A plug-and-play platform for in-app and in-game experience personalization



Personalization and recommendation models are widely adopted by technology and entertainment companies as highly efficient tools for digital experience improvement and conversion optimization. The traditional model development and productization process, however, requires significant engineering effort that increases the time to market and implementation costs. In this article, we discuss the design of a personalization platform that reduces implementation complexity and improves the quality of recommendations using reinforcement learning.
We consider the case of a company that develops video games and mobile applications. The company aims to improve user engagement and in-game monetization with personalized offers, promotions, and notifications that are shown in the feeds of mobile apps or in-game shops. Examples of such offers include game upgrades, virtual currency packs, and special deals in loyalty mobile apps:
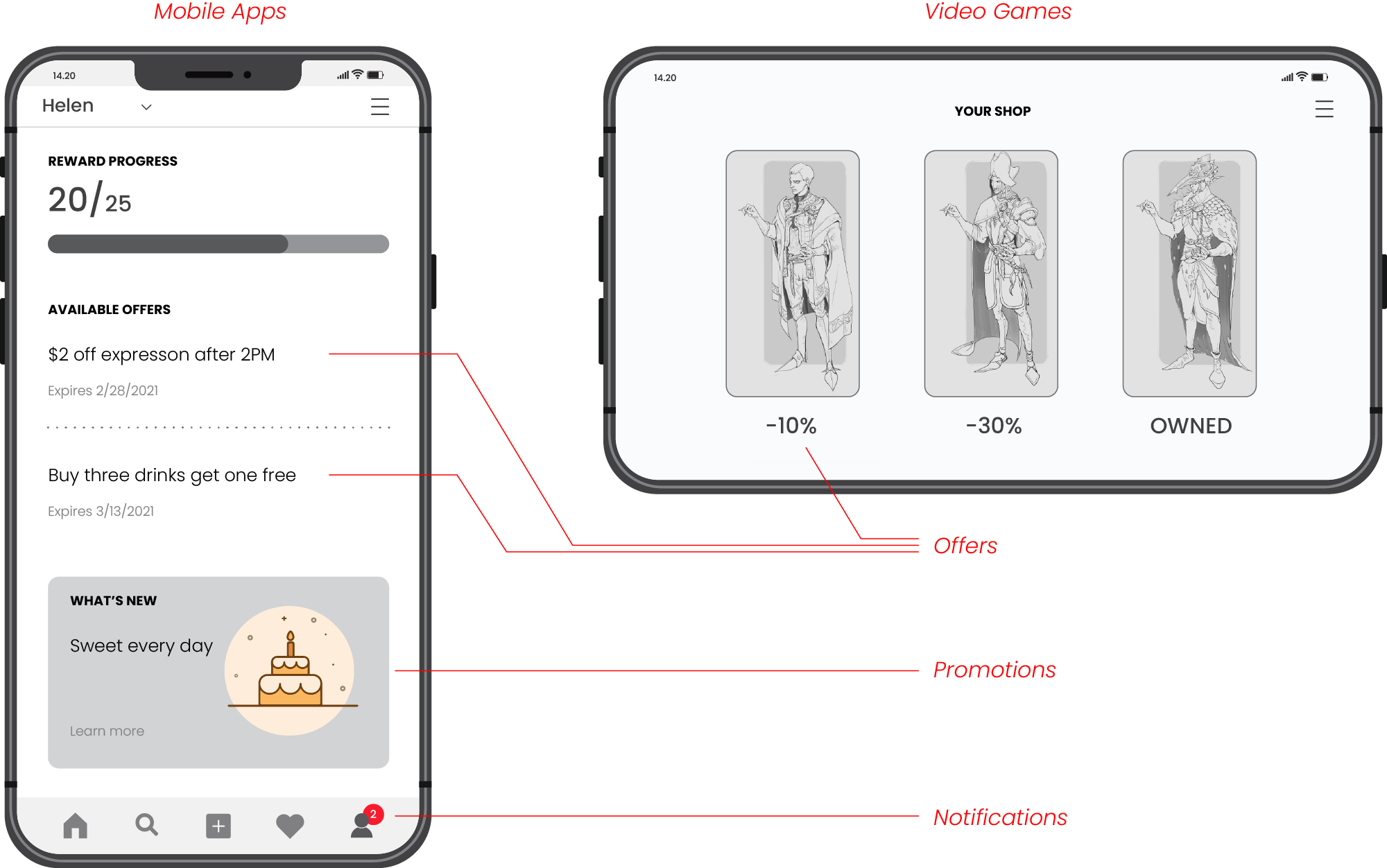
Design Goals: Strategic Optimization and Automation
From the business perspective, the primary goal of the company is to improve the long-term performance of the application or game. This performance can be measured using various engagement and monetary metrics, including the offer acceptance rate, in-app user spend, and duration of game sessions. Most users interact with the product over a relatively long timespan, so it is important to optimize each action (offer, promotion, or notification) in strategic content that includes both past and previous steps as opposed to optimizing actions in isolation. We can associate each action $a_t$ with a portion of value $r_t$ measured in engagement or monetary terms, so that the total value derived from an individual user over a long timeframe will be a sum of these portions:
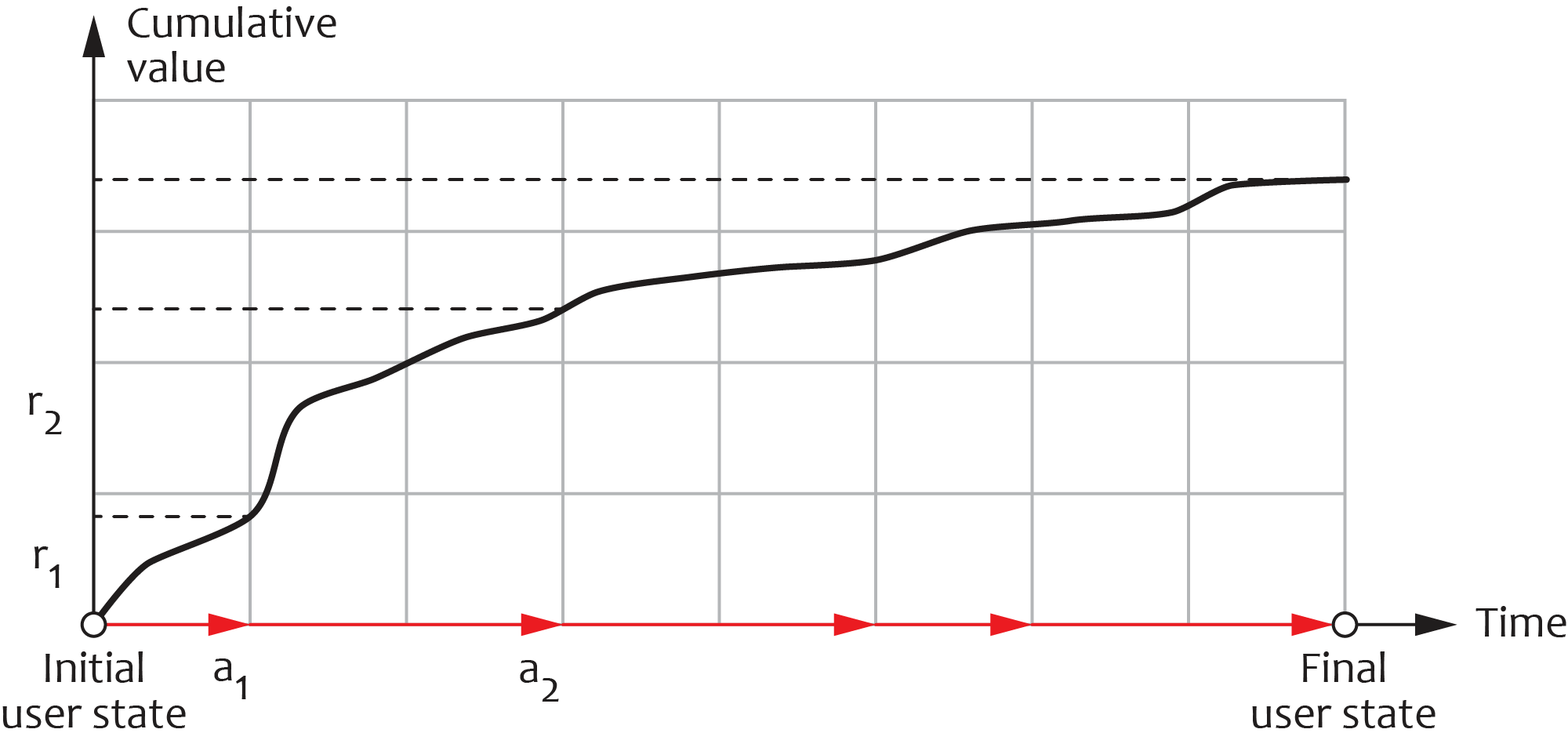
The flexibility in defining the value metrics and the ability to strategically optimize the sequences of actions are among the main design goals for the platform.
From the engineering perspective, the main consideration is the effort and time associated with the solution implementation and operationalization. Traditional targeting and personalization techniques, such as propensity scoring and collaborative filtering, generally require putting significant effort into feature engineering, model development, and productization for each use case. In particular, some effort is usually required to operationalize the scores produced by predictive models and develop transactional decision-making components on top of them. Achieving a high level of automation using a prescriptive rather than predictive approach is generally a design goal for a modern personalization platform.
The traditional personalization methods also assume the availability of historical user interaction data that covers all actions or at least action types. This assumption does not hold true in many scenarios, including releases of new game versions, new application features, and new types of promotions. In such cases, we might need to develop custom workarounds or arrange randomized experiments for data collection, which both increase the engineering effort and decrease the system efficiency. Consequently, the ability to learn and adapt in dynamic environments is also an essential design goal for the platform.
Solution: Reinforcement Learning Platform
Conceptually, the objectives described in the previous section can be addressed using reinforcement learning techniques. First, reinforcement learning methods are specifically designed for strategic (multistep) optimization and provide powerful statistical tools for performing this optimization based on noisy feedback collected from the environment. Second, reinforcement learning explicitly addresses the problem of dynamic exploration and interactive learning based on the feedback collected from the environment—most reinforcement learning algorithms can start to operate without pre-training on historical data and learn from ongoing observations. Finally, reinforcement learning algorithms can generally be viewed as autonomous agents that follow the prescriptive paradigm we mentioned in the previous section.
Unfortunately, the practical adoption of reinforcement learning methods in enterprise settings is very challenging for several reasons. First, most reinforcement learning algorithms are prone to stability and convergence issues requiring performing various safety checks and careful monitoring. Second, interactive learning implies that the agents need to be integrated directly into the production environment, complicating maintenance and creating additional risks. Finally, deployment of untrained agents that take random actions directly in production is unacceptable for most companies despite the fact that reinforcement learning is theoretically capable of bootstrapping this way.
The advantages of reinforcement learning, however, outweigh the challenges associated with its adoption, and many reputable companies reported that they use reinforcement learning algorithms in production. This includes a loyalty app optimization solution developed by Starbucks [1], a strategic ad optimization solution created by Adobe [2], and the user experience optimization solution developed by Facebook for its social network platform [3].
In this section, we discuss the design of the platform that was recently developed by Grid Dynamics based on Facebook's ReAgent framework and several lessons that we learned from its practical adoption.
Experience Optimization as a Markov Decision Process
Let us start with a brief review of how the engagement optimization problem can be represented in reinforcement learning terms. We have previously stated that the personalization agent interacts with the user in discrete steps, and it takes a certain action $a_t$ at each step $t$ receiving back value $r_t$ that characterizes the engagement or monetary gain derived from the user after the action was executed. We refer to value $r_t$ as reward following the reinforcement learning terminology. Finally, we can assume that at any time step, the state of the user and interaction context can be described by a feature vector, which we denote as $s_t$. Consequently, the entire user journey can be represented as a sequence of transitions $(s_t, a_t, r_t, s_{t+1})$ which we refer to as a trajectory. The figure below depicts a toy example of a trajectory assuming a discrete set of five states:
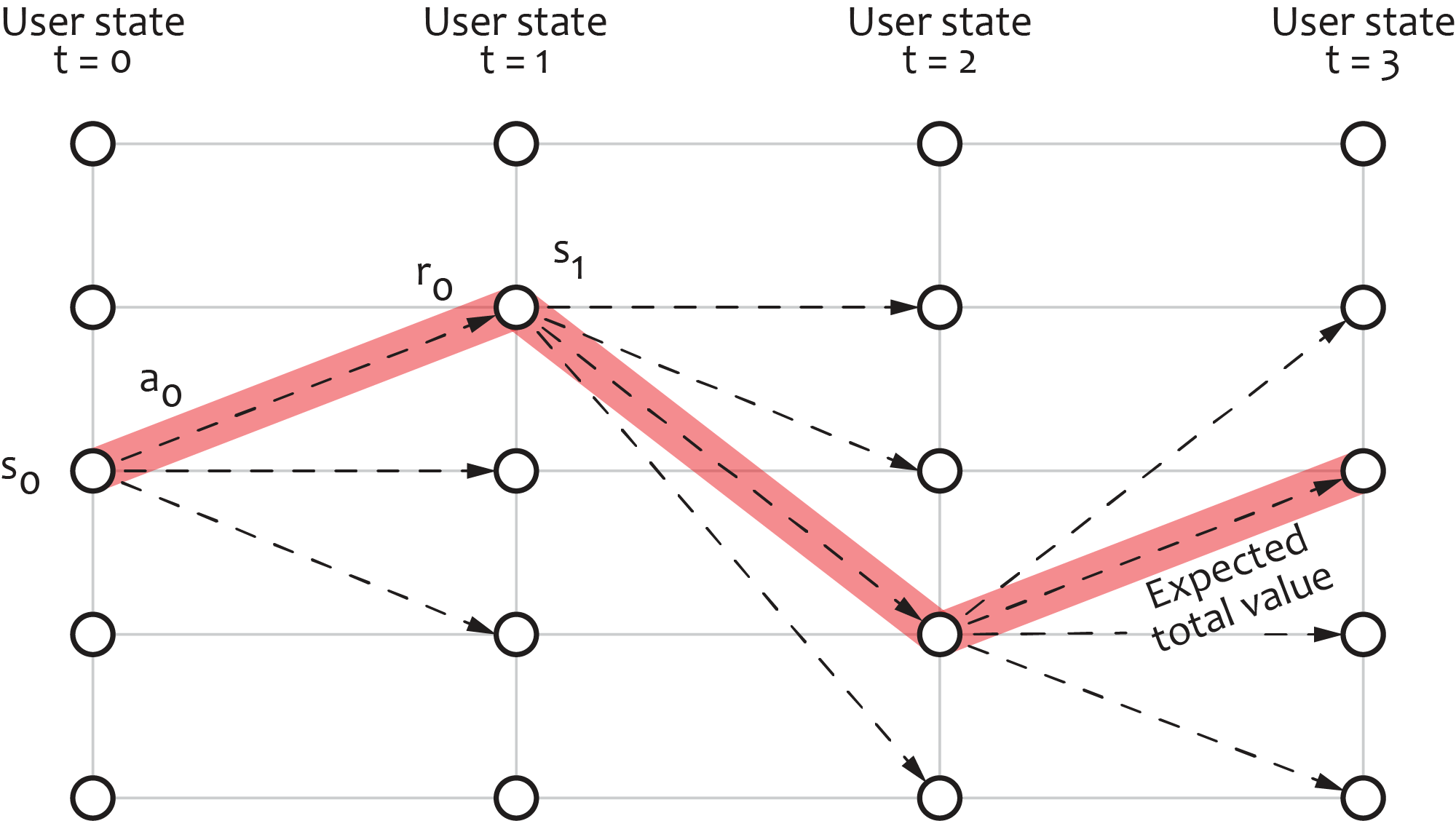
In practice, the state is a multi-dimensional real-value vector. More importantly, we must design the state vector in a way that $s_t$ incorporates all significant information about the user and context up to the moment $t$ so that the probability distribution of rewards and next states does not depend on the previous states and actions; that is
$$
p(r_t, s_t | s_0, a_0, s_1, a_1, \ldots) = p(r_t, s_t | s_{t-1}, a_t)
$$
This property, known as Markov property, drastically simplifies the design of models that support action optimization, as well as improves their computational efficiency. We elaborate on this topic in the next section.
Selecting the Algorithm
Reinforcement learning provides a wide range of solutions for action optimization in the Markov decision process. These algorithms differ in their sample efficiency (number of transitions needed to learn an efficient action policy), supported action spaces (discrete or continuous), and computational efficiency.
One of the largest categories of reinforcement learning algorithms is value-based methods. The common feature of these methods is that they explicitly estimate the expected return (sum of rewards) of the trajectory and then use it to construct an action policy. All practically important value-based methods leverage the Markov property of the environment that allows recursively calculating the return. For instance, one particular way of estimating the value function of a trajectory that starts in state $s_t$ given that we take action $a_t$ is as follows:
$$
Q(s_t, a_t) = \mathbb{E}\left[\sum_{\tau = t}^T r_\tau \right] \approx r_t + \max_a Q(s_{t+1}, a)
$$
This approximation allows us to fit the value function $Q(a,s)$ using regular supervised learning methods based on multiple transition samples $(s_t, a_t, r_t, s_{t+1})$ collected from the environment. Moreover, it is valid to collect these samples in batches under one action policy and then train another policy based on this input. This property has a major impact on the platform architecture, as we discuss in the next section. The value function is then used to determine the best possible action in the current state and to construct an action policy that balances value maximization and random exploration of the environment.
One of the most common, robust, and generic algorithms that implements the above approach is Deep Q-Network (DQN), which uses a deep neural network as the value function approximator and also improves the computational stability and efficiency of the learning process using several heuristic techniques. In practice, we found that DQN and its variants work reasonably well for most personalization problems. One of the DQN’s shortcomings is that the action space is required to be discrete and relatively small; it is apparent from the above recursive equation that searches for the value-maximizing action at each step, which requires enumerating all elements in the action space. In personalization applications, this assumption can sometimes be limiting because the number of available promotions or promotion-placement combinations can be relatively high. This problem can be alleviated by using action-critic algorithms that support continuous action spaces, and the platform we describe below supports this option.
Platform Architecture
In light of the above section, it can be appealing to integrate a reinforcement learning agent such as DQN directly into the production environment so it can execute the offer personalization decisions in real time and instantly learn from the feedback. Unfortunately, implementing and operating such a solution in practice is challenging because it provides no way to modify, retrain, or evaluate the agent separately from the production environment.
We can address the above problem by decoupling the agent from the application backend services or video game servers, as shown in the following figure:
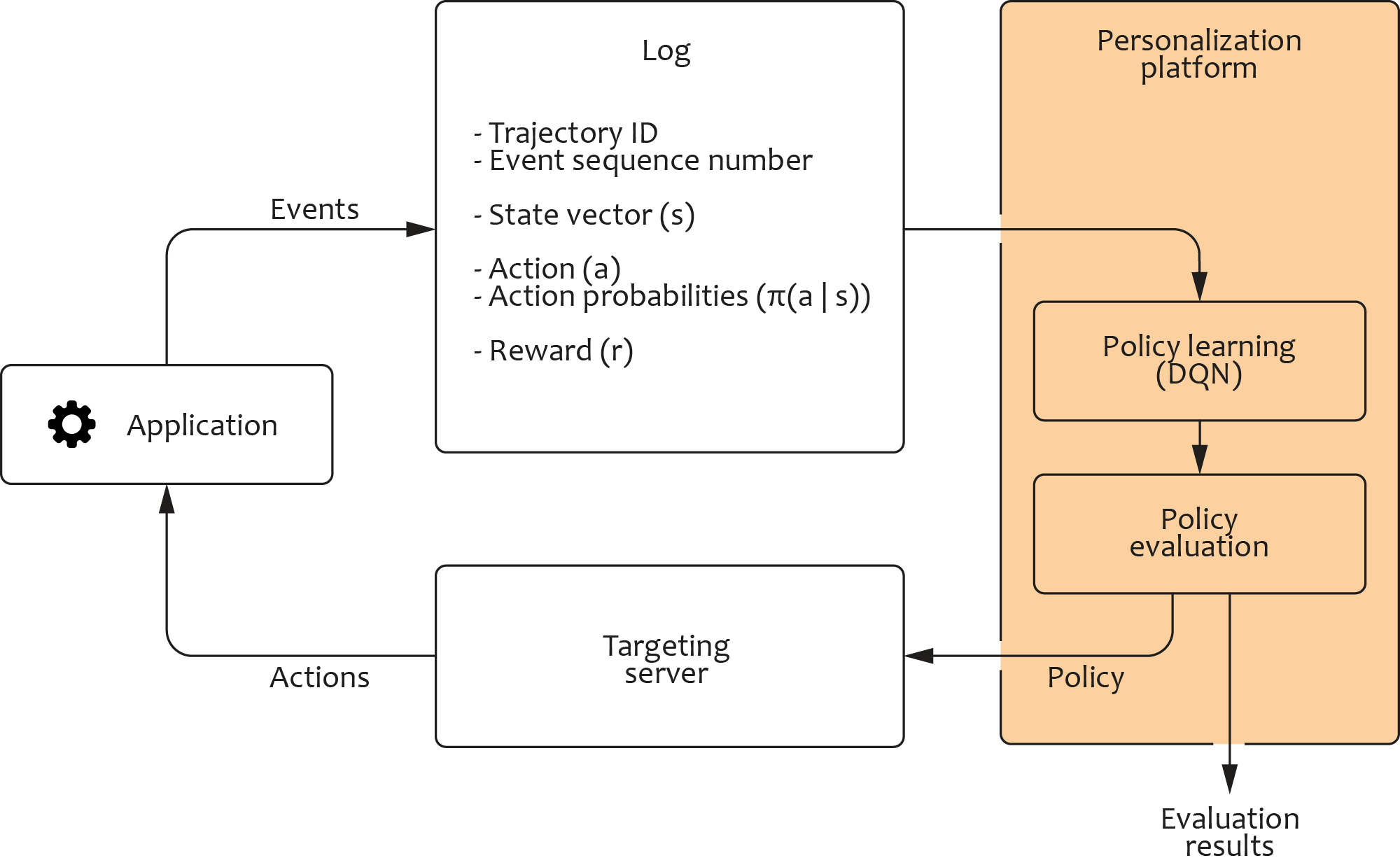
In this architecture, the transactional applications are required to log the user interaction events in a certain format that includes the customer journey ID, sequence number of the event within this journey, state vector associated with the event, action taken by the agent, probabilities of other possible actions, and the reward. These logs are then used to iteratively train the agent:
- We start with collecting logs under the initial action selection policy, which can be random or rule based.
- The logged states, actions, and rewards are used to train an arbitrary off-policy reinforcement learning algorithm: the log is replayed event by event simulating the actual interaction with the environment.
- The logged action probabilities are used for the counterfactual evaluation of the policy produced using the training process.
- If the evaluation results meet the quality and safety criteria, the new version of the policy is deployed to production, and the training cycle repeats.
The design depicted above is implemented as a generic platform using standard components. The platform supports several reinforcement learning algorithms that are integrated from open-source libraries without modifications, and it is easy to switch between the algorithms. The platform also supports several methods for counterfactual policy evaluation (CPE) and provides generic interfaces for the analysis of the evaluation results. Finally, the targeting server depicted in the diagram represents a generic deployment container for the trained policies that are exported from the platform as binary artifacts. The server processes personalization requests from the transactional applications, blocks certain policy decisions based on the business rules, and manages the a/b testing logic.
The solution described above takes a fundamentally different perspective on personalization models compared to the traditional methods. It uses reinforcement learning not just as an algorithm for the value function estimation, but as an end-to-end optimization machine that packages together exploration, learning, and evaluation capabilities. Such versatility is one of the main advantages of reinforcement learning compared to traditional data science methods such as propensity modeling.
Design of the States, Actions, and Rewards
The platform described in the previous section generally provides a high level of automation, but it still requires designing the rewards, states, and actions as a part of the integration effort. In this section, we take a closer look at these details.
For the sake of illustration, we focus on the case when the application allows displaying only one offer instance at a time, although it is often the case that a user is presented with a lineup of several offers. An example timeline that illustrates this scenario is presented in the figure below:
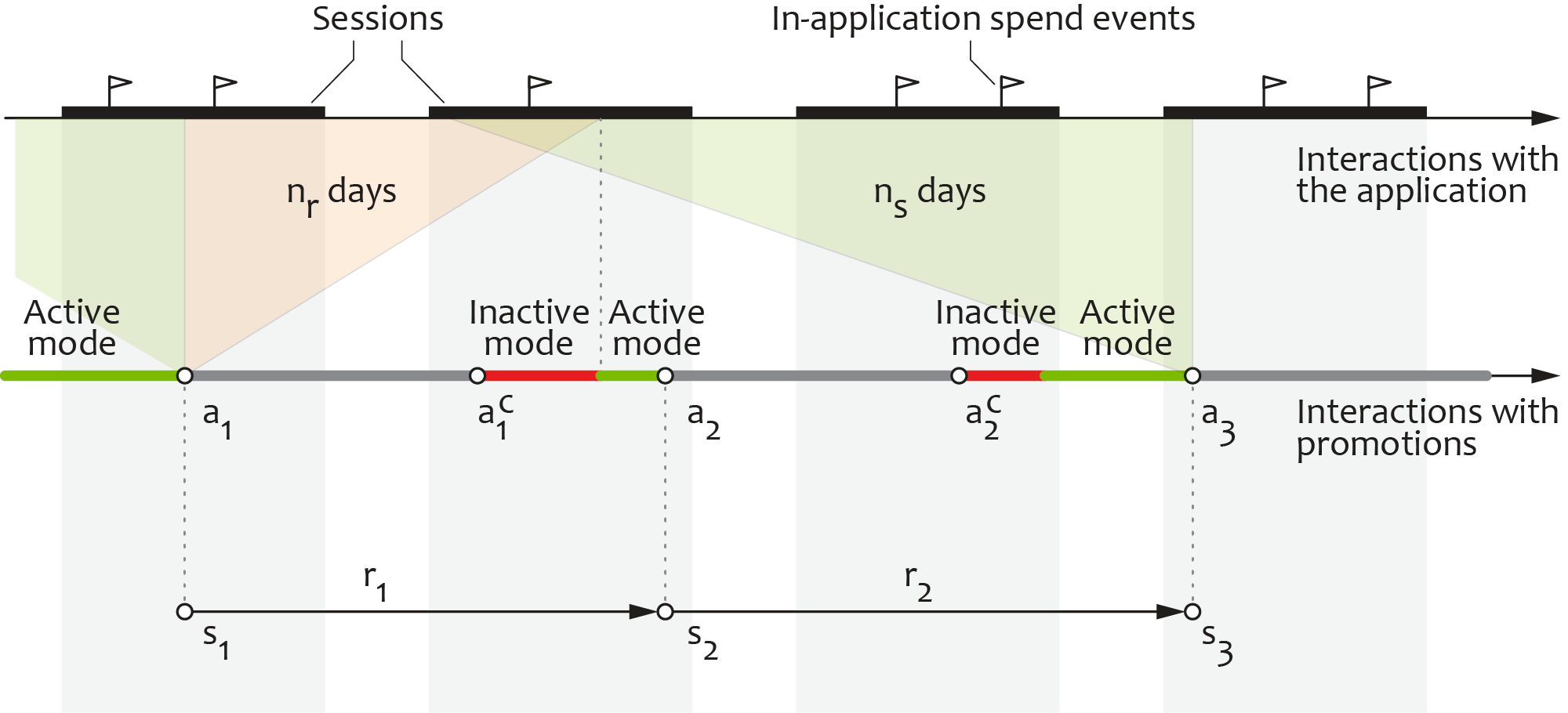
The agent makes the offer decisions sequentially, so that the user is first offered with an option $a_1$ and then the agent waits until the offer is either accepted (event $a^c_1$) or expired. The minimum time between the offers is limited to $n_r$ days, and the agent switches to the inactive mode if the offer is accepted sooner. Once the offer is accepted or expired, the agent switches to the active mode, generates the next offer $a_2$, and the cycle repeats.
In many digital applications, offers have a monetary cost of zero for the company that issues them. For instance, video game publishers commonly use in-game upgrades and virtual currency packs as promotion vehicles. In such cases, it is important to include a no-action element in the action set, monitor the uplift delivered by offers compared to the no-offer baseline, and implement penalties that prevent the agent from learning a policy that abuses the incentives. The uplift can be managed more directly for offers that are associated with non-zero monetary costs by factoring these costs into the reward design.
The platform supports several reward calculation methods, including in-app revenue, virtual currency spend, and binary rewards (reward of one if the offer is accepted and zero otherwise). In all these cases, the reward is calculated based on time windows of $n_r$ days after the action, and, consequently, the reward values are obtained with a delay of $n_r$ days. To create a complete log that could be consumed by the reinforcement learning platform, the log records produced at the time of actions are stored in a buffer and later joined with the corresponding rewards.
The stated features include some engagement metrics, such as the duration of sessions, a calendar, and user demographic features. The engagement features are calculated over the fixed time window of $n_s$ days before the action, as shown in the above figure.
Incremental Training
The log-based approach helps to decouple the agent training process from production operations, but it imposes certain challenges as well. One of the potential problems with platform operationalization is incremental training. All reinforcement learning algorithms, by definition, aim to maximize trajectory returns and thus require trajectories and returns to be properly specified. In the case of a personalization platform, a user can interact with the application for an indefinitely long time, and thus her trajectory can grow indefinitely. This potentially can result in trajectory misspecification. To better understand the problem, let us go through the DQN training process for the following example trajectory:
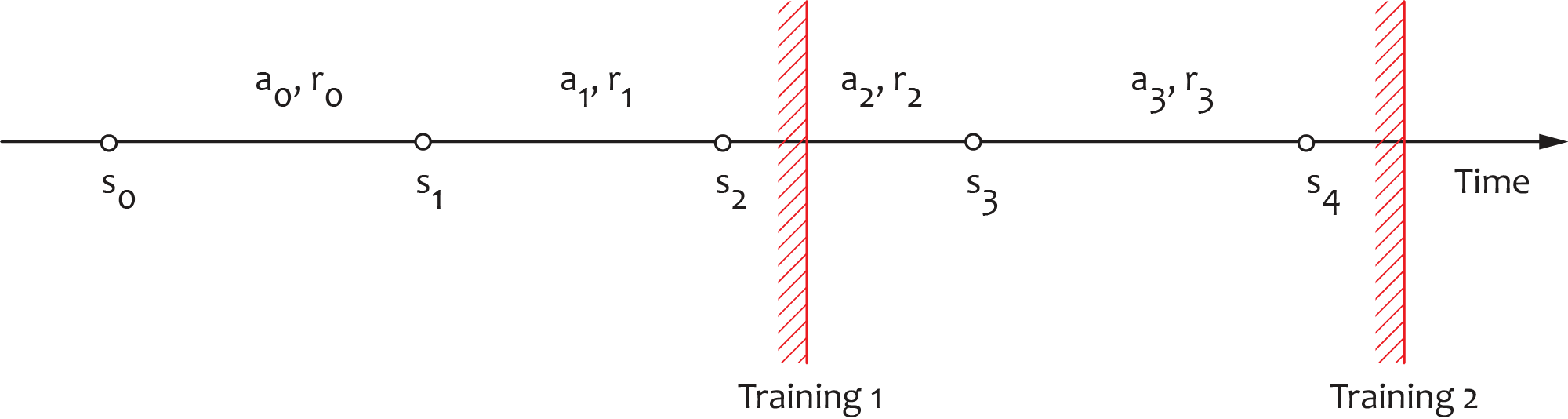
We first assume a log with the first two transitions from this trajectory and calculate the target labels for the DQN training as
$$
\begin{aligned}
&Q(s_0, a_0) = r_0 + \gamma \max_a Q(s_1, a) \\
&Q(s_1, a_1) = r_1
\end{aligned}
$$
The state $s_2$ is a terminal state in this trajectory, so we expand the recursion only for the first transition. Assuming that the trajectory is extended with two more transitions by the time of the second training, the new target labels are computed as follows:
$$
\begin{aligned}
&Q(s_2, a_2) = r_2 + \max_a Q(s_3, a) \\
&Q(s_3, a_3) = r_3
\end{aligned}
$$
Consequently, the DQN buffer contains two unrelated pairs of samples by the time of the second training, which makes the strategic optimization across all four transitions impossible. This problem can be addressed by using longer trajectory segments or other adjustments that ensure the correctness of incremental learning.
Results
The reinforcement learning platform proved itself to be an efficient solution for achieving the goals we set at the beginning of the article. First, its strategic optimization capabilities can deliver significant uplift compared to basic rule-based or propensity-based solutions. In some cases, we observed uplifts of about 20% compared to the legacy baselines.
Second, the integration process of the platform is relatively short. In many cases, the pilot project can be implemented in about eight weeks, from the initial analysis to production launch. Although this is not a perfectly plug-and-play solution (yet), it is a major step forward compared to the traditional modeling approach.
Finally, the platform provides advanced automation capabilities that include counterfactual policy evaluation, a/b testing, and an array of reinforcement learning algorithms out of the box. This helps to focus on business problems such as reward and action design as opposed to focusing on basic modeling and MLOps tasks.
References
- Jennifer Sokolowsky, “Starbucks turns to technology to brew up a more personal connection with its customers”, 2019
- Georgios Theocharous, Philip Thomas, and Mohammad Ghavamzadeh, “Personalized Ad Recommendation Systems for Life-Time Value Optimization with Guarantees”, 2015
- Jason Gauci et al., “Horizon: Facebook's Open Source Applied Reinforcement Learning Platform”, 2019