
Let’s face it — Oracle Endeca is an out-of-date e-commerce search technology solution. Endeca’s lack of personalization and support for omnichannel capabilities have been common problems for many large retailers, and the issues were not getting solved by ATG. We at Grid Dynamics have seen this first-hand, as we have assisted many large retailers in moving to a modern search engine solution outside Oracle ATG. We’ll outline the pain points of using Endeca, and then describe the journey to a modern search engine using a specific client’s migration to Solr as an example.
One of our large retail customers had used Endeca as its e-commerce search engine because it was a part of their Oracle ATG e-commerce platform, and was thought to be a powerful tool. Initially, Endeca performed fine, but as competitors started rolling out new, advanced search features, it began to suffer in comparison. Additionally, analytics showed that search user experience was poor, as many keywords had no search results. Endeca also wasn't able to support modern features such as personalization and visual search, which consumers now expect to see. Since we had already worked on search replatforming quite a few times for other retailers, we were a logical choice to help this retailer replatform as well. They believed that a new search platform would improve their product discovery experience, and raise their online conversion rates and revenue per conversion.
Our solution was to build them a new search engine with Solr, and integrate it with their existing ATG system, a process which was completed in just a few months. Their conversion rates increased by over 20%, and their revenue from search increased by 25% over a one year period, and other metrics improved as well. We have done similar work for quite a few large retailers, and while replatforming search to Solr is not a trivial process, the benefits can be substantial. This is our in-depth guide on what features modern e-commerce search should have, and how to acquire them via migration from Endeca to Solr.
Overview
Here are the topics that we cover in this post on building a customizable search engine:
- The features that customers and merchandisers need from a modern search and browse functionality.
- Why Solr is better suited than Endeca to meet these expectations.
- How to migrate from old, black-box platforms to cloud-deployed, open source search engines.
- The approximate results you can expect from replatforming off Endeca to the cloud.
- What comes next in the replatforming process.
State-of-the-art site search
Before we jump into the details of search engine migration, we would like to describe the capabilities of a high-quality search and browse user experience. These can be roughly divided into features that directly affect the customer experience and other features that improve the merchandising team’s efficiency. We’ll start by looking at how search engines should understand a shopper’s intent.
How to recognize user intent
A high-quality customer search engine needs to understand queries at a deep, semantic level, so that it can show the most relevant results to users. We identified five major features that a search engine should provide to be successful:
- Natural language understanding (NLU): True NLU is hard to achieve, but fortunately, there are a plethora of powerful open source libraries to make it easier. Another positive is that the retail domain has its own specifics, which makes it easier to identify and process "natural language" queries. For example, if a customer searches for a “new blue cocktail dress on sale under $100”, each of the unique terms should be mapped to different attributes. “New” should be mapped to the newness attribute of products or a special category with new arrivals, “on sale” to a special attribute or category of on sale products, and “under $100” to the price of products, returning search results of products less than $100.
- Concept search: The role of the search engine is to understand the semantics of every word in each query so that they are mapped to the correct attributes. This can be difficult, due to the multiple meanings of certain words: for example, in the phrases “black dress shoes” and “little black dress”, “dress” does not mean the same thing. Thankfully, there is technology out there that can understand these semantics. We have previously implemented such a technology on open source search engines for our clients. In fact, we have even written about this very subject.
- Dynamic adjustments for improved relevancy in real time: Each query must be treated differently based on which products are in stock and what the retailer carries. If a customer’s query is too specific, the engine might not understand certain terms with high confidence. Therefore, the strictest mapping would only give the customer two results from the entire catalog. It makes sense to return more products, even if some do not fully correspond to all of the terms in the query. These decisions may be configured as general policies of the engine, with the final decision-making left to the search engine based on the current environment.
- Understanding of retail language domain: First and foremost, this means that the search engine should be configured with retail-specific linguistics, synonyms, hyponyms, etc. We can also use techniques to automatically discover popular terms based on customer behavior -- what terms people commonly use to discover certain products. Finally, the search engine should know how to handle a situation where a customer searches for an item and no results appear. Instead of showing customers a blank page, search engines should provide similar results or recommend other relevant products.
- Real-time view of omnichannel inventory, availability, and pricing: Nothing is more frustrating to users than finding a product on a search page, going to the product page, choosing the right size and color, and then finding out that this specific combination (SKU) is not available. What’s even worse is when shoppers see outdated prices and promotions on the search page, which can lead to the shoppers seeing different prices during checkout, potentially resulting in legal issues. To avoid this, the search engine should be scalable enough to maintain online and in-store catalogs, and have up-to-date information about the availability and price for all SKUs. To learn more about inventory replatforming, check out our blog post here.
Getting personalized results from search engines
The most important capability that modern customers expect from their search experience is personalized results. We identified a handful of features that a search engine should be able provide, as shown below. For our purposes, personalized boosting also contains segmentation and recommendation boosting.
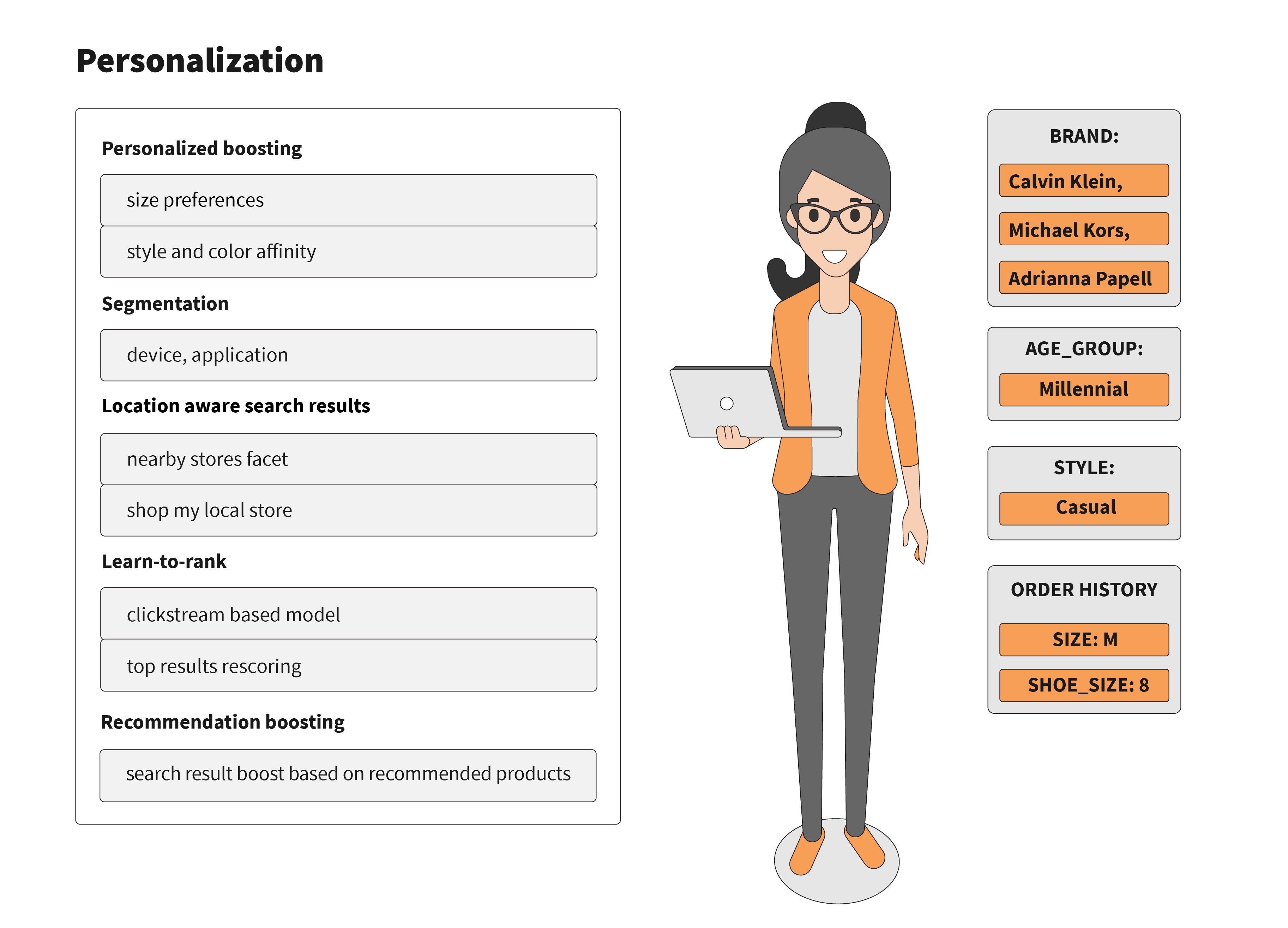
When it comes to search, personalized boosting is less about showing or hiding certain products, and more about the correct ordering of search results. To accomplish this, a search service should understand the customer profile on an individual or segment level, and carry additional, hidden information about each product to boost relevant products, and bury irrelevant ones. A side effect of this level of personalization is an increased need for scalability and high performance. This is because personalized search results are very difficult to cache, which leads to significantly more requests coming from the CDN to the origin.
Making things more complex, the search engine frequently deals with situations when many products are equally relevant for the user’s query. Therefore, it has to apply additional signals to decide what products to place on the first few pages. These signals can be raw business signals like newness, popularity, or margin, or some combination. However, such an approach lacks personalization; it is much more powerful to use customer behavior to make personalized boosting decisions. Learn-to-rank models can be trained with historical customer-product engagement data and then applied to the re-ranking of top results to achieve a personalized product ranking.

There are many other innovative features that provide a great product discovery experience, which are adjacent to the core search engine. These features include visual search, visual recommendations (“more like this”), voice search, conversational search, and more. Having a solid, open source search engine foundation enables the use of these features, and we’ll explore them further in other articles.
What features are necessary for merchandisers
Besides providing an excellent customer experience, modern search engines need to help merchandisers be more effective and efficient. Some important search engine features for merchandisers are shown in this image:
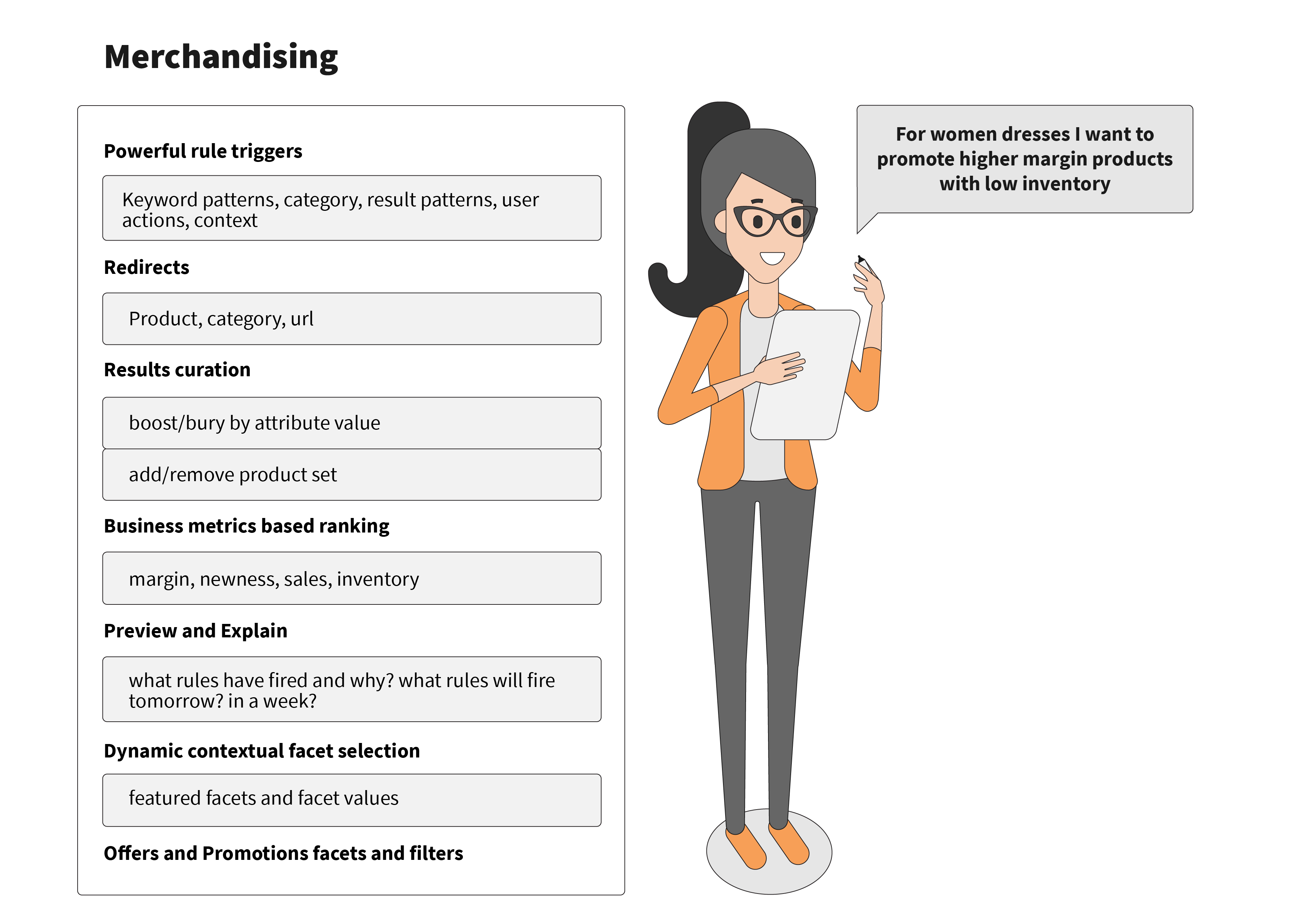
Rules should support powerful and flexible triggering mechanisms. These include: query keyword patterns, categories, result patterns with a specific case of zero results, customer actions, and the overall context of search interaction. The supported actions typically include redirects, selection of facets, and boost and bury rules for products having particular attributes. These actions result in set-wide rules of ordering search results by natural relevancy or by product attributes.
At any given time, a search engine should be able to explain exactly why a particular product either matched or didn’t match the query, and why a matched product was ranked in a particular way. Essentially, the rules should be easily explainable and transparent. Also, when there is a change in the search configuration or the business rules, a merchandising manager should be able to preview the effect of the change on the actual results before applying it to the production environment. This enables merchandisers to halt upcoming changes if the results appear to be negative.
Analytics are highly important features for merchandisers. The search engine should provide information about low-performing products, low-performing queries, and overexposed and underexposed products (products that appear in search results too often or too rarely). Additionally, the engine should be smart enough to offer an explanation on why certain behaviors are observed. For example, certain words in a query may be unrecognized, leading to poor performance. Other products may lack certain attributes that hurt their appearance and relevancy. Or, most typically, business rules may be configured in such a way that prevents showing otherwise relevant products to customers in some cases. With this information, merchandising managers and other business users should be able to quickly find the root causes of their problems, and adjust the search configuration.
Last but not least, a modern search engine should scale to omnichannel catalog sizes and traffic, provide high performance, support cloud deployment, and maintain and operate in production easily. Now, let’s take a closer look at the available search engine technology options.
What are the current search technology options
If we compare the requirements of the modern e-commerce search engine with what Endeca provides, we can see that it does not stack up. Endeca is an old but respectable search engine, and, when configured correctly, it can still provide decent relevancy — it was a solid technology choice five years ago. However, it lacks features that modern shoppers and retailers need.
Oracle hasn't substantially upgraded Endeca in years, which has led to a widening gap between product functionality and market expectations. Let’s consider five major issues with Endeca:
- It doesn’t support omnichannel capabilities: The increased size of omnichannel catalogs makes them difficult to scale. The combination of increased time required to index catalog updates, the growing size of the index, and slow search makes Endeca challenging to operate. It’s just not scalable for the modern Internet.
- Endeca can’t handle near real-time inventory, availability, pricing, or promotions updates. With new omnichannel requirements, retailers need to keep the search index consistent and updated every several minutes, and Endeca is not able to provide this level of support.
- Endeca is not a cloud-friendly application: It doesn’t support a cloud deployment model on modern cloud providers, including AWS, Google Cloud, or Microsoft Azure.
- The mechanism Endeca uses for boosting and burying doesn’t support personalization.
- As a part of the ATG suite, Endeca has high ownership and maintenance costs.
Since Endeca is a closed source product that is notoriously “black-box”, any customization is cost prohibitive or even impossible. Endeca is therefore not a good choice for modern retailers that need to provide a state-of-the-art search experience to their customers online and in-store.
Many large e-commerce companies are therefore choosing to use open source stacks, like Solr or Elasticsearch. While most retail implementations are currently on Solr, we consider both of these base platforms more or less equal in their capabilities with slight differences. In general, Solr is more customizable, and can better support near real-time inventory and pricing updates. Elasticsearch, on the other hand, is an easier option to begin with. We are going to discuss a detailed comparison of Solr and Elasticsearch for e-commerce use cases in a separate blog post in the near future. For the purpose of this post, however, we will focus on Solr as the replacement for Endeca.
While Solr is a great foundational technology, it provides only general-purpose search capabilities. In order to build e-commerce functionality, it should be enhanced and customized. The good news is that such customizations are not only feasible, but can be done relatively quickly and inexpensively. We have already written about some customizations on our blog. Please reach out to us if you want to know more about the specific customizations. In the meantime, let’s discuss how to approach replacing Endeca with Solr in a way that doesn’t affect day-to-day business while the migration is taking place.
Our migration approach
Before diving into the details below, here’s a brief roadmap of the migration process:
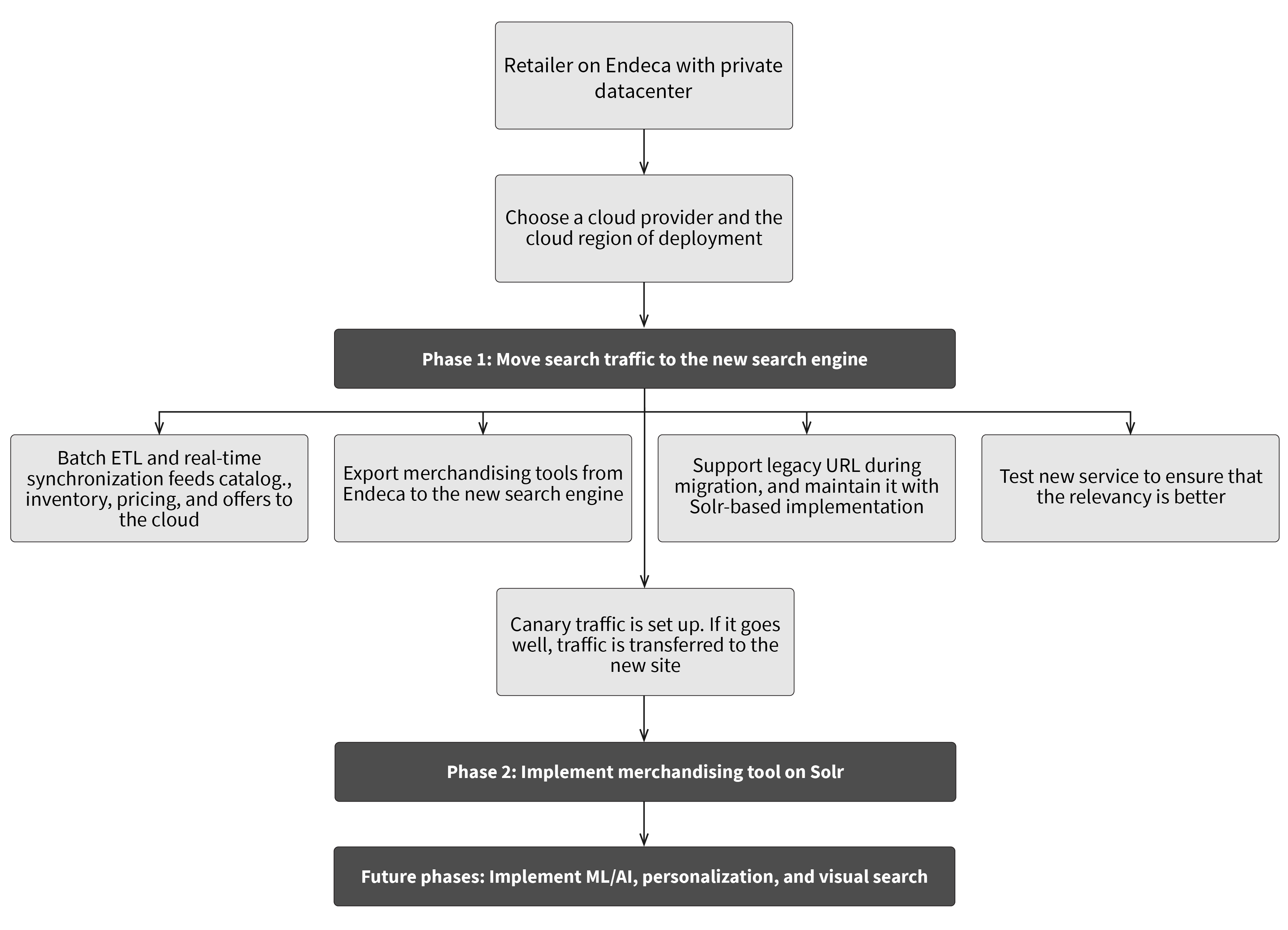
For the purposes of this discussion, let's assume that before the migration of search functionality, a retailer uses an ATG platform with Endeca deployed in a private datacenter, and that the new search engine is based on Solr. The goal of the first (and main) phase of migration is to get production search traffic from Endeca to the new search engine in the cloud, without negatively affecting customer experience and business KPIs. To minimize the time of the first phase, merchandising managers can keep using the Endeca experience manager, and only move the retailer to the new search and browse customer experience configuration tool in the second phase. Some advanced functionality, like ML/AI, personalization, conversational search, and visual search, can also be pushed to the future phases, once the foundation and core search is ready. However, some features that were not possible in Endeca - an omnichannel catalog, store-level inventory, and near real-time inventory updates - can be implemented in the first phase as a part of the core search engine driving immediate business value.
One of the first decisions in replatforming is the choice of the cloud provider and the regions where the new service will be deployed. Cloud infrastructure setup is an interesting topic by itself, and will be the topic of another future blog post. In any case, the cloud setup for a search service is not too difficult, as search services provide just read-only functionality, and don’t store PCI or PII data. We assume that customer traffic will go through the ATG platform, and only then get to the search service. So we’ll need to take into account latency between the datacenter and the cloud region when choosing the region, as seen in the infographic below:
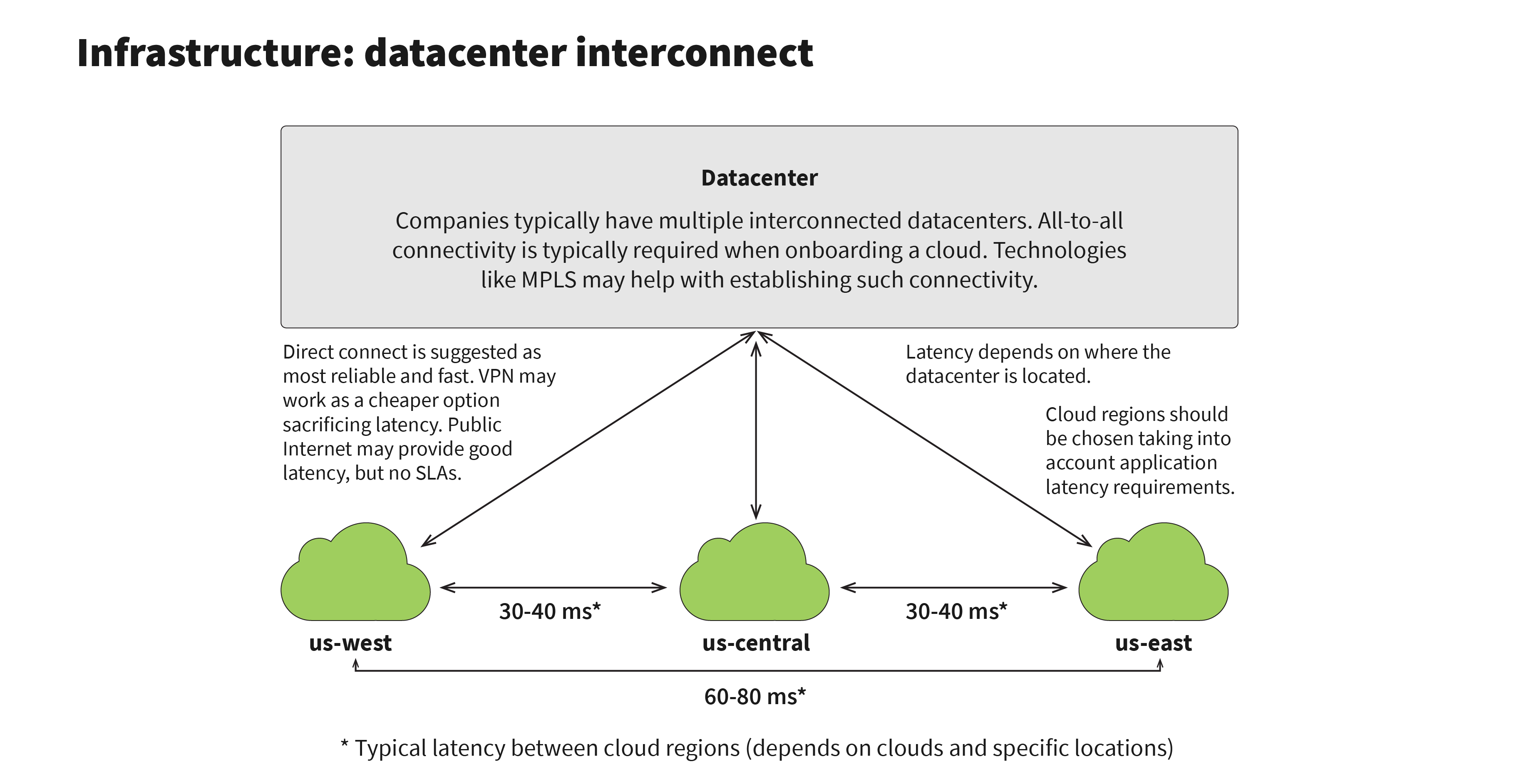
To reduce latency, if current datacenters are in the east coast, cloud regions will also need to be in the east coast. If current datacenters are geo-distributed and working in active-active mode, so will the cloud setup. If the networking is configured correctly, the overhead for latency will not exceed 10-20 ms, which will be compensated by the lower latency of Solr-based search service compared to Endeca.
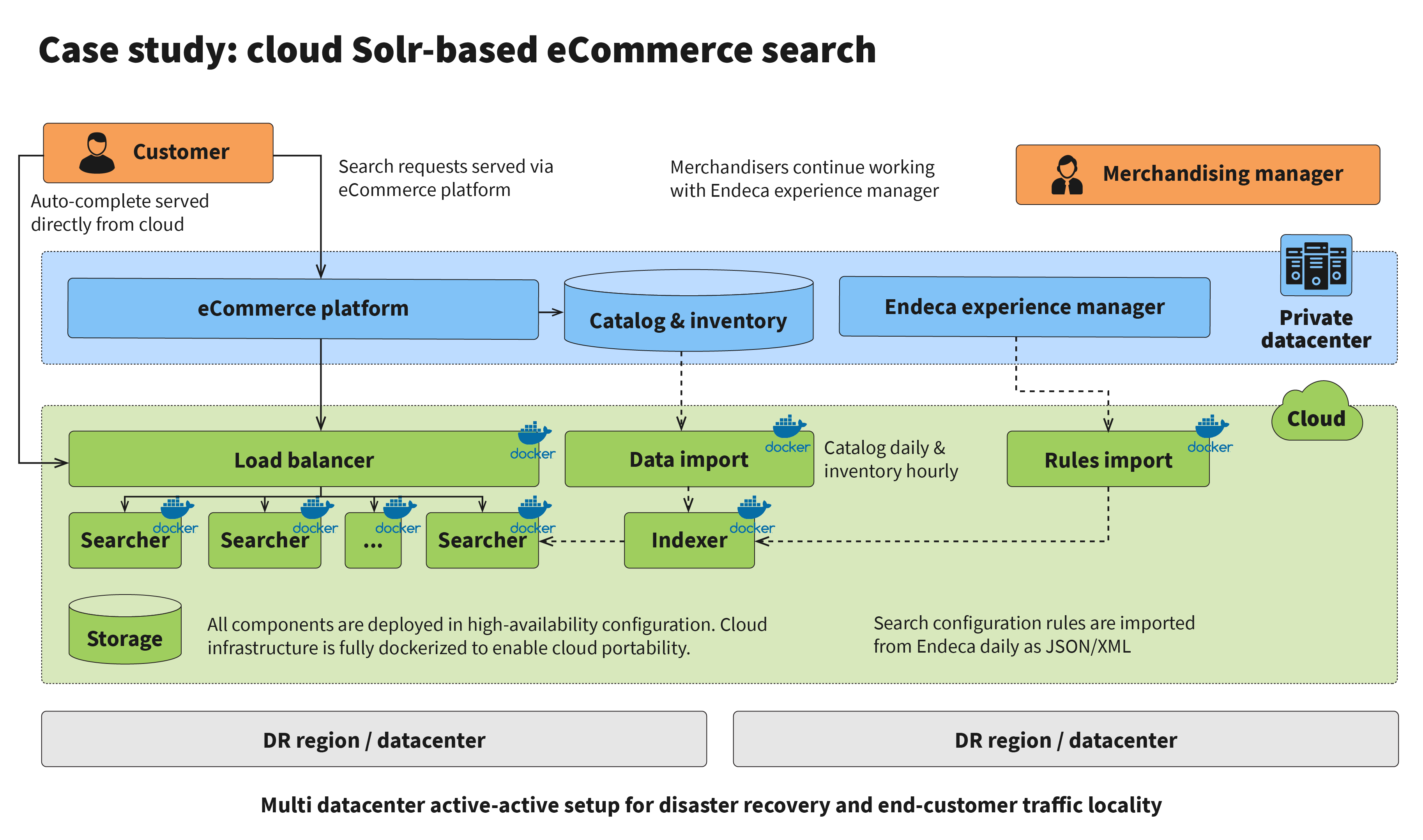
Once the cloud infrastructure is set up, development of the new service can start. In parallel with development of the new search service, integration logic in ATG needs to be developed to call the new service instead of Endeca. Batch ETL jobs and real-time synchronization mechanisms must be set up to feed the catalog, inventory, pricing, offers, and promotions to the search engine in the cloud. Since similar batch jobs should already exist for Endeca, they can be reused. At this stage, a separate synchronization mechanism should be implemented to export merchandising rules from the Endeca experience manager and import them to the new search engine. With enough knowledge of Solr and understanding of the format of the rules, this conversion can be implemented relatively easily. As a side note, changing from Solr to Elasticsearch will not change the architecture significantly: the indexing process will be most affected. The new architecture of the legacy ATG platform working with the new search engine can be seen in the following infographic:
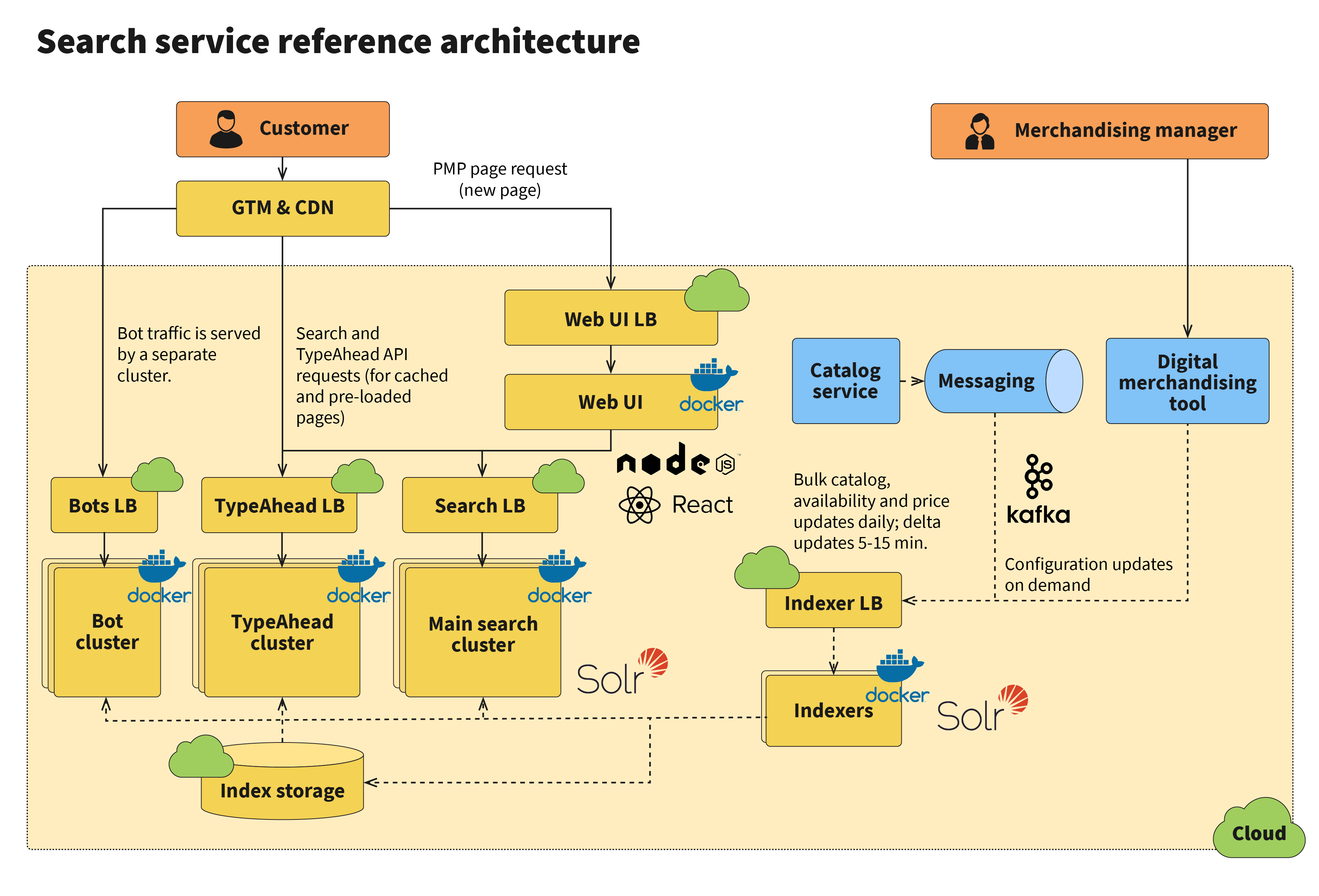
Even if the web UI layer has already migrated to the cloud, the architecture will look very similar, just with quicker catalog and inventory updates due to the presence of streaming with Kafka:
Before switching production traffic to the new service, two important actions must be taken . First, Endeca has a very specific URL structure for search and browse pages, so changing the structure at this point will negatively affect SEO. Thus, the legacy URL structure must be supported while the migration is underway, and Solr-based implementation needs to be expanded to maintain this structure. Second, the new service will need to be extensively tested for search relevance to ensure consistent or better customer experience after the switch. This is accomplished in several ways:
- Automated relevancy testing: The development and QA team can implement a set of tests to check correlation of new and old search results.
- In-house exploratory testing: The top 100 search queries can be selected based on historical search logs, and then checked by business users and QA team to ensure relevancy.
- Crowd exploratory testing: Crowd outsourcing services can be used to test the relevancy of long tail queries for the top 1000 or 10000 queries based on search history.
To make relevancy testing and tuning easier, we implement a smart test analytics tool that collects advanced metrics from the search engine, explores current catalog and product attributes, and helps identify poorly performing products or search queries. At this point, search configuration analysts catch most of the issues related to the lack of linguistics configuration (synonyms, hyponyms) and mis-attributed products. Advanced tools for product attribution and self-correction can be implemented later in the journey so the first phase won’t be delayed.
Once the search tuning is done, canary traffic can be sent to the new service. At this point, site analytics tools should be set up properly to measure the effect of the canary release. If the canary release goes well, which it almost always does when tuning is done correctly, full traffic can be switched to the new search service. The whole process end-to-end usually takes several months from inception to production.
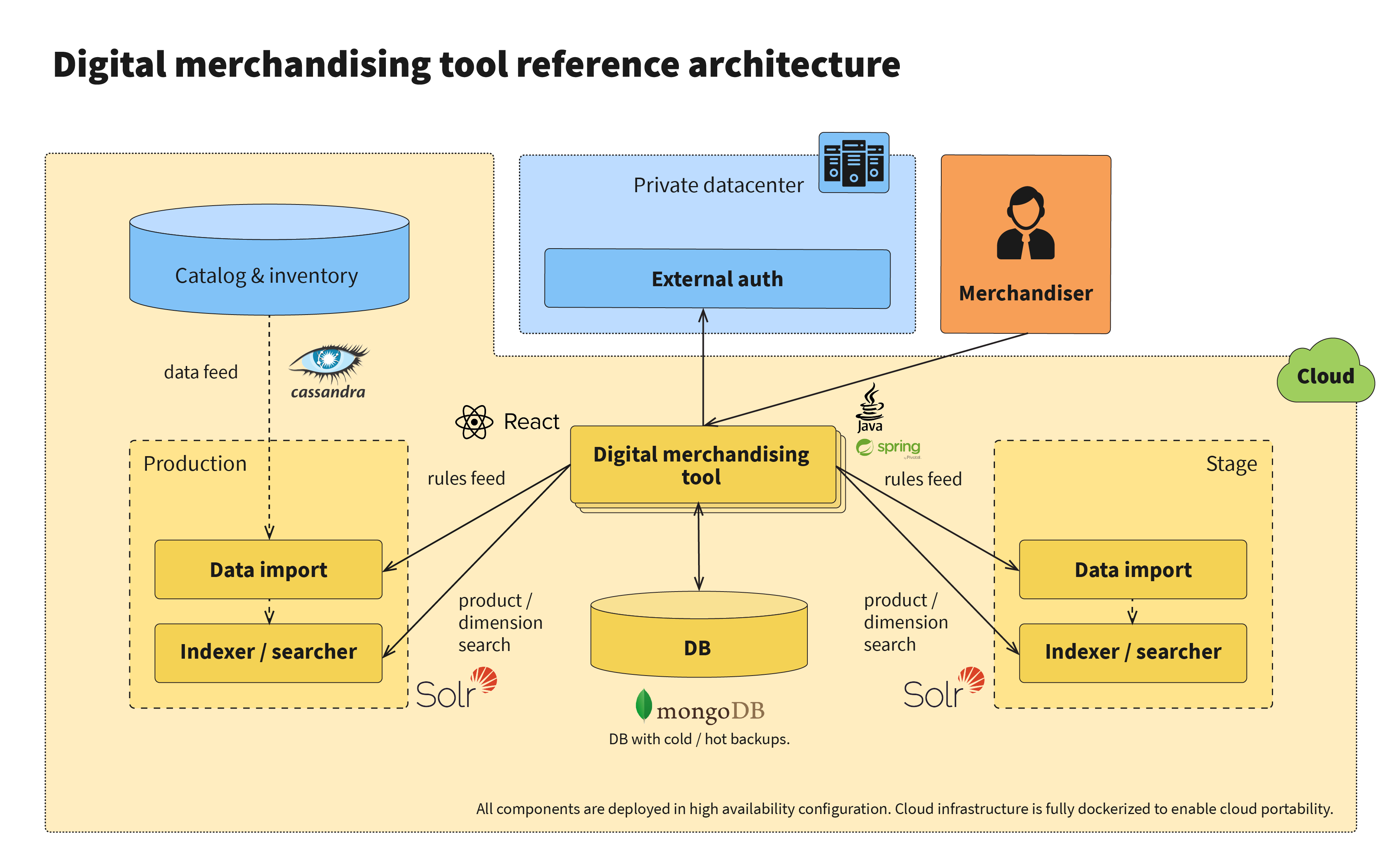
During the next phase of the replatforming, a merchandising tool can be implemented, allowing business users to switch from the Endeca experience manager to the new tool, with the reference architecture shown below. However, this is a separate part of the replatforming, and is not considered when looking at the results below.
Results
Based on our experience, the first phase of search migration can bring improvements in a number of areas.
First, you should see conversion rates increase. This number heavily depends on the quality of initial configuration and the goal of migration. If the initial configuration was heavily configured with business rules, and the goal of the new service is to provide search results as close as possible to the original search, the initial increase in conversion is likely to be small. Otherwise, we saw search session conversion rates increase by 20% or more. In any case, conversion rates are likely to increase after more advanced functionality is implemented.
Second, the overall revenue from search, as well as the search revenue per visit, may increase due to new omnichannel features and the support of omnichannel inventory, availability, and pricing. In some of our engagements, we saw revenue from search increasing by 25%, and search revenue per visit increasing by 10% over a one year period.
Other important metrics that should improve after migration include the percentage of zero result queries, engagement with zero result queries, performance of search and browse pages, and infrastructure costs due to auto-scaling for peak usage periods such as the holiday season.
Last but not least, the migration of the core search engine will unlock further innovation in the product discovery space. Implementing personalization, conversational search, visual search, visual recommendations, “more like this”, and other features will be easier on a customizable and extendable open-source foundation. Search may also be a low-risk entry point to the cloud for the enterprise.
What’s next: Further steps in the replatforming process
Many retailers are struggling to transition from legacy platforms to the cloud. Replatforming is a large, challenging task, and it can be difficult to even get the process underway. For merchandising-focused retailers and department stores with large catalogs, a strong place to start is with the search and browse functionality. After all, if a customer can’t find the right product, they will not be able to buy it, no matter how well the purchasing experience works. Another benefit to replatforming search and browse functionality is that there are several powerful, open source search engines that may serve as a starting point for implementation. Finally, it’s a good pilot for cloud migration because it is read-only, non-transactional, and doesn’t contain PII or PCI data.
In our experience, search-to-cloud implementation projects can be accomplished within several months, have low risk, and usually remain within a reasonable budget. The migration of search and browse to a modern open source stack not only improves customer experience, which leads to higher conversion rates and revenue, but also opens a path to innovation and differentiation in the product discovery space. Additionally, it give teams an opportunity to embrace digital transformation and nurture digital culture with a public cloud, continuous delivery, and open source. Replatforming search and browse is not easy, but it’s a short process, it’s effective, and we’ve laid out all the details here to make it even simpler.
In our next post, we’ll discuss building a microservices platform in the cloud. Such a foundational platform is required to migrate more services to the cloud. This increases the efficiency and predictability of migration, and allows the managing of large systems consisting of hundreds of services and components. If you have any questions about replatforming search off of Endeca, or want us to help in your own replatforming, please contact us!