
How to identify vehicle tires using deep learning visual models




In the modern world, advanced recognition technologies play an increasingly important role in various areas of human life. Recognizing the characteristics of vehicle tires is one such area where deep learning is making a valuable difference. How? Read on to find out.
Who benefits from tire parameter recognition?
Solving the problem of recognizing tire parameters can help to simplify the process of selecting tire replacements when you don't know which tires will fit. This recognition can be useful both for customer-facing ecommerce and in-store apps used by associates to quickly read necessary tire specs.
Despite the obvious importance of this task, there are currently no working solutions on the market for this specific purpose.
In our project, we leveraged a combination of deep learning modes, OCR and information retrieval techniques to solve the tire recognition problem. As a result, we developed a mobile app that is able to identify the tire using an image snapped by a smartphone camera.
In this blogpost, we will go through the entire life-cycle of implementing a tire spec recognition tool - starting from data retrieval all the way to deployment on Amazon Web Services.
Our approach for recognizing tire specs
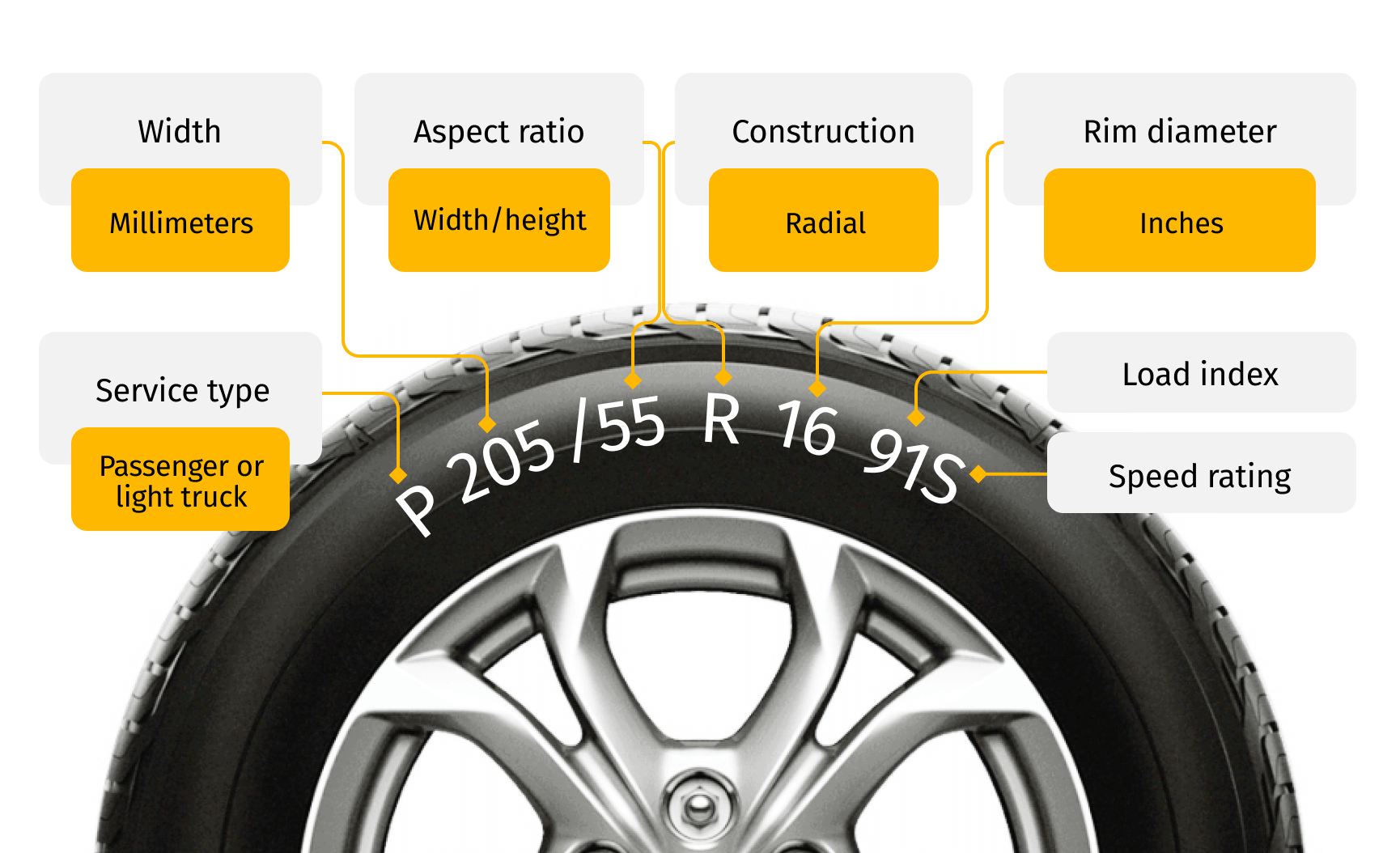
Since all tires look very similar, we have to rely on standard tire branding and specifications inscribed on the tire wall.
In real life, tire images look more like the image below, presenting a significant challenge to recognize specifications dealing with dirt, lighting conditions, suboptimal angle, etc.

We started by splitting the problem into the following tasks:
- Image segmentation and preprocessing - to get a strip of tire from an original image;
- OCR (text detection and recognition) - to detect and recognize text on the strip;
- Post processing & retrieval - to correct OCR errors and improve the recognition quality with heuristics.
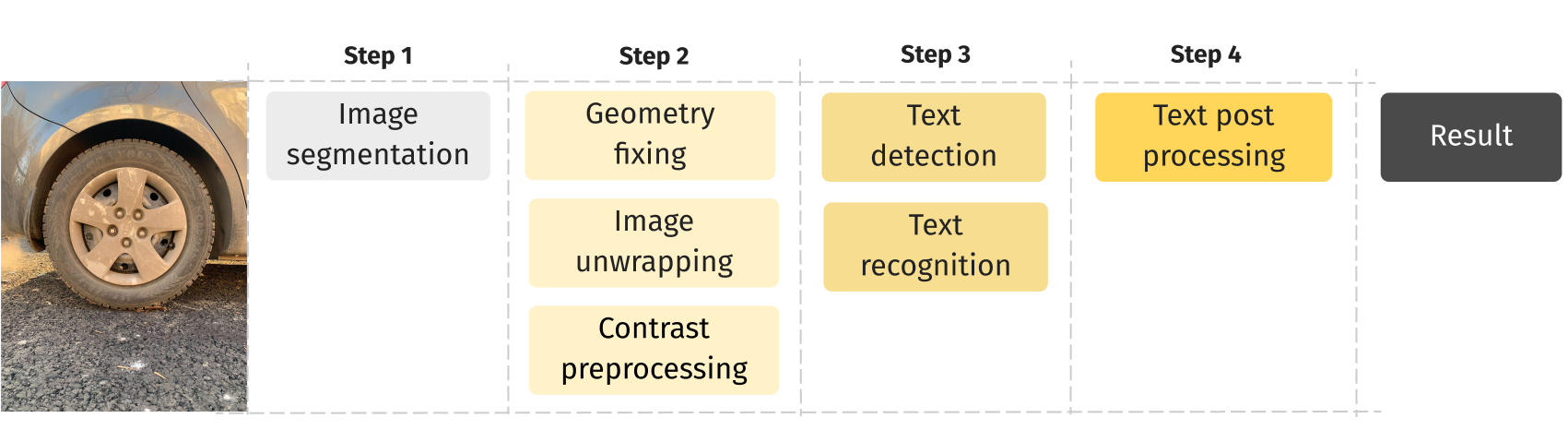
Accordingly, the most important tasks were to train the model to locate the tire in the image and correct various flaws (lighting, wrong angle, etc.) so that the inscriptions could be recognized using the ready-made OCR.
Task 1: Preparing the tire image dataset
Dataset preparation is a critical technique in any Machine Learning project. For this project, however, there were no ready-to-use datasets available. So we decided to use online stores, bulletin boards and search engines for data searching and collecting.
During the research process, we decided that online stores and bulletin boards would be the main data sources, since there were thousands of images and, most importantly, almost all of them had structured descriptions. Images from search engines could only be used for training segmentation, because they did not contain the necessary structured features.
So we collected more than 200,000 tire images with different quality, shooting angles and backgrounds.

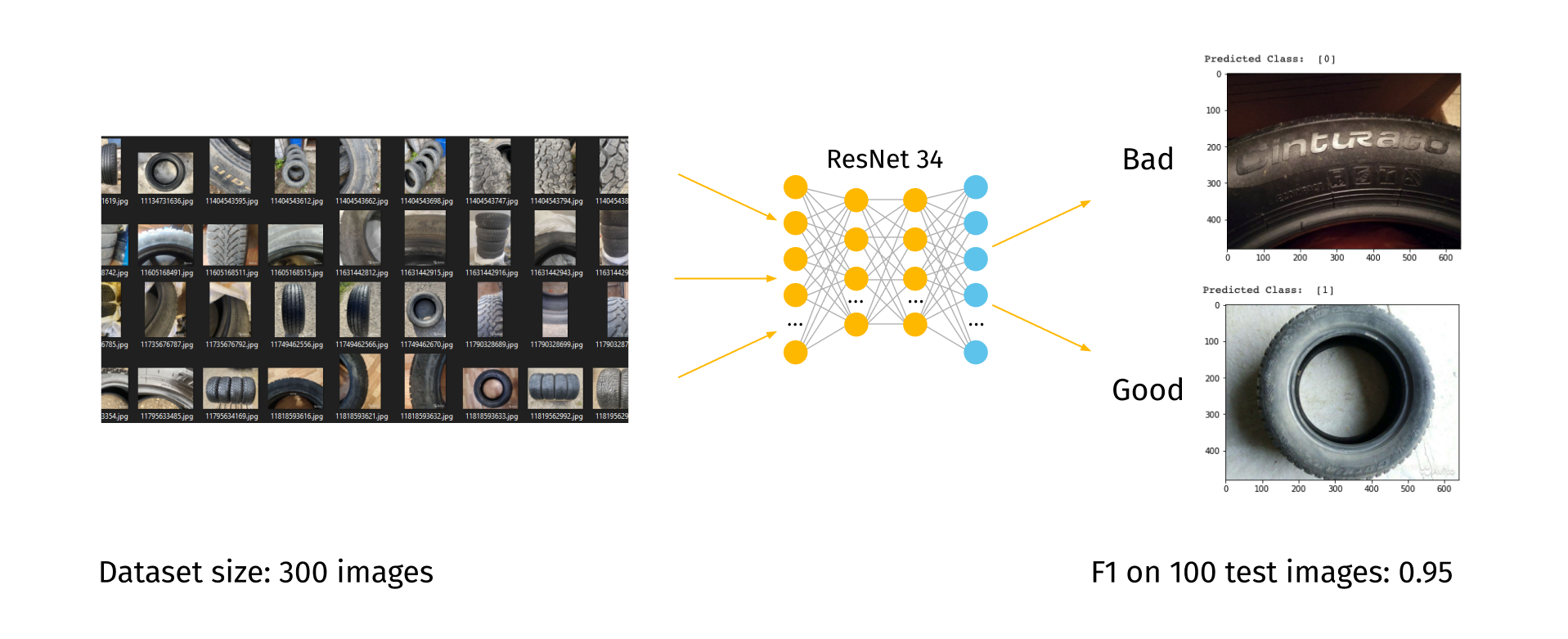
We faced the next balk in our research: most of the collected data was not suitable for our task, so we had to filter those images. Since manually checking all the images would take a very long time, we used a classification model based on ResNet34 to automatically filter the images according to predetermined requirements.
We labeled a bunch of images with two classes “bad”:0 and “good”:1 and trained a simple binary classifier to help us in further dataset cleanup.
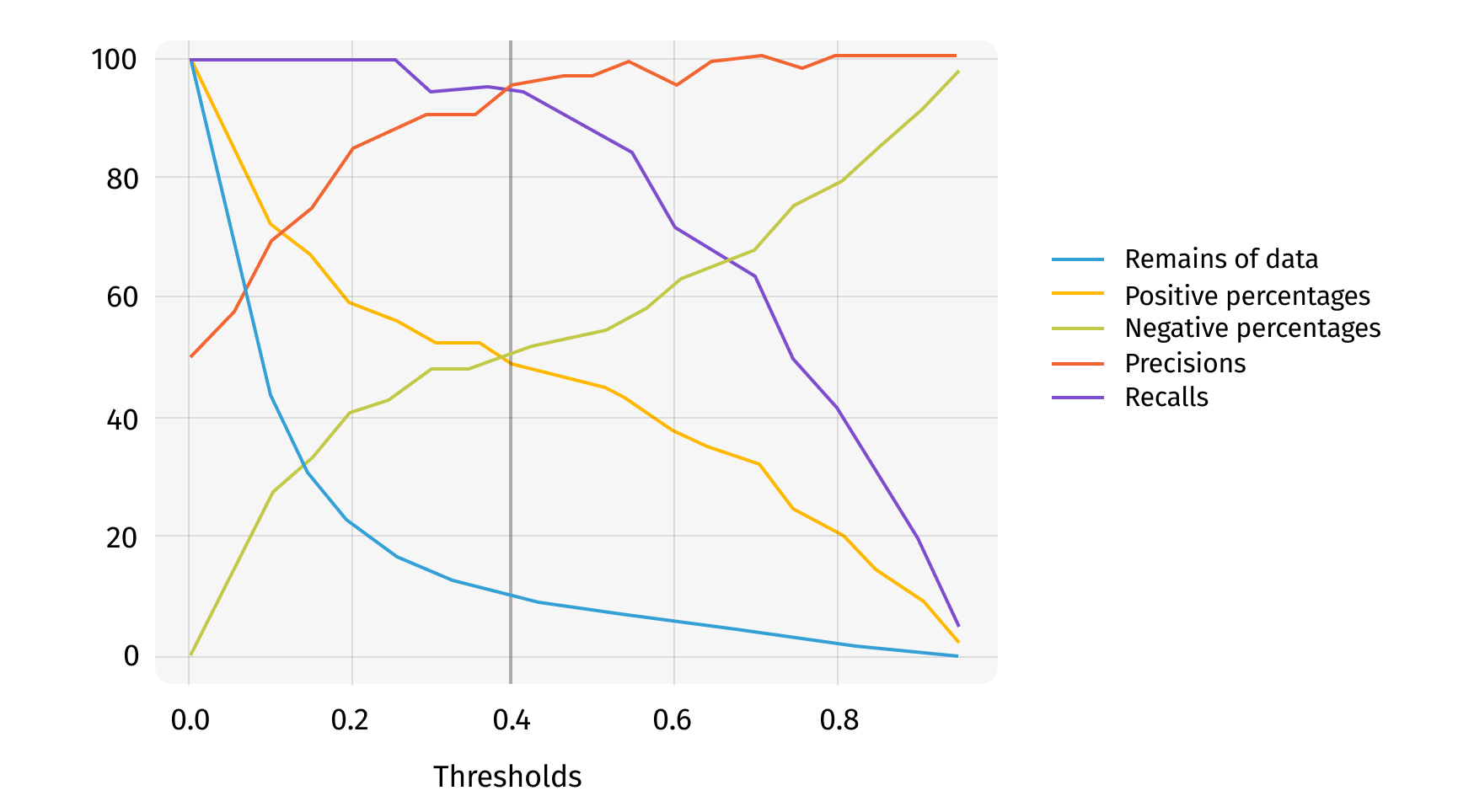
We used the ROC approach to choose the best model confidence threshold 0.4:
After automatic image validation, about 5,500 images were selected as suitable for further use.
Task 2: Detecting the tire in the images
For the task of detecting the location of tires in the images, segmentation models and classic openCV methods can be used to find circular shapes (findContours, HoughCircles). We discovered, however, that classic openCV methods require manual changes in parameters and depend too much on the quality of the original image, so it was decided to use the segmentation models instead.
Segmentation models assign each pixel in the image to a particular class with some probability, thus creating a semantic mask of the image, identifying objects of interest. In our case, we used a different binary segmentation model for detecting “tire” and “background” classes.

In our work, we trained more than 30 different models.
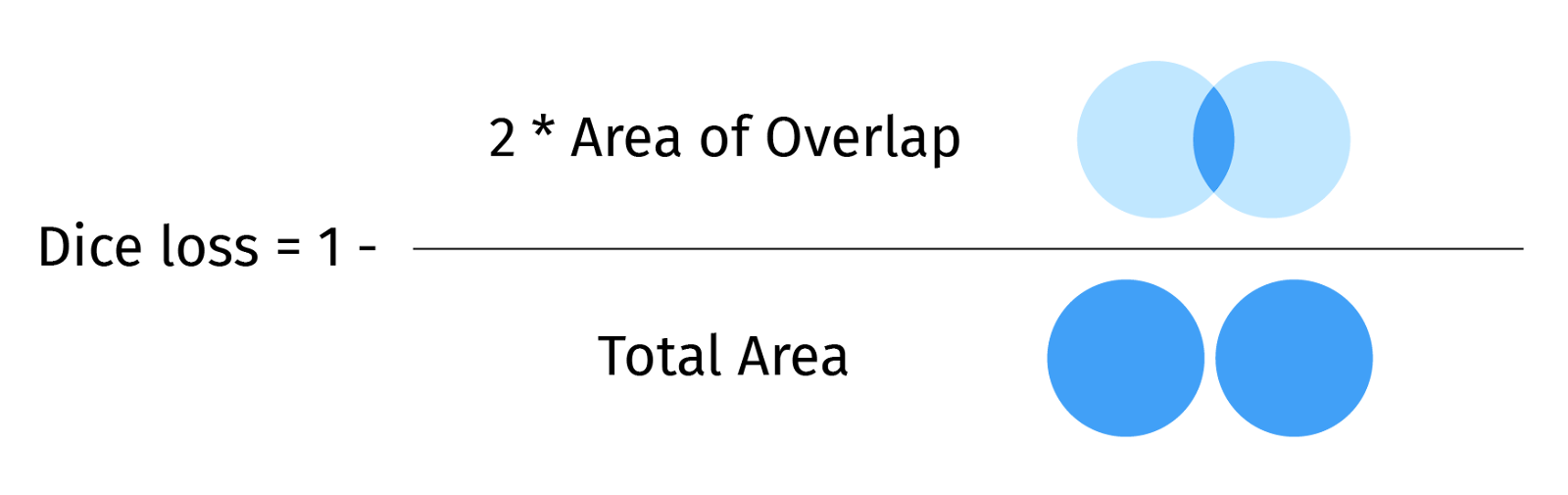
We used the Dice loss formula for training all models, as depicted below:
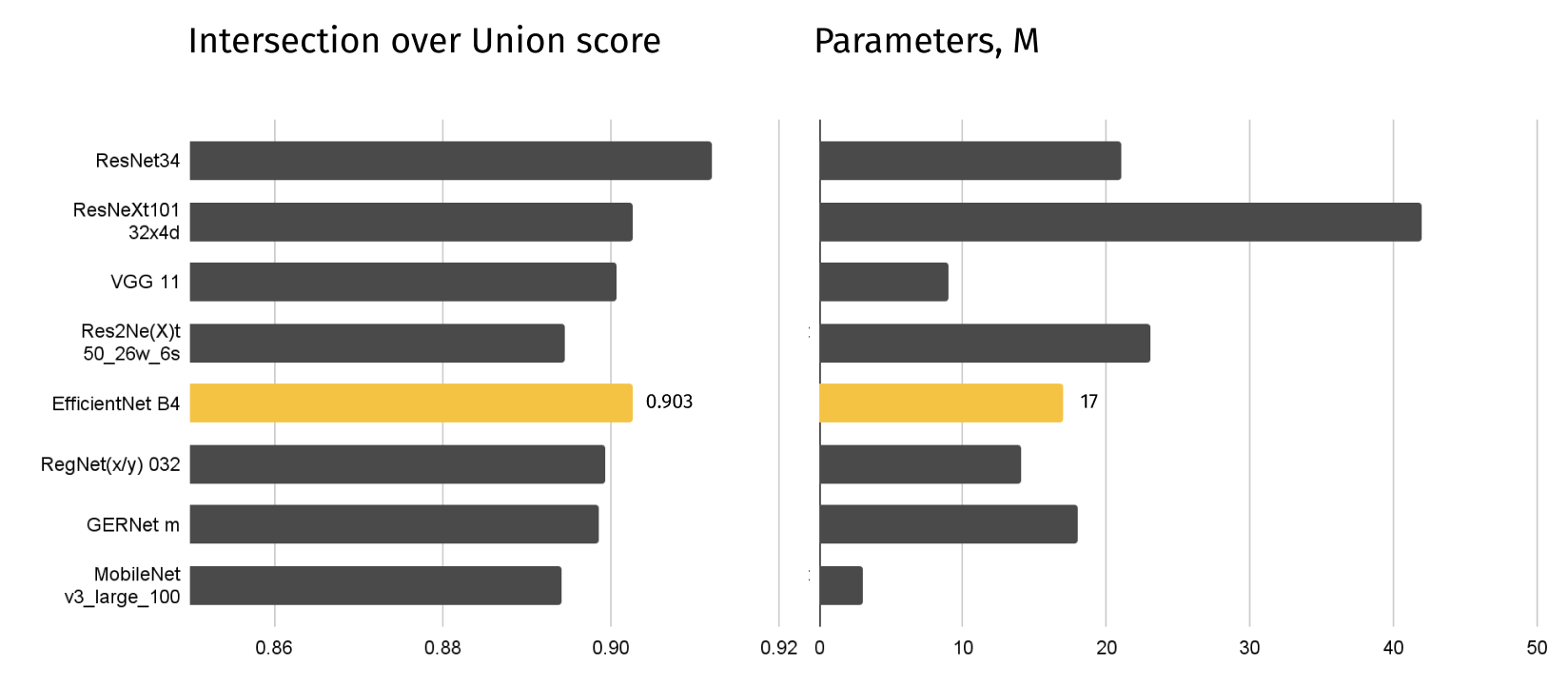
To evaluate the quality of the segmentation, we used the traditional Intersection over Union (IoU) metric:

After checking the IoU of all models, the leader model was chosen, which gave one of the best IoU scores with the fewest parameters - EfficientNet B4.
As a result of this stage, we were only able to detect the tire from the image, and all processes occurring at this level do not affect the background or the wheel.
After that, the transition to the next step was carried out.
Task 3: Image preprocessing and transformation
In order to successfully recognize the parameters on the tire, it is necessary to correct the contrast of the image so that the desired parameters stand out more clearly.
For this purpose, 3 possible methods of changing the contrast were researched - Linear calculation, Histogram Equalization (HE) and Contrast Limited AHE.

The problem of low contrast between the text and the background on which the text is located on the tire, as well as both being the same color, made it difficult to distinguish even the outline of the letters. Therefore, we had to choose a contrast pre-processing method that would enhance the contrast of the contours and not create unnecessary noise in the image.
We settled on the CLAHE (Contrast Limited Adaptive Histogram Equalization) method because it prevents the problem of noise amplification and performs well in improving the local contrast and enhancing the definition of edges.
The next important step was to apply image perspective correction. It is necessary for the circle to be centered in order to get the most even tire strip with distinct inscriptions. Using the function getPersectiveTransform, we were able to achieve good results for this task.

Tire circle is later unfolded into a strip with the WarpPolar function.

Here the tire strip is shown without the perspective fix:

And here the tire strip is shown with the perspective fix:

As a result , we have an aligned tire strip with well-defined tire specs on it.
After these steps, we moved on to the task of detecting the text on the tire strip.
Task 4: Detecting text on the tire
As you can see in the images of the tire strip above, the text on the surface of the tire is not in a continuous stream, but is located in blocks with empty space between them. Accordingly, we first needed to correctly detect all the blocks of text with the greatest accuracy, in order to then recognize the text in the found blocks.
In our case, it is important to find only relevant objects rather than finding all of them. It turns out that the precision has to remain high as the recall increases - which means there will be a large area under the precision-recall curve. So we used the Average Precision metric, which is equal to the area under the precision-recall curve.
To solve this problem, more than 14 pre-trained text detection models were evaluated using 2 different tire image sources: with contrast preprocessing and without it. Blocks of text detected by the models were compared with the blocks marked up by us.
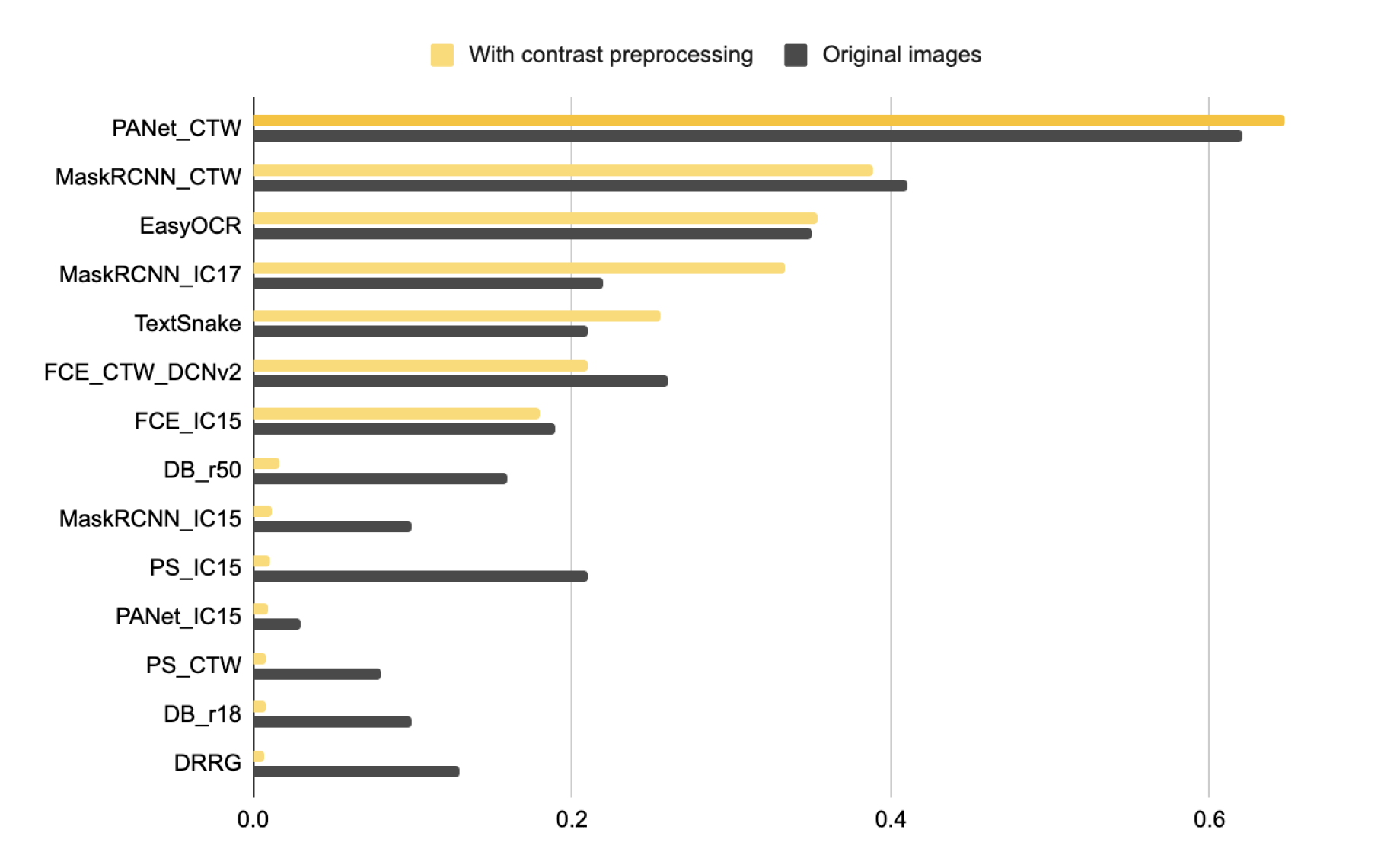
The PANet_CTW model showed the highest value of the metric on contrast preprocessed images, so it was implemented into the system.
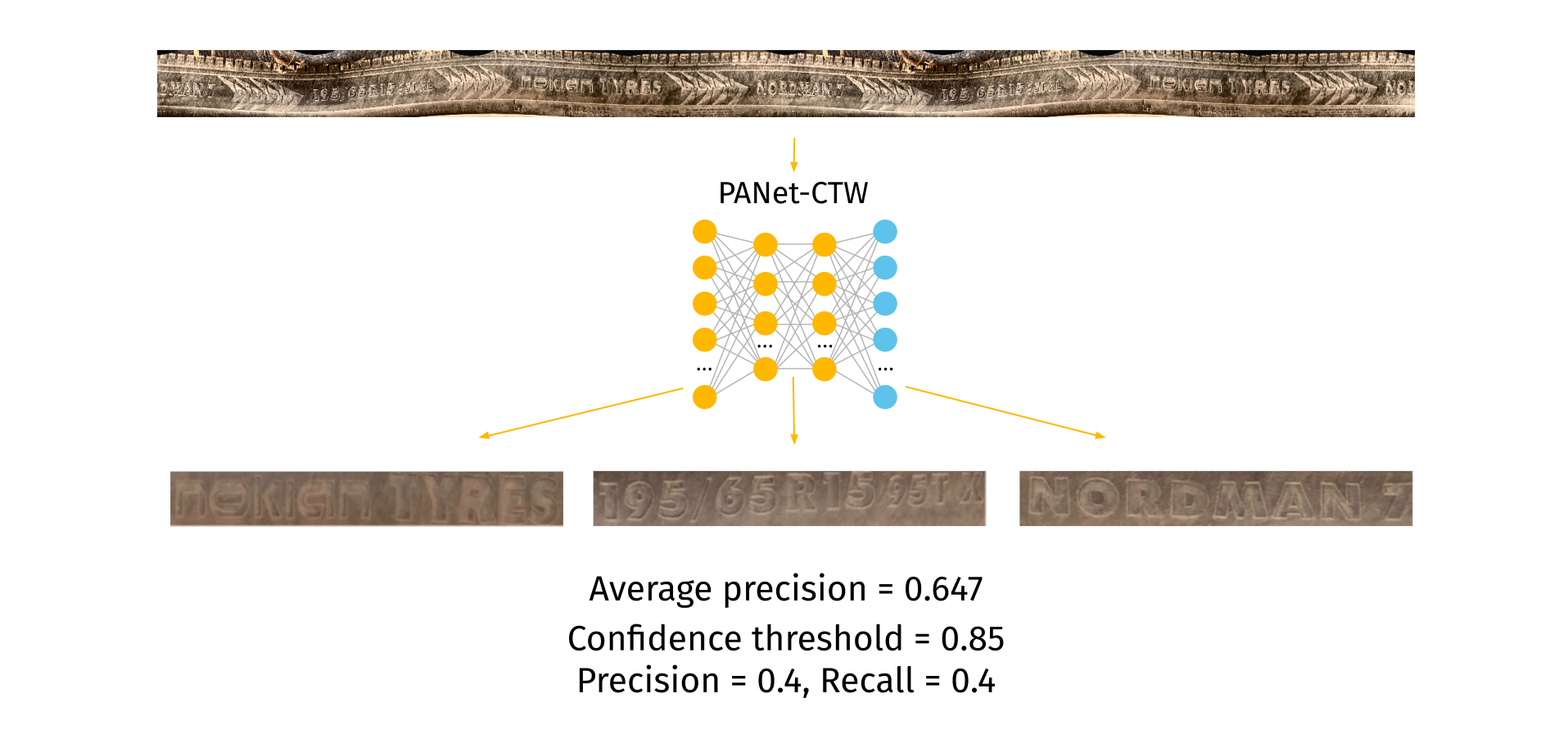
Finally, we moved on to the most important stage - text recognition. This stage is the most difficult and important, and mostly depends on whether the tire can be recognized or not.
Task 5: Recognizing text on the tire
To solve this problem, 10 text recognition models were evaluated.
Character error rate was used as a measure of the success of text recognition on pre-labeled images of text blocks:

| Ground Truth | Predict | CER |
| nokian | nakeon | 0.5 |
| nokian | nokian | 0 |
| nokian | rokkey | 0.66 |
The CER calculation is based on the concept of Levenshtein distance, where we count the minimum number of character-level operations required to transform predicted text into the ground truth text.
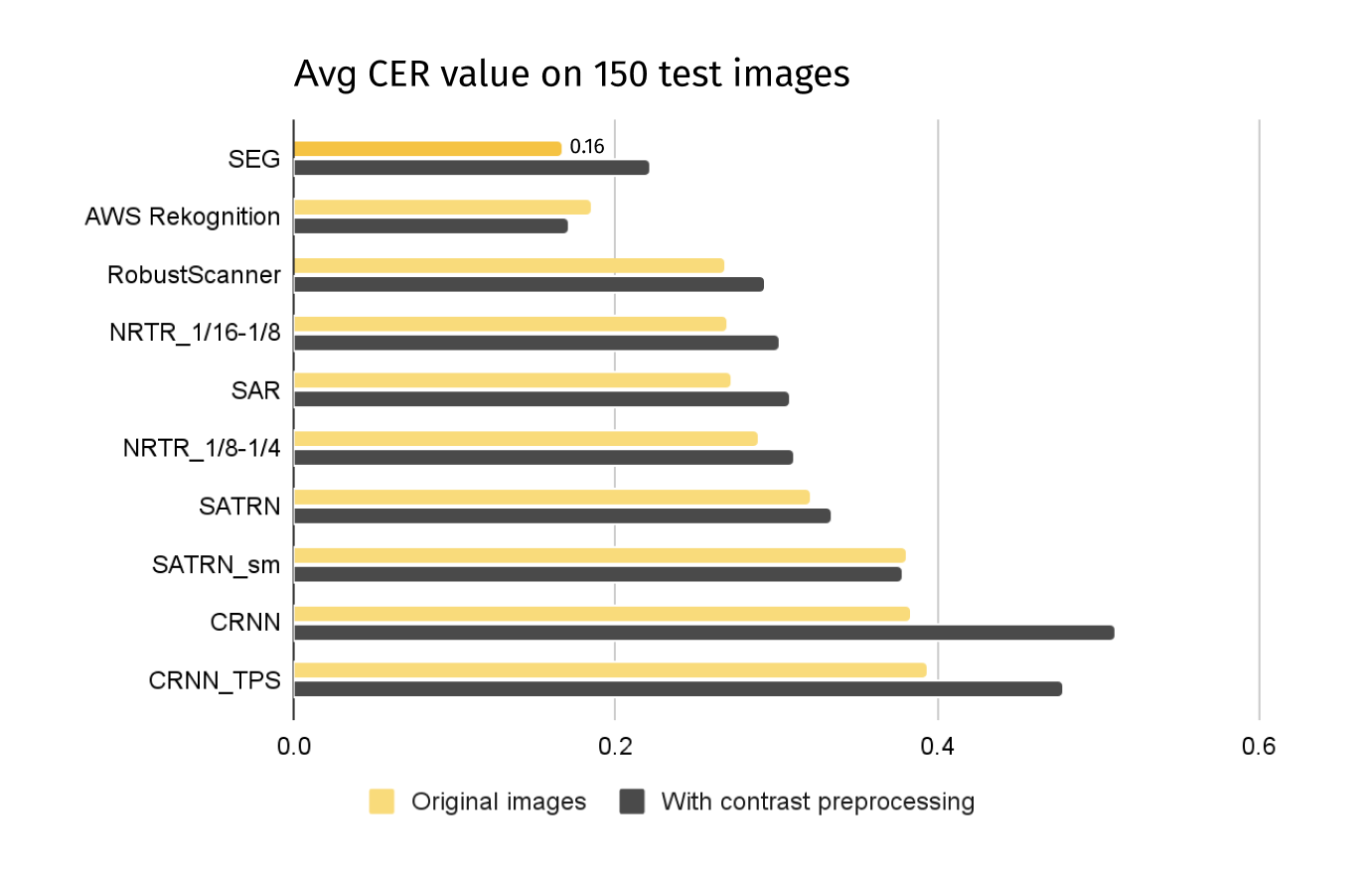
Based on the results of the model's evaluation, the best model was found. SegOCR without contrast preprocessing was selected and implemented into the system.
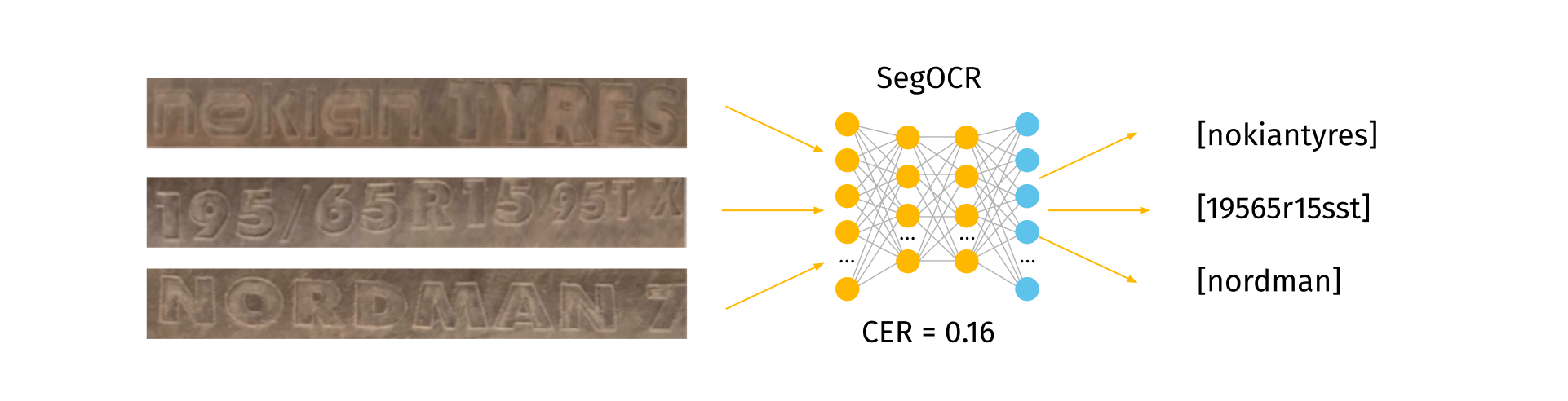
How do we know what type of tire information each of the model's predictions refers to?
For that we implemented the post-processing of recognition results, allowing us to compare the set of recognized text with specific features of the car tires to get an idea of the context of the found character sets.
Task 6: Post processing & retrieval
For post processing, more than 15000 records with tire characteristics were collected from the tire stores we were working with. The data was structured as follows:
| Manufacturer | Model | Width | Height | Radius | Load_index | Speed_index | Seasonality | Stud |
| Continental | ContiWinterContact TS830 P FR | 295 | 40 | 19 | 108 | V | Winter | Studless |
| Continental | ContiCrossContact LX 2 FR | 285 | 60 | 18 | 116 | V | Summer | NaN |
| Continental | ContiWinterContact TS860S | 305 | 35 | 21 | 109 | V | Winter | Studless |
| Continental | CrossContact Winter FR | 295 | 40 | 20 | 110 | V | Winter | Studless |
| Continental | ContiWinterContact TS830 P SUV | 305 | 40 | 20 | 112 | V | Winter | Studless |
Using Levenshtein distance and the recognized words on the tire, we were able to find matching values in the table. The output data contains information about the manufacturer, model, height, width and radius of the tire.
You can see the search algorithm result for the corresponding information about the tire and the output data format in the tables below:
| manufacturer | model | width | height | radius | load_index | speed_index | seasonality |
| Nokian | Nordman 7 | 185 | 65 | 15 | 92 | T | winter |
| Nokian | Nordman 7 | 195 | 65 | 15 | 95 | T | winter |
| Nokian | Nordman 7 | 195 | 65 | 15 | 95 | T | winter |
| Nokian | Nordman 7 | 195 | 65 | 15 | 95 | T | winter |
| Nokian | Nordman 7 | 195 | 65 | 15 | 92 | T | winter |
| Nokian | Nordman 7 | 185 | 60 | 15 | 92 | T | winter |
Task 7: Evaluating the pipeline metrics
The CER metric values on the entire pipeline before and after post processing looked as follows:
| before post processing | after post processing | |
| AVG brand CER ↓ | 0.38 | 0.34 |
| AVG brand CER ↓ | 0.34 | 0.53 |
| AVG brand CER ↓ | 0.48 | 0.30 |
To improve the quality of the pipeline, we took a refinement approach in which we used the segmentation model three times: first for object detection, second for segmentation and third for segmentation after perspective restoration.
First, we predicted the mask on the original image, filtered the mask, and derived the rectangular bounding box. Then, we cropped the image and predicted with the same model on the cropped image. After that we performed perspective restoration and segmentation again.
We achieved the following CER metric values on the entire pipeline without post processing:
| AVG brand CER ↓ | 0.37 |
| AVG model CER ↓ | 0.32 |
| AVG specs CER ↓ | 0.48 |
Due to a small difference in performance and a longer execution time, we decided to stay on the standard version.
As the main metric, we use Recall@k, where k = 1, 5, 10. This metric counts the correct prediction if a correct tire was found among the top K search results.
| K | 1 | 5 | 10 |
| Recall@k | 0.42 | 0.44 | 0.45 |
For the task of finding tires with the same parameters, there are the following Recall@k metrics:
| K | 1 | 5 | 10 |
| Recall@k | 0.42 | 0.73 | 0.73 |
Task 8: Deployment
Because the mobile phone application uses cloud computing to recognize tire characteristics, we chose AWS to host the cloud part of our solution.
The AWS infrastructure scheme is depicted below:
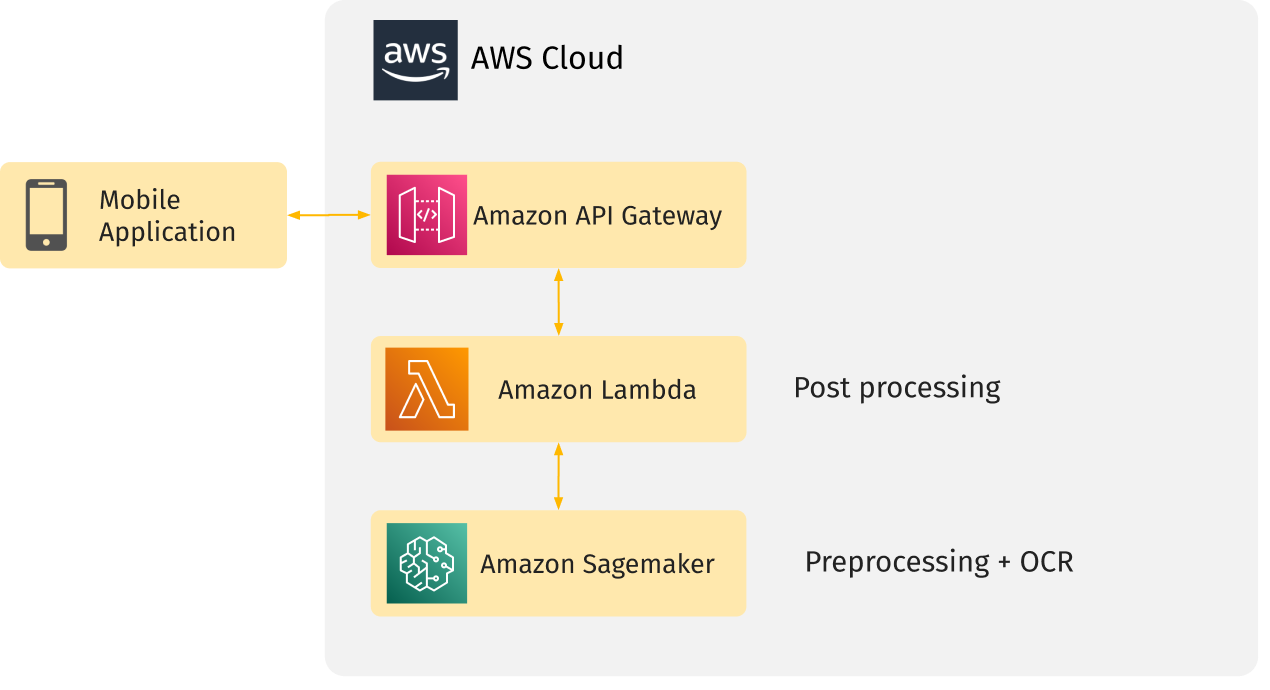
As you can see, the parts responsible for preprocessing and OCR are hosted in AWS Sagemaker. We also use AWS ECR to store the Docker image needed to deploy the model to Sagemaker and S3 Bucket to store model artifacts.
The post-processing part is hosted in an AWS Lambda function and this function receives a request through an API Gateway. The lambda function gets the model prediction from Sagemaker Endpoint, post-processes it, and returns a response with the recognition results to the mobile application.
We automated the process of deployment into AWS for convenience. The deployment scheme is depicted below:
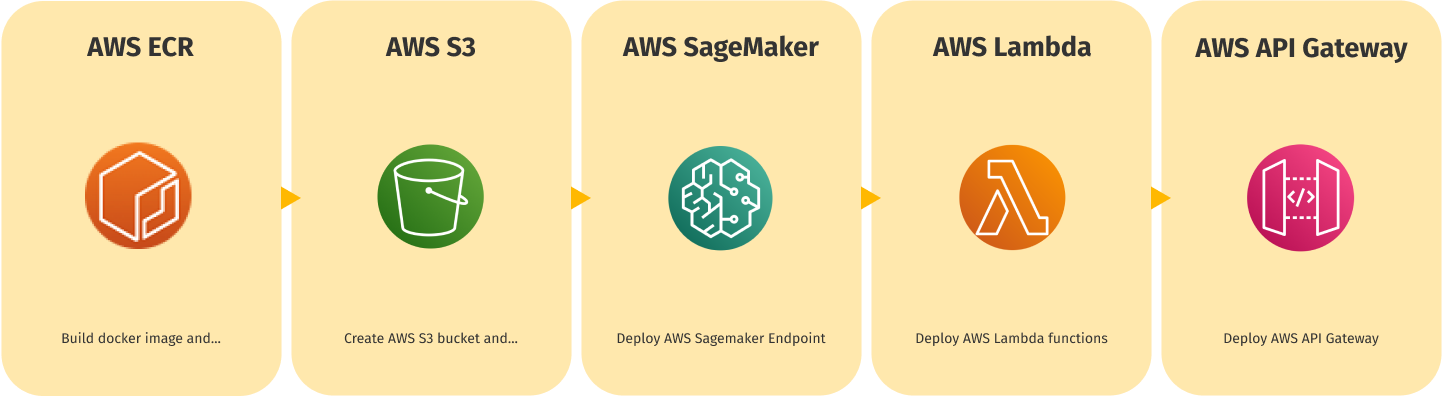
Task 9: Mobile application development
For the user interface we developed a mobile application that enables the user to take a photo of a tire or upload an image from the gallery. The tire image is sent to the API of our cloud infrastructure, where it receives a response containing the discovered information about the tire.
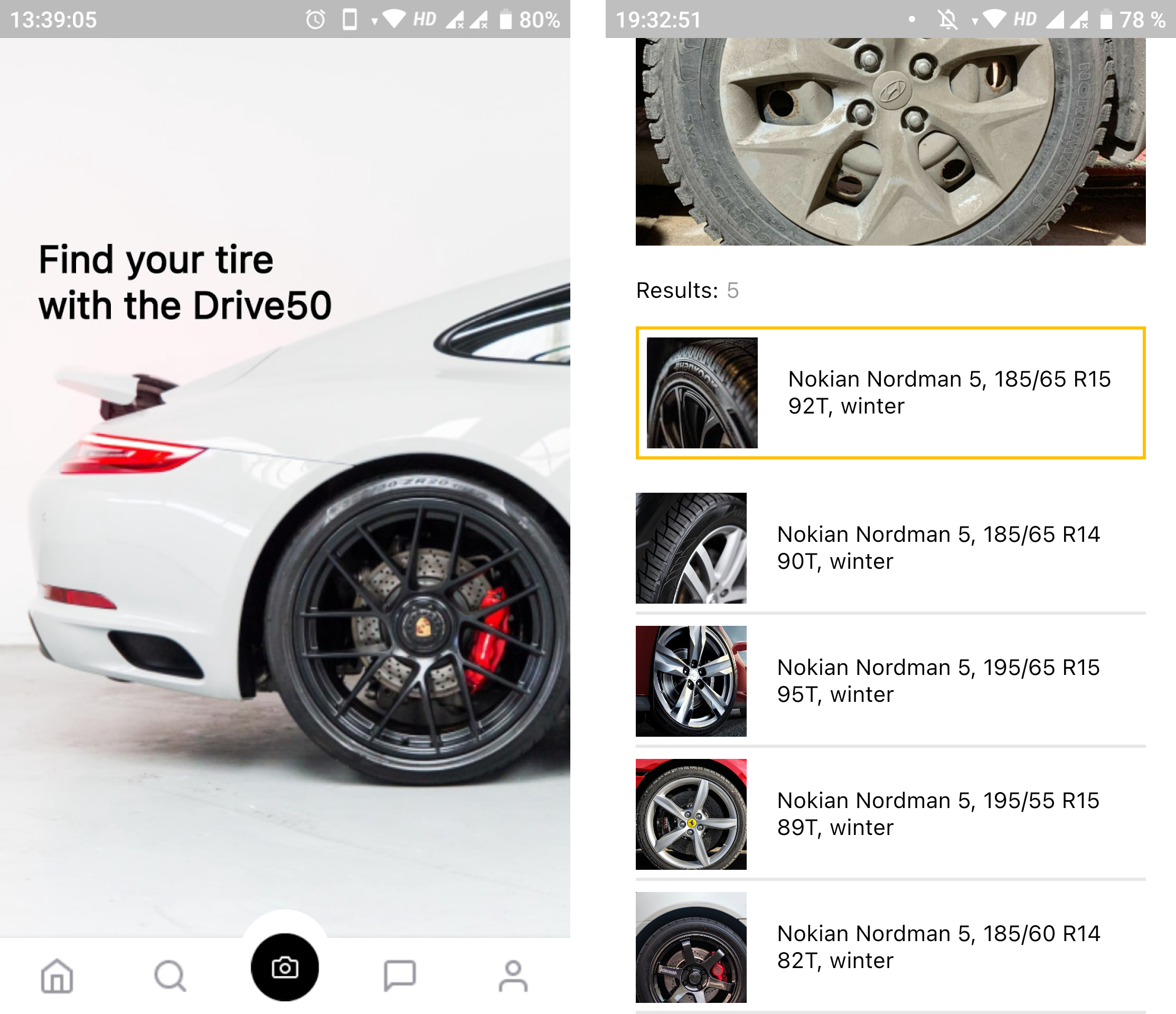
Conclusion
In this blog post we have described the complete process of creating a tire lettering recognition system from start to finish. Despite the large number of existing methods, approaches and functions in the field of image recognition and processing, there remains a huge gap in available research and implementation for very complex and accurate visual search systems.
For this project, we performed a lot of research, studied many approaches and processed a huge number of results, which made it possible to create an accurate and practical visual recognition system, despite time constraints and lack of niche expertise in this field.
Of course there are still areas for improvement. The performance of the OCR process can be improved by retraining the detection and recognition models on our dataset. Post-processing can also be improved by expanding both the search database itself and by improving the search algorithm. This will allow you to more accurately correct OCR errors and generate a better response for the user.
The tire recognition solution we developed, thanks to the ever-increasing popularity of visual search systems, can be used to solve business problems in various areas related to the automotive industry.
A final thought: don't be afraid to explore and solve even the most difficult problems, and good luck!
Reach out to us if you are interested to learn about the benefits of visual search for your industry.