
How to create a serverless real-time analytics platform: a case study

We recently built an analytics platform for a startup company whose mobile game acts as a digital advertising platform while providing rewards and instant winning experiences to its users. The app is in the top three in the lifestyle category on Google Play Store and top 10 in the Apple App Store, so it has dozens of millions of daily active users.
To play the game, users have to watch an ad, and every ad converts to revenue for the company. The company’s business analysts were performing offline analysis of user transactions daily and building reports for their marketing colleagues to help them track and tune the efficiency of the ad campaigns.
The company soon realized that it needed to have real-time data to derive insights about user behavior. It would be able to increase conversion rates and improve user engagement if it could personalize promotional offers and game moments for specific audiences of users. To do that, the company needed to build an in-stream processing platform.
To make the content more attractive, this platform needed to build a holistic profile of user activity based on detailed tracking of user interactions within the app. That would increase overall network traffic, so the platform would have to scale to accommodate the additional load – and to meet a hoped-for increase in the number of users as the app became more popular. Temporary unavailability was unacceptable, so the platform needed to be fault-tolerant as well.
In the app, users make decisions about which game card to play in about five seconds. This interval became the target SLA for serving a personalized ad.
All of these factors indicated a cloud-based solution. Our assignment was to create a production-ready platform within a couple of months. We had a small team of three data engineers and a goal of proving to stakeholders the value of a near-real-time analytics platform by bringing it live quickly and economically – and that led us to serverless computing.
What is serverless computing?
Serverless computing has been called the next step in cloud evolution. “Serverless” is really a misnomer; code still runs on cloud-based servers, but users don’t have to dedicate or manage any underlying infrastructure to handle tasks. There’s no provisioning of VMs, network and security configuration, or installation and administration of software. Instead, the serverless platform just handles the events an app calls for.
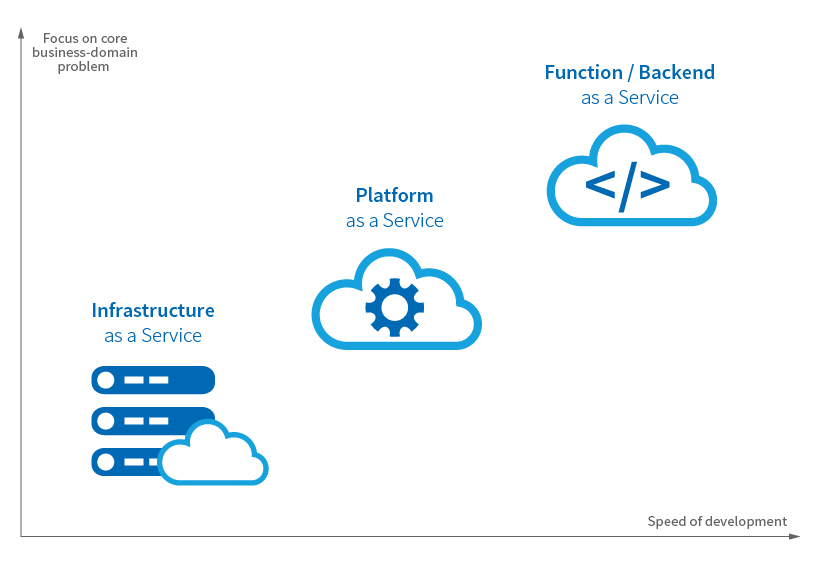
Serverless computing puts the focus on solving business problems (“How do we implement a solution?”) rather than non-core business domain concerns (“How many VMs do we need? How can we make our network setup more reliable and scalable?”).
There are two types of serverless computing: Backend-as-a-Service (BaaS) and Function-as-a-Service (FaaS). BaaS is about integrating third-party services and products to solve technical problems. FaaS is about focusing on writing code.
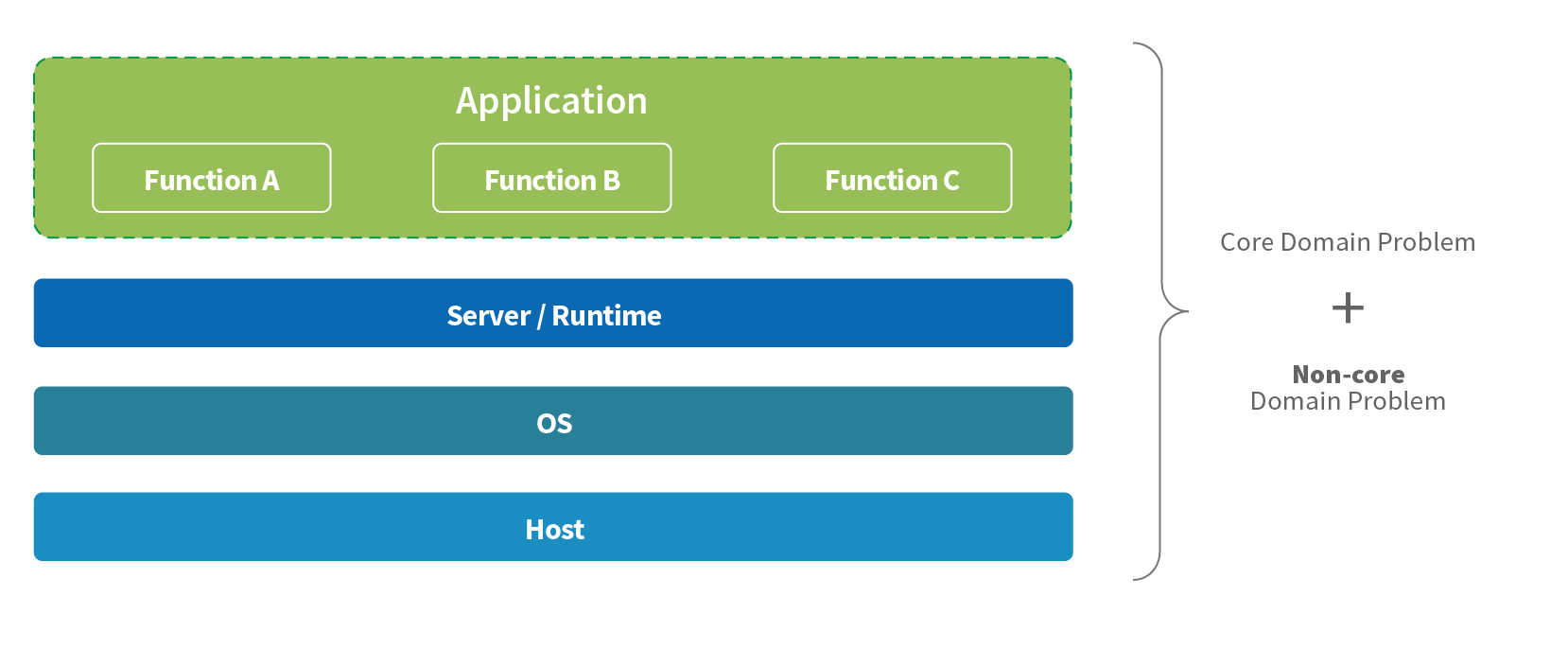
In a “serverful” world application code runs on some kind of server, and developers usually have to be concerned with some of the underlying components.
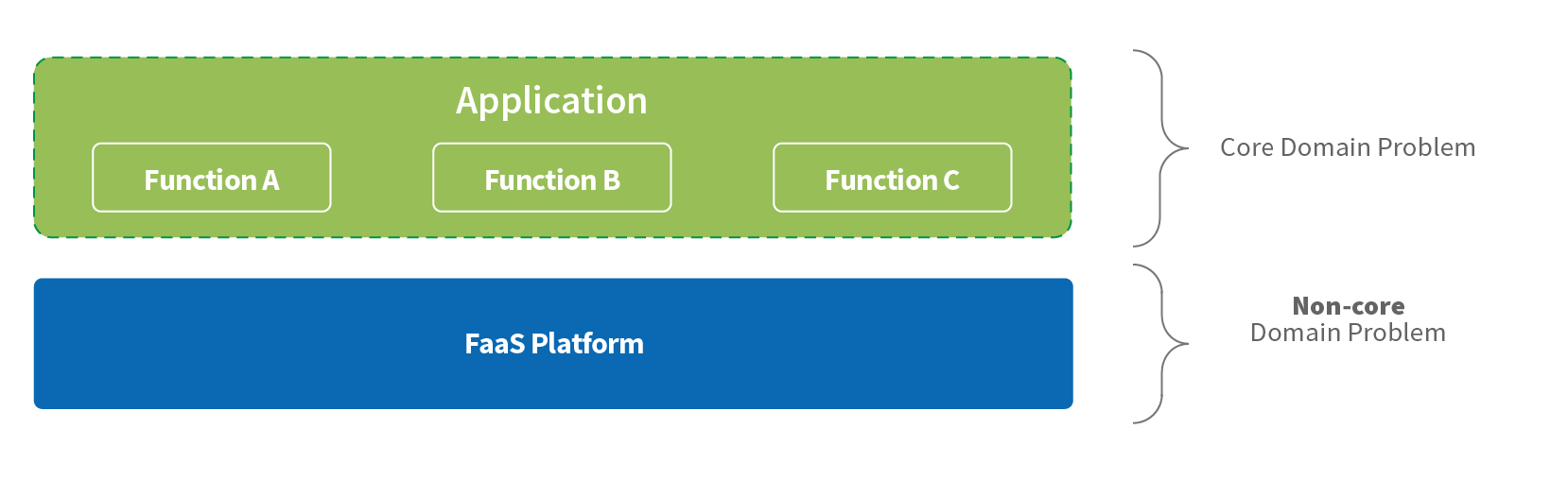
In the serverless world, any non-core business domain concerns are handled by a FaaS platform.
Not every application can take advantage of a serverless architecture. Such high-level abstraction implies that:
- low-level customization must be limited or omitted
- because infrastructure is outsourced, there’s no one to call when a server crashes, and even if you are given support, troubleshooting and recovery will not be a 100% transparent process
- migrating a solution to a different cloud provider or on premises is difficult or impossible
But in our case, the short time-to-market constraint made the flexible scaling provided by the BaaS and FaaS abstractions vital.
Solution architecture
Our client utilized several third-party data management platforms (DMP) and demand-side platforms (DSP), which were responsible for provisioning clients with promotions that targeted specific segments or audiences of users. To implement near-real-time personalization, we needed to:
- Collect mobile clients’ events
- Classify users’ behaviors into segments based on business rules
- Provide the company’s marketing team with a way to define and fine-tune rules on the fly, with no pipeline downtime
- Propagate classification results to the DMP/DSP partner systems
We chose to base the solution entirely on Amazon Web Services (AWS), for three main reasons:
- The client’s existing mobile app back-end infrastructure was already based on AWS.
- AWS has a rich serverless ecosystem that continues to expand and evolve.
- Most of the AWS services we wanted to use are mature enough to be relied on in production.
Our solution architecture comprises three main in-stream pipelines.
Data collection pipeline
Mobile clients are coded using a RESTful event tracking API that lets us ingest user actions and in-app events. The EventTracker API is backed by Java and a SpringBoot-based application deployed to AWS Elastic Beanstalk. The serverless platform takes care of such nonfunctional concerns as:
- provisioning of a web server for the app
- load balancing
- autoscaling per defined strategy (requests count, latency, CPU, I/O, etc.)
- monitoring and alerting
- log rotation
- green/blue deployment, rollbacks, versioning, etc.
Intercepted events get enriched with some server-specific information useful for subsequent troubleshooting and auditing, such as interception timestamp and cluster node IP address. After the enrichment step, to increase downstreaming throughput, the event tracker aggregates the events into small batches of limited size, and the aggregation itself is constrained by duration. We set the size and duration parameters to low numbers to mitigate the risk of losing data in the event a failure occurs before the data has been moved to persistent storage.
Any events that serve as master data for the entire solution could be of interest of many different services, so it was important to introduce decoupling between the producer and consumers to support pipeline extensibility and scalability. The high-throughput, low-latency buffering and decoupling is handled by serverless AWS Kinesis Data Streams.
If we experience any communication issues with the queue, including service unavailability due to network issues or throttling, the batch gets failed over to highly available Amazon S3 storage, which prevents mission-critical data from being lost due to occasional downstreaming issues that have to be taken care of in distributed systems to fulfill at-least-once delivery guarantees.
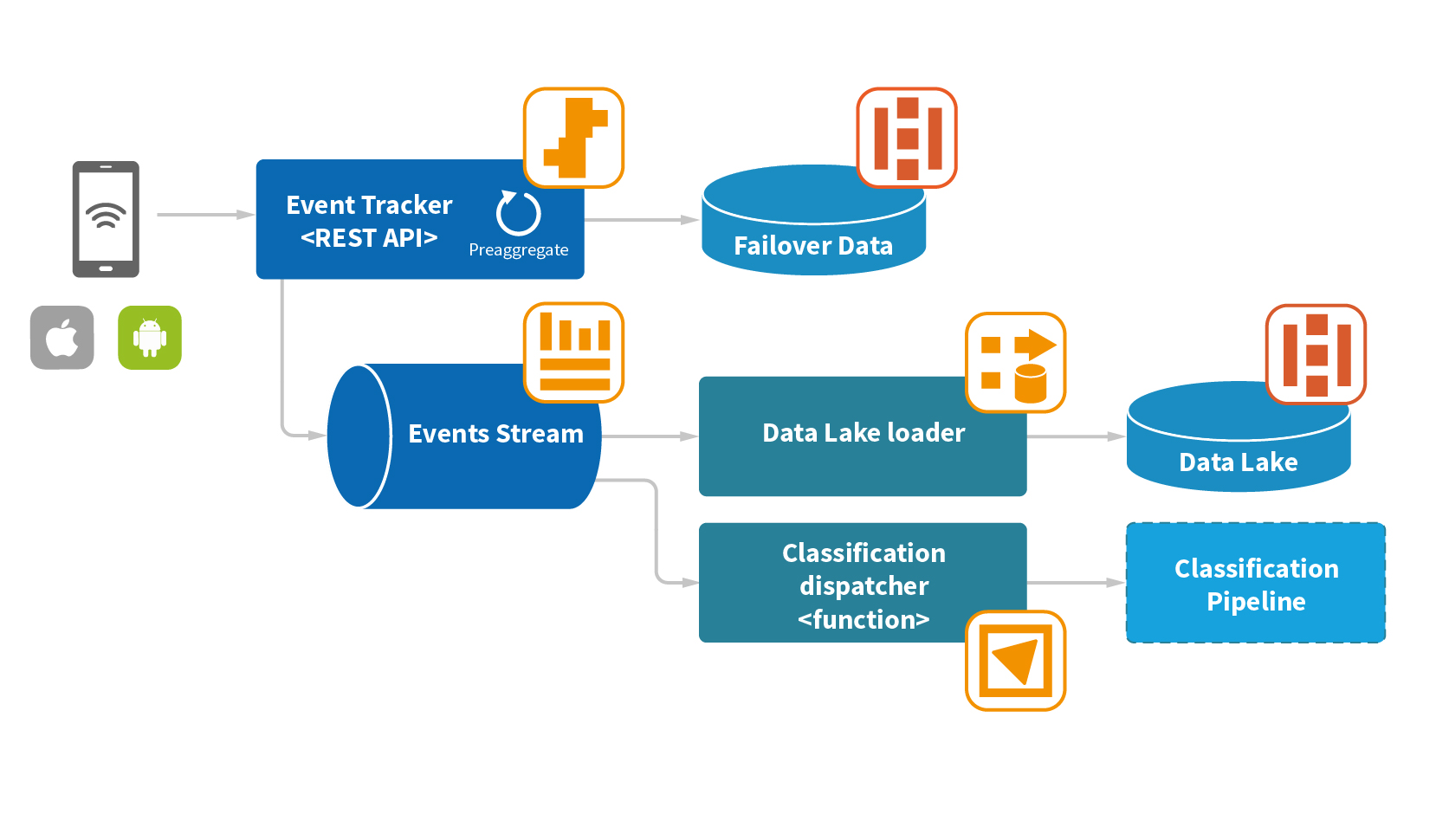
One of the main consumers of the events is a component that ingests data for an S3-based data lake. The data lake, which provides petabyte scalability and durability features, serves as a base for building a historical context of users’ activities, which is a key contributor to a 360-degree view of users’ behavior.
The actual ingestion is performed by AWS Kinesis Firehose, which every 10 minutes applies gzip-compression to data batches of a maximum size of 128M and writes them into S3, thus minimizing the amount of I/O and storage space needed at the destination. The master dataset’s index structure is based on a processing time prefix in UTC (YYYY/MM/DD/HH), which is added by the BaaS service. “Processing time” refers to the time when an event is processed on consumer side. The index structure enables the data lake to provide optimized hourly, daily, monthly, and yearly partition processing.
The nature of mobile applications is such that a client can use an app while being offline for a long period of time – for example, on a long airplane flight without internet access. During that time all of the events the app generates are accumulated locally on the device, then delivered later when the client comes online. Processing time can be significantly different from event time – the time when an event was created on the client/producer side – which is the most important for the target use cases. Consumers of the data cannot rely on the processing time to get correct analytics results.
In our solution we created a dedicated process that aims to simplify things for data consumers by performing event-time repartitioning and reconciliation of the master dataset.
Besides the data lake ingestion, the event stream gets consumed by an AWS Lambda FaaS function that filters and dispatches certain types of events (i.e. “user-opened-app”, “user-clicked-on-ad”, etc.) down a classification pipeline. The FaaS platform had to meet certain nonfunctional requirements:
- Fit for near-real-time scenarios – The event stream gets pulled by the platform about every 250ms. Function instance initialization can add additional subsecond latency, but that’s still acceptable in terms of the target SLAs.
- Scaling-out capabilities – Each stream shard (a unit of scaling in Kinesis Data Streams) gets assigned a dedicated Lambda function instance, which has its own lifecycle and dedicated resources (disk, CPU, memory).
- Scaling-up capabilities – You can tune only memory capacity, but all other resources get implicitly and proportionally increased together with it (i.e. 2x memory results in 2x CPU).
- Reliable error handling – If a function invokes an exception, the platform will retry with the same input until it succeeds or until the data expires in the upstream pipeline (in 24 hours by Kinesis Data Stream default retention).
- Straightforward monitoring and alerting – The platform provides monitoring and alerting out of the box via integration with AWS CloudWatch and X-Ray.
- High availability – Function instances get dynamically allocated across different Availability Zones in a Region.
Integration between Kinesis Data Streams and Lambda is also out of the box, and doesn’t require much administrative effort.
Per AWS specification, a Lambda function retrieves records from a Kinesis Data Stream shard in order of processing time (not event time). The serverless platforms don’t provide an exactly-once delivery guarantee, so reordering and deduplication is left on the shoulders of consumers.
In our case, we didn’t apply the cleansing steps in near real time in the lambda architecture speed layer; we were willing to trade correctness of results for low latency. The correctness should get reconciled in the lambda architecture’s batch layer.
The dispatcher function connects to the classification pipeline via a REST API.
Classification pipeline
Classifier acts as the entry point to the pipeline. This RESTful service is based on the same technology stack as EventTracker. As soon as an event reaches the API, the service determines what user originated the event and looks up its data from the user data cache. The caching component is backed by AWS ElastiCache, a fully managed in-memory data store that provides submillisecond latency for IOPS.
Finally, the event data that represents the real-time context gets joined with the user’s state data (historical context). The product of this operation forms a 360-degree view of the user’s behavior.
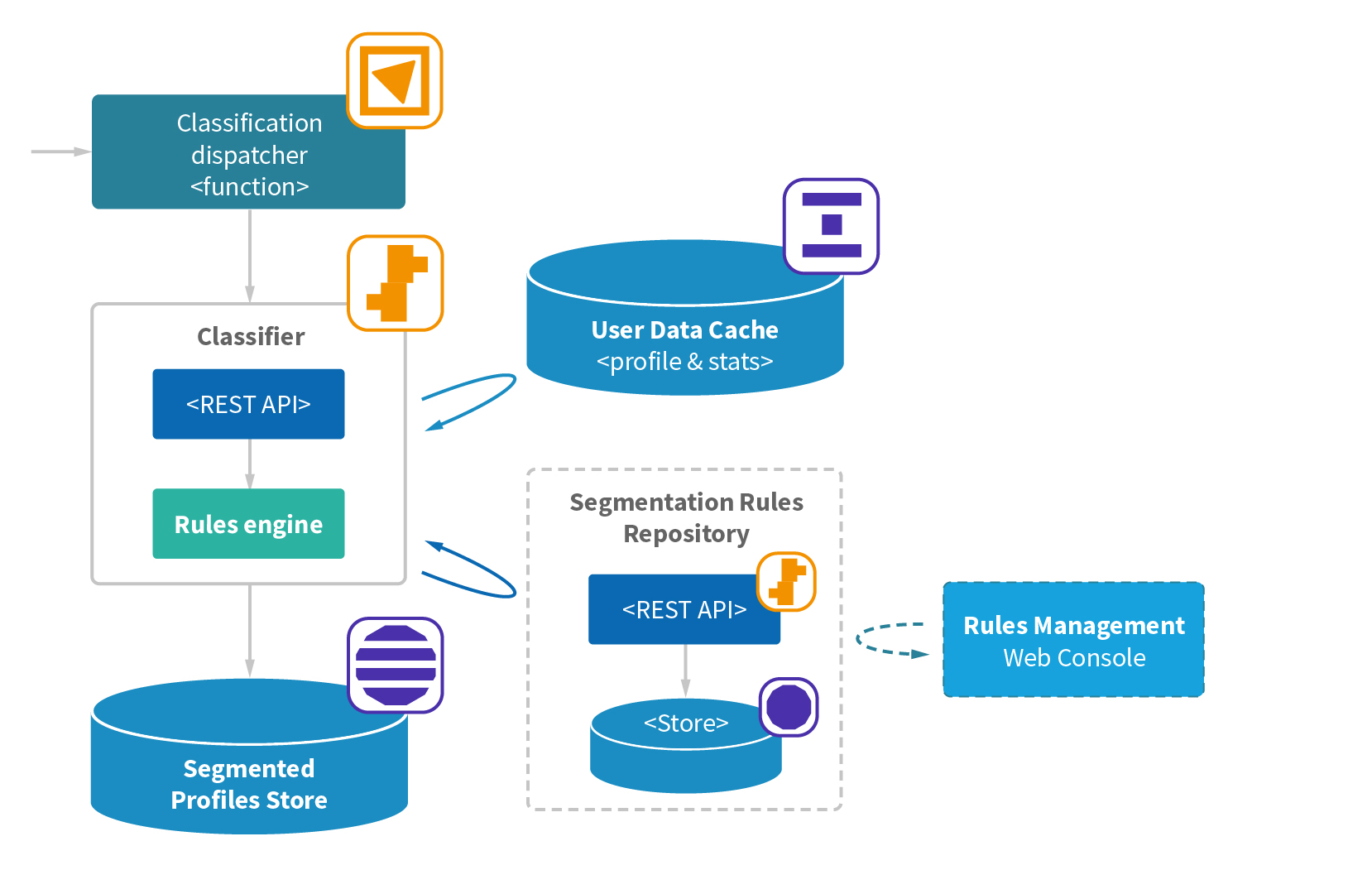
As soon as the view is formed, it gets passed for segmentation to an Drools-based rules engine, which is responsible for the actual classification procedure. The framework provides:
- The ability to define a human-friendly DSL for rule creation in a business domain language
- Support for logical, comparison, extraction, and pattern-matching functions, based on enhanced implementation of the Rete algorithm
- The ability to introduce user-defined functions
- Scalability via embeddable deployment (rules metadata used in read-only mode, no shared computation state between concurrent engines)
Business and marketing team members can define and manage rules via a dedicated web console that integrates with a RESTful segmentation rules repository.
As a result of the classification every new user gets associated with a profile that contains segments they’ve been identified with. The segmented profile gets written to dedicated storage. For users the system already knows about, the existing profile gets merged with new segments that were matched in a new round of classification.
The profile segment merging procedure is fairly complex. It has to take into account hierarchy and different types of segments. Some segments must be overwritten, and some can only be appended to.
We use DynamoDB, a highly scalable, low-latency serverless NoSQL database, as the underlying technology for the the segmented profile store.
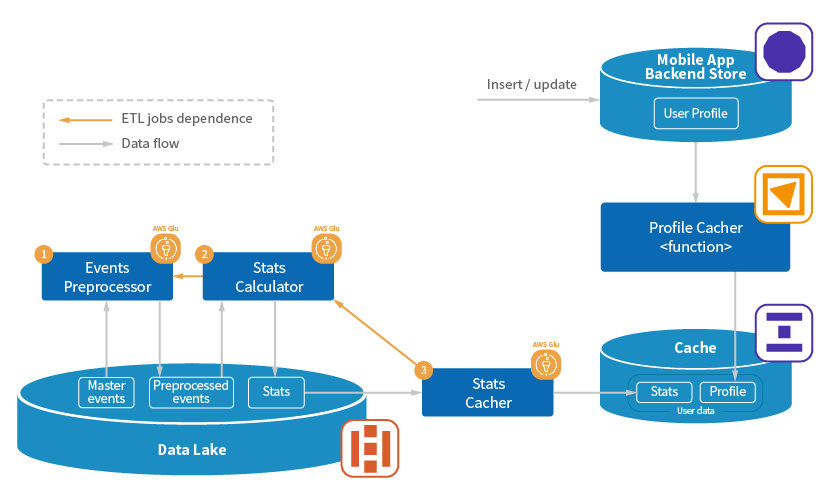
User data cache population
The data hash value has the following schema representation:
| Key | Value Type | Value example |
| profile | JSON String | { "deviceId": "d1", "deviceOS": "iOS", "birthDate": "1990-01-01", "gender": "male", ... } |
| stats | JSON String | { "isRegularPlayer": true, "lastEngagement": "2018-01-01 10:00:55:+00:00", "watchedAds": [ "A", "B", "C"], "skippedAds": [ "X", "Y", "Z"], ... } |
Profile data is based on user information (birth date, gender, etc.) originated from the transactional backed store of the mobile app (AWS RDS Aurora). Every insert/update on the UserProfile table triggers a Lambda function propagating the action to the corresponding entry in the user data cache. Such write-through updates in combination with an entries eviction strategy (controlled by a time-to-live variable) ensure that profiles are always up to date and deprecated users don't waste cache capacity.
We get statistical data from master data lake events, which are reordered and repartitioned by event time, deduplicated, compacted, and converted to columnar Parquet format. The calculation logic on top of the preprocessed events creates hourly, daily, monthly, and yearly statistics about user activity and engagement. The ETL is performed by PySpark code running on the serverless AWS Glue framework. The jobs pipeline that contributes to the statistics gets triggered hourly.
Activation pipeline
Everything we’ve done so far leads up to the final activation stage, in which we personalize the actual user experience. The mobile application should receive a relevant ad when we serve each user’s requests.
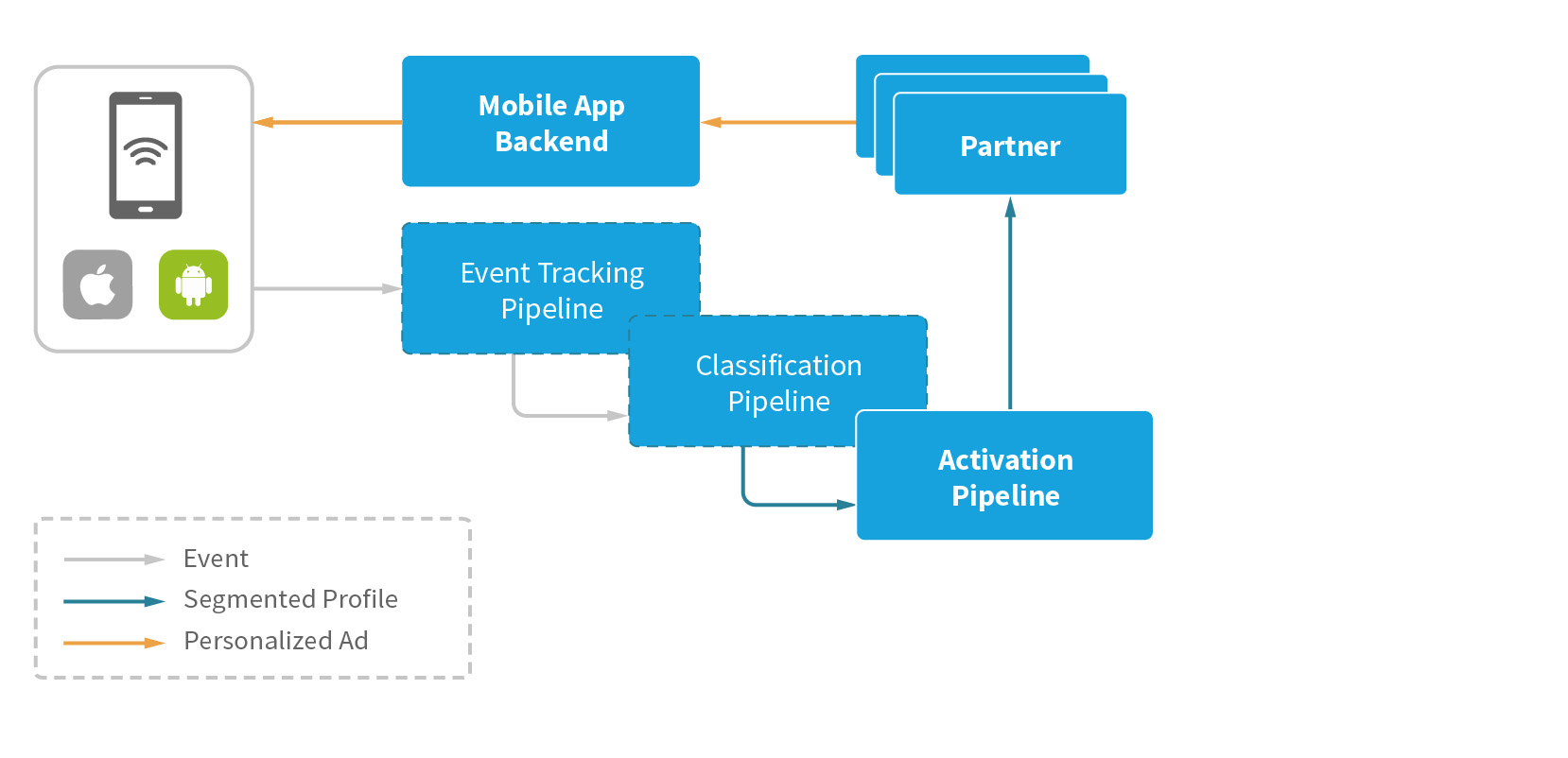
The segmented profiles we built in the upstream pipeline contain valuable attribution information that allows us to predict users’ interests. They have to be propagated to multiple third-party partners. The nonfunctional requirements for the pipeline are:
- Near-real-time update delivery
- Autoscaling based on traffic spikes
- Flexibility in terms of integration with different partners’ API types
- Isolation of the integrations; issues with one partner must not affect others
We created an architecture to meet these requirements:
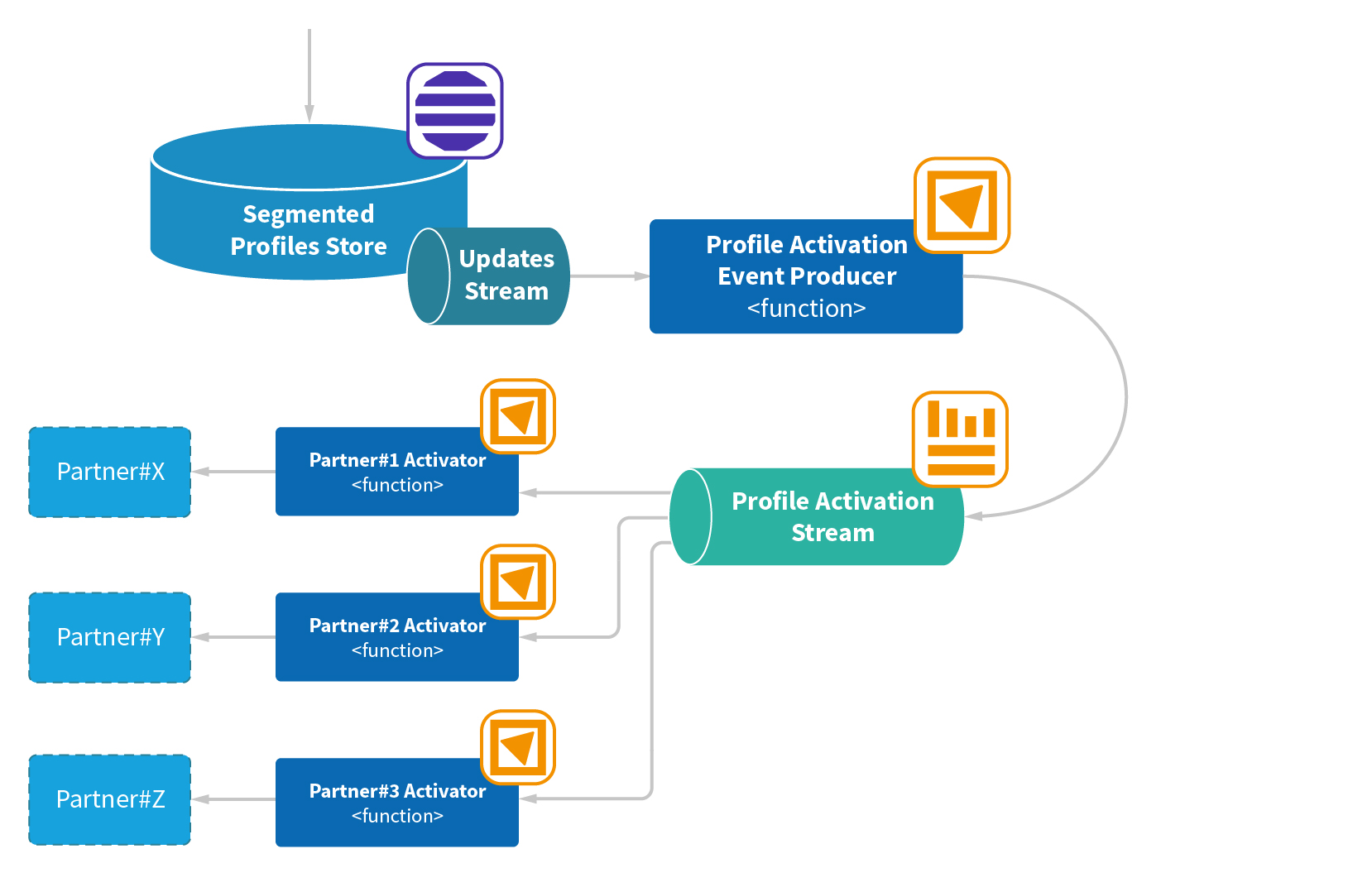
Every update to the table that stores segmented profiles creates an event that gets pushed to a DynamoDB Stream (under the hood by DynamoDB itself). A Lambda function consuming the updates extracts the payload from the segmented profiles events and propagates it to a dedicated Kinesis Data Stream, from which it gets picked up for subsequent activation.
The final step is performed by Lambda-function consumers, each of which integrates with a particular partner.
DynamoDB Stream has different characteristics in terms of scalability compared to Kinesis Data Stream, in that you can’t explicitly customize the number of shards for it. The number depends on the amount of table partitions, which in its turn depends on amount of provisioned IOPS/throughput for the table. Bumping up the IOPS to scale the pipeline was not a viable choice for us in terms of cost, nor was implementing something like [[Lambda fan-out](](http://)https://aws.amazon.com/blogs/compute/messaging-fanout-pattern-for-serverless-architectures-using-amazon-sns/), because it introduced overhead with the PartnerActivator services location and error handling. We wound up introduced an intermediate stage of propagation of the updates to Kinesis Data Stream.
The activated results of the classification stage provide real-time context to partners, whose systems can then make better decisions about what ad to show to each user at a given moment in time.
Serverless and disaster recovery infrustructure
We would have liked a BaaS and FaaS that could also provide fault tolerance against Region-level outages. Unfortunately, there is no such out-the-the-box capability for the majority of AWS services we used.
We have seen a few Region-level outages that lasted more than an hour. They would have caused unacceptable data loss for us, so we had to plan a custom disaster recovery (DR) infrastructure.
Taking into account target recovery time objectives (RTO) and recovery point objectives (RPO) and budget, we decided that supporting a “warm standby” DR scenario for the data collection pipeline would be sufficient to keep the master dataset from being inconsistent. If we did that, we could recalculate everything in the other pipelines from what we found in the data lake on demand.
We implemented cross-Region deployment of data collection pipeline with an automatic failover served by fully-managed DNS AWS Route53:
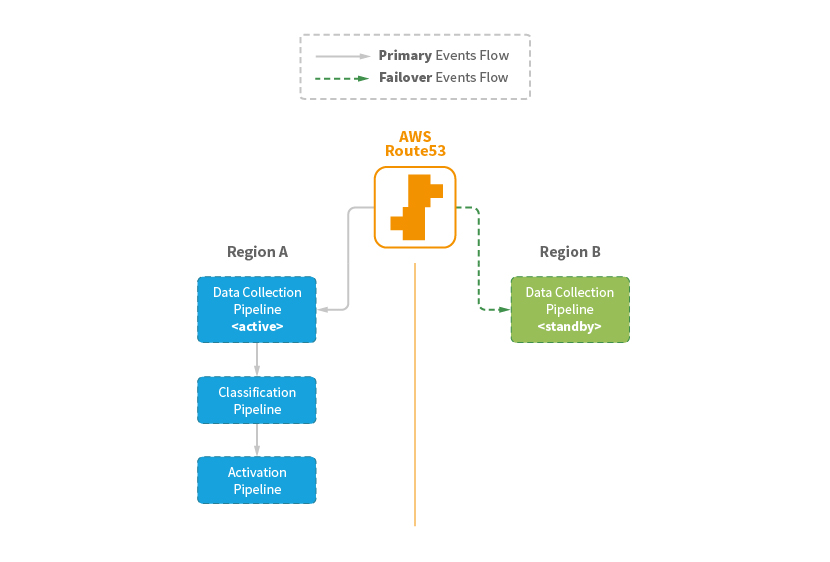
Conclusion
Today, the digital advertising industry realizes the value of personalized offers; for maximum revenue, an ad campaign must target specific audiences of clients, and in the right time, which is real time.
Like our customer, many companies need to add in-stream near-real-time processing support to their existing data platform, or build it from scratch. Building a new platform takes more time and resources, which adds additional challenge.
Serverless tools in the hands of a few development professionals can meet this challenge. As long as cloud vendor lock-in and the drawbacks of infrastructure outsourcing are not deal-breakers, a serverless solution can enhance time to market; our experience shows that delivery of a serverless in-stream processing solution could take as little as one-tenth the time of a similar serverful version.
Ivan Petrushin