
How we built a conversational AI for ordering flowers over Amazon Alexa or Google Home

The capabilities of speech recognition and natural language processing are rapidly increasing and now allow people to regularly engage with AI programs in human-like conversations. This opens the doors for an entirely new generation of smart devices and use cases. One of the most promising is voice-powered retail shopping.
To demonstrate the potential of conversational AI for commerce, Grid Dynamics Labs has developed a voice assistant “Flower Genie” for the Amazon Alexa and Google Home platforms. Flower Genie allows customers to select and order flower bouquets from an online catalog using voice-based interactions. Grid Dynamics Labs has already implemented this technology with a large flower seller to create a platform that is enterprise ready and currently being put into production.
In this post we discuss how we built the conversational AI system for ordering flowers and what lessons we learned while working on different aspects of the project including conversation design, data collection, natural language processing, testing and certification.

An overview of the dialog design process
Our voice system allows the customer to find a bouquet of flowers according to various preferred criteria and then order it by voice. This voice compatibility needs to be able to work across various devices including Amazon Alexa, Google Home, or a smartphone.
The design of a dialogue flow for such a system has to take many factors into consideration, including:
- Understanding user experience - This involved working with domain experts and designers who have a strong understanding of user needs, supported by research into user statistics and analysis of rival businesses.
- Data analysis - This allowed us to understand what we could expect from users, and what technologies we would need to make the whole voice system work. Although, we didn’t have a database of real conversations to build from, we used all the available data we could find: web searches, customer support logs, Amazon QA, etc. However, many of use-cases can only be clarified during testing with real users.
- Existing business processes and APIs - Our voice application needs to communicate with existing back-end systems, which are usually designed for web and mobile channels and may not work that well for voice systems.
- Conversation design rules - There are many ready-to-use rules and design guidelines for voice systems that can help achieve a good user experience as well as meet the certification requirements of Amazon and Google. We will discuss this further later in this post.
Generally, the conversation can be logically represented by the following stages:
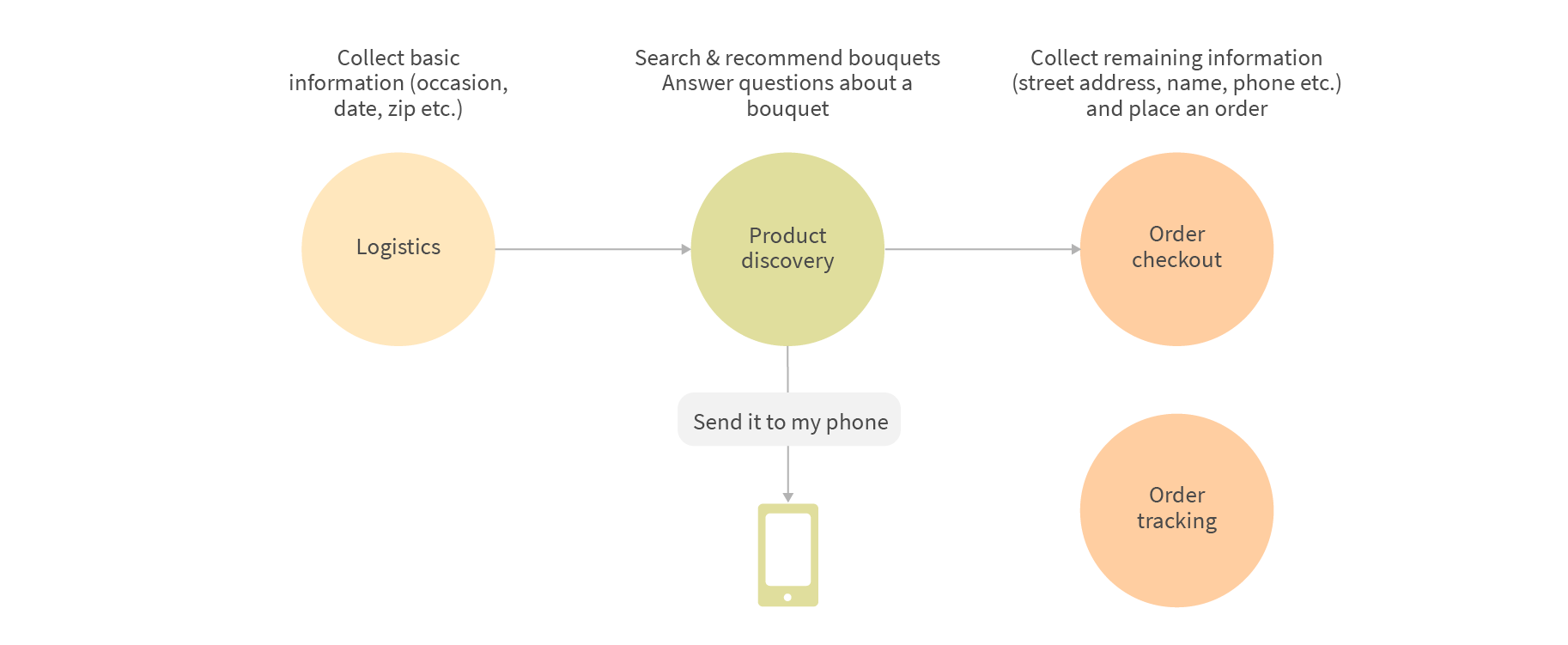
During the Logistics stage we need to understand what user wants, for example the type of bouquet they’re looking for and the occasion. We also need to collect basic delivery information to determine what products are available for the desired date and location.
The Product Discovery phase is a user-initiated process, as opposed to the system-initiated Logistics phase. Basically, the users are looking for bouquets according to their requirements (e.g. "Do you have a classic bouquet of roses and lilies", "I don’t need a vase", "I want something cheaper"), as well as asking clarifying questions about the products (e.g. "How many roses in this bouquet?", "Does it come with a vase?", "Do they come bloomed when delivered?"). The goal of this phase is for the system to help users find a suitable product among the various options. The presence of the Alexa screen also plays an important role here - no user will want to purchase a bouquet if they cannot see how it looks first - so the generation of devices that include displays enables additional convenient shopping experiences.
In some cases, the users will not complete the transaction during this session, but rather decide to save the information for later processing. To support this useful scenario, the user is provided with an option to send product information somewhere - usually, a smartphone, by saying “please send it to my phone”. This allows the user to bookmark some of the options that they’ve found, for instance, if they want to view them later on another device, or share them with other people.
The last phase is the Order Checkout. At this stage, we need to collect the remaining information like the full street address, recipient’s name, phone. Although this step seems straightforward, in reality it is a complex part in a conversational system. Speech-to-text systems still struggle with reliable recognition of such entities, and particularly people’s names which can be literally anything. The real humans suffer from a similar problem - it’s often hard to recognize a name that you’ve never heard before, isn’t it?
Transactions are processed by Amazon Pay or Google Pay, the customers just need to confirm the order by voice ("Do you want to place an order using Flower Genie?" - "Yes") to pay using payment details pre-configured in their Amazon or Google account. But in order to use a voice purchase, the customer must manually enable it for a particular skill, and also optionally enable a four-digit voice code to protect against unwanted orders.
The customers can also track their orders at any time during the conversation by saying: “What is the status of my order with a bouquet of red roses?”
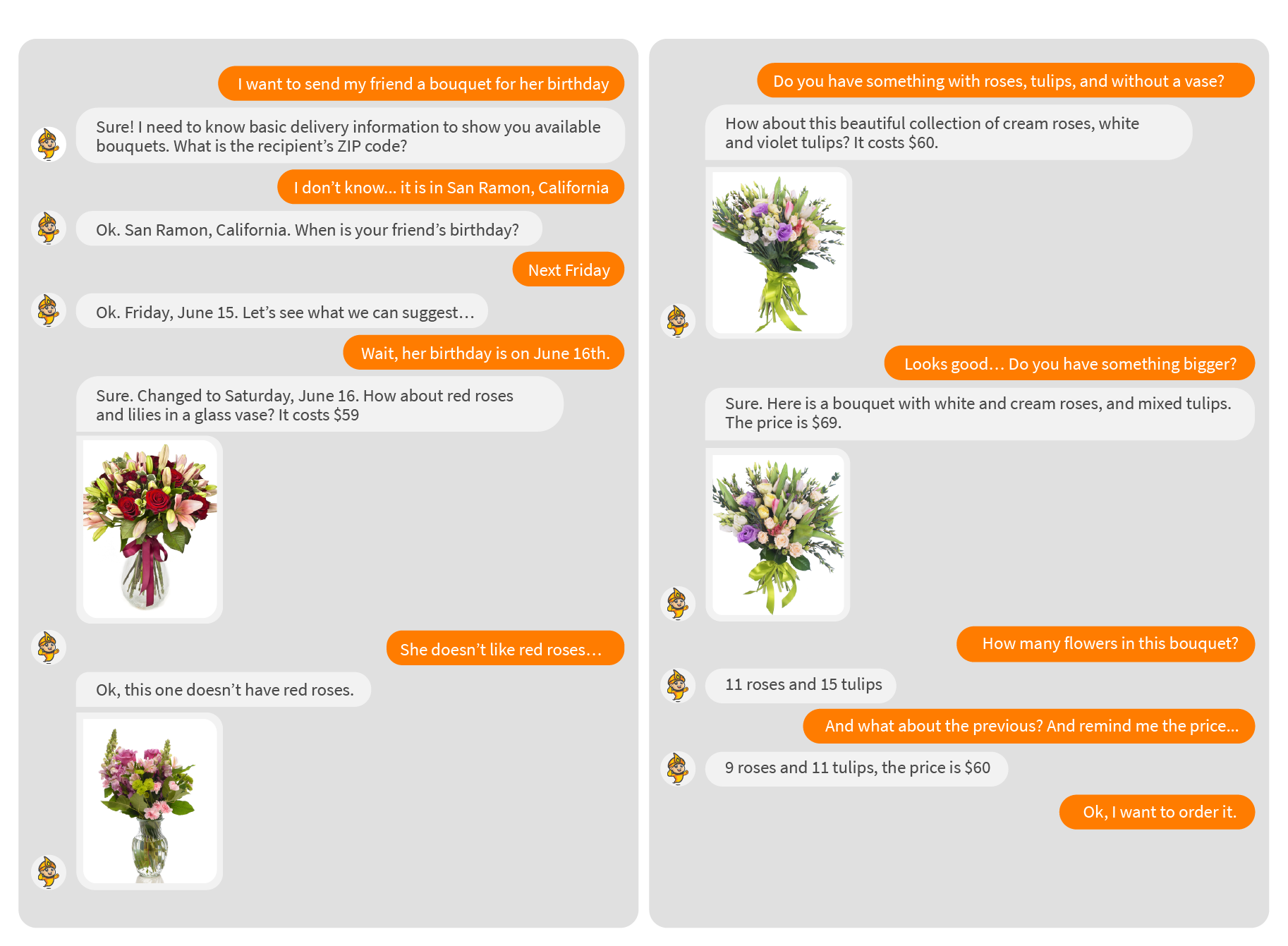
Let’s visualize a plausible conversation between a user and the voice system:
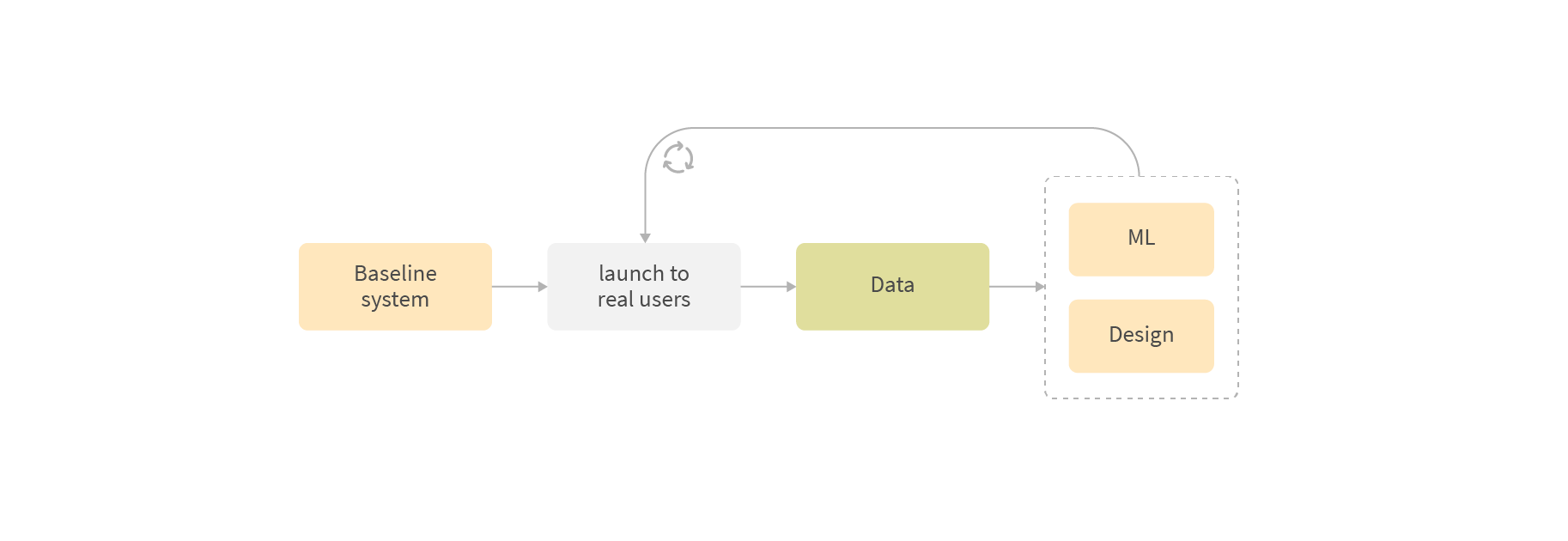
The Circle of Data, Design, and Testing
The development process for voice systems relies heavily on the feedback from how real users interact with the system. The lifecycle of the project after the initial launch includes three stages: (a) observe what users are doing with the system; (b) collect & analyze the behavioral data; and (c) improve the UX and retrain the models. Then rinse and repeat. It’s important to realize that the quality of your conversation design is just as important as the quality of your models. These two aspects are dependent on each other where the data is key for both, like in any ML-based system.
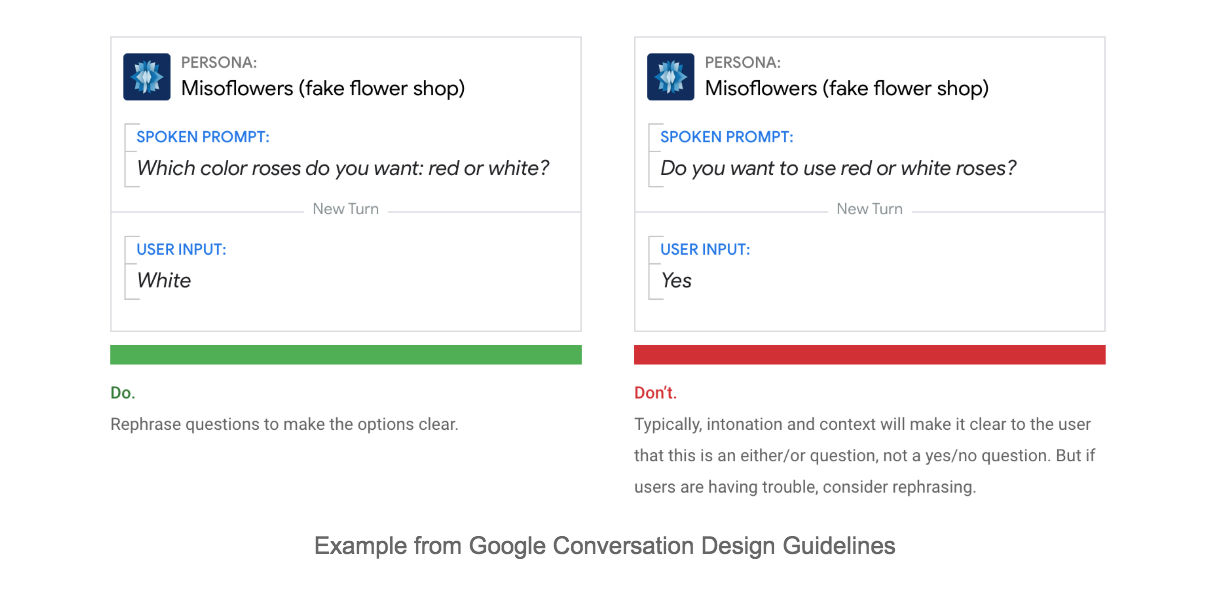
Human language is complex, and even simple conversation consists of many components that need to be considered during the development in order to build conversations that are natural and intuitive for users. That’s where knowledge of conversation design helps, in order to be able to:
- Understand how to build natural and intuitive experiences for different device types: voice-only, voice-first with display, smartphone.
- Take into consideration voice interface constraints: “voice” is an efficient input modality, but “speech” is inefficient in many cases, and we need to take care of the design that minimizes the cognitive load on the human brain.
- Pass Amazon Alexa and Google Assistant’s certification which means following their design guidelines.
We cannot overstate the importance of real conversations rather than assumptions of what users will ask, and how. Given the enormous variation in how people think and speak, you can bet your house that they will always surprise you! Let’s say you want to design a conversation to allow user to specify a delivery date upfront, and then change it anytime during the order. At first glance this doesn’t seem difficult as you expect to hear phrases like “please deliver the bouquet next Friday”. But you then find yourself facing real life situations where a user for example asks:
- “If I order today, is it possible to deliver tomorrow?”
- or “Can I order flowers now and have them delivered on the 26th? My wedding is on the 29th and I don’t want them coming too early...”
And these are actually not rare examples. Here the user has provided multiple dates and its difficult to determine which one is the desired delivery date. In addition, the user wants to know whether it is possible or not, rather than just specifying that they want to change the date. ML can solve all these cases, as long as you understand that it’s a part of the training.
Another example of surprises for the system that you should expect from users is the so-called “uncooperative behavior”, when users stray from the happy path, for instance:
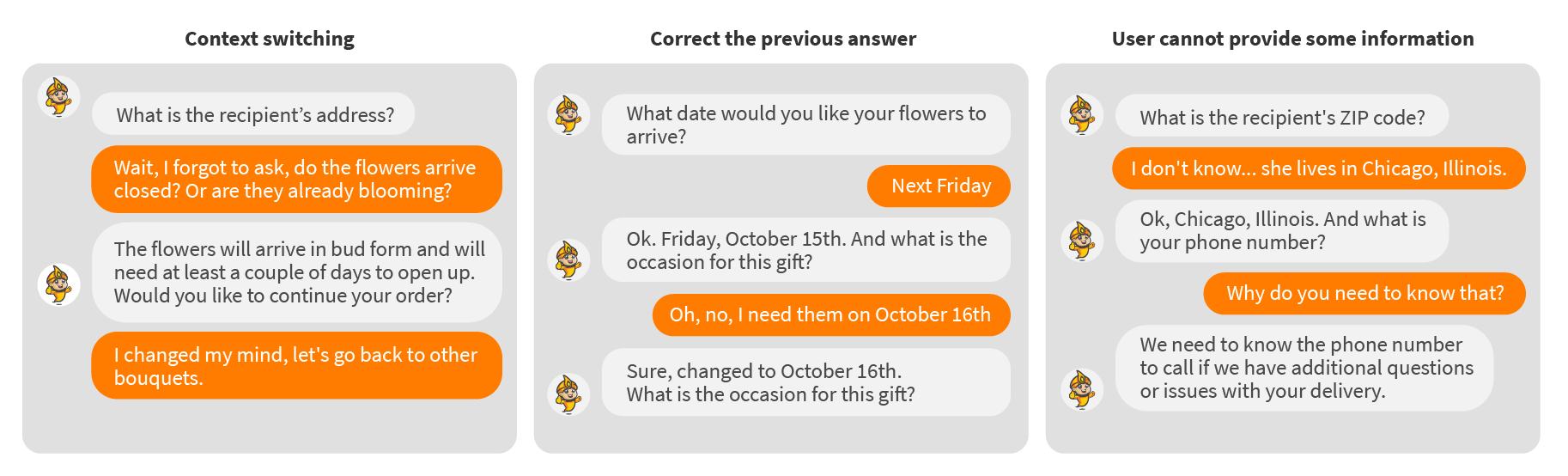
Here are some useful tips based on our experiences:
- Learn Conversation Design and ask UX and domain experts to help design the conversations. There are many guidelines, books, and articles from people who have already faced many conversational AI challenges and have developed ready-to-use recipes to overcome them.
- Test with real users and learn from this data. Testing with only ten people will give you results biased to those individuals, so only crowd testing can tell you the real quality of the system and identify any problems with it.
- If you are building the dataset from scratch, try to start with a simple prototype, collect the data using it, analyze, and only then work on more advanced solutions.
Conversation design is a pretty broad topic for this post but it’s a must-have to build good UX. There is very helpful design guidelines from Amazon and Google, you can find the links at the end of this post.
General architecture of the system
Although recent academic research is moving towards fully ML solutions, when everything is solved using end-to-end models, we found that hybrid (ML with rules) approaches are still the best starting option for goal-oriented conversational AI. At the same time, the progress of Deep Learning in NLP, especially with the rise of Transformers, allows solving more and more tasks using machine learning. This is important because rule-based implementations show that it’s very difficult to solve a range of context-aware tasks even for small systems. We believe that the next generation of goal-oriented conversational AI systems will be more end-to-end, powered by transfer learning and unsupervised approaches, but easily controllable by business rules where needed.
For this project we used a framework developed by Grid Dynamics Labs during our previous projects, that already handles various conversational features including context switching, conditional slots, explicit and implicit confirmation, validation, and also allows writing multiple dialog agents which can be easily plugged-in to the system. In addition, it meets the following requirements for our project:
- It should be built using open-source technologies.
- It should be a cross-platform system that can support a wide range of channels including Amazon Alexa and Google Home, extendable to address more channels in the future.
- It should be multi-modal, i.e. supporting voice-only devices, devices with a display, and smartphones.
At the core, the system consists of the following components: Natural Language Understanding (NLU), Dialog Manager, Dialog Agents, and Natural Language Generation (NLG). The human utterance first passes through NLU module to be converted to machine-readable semantics. The Dialog Manager and Agents can then fulfill the request and predict the next dialogue step. The enriched response is then converted back to conversational form through NLG module.
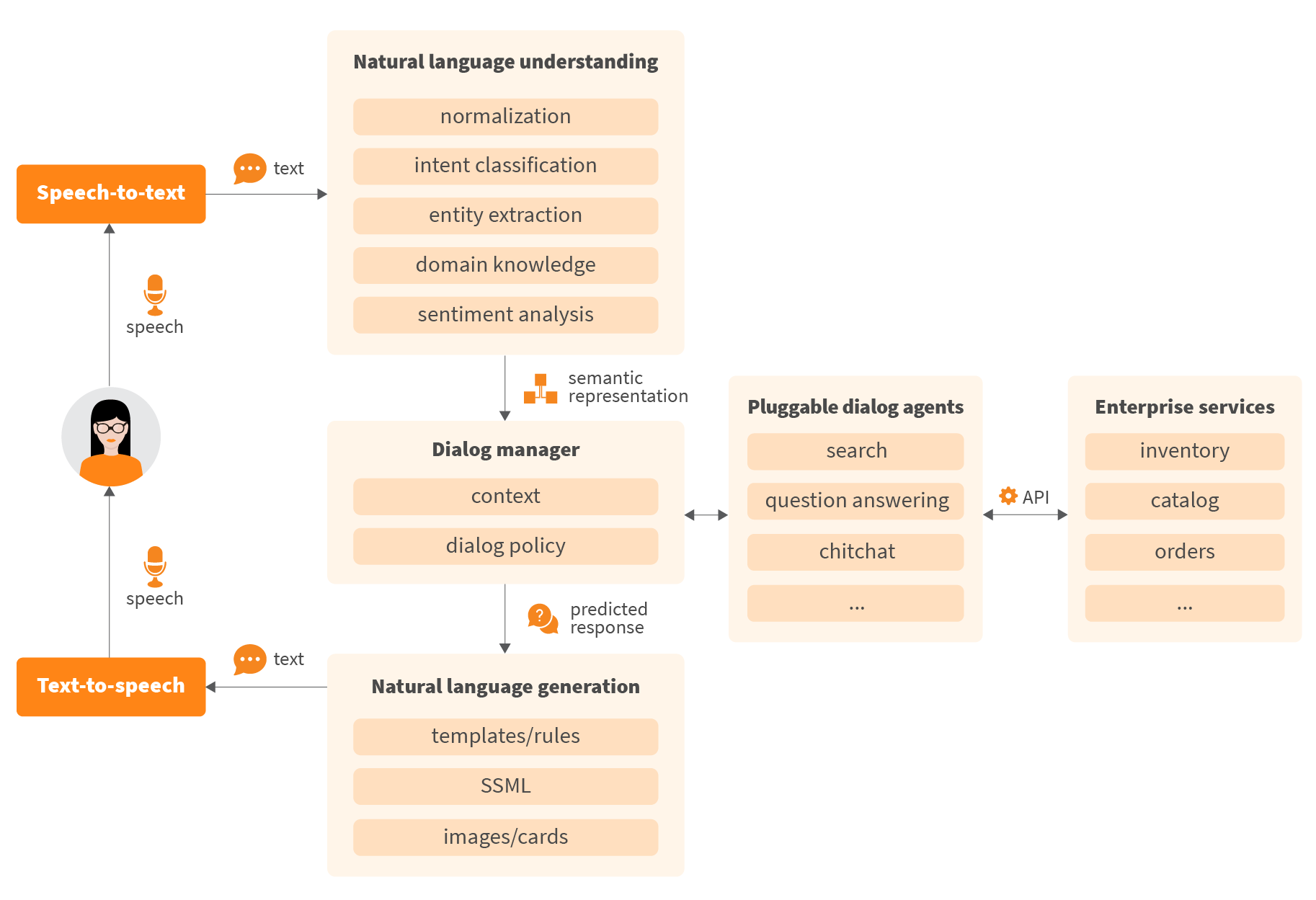
Let's take a quick look at each component:
Natural Language Understanding (NLU) - extracts an intent and information provided by a user that helps to predict the next action in the dialogue. NLU is powered by Deep Learning models to solve various tasks like Intent Classification, Named Entity Recognition, Relation Extraction, etc. The results of this component are then used by Dialog Manager and Agents to process the user’s request and make a decision about the next action in the conversation.
Dialog Agents (or skills) - The dialog agent is the basic reusable unit of the system, which is responsible for some specific part of the conversation. It also contains business and integration code. Splitting the system to multiple agents allows us to have a flexible architecture, where we support context-switching between small units with different approaches and models inside. Each dialog agent also has its own “context” where it is possible to store some information that can be used later in the conversation, or can be shared with other agents.
We have three types of agents in our framework:
- System-initiated (e.g. slot-filling) - when a skill leads a conversation and guides users through a set of questions to complete a task.
- User-initiated (e.g. QA and search) - when a user asks questions, makes requests, etc.
- Small talk - which can sometimes be useful even in goal-oriented skills, for example to respond to user's utterances that are not directly related to the goal but make conversations natural (e.g. “How are you?”, “This bouquet is awesome!”)
In Flower Genie we have the following dialog agents: Logistics, Product Discovery, Product QA, Order Checkout, and Order Tracking. The most important are the Product Discovery and Product QA agents we described above, where we help users find suitable products. Here we use a classical approach that combines intent classification with entity and relation extraction powered by a search engine.
Dialog Manager - maintains the state of the conversation, routes incoming requests to specific dialog agents, and supports context switching between them. Dialog Manager is a key component of the system that makes it easy to add new skills to the application.
Natural Language Generation (NLG) - allows for converting the predicted response into natural language. It can produce different response formats (text, SSML, images, cards) depending on the channel and device type being used. Here we use templates because it’s a more stable and predictable way to generate the text for goal-oriented agents. However, we also consider Deep Learning approaches because models like GPT-2 recently showed a completely new level of text generation and there is also a lot of research work currently being undertaken by various research groups into controllable text generation.
Channel Adapters - are responsible for integration with a specific platform like Amazon Alexa or Google Assistant. Each platform has its own API, security requirements, and payment workflows.
Speech recognition and synthesis are handled by Amazon Alexa and Google Assistant. However, we actually found that these platforms are pretty poor at general speech-to-text for specialized or rare domains and there is no way to extend their models (like in Amazon Transcribe), except using their built-in intent-slot models.
Understanding customer queries using Deep Learning
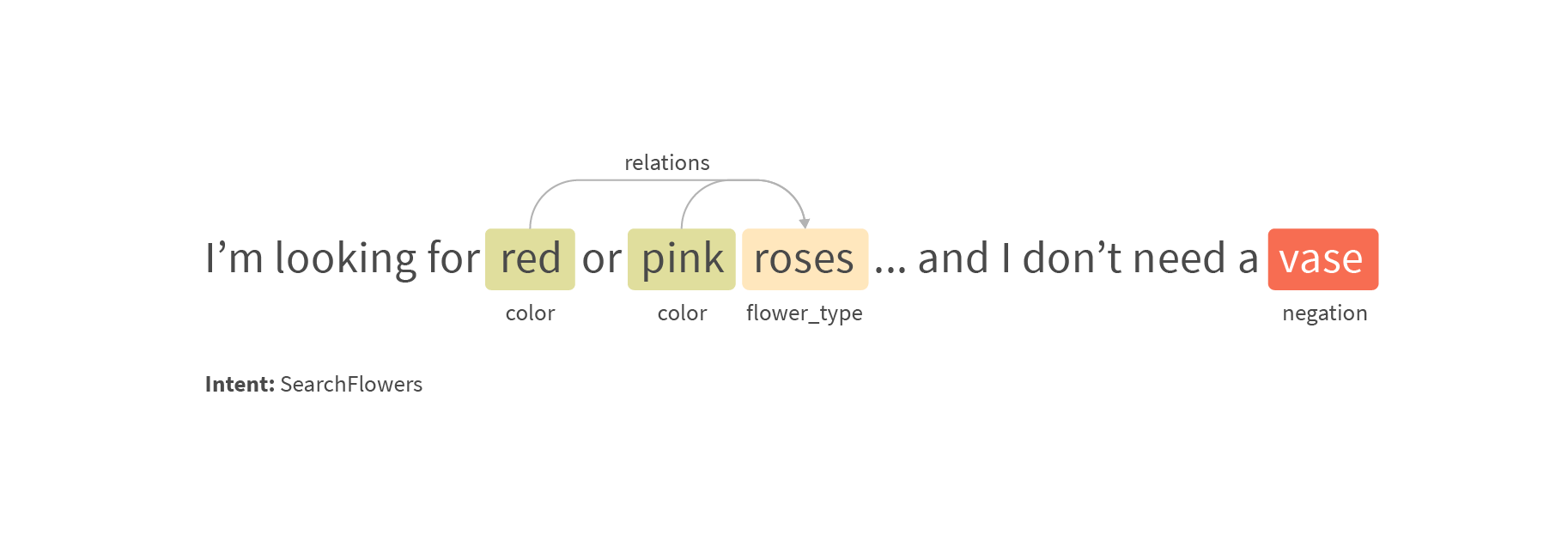
Our system needs to understand customer utterances in order to retrieve customer data, answer questions, and search for products. For those goals we solve tasks like intent classification, named entity recognition (NER), negation detection, relation extraction, etc. Usually intent classification and NER are key parts of the NLU component. If the user's intention is classified wrongly then there is a high chance that the conversation will go in the wrong direction and the user will not understand what is happening. Intent classification may look simple because it's just a classification of short sentences, but in practice, you often need to separate very similar utterances into different intents, or sometimes the same utterance can have different meanings depending on the context.
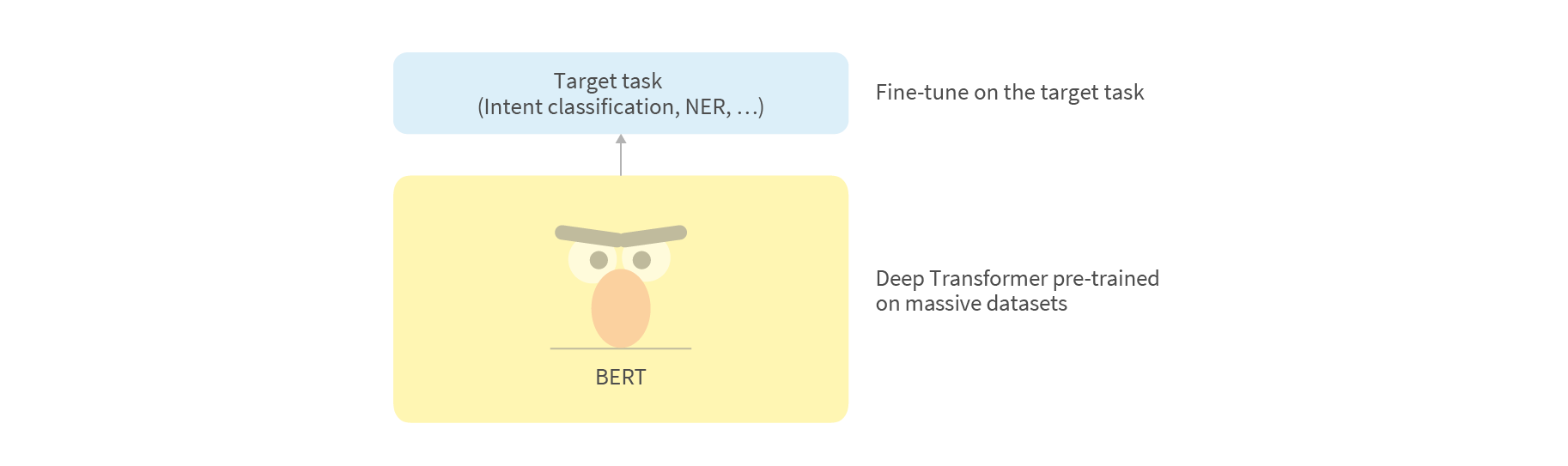
Recent progress in Deep Learning allows us to build much better NLP models, especially with raise of transformer-based models like BERT, GPT-2, etc. These models along with other progress related to model adaptation made Transfer Learning in NLP comparable to what we have in Computer Vision area. Transfer Learning allows leveraging of the already existing data of some related tasks and domains. It can also be in the form of pre-trained language models (trained on very large datasets) where we don’t need to learn complex language concepts from scratch for our target tasks. As a result, it also helps achieve better results and deal with smaller datasets. In our project, we used pre-trained BERT for all our tasks. We found that fine-tuning noticeably improves the quality and Adapters help to do this significantly faster. BERT’s sentence pair classification allows us to use dialog history to better classify ambiguous dialog acts. For multi-intent classification we also evaluated both multi-label classification and segmentation approaches.
Sometimes it is not effective to use intent classification combined with NER. Instead, it is better to use additional Question-Answering models in form of response selection or reading comprehension, especially for cases like FAQ or similar. For example, instead of adding 50 new intents for a new set of questions, it might be better to add several general intents and use additional models that select suitable answers, e.g. retrieval-based models. Alternatively, Reading Comprehension models can be used if you have the resources and data for fine-tuning and it is well suited to your use-case. On the other hand, sometimes all the above aren’t enough and you need to go into the details and use various semantic parsing models to work with more complex expressions.
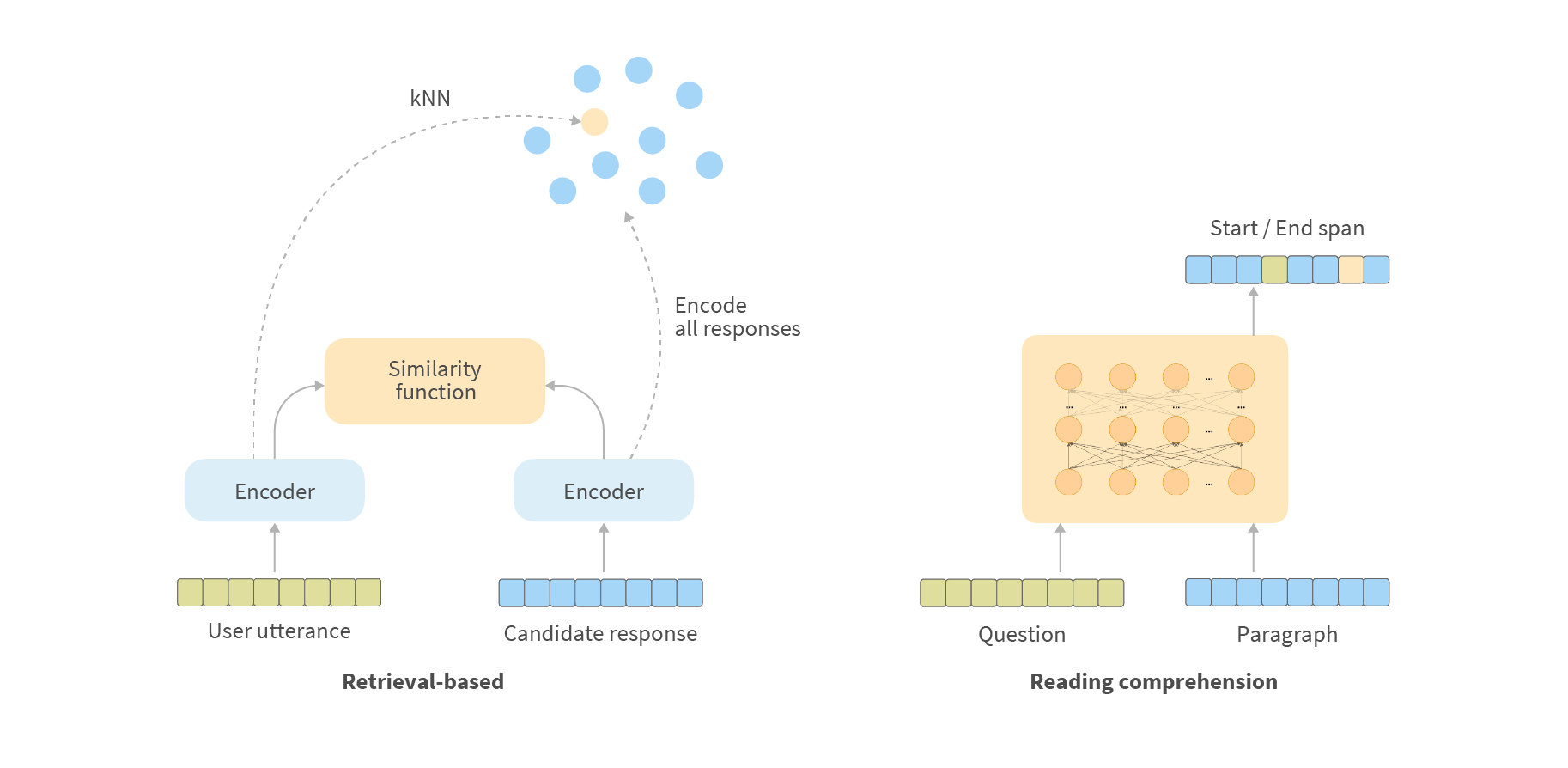
We will go into greater detail on these in the next blog post.
Building the dataset from scratch
There are a number of approaches that can be taken to build the conversational dataset from scratch, each with its own pros and cons depending on factors such as complexity, time, budget, domain, and desired quality. However, you can use a combination of these approaches on different stages of your project, for example building a simple baseline system to collect a dataset for more complex solutions.
In our case we started with Dialogflow, which helped us to build a prototype quickly with a small dataset and didn’t require building our own ML infrastructure. At the same time, we started working on a custom ML solution, which we switched to after collecting enough data. To build the dataset for the prototype we decided to generate it from templates. We built a small tool (similar to Chatito) to generate datasets for intent classification, slot and relations extraction tasks. Then we started to extend the dataset based on real conversations between our system and test / real users. We also used Amazon MTurk and various augmentation techniques to increase the dataset size on different stages of the project.
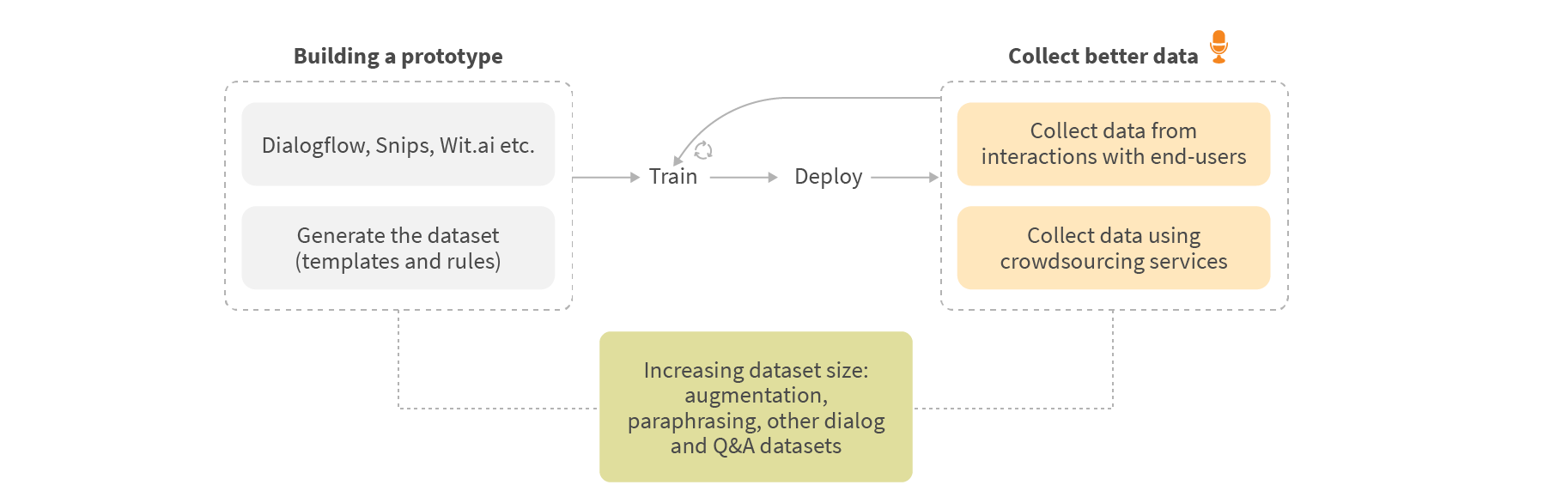
Here is a summary of the approaches we tried when creating our dataset:
- Generate the dataset using tools like Chatito or Chatette. Keep in mind that data generated based on templates or grammar rules usually has well-recognized patterns and models will likely overfit on them. To achieve good results you also need to build additional tools to analyze such datasets in terms of word distribution, train/dev/test split, etc. The advantage is that these tools generate already labeled datasets, but are usually limited only to intent and slots.
- Collect data using Amazon Mechanical Turk. You can use it to collect utterances and rephrase them. The main issue with this kind of approach is that turkers don’t have a real goal (obviously because they are not real customers). Instead, they just provide examples for the specified context.
- Use existing datasets from similar domains or tasks. Even when you have a different domain, you still can find some samples for general dialog acts (e.g. RequestMore, Greeting, Help, Affirm, etc.) in other existing datasets. Such datasets can be also used for Transfer Learning. For example, you can pre-train the model using some big conversational dataset and then fine-tune it for your task.
- Use datasets like Amazon QA. In our case it helped us with questions the user would be likely to ask such as questions about the bouquets, delivery, etc.
Ultimately, the best dataset can be collected only after interactions with real users have been observed, which should be done as early as possible. It is also important to collect the data in dialog format, instead of independent intent-slots, because it will help in understanding the user's behavior, as well as to use a dialog history as a feature for your models to handle context-aware cases.
The testing and certification process
Testing of voice applications is fairly similar to testing of any other kind of system however, it also has its own unique difficulties as well as some additional steps. As for any other system, we have Unit, Functional, Integration, and Model testing because we have ML-based components.
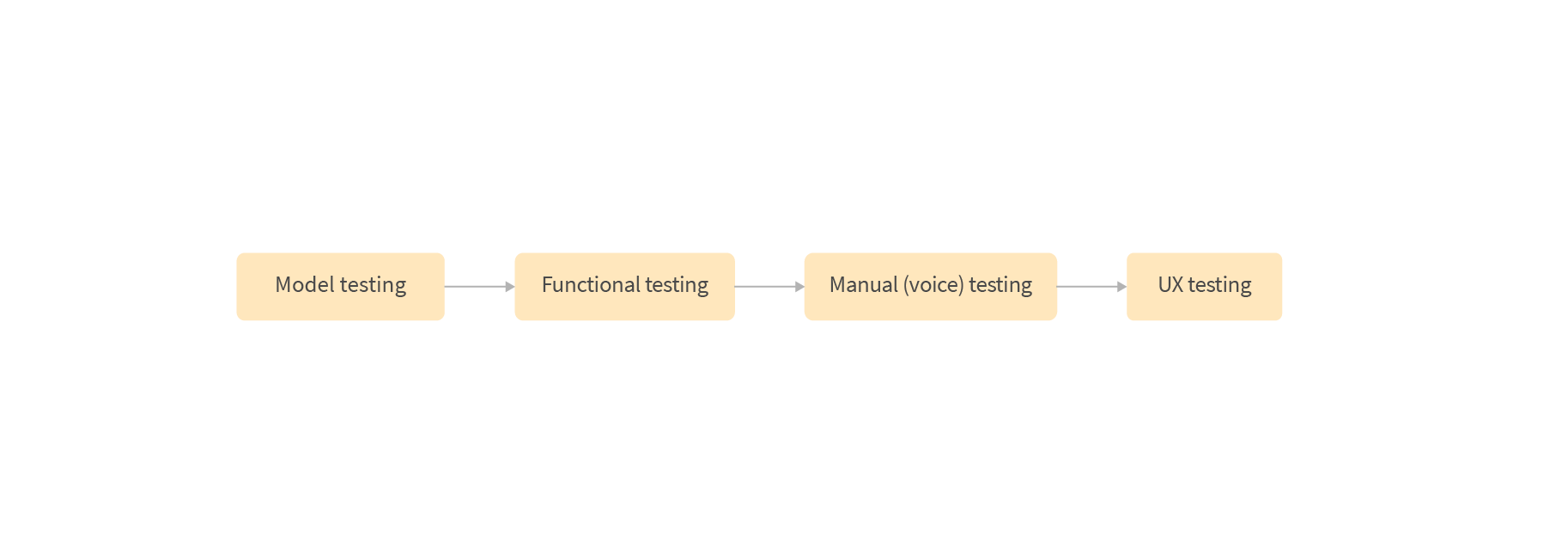
Compared to a classic Model testing for measuring the model’s quality and performance, we also included two additional approaches:
- An additional small test dataset for a sanity check to more quickly detect critical functional issues at early stages before deploying it for the next levels of testing. It can also be helpful for demo cases.
- A “diff” step for model testing to automatically identify differences between the previous and new model on the test dataset, even when the models have the same accuracy.
It's also important to play around with the model so that you’re not relying solely on looking at scores, especially in the early stages.
The next level of testing is Functional testing. Developers and quality engineers write tests to verify various branches of the dialogue and integrations with other systems. They also test various conversation-specific cases such as handling of errors or unexpected inputs, the presence of follow-up questions, context switching, etc. All components are tested together at this stage, using our internal API. It is also possible to write automated tests, which includes speech-to-text and text-to-speech using tools like Bespoken. It helps to test integrations between a platform like Amazon Alexa and your back-end, but it doesn’t help to test speech-to-text.
Many issues can be found only during Manual Testing (via voice) due to speech-to-text issues related to non perfect speech-to-text technology, noisy environments, and different accents. People also speak differently in voice and text channels, so here we are considering only voice communication rather than the “chat” testing interfaces provided by Amazon and Google in development consoles.
As mentioned previously, UX testing is a crucial part of voice applications, so only good UX testing allows good results to be achieved. You should continuously test the solution outside of your team to collect objective feedback. The more people who play with your system, the more useful data can be collected and new use cases can be figured out. UX Testing is not limited to sessions during development, you should also incorporate monitoring to continuously collect the data in production and analyze it to improve usability. You can detect or measure various things like: the number of dialog acts needed to complete particular tasks, the places where users stop the conversation, classification results with low confidence, user repeats, errors, etc.
Sometimes developers need to debug applications with Alexa locally and services like ngrok can help to do that. It works like a proxy service to your local web server. You install their application locally and they generate a unique link with HTTPS support which you can put to your skill configuration. The requests from Alexa then go to this resource, it forwards requests to your locally installed ngrok, and it is then forwarded to your web service.
When you submit your skill to the Amazon or Google skills store, it must pass a certification process before it can be published live to customers. It includes different security, functional, and UX requirements. It’s important to pay attention to functional and UX requirements in advance because it may affect your implementation: how to properly ask questions, react to specific built-in intents etc. Both platforms still have some drawbacks associated with how the skill publishing is organized. For example, with Amazon Alexa you cannot control when to make your skill live - it will be published to the store automatically immediately after certification. This can be inconvenient, especially when you support payments in your system because Amazon testers will create orders during certification, which requires that you track the orders they created and cancel them, because the certification can be done only for the production version. Therefore, the release process needs to consider that you may need to setup Blue-Green deployment. But the most inconvenient aspect of this is that you need to certify the skill even for small changes to the NLU layer, which in most cases is not well related to functionality of your skill, and the review may take from a few days to a week. But if you use your own models, you can silently update them without any additional certification.
Conclusion
The capabilities of speech recognition and natural language processing are rapidly improving and now allow highly engaging and useful voice applications to be built. New voice devices that include displays open the door for completely new kinds of shopping experiences, which weren’t very convenient in the previous generation of voice devices. The technical challenges inherent in perfecting conversational systems are steadily being overcome and the development is becoming simpler due to a combination of technology improvements in speech-to-text and machine learning as well as in the devices/platforms themselves.
However, while voice platforms like Amazon Alexa and Google Home have advanced rapidly, as we discovered in this project, it is still not easy to develop a quality conversational AI system. These are primarily centered around context-aware cases, conversation design, and lack of data for training. There are still unresolved problems that remain around understanding human language because of the many complexities it contains and the lack of commonsense knowledge in the models.
Ultimately, the challenges inherent in the development of these systems underlined the importance of having robust testing systems in place and having a good understanding of the Amazon and Google certification requirements. Recent progress made in NLP has allowed for a significant increase in the quality of NLU capabilities for goal-oriented skills, but Engineers and ML alone cannot solve everything, and only collaboration with designers and domain experts all working together on data collected from real conversations can produce truly successful outcomes.
In our next post, we will explore the technical aspects raised in this article, allowing you to gain a more complete understanding of the challenges involved in developing conversational commerce systems. For more information on Grid Dynamics Labs and the full range of services we provide, click here.
Resources
Conversation Design
The official Amazon and Google design guidelines:
https://developer.amazon.com/docs/alexa-design/get-started.html
https://designguidelines.withgoogle.com/conversation/conversation-design/
https://developers.google.com/assistant/transactions/physical/design
A series of useful articles from Nielsen Norman Group:
https://www.nngroup.com/articles/voice-first/
https://www.nngroup.com/articles/audio-signifiers-voice-interaction/
https://www.nngroup.com/articles/intelligent-assistant-usability/
NLP libraries and tools
NLP libraries: 🤗Huggingface Transformers, Flair, spaCy
Frameworks for building AI assistants: Rasa, DeepPavlov
Labelling tools: Doccano, Prodigy
Dataset generators: Chatito, Chatette