
Enterprise-grade ML Platform in AWS: A Starter Kit


Modern enterprises operate with tremendous amounts of data, and data management has become an integral part of business decision-making processes, KPI management and reporting. However, getting advanced insights from data and ML models is a sophisticated process that many companies still struggle with. Even for a company that has successfully built a data platform, it takes a significant amount of time to build an ML platform with CI/CD capabilities, a model serving layer and features preparation.
At Grid Dynamics, we have built many ML platforms for our clients, leading us to develop an ML Platform Starter Kit for AWS to accelerate the provision of the ML Platform and avoid common pitfalls. The ML Platform is also integrated with our Analytics Platform, providing a simple and fast way to provision both data and MLOps capabilities in AWS.
ML Platform reference architecture
We generally view MLOps as a combination of model development, data engineering, and CI/CD capabilities that are needed to support the following model development life cycle:
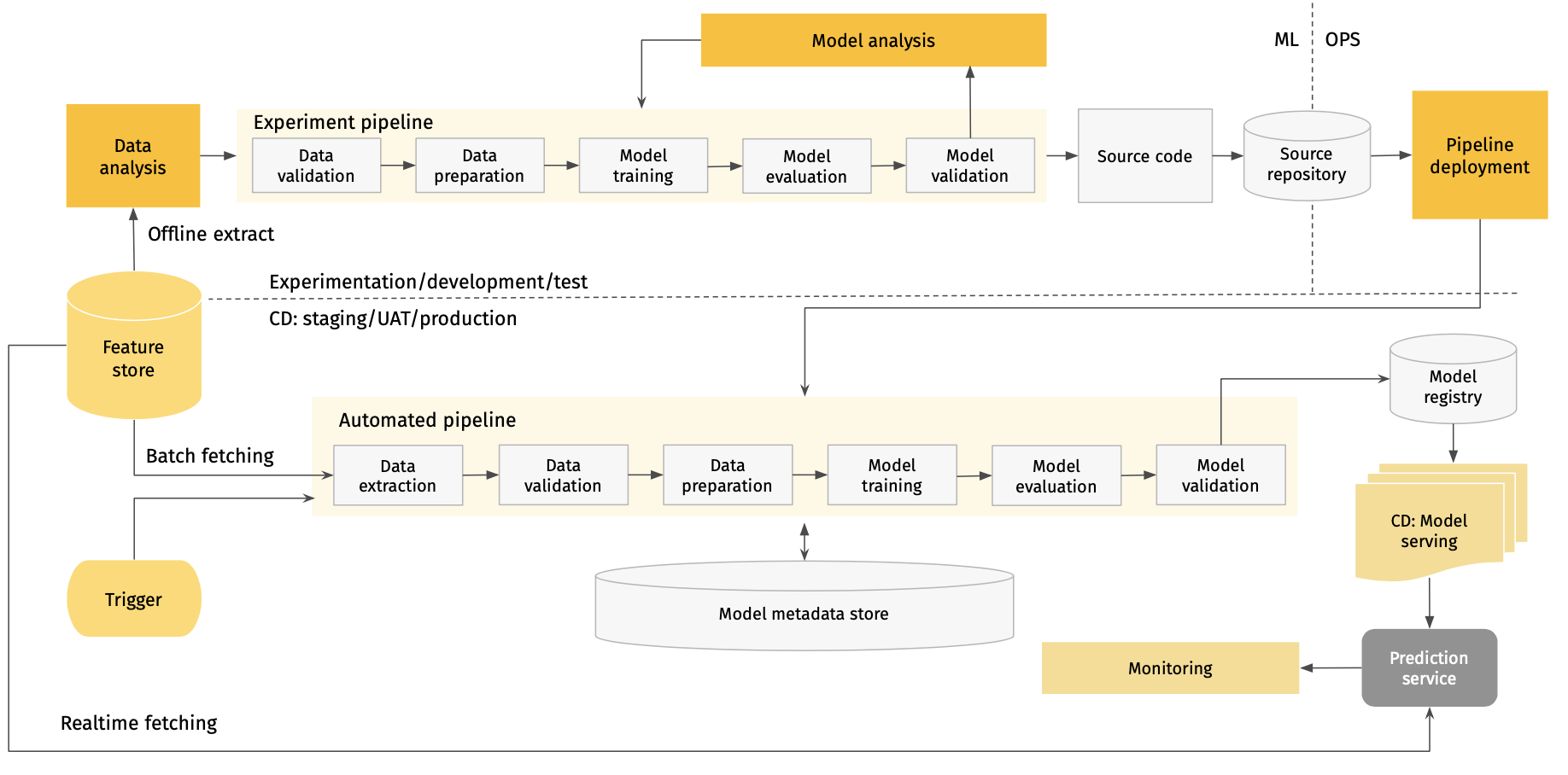
This reference architecture demonstrates how the model development process in the top left corner integrates with the CI/CD pipelines and serving infrastructures, enabling efficient MLOps.
ML Platform capabilities
The reference architecture demonstrates the major capabilities that the ML Platform should provide. They are:
- Experimentation pipeline;
- Automated CI pipeline;
- Continuous deployment and serving infrastructure management.
Let us elaborate on each capability in detail.
Experimentation pipeline
The experimentation pipeline is a core part of the development infrastructure as it provides the right tooling and process to work with data, create data extracts, train and validate models, register new features (datasets) and track experiments. Once a commit is created the model passes to the next step: automated CI/CD pipeline. The features used in model development can be published manually during model development, or automated in the CI pipeline step.
Automated CI pipeline
The automated CI pipeline takes care of all the complexity involved in creating a model, preparing a dataset for model training, running model training, evaluating the trained model, tracking the trained model and corresponding artifacts, and storing artifacts in the model registry. Continuous integration drastically reduces the manual efforts required to create a model, helps to avoid typical issues happening during semi-automated deployment and tracks not only model, but also model metadata and features, to reproduce training if needed.
Continuous deployment and serving infrastructure management
Once artifacts are published in the model registry they are ready to be delivered to serving environments. Depending on the model nature – batch or real-time serving – impacts which continuous delivery method is used:
- Batch model typically runs by schedule or event on top of a cluster;
- Real-time serving is typically implemented through a REST endpoint.
For a batch serving model, Apache Spark or Apache Flink application can be used, while a real-time serving model requires exposing interaction through a REST interface. Taking this reference architecture into account, Grid Dynamics has developed an ML Platform for AWS which we describe in the next section.
Solution architecture
Model development and model training
Model development and model training are the most time consuming parts of implementing an ML platform because they require setting up multiple environments with customized dependencies and infrastructures for different models, running and tracking different experiments for improving the model’s quality and many more important activities. Unification and automation of this process significantly reduces size from code to market.
The ML Platform, visualized in the architectural diagram below, is built using cloud-native best practices, with the ability to migrate to cloud agnostic if needed. Best-in-class cloud-native service, AWS SageMaker, provides a fully managed machine learning service, and Data Scientists and Developers are given access to Jupyter notebooks running on managed instances. AWS provides a number of sample notebooks with written solutions for a wide range of problems using their built-in algorithms. Those algorithms are highly optimized to run efficiently against extremely large data in a distributed environment. Moreover, it supports bring-your-own-algorithms and frameworks that makes it a much more flexible service for various needs.
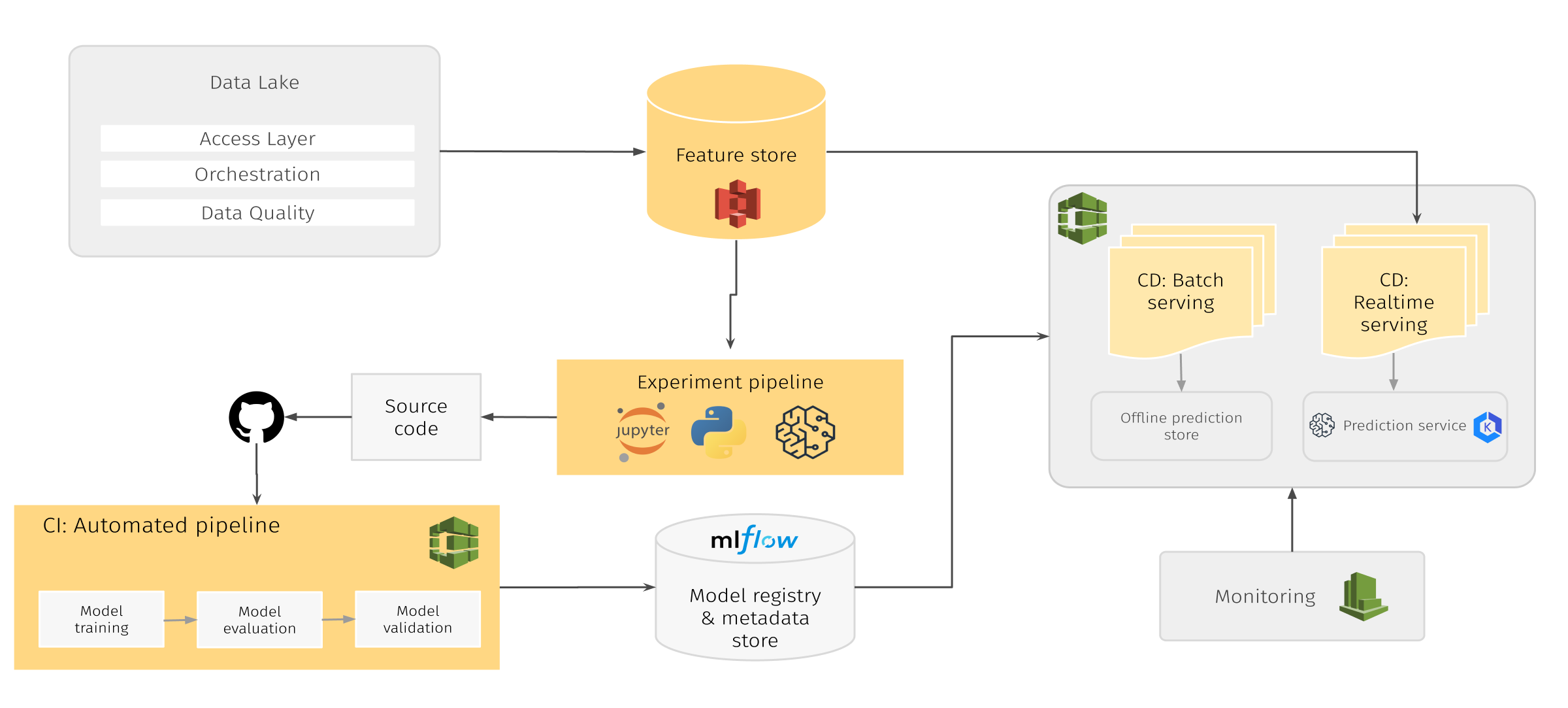
AWS SageMaker and MLflow
In the ML Platform, AWS SageMaker is used for model development, training, validation and serving, covering the major parts of the ML Platform capabilities we discussed above, while MLflow is used for experiments tracking and as a model registry. The reason the Platform comes with both SageMaker and MLflow is because SageMaker is focused on simplifying model development, hypothesis testing and deployment, whereas MLflow provides better capabilities in experiments tracking, comparison and model lifecycle management.
Generally, MLflow helps to manage the ML lifecycle, including experimentation, reproducibility, deployment, and a central model registry. MLflow currently offers the following components:
- MLflow Tracking
- MLflow Projects
- MLflow Models
- MLflow Registry
MLflow Tracking is organized around the concept of runs, which are executions of some piece of data science code. Each run records the following information:
- Code version – Git commit hash used for the run;
- Start and End time;
- Source – name of the file to launch the run, or the project name;
- Parameters;
- Metrics – with ability to visualize a metric’s full history;
- Artifacts – output files in any format (images, model’s data files).
MLflow Projects are just a convention for organizing and describing your code to let other Data Scientists (or automated tools) run it. Each project is simply a directory of files, or a Git repository, containing your code.
MLflow Model is a standard format for packaging machine learning models that can be used in a variety of downstream tools. Each MLflow Model is a directory containing arbitrary files, together with an ML model file in the root of the directory that can define multiple flavors in which the model can be viewed.
The MLflow Model Registry component is a centralized model store, set of APIs, and UI, to collaboratively manage the full lifecycle of an MLflow Model. It provides model lineage (indicating which MLflow experiment and run produced the model), model versioning, stage transitions (for example, from staging to production), and annotations.
The Model Registry introduces a few concepts that describe and facilitate the full lifecycle of an MLflow Model:
- Model – MLflow Model is created from an experiment or run that is logged with one of the model flavor’s methods.
- Registered model – MLflow Model can be registered with the Model Registry. A registered model has a unique name, contains versions, associated transitional stages, model lineage, and other metadata.
- Model version – unique number for specific model version.
- Model stage – each distinct model version can be assigned one stage at any given time. MLflow provides predefined stages for common use-cases such as Staging, Production or Archived.
- Annotations and descriptions – any relevant information useful for the team such as algorithm descriptions, dataset employed or methodology.
The illustration below shows the general approach of working with MLflow:
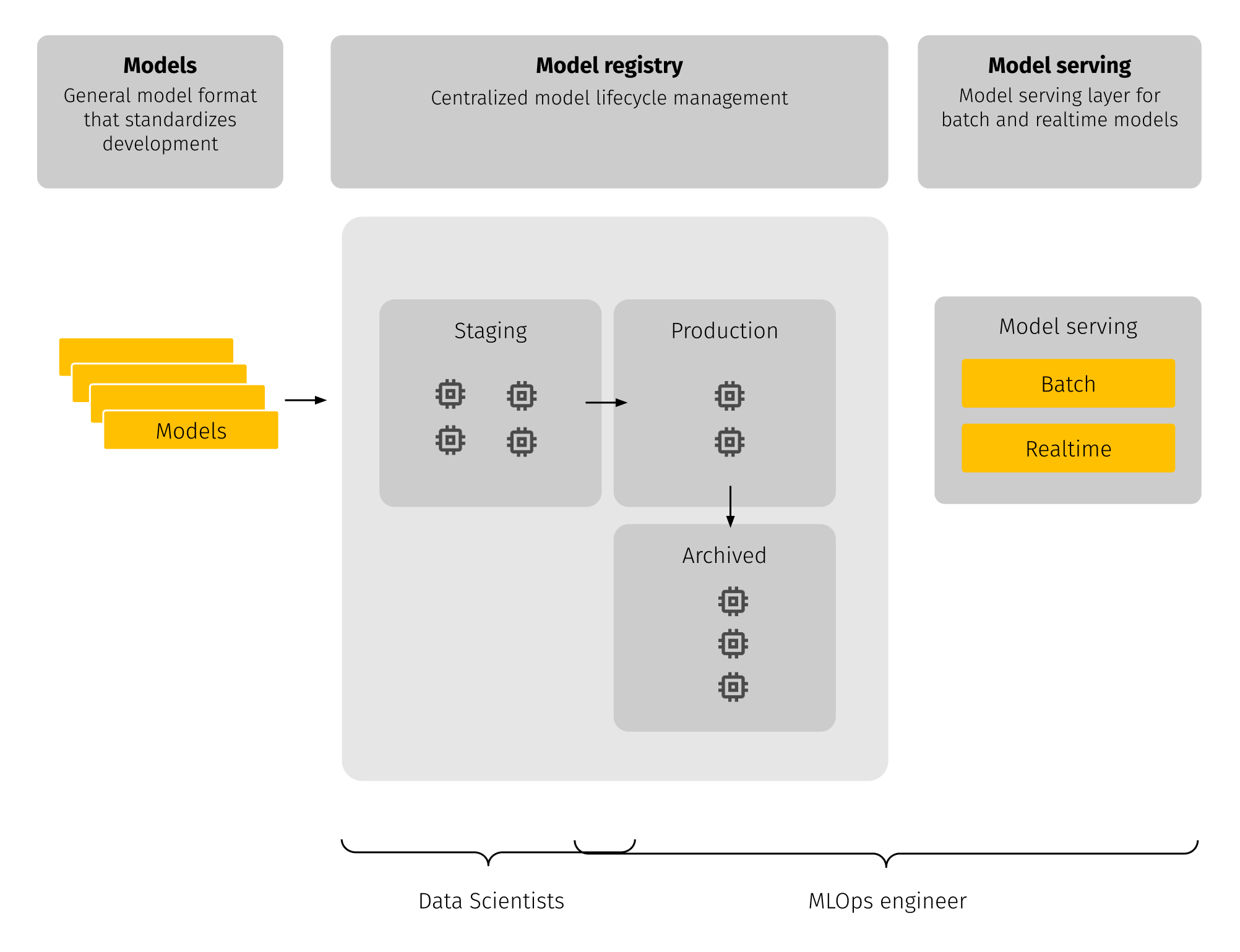
The advantages and features we have mentioned here make MLflow an irreplaceable part of MLOps practice.
CI/CD automation
Continuous integration and continuous delivery automation is a core part of any platform, and the ML Platform is no exception. The ML Platform comes with a pre-created CI/CD pipeline which helps to enable MLOps. At the provisioning stage, CI automation connects the given repository to build pipelines on top of AWS CodeBuild.
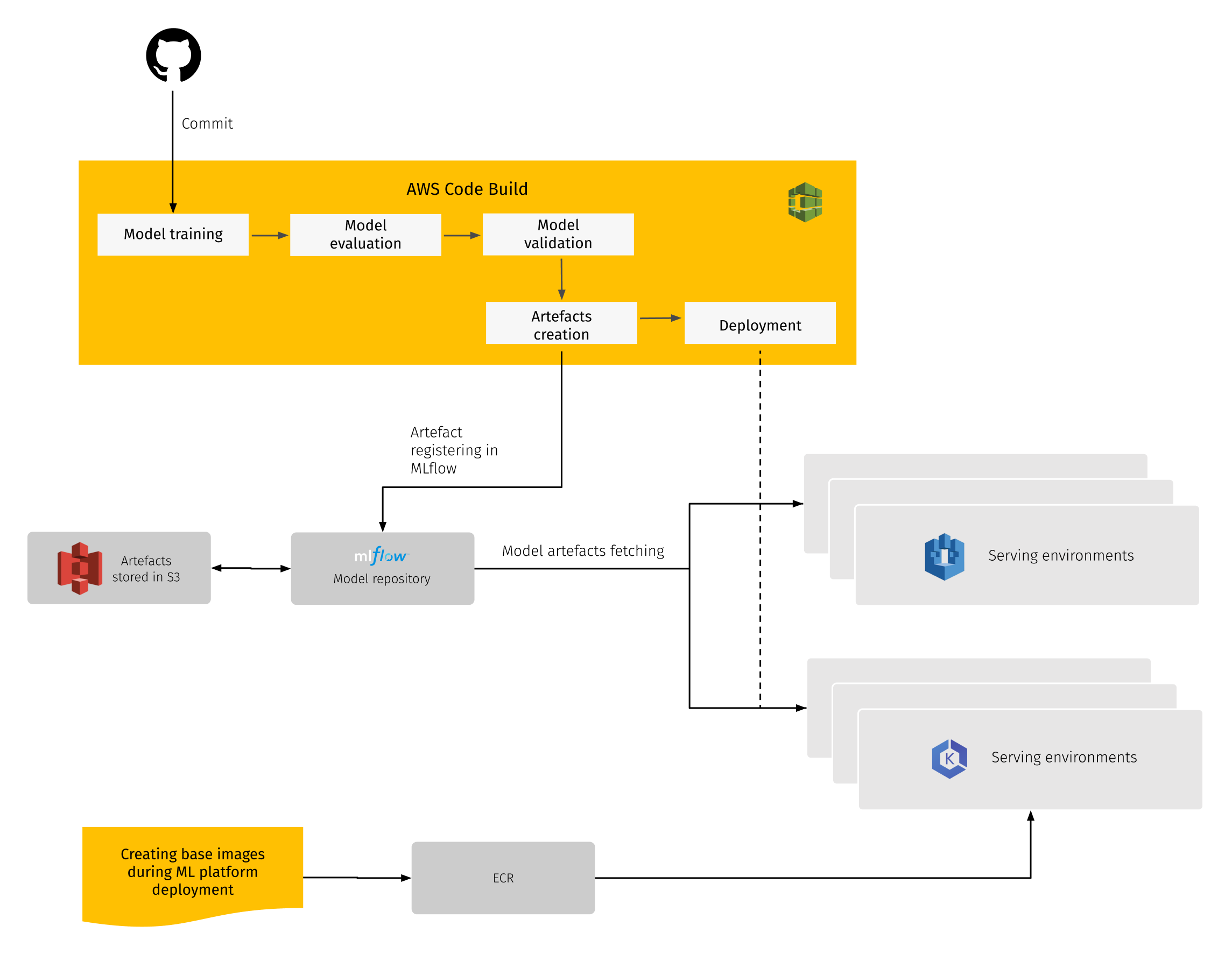
Once in the repository, any changes that appear will automatically trigger the pipeline to execute the following steps:
- Triggered build installs needed dependencies;
- Create artifacts;
- Run model training;
- (Optional) run scoring or evaluation.
Once the model is created and published in MLflow it can be used for deployment. CD automation takes the model and deploys either to Kubernetes cluster or to SageMaker endpoint.
Continuous integration and delivery for the ML models includes the pipeline, which wraps the model to a Python Flask application to expose the REST endpoint in Kubernetes or SageMaker.
The ML Platform comes with an example model and pipeline which demonstrates the concept. Overall, the ML Platform provides:
- MLflow as metadata management application;
- SageMaker notebook for model development and training;
- CI/CD pipeline implemented on top of CodeBuild and CodePipeline;
- Churn prediction model which demonstrates platform capabilities
Continuous delivery is tightly connected with the model serving layer which is built on top of both Kubernetes and SageMaker; where Kubernetes provides more flexibility and cost savings, and SageMaker provides scalability out of the box along with monitoring.
Model serving layer
The final step to a successful machine learning model development project is deploying that model into a production setting. Model deployment is arguably the hardest part of MLOps.
Model training is relatively formulaic, with a well-known set of tools and strategies. Model deployment is the exact opposite. Choice of deployment strategy and infrastructure is inextricably tied to user expectations, business rules, and technologies in any organization. Another possible source of problems is different algorithms used during the training stage. As a result, no two model deployments are the same.
The simplest, although not the cheapest, way to serve models is to use AWS SageMaker endpoints. AWS SageMaker endpoint is a fully managed service that allows you to make real-time inferences via a REST API.
If the model was developed on top of AWS SageMaker SDK then it’s pretty easy to deploy to the endpoint and make it available for API calls. This approach has some disadvantages:
- High dependency from SageMaker machine learning libraries;
- Pretty expensive prices for provided instances.
Another option for the serving layer is to use MLflow to create artifacts for every logged model and store them in the Model Registry. MLflow provides a common way to read artifacts and get predictions for a wide range of machine learning algorithms. It allows the creation of a Flask application that can read different artifacts and handle API calls for predictions. The same artifacts could be deployed to AWS SageMaker endpoint using MLflow functionality.
The diagram below shows the high level process of developing and deploying a model using the ML Platform.
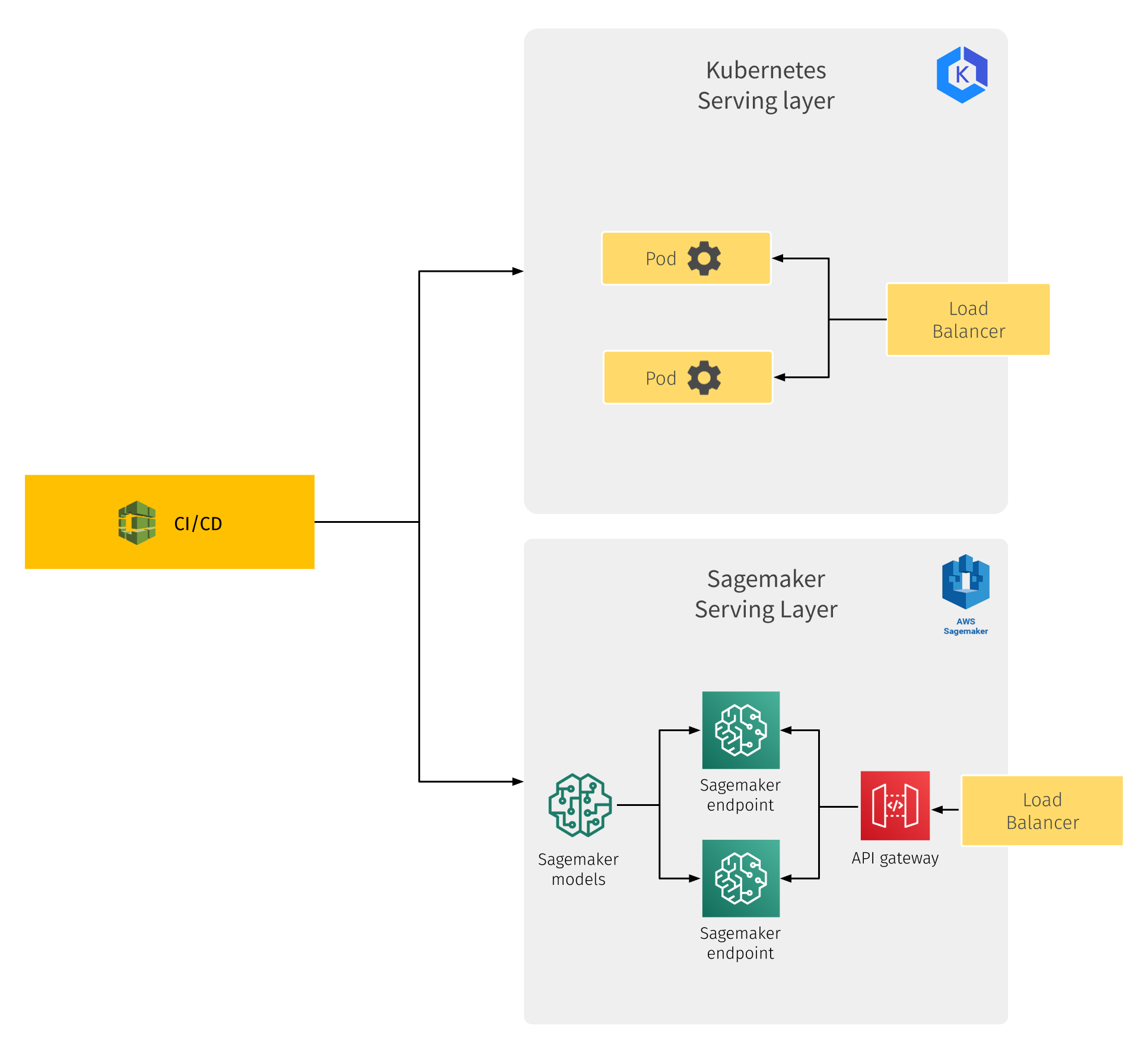
The ML Platform supports serving models either on top of AWS SageMaker endpoint (more expensive), or as a Flask application inside Kubernetes cluster (less expensive). Both approaches can use MLflow models for deployments.
Conclusion
Many companies spend a lot of time trying to resolve the following difficulties during the model development process:
- Complex infrastructure with diverse hardware and diverse environment needs, including libraries and frameworks;
- Multiple steps in the ML workflow with different requirements (e.g. fast compute for training, high bandwidth for data ingestion, low compute and lots of manual work in data preparation);
- Model lifecycle management – unlike traditional software, machine learning models can not be deployed and forgotten, as new data may imply a need to check for model drift and automatically update it;
- Compliance with current operations, not introducing completely new workflows for DevOps teams;
- Organizational adaptation to this new shared-responsibility.
The ML Platform helps to establish and unify model development, data engineering and CI/CD practices by introducing MLOps principles that enable Data Scientists and Data Engineers to focus their time on finding solutions for business problems instead of wasting time on endless reengineering of pipelines and models.
If you’re interested to learn more about our ML Platform, get in touch with us to start a conversation.