
How to build visual traffic analytics with open source: car tracking and license plates recognition


In today’s data-driven digital economy, businesses collect an abundance of data to inform and optimize their processes and strategies. An emerging trend in data collection is to analyze road traffic data, including vehicle detection and tracking, mobility patterns, traffic volume, road network performance, and even license plate recognition.
But how is the data collected and which technology is best suited for the task? This article is based on our experience with a visual and object detection solution for one of the leading suppliers of convenience store and fuel dispenser technologies. The company was interested in tracking incoming cars to analyze traffic patterns for business optimization. We created a solution for car tracking and license plate recognition, with up to 90% accuracy.
Analyzing the business problem
With video footage of moving vehicles recorded from a gas station camera, we sought to find a fast and efficient way to:
- Detect and count cars passing the gas station;
- Track cars to determine if they stop at the gas station; and
- Detect and recognize license plate text.
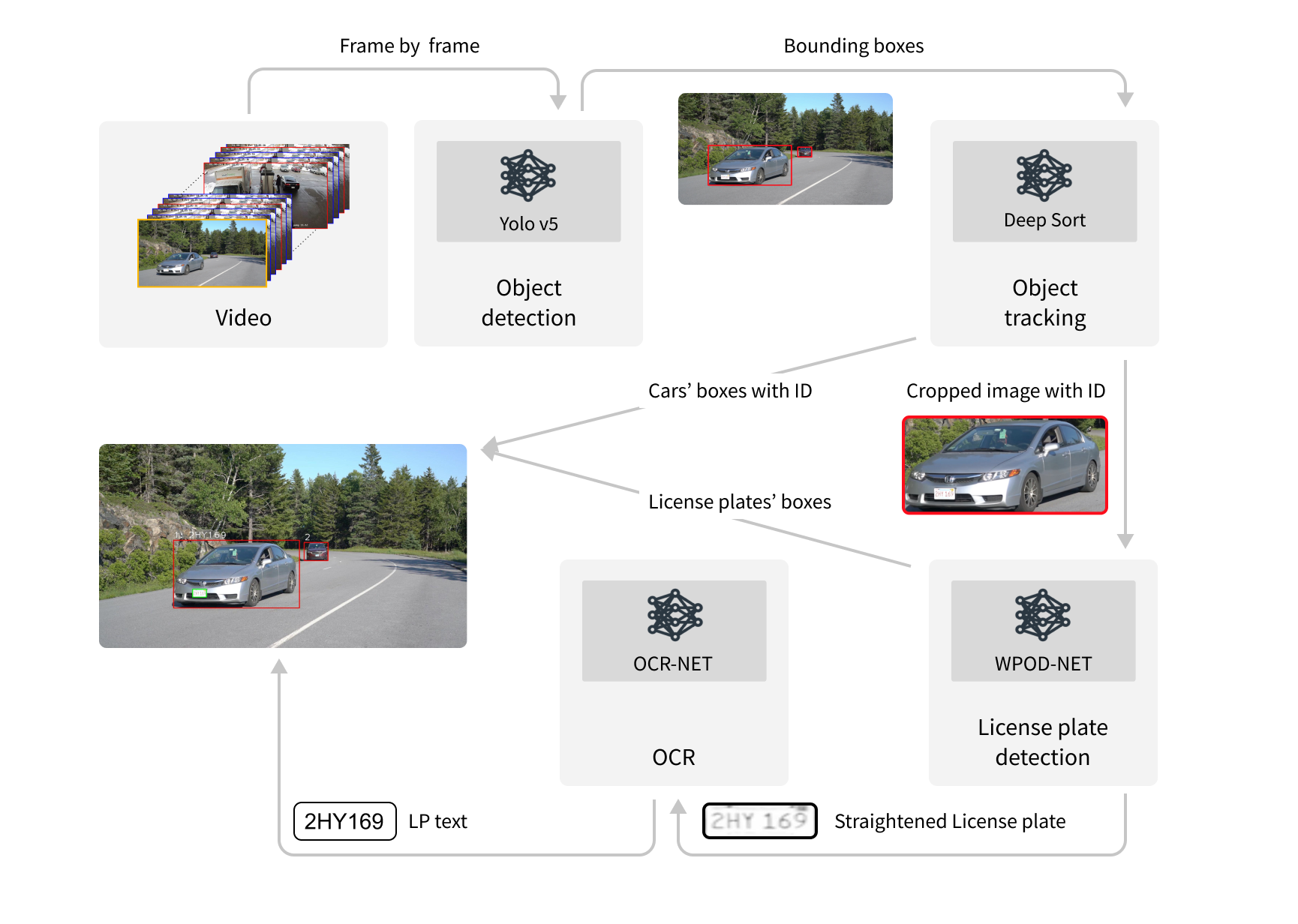
There is no straightforward task to sufficiently address all the challenges we faced, so we created a complex pipeline consisting of a few independent parts:
- Object detection: First, we need to detect cars in the video frames and determine the position of each car by finding the bounding boxes around them.
- Object tracking: We also need to detect cars in each frame independently, and match the same vehicles from different frames to create “tracks” - paths of cars moving in the video.
- License plate detection: For each detected car, we also need to detect the license plate on it, as well as unwarping the license plate if it is distorted (at an angle to the camera).
- License plate recognition: The next step is to recognize the text on each license plate.
- History analysis: And last but not least, we need to analyze the history of outputs from previous steps to summarize information about the car.
The generalized pipeline is depicted as follows:
Why object detection and object tracking?
For object detection, we need to detect an object in a frame, put a bounding box around it and classify it as a car or something else (traffic light, road sign, tree etc). The object detection algorithm needs to be able to process each frame independently and identify numerous objects in each frame.
For object tracking, on the other hand, we need to track particular objects - in this case, cars - across the entire video. For example, if the object detection algorithm detects 3 cars in the frame, the object tracker has to identify the 3 separate detections and needs to track it across the subsequent frames (with the help of a unique ID).
We use both these methods to identify and track the movement of cars so we have a summary of information about traffic behavior to provide detailed analytics to business owners.
Read on to find out how we solved the car detection and tracking, and license plate detection and recognition problems using various technologies.
Step 1: Detecting cars
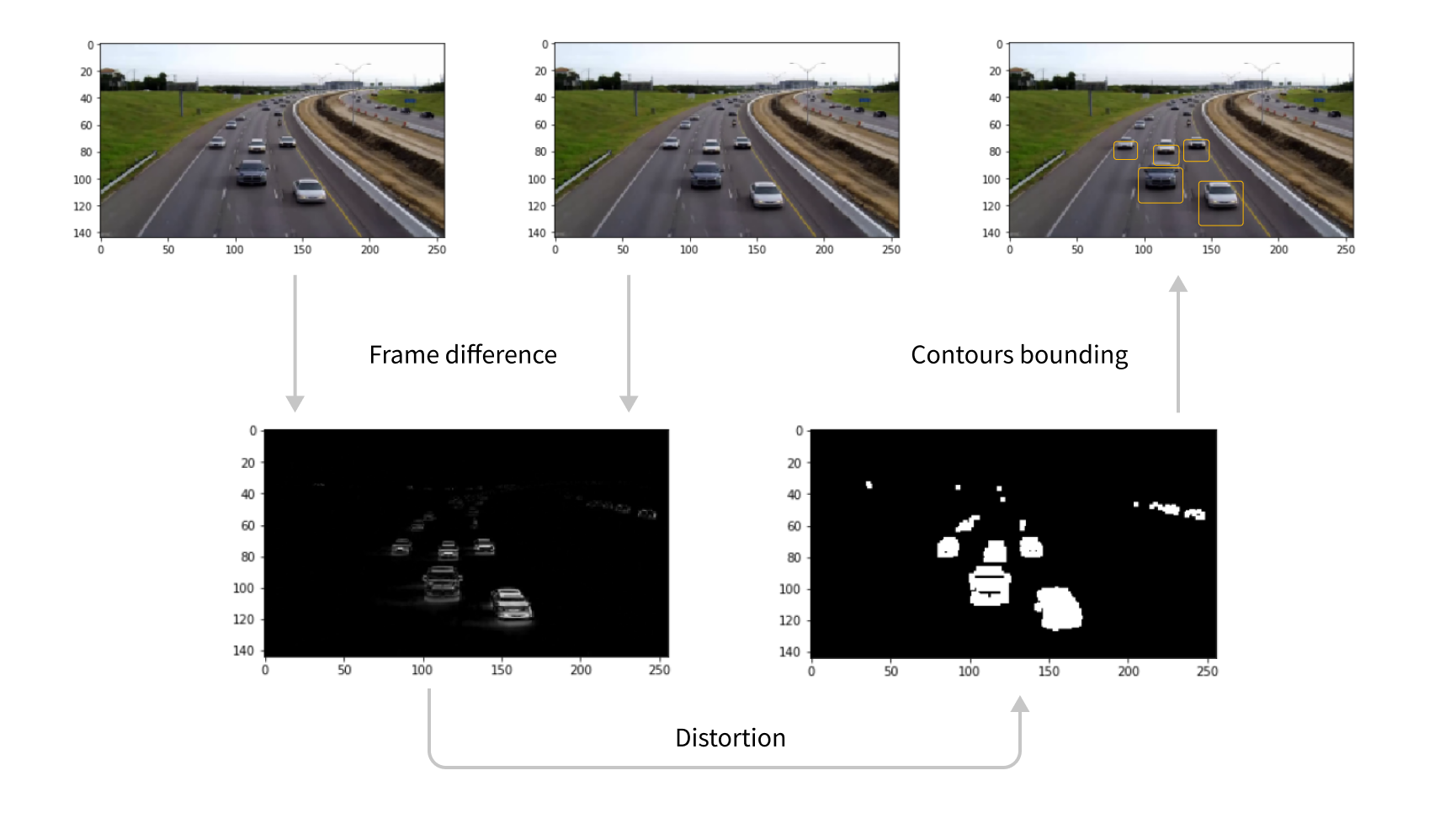
Our initial attempt involved a simple, classic method using frame difference for car detection. At first, it takes the absolute difference of adjacent frames pixel by pixel, then it distorts to increase the contrast. Finally, it calculates a rectangular bounding box of each “white” cluster. While it works quickly, it only detects the movement of cars and is unable to differentiate between cars and other objects.
Classic Frame Difference
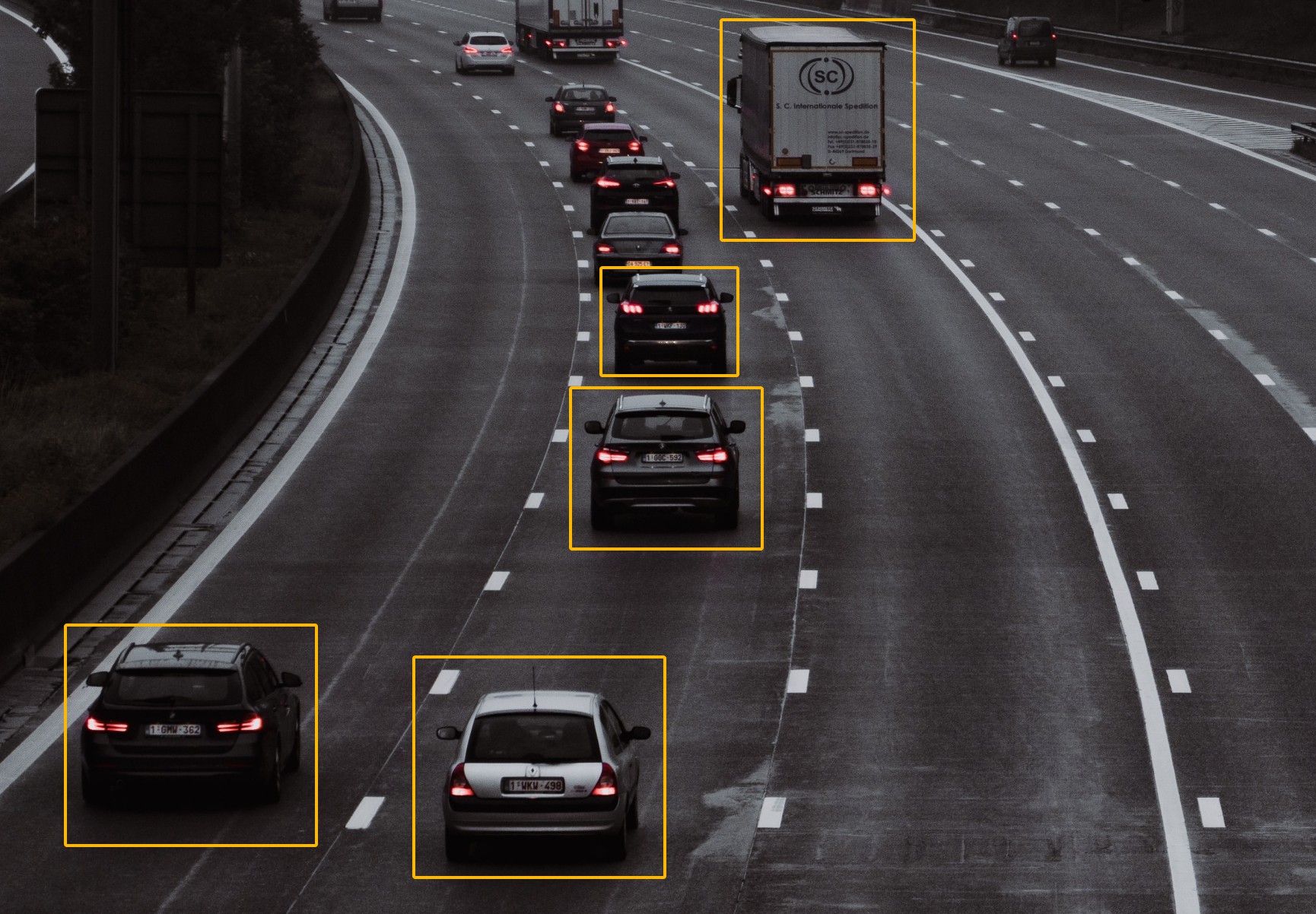
To resolve the object classification issue we tried the YOLOv3 algorithm to detect objects more distinctively[1,2,3]. YOLO (“You Only Look Once”) is a popular algorithm because it achieves high accuracy and is able to run in real time. The algorithm requires only one pass (“only looks once”) through the network to make object detection predictions.
It works by dividing images into grid cells or boxes and uses a deep convolutional neural network (CNN) algorithm to classify all of them. Using non-maximum suppression to filter boxes, the most probable positions of cars are returned. Non-maximum suppression is a class of algorithms to select one entity, such as bounding boxes, out of many overlapping entities. We chose the selection criteria to return the most probable results.
Our observation concluded that YOLO is more robust than classic frame detection because it has higher accuracy and classifies all objects, although it is somewhat slower. As a final step for more accurate predictions in the same amount of time, we updated to YOLOv5 and changed TensorFlow to PyTorch[4].
YOLO

Step 2: Tracking cars
With a workable solution for accurately detecting cars in the video, we needed to solve the challenge of tracking the cars’ movements.
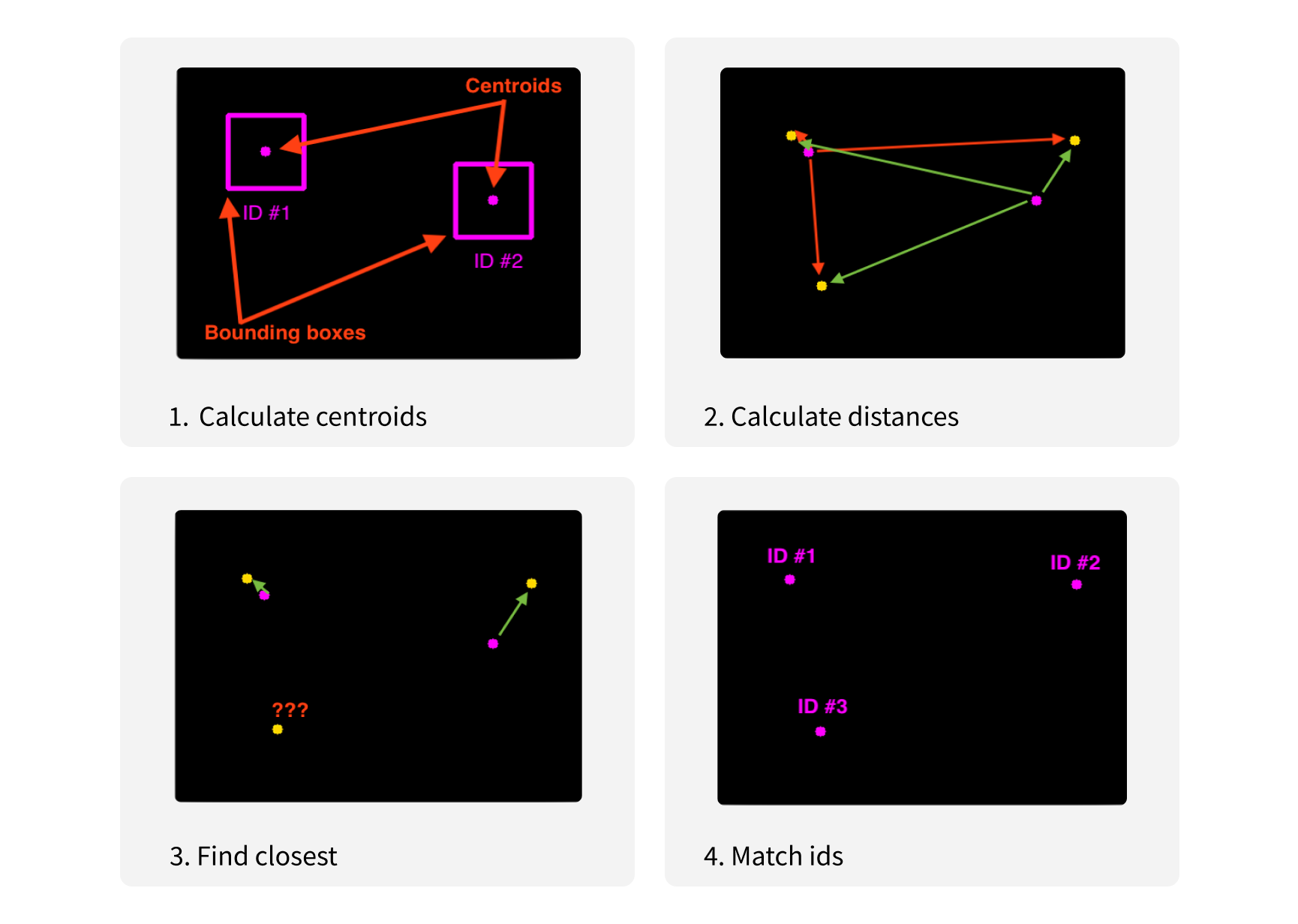
Classic method using Euclidean distance
We first tested a straightforward classic method using Euclidean distance. This method involves finding centroids of each box in the frames, and calculating the distances from all centroids in one frame to each object in the adjacent frame. The next step is matching car IDs by finding the closest centroids for each new box.
This algorithm works very fast, but is very sensitive to camera angles and fails when cars are too close to each other or when they intersect.
Euclidean distance algorithm
Advanced method using DeepSORT
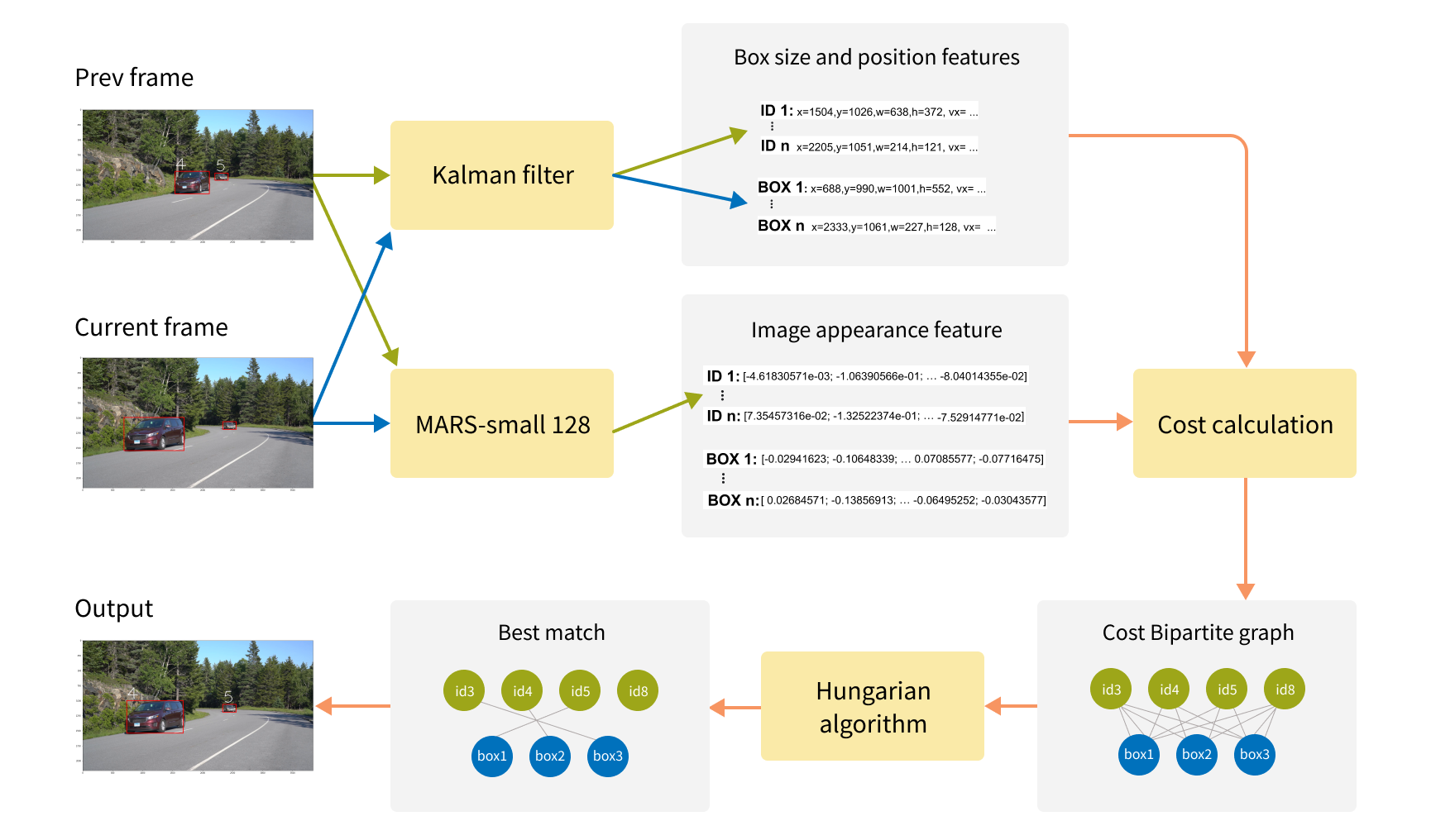
It was clear that a more advanced object tracking algorithm was needed, so we turned to DeepSORT[5,6,7]. DeepSORT creates two lists of features for each car in a frame:
- Box size and position features extracted from box parameters and history by Kalman filter; and
- List of appearance features extracted from a car image by Deep CNN MARS-small128.
By combining the two feature lists, it calculates the cost matrix and determines the best match. Although it is slower than the classic algorithm, it is more robust and returns more accurate results. However, it also fails with occlusions.
After trying different models to express appearance features and changing TensorFlow to PyTorch[8], we achieved better performance, but unfortunately, the occlusion problem remains unsolved.
DeepSORT
Step 3: Detecting license plates
We are now able to detect and track the movement of cars, but we still need to detect and recognize the license plates on those cars.
Classic computer vision method
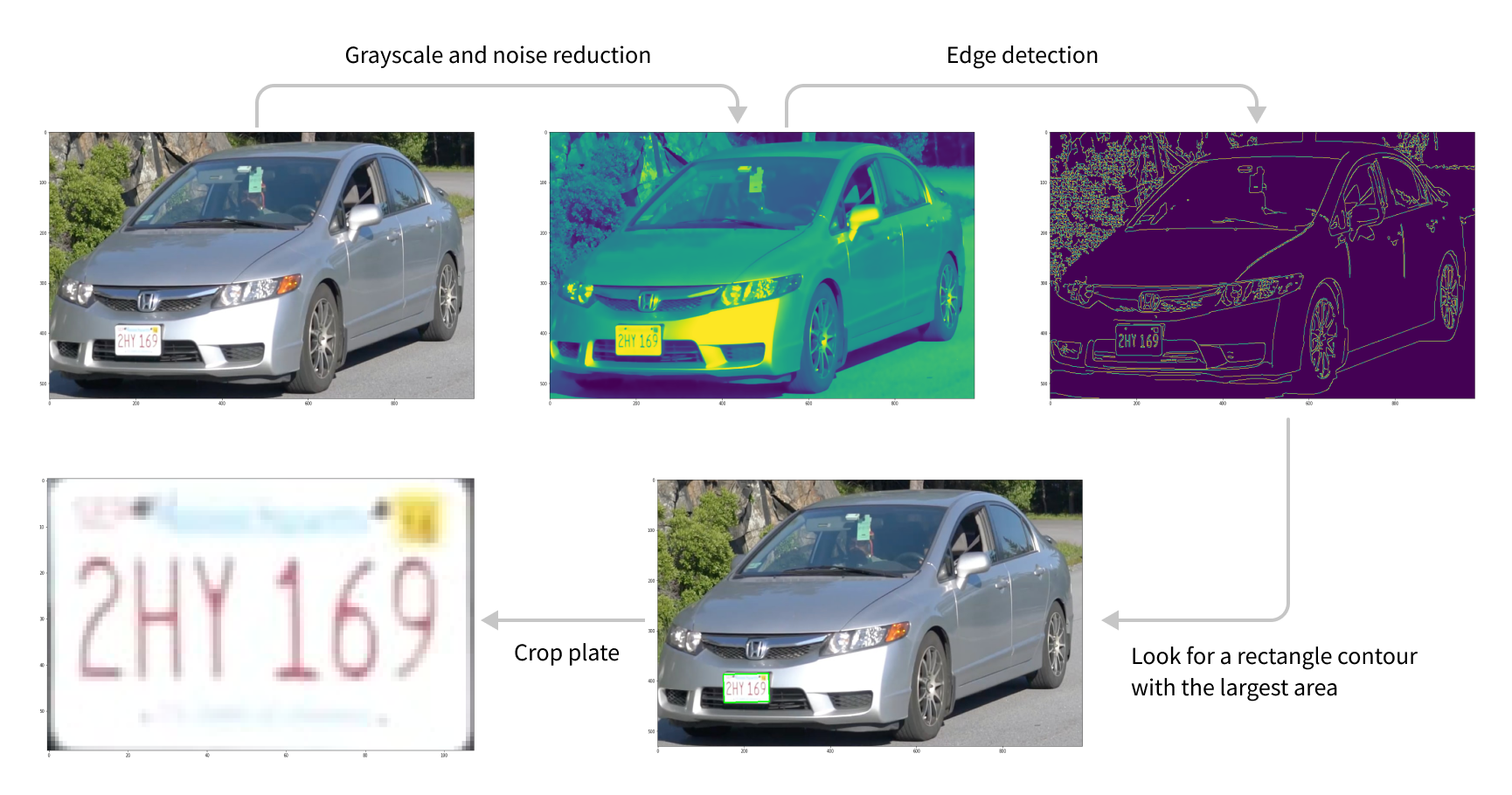
Primarily, we tried the most straightforward solution to the plate detection problem: to use the classic computer vision method (Classic OpenCV) of converting the input image to grayscale, detecting the edges and looking for a simple rectangular contour with the largest area. Although this method is almost instantaneous and easy to implement, the poor performance and the significant number of false positives led us to search for a better solution.
Classic OpenCV algorithm
Advanced WPOD-NET method
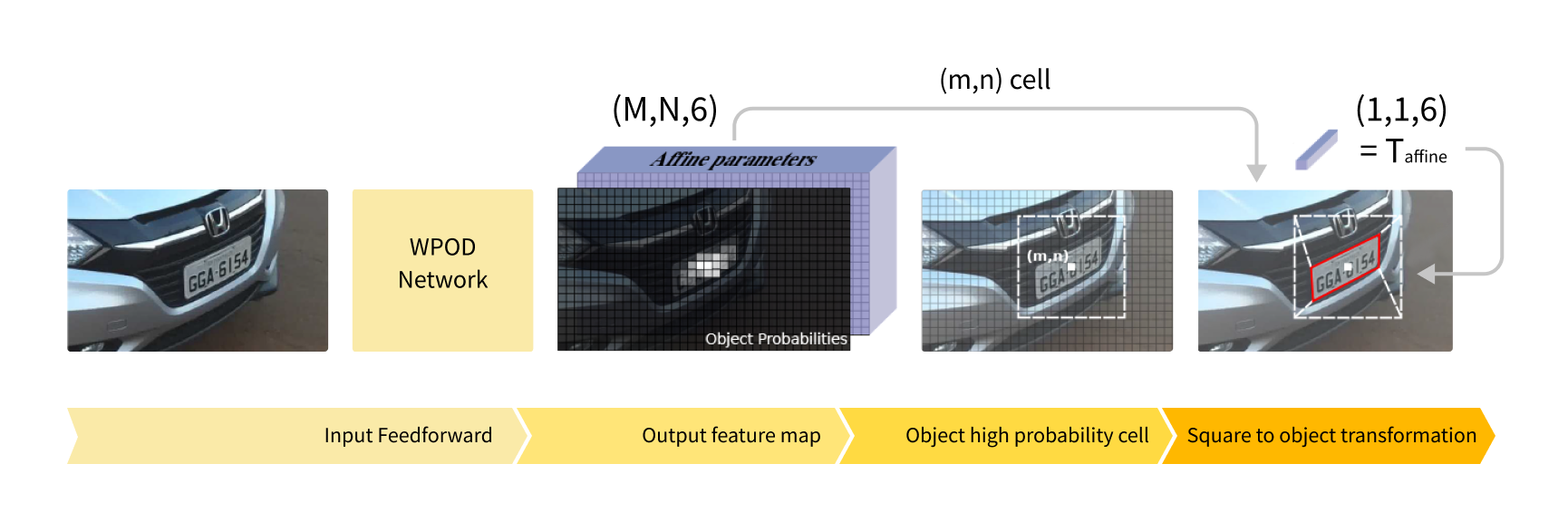
To take advantage of a license plate's intrinsically rectangular shape, we proposed a novel CNN called Warped Planar Object Detection Network[9,10] (WPOD-NET). This network learns to detect license plates in a variety of different distortions, and regresses coefficients of an affine transformation that “unwarps” the distorted license plate into a rectangular shape resembling a frontal view, and returns the results with the highest confidence. WPOD-NET is trained on European, USA, and Brazilian license plates, but can be fine-tuned to detect license plates from other regions if needed. Despite being 20x slower than OpenCV, WPOD-NET still runs in real time, is much more robust and provides state-of-the-art performance.
We do not run detection if the area of the car bounding box is smaller than a threshold. If the car is too far away, it is almost impossible to detect and recognize the license plate correctly. Also, we do not return only one box, but save all images to the history using a confidence threshold for further analysis.
WPOD-NET algorithm

Step 4: Recognizing license plate characters
Detecting a license plate is one thing, but reading the text on the plate is an entirely different kettle of fish!
EasyOCR method
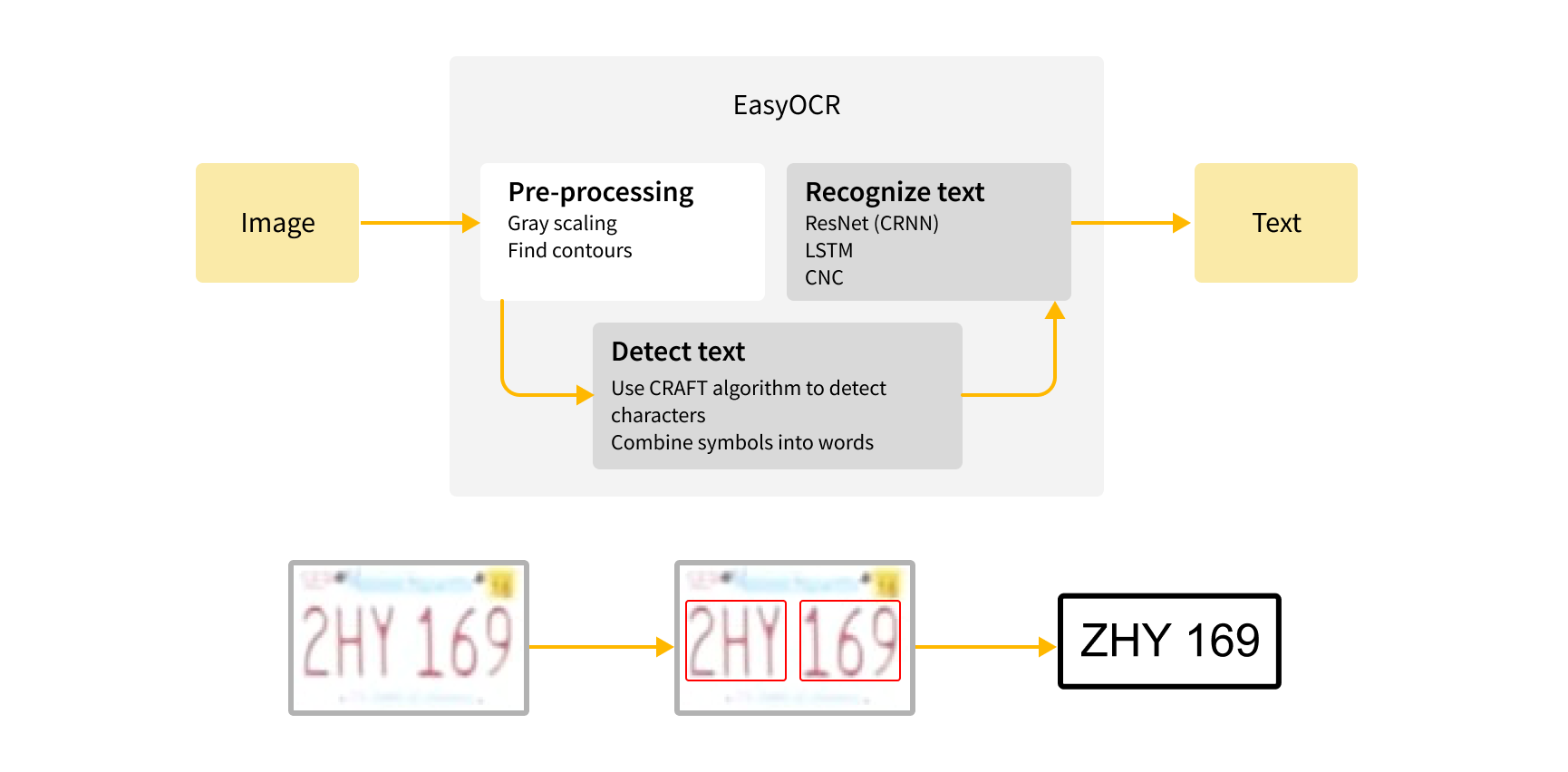
EasyOCR[11] was the first optical character recognition solution we tested to recognize the symbols on detected license plates. By importing the corresponding python library and feeding it an input image, it pre-processes the image (grayscaling and noise reduction), finds the contours and uses the CRAFT algorithm to detect characters and combine symbols into words. The final step is text recognition using CRNN and LSTM.
EasyOCR’s performance, however, was far from acceptable for two reasons:
- The model was trained on textual data, so it detects complete words, not license plate numbers with (almost) random sequences of characters;
- EasyOCR does an excellent job on numbers but has constant misclassification on letters.
EasyOCR algorithm
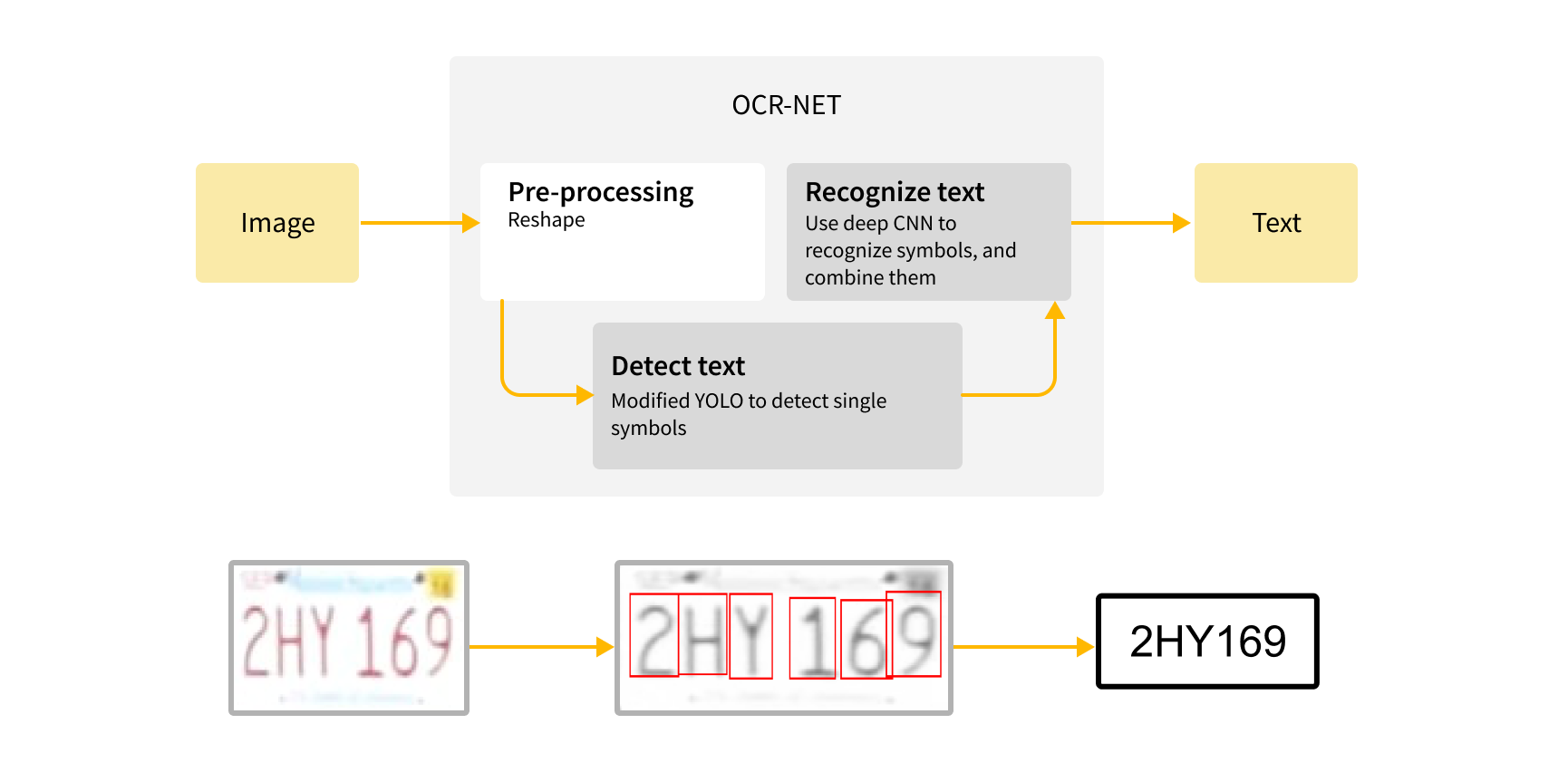
Advanced OCR-NET method
So, after a bit of research, we discovered a far superior solution called OCR-NET[12,13]. The pipeline for OCR-NET is split into two main steps:
- The first is character segmentation. This is performed using a modified YOLO network on the reshaped image. However, the training dataset was synthetic and augmented license plates from different regions (primarily Europe, the USA, and Brazil).
- The second step is character recognition. This involves using deep CNN to recognize the segmented symbols, and combining them using non-maximum suppression to find the most probable, non-overlapping set of characters.
OCR-NET performs much better than EasyOCR because it is trained on license plates and does not try to find words but recognizes each symbol independently.
As with license plate detection, we do not run recognition if the area of the plate box is smaller than a threshold as it is almost impossible to recognize the license plate correctly. For further analysis, we don’t only return the text by combining symbols, but save all the information about each character, such as the detected box and list of probabilities.
OCR-NET algorithm
Step 5: History analysis
The final steps were to analyze the history of outputs from previous steps to summarize all the information we have gathered about the cars.
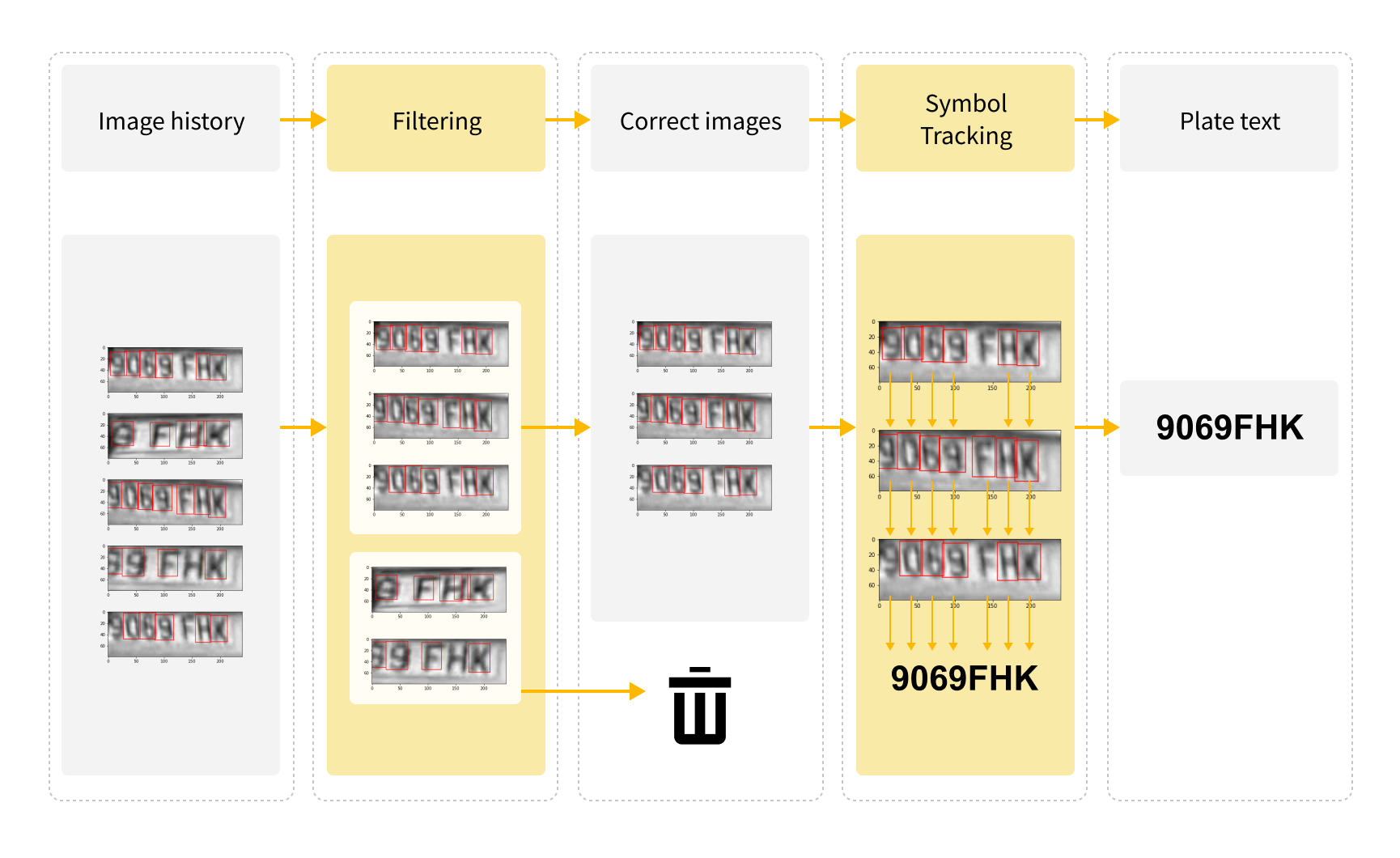
Can we accurately recognize each symbol in a license plate?
In the plate recognition task, we initially just selected text with the highest average confidence. However, we realized that this method often misses symbols because, with fewer characters, the average is a little higher.
This led us to determine a method for tracking the license plate symbols across frames in history. Since the image size for license plate detection is constant, the characters would remain in more or less the same position in each frame. So, using the Euclidean distance tracker, we compared the positions of each symbol to match the same symbols on adjacent frames.
Unfortunately, some license plate images were truncated, which resulted in the wrong text being recognized because symbols were matched to incorrect positions. By adding a simple filtering of images using DBSCAN clustering to delete broken/truncated images, we were able to make the algorithm more robust.
One problem still remained, however: confusion between similar symbols. We could use a more complex, slower model to reduce such cases, but we cannot fully solve this problem.
License plate analysis
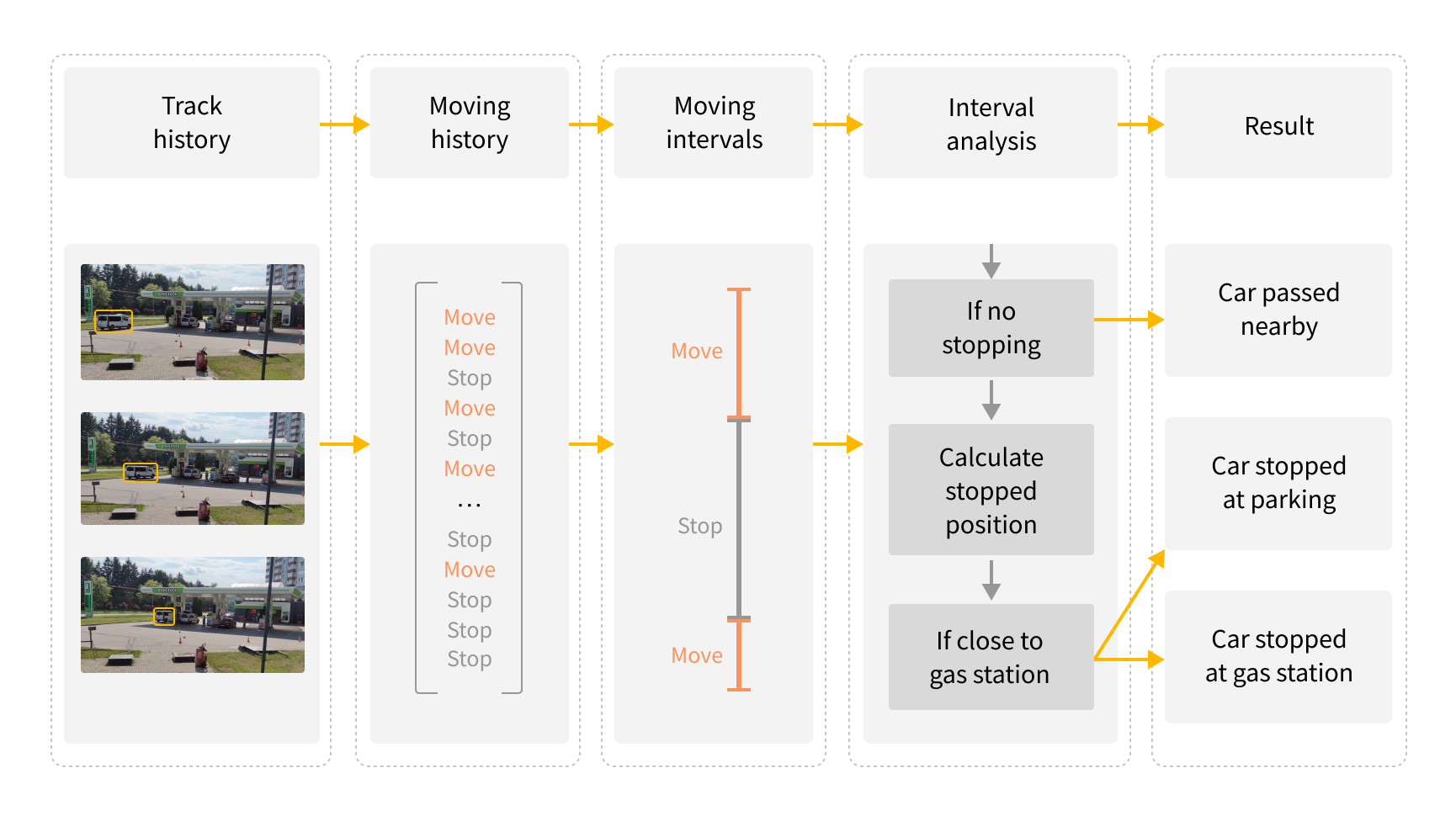
Do cars pass by, fill up or park at the gas station?
To determine the actions that cars take in relation to the gas station, we added track classification. In each frame the algorithm determines whether the car is moving or stopping using the distance threshold of the car between adjacent frames. The track history from the frames is converted into stop/move intervals and is classified according to the following schema:
- if the car moves continuously without stopping, it is classified as having passed by the gas station.
- if the car stops, we calculate the position in which it stopped, which is either:
- close to the pump, and classified as having stopped at the gas station; or
- close to the gas station, and classified as having stopped at the parking area.
The location of the pumps is manually inserted in the function, although this could be included in the object detection algorithm in future.
Track classification
Results and benchmarks
After running the pipeline on a set of test videos with 25 cars with visible license plates, we achieved approximately 90% license plate analysis accuracy (Table 1).
Observations from the results reveal that the main problem of using average confidence was missed symbols on about 40% of license plates. The tracking algorithm completely solved this problem and increased the correctly recognized symbols by 10%. Image filtering did not improve the overall accuracy much, but it did make the algorithm more robust. Remaining issues include symbol confusion and mismatching car IDs.
Accuracy analysis
Table 1. Plate analysis accuracy
Speed analysis
Execution speed is just as essential as accuracy for this use case. Having evaluated runtime on different videos, we got an average of 2-3 frames per second with Full HD videos using CPU, and 1-2 frames per second with 4K. After updating our models to the PyTorch version that can utilize GPU, speed increased significantly. Detection accelerated X7 and tracking X4. Some detailed benchmarks are shown in Table 2.
The resulting rate using the GPU is about 5-8 frames per second with Full HD videos, and 4-5 frames per second with 4K, which is adequate for real-time use.
Table 2. Runtime evaluation
* Results of speed test on the video 11 seconds, 1920*1080p, 24 fps
Conclusion
A trial and error approach is fundamental to ensuring optimum results. After testing many models, we successfully designed and implemented a pipeline for collecting car analytics - from car detection and tracking to license plate detection and recognition. Each model in the pipeline is independent and can be seamlessly replaced with any state-of-the-art model suitable for the task.
Performance
Our pipeline performs well enough: about 90% of symbols are recognized correctly, and apart from symbol confusion, 88% of license plates were recognized correctly in the test videos.
The only remaining issues influencing the solution performance are:
- Confusions in symbol recognition, e.g., O vs. 0, I vs. 1
- Mismatching IDs in car tracking due to object occlusions
Speed
The resulting pipeline version is fast: it runs 5-8 frames per second when car detection and tracking run on GPU, which is adequate for real-time use. This result can be improved even more. To this end, license plate detection and recognition should be configured to use GPU more effectively.
Business value
A wide range of verticals such as Retail, Real Estate, Governments, City Planning, Outdoor Advertising, Transport, Tourism, Oil and Gas, and many more, turn to traffic data to unlock valuable insights for their business.
Businesses can use this data to extract key insights about their business performance and how to optimize it for better customer service. For example, the gas station in this use case is able to:
- Manage staff rosters based on traffic volume trends to ensure adequate and speedy customer service at all times;
- Identify repeat customers to offer personalized services;
- Optimize parking areas based on traffic flow and identified needs;
- Evaluate how well marketing initiatives are performing by counting cars that stop versus cars that pass by;
- Streamline traffic flow layout according to identified patterns to avoid congestion or potential car accidents.
The key takeaway: businesses that use data intelligently are businesses that retain competitive advantage!
We would love to hear your feedback on the methods we used to detect, track and recognize cars and license plates. How would you do it differently? Do you have any suggestions on how to solve the problems of symbol confusion and object occlusion? Shoot us a message below or get in touch with us for a chat!
References
- https://towardsdatascience.com/guide-to-car-detection-using-yolo-48caac8e4ded
- https://github.com/nandinib1999/object-detection-yolo-opencv
- https://pjreddie.com/media/files/papers/YOLOv3.pdf
- https://pytorch.org/hub/ultralytics_yolov5/
- https://nanonets.com/blog/object-tracking-deepsort/
- https://github.com/nwojke/deep_sort
- https://www.programmersought.com/article/78513854105/
- https://github.com/ZQPei/deep_sort_pytorch
- https://openaccess.thecvf.com/content_ECCV_2018/papers/Sergio_Silva_License_Plate_Detection_ECCV_2018_paper.pdf
- https://github.com/data-prestige/train-wpod-net
- https://medium.com/@nandacoumar/optical-character-recognition-ocr-image-opencv-pytesseract-and-easyocr-62603ca4357
- https://github.com/sergiomsilva/alpr-unconstrained
- http://sergiomsilva.com/pubs/alpr-unconstrained/
Image references
- https://towardsdatascience.com/guide-to-car-detection-using-yolo-48caac8e4ded
- https://openaccess.thecvf.com/content_ECCV_2018/papers/Sergio_Silva_License_Plate_Detection_ECCV_2018_paper.pdf
- https://www.analyticsvidhya.com/blog/2020/04/vehicle-detection-opencv-python/
- https://www.pyimagesearch.com/2018/07/23/simple-object-tracking-with-opencv/