


Over the last ten years, the role of data in modern enterprise has continued to evolve at a rapid pace. Companies launched initiatives to define and execute their data strategy, appointed Chief Data Officers, and created large teams to collect, manage, and generate insights from data. With increased awareness and higher demands for data, the concept of an analytics platform evolved as well.
It is now no longer enough to implement a data lake to manage increased volume, velocity, and variety of corporate data assets. The veracity, or trustworthiness of data has also become vital along with accessibility, ease of use, and support of DataOps and MLOps best practices. In this article, we will describe the blueprint for the modern analytics platform and the journey from a data lake to a modern data analytics toolset.
The prehistoric era and the big bang of data
In the good old days, when data was small and structured, OLAP cubes ruled the world of analytics. EDW technologies and analytical databases coupled with reporting and limited machine learning capabilities were enough to manage corporate data assets and satisfy corporate analytics needs. The number of data sources was manageable and the vast majority of data collection was done in batches on a weekly or daily basis via ETLs.
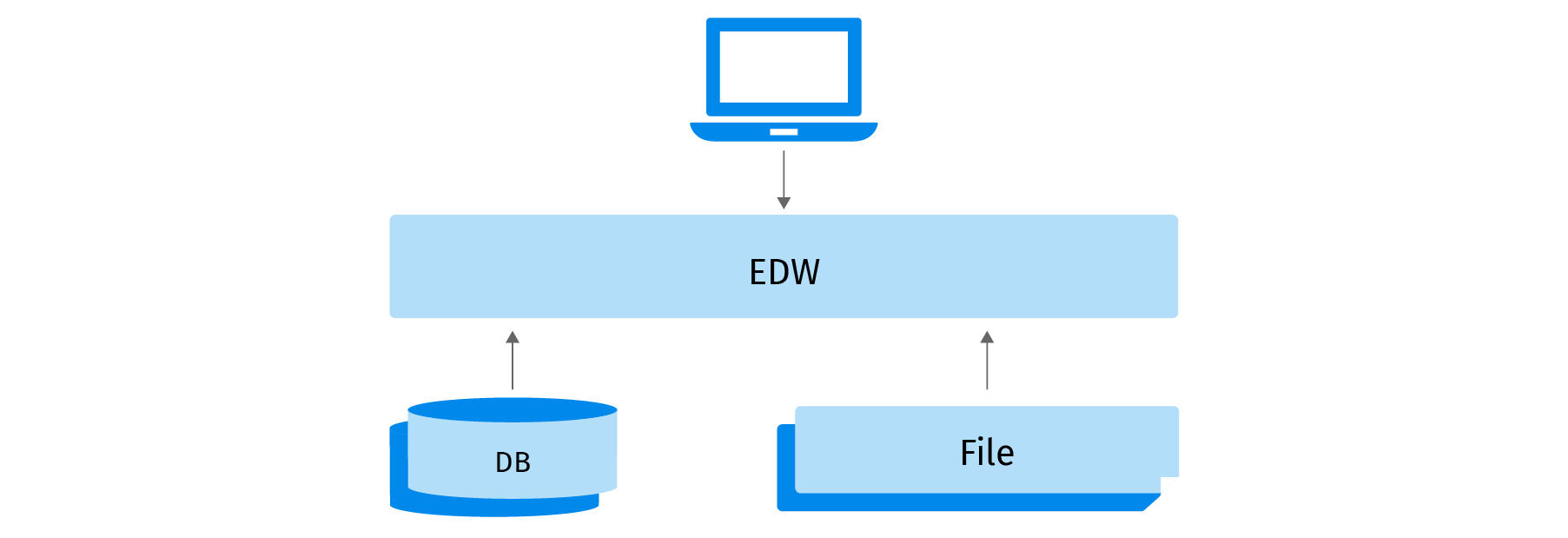
But the digital era brought changes that traditional analytics ecosystems couldn’t deal with well:
- As people massively moved online the number of digital interactions with customers, employees, users, and vendors increased enormously leading to the explosive growth of captured data. Clickstream started generating terabytes of data on a daily basis.
- The adoption of IoT increased data volumes even further.
- Companies saw value in unstructured data such as images, voice, and text. The collection of this data triggered advances in AI, which allowed for insights to be generated from this data.
- Keeping individual datasets in silos made it difficult to implement a 360-degree view of a customer and enterprise.
EDWs couldn’t handle the new volumes, variety, and velocity of data. The new generation of systems called data lakes, which were often based on Hadoop (HDFS) and Spark technologies, took over the analytics world.
Data lake or data swamp?
These data lakes quickly matured and by the mid-2010s most companies had deployed data lakes and used them to aggregate all enterprise data assets. The maturity of cloud computing was lagging so most deployments were done on-premise in data centers. It was surprisingly easy to dump the data in the lakes and the cost of storing data in the lakes wasn’t prohibitively large.
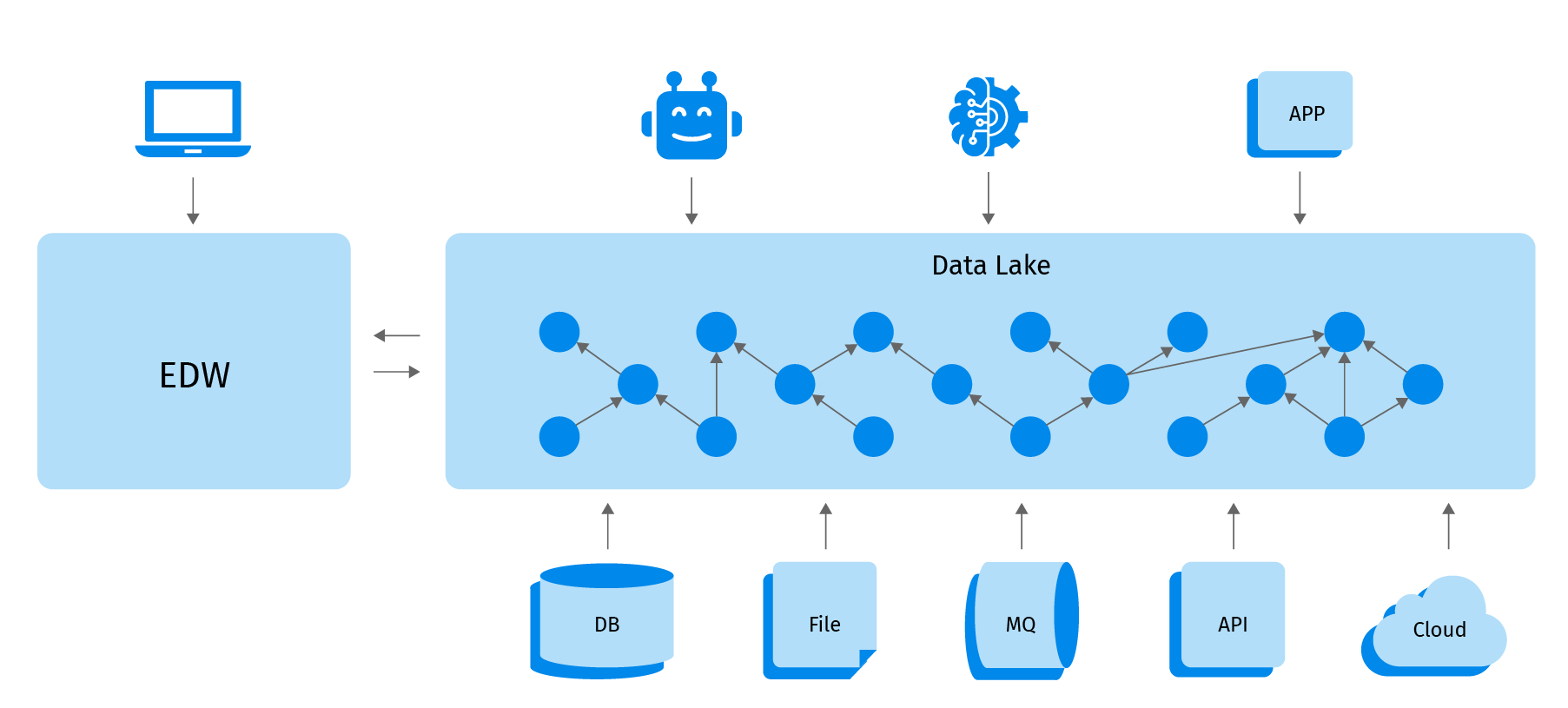
Unfortunately, getting value out of data was becoming a much bigger problem. The early data lakes had a variety of issues:
- While putting data in the lake wasn’t difficult, processing data and connecting different datasets together required new skills and expertise.
- Finding the right data in the lake was difficult, leading to the low productivity of data analysts and scientists. The inability to find the right data often led to duplication of data, further worsening accessibility issues.
- Security policies tended to be either too relaxed or too strict, leading to either exposing sensitive data to the wrong people or restricting access so much that the lake was difficult to use.
- Stream processing remained an advanced technique that many companies didn’t implement.
- Lack of DevOps and DataOps processes as well as non-existent best practices for testing of data pipelines made the development of new data processing pipelines extremely difficult.
All those challenges led to a rapid deterioration of trust in the data from analysts, scientists, and business stakeholders. Companies quickly saw diminishing returns and observed their data lakes turning into data swamps.
The analytics platform blueprint
By the mid 2010’s, the simplicity of getting data into the lakes resulted in many companies recognizing they had simply created data swamps. In many ways, it was a reasonable position to reach in the journey towards a truly data-driven organization. However, there is no excuse to repeat the same mistake in 2020 and get stuck with a basic data lake.
After helping a number of Fortune-1000 companies and tech startups build analytics platforms from scratch or migrate them to the cloud, Grid Dynamics created a technology blueprint for a modern Analytics Platform.
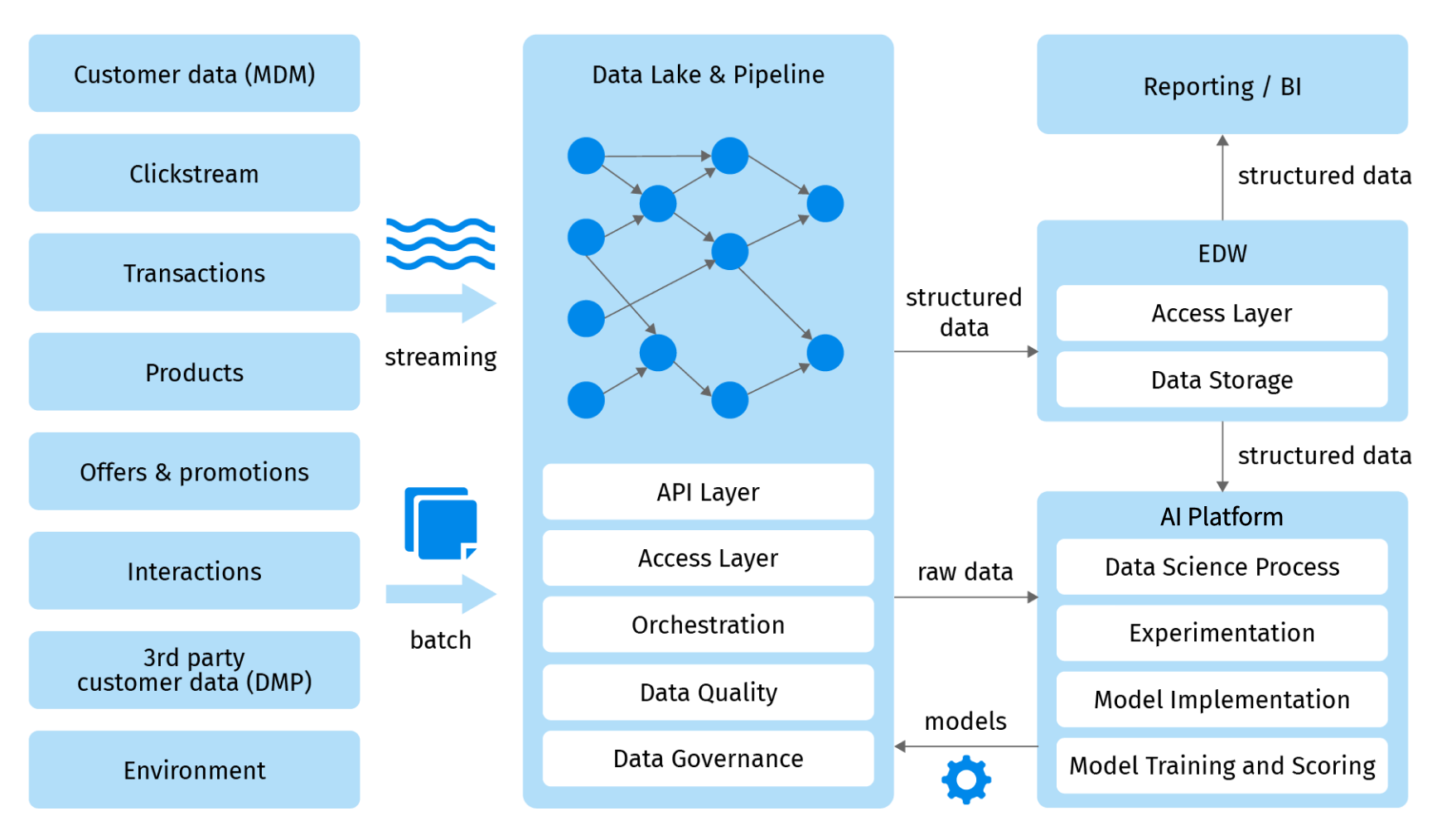
When coupled with the right data governance, DataOps, and MLOps best practices, processes, and organizational structure, it provides a robust set of capabilities to satisfy the data, analytics, and AI/ML needs of any enterprise. Let us briefly describe its capabilities.
Data lake
The data lake still plays a central role in the picture. All data ingest and processing initially goes through the data lake. However, the new data lake is not limited to storing and processing data. It has a number of important capabilities:
- Orchestration - the total number of data ingestion, cleansing, deduplication, and transformation jobs in a typical enterprise can be measured in the thousands or tens of thousands. Data pipeline orchestration is needed to execute the jobs at the right time, manage inter-job dependencies, facilitate the release and continuous delivery process, and enable flexible configurations. You can find more details about the importance and value of orchestration in our recently published whitepaper.
- Access layer - putting data in the lake is easy. Getting secure, convenient, and fast access to it is hard. Access layer capability enables data analysts and scientists to find and retrieve the required data. Together with the data catalog, an access layer can be extended into a semantic layer.
- API - in addition to the access layer that serves data analysts and scientists, modern analytics platforms often need to provide access to data to other applications. To do that in real-time, batch and streaming APIs need to be implemented. In case real-time access to key-value data is needed, additional systems and databases may be deployed to satisfy the performance and scalability needs of the client applications.
- Data catalog and lineage - while data catalog can be thought of as part of the access layer, we separate it as it is often implemented on a different technology stack. For example, the access layer to a data lake can be implemented in Apache Hive or Apache Presto and typical technologies for data catalog include Apache Atlas, Amazon Glue, Collibra, or Alation. In any case, the purpose of the data catalog is to enable data analysts, scientists, and engineers to find the required datasets in the lake and EDW. Data lineage is then used to analyze how and from what datasets a particular dataset was created. For more details, please read our recent whitepaper.
- Data monitoring and quality - the famous saying “garbage in - garbage out” best applies to analytics platforms. Data can get corrupted due to a number of reasons including defects in data sources, issues with data import middleware or infrastructure, and defects in data processing pipelines. No matter how it gets corrupted, it is important to catch the defects as early as possible and prevent them from spreading in the system. For more details, please refer to our blog post and whitepaper.
Ingestion: batch and streaming
The lake has two major ways to ingest data: batch and streaming. Batch processing is used to get data from services via API calls, import files, and database dumps. Stream processing relies on modern messaging middleware such as Kafka, or cloud services. Products such as Lenses.io help to maintain data quality at this level. The streaming data ingestion is not limited to clickstream and is often coupled with application design patterns such as CQRS.
EDW
While solving a number of new problems, data lakes do not completely replace enterprise data warehouse systems. EDW is an important part of a modern analytics platform and helps with fast and secure access to structured and pre-processed data. To ensure high performance and scalability, most reporting and visualization tooling should be implemented on top of EDWs instead of directly having access to data lakes. In many cases, data scientists will find it more convenient to work with “golden data” in EDW than having direct access to data lakes.
Reporting and visualization
Reporting and visualization remain important capabilities of any analytics platform. Most business users still interact with data via reporting and visualization tooling instead of getting direct access to EDWs or data lakes.
AI/ML platform
The rise of AI and machine learning in recent years increased the importance of augmenting human decision-making processes. To be able to scale AI/ML efforts at the enterprise scale, and implement efficient MLOps processes, data scientists need a platform. Modern AI/ML platforms have a number of capabilities to make the life of data scientists easier including:
- Data preparation and experimentation
- Notebooks
- Feature engineering
- AutoML
- Model training and scoring
- Batch and real-time serving
- ML quality control
The AI/ML platform as well as the MLOps process deserves a separate blog post so we will not get into a detailed discussion here.
CI/CD infrastructure
As with any code, data processing pipelines have to be developed, tested, and released. Analytics platforms often miss CI/CD capabilities, increasing the number of defects in data processing and leading to poor quality of data and unstable system performance. At the same time, DevOps and continuous delivery processes for data pipelines have their own specifics:
- Due to large volumes of data, a strong focus should be placed on unit testing and functional testing with generated data.
- Due to the large scale of the production environment it is often impractical to create on-demand environments for every execution of the CI/CD pipeline.
- Data orchestration tooling needs to be used for safe releases and A/B testing in production.
- A larger focus needs to be placed on data quality and monitoring in production and testing for data outputs.
Overall, the principles we outlined in the article about the release process for microservices apply to testing of data pipelines. Data pipelines and data processing jobs can be thought of as microservices in the regular application architecture. Instead of API contracts in the case of microservices, data pipelines' contracts are files or data streams.
Technology stack options
There are many technology options for each capability in the blueprint. Having practical experience with many of them, we will give several examples in the table below: one based on open source stack, one based on 3rd party paid products and services, and one based on cloud services of the three major cloud providers: Amazon AWS, Google Cloud, and Microsoft Azure.
| Capability | Open-source | 3rd party | AWS | GCP | Azure |
| Data lake | Hadoop, Hue | Databricks, Cloudera | S3, Glue, EMR | Google Storage, Dataproc, Dataflow | Blob Storage, Data Catalog, HDInsight |
| Messaging | Apache Kafka | Lenses.io Confluent | Kinesis | Pub/Sub | Event Hubs |
| File storage | HDFS | S3 | Google Storage | Blob Storage | |
| EDW | N/A | Snowflake | Redshift | BigQuery | Azure Synapse is in GA phase |
| Access layer | Hue | Talend Datameer Informatica | Athena | N/A | Data Lake Analyticse |
| Reporting and visualization | Apache Superset | Tableau Looker | N/A | Generally N/A Specifically Google Analytics | Microsoft Power BI |
| Orchestration | Apache Airflow | Talend | Glue workflow Data Pipeline | Cloud Composer (built on the Airflow) | Data Factory |
| Data catalog | Apache Atlas | Alation Ataccama | Glue Data Catalog | Data Catalog | Data Catalog |
| Data lineage | Apache Atlas | Alation Ataccama Manta | N/A | N/A | N/A |
| Data quality | Apache Griffins | Ataccamaa | Deequ | N/A | N/A |
| Application platform | K8s | Openshift | EKS | GKE | AKS |
| AI platform | Kubeflow, MLFlow | Dataiku | Amazon Sagemaker | Google AI Platform | Azure AI platform |
How to get started
Building an analytics platform with all the necessary capabilities may seem like a daunting task. No one wants to spend months building a core platform from scratch, learning, and making mistakes in the process. The “speed to insights” is too important.
At Grid Dynamics we help companies large and small build a robust platform from scratch, upgrade their existing lakes into enterprise-ready analytics platforms, and migrate their data lakes to the cloud while upgrading them. Whether you want to build a platform from scratch, migrate on-premise data to the cloud, or upgrade an existing cloud platform, we can recommend the best technology stack depending on the current state of the business and plan the journey towards the analytics platform together.
To further speed up the implementation of the core platform, we have implemented a number of starter kits for the entire platform and specific capabilities such as data quality, data monitoring, anomaly detection, and machine learning.
Conclusion
The data analytics needs of modern enterprises extend far beyond basic data lakes. To increase accessibility and trustworthiness of data and realize the value of data, companies need to implement capabilities such as data governance, access layers, API, data quality, and AI/ML platforms. Utilizing existing blueprints and starter kits that combine the best products from open source, 3rd party products, and cloud service offerings helps to minimize the time spent on building scaffolding and foundation, achieve high stability, and arrive at implementing value-added AI and ML capabilities faster.
At Grid Dynamics we’ve helped Fortune-1000 companies across industries design, implement, and upgrade their existing cloud analytics platform or migrate an on-premise platform to the cloud. Reach out to us to schedule a briefing or workshop to explore more details of the capabilities of modern analytics platforms, technology options, cloud migration journeys, and optimized paths to upgrade.