
Fighting with biases: How to measure diversity in streaming media




TV broadcasters have long held an indisputable title as the main players in the home entertainment industry. But, with the advancement of broadband technologies, this industry has been rapidly taken over by the online streaming platforms, which now became the most prominent source of information and entertainment.
Some of the main benefits of on-demand online streaming is the freedom to choose the content at any given time, but even more so, the ability of the provider to custom tailor the service to fit the individual user’s preferences.
In order to do this effectively, giants of the streaming industry such as Netflix, Hulu, and Disney+, have been investing heavily into their recommendation systems over the past couple of years. And while everyone watching Netflix must agree that the quality of recommendations has improved exponentially over the past two or three years, this didn’t happen without some controversy.
The most notable example is the personalized thumbnail feature Netflix introduced in 2017, where the recommendation model generates a custom thumbnail so that each user will see a different image representing the same movie. This project was largely based on an internal research which suggested that users tend to make their decisions largely based on visual artwork presented. The problem emerged, when many African-American users reported that their thumbnail design was featuring black actors, even though their roles in the movie were marginal or insignificant, indicating that ethnicity information is being used directly or indirectly. [source]
The ‘bias’
Racial bias is a recurring subject in machine learning discussions and represents certainly one of the biggest hurdles modern machine learning applications face.
It is unlikely that any streaming service provider, with a competent legal department,will intentionally use race or ethnicity as a feature. However information flows in mysterious ways, and there are features through which ethnic information may “leak” into a recommendation model:
- Movie cast - People have favorite actors whose movies they follow , and streaming services definitely use this as a feature
- Movie directors - Directors often have recurring actors, or deal with similar themes.
- People who liked that also - This is perhaps the single biggest contributor to ethnically driven recommendations. Movies are often filmed and targeted for an audience from a specific ethnic group, or deal with themes which are more common among certain groups ( hip hop for example)
- People in your area also - Similarly to the previous one, if there are geographic clusters of preferred story topics, actors or ethnic preferences, this may lead to someone being recommended ethnicity-inspired content.
This simply shows how difficult it may be to completely cancel out ethnicity information from a recommender system, without seriously impairing its performance. So instead of trying to delete features, one solution is to add features which could represent ethnic, age and gender diversity. These features can further be included as the recommendation or even ranking criteria.
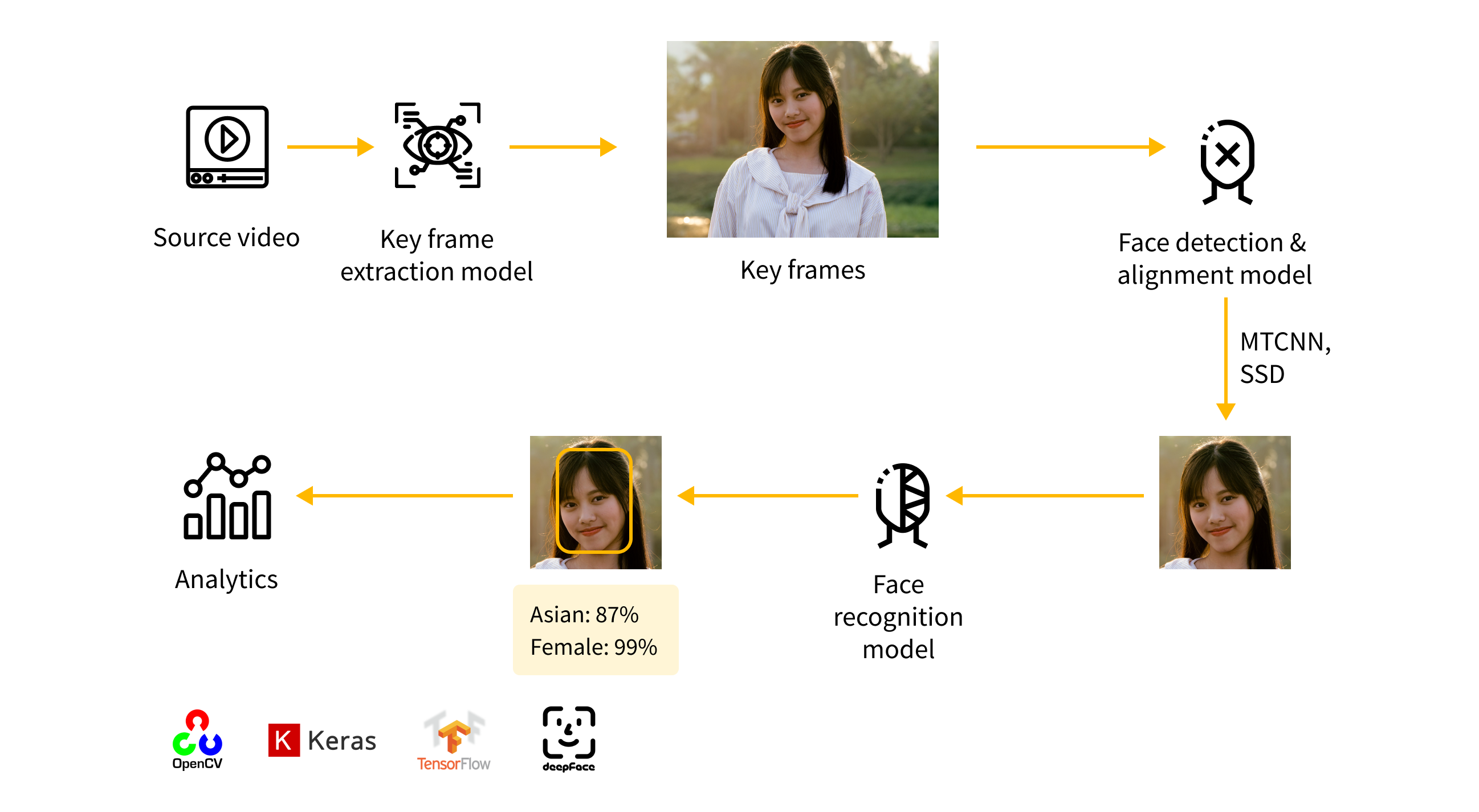
We propose a method for automatic video diversity estimation. First step in our approach is to extract faces of all participants in videos using object detection models. After that, extracted faces are classified into different age, ethnicity and gender groups using CNN deep learning models. Finally, we evaluate the approach not only in terms of accuracy, but time and memory demands as well. That is, methodology should be capable of processing large amounts of videos in a cost and time efficient manner while retaining its accuracy.
Methodology
Face detection
The first step in our pipeline is to detect where the faces are in the video. OpenCV library can help us split the input video into a chain of frames, each frame being a single RGB image. This way, our video processing task becomes frame-by-frame image processing.
Detecting instances of objects of any class within an image is commonly referred to as object detection. Since in our case the only class we want to detect is a face, and since face detection is a task that has been tackled by researchers before, it would be useful to take a look at some existing approaches.
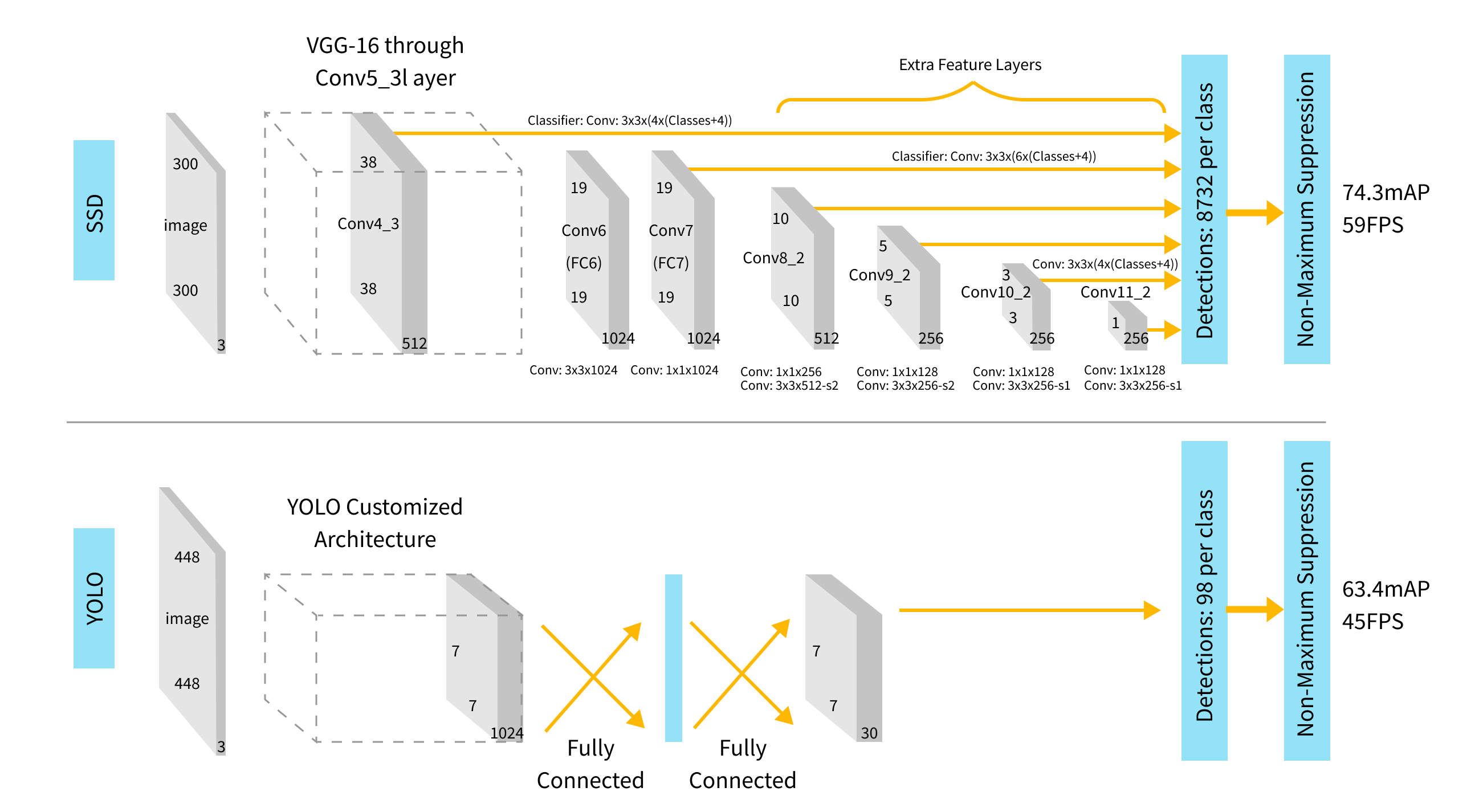
The state-of-the-art object detection methods can be categorized into one-stage methods and two stage-methods. The main difference between these is the way in which they handle the speed-precision trade-off. One-stage methods prioritize inference time ,i.e., they sacrifice precision in order to be able to perform inference on large numbers of images quickly, which makes them useful in online object detection tasks. Examples of such models include YOLO, SSD and RetinaNet.
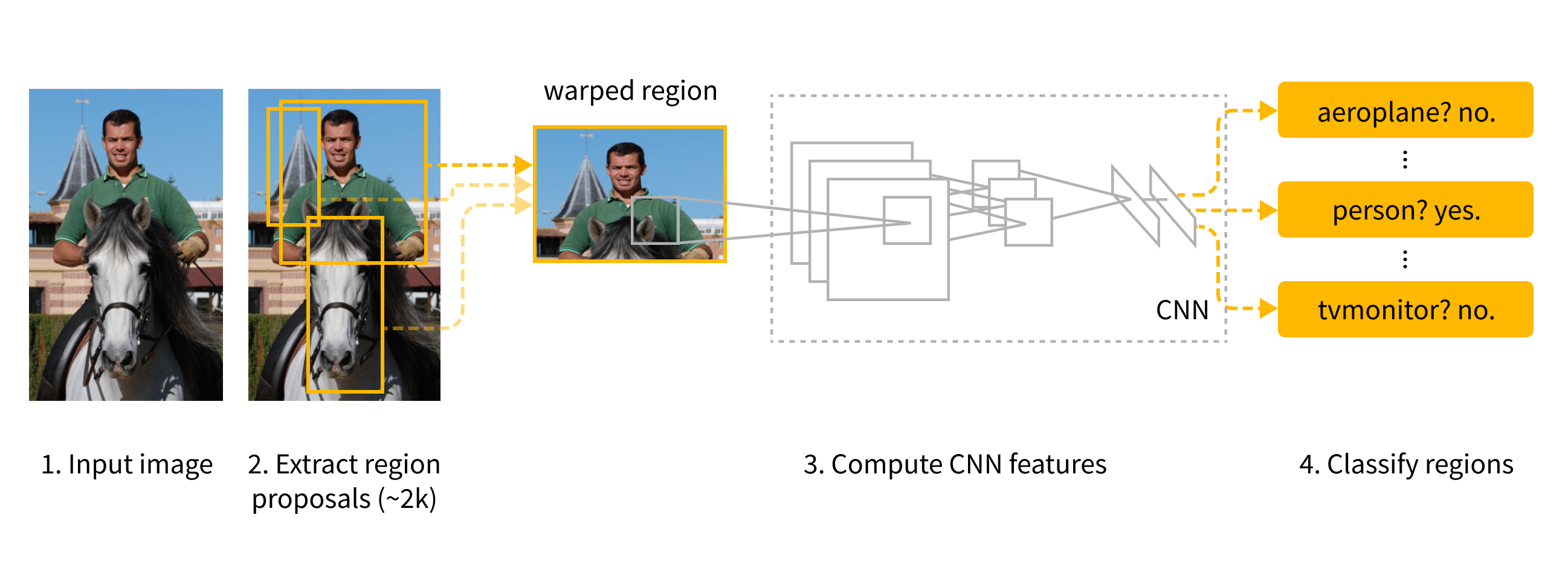
On the other hand, two-stage methods prioritize detection precision. They provide better performance, but at the cost of speed. The reason they are called two-staged is because they tend to be a combination of two models: Region proposal network, which identifies regions of the photo with the highest probability of containing an object, and classifier model, which tries to guess which object is present in these regions. MOst notable examples of two-stage models are Cascade R-CNN, Mask R-CNN and Faster R-CNN.
Since the problem we are trying to solve demands both speed and accuracy, a one-stage model class Single-Shot multibox Detection (SSD) with Mobilenet backbone turned out to be the best choice for face detection.
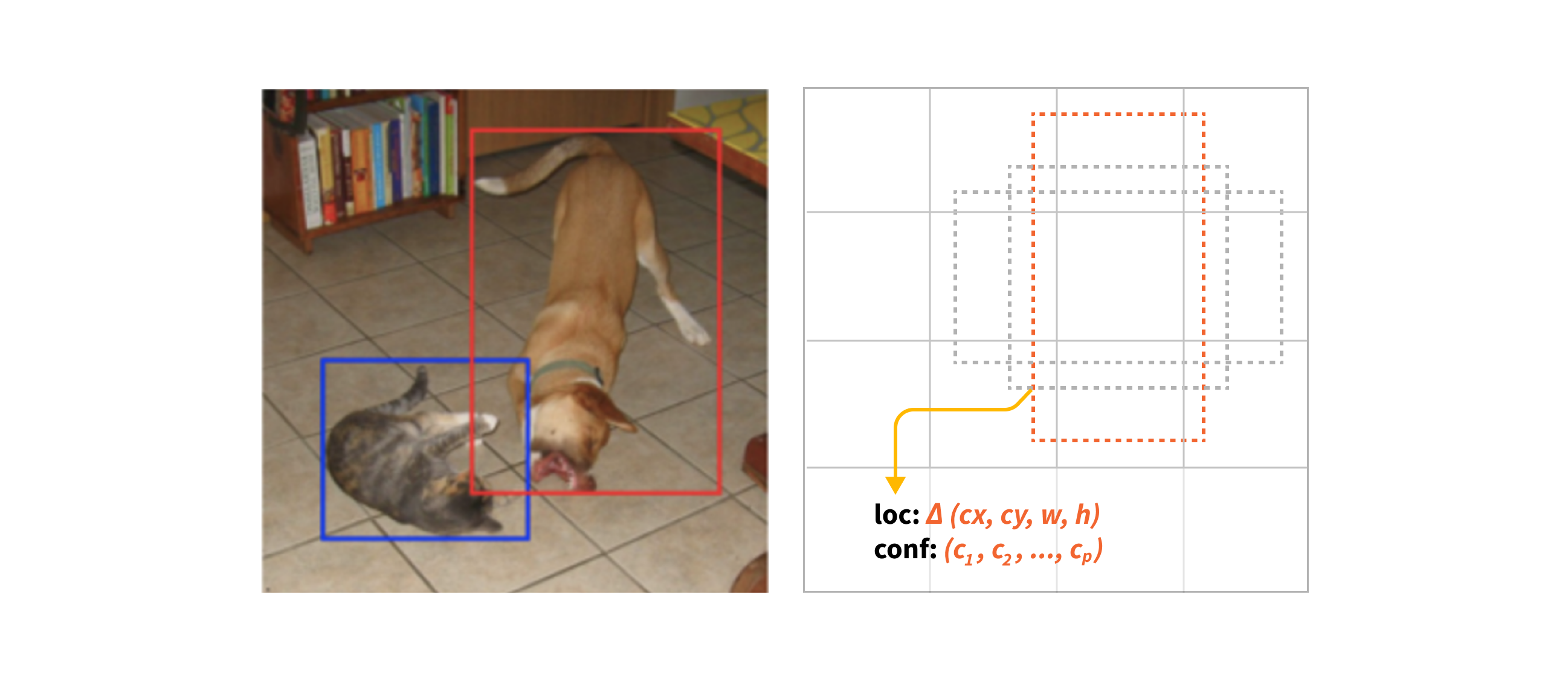
SSD is based on a feed-forward convolutional network which starts off by testing a predetermined set of bounding boxes. For each default box, it predicts both the shape offsets and the confidences for all object categories ((c1, c2, · · · , cp)).
At training time, it first matches these default boxes to the ground truth boxes. The model loss is a weighted sum between localization loss (e.g. Smooth L1) and confidence loss (e.g. Softmax).
The early network layers of SSD can be based on different architectures, for example the original framework was based on VGG-16, however there are more efficient alternatives that can be incorporated. One of the most efficient models in terms of speed is mobilenet.
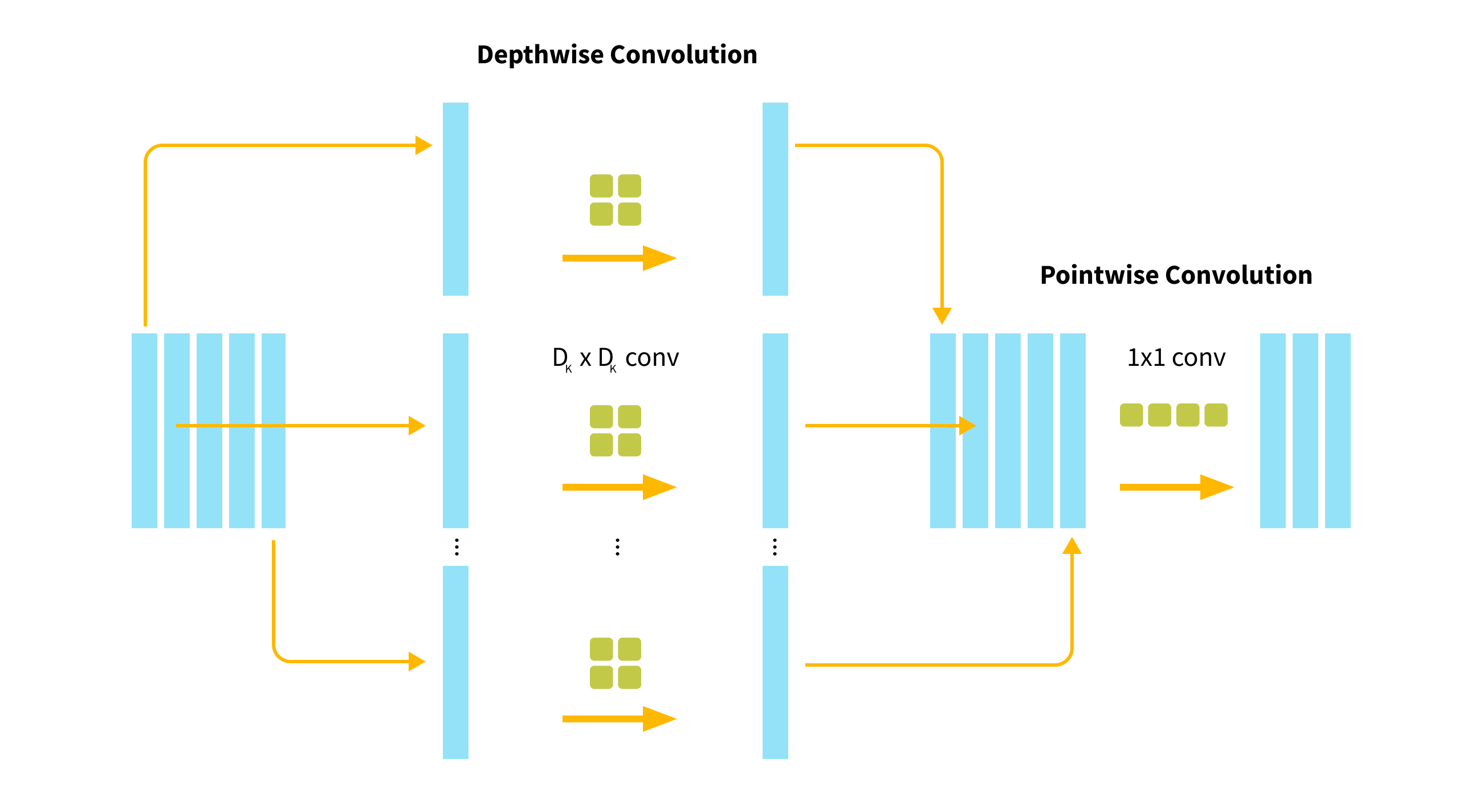
The key component of mobilenet’s efficiency are depth-wise separable convolutions which use between 8 to 9 times less computation than standard convolutions do at only a small reduction in accuracy. The combination of a depthwise convolution and 1 × 1 (pointwise) convolution is called depthwise separable convolution.
Gender and ethnicity classification
For the next step we will only use a part of the image, that is within the face bounding box. Gender and ethnicity models are two separate classification models, each of them trained on publicly available Fairface dataset. To include more representations of faces displaying different emotions, we enriched this dataset with additional data we scraped from the internet.
For the gender classification part, we used a pre-trained gender model from a deepface framework which is based on the VGG-Face model.
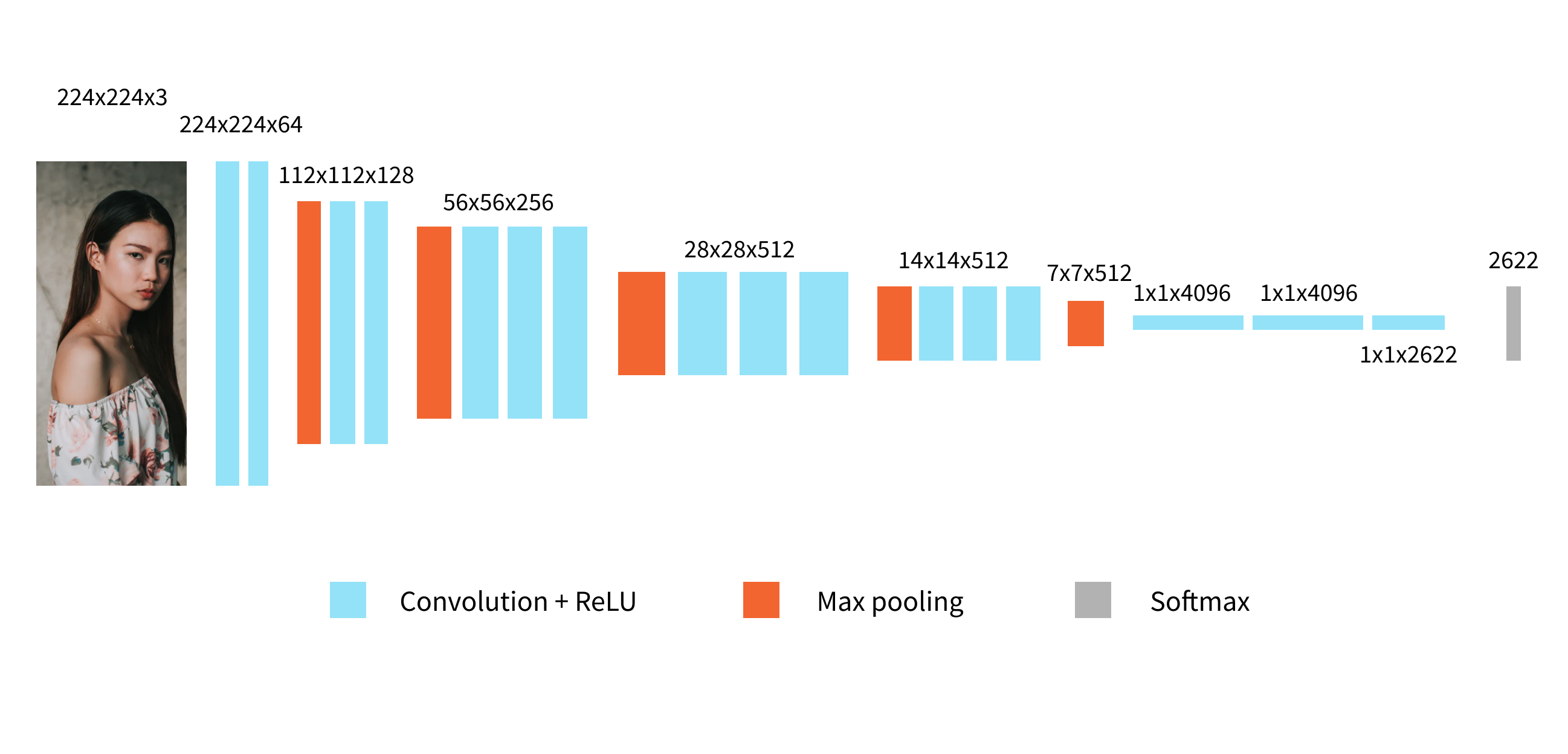
Training it from scratch would require a lot of time and effort, so a better solution is use fine-tuning - take a model which is pre-trained on a large dataset, unfreeze top layers and train them using our small dataset.
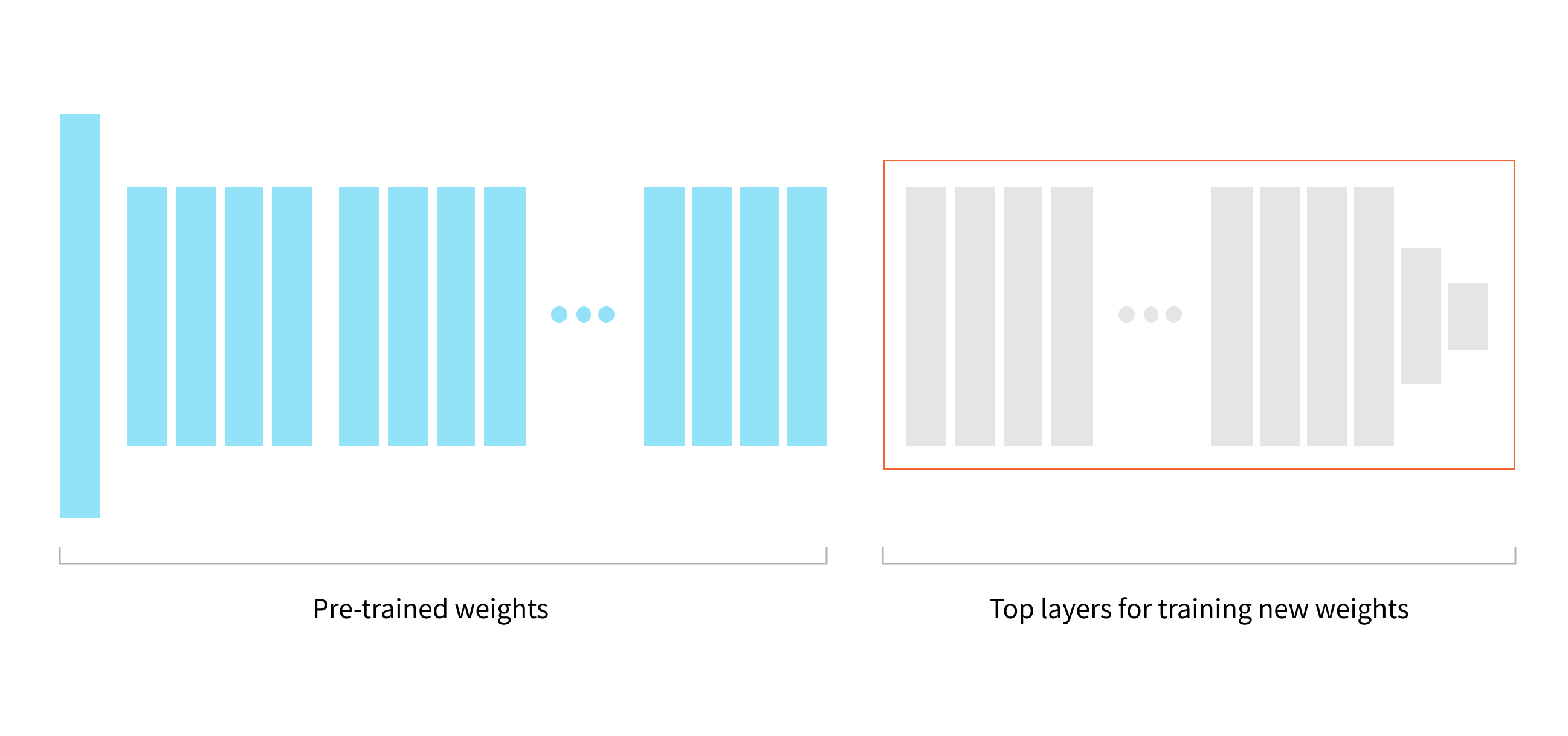
For our training strategy, we use callbacks to save the model weights at some frequency, callback to stop training when a validation loss metric has stopped improving and a callback that updates the learning rate value on each epoch. These techniques ensure better prediction accuracy with the minimum number of training epochs.
It turns out that determining someone’s ethnicity on the video is a much more difficult task than determining their gender. We needed to significantly increase the variety of our training images. To achieve this, we tested various data augmentation techniques, the most promising one being lowering image resolutions and brightness with randomized coefficients. Some other augmentation techniques, such as noise adding augmentation methods, surprisingly weren’t much useful.
Our initial vanila ethnicity classification model wasn’t going to cut it. We finally settled on EfficientNetB2 network using the same fine-tuning approach we used on our gender classifier, with the same list of callbacks.
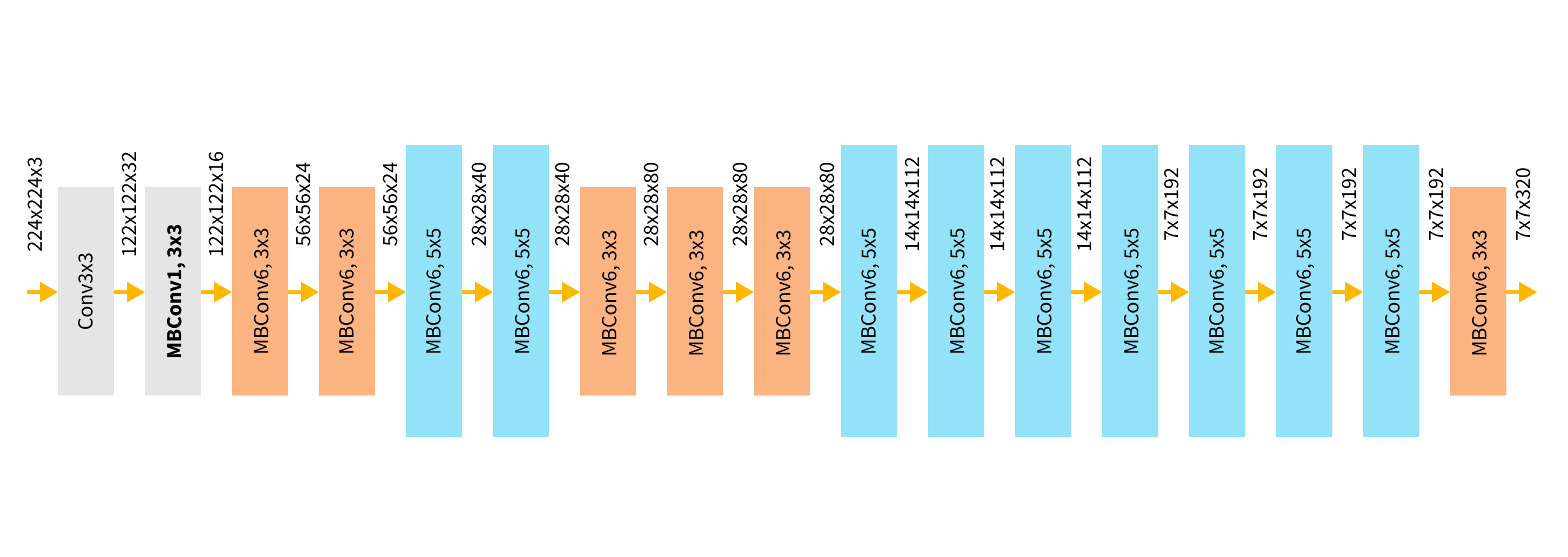
Evaluation
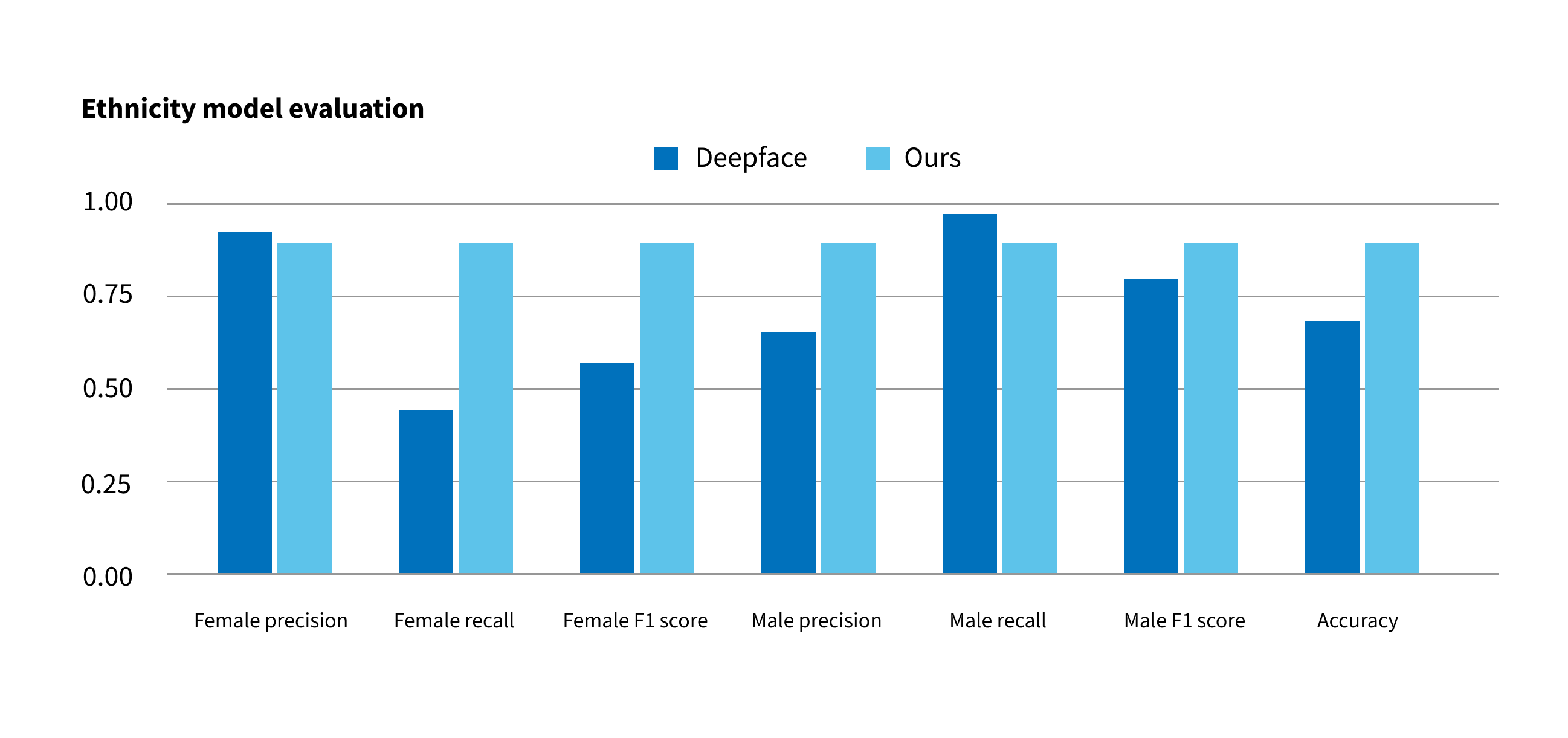
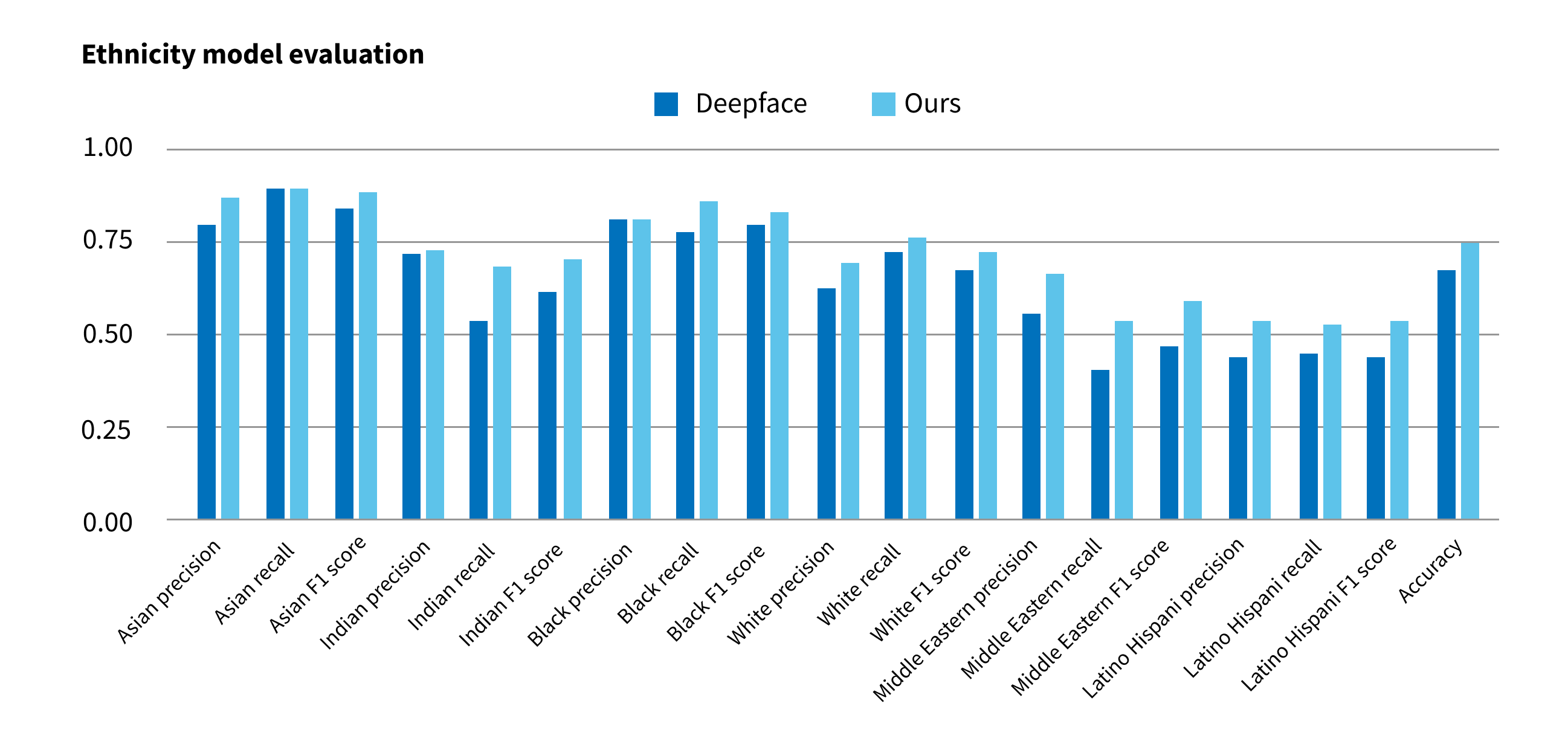
Using a balanced Fairface dataset and various model tuning techniques, we were able to achieve 30% accuracy improvement compared to the DeepFace gender model. Ethnicity model tuning was much more challenging, but we managed to achieve the accuracy improvement of 11%.

Memory, time monetary cost estimates
As we mentioned above, besides accuracy, time, memory and monetary costs are just as important performance indicators. We tried to find a balance between speed and precision. So we estimated monetary costs by testing on different AWS Cloud provider machines with different configurations starting from the cheapest one to the most expensive one.
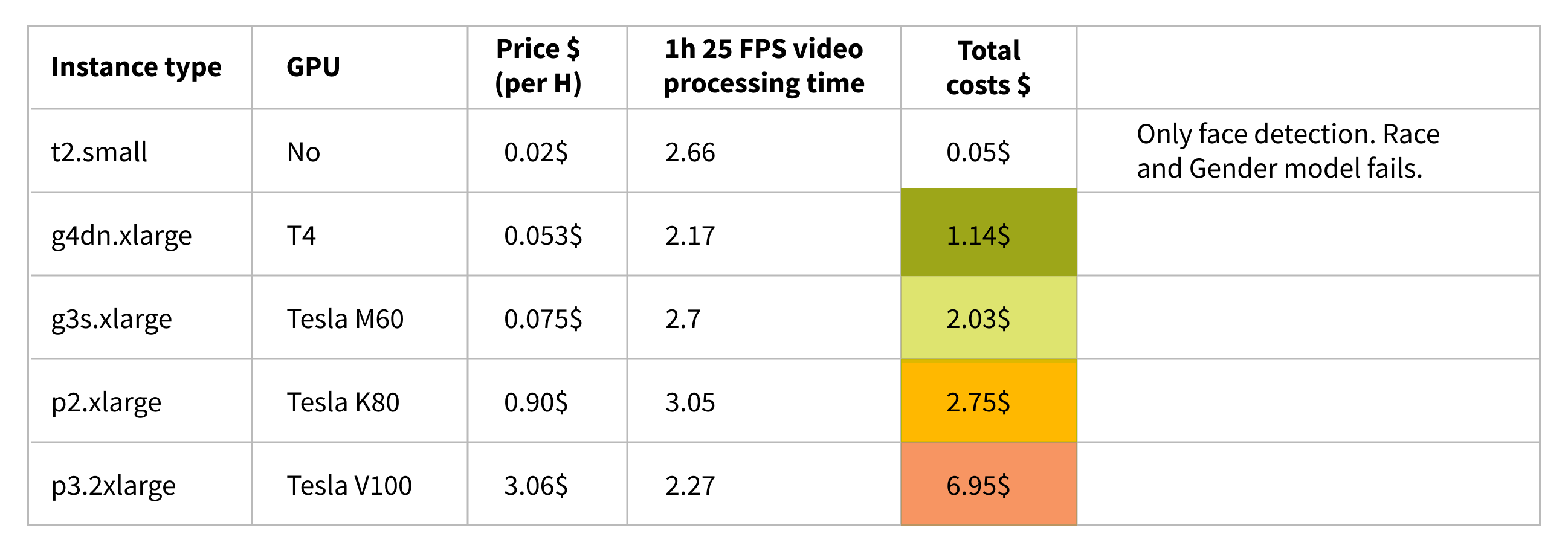
From the cost perspective the most efficient approach seems to be running video processing on an ‘g4dn.xlarge’ instance with Nvidia T4 GPU.
Batch processing
In order to make video processing less time-consuming, it would be useful if we could run predictions on a batch of frames at the same time, rather than on a frame-by-frame basis.
But since consecutive frames may have different numbers of faces, the main problem with batch processing in object detection is mapping those model predictions with their respective frames once all results are stacked together.
Object detection model takes multiple frames as input and outputs a matrix of bounding boxes and scores. Face bounding boxes are represented as a matrix of shape [number_of_frames x number_of_faces x 4], while scores are presented as a 2-dimensional matrix of shape [number_of_frames x number_of_faces] with elements being probabilities that a face is detected in the respective bounding box. The maximum number of faces the model can detect was set to 100, so we used the scores matrix as a mask to filter out faces with prediction scores lower than a certain threshold.

Moreover, we used masks to create vectors of ids in order to map faces to their frames. Firstly, we generate a vector of id’s by multiplying the mask matrix with the vector of sorted index values from 1 to number_of_frames. Secondly, we flatten the matrix, filter out the zeros and end up with an array of values that map each row in a bounding box matrix to its corresponding frame.
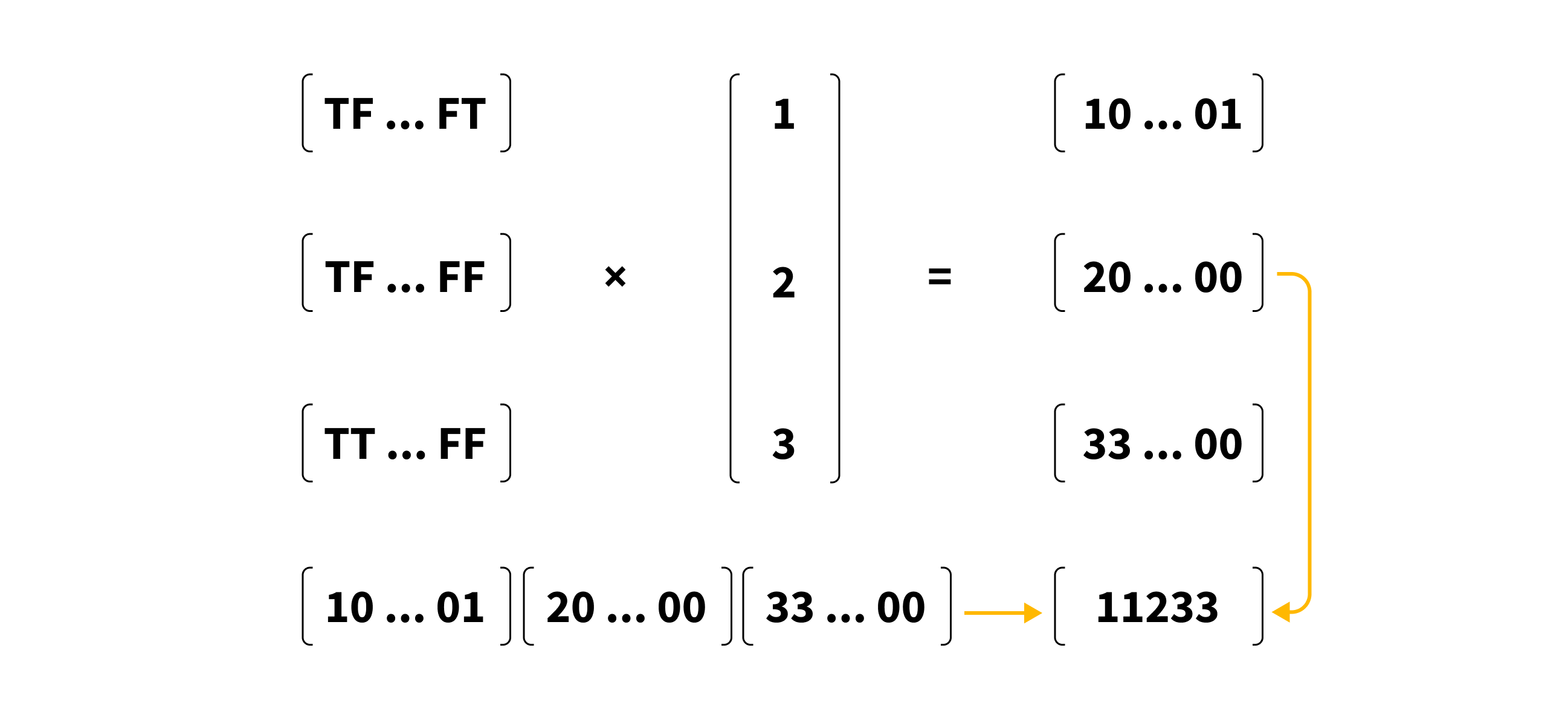
We can use this new matrix to filter faces, after which the rest of the faces are stacked into one batch for further processing. In the end, faces which are too small are removed, and small boxes are padded. All this can be done in one pass using an array to mask small boxes and expand them by a default padding parameter.
In order to prepare a batch of images resized to required shape for classification models further in a pipeline, we use a matrix of faces coordinates and an array of respective frames. This was implemented by the function blobFromImages, from the opencv package, that returns a 4-dimensional matrix [number_of_faces x number_of_channels x width x high]. Therefore, we have a fully prepared batch that could be fed into our classification models, whose final output is an array of labels for each face. Finally, we used the vector with frame ids to map the bounding boxes and labels back to their respective frames.
In comparison with our batch processing implementation, the original naive frame-by-frame method took approximately 17.6% more time to process the same video samples!
Conclusion
The ability to automatically assess the diversity of videos has use-cases that go way beyond recommending movies. Retailers are interested in ethnic, gender and age distributions of people visiting their stores. What used to require hiring a market research agency, surveys and questionnaires can be done cheaply with a single in-store camera.
As next steps, we can further improve the accuracy of our models by highlighting multi-object tracking in the videos. Beside this, additional models may be added to the pipeline, such as emotion recognition, for example. This could be used to determine the satisfaction level of customers for instance.
Finally, an important note should be made about the existing face classification datasets. Often, these datasets need to be complemented by faces of all nationalities, genders and ages, with additional variations. Parameters such as emotion, facial symmetry, length or width of facial elements play an important role in the variety of datasets intended for face classification tasks. By adding examples of individuals with a variety of these characteristics, it may be possible to improve the quality of classification and, as a result, the quality of diversity analysis as a whole.