
How to Release Components Independently when you have a Distributed Monolith


It's an e-commerce web application for a top-tier North American retailer. Quite a large application system - a few hundred developers are working on it. The system was rebuilt from scratch from a heavy monolithic enterprise application platform to a number of separately deployed components interacting over the network and running in the cloud. Why? Because they need new business features fast, 365 days a year. The problem? Feature releases are still once a month.
The issue is not specific to e-commerce. Most business applications have their functions spread over many parts of the system, which is also continually changing. It is difficult to fit into a thin and stable API. That's why so often a re-platforming from a monolithic application system to an ensemble of components communicating over the network doesn't end up with a microservice design. More often it becomes a tightly coupled conglomerate, where changes have to be orchestrated and come to production in aggregated big-bang releases.
There are many signs that point to this issue. A centralized QA team aiming at end-to-end application validation, usually by UI tests. The individual component teams without testers or even without some component-level tests. A centralized release team. Pieces of code shared between components so a change in the shared part requires updating all the dependent modules. Circular dependencies between application components.
A common recommendation is to step back. Restrain the component interfaces and segregate different functions to different modules. Or build comprehensive suites of component tests and build multi-functional application teams. That does work. Except for one problem - it is often prohibitively expensive. And it usually doesn't give the desired change velocity because a business feature is not a change in a single API service.
So we prefer to think differently and put on the developer's shoes. As a developer of a business feature, I most likely won't have an opportunity to develop my feature and reliably test it in isolation. At most I can rely on the fellow QA team that can validate if my feature works correctly as a part of the whole system. In a perfect world, I'd want a full copy of the production system for development. I’d then want users to leave the production system for some time so I could deploy and check the new version without disruptions, hand it to the QA and then, if everything goes well, let the users come back.
From daydreaming to whiteboard
For most cases I don't need the production system itself, a perfect copy is fine. A full copy of the production environment for each feature would be way too expensive. But a "perfect copy" is not necessarily a "full copy". A "shallow copy" is just as good. To make a shallow copy I don't have to replicate each piece of the system, instead I access the system components by references and copy only the references. So I get a perfect clone essentially for free.
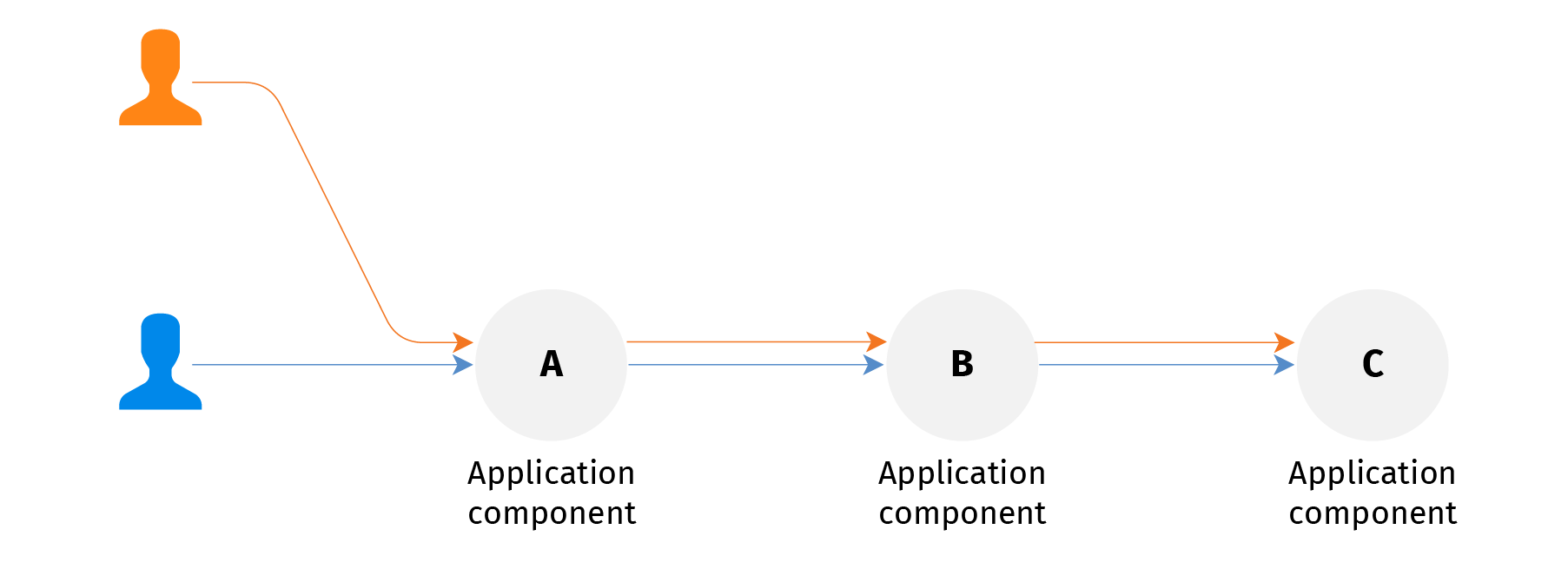
Having a full application system at my disposal, I update my component to the new version implementing the desired feature. The "copy on write" technique helps - it is complementary to "shallow copy". Here I deploy a new instance of my component side-by-side with the production one and update the reference to it. Now my clone of the system differs from the original one, but the difference is exactly my deployment.
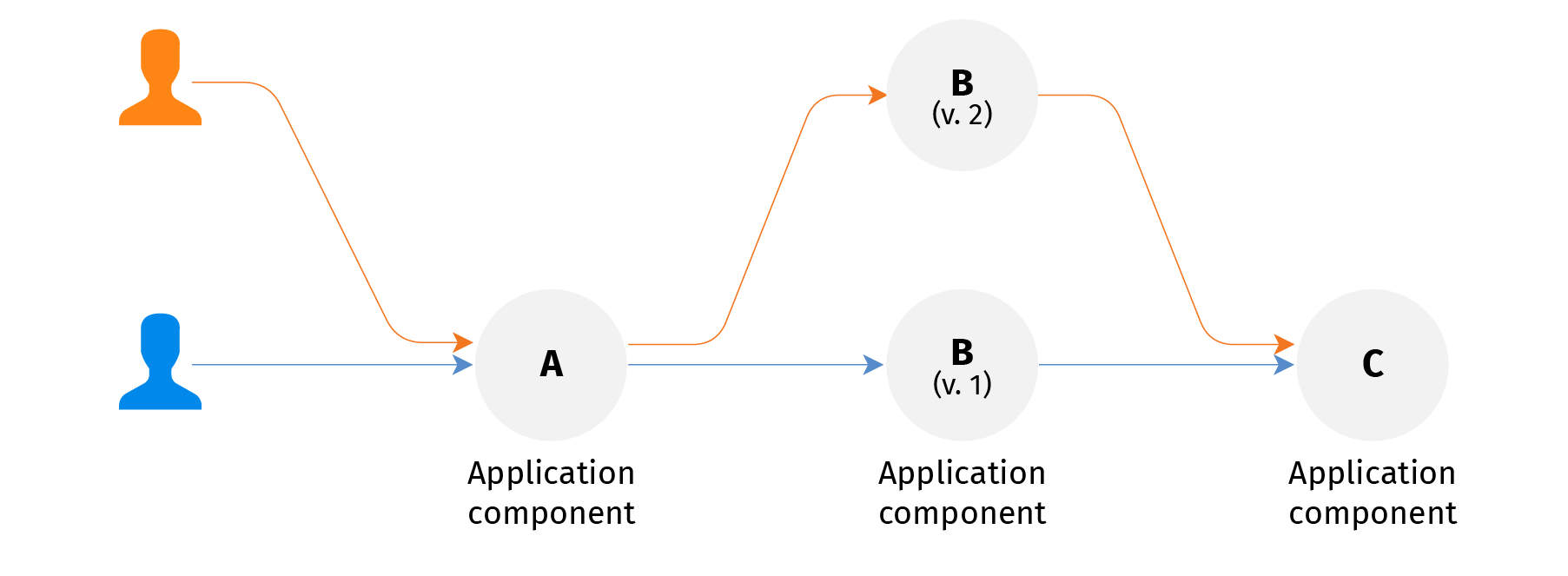
So my company needs just a single non-production instance of the application system. Everyone will have a (shallow) clone of it for development and testing. And a single full production system - I deploy my update to its clone and switch users to it when ready.
It looks similar to communication channels within a telecom network. The channels share the network but they don't intersect and don't see each other. Similarly, we refer to these shallow clones of application systems as "channels" or "deployment channels". These five operations cover the life cycle of a channel:
- Create
- Clone (implements shallow copy)
- Update (updates a component deployment with copy-on-write)
- Delete
- Garbage collection
Once they’re implemented, each channel can be used just as a regular independent system instance. But let's move from abstractions to real world implementations. Fortunately most of it can be done with available open source tools or cloud services. So let’s see.
Assuming we're still dealing with a web application, it may expose APIs for mobile clients or serve web pages for desktop browsers - it doesn't matter. In any case, user actions come in the form of HTTP requests. HTTP doesn't maintain user sessions. But HTTP requests come with metadata that allows segregation of users, so requests from a user can be distinguished from requests by another user. It could be done by way of HTTP cookies or authentication tokens, or in the most obscure cases by source network addresses. It’s not a problem if we don't separate requests from two similar users, we just need to ensure that requests from a single user don't come to different buckets.
Incoming requests don't pour directly to the application services. Instead they come to a border proxy service or an API gateway such as Apigee. It is the first tool in the kit. It does a few things - segregates requests from different users, sorts users to cohorts according to operator-defined criteria, and labels requests from a cohort with a tag. For example QA engineers evaluating the new functionality may be one cohort, a pilot user group for early access the other, and the bulk of the user base the third. Then the border proxy configuration associates user cohorts with deployment channels and indicates the selected channel with a label in the request metadata. For HTTP the label is a request header with a known name and the channel name as the value. But the requests from different cohorts still go through the same fire-hose.
At this moment we may need to send requests from different cohorts to different application system instances. That's pretty easy if they are full copies - the copies don't intersect. They have different network endpoints so the border proxy just needs to forward requests from a bucket to the specific network address. But when the channels are shallow clones they share application components and their network endpoints. Apparently the usual L3 network traffic routing is not enough, we need it respecting application level context - the request labels. Service mesh is a class of application networking middleware doing exactly that. Istio is the most prominent example but Buoyant LinkerD pioneering the service mesh trend and HashiCorp Consul Connect are also worth mentioning. Service mesh is the second piece in the kit.
Service mesh acts at the application layer (L7) rather than the network layer (L3) where the regular network routing works. When an application code calls an HTTP service, it makes an HTTP call to a URL (say http://example.com/service). From the application side the URL is the entry point to the remote service. However, for the networking stack the URL doesn't make any sense. Instead it sees a TCP connection to port 443 at a host with the IP address resolved from example.com by DNS. The rest (/service URL path, request method, request metadata) is out of its scope. So the application and the networking stack act in the same context (HTTP call to the URL) but see it completely differently. And that's a problem.
In contrast, a service mesh middleware sees an HTTP request to http://example.com/service, exactly as the application. Then it may apply various logic mapping to the service endpoint (the URL) to network endpoints of particular service instances and back. This is regardless of scaling, upgrades, experiments, and failure recoveries. So the application code communicates directly to http://example.com/service service as it is implemented rather than relying on assumptions, conventions, and operations craftsmanship.
A well-implemented service mesh is transparent for application servers and clients. Effectively it can be injected to a running system on the go - with zero configuration it works like a bare network. Though in our case the service mesh routes HTTP requests not just by the host part of the URL, but also observes the request labels assigned by the border proxy or the API gateway.
The last part of the toolkit cannot be taken from the shelf. It belongs to the application. The border proxy labels incoming requests and the service mesh routes requests according to the labels. But the application code needs to retain those labels. For example if it is a catalog UI component calling catalog, inventory, and pricing API services, the catalog UI must relay the incoming request label to the resulting outgoing requests to API services. If the incoming request has a "v1" label in its HTTP headers, the catalog UI calls to inventory and pricing APIs must have the same HTTP header.
A frequent perception is that it is not a problem, that such a complication is not necessary, and that the regular traffic shifting facility of any modern load balancer does the job. So if I want to roll out a new release, I deploy it alongside the old version and gradually shift traffic to it. Unfortunately it works to a limited extent only in the case of a true microservice architecture when each service is independent, comprehensively tested in isolation, and fully backward compatible. So end-to-end testing before release is surplus. However, it is rarely the case. Moreover, shifting a fraction of the traffic means a fraction of each user's traffic. So each user will get a mixture of the old and new experience. It also makes comparative evaluation (A/B experimentation) of application code features impossible.
From whiteboard to software
Now let's see how it plays out in a real environment - an e-commerce web application, Istio service mesh, and Apigee Edge API gateway. For simplicity the application runs on a Kubernetes cluster but technically an Istio service mesh can be deployed at multiple Kubernetes clusters, bare cloud VMs, or in a mixed Kubernetes-VMs setting. Istio has a dedicated API object (VirtualService) controlling traffic routing in the service mesh. Here it is:
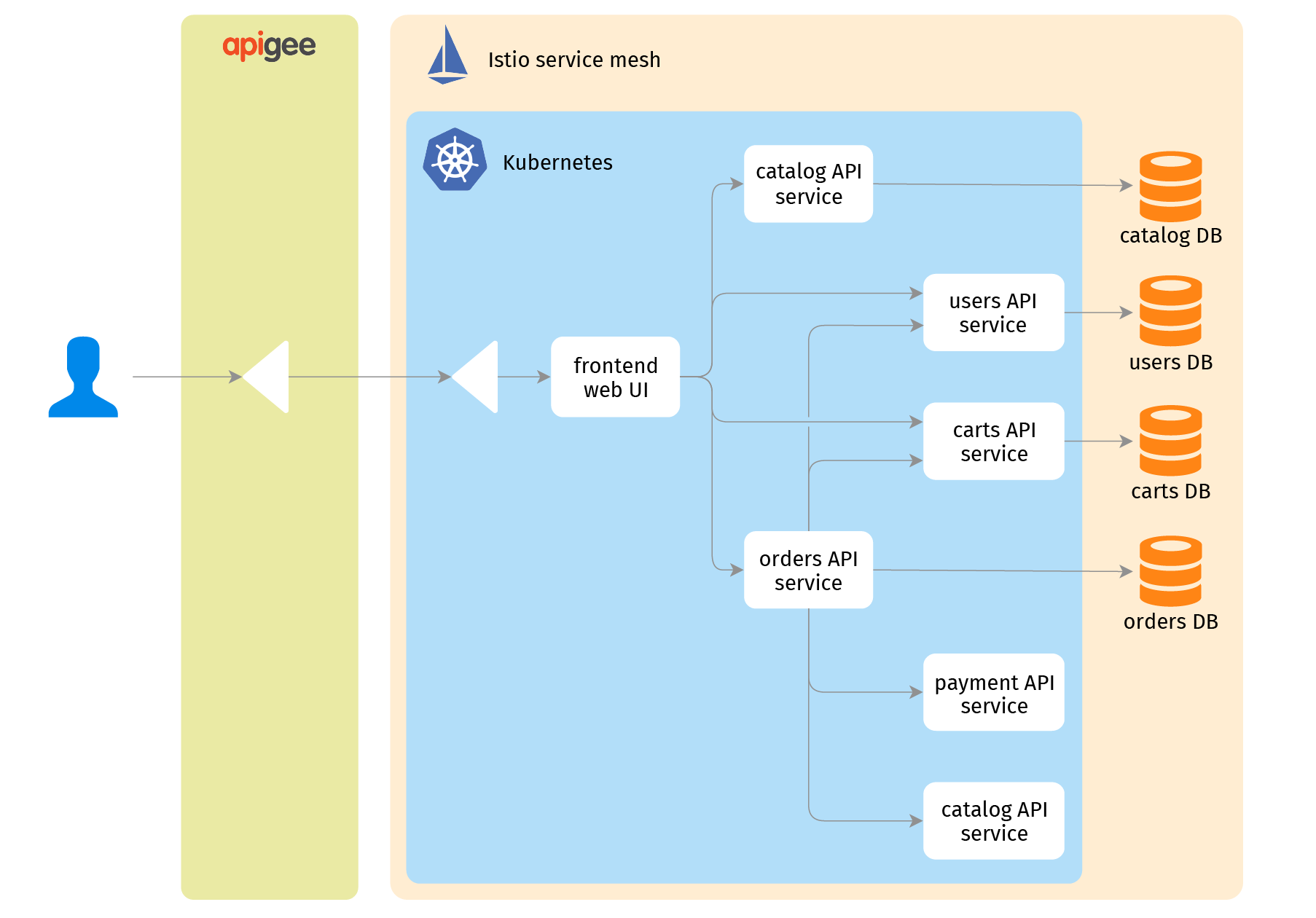
At this point the new parts (Apigee, Istio and the application support for request labels) add nothing. But the actual process under the hood becomes a bit more interesting. When I enter the site URL in my browser, the request goes by Apigee Edge proxy that adds a channel header with, say, "v1" label and forwards it to Istio ingress proxy at the edge of the Kubernetes cluster. By default the service mesh ingress proxy forwards the request to a frontend service instance ignoring the label. With additional conditional routing, it does the same - for now, because only the single frontend instance is available.
Use case: release to production
To make use of it, let's release a new version of the catalog service. What's interesting is that the application users don't interact with the catalog service directly, they see only the UI frontend. So they cannot be diverted to another network endpoint to see the new version. To complete the task, one should take a few steps. The first is to make a shallow clone (a channel) of the system for a new deployment. Let's call it "v2". "Make" means a set of Istio VirtualService routing objects that apply to requests with the label header equal to "v2". For now these routes point to the same old application component instances.
Next is to add a rule for the Apigee Edge proxy. It will select QA users by a specific HTTP cookie that QA users set in their browsers. QA users are assigned the "v2" label. So as a QA user I set the cookie in my browser, enter the site URL... and see the same picture because for now the "v2" channel coincides with "v1".
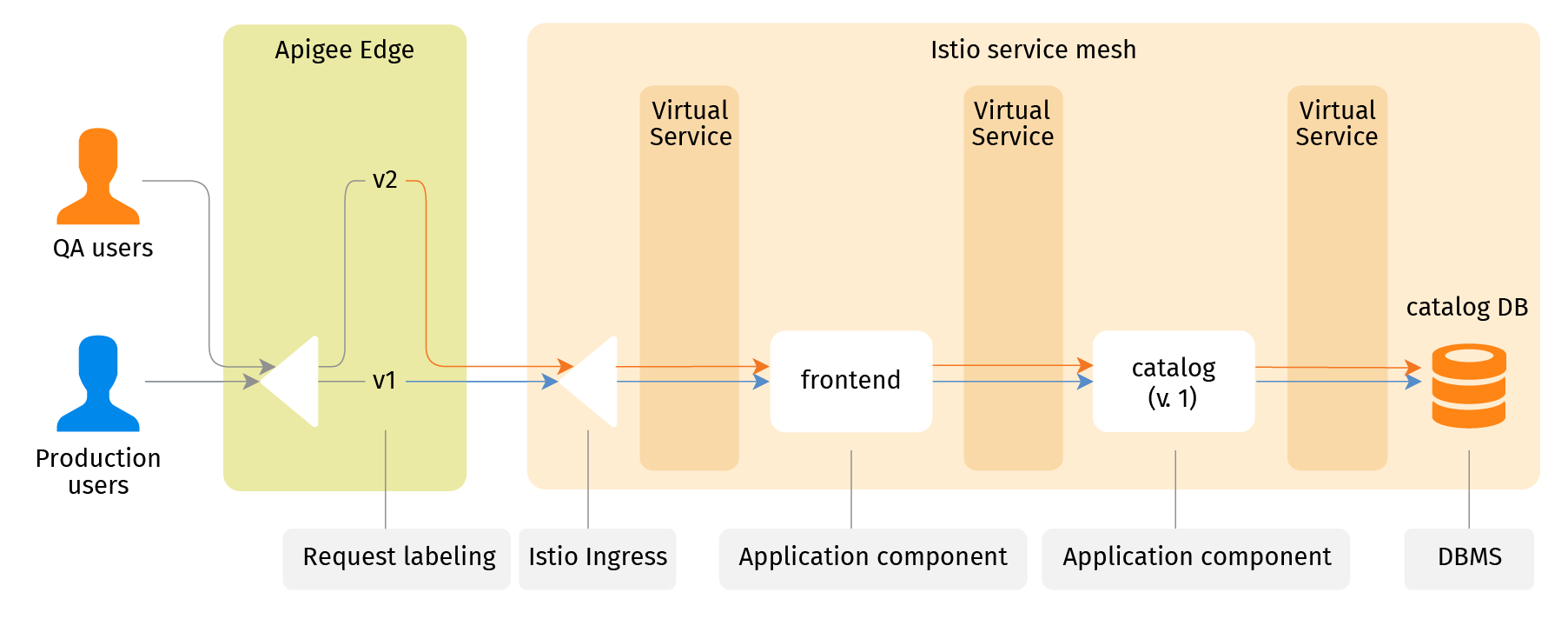
Now I deploy the new version of the catalog service. I deploy it alongside the existing one, label it as "v2" and update service mesh routing (the catalog VirtualService) to send requests with the "v2" label to the new ("v2") catalog instead of the old ("v1") one. It wouldn’t change anything if the application doesn't relay label headers because the catalog service doesn't get labeled requests directly from the border proxy that adds those labels. But because every application component adds the same label to each outgoing request it sends to fulfill the incoming one, the whole tree of requests caused by the initial one from a user is routed consistently, to the same instances, within the same channel - either "v1" or "v2".
It does not change anything for the majority of users. Their traffic (labeled with "v1" at the border proxy) still goes by frontend to the "v1" catalog API service. But the QA users accessing the same site get the new catalog experience. They may validate the system end-to-end using a traditional monolithic testing approach. Effectively, QA users and everyone else see two different application systems, as if they were deployed separately and share only the data. Practically these two systems are virtual, sharing most of the same components.
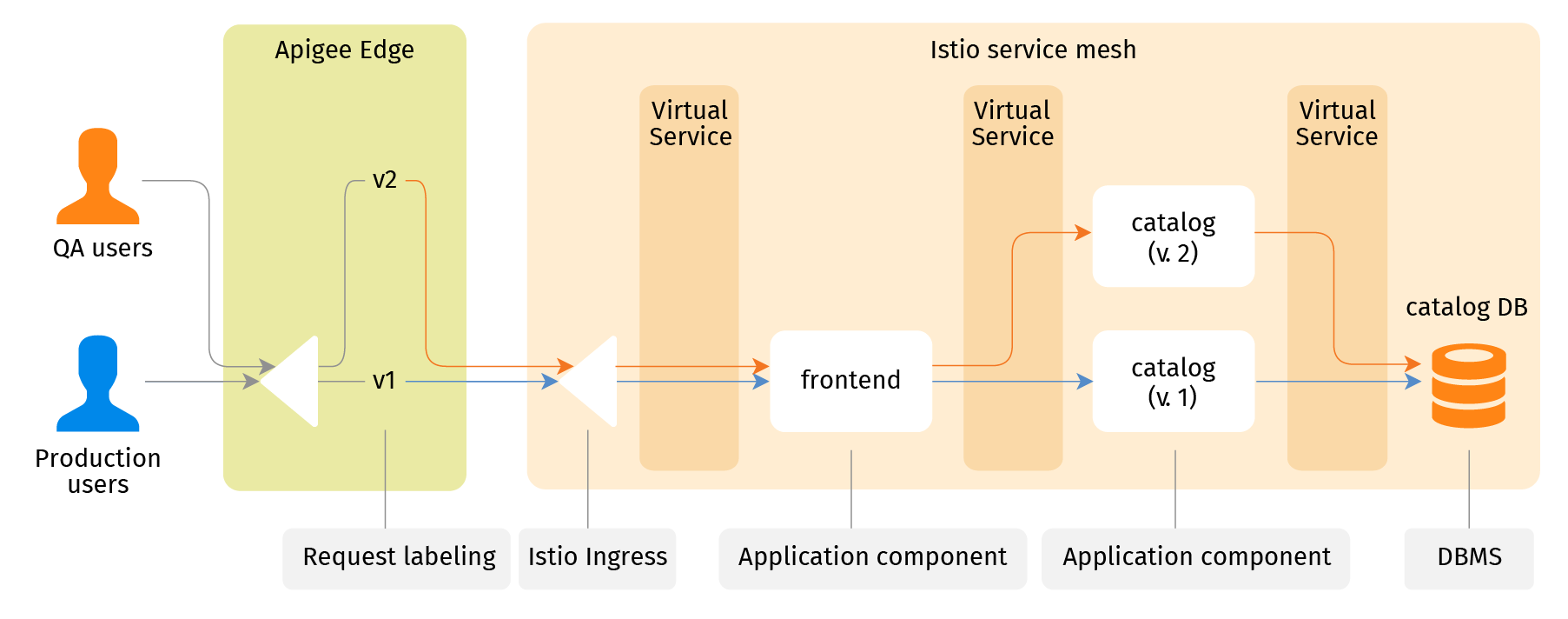
Once everyone is satisfied, the Apigee Edge proxy can be reconfigured to gradually re-assign the production users to the "v2" channel. Once done, "v1" routes may be removed. This leaves the old ("v1") catalog API service without any link pointing to it, so it can be destroyed (garbage collected).
At this time I take minimal risk - users see exactly the same instance of the application system as was validated. Not "similar", not "using the same artifact versions" - such similarities leave a lot of room for discrepancies that can and will cause issues. Just exactly that instance, certified.

Use case: A/B experiment
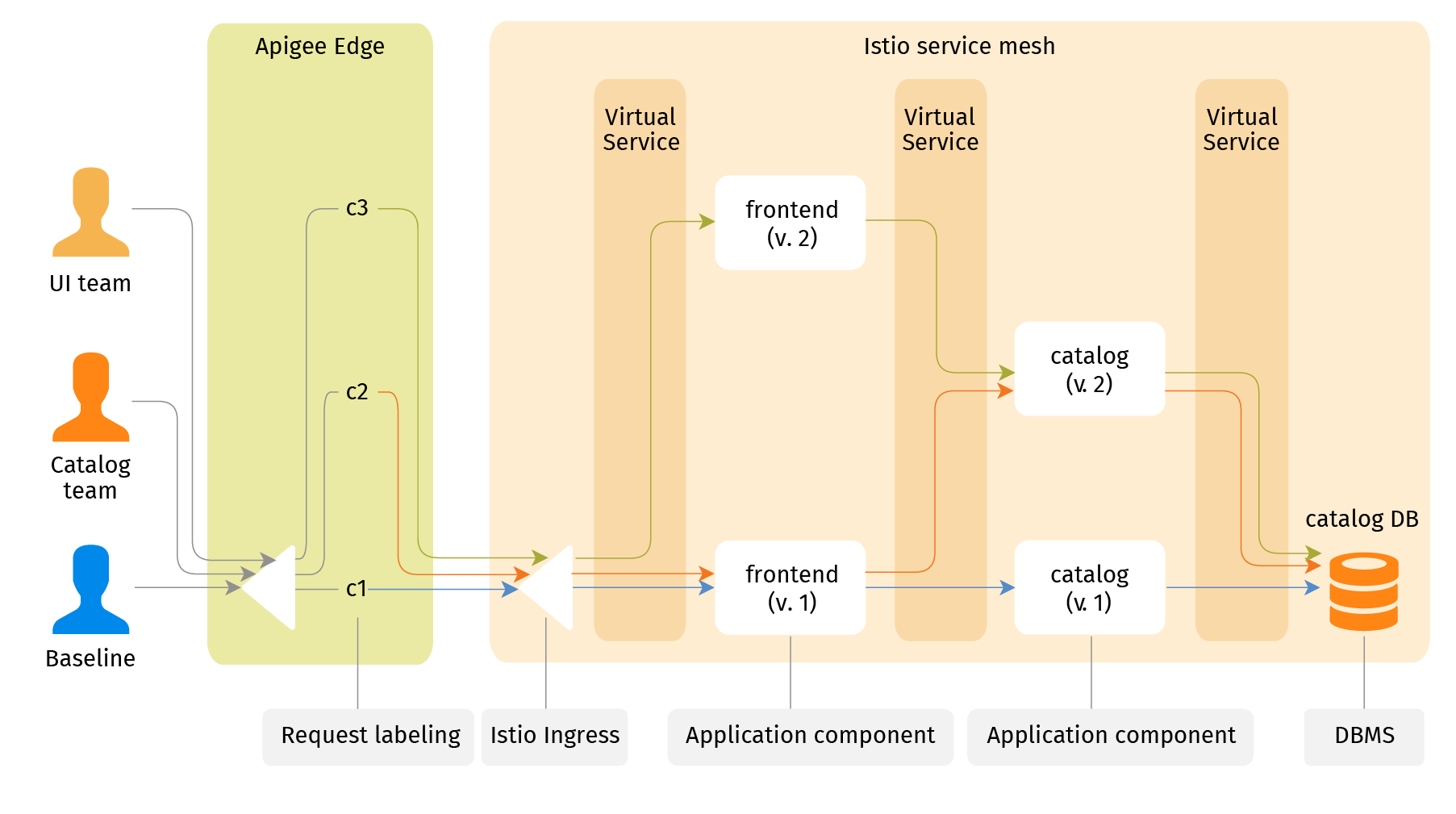
Still in production, I want to evaluate two new versions of the catalog service. This time I make two shallow clones of the production system - channels "a" and "b". The new versions of the catalog service are deployed to these new channels so the production baseline and the new channels are now different. The border proxy is configured to segregate two test groups of users, say 1% of the Australian user base each. It is then set to label requests from those two groups with the "a" and "b" channel labels. Now one test group sees the application with catalog version "a" and a second group with catalog version "b", while nothing is changed for the others. So I can measure conversion, retention, or whatever else using the convenient tools. The experimental channels may differ as little or as much from the baseline as desired. It could be either a different feature flag, or it could be a complete rewrite - both are fine.
Use case: development environment
Recalling the original problem, the application system in question is a distributed multi-component one. But its components are not independent microservices. They cannot be developed and tested in isolation. As a developer I need a complete application system as the environment for my component. Now I have it - a shallow clone of the shared baseline non-production deployment. Usually the baseline deployment follows the production one. Each development group has its own clone or several clones. From the cost perspective these clones are as much as the deployments by the group, usually a single component instance.
If several components are getting dependent features (for example if a UI improvement depends on a new catalog API feature) development teams may create their deployment channels in a chain - the catalog team clones the baseline (and deploys new catalog API component builds there) to make its working channel. The UI team in turn clones it and deploys new frontends. Of course it is more fragile than independent development. But sometimes it allows for shipping a business feature within one development sprint, while with an independent process it may take two or three.
Is it the silver bullet?
It may appear that this technique with service mesh and deployment channels solves most SDLC issues of real (imperfect) business server applications without the constraints of rigorous microservice architecture. Of course however, it comes with limitations:
- It requires sequential component release to production. Yes, one may have many deployment channels in production, undergoing evaluation, or testing. But eventually at most one channel becomes the new baseline serving the users by default and others become outdated. It is similar to a version control system such as Git - once a commit is pushed to the trunk branch, others have to rebase. Here we have a similar story - other components need to get fresh clones from the new baseline and deploy there. So these fresh channels may become the baseline later.
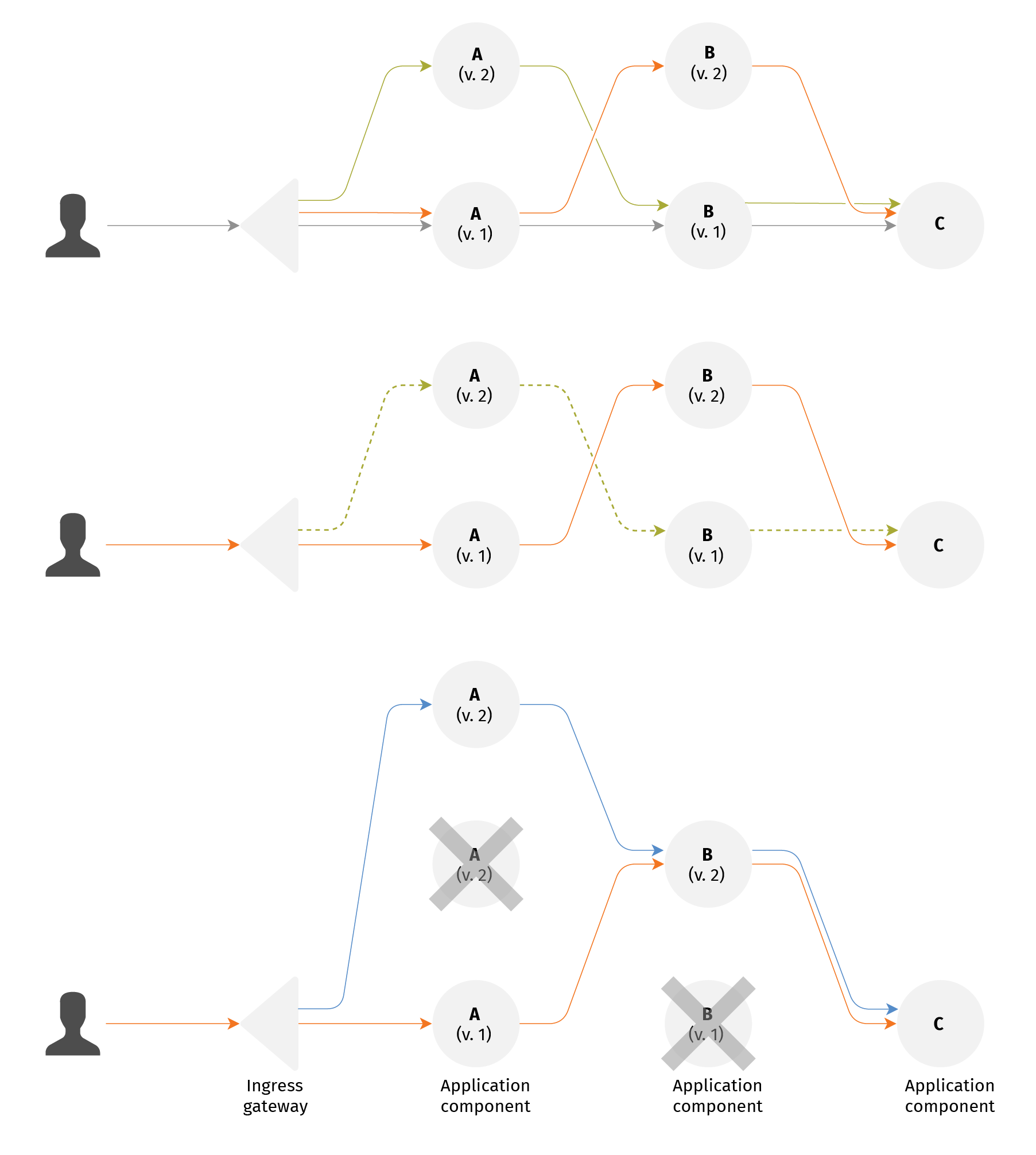
Two sequential releases with "rebase".
Microservice architecture doesn't have this limitation, each microservice can be released independently. It potentially lets development scale more - if a typical business feature can be confined to a single service. Or if individual microservices deliver new features to production quickly, another service can get the prerequisites for its improvement in a matter of days or even hours. - Service mesh technologies are relatively mature only for synchronous service-service communication by HTTP-based protocols and communication patterns such as REST, HTTP RPC, gRPC, or WebSockets. But modern multi-component application systems also actively embrace asynchronous communication by messaging. And service mesh implementations for messaging are still in their infancy.
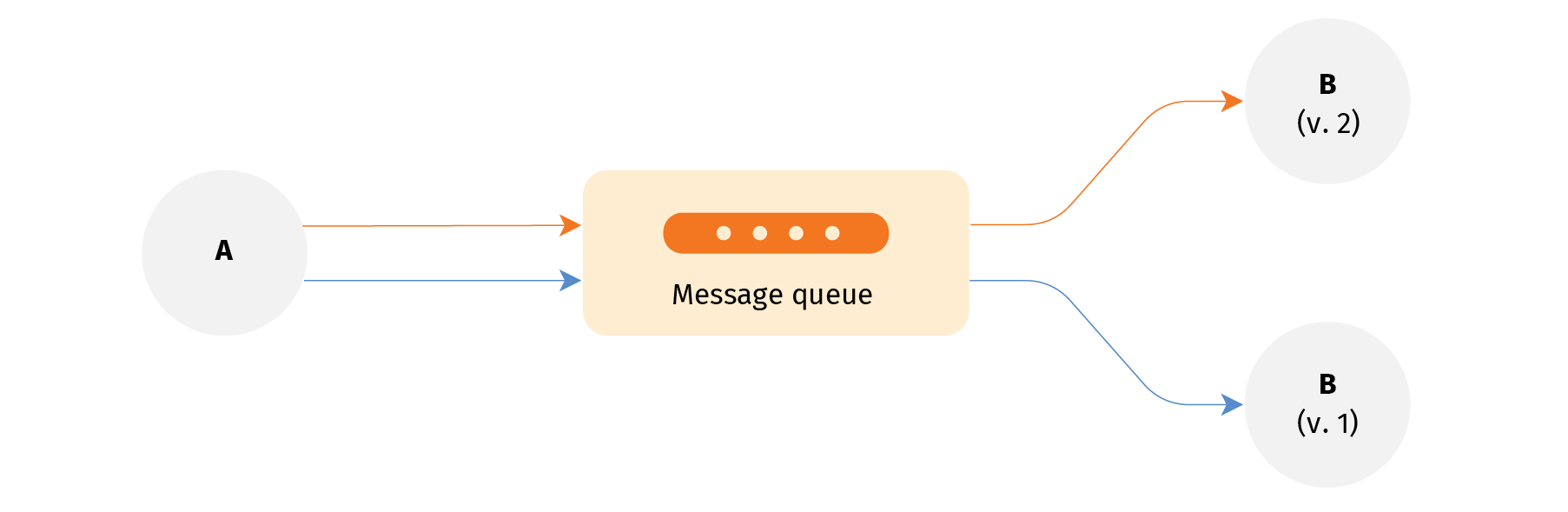
Message queue with writer for 2 channels and readers in 2 channels.
- State persistence is even more challenging. Istio can connect an application client to a DBMS server. But it cannot split the connection like it does for HTTP because for Istio a DBMS connection is an opaque TCP stream. One may argue that in a microservice architecture a DB is exclusive to its managing service and only the service accesses it directly. That's fine, but this managing service needs upgrades too. And likely the new version of the service needs its data to be useful.
However, the microservice architecture is not a panacea either. We saw in practice that if a business problem cannot be decomposed to a flat set of independent small sub-problems, the corresponding application system may be multi-component, but it will not adhere to a microservice architecture. It may be a conscientious choice - in the previous post we showed that it may be the right way to scale application development. Enforcing strict service isolation regardless that may lead to an over-complicated system and development inefficiency. In such (quite common) cases, it's better to accept the explicit system complexity and manage it by the right middleware (service mesh) and use patterns (deployment channels).