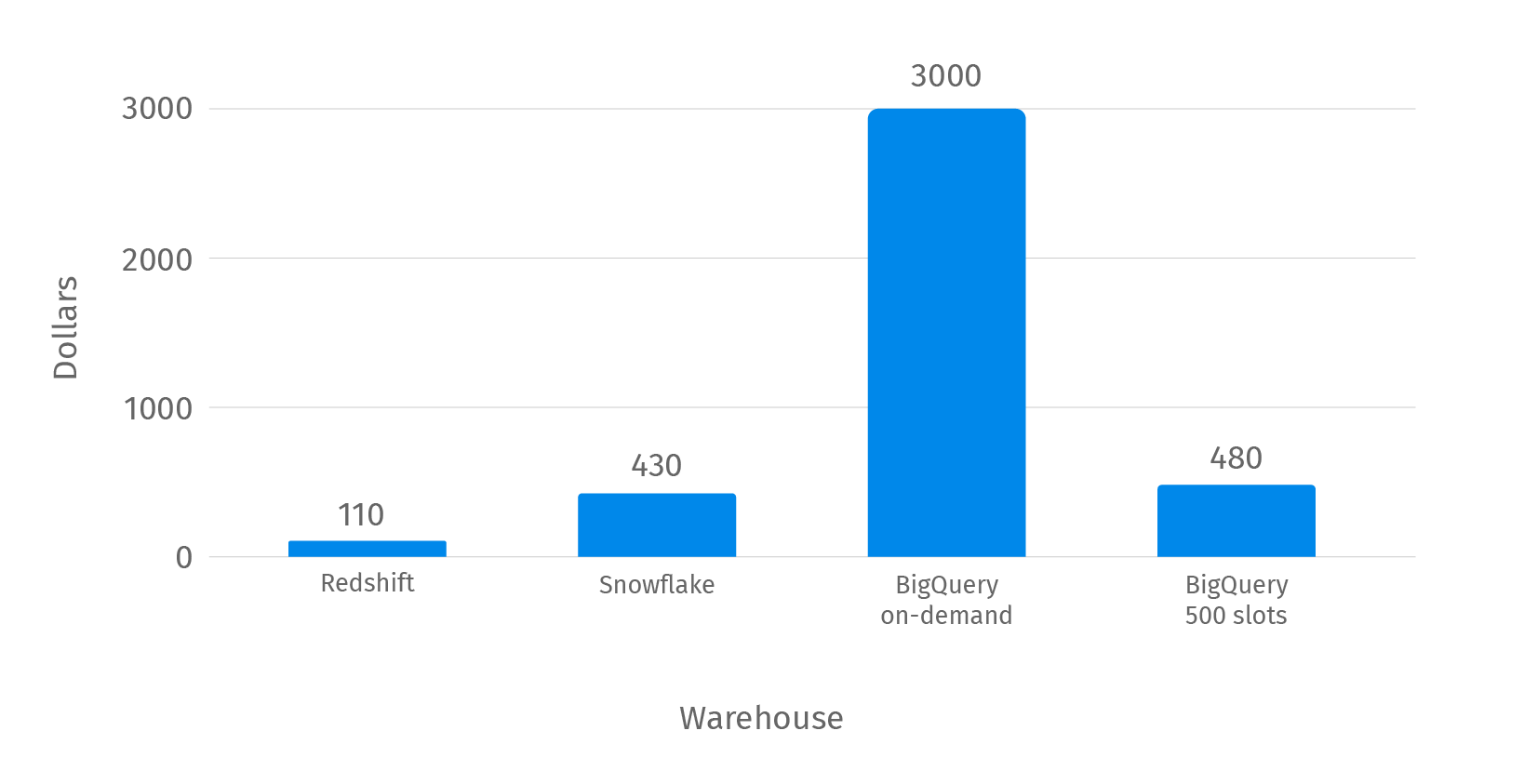
Here are expenses by EDW.
We want to note that BigQuery with an on-demand strategy was very expensive but showed the best results in terms of performance.
Conclusion
We have combined performance and cost comparison results by EDW in the table below. As we can see BigQuery with an on-demand pricing model is the most expensive setup from our evaluation experiment. But on the other hand it showed dramatically better performance than competitors and won in almost all of the queries categories. If we are going to compare relatively similar setups in terms of pricing, then it makes sense to consider the first three columns (Redshift, Snowflake, BigQuery 500 slots).
| Category/EDW | Redshift | Snowflake | BigQuery 500 slots | BigQuery on-demand |
| Cross join | Fair | Good | Good | Excellent |
| Full outer join | Good | Excellent | Good | Excellent |
| Inner and left join | Good | Good | Fair | Excellent |
| Low level | Excellent | Good | Good | Excellent |
| Middle level | Good | Excellent | Fair | Excellent |
| Union and intersect | Fair | Good | Good | Excellent |
| Where condition | Good | Excellent | Fair | Excellent |
| UDF | Good | Excellent | Fair | Excellent |
| Window function | Good | Good | Good | Excellent |
| Expenses | 110$ | 430$ | 480$ | 3000$ |
Each data warehouse met our requirements related to concurrency and number of open connections but, in general, they each have restrictions. In Redshift, the level of concurrency is limited to 50 queries, but official documentation recommends you don’t set it greater than 15. Snowflake doesn’t have hard limits related to concurrency. You can manage it using internal parameters. To meet concurrency requirements, Snowflake recommends using multi-clustered warehouses with auto-scale or maximized mode instead of improving the size of the warehouse. BigQuery has a limit of 100 concurrent queries in interactive queries, but the batch doesn’t have limits.
From the developer side we want to note that each data warehouse provides Web SQL editors. BigQuery has the most advanced editor with the ability to share SQL code, auto-completion, and pre-calculated sizing of the scanned data. Redshift and Snowflake don’t have this functionality. Snowflake has a good support team, we found a lot of answers on your questions in the community.
If you have a very limited budget for EDW, Redshift is your best choice. However, Redshift requires additional effort from the developer side in order to reach good query performance. Snowflake is the most advanced data warehouse in terms of provided features. It has good performance but quite expensive pricing. BigQuery is an easy to use data warehouse, but can become expensive. You just need to load data to the tables.
In terms of performance, BigQuery with an on-demand strategy of pricing gives you the ability to execute queries very fast but charges in this case are also high. In terms of security, each data warehouse provides a comprehensive set of features to keep your data safe. This includes automatic data encryption, user roles, and data loss prevention tools.