
Enhance customer experience with Multi-Language Semantic Search


We live in a multicultural society with more than 7, 000 languages spoken across the world today. To better serve the needs and preferences of global consumers, retailers need to understand the unique nuances and characteristics of the diverse languages their customers speak. It is no longer enough to offer English-only search and product discovery, and leading service providers are capitalizing on multilingual semantic search to offer their customers a more personalized, convenient experience, resulting in higher conversion and retention rates.
How does semantic search work?
In a previous post, Boosting product discovery with semantic search, we have shown that using semantic search is critical for modern e-commerce platforms. Concept recognition enables companies to increase search precision, and as a result, significantly improve customer experience for operations like faceted navigation or product sorting. Our experience in semantic search integrations for leading tier-1 retailers has also proven a considerable uplift in conversion rates.
In our Semantic query parsing blueprint paper, we created a thorough guide for semantic search implementation on the base of available open-source frameworks like Solr and Elasticsearch. Let us briefly summarize some of the main conclusions from this work:
- When we index products, we need to create an additional index with a special meaning. It should contain documents with a structure, that has fields like id, fieldName, value, for example:
These documents are created on the basis of the attributes of products being indexed. We refer to such documents as ‘concept’ documents, since each document of such a structure represents a certain concept that may appear in a user’s search phrase. In our example above, the concept states that the sub-phrase ‘silver jeans’ is a brand; i.e. there is at least one product that has a field ‘BRAND’ with value ‘silver jeans’.{ "id": 28, "fieldName": "BRAND", "value": "silver jeans" }
-
Product search should be executed in 2 stages. In the first stage we need to produce and collect all the possible sub-phrases from the user phrase. Then we need to recognize concepts among obtained sub-phrases. Concept recognition is performed as a search of the concept documents that have ‘value’ equal to sub-phrase. A concept is considered to be recognized when we find at least one document for the given sub-phrase.
-
In the second stage we try to cover the user’s phrase with found concepts. There could be many variants. Each variant can be considered as a hypothesis about the real meaning of the user’s phrase. For example, suppose the search phrase is ‘silver jeans’. When we split it into sub-phrases and try to find concepts, we may come to the below results:
Silver -> Material
Jeans -> Product Type
Silver Jeans -> BrandThere are 2 ways to cover initial user phrase with these concepts:
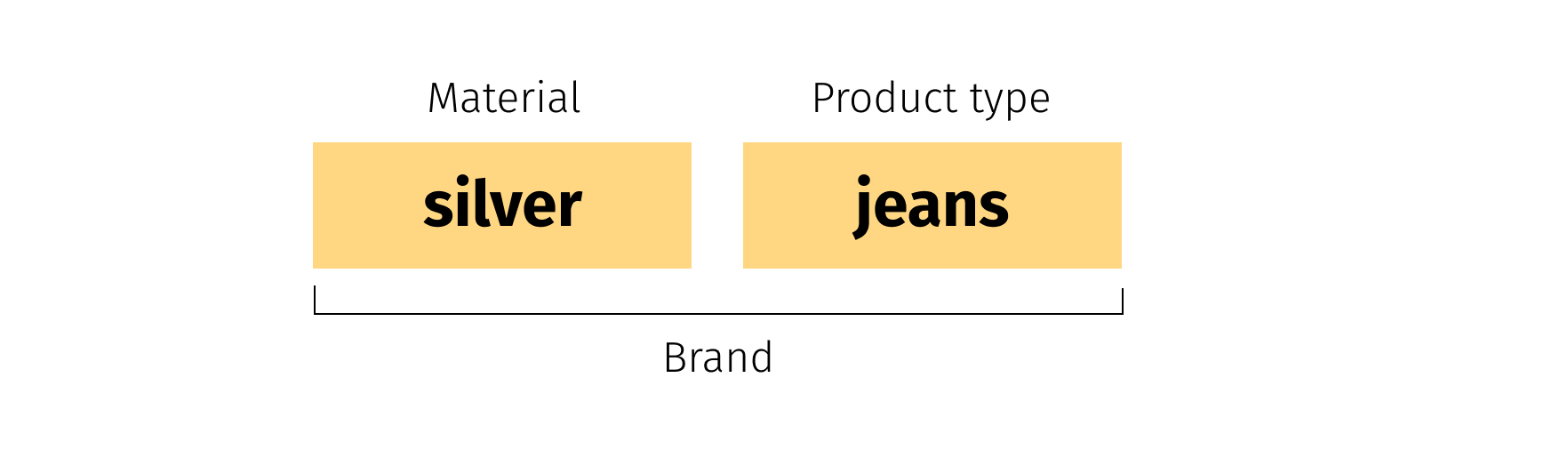
Thus, for our simple example we can produce 2 hypotheses: the user wants to find jeans made from silver material or is looking for products from the Silver Jeans brand. -
On the base of the hypothesis set we can build a Boolean Query for product documents index.
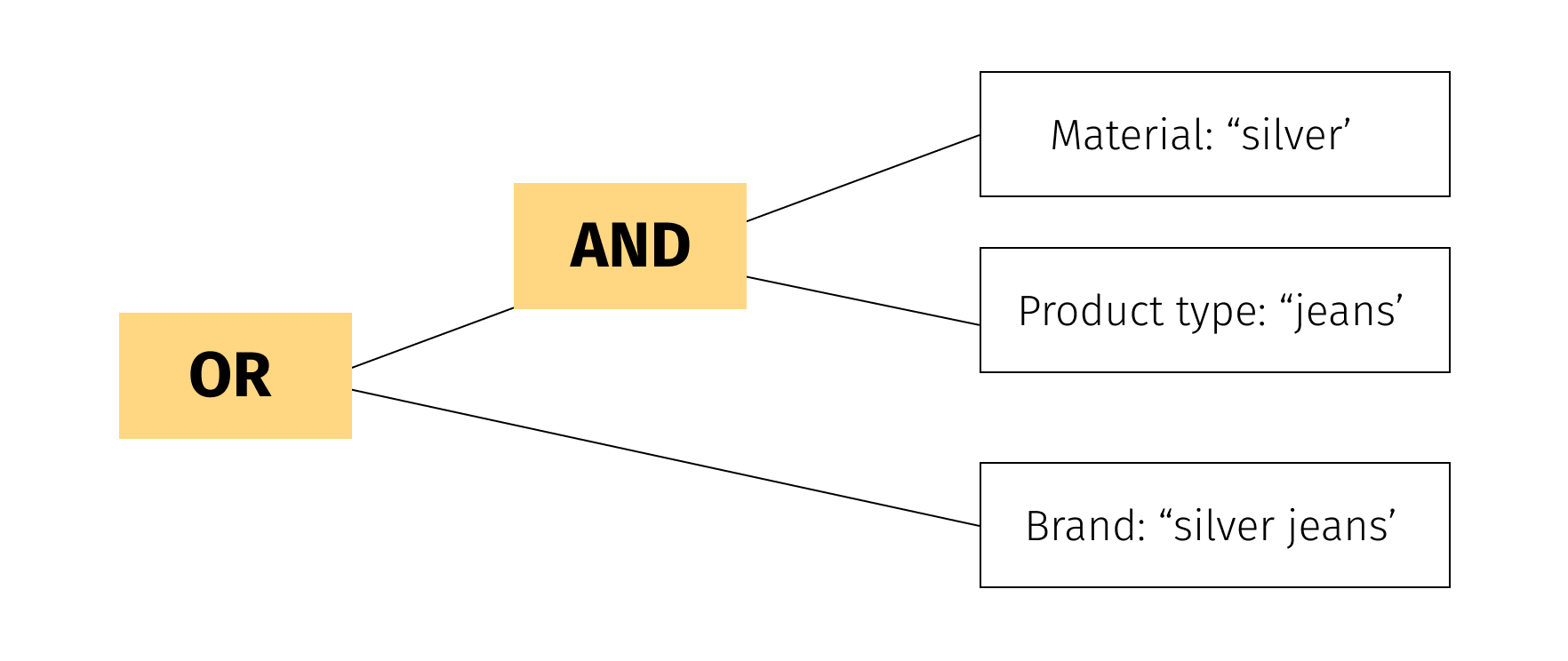
If we run this query, we can get all the products that match the built hypothesis.
This technique improves search precision considerably and can increase the conversion rate up to 20%.
Not only English
So far we have assumed that e-commerce platforms only process search requests written in English. This assumption is valid for many online retailers in the USA, however, some of our customers sell their goods worldwide. They need to provide the ability to search for products using the native language preferred by their clients.
Semantic search approach for different languages
Let’s have a look at what we need to change in our approach to provide relevant search in several languages.
The first thing that we want to do is separate indexes specific for each language from each other. Thus, for each supported language we want to have indexes with concepts and products. During query time we usually recognize the language of the search phrase and assume that it corresponds to website localization and that its value is available as one of the search parameters. Instead of having common indexes and trying to filter concepts and products, it’s more convenient just to send requests to appropriate indexes. Such a separation has considerable advantages:
- It simplifies the logic of request processing. We don’t need to add an extra filter into search requests and that filter should not be applied to the search result.
- It reduces the number of documents in each index and, as a result, improves query processing performance. To be precise, products may have different availability in different marketplace localities which means that the number of documents in each index corresponds to the number of products relevant to the current language context.
- It uses index settings specific for each language, which include a tokenizer, linguistic analyzers, stop-words, etc.
Once we’ve separated indexes, we need to provide ingesting products and concepts for each of the supported languages. Unfortunately, using automatic translation for this purpose is not ideal, and mistakes made in product attributes processing can result in relevant products not being displayed in search results. Relevant search requires products to have attributes properly translated to all the supported languages.
Technically the ingestion stage may look like the following. One data record may represent a single product:
{
"id": 28,
…
"PRODUCT_TYPE": {
"en": "pants",
"de": "hose",
"ru": "брюки"
}
…
} In this case, for each language, we need to produce several localized documents, and those documents are to be ingested into corresponding language-specific indexes.
Another option is having separate items for each combination of language and product id in the Data Source; for example:
{
"id": 28,
"language": "en",
…
"PRODUCT_TYPE": "pants",
…
}
{
"id": 28,
"language": "de",
…
"PRODUCT_TYPE": "hose",
…
}
{
"id": 28,
"language": "ru",
…
"PRODUCT_TYPE": "брюки",
…
} The processing logic here is much simpler, because for each data record we need to produce only one document. However, the number of items that need to pass through the indexing pipelines will be significantly higher.
The query-time request processing logic for each local language is similar to the logic for the English language. Since we know the language of the query, we can perform the same set of operations we used before:
- produce sub-phrases;
- find corresponding concepts;
- create all the possible combinations of covering initial search phrase with found concepts;
- build product query and apply it to language-specific product index.
Language-specific operations for semantic search
In spite of the fact that the common flow remains the same, it’s important to note that we need to apply some operations that are specific to each of the supported languages. Let’s discuss them briefly:
- It’s very important to use a proper tokenizer. While for many languages, including almost all European languages, we can use a whitespace tokenizer, for some Asian languages like Chinese, Korean, Japanese and Thai, this is not sufficient. One or several hieroglyphs can appear to be separate words, and for the described semantic approach it’s very important to split them in the right way. Tokenizers for these languages are usually quite sophisticated. And for some managed search platforms, (like Amazon Opensearch) the set of supported tokenizers can differ from the similar open source frameworks. The Korean language tokenizer on Amazon Opensearch for example, uses quite an old seunjeon plugin, while Elasticsearch applies Nori. For the proposed semantic approach, the operation of tokenization is applied both in index time for generating text and shingled fields, and in query time for producing sub-phrases. It's required that these operations are the same, otherwise the documents may not be matched. Index-time tokenization is defined by settings and hidden behind the scenes, while in query time it’s normally done by custom code. During query time it’s crucial to use the same version of the same tokenizer, which is used by the backend search framework.
- It is necessary to apply a correspondent chain of analyzers for each language. This statement sounds obvious for operations such as stemming because it’s clear that each language has its own rules and word endings; however, the presence of some specific logic in lowercase operations for Greek and Turkish really surprised us.
- It’s critical to provide a unique set of vocabulary linguistics for each supported language. This includes stop words, synonyms, hyponyms, ‘no-go’ words etc. While the standard list of stop words can be taken from a corresponding Lucene analyzer, the list of synonyms is normally specific for each retailer and explicitly depends on the products that are being sold.
- Also it is important to take into account is that spelling corrections are specific for different languages. There could be different approaches for implementing spell-check operations, and although this topic is out of the scope of this article, it’s interesting to note that there is little clarity on whether spelling correction can be applied for Chinese and some other hieroglyph languages.
Conclusion
To sum up, the approach we took, based on the combination of semantic search and language-specific linguistic operations, has proven to be very effective. For example, we delivered a customized search platform for a client that supports more than 20 local languages that resulted in a considerable conversion rate improvement.
Looking forward, we are exploring scenarios in which customers use a cross-lingual approach - mix of their native language and English - in their search queries. This has to do with the fact that many brand and product names are in English, and simply because English is a globally recognized and widely-used language. While using English words against a localized index can still yield good results, we are working on a solution that enables searching for products using both native and English language sub-phrases for optimal results. In our next post we’ll try to solve this issue and share the results with you.
Interested in multi-language semantic search for your business? Get in touch with us to start a conversation!