
How deep learning improves recommendations for 80% of your catalog


Are only 20% of your product catalog recommendations behavior driven?
Product recommendations have become an essential sales tool for e-commerce sites. These recommendation systems typically use collaborative filtering, a common approach for building behavior-based recommendation engines using customer interactions. Collaborative filtering works well when there are adequate user-item interactions, but falls short when interaction data is sparse (see example figure below). Following the Pareto principle, 20% of a catalog will usually get 80% of the traffic, the rest of the catalog does not have enough interaction data for collaborative filtering to make meaningful behavior-driven recommendations. This is called a “cold-start problem”. When collaborative filtering fails, most e-commerce sites fall back on content-based recommendations. However, using deep learning we can make collaborative filtering approach viable even for products with minimal customer interaction data. In this blog, we discuss how we trained a deep learning model to map product contents to collaborative filtering latent features to provide behavior-driven recommendations even for products with sparse data.
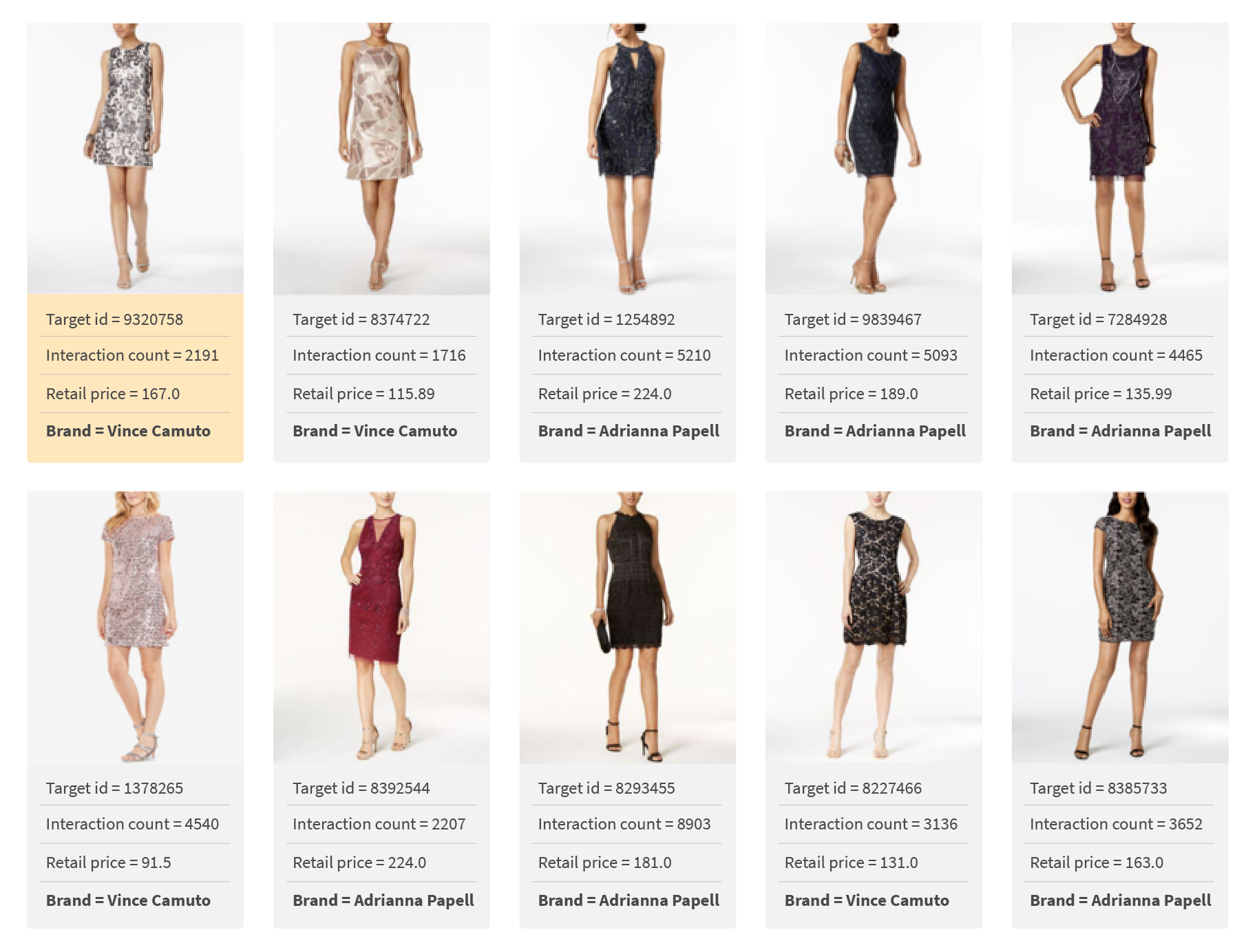
| High popularity dress rich interaction history |
Low popularity dress sparse interaction history |
|---|---|
 |
 |
| The model successfully captured a cohesive set of dresses very well. | The dress style is very inconsistent. It is essentially a random set of dresses. |
User behavior modeled with an interaction matrix
First, let’s revisit the collaborative filtering approach. We model an interaction between users and items as an “interaction matrix,” where cell value represents how likely it is for a given user to select a given product. We have only partial information about the contents of this matrix based on explicit or observed customer behavior. Explicit behavior may be a product rating given by a customer. Observed behavior tries to deduce how much a customer likes the product by implicit signals, for example, when a customer views a product, adds it to their cart, or purchases it. Our goal is to build a model that can predict the values of the empty cells of this interaction matrix.
One of the most popular approaches to fill the interaction matrix is matrix factorization. We try to approximate the interaction matrix as a product of two matrices of lower dimensions, user factors and item factors:
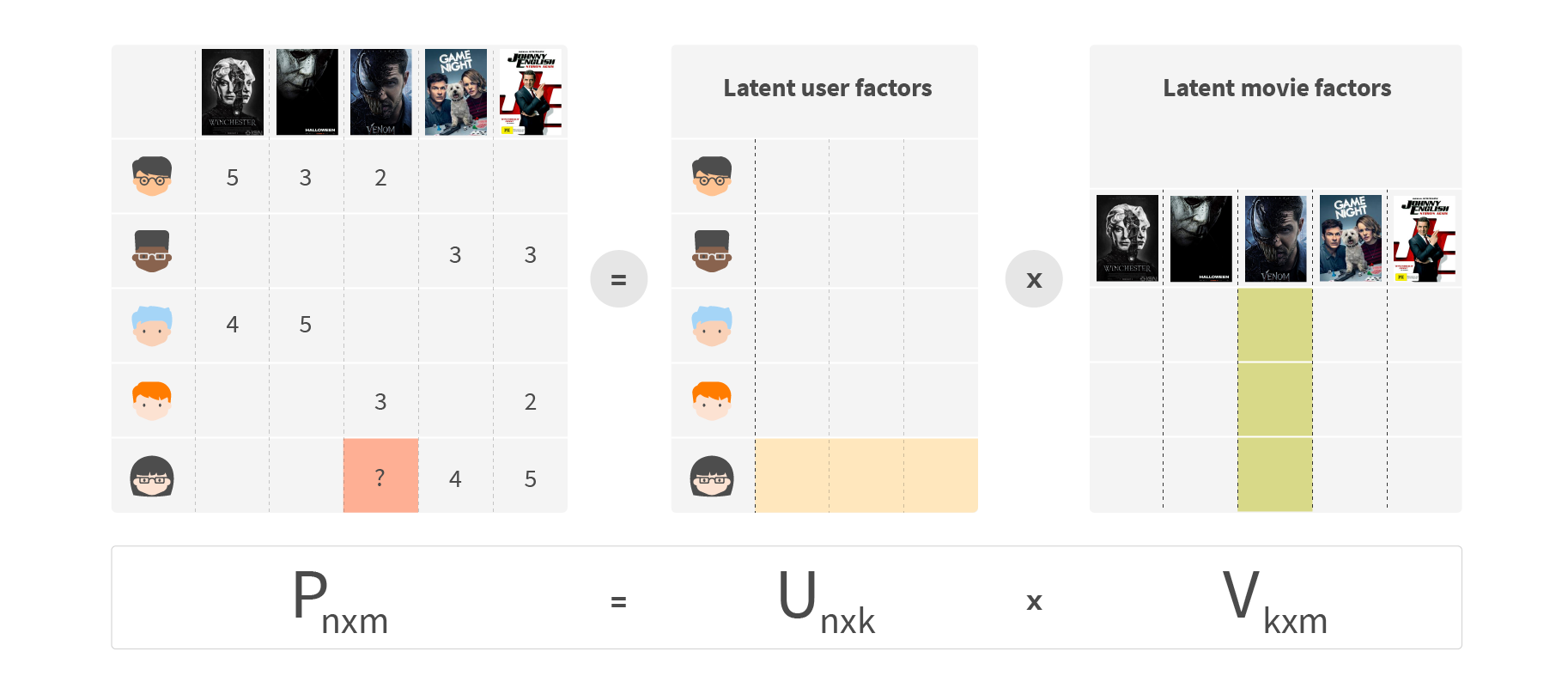
The scalar product of a row of matrix U and a column of matrix V gives a predicted item rating for the missing cells. Predictions for known items should be as close to the ground truth as possible. We fit those two matrices with known data using optimization algorithms.
Once trained, user and item matrices contain latent factors, called embeddings, which represent preferences of a user and features of an item. Each embedding represented some aspect of the user preferences and item feature, which is useful in predicting their behavior. In a well-trained system, similar users and items cluster together in latent vector space, which gives the model its predictive power.
Apply alternating least squares to the problem
One of the classical approaches for matrix factorization is called Alternating Least Squares or ALS.
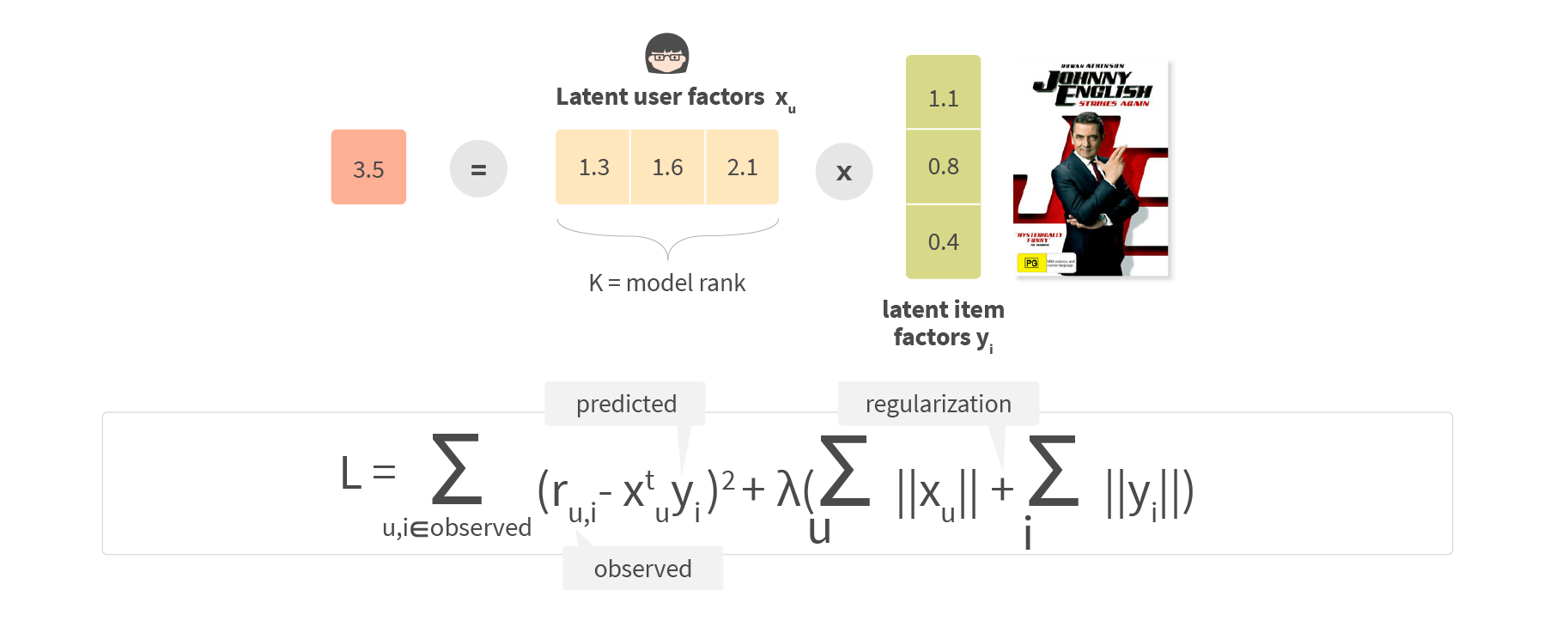
In this approach, we define loss function L and iteratively change user and item embeddings to minimize this loss function. The first part of the loss function is the quadratic deviation of the predicted rating from the ground truth. The second part is the regularization, which helps to prevent overfitting by suppressing embedding vector norms.
The convergence process is iterative. Each step solves a local optimization problem for one matrix considering the values of the second matrix as fixed constants. We solve the optimization problem for another matrix, and the process repeats. Due to this repeating process, the loss function at each step is convex; it has no local minima. This algorithm then converges very quickly.
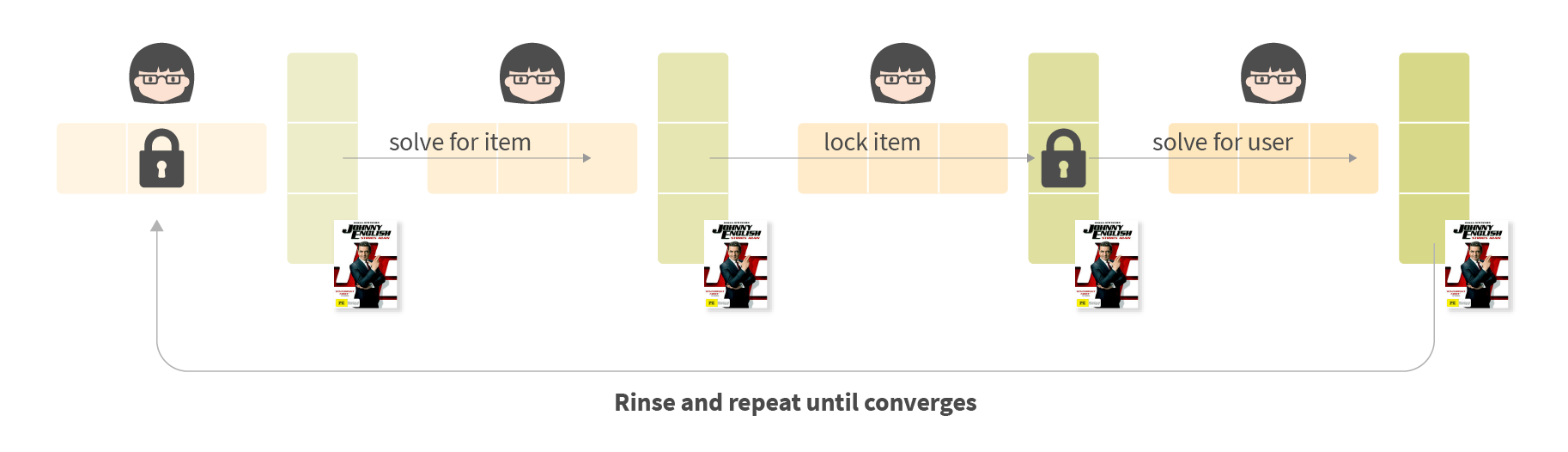
Matrix factorization produces item embeddings when there is a lot of interaction data available. It falls catastrophically short, however, when it comes to long-tail items and new users, as embeddings become mostly random values. Visualizations of clusters begin to appear after training ALS:
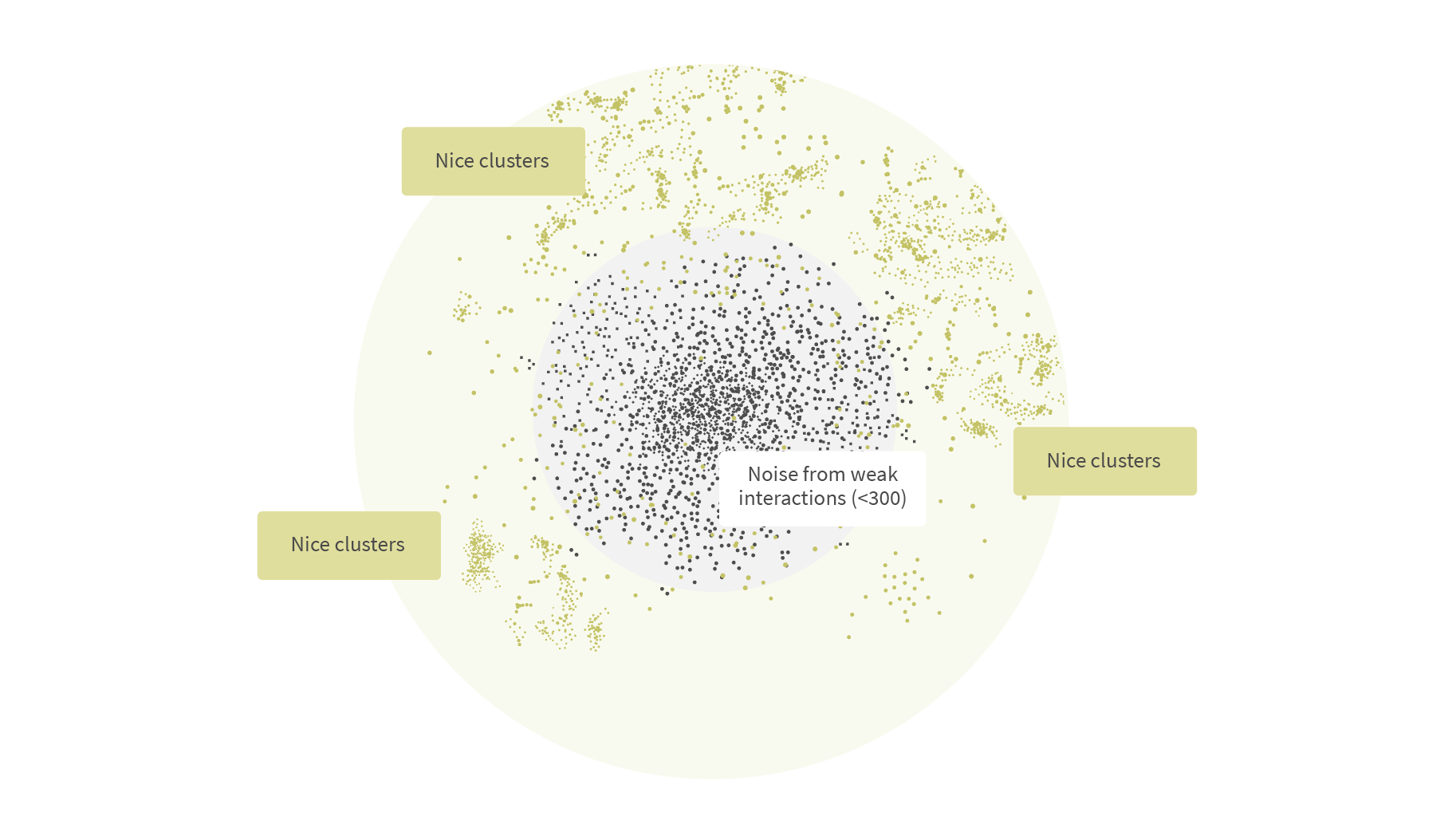
In the center, a noise cluster forms from elements with a small number of user interactions. These are long-tail products where the number of interactions is less than 300. Green dots represent products with a large number of user interactions, where there is a cluster structure of similar products.
Using ALS embedding we get, not only user-item recommendations but also “similar items” or “item-to-item” recommendations using nearest neighbor search in product embedding latent space. The quality of such recommendations, however, quickly deteriorates when interaction data is sparse. In the below chart, we see the percentage of irrelevant products in the recommended output to the number of interactions as assessed by an expert curator.
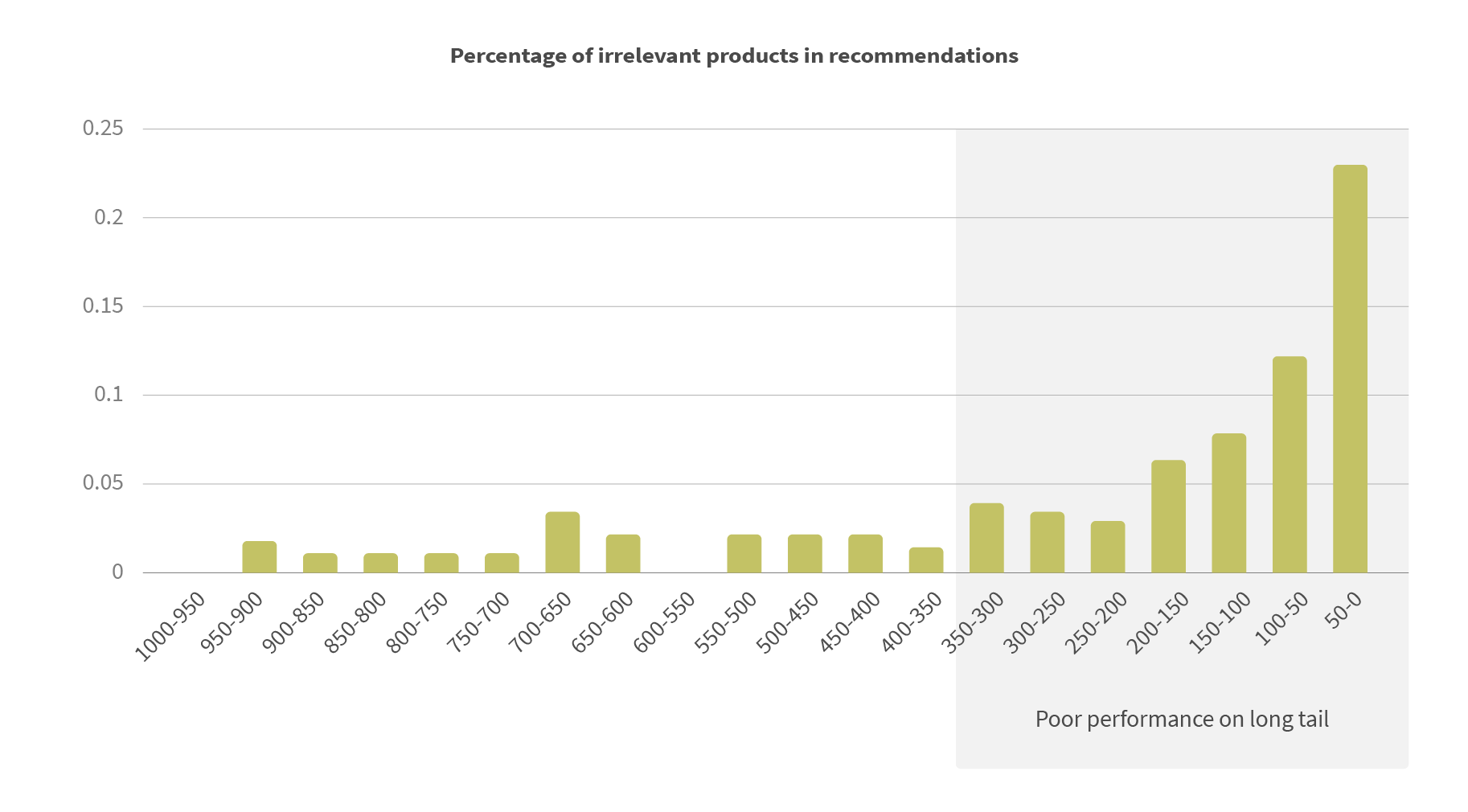
Solve weak interactions with hybrid recommendations
We need to find another approach to provide high-quality recommendations in the last case while maintaining the structure of the ALS vector space. Enter deep learning. As viewed as universal function approximators, deep learning models can use the content of the items to predict ALS embedding for them. We can train a deep neural network which can take item attributes, text, features, and images to predict ALS embedding of this product.
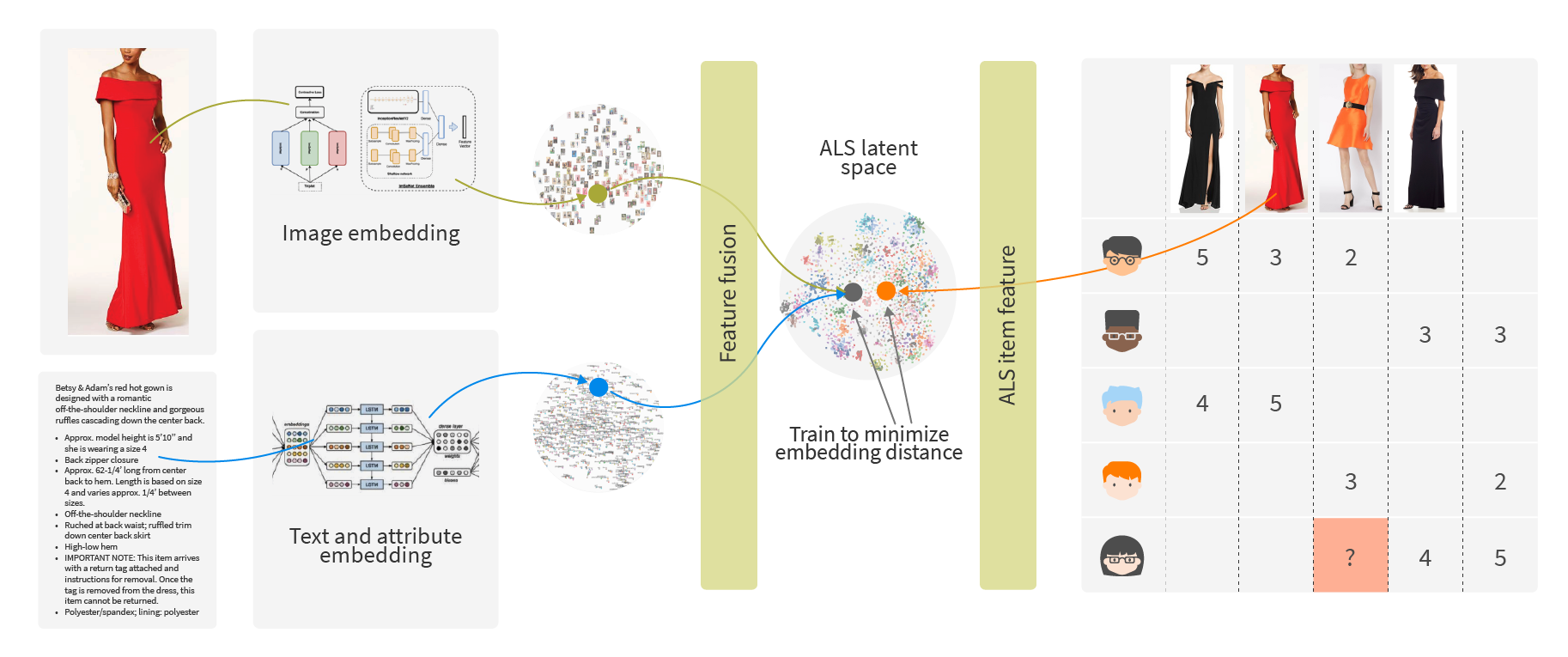
When the neural network is trained to predict ALS embeddings, it takes into consideration user-to-item interactions. We train a neural network to capture the most critical features from the images, text and other available attributes to predict the most valuable information from the clickstream encoded in the ALS embeddings.
Shown below is the architecture of the neural network:
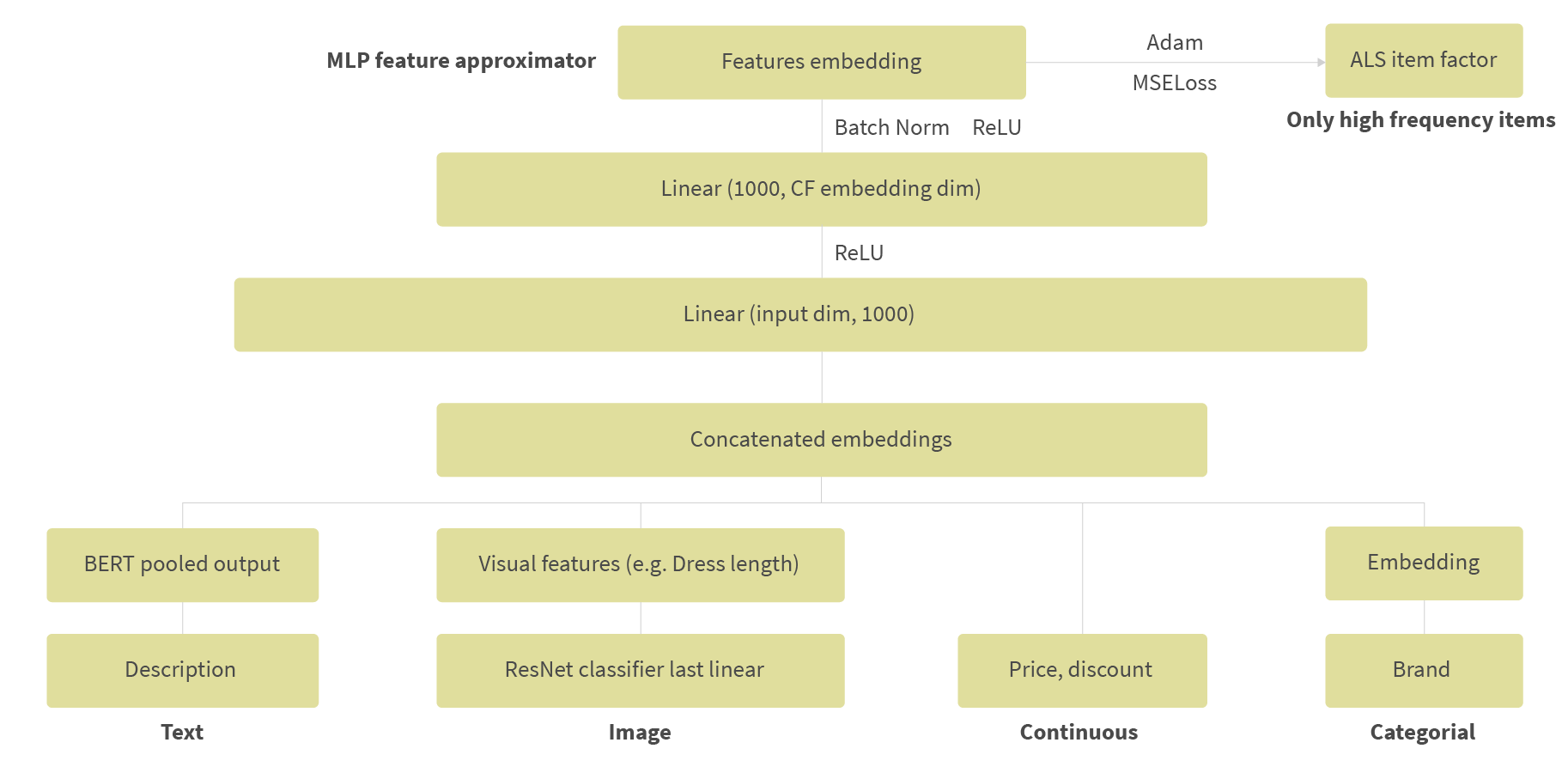
To vectorize text features, we use pre-trained Bidirectional Encoder Representations from Transformers (BERT). BERT obtains state-of-the-art results on a wide array of Natural Language Processing (NLP) tasks. For image feature embeddings, we used several ResNeXt-50 attribute level classifiers with a subsequent concatenation of embeddings. We also include other features, like price, brand and occasion. For minimizing space between predicted embedding and ALS embedding, we use MSE Loss.
After several cycles of training, we visualize the ALS latent space again:

The new space of items contains separate clusters. Now long-tail products with low customer interaction are intermingled with “fat head” products with a lot of customer interaction.
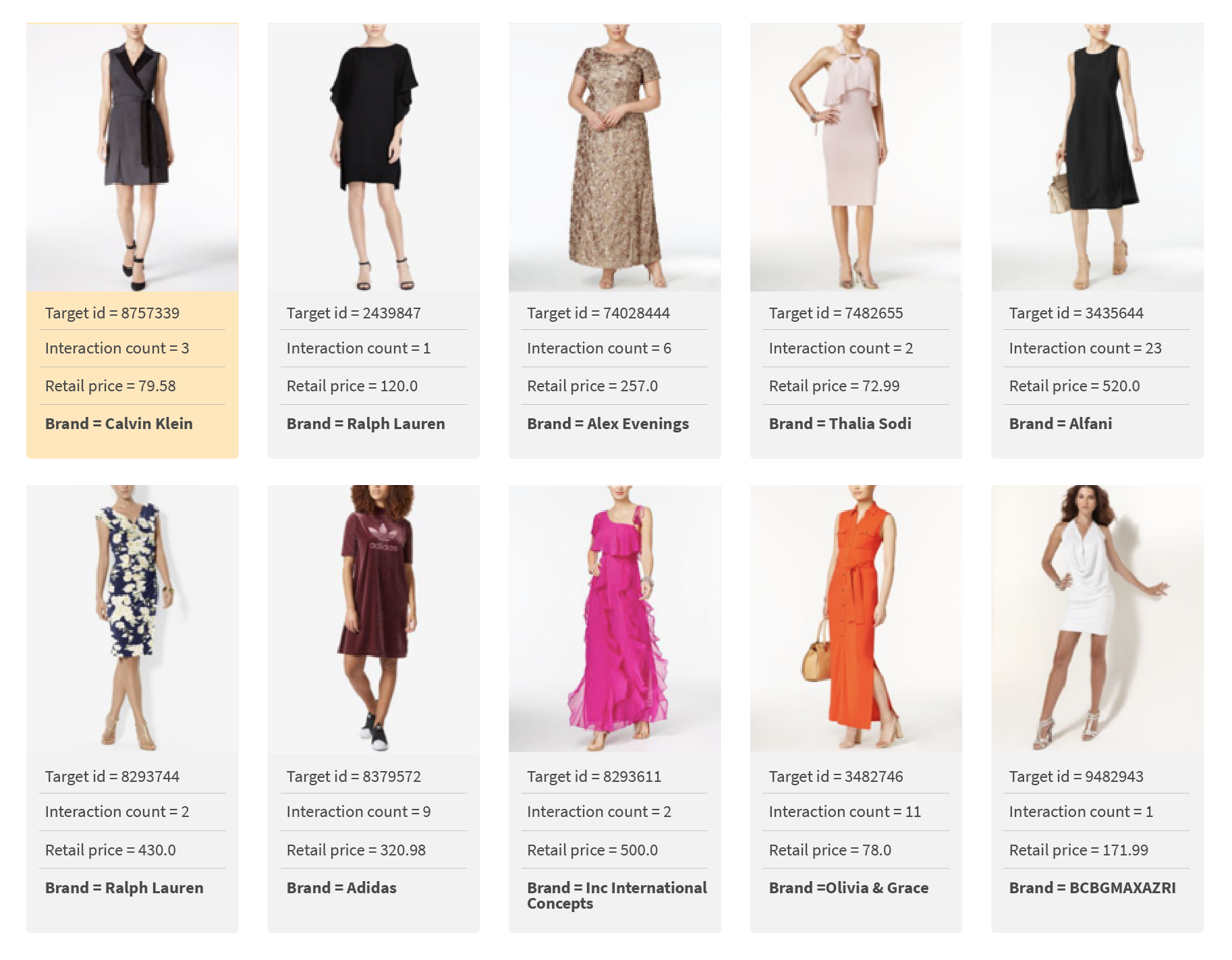
Let’s retry the nearest neighbors of the previous low popularity product with id=8757339 (top left). After users clicked on the target dress just three times, the results are far more relevant:
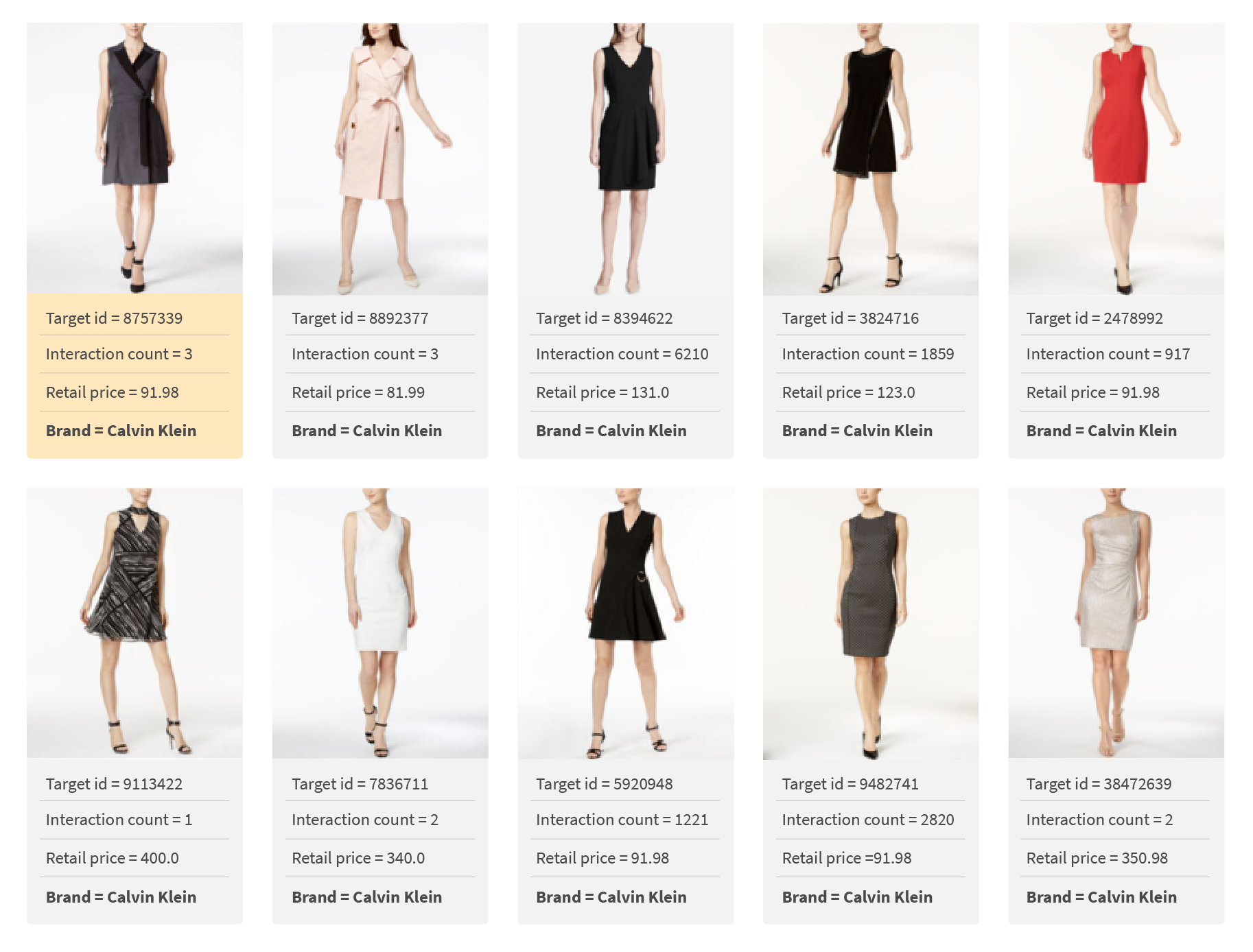
Now similar items for the products from the long tail looks much better.
Formal model evaluation metrics, calculated on low popular products, also show quite an improvement: we achieved an increase in Normalized Discounted Cumulative Gain (NDCG) @10 from 0.021 to 0.127 and average precision from 0.014 to 0.092.
Conclusion
By fixing the low volume product collaborative filtering issue with deep learning, we now have a powerful instrument at our disposal to improve the quality of our recommendation systems. To improve sparse data recommendations, we trained a neural network to approximate ALS embeddings for popular products. Using product features, like image and text, we can predict ALS embeddings for products from the “long tail.”
We can now show high-quality recommendations for the entire product catalog, for both popular and less popular products. We discussed how a retailer’s sales concentrates on only 20% of the product catalog because the remaining products do not contain enough interaction data for the recommendation engine to analyze properly. Using long tail techniques discussed in this blog, we can now engage hard to reach customers with recommendations capable of serving 100% of the catalog! This is not a trivial problem. The Pareto principle is widespread and most catalogs experience this 80/20 phenomenon. Deep learning can overcome data interaction inequality and help solve other similar problems in e-commerce and beyond.