
Recent Natural Language Processing breakthrough in Computer Vision


With the recent invention of the transformer architecture, we have seen major breakthroughs in the Natural Language Processing (NLP) domain. It is no surprise that attempts to transfer these techniques to other domains is also currently trending. For example, since 2020, the self-attention (SA) mechanism and its derivatives have been successfully applied to Computer Vision (CV) tasks. As a result, many non-CNN architectures and mixed architectures (CNN+SA) appeared, with the SA-based architectures (transformers) establishing State-of-the-Art (SotA) level performance based on CV benchmarks. This created a perception that SA was the supreme choice over CNN. However, a recent ConvNeXt publication [2201.03545] A ConvNet for the 2020s shows that the main advantage of SA and transformer-based architectures can be explained by specific training techniques borrowed from NLP rather than by the perceived supremacy of SA over CNN. In fact, the creators of ConvNeXt express their hope that “the new observations and discussions can challenge some common beliefs and encourage people to rethink the importance of convolutions in computer vision”.
This is a great example of why it’s crucial for Data Science and Machine Learning practitioners to understand the context behind different approaches and model architectures. Thus, the main aim of this blog post is to show how SA and other ideas from transformer-based architectures can be successfully applied to Computer Vision tasks.
CNN vs. Transformers
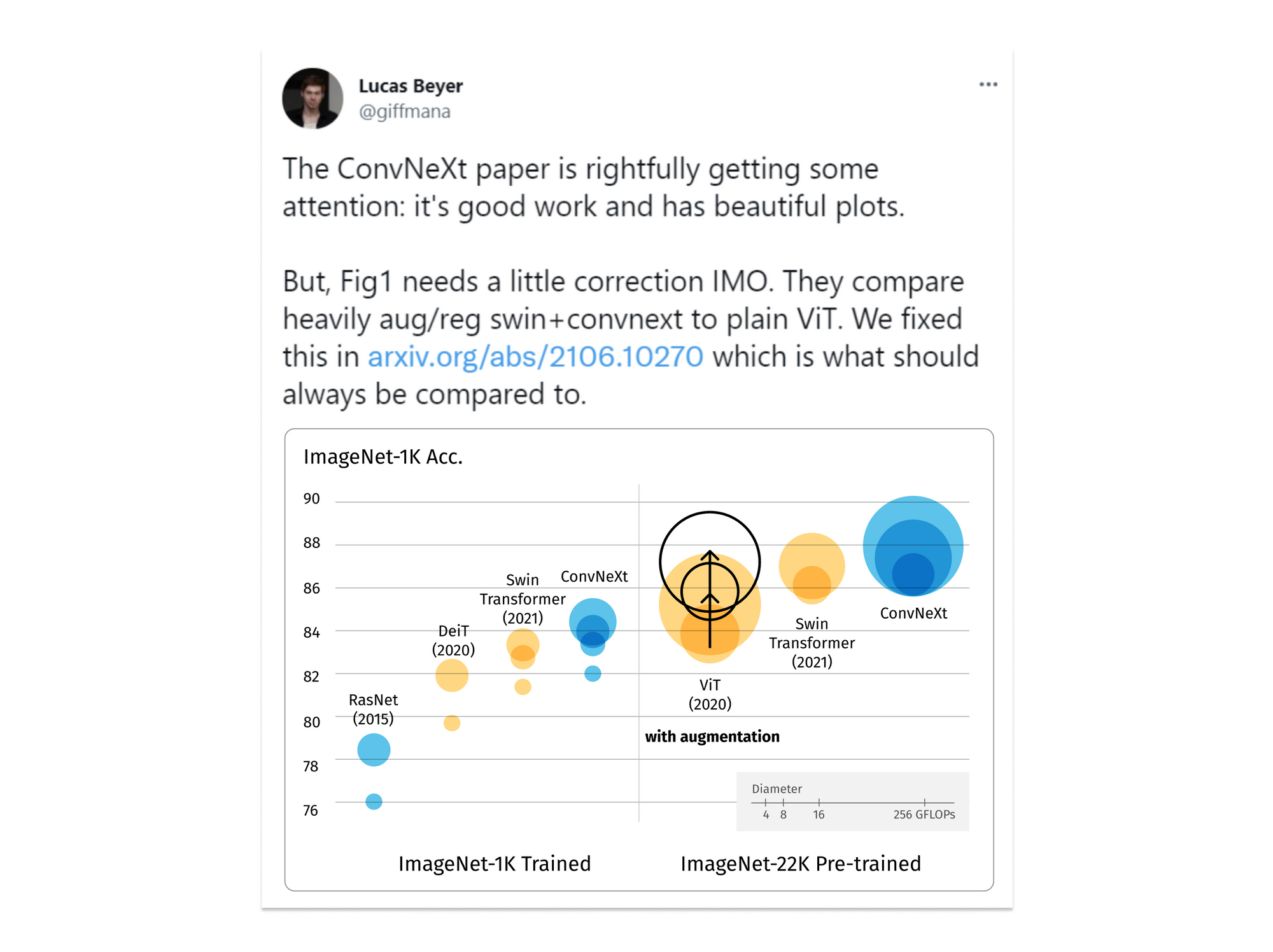
Depicted in the figure above you can see an updated performance comparison between CNN (ConvNeXt) and transformer-based architectures (ViT, Swin) on ImageNet tasks. Before the ConvNeXt publication, in which the above (original) comparison was made, transformer-based architectures were SotA with relatively higher supremacy over CNN. Although ConvNeXt competes well with Transformers in terms of accuracy, robustness and scalability, Transformers surpass CNNs in many vision tasks due to their superior scaling behavior with multi-head self-attention being the key component.
According the ConvNeXt paper, in recent literature, system-level comparisons between CNN and Transformers (e.g. a Swin Transformer vs. a ResNet) show that they become different and similar at the same time: they are both equipped with similar inductive biases, but differ significantly in the training procedure and macro/micro-level architecture design. This implies that a significant portion of the performance difference between traditional CNN and Transformers may come down to the training techniques used.
If you are interested in details of transformer techniques from the NLP domain that helped to improve CNN architecture and the training process, we recommend reading the original ConvNeXt paper [1].
In this blog post we will cover the following architectures:
- Image-GPT
- Vision Transformer
- Swin
- DETR
- VirTex
- DALLE
- DINO
- CLIP
- Long-Short Transformer
- Trans-Unet
- DeiT
We will also discuss some alternative approaches derived from the SA mechanism:
- Lambda networks
- Involution
- MViT
Tasks like image capturing and image restoration (generation) need long term attention; that's why it is worthwhile for CV specialists to fully understand the self-attention concept and its derivatives that appeared first in NLP.
Prerequisites for this blog
To fully understand and benefit from this blog post, the reader should be at least somewhat familiar with the SA mechanism and Transformer architecture. Below we provide some references and visualizations to help interested readers recall the details:
- To better understand SA, we recommend starting with this video: Attention is All You Need [2].
- Before we start discussing specific architectures, please take a look at the collage below depicting the main formulas and figures taken from the essential paper entitled Attention is all you need [3].
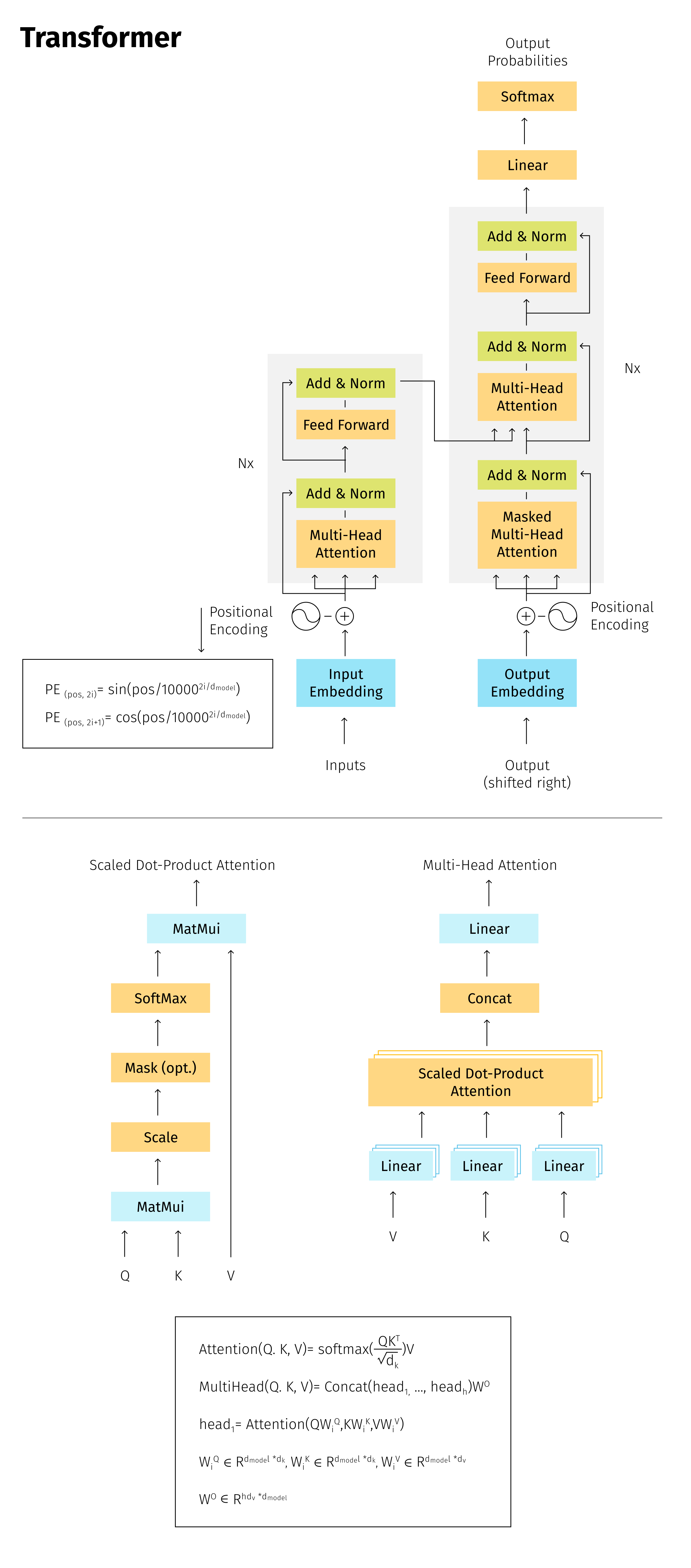
Below are some visualizations from a video based on the Attention is all you need paper: Transformer (Attention is all you need) [2]. This should help you recall the technical details under the hood of the SA mechanism.
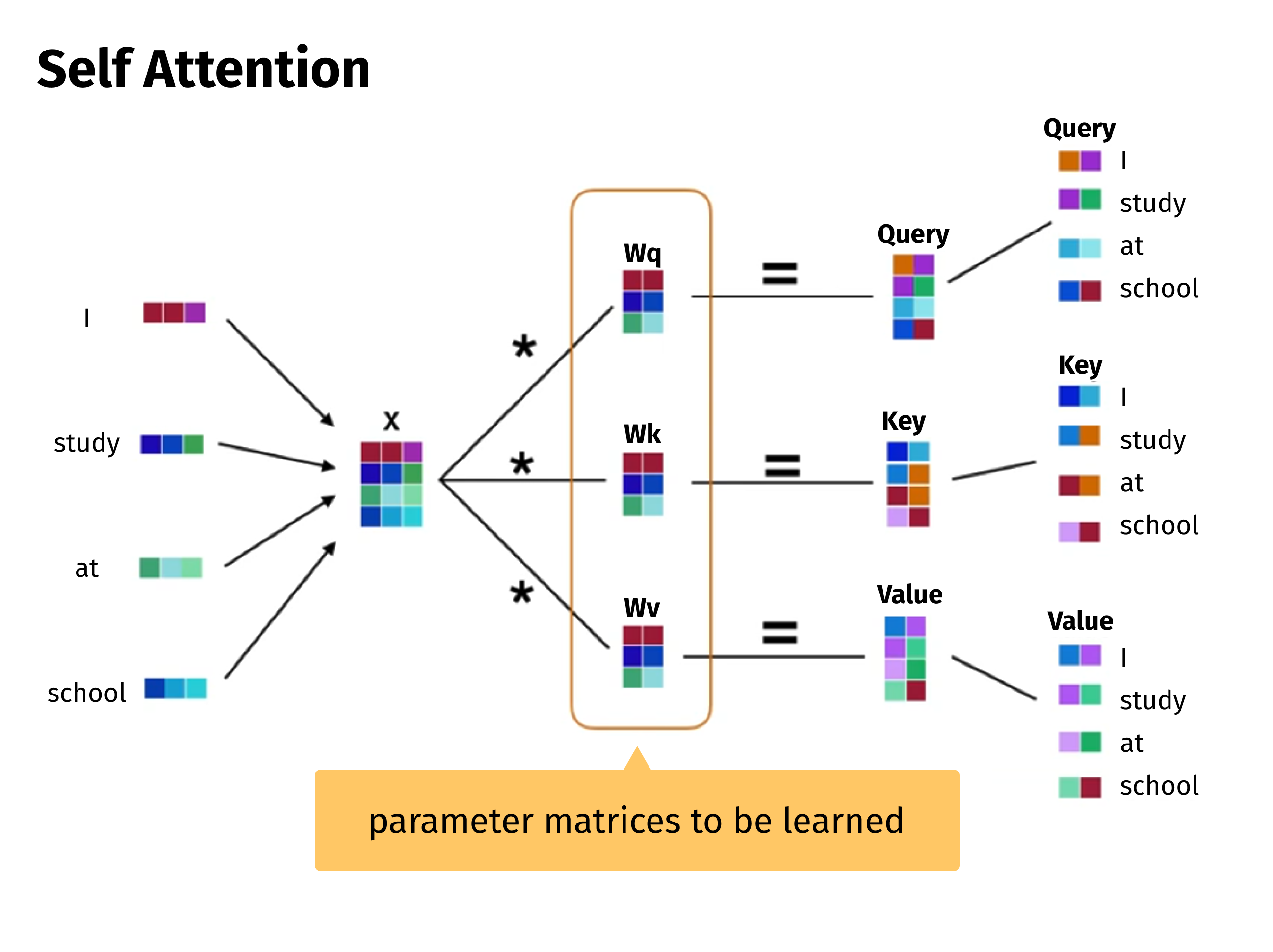
![These figures contain context-aware intuition of SA. From the technical standpoint, SA is still a matrix multiplication operation, where weight matrix is learnt during model training. This means that SA allows for context-aware processing and making use of GPUs at the same time, contrary to vanilla recurrent networks. [3]](https://grid-dynamics-blog.ghost.io/content/images/2022/04/Frame-5581--1-.png)
![The Encoder Layer of the Transformer. [3]](https://grid-dynamics-blog.ghost.io/content/images/2022/04/Frame-5582--1-.png)
![In the Decoder, all words on the right side are masked. [3]](https://grid-dynamics-blog.ghost.io/content/images/2022/04/Frame-5583.png)
![Decoder layer [3]](https://grid-dynamics-blog.ghost.io/content/images/2022/04/Frame-5584.png)
Now that we have recalled the essentials of the SA mechanism and Transformer architecture, let’s proceed with discussing Transformer- or SA-based architectures applied in the CV domain.
Transformer-based approaches in CV
ViT
According to the paper, An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale [4], a pure transformer applied directly to sequences of image patches can perform very well on image classification tasks. When pre-trained on large amounts of data and transferred to multiple mid-sized or small image recognition benchmarks (ImageNet, CIFAR-100, VTAB, etc.), Vision Transformer (ViT) attains excellent results compared to SotA convolutional networks while requiring substantially fewer computational resources to train.
![This model design represents the first attempts to apply Transformers in CV. As you can see, it is fairly straightforward - word embeddings are substituted with flattened image patches. [4]](https://grid-dynamics-blog.ghost.io/content/images/2022/04/Frame-5585.png)
And this is how the first Vision Transformer (ViT) came to be. Compared to the NLP Transformer, there is only one minor change: locations of Normalization layers are different. For pretraining, ViT uses a masked LM approach in the same way BERT does.
At the time of this publication, as mentioned, ViT had superior performance to SotA CNN models in classification tasks: ResNet and EfficientNet. Although, as most Transformers are, this is also quite a heavy model.
Image GPT
Inspired by progress in unsupervised representation learning for natural language, the paper, Generative Pretraining from Pixels [5], examines whether similar models can learn useful representations for images. Image GPT enhances straightforward adaptation of transformers with pre-training of an autoregressive and masked language model for pixels’ sequences. This helps the model to regenerate the missing part of the picture from the starting patch.
Other than that, it is roughly the same approach as ViT:
- An image is split into patches for attention;
- The patches are flattened with learnable Linear Projection.
To reduce complexity of the model, the authors utilized their own 9-bit color palette to represent pixels. The authors also apply a Linear probing method to choose the most suitable layer for feature extraction. This method is widely used in many of the architectures that are described below. Its main idea is that an optimal layer for feature extraction can be selected by building a simple linear classifier on each layer and comparing the performance of the received models.
At the time of publication, Image GPT beats CNNs on CIFAR-10/100 and shows a comparable performance on ImageNet, semi-supervised learning.

Swin Transformer
The Swin Transformer: Hierarchical Vision Transformer using Shifted Windows [6] paper presents a new vision Transformer, called Swin Transformer, that serves as a general-purpose backbone for computer vision.
As the name of the paper suggests, the Swin Transformer combines the Hierarchical Vision Transformer and the Shifted Windows approach, and achieves impressive results in segmentation as depicted below:
- ADE20K semantic segmentation: #1 for single model (53.9 mloU)
- The largest and most difficult segmentation benchmark
- 20,000 training images, 150 categories
- Significantly surpass all previous CNN models (+5.5 mloU vs. the previous best CNN model)
- COCO object detection: #1 #2 #3 for single model (60.6 mAP)
- Significantly surpass all previous CNN models (+3.5 mAP)
- COCO instance segmentation: #1 for single model (52.4 mAP)
- Significantly surpass all previous CNN models (+3.3 mAP)
The main idea of the model architecture is utilization of a Shifted Window for self attention. This idea allows for wider context without increasing the complexity of a model. For a better understanding of how it works, examine the diagram below:
![In layer l (left), a regular window partitioning scheme is adopted, and self-attention is computed within each window. In the next layer l + 1 (right), the window partitioning is shifted, resulting in new windows. The self-attention computation in the new windows crosses the boundaries of the previous windows in layer l, providing connections among them. [6]](https://grid-dynamics-blog.ghost.io/content/images/2022/04/Frame-5589.png)
![The proposed Swin Transformer builds hierarchical feature maps by merging image patches (shown in gray) in deeper layers and has linear computation complexity to input image size due to computation of self-attention only within each local window (shown in red). It can thus serve as a general-purpose backbone for both image classification and dense recognition tasks. [6]](https://grid-dynamics-blog.ghost.io/content/images/2022/04/Frame-5590.png)
The hierarchical representation - Merging 2 neighboring patches (words) at each stage - is depicted below:
![Hierarchical representation [6]](https://grid-dynamics-blog.ghost.io/content/images/2022/04/Frame-5591-1.png)
The main advantage of Swin compared with ViT is that SA is local, therefore, the complexity of the architecture is linear.
DETR: DEtection TRansformer
The End-to-End Object Detection with Transformers [7] paper presents a new method that views object detection as a direct set prediction problem. DEtection TRansformer, or DETR, is an example of a mixed architecture: CNN + SA, that shows comparable performance with SotA results in object detection. In this architecture, the object detection is formulated as a task of mapping an image to a set of detections (see diagram below):
![ResNet feature extraction (2d) is combined with positional spatial encoding to obtain input for a transformer part. The transformer processes limited-length sequences and, having an object query, produces the output. That output is consumed by a prediction head which generates the final output. [7]](https://grid-dynamics-blog.ghost.io/content/images/2022/04/Frame-5592-1.png)
The inference process requires learned object queries (1 for each class) which are taken as input for the decoder. An important advantage of the model is that inference provides not only detections, but also reasoning (attention mask) simultaneously.
Implementation in PyTorch is pretty simple:
class DETR(nn.Module):
def __init__(self, num_classes, hidden_dim, nheads,
num_encoder_layers, num_decoder_layers):
super().__init__()
# We take only convolutional layers from ResNet-50 model
self.backbone = nn.Sequential(*list(resnet50(pretrained=True).children())[:-2])
self.conv = nn.Conv2d(2048, hidden_dim, 1)
self.transformer = nn.Transformer(hidden_dim, nheads,
num_encoder_layers, num_decoder_layers)
self.linear_class = nn.Linear(hidden_dim, num_classes + 1)
self.linear_bbox = nn.Linear(hidden_dim, 4)
self.query_pos = nn.Parameter(torch.rand(100, hidden_dim))
self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
def forward(self, inputs):
x = self.backbone(inputs)
h = self.conv(x)
H, W = h.shape[-2:]
pos = torch.cat([
self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1),
self.row_embed[:H].unsqueeze(1).repeat(1, W, 1),
], dim=-1).flatten(0, 1).unsqueeze(1)
h = self.transformer(pos + h.flatten(2)permute(2, 0, 1),
self.query_pos.unsqueeze(1))
return self.linear_class(h), self.linear_bbox(h).sigmoid()
DETR for Panoptic Segmentation
The Panoptic segmentation task is a combined task of instance and semantic segmentation, thus, custom metrics specific to the panoptic segmentation formulation should be applied. DETR architecture is applicable to this task and demonstrates results comparable to SotA.
The technical approach is not very complicated:
- A separate segmentation head is trained after the detection model or along with it.
- The encoder is applied to each detection and Multi-Head Attention (MHA) builds binary heatmaps in low resolution for each.
- Then, FPN-style CNN is utilized to increase the resolution.
Depicted below is an example of MHA binary heatmaps in low resolution over the output of the encoder:
![Example of MHA binary heatmaps in low resolution over the output of the encoder [7]](https://grid-dynamics-blog.ghost.io/content/images/2022/04/Frame-5593-1.png)
VirTex
The VirTex: Learning visual representations using textual annotations [8] paper shows an approach of how joint training of CNN + Transformer on a dense image captioning task can help with other CV tasks. The idea is to transfer a trained feature extractor to other applications. The training process has a particularity: autoregressive LM (not masked) with 2 directions: forward and backward is trained.
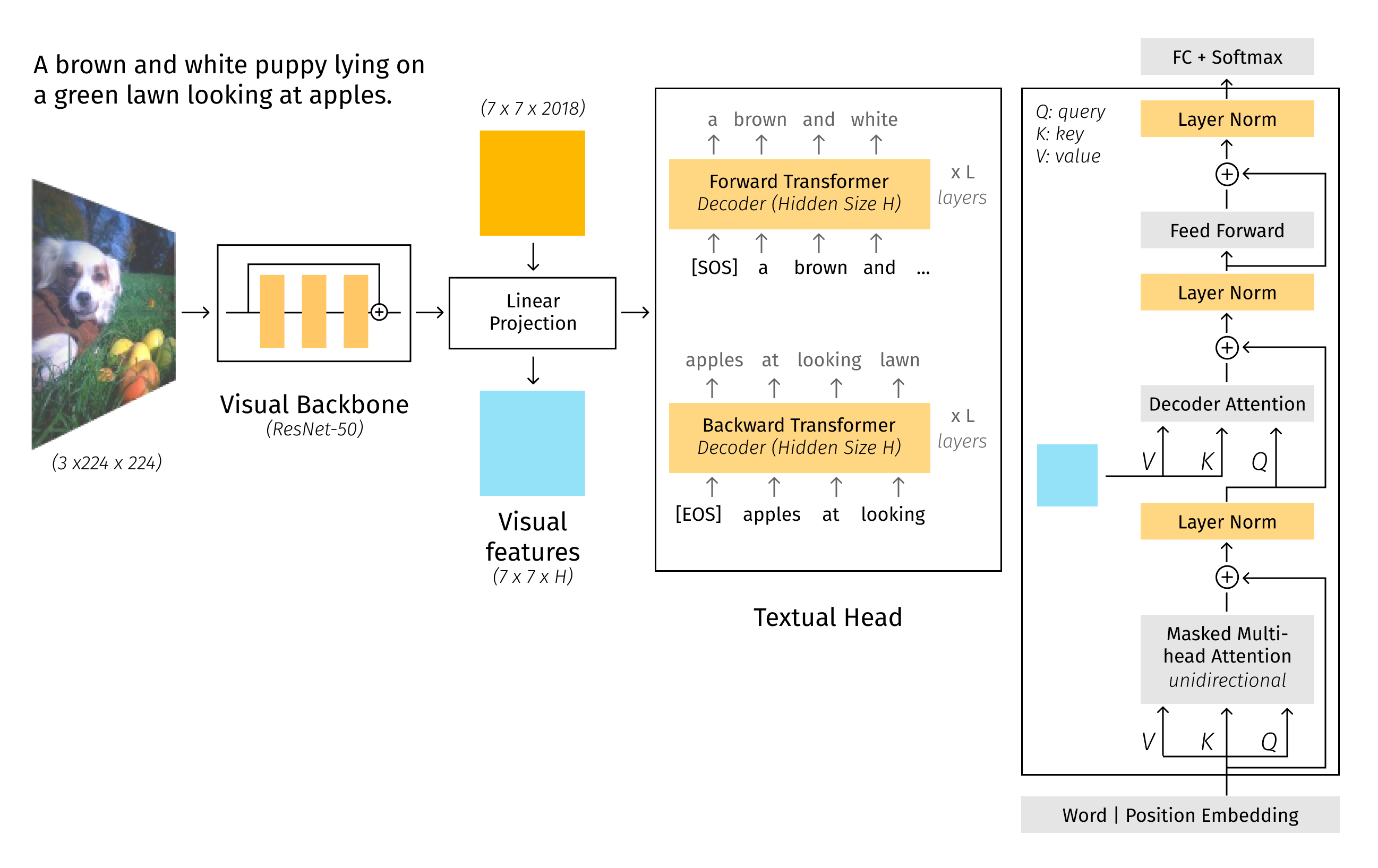
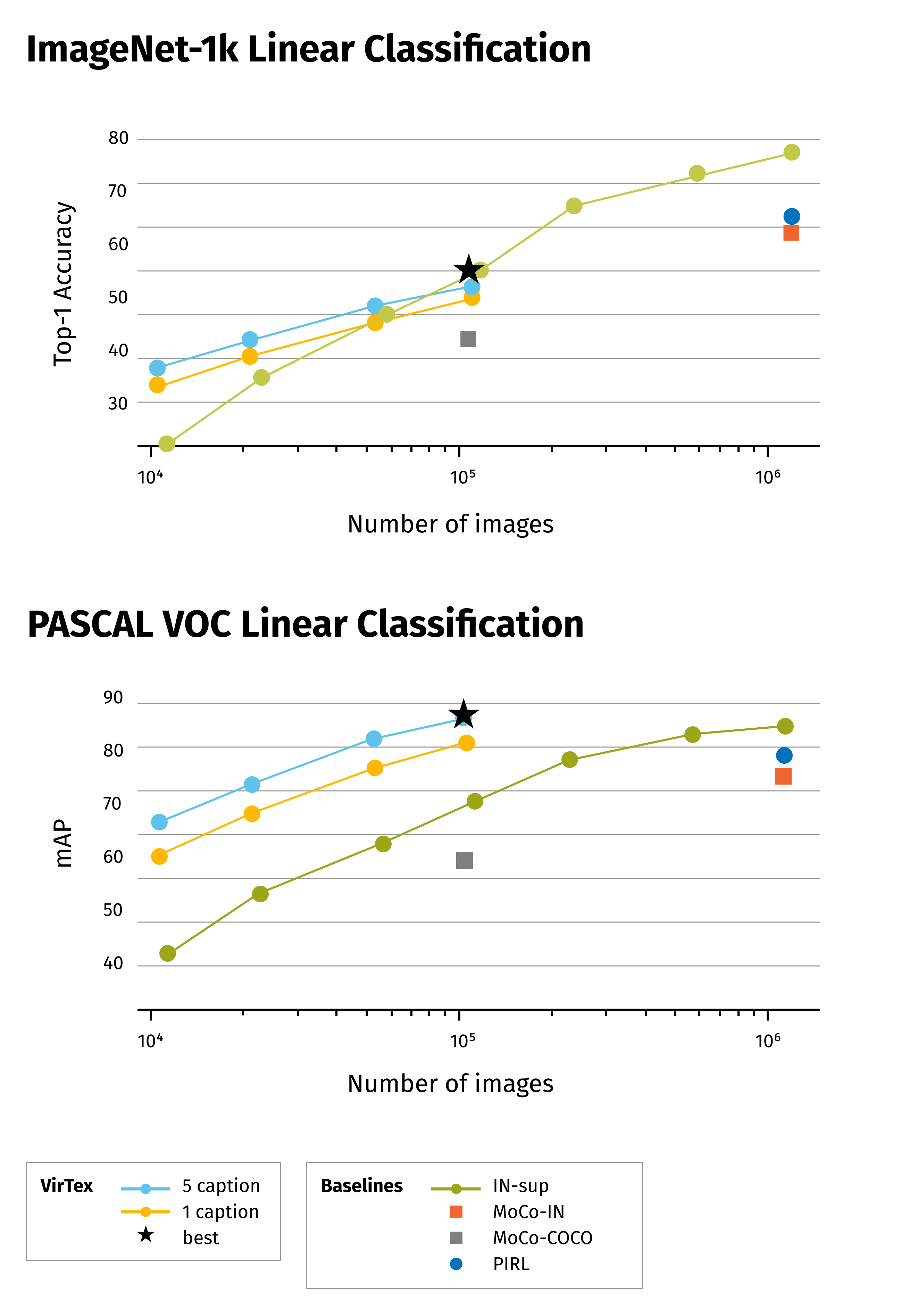
![VirTex examples [8]](https://grid-dynamics-blog.ghost.io/content/images/2022/04/Frame-5600-1.png)
The paper claims that visual features from VirTex are more data-efficient.
DALL-E
DALL-E [9]is a famous architecture presented by OpenAI that shows impressive capabilities in image generation from text input. It’s training process consists of two stages:
- Stage 1. Train a discrete variational autoencoder (dVAE) to compress each 256×256 RGB image into a 32 × 32 grid of image tokens, each element of which can assume 8192 possible values;
- Stage 2. Concatenate up to 256 BPE-encoded text tokens (16384 vocab size) with the 32 × 32 = 1024 image tokens, and train an autoregressive transformer (decoder GPT style).
![Image generation from a textual description [9]](https://grid-dynamics-blog.ghost.io/content/images/2022/04/Frame-5601.png)
DALL-E uses three kinds of sparse attention masks, which are shown below. The convolutional attention mask is only used in the last self-attention layer: “row, column, row, row”... “conv”
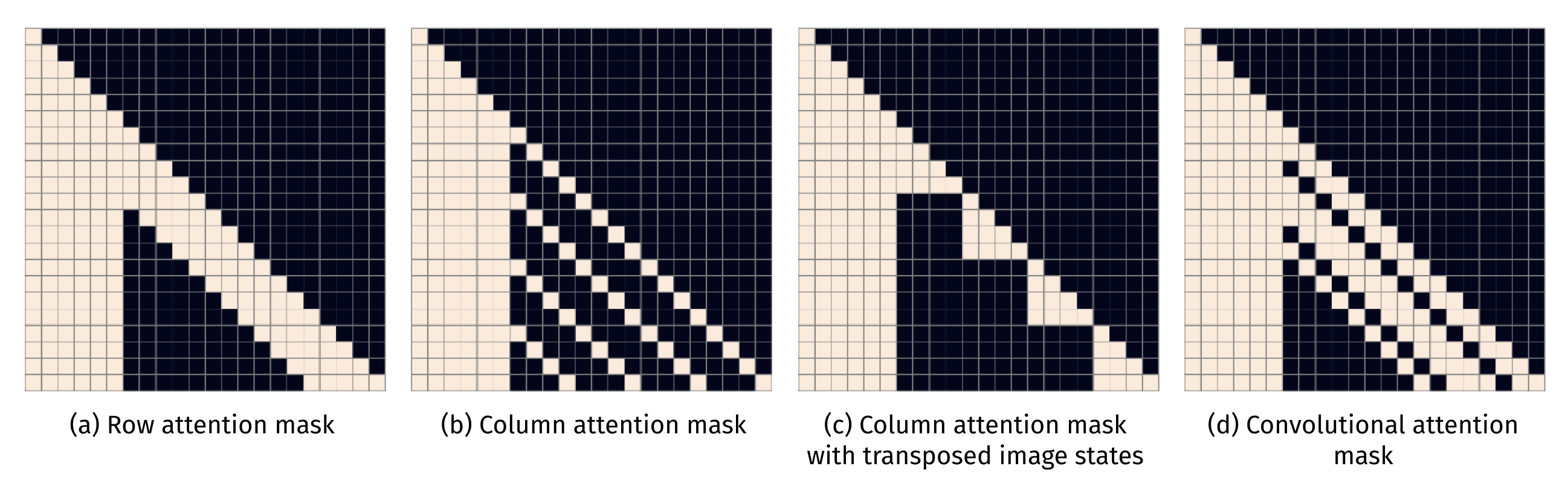
Preliminary experiments for models up to 1.2 billion parameters were carried out on Conceptual Captions, a dataset of 3.3 million text-image pairs that was developed as an extension to MS-COCO.
For a model with 12-billion parameters, OpenAI created a dataset of a similar scale to JFT-300M by collecting 250 million text-images pairs from the internet.
DINO
DINO [10] is a simple self-supervised approach that can be interpreted as a form of knowledge distillation with no labels. With this approach, two models are trained: teacher and student networks. Both networks have the same architecture but different parameters. Teacher parameters are updated with an exponential moving average (ema) of the student parameters, and the models are trained to output similar representations.
An important particularity of the approach is that two different random transformations of an input image are passed to the student and teacher neural networks.
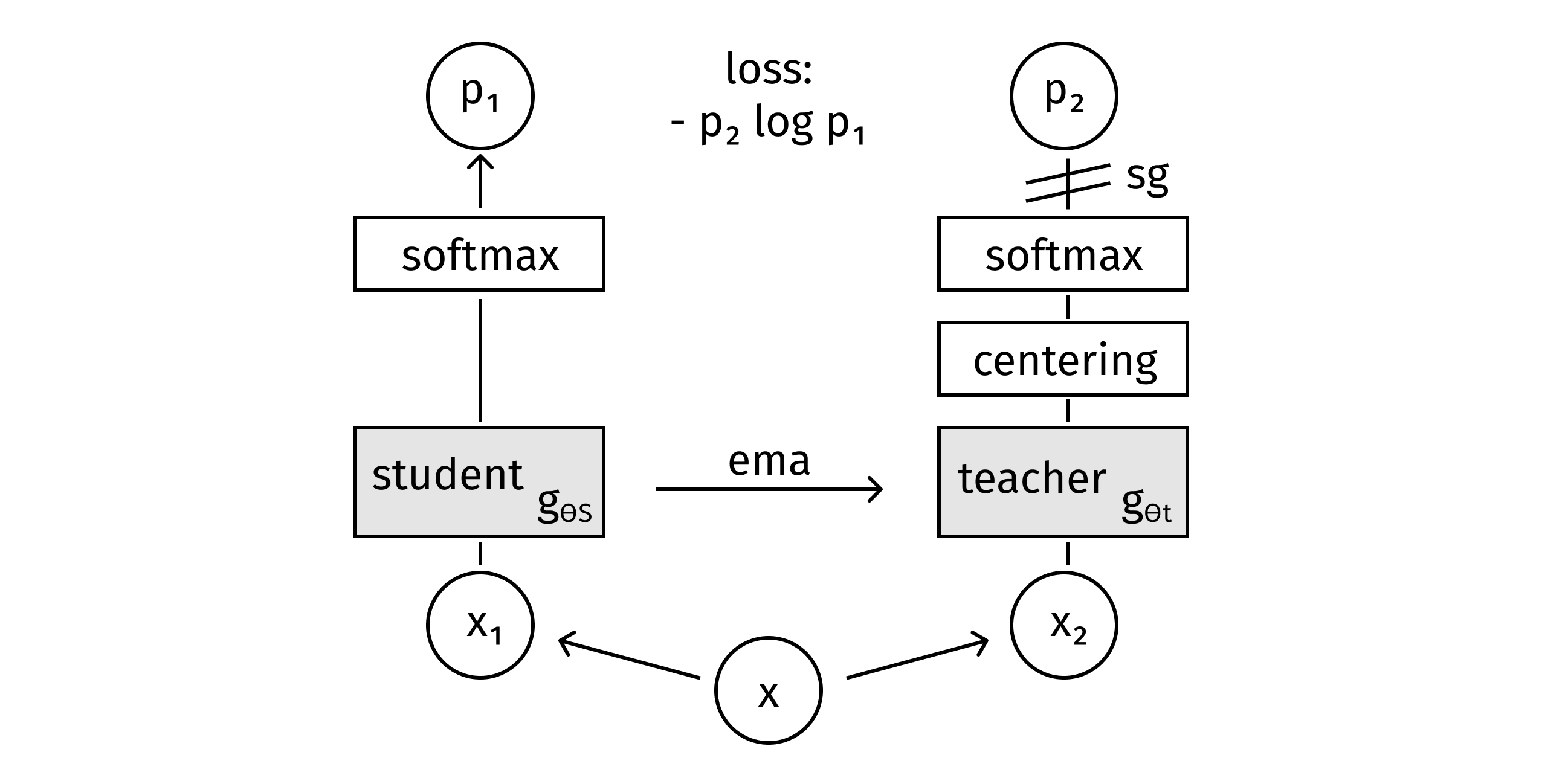
Algorithm 1 DINO PyTorch pseudocode w/o multi-crop.
# gs, gt: student and teacher networks
# C: center (K)
# tps, tpt: student and teacher temperatures
# l, m: network and center momentum rates
gt.params = gs.params
for x in loader: #load a minibatch x with n samples
x1, x2 = augment(x), augment(x) # random views
s1, s2 = gs(x1), gs(x2) # student output n-by-K
t1, t2 = gt(x1), gt(x2) # teacher output n-by-K
loss = H(t1, s2)/2 + H(t2, s1)/2
loss.backward() # back-propagate
# student, teacher and center updates
update(gs) # SGD
gt.params = 1*gt.params + (1-1)*gs.params
C = m*C + (1-m)*cat([t1, t2]).mean(dim=0)
def H(t,s):
t = t.detach() # stop gradient
s = softmax(s / tps, dim=1)
t = softmax([t - C] / tpt, dim=1) # center + sharpen
return - (t * log(s)).sum(dim=1).mean()
Attention maps learned by DINO (without target masks!) can be interpreted as a mask of main object(s) on a picture:

More impressive visualizations can be found in the following videos: DINO and PAWS: Advancing the state of the art in computer vision [11].
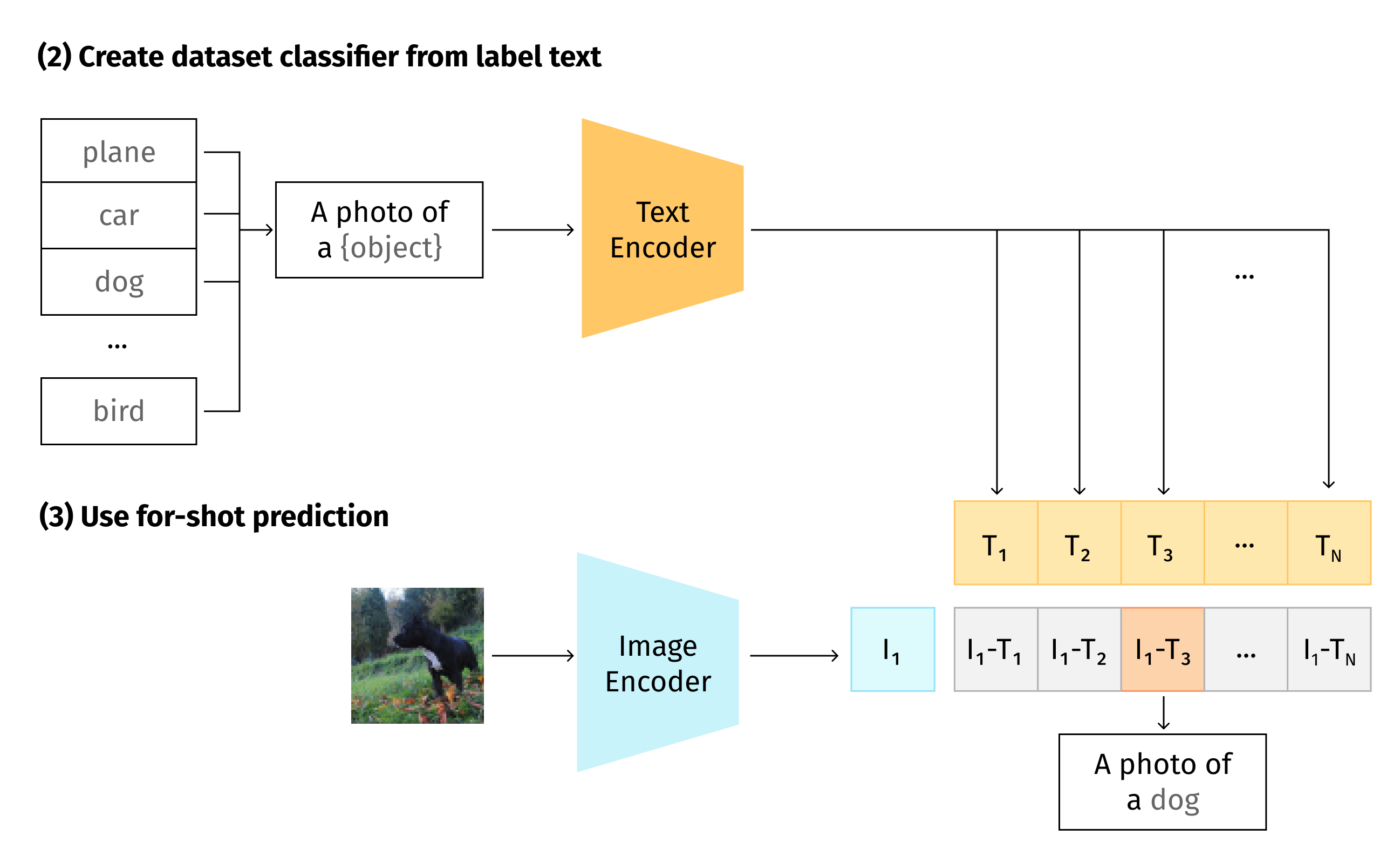
CLIP
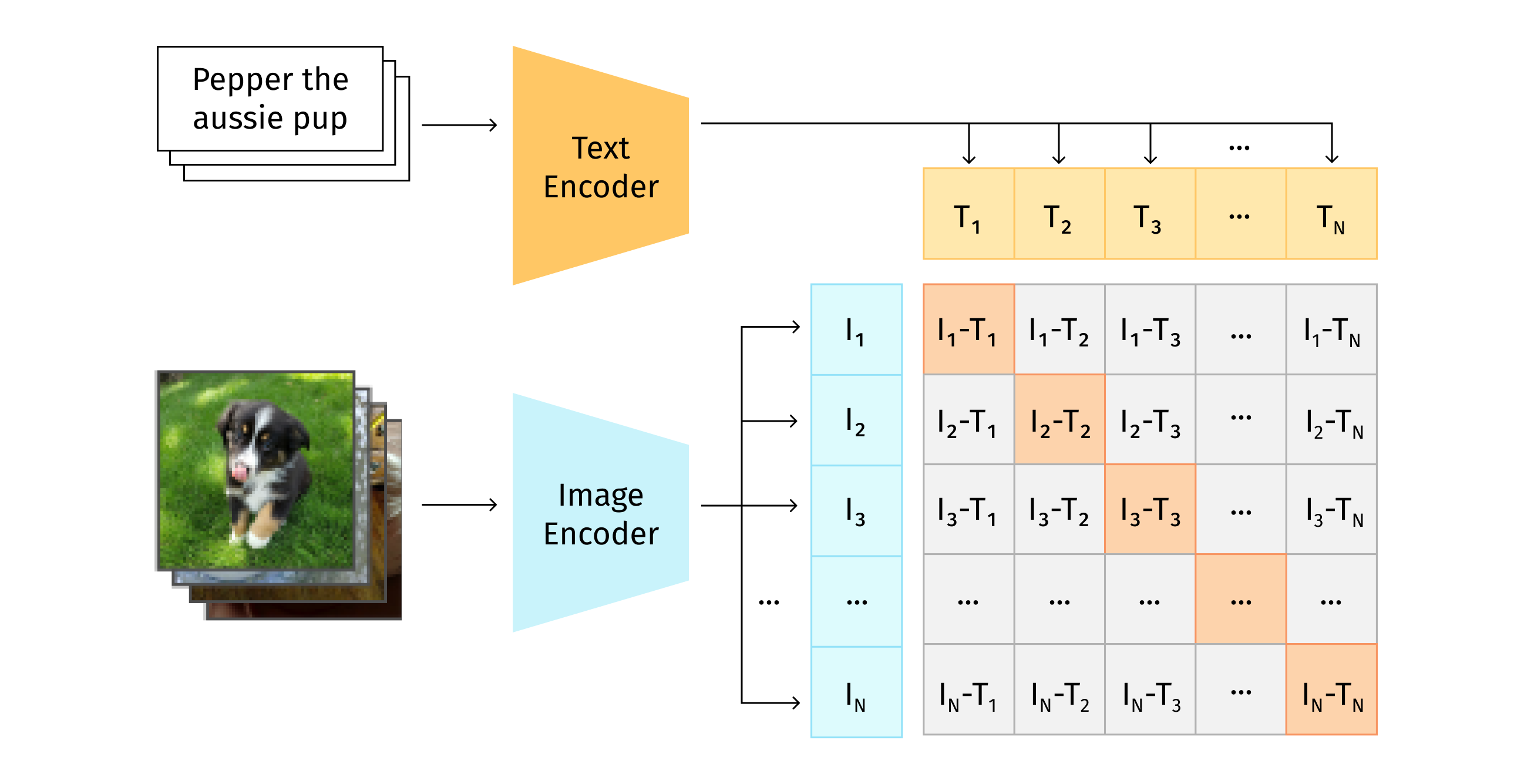
Contrastive Language-Image Pre-training, or CLIP [12], is an efficient method of learning from natural language supervision. CLIP is trained on 400 million image-caption pairs. In the inference process it predicts the most relevant text given an image. That is, this is a zero-shot learning approach - a model trained on an image-captioning dataset that can be used for classification.
The CLIP training diagram is shown below:
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, 1] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
#t - learned temperature parameter
# extract feature representations of each modality
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(I) #[n, d_t]
# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
#scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
#symmetric loss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
CLIP jointly trains an image encoder and a text encoder to predict the correct pairings of a batch of (image, text) training examples. [12]
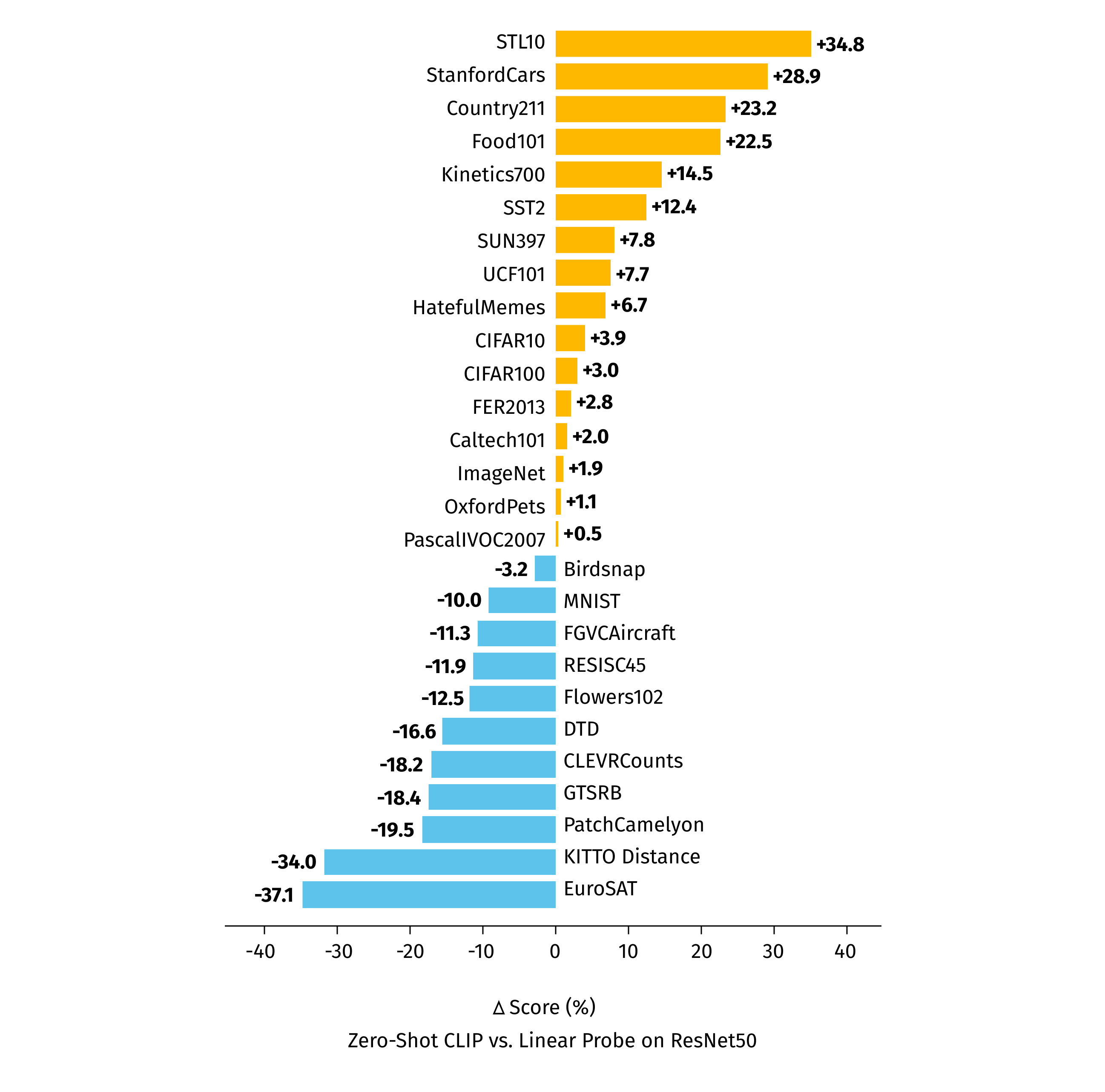
Depicted below is the CLIP inference diagram, along with the benchmark on different datasets. As you can see, CLIP outperforms ResNet50 on many benchmarks, but underperforms on others. So, even though this approach is not entirely superior, it can be useful in various situations.
Long-Short Transformer
The Long-Short Transformer [13] model is named after the short-term attention mechanism that uses windowed attention in the same way Longformer or BigBird do. Long term attention reduces dimensions for key and value matrices (K and V in the common Transformer notion), but reduces sequence length n -> r, and not the embedding size like Linformer does. Short- and long-term attentions are applied in parallel, and results are concatenated.
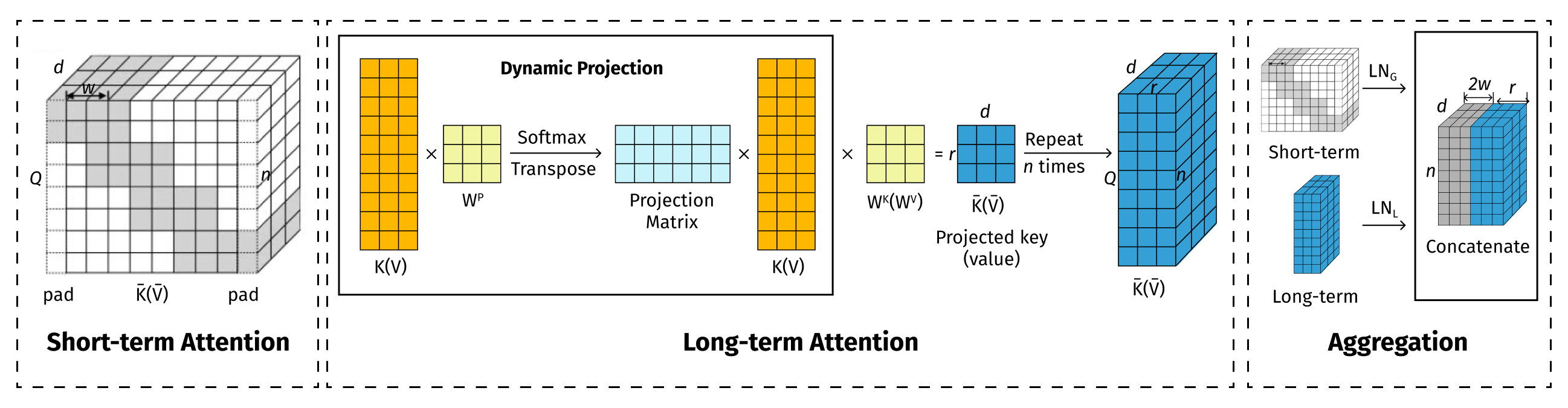

In the research paper, Long-Short Transformer: Efficient Transformers for Language and Vision [13], the above L-S Transformer model achieves the following performance results:
- Transformer-LS achieves 0.97 test BPC on enwik8 using half the number of parameters than the previous method, while being faster and is able to handle 3× as long sequences compared to its full-attention version on the same hardware.
- On ImageNet, it can obtain the state-of-the-art results (e.g., Top-1 accuracy 84.1% trained on 224 × 224 ImageNet-1K only), while being more scalable on high-resolution images.
TransUNet
The u-shaped architecture, also known as U-Net, has achieved tremendous success for medical image segmentation tasks; however, due to the intrinsic locality of convolution operations, U-Net generally demonstrates limitations in explicitly modeling long-range dependency. TransUNet, which combines the merits of both Transformers and U-Net, has proven to be a strong alternative for medical image segmentation, capable of achieving SotA results.
Main particularities of TransUNet:
- Image patches are encoded with Transformer encoder;
- A trainable linear projection to unroll patches;
- Positional embedding.
A full diagram of the model architecture is depicted below:
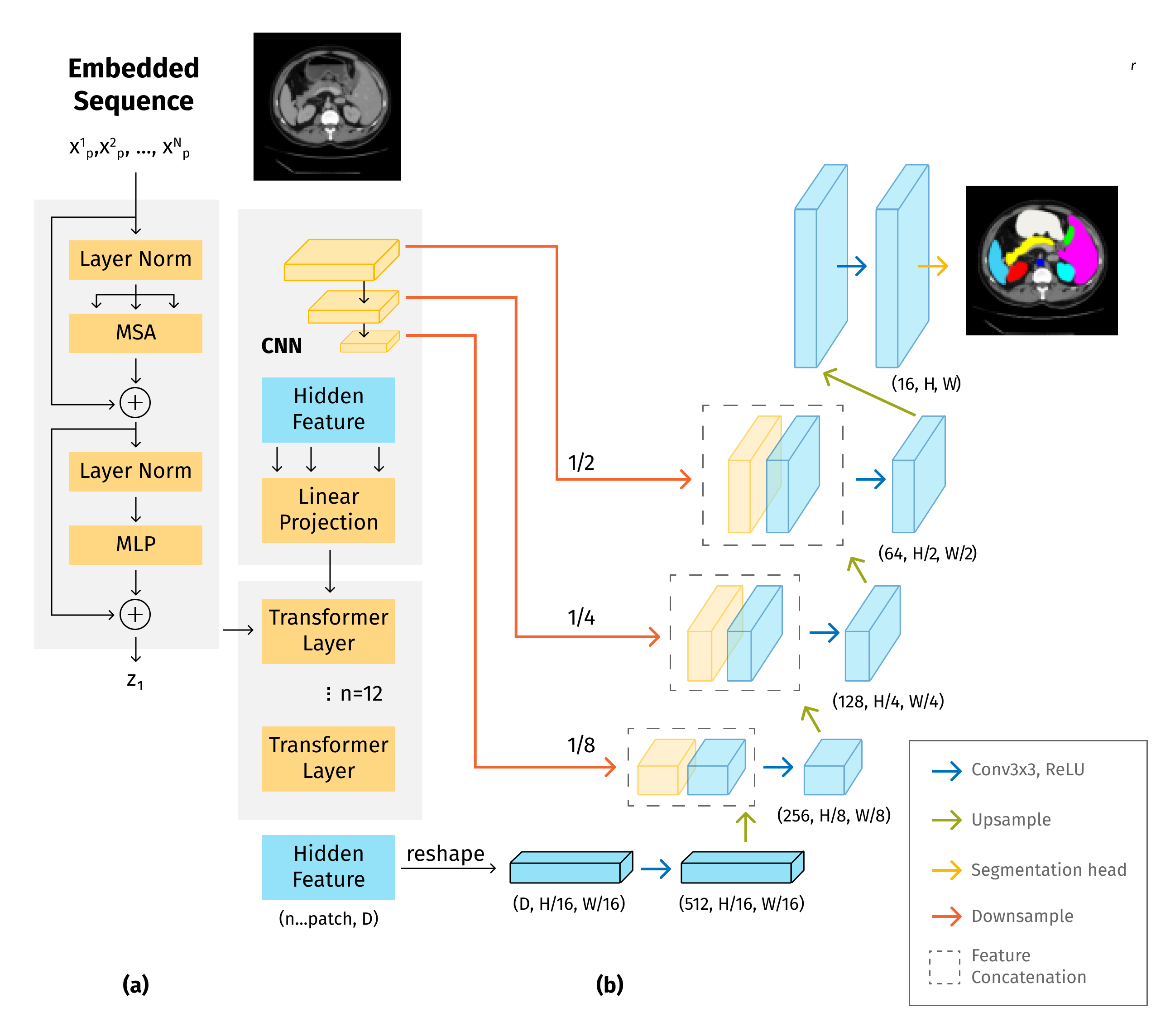
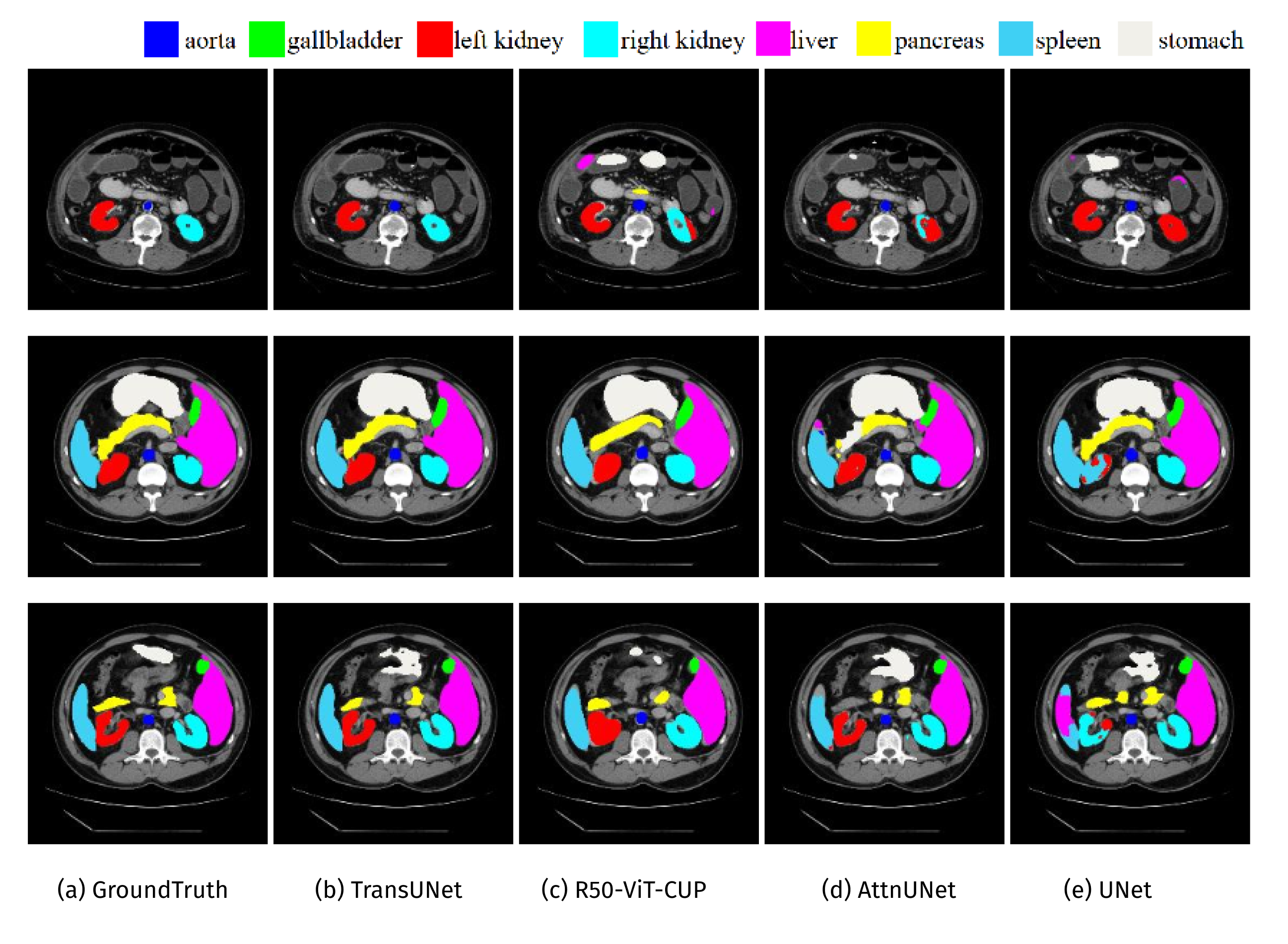
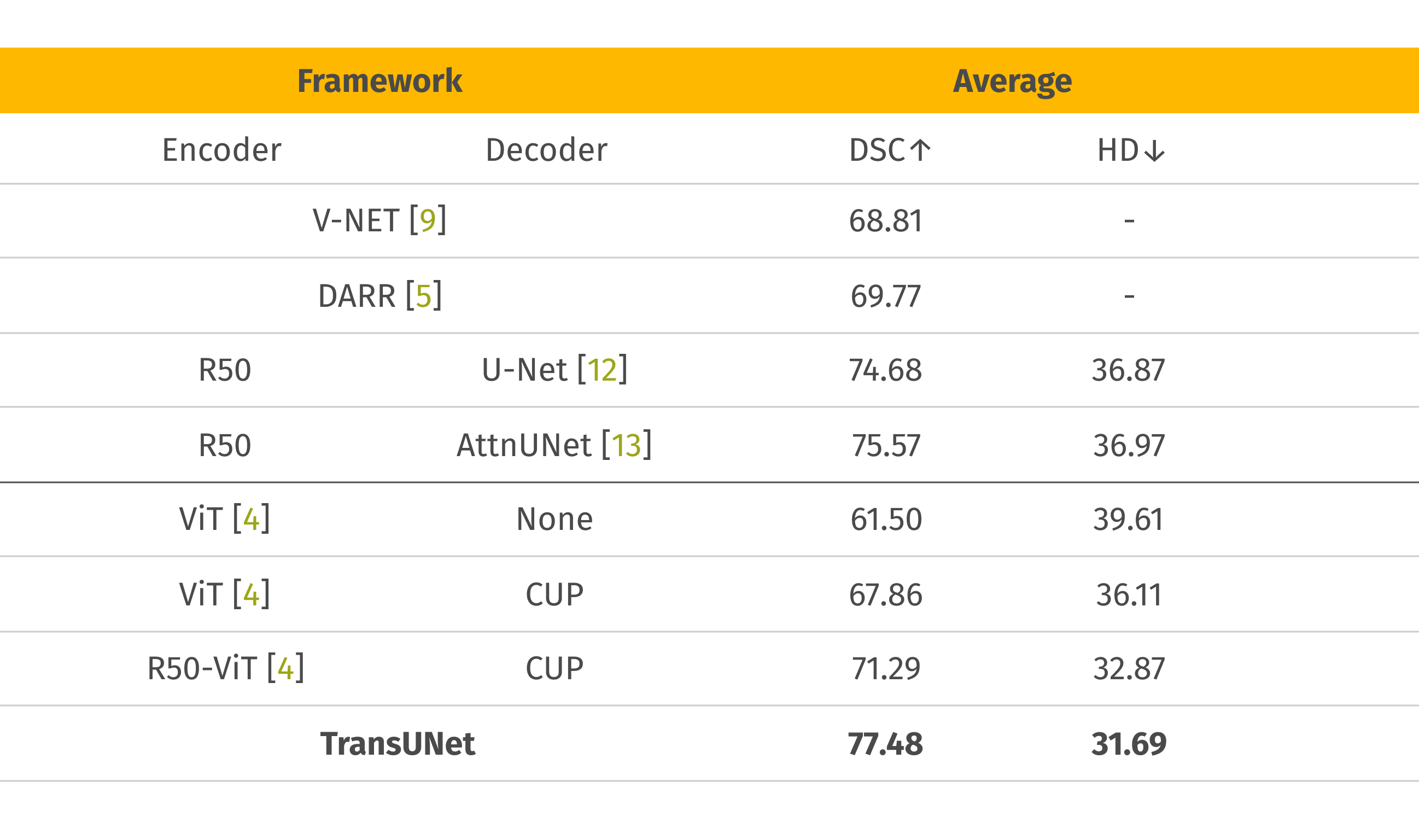
Dice score (DSC) and Hausdorff distance (HD)
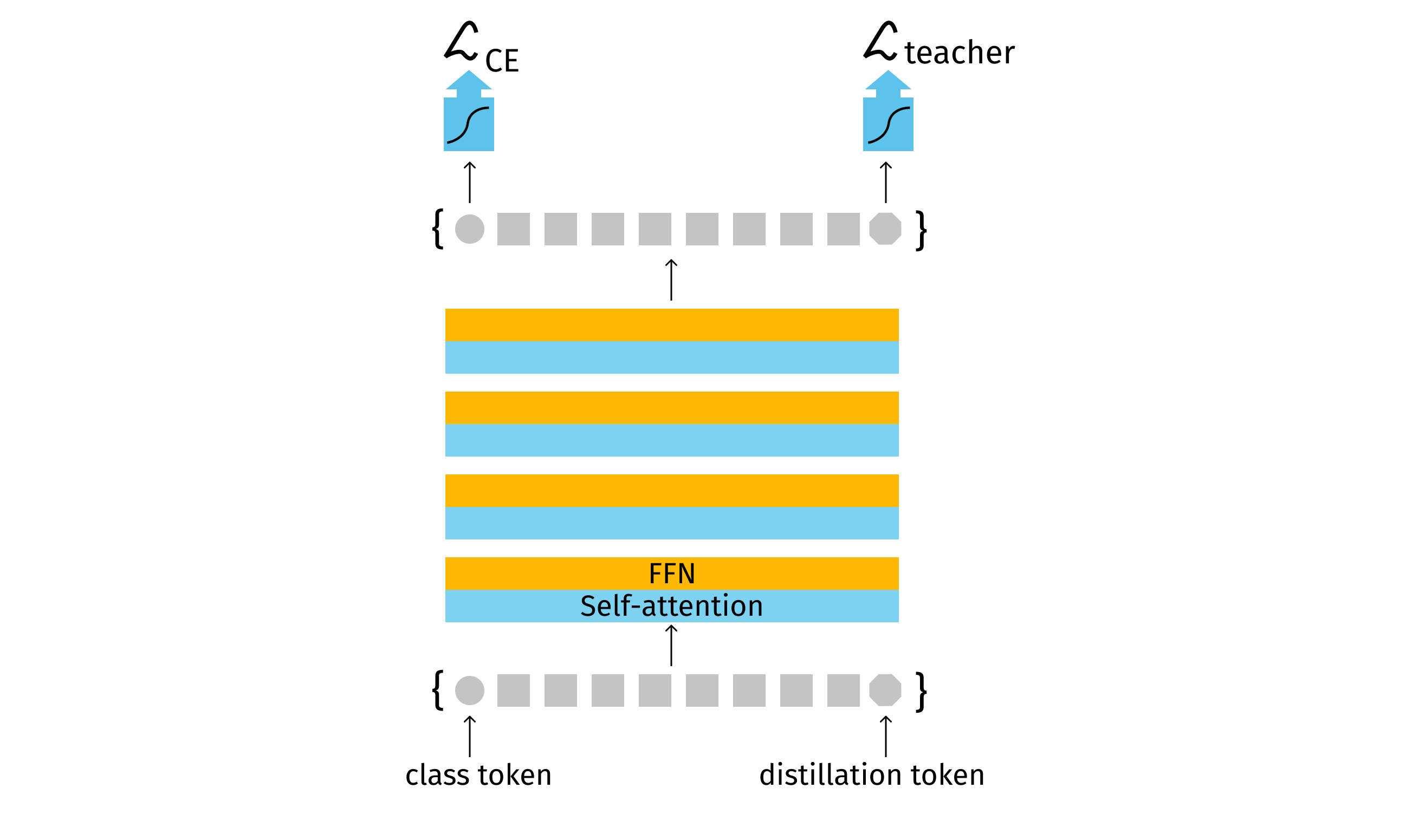
DeiT (Data-efficient Image Transformer)
As mentioned above, Transformer architectures are usually heavy and, thus, require huge training datasets to achieve a desired performance level. However, there are approaches to tackle this problem and Data-efficient Image Transformer, or, DeiT [15] is one of them. It achieves SotA classification performance with only 1.2M training images, which is impressive for a Transformer.
The trick of the DeiT approach is that the model learns from both the dataset and the teacher model - a common CNN-based architecture.
Trainable Classification and Distillation tokens are used to distinguish the prediction results and the prediction exposed to the teacher model.
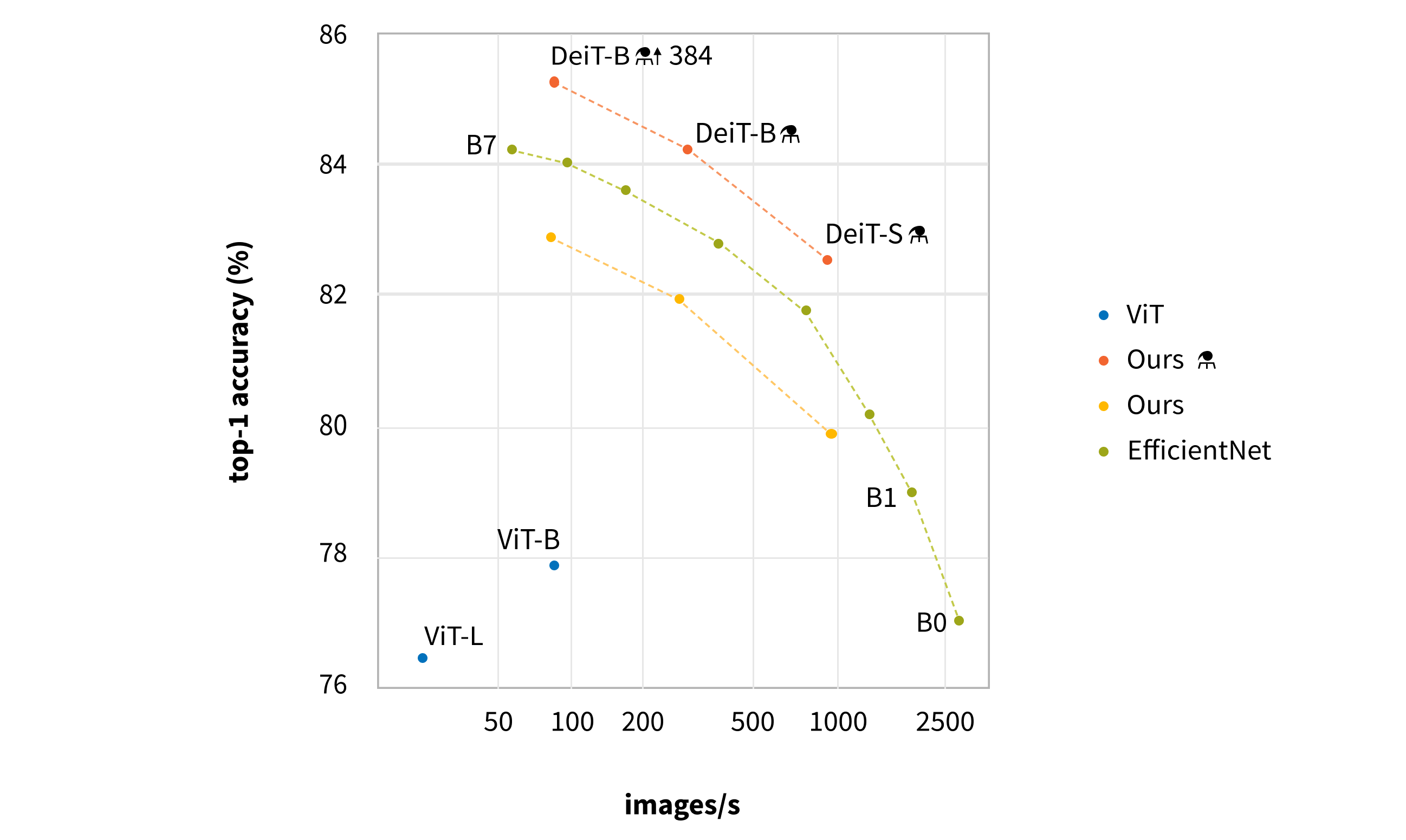
Throughput and accuracy for DeiT on Imagenet, trained on Imagenet-1k only:
Transformer-inspired architecture
As we can see, for a long time the mainstream approach was to apply SA to CV tasks. As a result, the Swin Transformer established SotA on various CV tasks. There were also attempts to combine CNN and SA, and as a result, TransUNet was established, which improved SotA on medical image segmentation tasks. A lot of researchers were inspired by the success of SA and tried to invent new types of attention or matrices manipulations. So let's discuss some alternative approaches: Lambda networks, involution, and MViT.
LambdaNetworks:
Lambda layers can be an alternative framework to self-attention for capturing long-range interactions between an input and structured contextual information (e.g. a pixel surrounded by other pixels). The resulting neural network architectures, LambdaNetworks, significantly outperform their convolutional and attentional counterparts on ImageNet classification, COCO object detection and COCO instance segmentation, while being more computationally efficient.
Modeling Long-Range Interactions Without Attention

Lambda Attention Mechanism
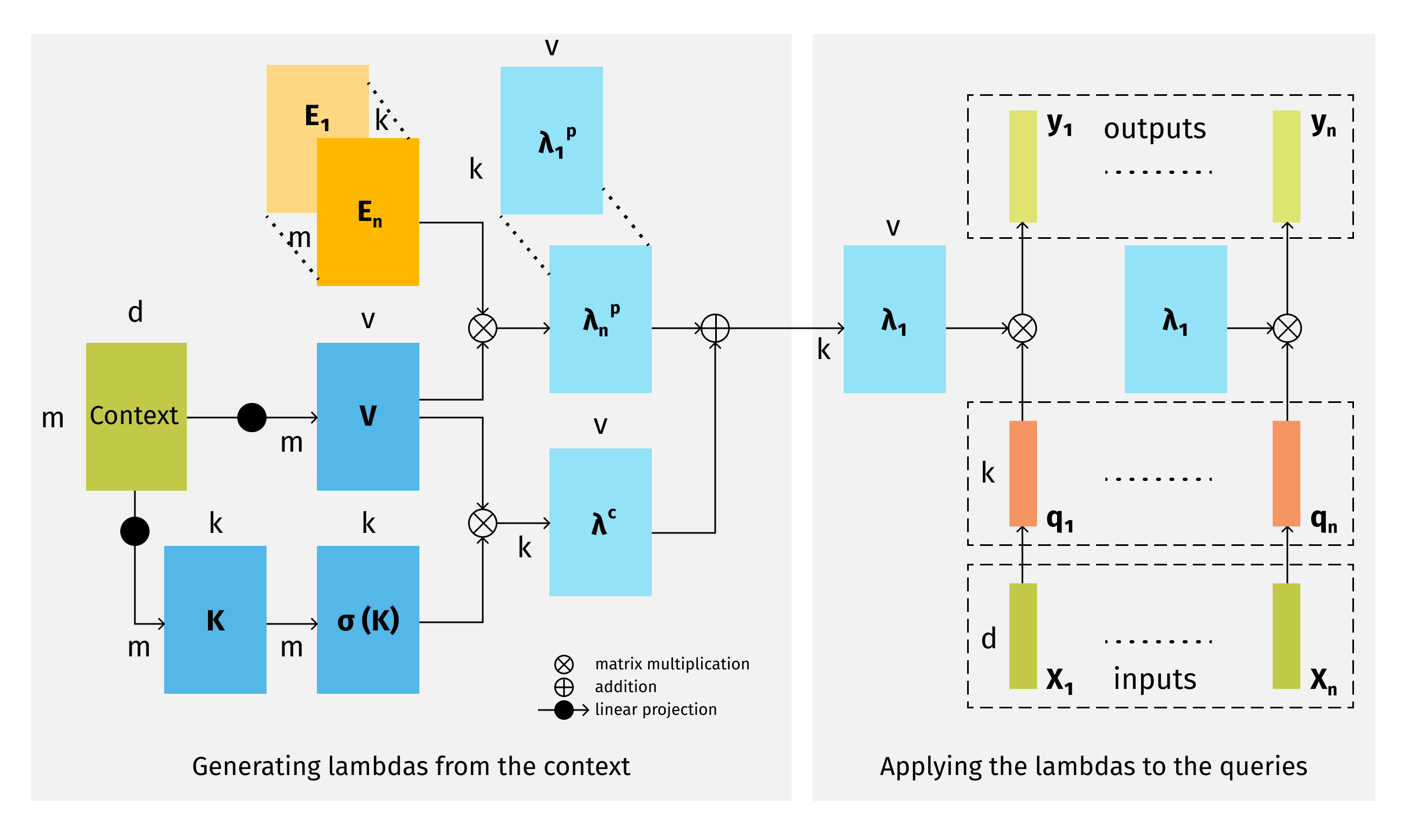

LambdaResNets, a family of hybrid architectures across different scales, considerably improves the speed-accuracy tradeoff of image classification models.
| Architecture | Params(M) | Train (ex/s) | Infer (ex/s) | ImageNet top-1 |
| LambdaResNet-152 | 51 | 1620 | 6100 | 86.7 |
| EfficientNet-B7 | 66 | 170 (9.5x) | 980 (6.2x) | 86.7 |
| ViT-L/16 | 307 | 180 (9.0x) | 640 (9.5x) | 87.1 |
RedNet: Involution
In the paper, Involution: Inverting the Inherence of Convolution for Visual Recognition [17], the authors present the concept of involution as an operation inverse to convolution:
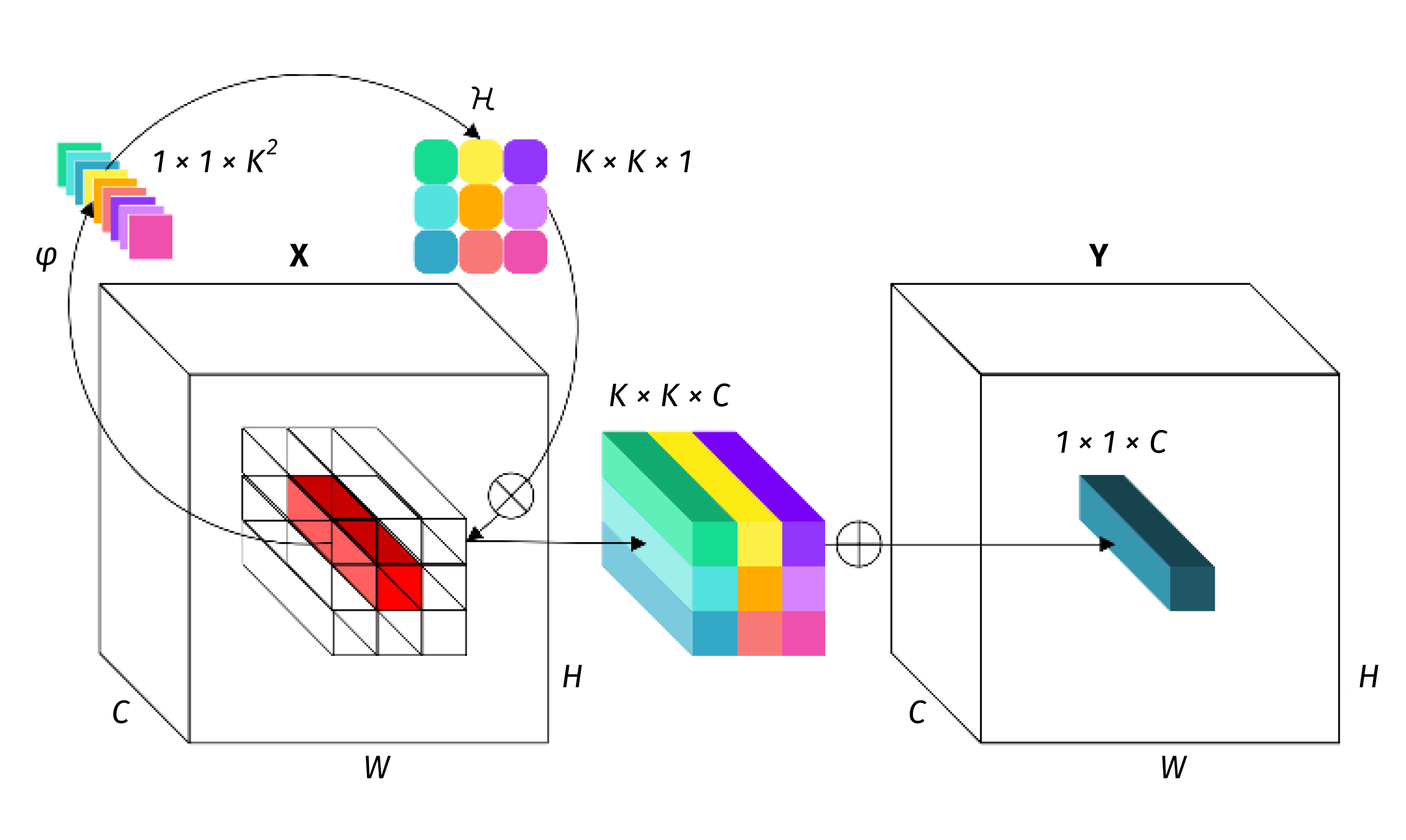
The authors claim that involution-based models improve the performance of convolutional baselines using ResNet-50 by up to 1.6% top-1 accuracy, 2.5% and 2.4% bounding box AP, and 4.7% mean IoU absolutely while compressing the computational cost to 66%, 65%, 72%, and 57% on the above benchmarks respectively.
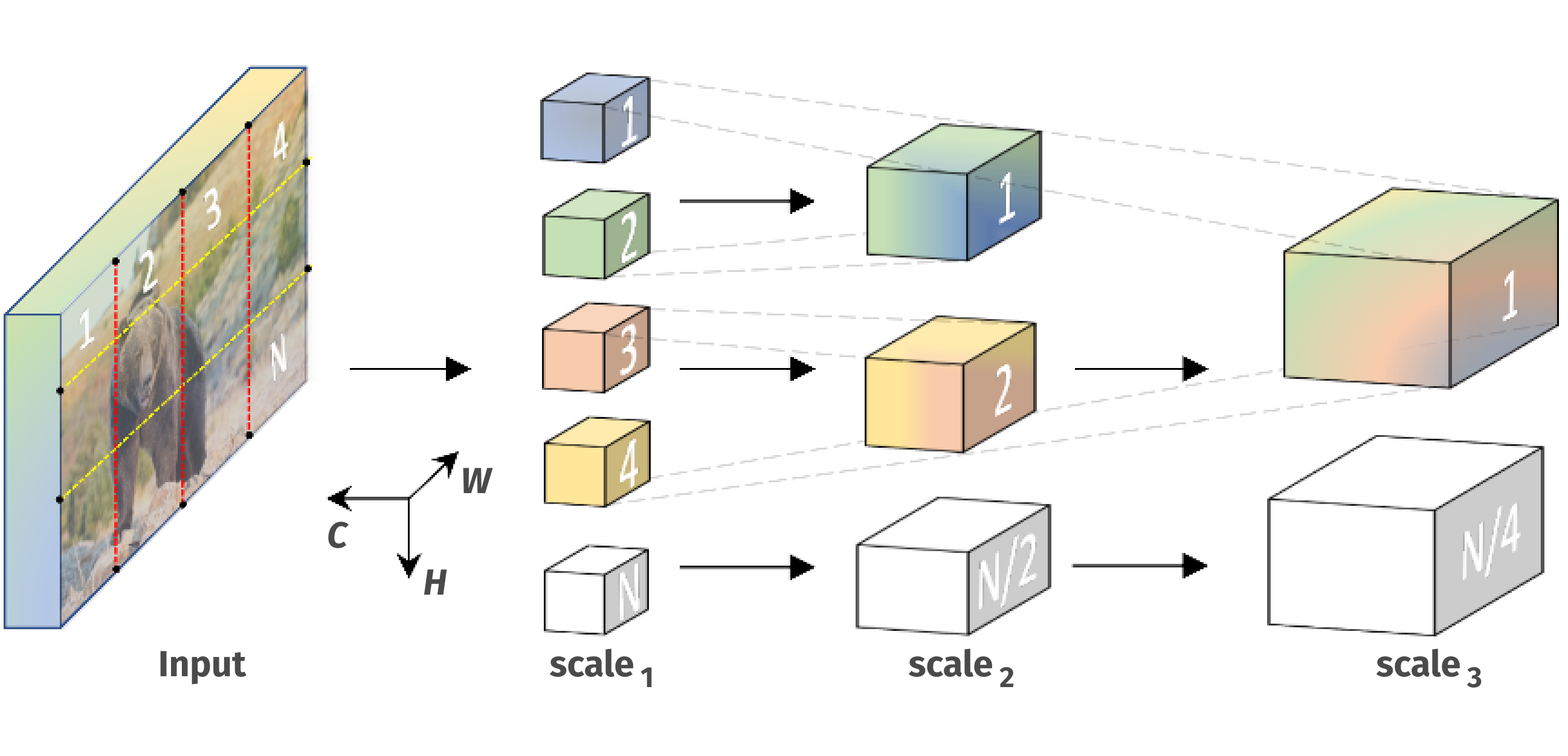
Multiscale Vision Transformer (MViT)
Multiscale Vision Transformer, or, MViT [18] uses pooling attention developed primarily for video stream (additional time dimension T) but could be applicable to other inputs:
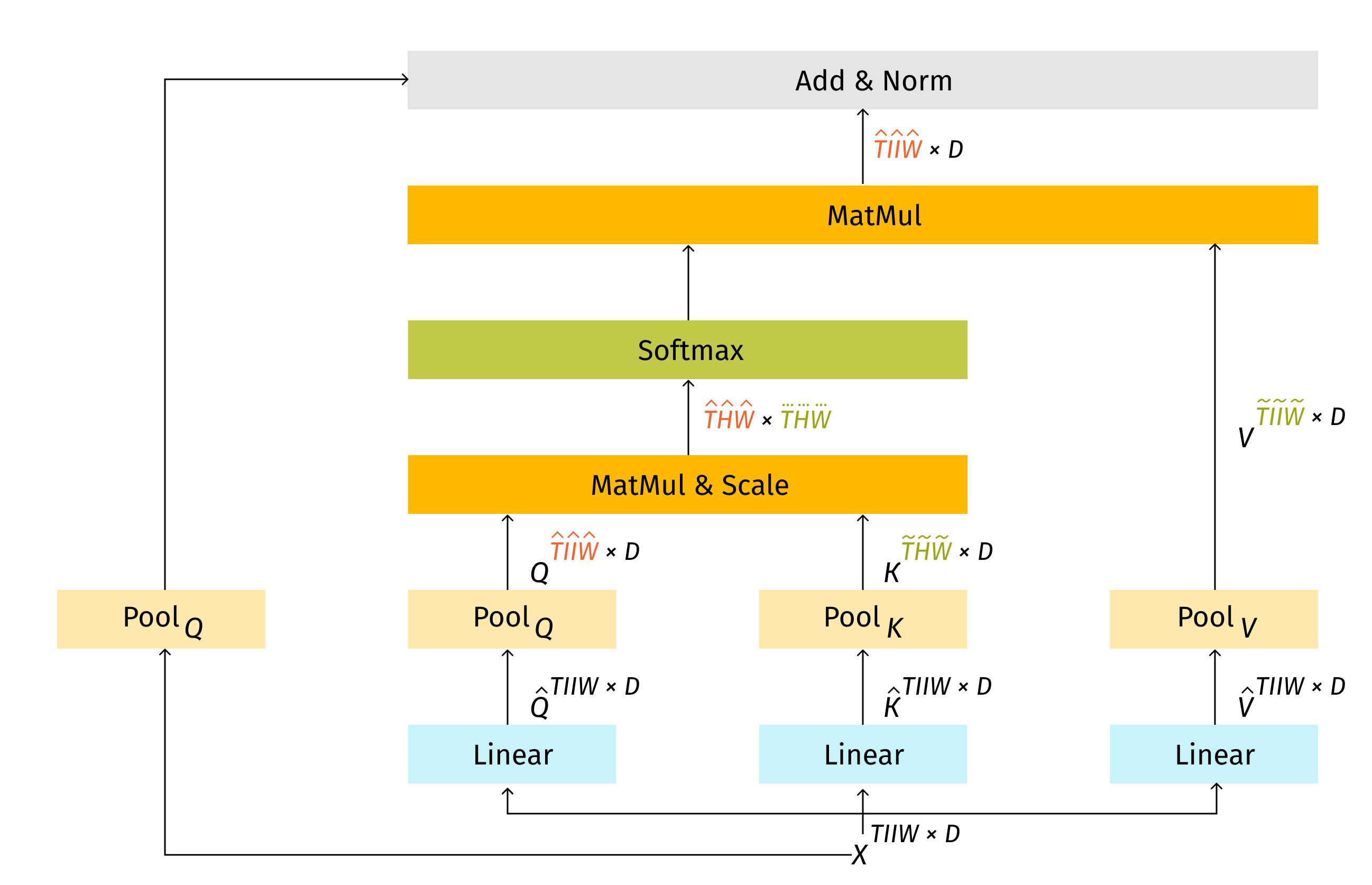
The particularities of the model are as follows:
- In Pooling Operator: L x D -> THW x D sequence length reshaped and then reduced by pooling kernel (k, s, p).
- Multiscale Transformers have several channel-resolution scale stages.
- Starting from the input resolution and a small channel dimension, the stages hierarchically expand the channel capacity while reducing the spatial resolution.
- Early layers operate at high spatial resolution to model simple low-level visual information, and deeper layers at spatially coarse, but complex, high-dimensional features ( Swin approach).
- Temporal dimension needed for video processing.
MViT overall architecture

MViT performance on Kinetics-600
| Model | Pretrain | Top-1 | Top-5 | GFLOPs×views | Param |
| SlowFast 16×8+NL[30] | - | 81.8 | 95.1 | 234×3×10 | 59.9 |
| X3D-M | - | 78.8 | 94.5 | 6.2×3×10 | 3.8 |
| X3D-XL | - | 81.9 | 95.5 | 48.4×3×10 | 11.0 |
| ViT-B-TimeSformer[6] | IN-21K | 82.4 | 96.0 | 1703×3×1 | 121.4 |
| ViT-L-ViViT[1] | IN-21K | 83.0 | 95.7 | 3992×3×4 | 310.8 |
| MViT-B, 16×4 | - | 82.1 | 95.7 | 70.5×1×5 | 36.8 |
| MViT-B, 32×3 | - | 83.4 | 96.3 | 170×1×5 | 36.8 |
| MViT-B-24, 32×3 | - | 83.8 | 96.3 | 236×1×5 | 52.9 |
Conclusion
Self Attention and Transformer-based architectures have recently boosted results not only in the NLP domain, but also in the CV domain. Integration of NLP and CV techniques have also inspired different creative approaches in both fields. These approaches have improved SotA, and the potential for even greater results is possible. Thus, every DS/ML/DL practitioner should be aware of these recent developments to successfully implement them to applied tasks.
If you’re interested in learning more about the integration of NLP and CV techniques, reach out to us to start a discussion.
References
[2] Transformer (Attention is all you need)
[4] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
[5] Generative Pretraining from Pixels
[6] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
[7] End-to-End Object Detection with Transformers
[8] VirTex: Learning visual representations using textual annotations
[9] Zero-Shot Text-to-Image Generation
[10] Emerging Properties in Self-Supervised Vision Transformers
[11] DINO and PAWS: Advancing the state of the art in computer vision
[12 ]Learning Transferable Visual Models From Natural Language Supervision
[13] Long-Short Transformer: Efficient Transformers for Language and Vision
[14] TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation
[15] Training data-efficient image transformers & distillation through attention
[16] LambdaNetworks: Modeling Long-Range Interactions Without Attention
[17] Involution: Inverting the Inherence of Convolution for Visual Recognition