
How to achieve in-stream data deduplication for real-time bidding: a case study

In this blog post we share our experience delivering deduplicated data during In-Stream Processing for a large-scale RTB (real time bidding) platform. A common problem in such systems is the existence of duplicate data records that can cause false results when processed by the analytic queries. One approach used in the industry performs deduplication each time a query is run, which is computationally expensive and causes major performance degradation. Our project’s objective is to deliver accurate business intelligence to the users while cutting processor resource use and decreasing response time by deduplicating the data before delivering it to the Lambda and Kappa systems where the actual data processing takes place.
The duplicate data problem
Our streaming pipeline receives a continuous click-stream from real-time collectors. Analysis of this data is used to evaluate the effectiveness of marketing campaigns, as well as for creating additional metrics and statistics.
In this project we use Amazon Kinesis and Amazon EMR with Apache Spark for the In-Stream Processing of several thousand events per second. After that processing step, the events are pushed to Kinesis. The Spark application reads data from the Kinesis stream, does some aggregations and transformations, and writes the result to S3. After S3, the data is loaded into Redshift.

By default, when consuming data from Kinesis, Spark provides an at-least-once guarantee. This is achieved with Kinesis checkpointing, which maintains the storing offset interval of a Kinesis stream in DynamoDB. If Spark fails in the middle of the Kinesis checkpointing interval, the next time it starts it will read all events from the beginning of the interval. This means each event can be processed/delivered more than once, which can lead to duplicates.
Apache Spark provides a mechanism to avoid duplicates which recovers data after failures and prevents flows from processing duplicates called Spark checkpointing. It is a built-in Spark Streaming feature, not to be confused with Kinesis checkpointing (which we mentioned in the previous paragraph). When Spark checkpointing is enabled, Spark saves metadata and processed RDDs to reliable, persistent storage, e.g.: HDFS. Another feature of Spark Streaming is the write-ahead log (WAL). The WAL contains data received from Kinesis (or any other input stream). It is used for state recovery after failures of the driver and receivers. The combination of checkpointing and WAL should help get close to the exactly-once guarantee. However, these features in Spark still don’t work correctly and cause performance degradation, especially if older versions are used. In our implementation we used Spark 1.5.2 and it had a number of issues, like SPARK-11740, SPARK-11324, SPARK-12004. Unfortunately, even the latest version of Spark still has performance and functional issues, like SPARK-19280, SPARK-19233.
To avoid all these issues, we decided to use Kinesis checkpointing to implement the at-least-once guarantee, and designed a separate lightweight solution to minimize the likelihood of duplicates. We tried two different approaches; the second worked significantly better than the first. Next, we’ll describe both in some detail and explain how we arrived at the final solution.
The first deduplication solution, as a batch process
Our initial approach to deduplication was done as a batch process:
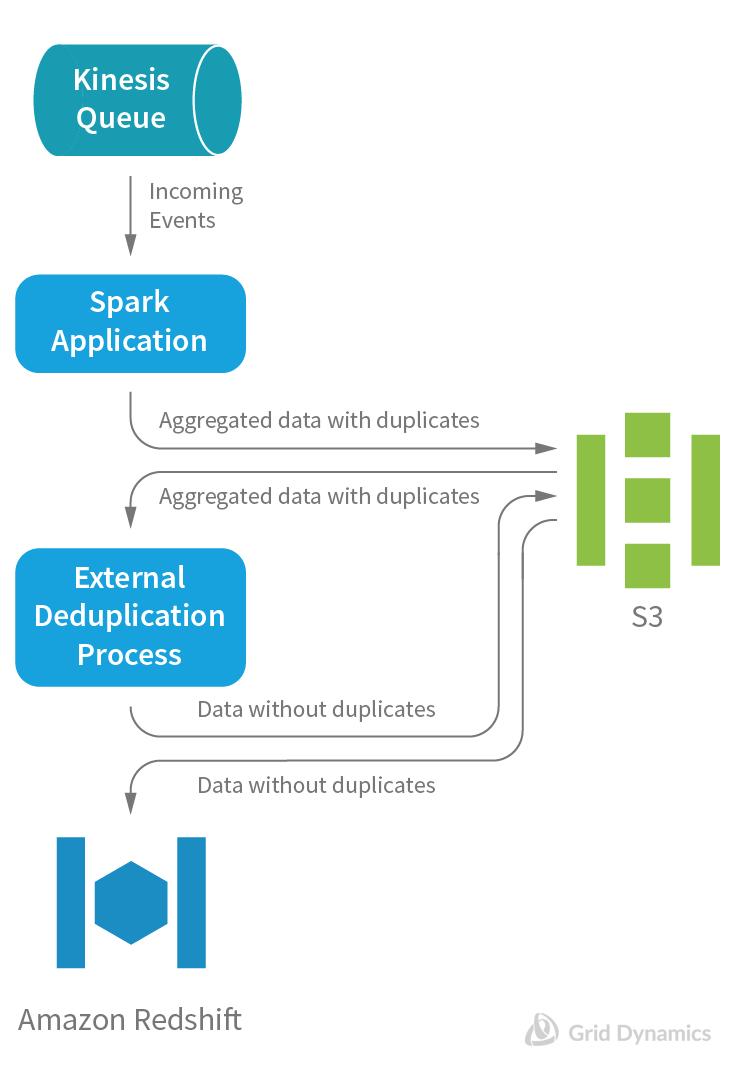
This solution helped us to remove duplicates before loading data to RedShift, but it had three issues:
- the time of delivery of good data to RedShift was taking up to an hour
- we were not able to implement business logic during processing of the stream, since it had duplicates.
- the architecture was significantly more cumbersome than the initial in-stream version without deduplication.
To solve these problems, we decided to implement a lightweight, duplicate-removing solution in-stream.
The second and final deduplication solution, in-stream
Solution architecture
In cases where built-in Spark functionality does not work well, the most obvious solution is to remove duplicates in-stream with pass-through deduplication. This should be a function in Spark flow that filters events based on their presence in a lookup database (cache storage). Our typical approach is to use Redis as a lookup database, as documented in our In-Stream Processing blueprint. However, the customer has asked not to introduce new system infrastructure components, so we decided to use Amazon S3 for storing deduplicator caches.
 In-stream data processing tier
In-stream data processing tier
During processing, the data was partitioned into a Spark stream. Each event got a unique ID based on the creation timestamp and was placed in a bucket whose number was calculated as a hash code of the event ID. Here is an example of how we partitioned the data:
def createPair(fields: Map[String, String]): (DateTimePartitionKey, Map[String, String]) = {
val partitionKey = DateTimePartitionKey(
fields(FlowField.EventDate),
fields(FlowField.EventHour),
fields(FlowField.EventId)
)
partitionKey -> fields
}To achieve good performance, we needed to run the deduplication processing in parallel. Since we already processed data in parallel with the partitioning scheme described above, we reused the same parallelism for deduplication. Therefore, we needed to partition the cache stored in the S3 filesystem the same way we partitioned data in the stream.
Cache storage on S3
Partitioning was implemented with a hierarchical directory structure:
- The date the batch was created was the first level,
- The hour the batch was created was the next level, storing all events within that hour,
- Bucket was the last level, and stored the actual cache files. Bucket was calculated in the same way as for data, i.e. using a hash of the event ID.
- Each cache file stored a batch of events.
We used the “append only” approach for adding files to the directory structure. In other words, for every processed batch, a single file containing new event IDs was added to the corresponding partition, so for our 3-minute batch size we had about 20 files in each partition. Names of all cache files were unique because they included the batch time:
/bucket/cache-dir/[date]/[hour]/[bucket]/[batch-time].cache
In real life it was something like:
/bucket/cache-dir/2017-03-15/17/19/1489778100000.cache
Having multiple cache files for each bucket might have become a bottleneck because of the high latency of S3 read operations. However, S3 throughput was good and we read files in multiple threads to achieve increased performance. The same approach was valid for writing data to S3.
To maintain consistency, both data and caches were persisted in one transaction. This was possible because both data and caches were stored in the S3 filesystem. During batch processing, data and caches were written to temporary directories. As soon as a batch was processed, its contents were moved to a final location as an atomic operation. If one of the move operations failed, the whole flow was stopped until the consistent state was restored manually. In our Spark application we had a helper class CacheLoader. It served as a holder for caches and had the following interface:
In our Spark application we had a helper class CacheLoader. It served as a holder for caches and had the following interface:
class CacheLoader {
// Each time getCache is called with a new partitionKey,
// it persists the last loaded cache to a temporary location and
// reads cache from the final location for the specified partitionKey
def getCache(partitionKey): Cache = { … }
// Persists the last loaded cache to disk
def persistCache(): Unit = { … }
}
The Cache itself was a simple data structure that consisted of two sets. The first one was an immutable set which contained data loaded from S3. The second one was a mutable set which was used for adding new event IDs.
We need getCache to be called only once for each partition key. Otherwise, it can read an outdated cache because some new event IDs might be persisted in a temporary location. The easiest way to do this is to sort data by key. This can be done during repartitioning using built-in repartitionAndSortWithinPartitions Spark method. Finally, the deduplication function looks like the following:
def deduplicate(stream: DStream[Map[String, String]]): DStream[Map[String, String]] = {
stream.map(CacheDeduplicator.createPair).transform((rdd, time) => {
rdd.repartitionAndSortWithinPartitions(partitioner).mapPartitions(iter => {
val batchTime = time.milliseconds
// Defines temporary cache directory for the current batch.
val tmpCacheDir = getTempCacheDir(batchTime)
// Defines the final cache directory.
val finalCacheDir = getFinalCacheDir(Config.RootDir)
val cacheLoader = new CacheLoader(finalCacheDir, tmpCacheDir, batchTime)
// Filtration is a lazy operation. So, we have to materialise data using Vector here.
// Otherwise cacheLoader.persist will be called before filtering events.
val input = iter.toVector
val output = input.filter {
case (partitionKey, fields) =>
val eventId = fields(FlowField.EventId)
// Returns cache for the partition key.
val cache = cacheLoader.getCache(partitionKey)
// Adds current event id to the cache and
// returns true if it does not exist, otherwise false.
cache.add(eventId)
}.map(_._2)
// Persists a cache loaded last time.
cacheLoader.persist()
output.iterator
})
})
}
In this function we map the input stream to a stream of pairs where the first element is a composite partition key while the second one contains the data. After that, we apply a transformation function on this stream which allows us to operate with RDDs and batch time. Finally, we call repartitionAndSortWithinPartitions on the RDD and filter the duplicates using our pass-through caching mechanism.
If you look at the solution carefully, you may notice that the number of buckets, not the number of partitions, defines the actual level of parallelism. The number of tasks that Spark will create for the deduplication stage will be equal to the number of cache data buckets, even if the partitioner has a greater number of partitions. The bucket structure on S3 should be designed with that in mind. A greater number of partitions may still be helpful if it is necessary to process delayed data, though, so in our case we set it twice as large as the number of buckets.
Conclusion: in-stream deduplication is a successful design approach
Implementation of in-stream deduplication reduces delivery time for the clean data compared to delivery time when performing offline deduplication, and use of S3 keeps the solution architecture and deployment topology simple and minimizes operational costs. The deduplication phase insures that we process only new events, and even if reprocessing is needed for some reason, it can easily be achieved by deleting both the caches and results data from S3.
Dmitry Yaraev