
How to implement multi-select faceting for nested documents in Solr


Nearly all major online retailers these days support faceted navigation, as it is a key instrument of product discovery. Facets provide a powerful, intuitive way to summarize search results from multiple perspectives. They also offer a straightforward interface to apply filters and refine navigation results. Without faceted navigation, product discovery in large catalogs would be a tedious business of either manually sifting through dozens of result pages, re-formulating search queries, or digging through huge category hierarchies.
Typically, a facet looks something like this:
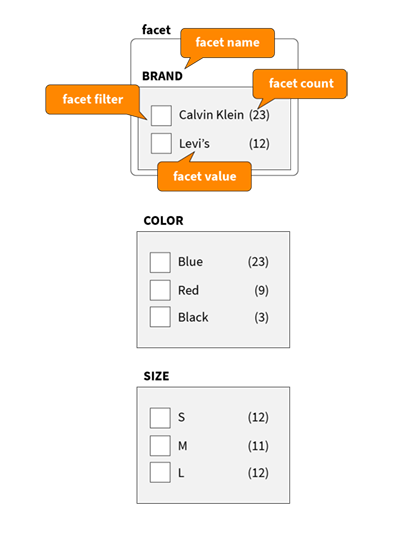
Each facet summarizes the navigation results for product attributes, such as COLOR or BRAND. The facets show what values (specific brand, size, color, etc.) of the attribute are present in the current results, as well as the number of individual products (stock keeping units, or SKUs) that correspond to each value. Therefore, facet values allow us to easily apply a facet filter, so that we can limit results to the products which have the selected attribute values.
On many sites, facets have single-select filters: they allow only the selection of a single value to be applied as a filter. After using a single-selected facet filter for the color ‘Blue’, the facets look something like this:

As you can see, all the facets have recalculated their counts, and the SIZE facet lost one of its values, “S”, as no products in a size S were blue. The COLOR facet lost all of its values but the selected color (blue), since products can only have a single color value.
This is a good baseline experience for searching online, but it offers limited functionality. What if there are two colors you like, and you want to explore products for both of them? With a single-select facet search, you have to constantly select and deselect facet filters, a task which quickly becomes time-consuming and frustrating. In addition, if you are unsure about the brand you are looking for, the single-select facet experience is unfriendly.
What you need is a multi-select facet which will allow you to select multiple facet values at once:

In this case, we are searching for products which are red or black, and are size M. This type of filtered search provides a far more convenient user experience, and is the de facto standard for major online retailers.
However, this approach presents significant implementation challenges. With single-select facets, each facet count directly represents the current result set. For example, if 12 red products are selected, then the COLOR facet would just contain “red (12)”, and nothing more. However, with multi-select facets, we are also interested in showing how many blue and black products there are if red products are not selected. In other words, to calculate the counts of multi-select facets, we need to ignore the filters which are applied to the current facet, yet respect the filters which are applied to all other facets.
This means that we can’t just calculate multi-select facet values based on the current result set. For each of the facets with applied filters, we have to prepare a special result set for the original query and all the filters except for the filters on the subject facet. So, instead of a single search+filtration and facetization pass, we may need as many additional searches+filtration as there are facets with applied filters.
This can take a pretty heavy toll on the search performance, especially in the case of large catalogs and result sets. The situation becomes even more complicated when we have a structured catalog (such as a product/SKU relationship) and are going after precise filtration.
This post describes our journey to employ the powerful Solr JSON facet API to support multi-select facets in a structured catalog. We applied performance optimizations and added usability features to help with automated filter exclusion, which is necessary for the correct multi-value facet calculations. We contributed our results in SOLR-8998 and SOLR-9510, both of which were delivered with Solr 7.4. With this release, Solr now supports multi-select faceting with nested documents out of the box.
Now that the high level explanation is complete, we will continue with a more detailed walkthrough of the basics of faceted search in Solr, and then get into the technical details of our solution.
Current state of searching with Solr facet query
We will first set up an example using products, facets, and SKUs, and show how faceting works from a technical perspective with Solr. Let’s say that we have an e-commerce site with the set of products shown below:
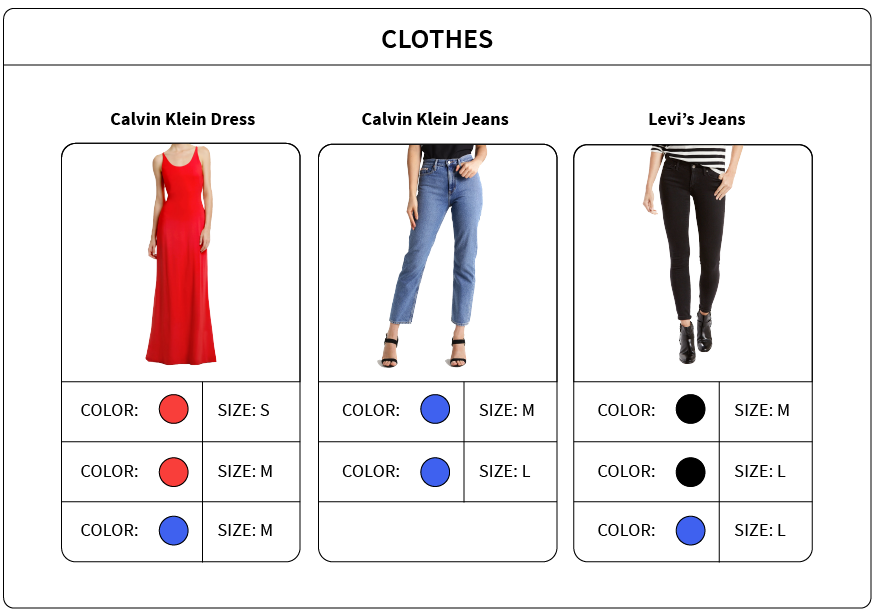
In our previous posts introducing nested documents in Solr and explaining Block Join Faceting, we discussed the basics of faceting and parent-child relations (another term for nested documents). Given the above data, and what we know from those posts, if a customer searches ‘clothes’, for example, they should be shown the facet ‘COLOR’ with values red:1, blue:3, black:1. These values represent the number of products that have at least one SKU with the corresponding attribute, not the total number of available SKUs in that color. Put plainly: one of the products has a SKU in red, one has a SKU in black, and all three have them in blue.
The next step is to write the data into documents. Once entered, we can use Block Join Query (provided by Solr) to search and filter through document hierarchies. The facets are then calculated using either the Block Join Facet Component, or with the JSON Facet API. Both of these processes require indexing SKUs as nested child documents, with one example shown below. These indices clearly show the three products and their nested child documents, with each document corresponding to a specific SKU of a certain size and color:
[
{
"id": "1", "scope": "product", "category": "clothes",
"product_type": "dress", "brand": "Calvin Klein",
"_childDocuments_": [
{ "id": "11", "scope": "sku", "color": "red", "size": "S" },
{ "id": "12", "scope": "sku", "color": "red", "size": "M" },
{ "id": "13", "scope": "sku", "color": "blue", "size": "M" }
]
},
{
"id": "2", "scope": "product", "category": "clothes",
"product_type": "jeans", "brand": "Calvin Klein",
"_childDocuments_": [
{ "id": "21", "scope": "sku", "color": "blue", "size": "M" },
{ "id": "22", "scope": "sku", "color": "blue", "size": "L" }
]
},
{
"id": "3", "scope": "product", "category": "clothes",
"product_type": "jeans", "brand": "Levi’s",
"_childDocuments_": [
{ "id": "31", "scope": "sku", "color": "black", "size": "M" },
{ "id": "32", "scope": "sku", "color": "black", "size": "L" },
{ "id": "33", "scope": "sku", "color": "blue", "size": "L" }
]
}
]
We are going to use this data set in several examples to come. The first step to operate it is to open Solr on your computer (let’s call the computer localhost:8983), and add the above documents to the index of a preliminary collection named collection1. Each Solr index can consist of several collections, which are similar to database domains. When you index documents or execute a query, you need to specify which collection it should be directed towards. To do all this, use the ‘Documents’ tab of Solr Admin UI (with ‘Solr Command (raw XML or JSON)’ document type).
We will now shift our attention away from document structures and return to our example. Let’s say that our customer searches for clothes, and we want to show her the product_type and brand facets. We would then send this HTTP request (for example, by opening this URL in the browser):
As expected, the Solr response contains counts for the products and brands:
"facet_fields":{
"product_type":[
"jeans",2,
"dress",1
],
"brand":[
"Calvin Klein",2,
"Levi’s",1
]
}
Remember that each facet value here represents a filter that can be applied to the given search result, and that the respective counts show the number of documents that would pass such a filter. So, if the user decides to narrow their search results by using the filter product_type:jeans, it won’t show any non-jean products. In this case, this means that dresses won’t be shown: the user will only see two documents. But what happens with the facet counts?
"facet_fields":{
"product_type":[
"jeans",2,
"dress",0],
"brand":[
"Calvin Klein",1,
"Levi’s",1
]
}
The counts for brand in the response seem obvious: there is only one Calvin Klein and one Levi’s product in the filtered search result. The product_type facet, however, looks a bit confusing because dress has a value of 0. On one hand, since we filtered out all of the dresses, a count of 0 for the dress facet seems to be a reasonable output. But on the other hand, from the user experience perspective, each facet value is just a potential filter. Users expect that by choosing several filters for one field, the search result would contain all of the products that pass these filters. This means that if a user chooses the filters product_type:jeans and product_type:dress together, they wouldn’t want to see a blank result page (nothing can be both a dress and jeans), but instead, they’d desire to see all of the results containing jeans or dresses. Therefore, for multi-select facets, a count of 0 for dress would not be correct. In our example, the product_type facet should look like this:
"product_type":[
"jeans",2,
"dress",1
]
This is because, as we explained above, if we add the product_type:dress filter along with the product_type:jeans filter, we need to see the counts for both facets. In other words, the counts for the product_type facet after filtering by product_type:jeans should look exactly the same as they were before the filter was applied. Essentially, the facet counts for multi-select searches should be unchanged, and only the documents shown to the user should reflect the filters being used.
Let’s go one step further and suppose that the user wants to apply a second filter (like a specific brand) on top of the first: for example, they might only want to see Calvin Klein jeans. This is what that request would look like:
The standard facet response to this query would be:
"facet_fields":{
"product_type":[
"jeans",1,
"dress",0],
"brand":[
"Calvin Klein",1,
"Levi’s",0
]
},
However, for multi-select facets, we would want to see a different outcome: product_type dress:1, jeans:1; brand ”Calvin Klein”:1, ”Levi’s”:1. In order to get this result, when calculating the multi-select facet for a specific field, we must exclude the filter of this field from the set of applied filters so that the filtered facet will still appear with its full count. Basically, while we want this field to be filtered in a search, we need to still see its facet counts, because otherwise they won’t appear when another filter is added.
Thus, to calculate the product_type facet, we need to exclude the product_type:jeans filter and apply only brand:“Calvin Klein”. Similarly, to count the multi-select brand facet, only the product_type:jeans filter should be applied. This process looks pretty cumbersome: filters have to be applied to each facet, and there can be dozens or even hundreds of facets in a large catalog. There has to be an easier way -- and there is.
Finally, we have come to the basic solution to our problem. When the user applies filters, we need to calculate multi-select facets. In order to count facets for any given field, we must exclude all user filters applied to it. For simple, flat documents, Solr provides a standard solution for this problem: tagging and excluding filters. Using this approach, we should mark each filter with a tag and request to exclude the tagged filter in the scope of a particular facet calculation. For example, our previous request with two filters should be specified as:
It yields us a single document with the desired multi-select facet counts:
"facet_fields":{
"product_type":[
"dress",1,
"jeans",1],
"brand":[
"Calvin Klein",1,
"Levi’s",1
]
}
This is exactly what we are looking for: all the facet counts we want to see are present. This solution works correctly for flat documents. The next step is looking at nested documents, which is where multi-select faceted searches really get tricky.
Multi-select Solr facet for nested documents
Suppose that we need facets for the color and size fields. One of the possible approaches to counting them would be using Solr Block Join Facet Component, which was described in our previous blog post How to Implement Block Join Faceting in Solr/Lucene. Unfortunately, this component doesn’t give the ability to exclude filters, so it is not suitable for calculating multi-select facets. Therefore, we turned to JSON facet API, which provides a flexible functionality for processing different types of facets, statistics, aggregations, and more. The issue with the JSON facet API was that it was too slow to work on a large scale e-commerce platform -- we had to find a way to make it faster.
Before we continue, we should say that Grid Dynamics was heavily involved in the development and creation of an important update that was delivered with SOLR-8998, and included in Solr 7.4. Our new feature, called uniqueBlock, was made in the scope of this update for the purpose of speeding up the JSON facet API. To utilize this function, the request must be formed as follows:
curl http://localhost:8983/solr/collection1/query -d 'q=category:clothes& json.facet=
{
colors:{
domain:{blockChildren:"scope:product"},
type:terms,
field:color,
limit:-1,
facet:{
productsCount:"uniqueBlock(_root_)"
}
},
sizes:{
domain:{blockChildren:"scope:product"},
type:terms,
field:size,
limit:-1,
facet:{
productsCount:"uniqueBlock(_root_)"
}
}
}'
As you can see, creating the proper request in JSON facet API is a bit tricky. First, we must search for products in the query. Next, we have to define the facet domain as all children of matched products, which we do here: domain:{blockChildren:"scope:product"}. Finally, we try to aggregate these children by unique value with the root field, which is automatically added to all child documents as a reference on their parents during indexing. The trouble in creating this request is worth it though, because of uniqueBlock.
This new function is a lightweight replacement for unique aggregation, designed and optimized specifically for rolling up facet counts of child documents. An important element in the request above is an official recommendation to define limit:-1. We discovered this definition while debugging Solr, and found that for our use case it speeds up both traditional ‘unique’ aggregations as well as the new ‘uniqueBlock’ aggregations. This improvement is related to the internal details of the implementation, as uniqueBlock is much faster when it has no value limits, while the default value for the limit parameter is 10. The end result is a function that works much faster for this particular task than the generic unique aggregation.
The Solr response contains both ‘usual’ counts (field count) that indicate the number of matched SKUs, as well as ‘rolled up’ counts equal to the number of products that have these SKUs (field productsCount).
Using the request above provides the following result:
"facets":{
"count":3,
"colors":{
"buckets":[{
"val":"blue",
"count":4,
"productsCount":3},
{
"val":"black",
"count":2,
"productsCount":1},
{
"val":"red",
"count":2,
"productsCount":1}]},
"sizes":{
"buckets":[
{
"val":"M",
"count":4,
"productsCount":3},
{
"val":"L",
"count":3,
"productsCount":2},
{
"val":"S",
"count":1,
"productsCount":1
}
]
}
}
}
That looks good! But what if the user now wants to apply the color:black and size:L filters? Well, our task becomes even more challenging. First of all, in this case the flat search query category:clothes doesn’t fit anymore, because we want to filter products that are both black and in a size large. Since we’re now filtering by children documents, we need to use to-parent block join query to see which parent documents have children that match the filters. Second, domains for the colors and sizes facets should be formed by a whole set of applied filters, with the filters of their own fields being excluded. While the JSON facet API is flexible enough to define a proper set of filters for each facet, it would be convenient to have a generic approach which would enable us to exclude specific filters from facet domains. This solution was developed in the scope of SOLR-9510. For our example, the request should look like this:
curl http://localhost:8983/solr/collection1/query -d
'q={!parent tag=top filters=$child.fq which=scope:product v=$childquery}&
childquery=scope:sku&
child.fq={!tag=color}color:black&
child.fq={!tag=size}size:L&
fq={!tag=top}category:clothes&
json.facet=
{
colors:{
domain: {
excludeTags:top,
filter:["{!filters param=$child.fq excludeTags=color
v=$childquery}",
"{!child of=scope:product filters=$fq}scope:product"]
},
type:terms,
field:color,
limit:-1,
facet:{
productsCount:"uniqueBlock(_root_)"
}
},
sizes:{
domain: {
excludeTags:top,
filter:["{!filters param=$child.fq excludeTags=size
v=$childquery}",
"{!child of=scope:product filters=$fq}scope:product"]
},
type:terms,
field:size,
limit:-1,
facet:{
productsCount:"uniqueBlock(_root_)"
}
}
}'
If you hadn’t noticed, both our search block join query and products filter category:clothes are tagged as top. This is done to exclude them from children facet domains, because if you look at it from the performance point of view, it’s better to create the child-level domains from scratch. For SKUs we use the whole set of filters, but add some exclusions, for example, child.fq with excludeTags=size. It’s very important not to miss the original parent’s filter, which is why we need to add the {!child of = scope: product filters =$fq) scope:product block join query to each of the children’s domains. We have 2 blue and 1 black products that are size L, while we have 1 L and 1 M products that are black, so the response comes out as shown below. The counts and product counts now perfectly correspond to their correct values -- the multi-select faceted search for nested documents is finally complete.
"facets":{
"count":1,
"colors":{
"buckets":[{
"val":"blue",
"count":2,
"productsCount":2},
{
"val":"black",
"count":1,
"productsCount":1}]},
"sizes":{
"buckets":[{
"val":"L",
"count":1,
"productsCount":1},
{
"val":"M",
"count":1,
"productsCount":1
}
]
}
}
}
Conclusion
The ability we introduced to exclude filters by facet domain significantly simplifies Solr requests for counting multi-select facets on the hierarchies of nested documents. It is highly recommended to use this feature with the new uniqueBlock aggregation, as this substantially boosts the performance of request execution. Further potential improvements are being developed, with one known addition being the use of a pre-cached filter of parent documents. Because this retains a set of matched parent documents in memory, it makes switching from matched children to parent documents much quicker.
Ultimately, a multi-select faceted search is a must-have for any large retailer that utilizes Solr. It creates a vastly better user experience, making it quicker and easier for consumers to find the precise products that they need. Previously, it was almost impossible to count facets in nested documents in Solr due to the slowness of the JSON facet API and the difficulty of excluding filters. However, speeding up the JSON facet API with uniqueBlock and using our method of tagging and excluding filters for specific facets has created a fix for this problem. This step-by-step process should work for everyone: it is a solution that has proven to be very successful. While the methodology looks complex, we have already laid out most of the process for you, so it should be easy to implement in your system.
If you have any questions or want to learn more about multi-select faceting in Solr, please send us a call or leave us a comment below!