
Relevant facets: How to select and promote facets with deep learning


Faceted navigation, a.k.a. guided navigation is a de-facto standard user experience for any serious online retailer. Facets seamlessly introduce your customers to the structure and attributes of an online catalog and provide shoppers with powerful tools to slice and dice their results with useful filters:
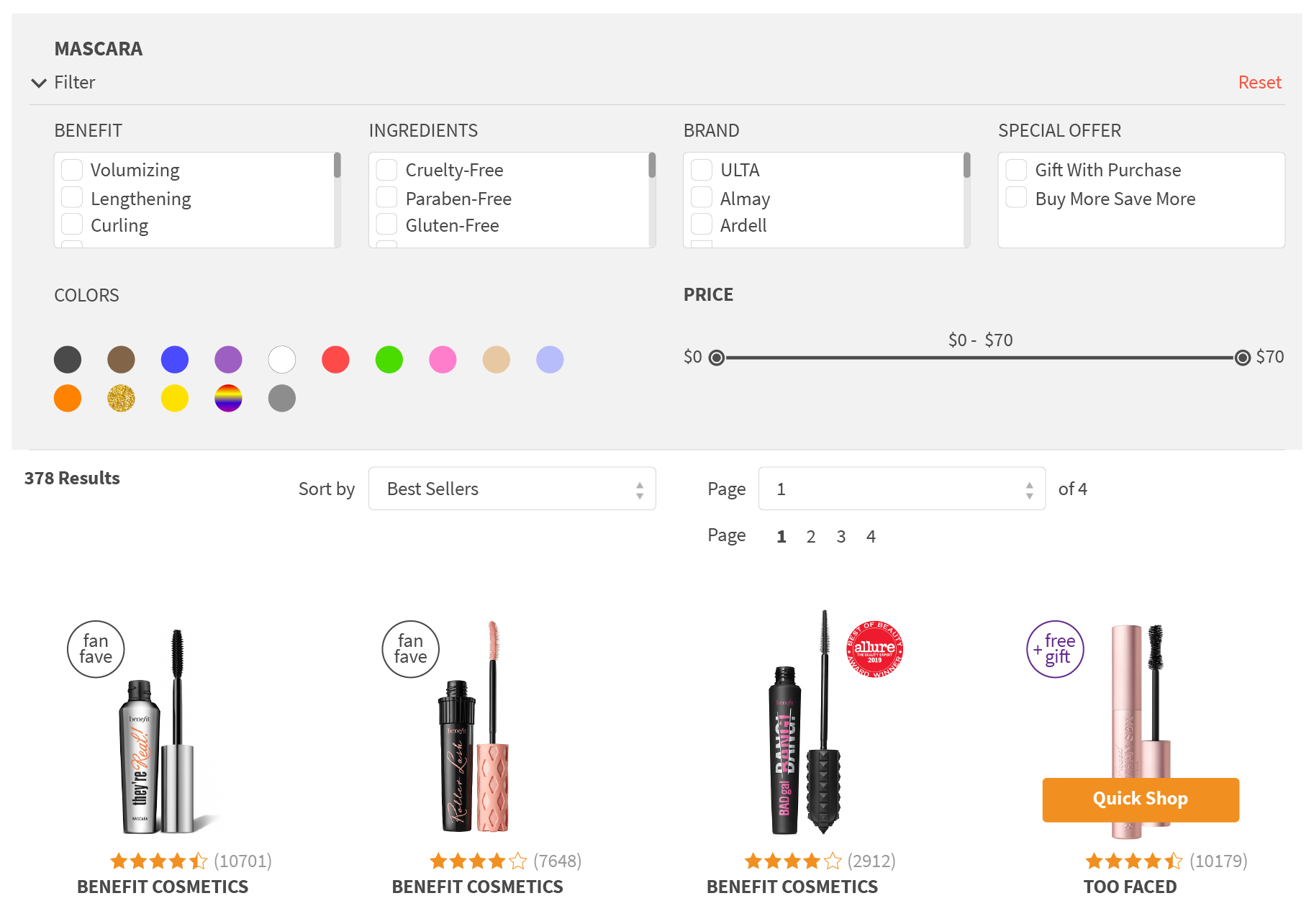
However, selecting what facets and filters to show to customers is not always that simple. Large department stores have hundreds of product types with thousands facetable attributes, and only a limited display area available to the category or search results page, especially on mobile devices.
The choice of facets, and how well they are ranked, makes a big difference and distinguishes a useful product discovery tool, which makes shopping easy and delightful from an annoying search bar, which occupies a large portion of the screen while only adding frustration to the shopping experience.
In this blog post we will review various strategies used by online retailers to present customers with relevant facets and will share our experience applying deep learning to this problem.
Retailers employ a variety of strategies to deal with facet selection and ranking. We can summarise those strategies with their pro and cons in following table:
Facet selection in ecommerce search
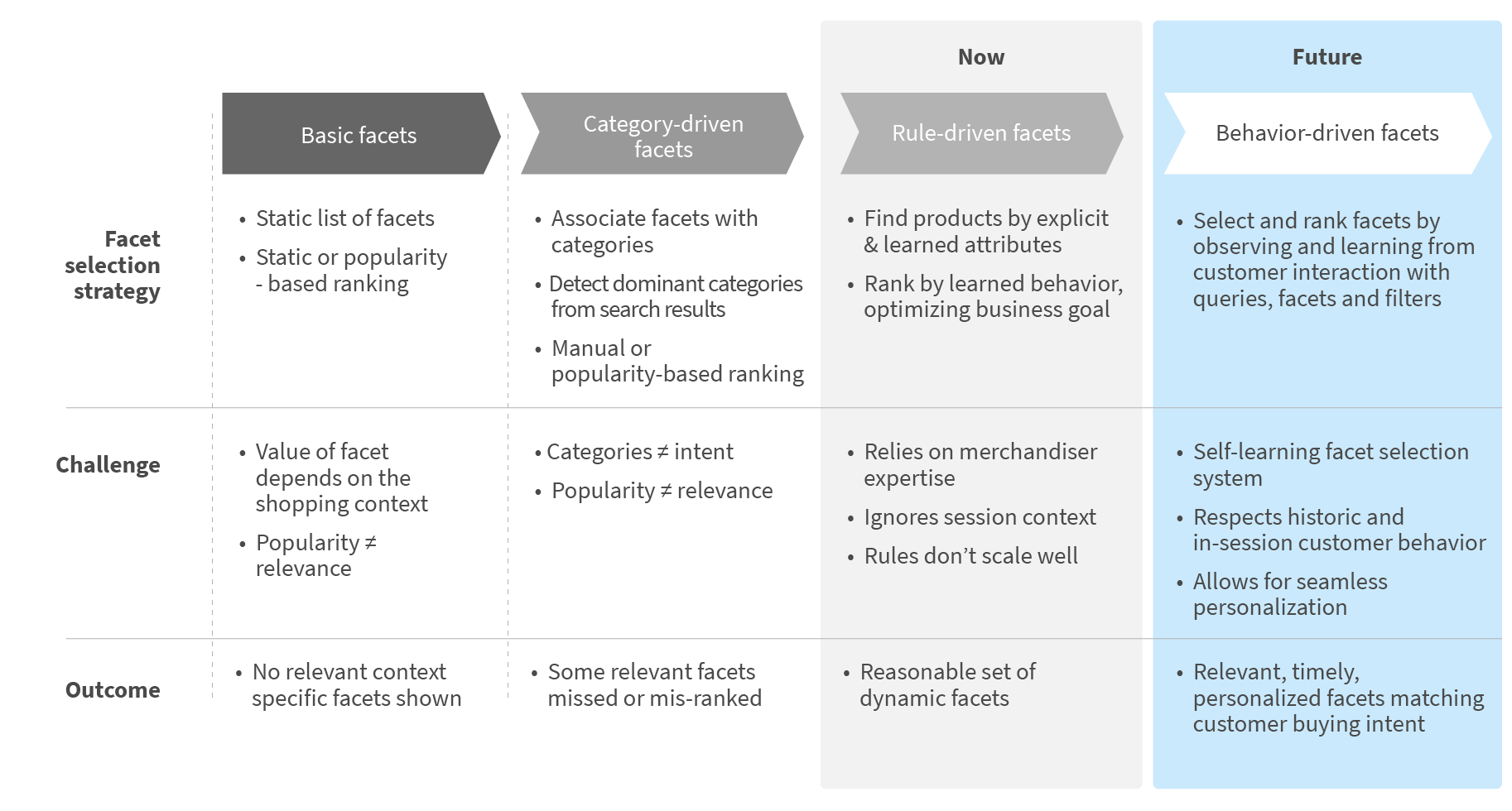
Historically, retailers used a static list of most popular facets, such as Brand, Department or Price, and some are still using this outdated strategy. Many retailers have category-specific facets and are trying to reduce search results to one or few categories which dominate the result set. These days, a majority of retailers use some form of merchandising engine to react to a particular customer’s context and suggest a relevant facet list as defined by the merchandiser.
However, those approaches do not employ probably the most valuable data sources available to online retailers - customer behavior data.
Let’s look into how we can use the power of natural language processing and deep learning to build a model which can suggest most relevant facets based on a current context, such as the customer query and already selected filters.
For starters, we will need customer engagement data in the following format:

Each row in this table represents a customer journey when they used filters refining search results from their original query.
Let's look at one of the examples:
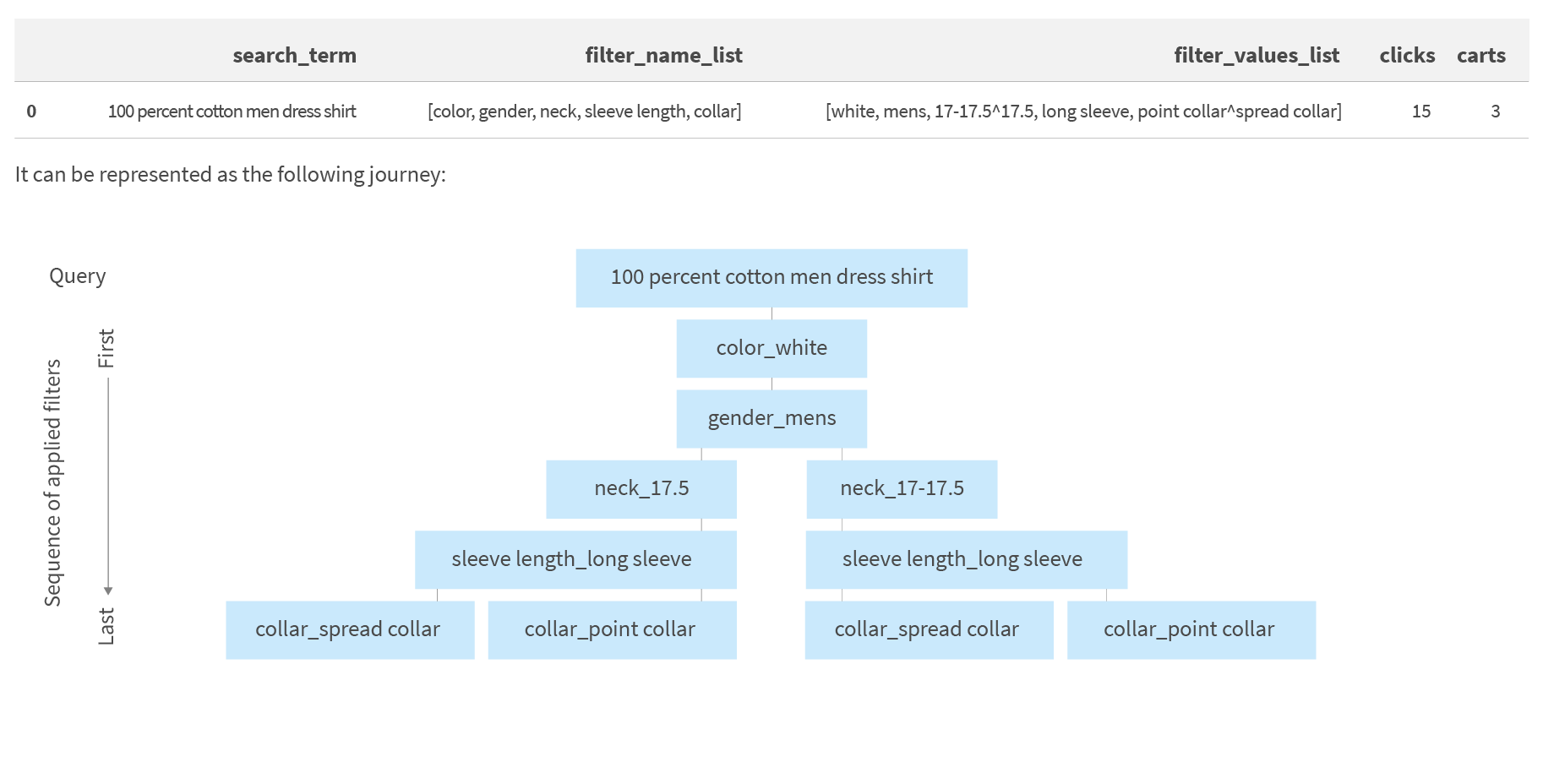
We will unfold this tree structure into the form useful for predicting next filter based on the current query and applied filters:

We can view our training goal as predicting the next event (filter application) in the series of events. For the purpose of dealing with sequences, the deep learning arsenal deploys a special kind of neural network: a recurrent neural network (RNN).
The recurrent neural network consumes input vectors one-by-one while building an internal vector representation of the sequence consumed so far. This internal representation is trained to be useful in predicting the target of learning.
Currently, the most popular RNN architectures are Gated Recurrent Units (GRU) and Long Short-Term Memory. The main idea behind those architectures is to selectively retain the necessary information about the sequence in a way useful for making predictions. For more details, we can recommend this article. For the purpose of describing our model, we will proceed with an LSTM architecture.
As the first order of business in training deep learning models, we have to vectorise our data. It generally consists of two different kinds of information: search query, which is a free-form word sequence and set of applied filters, which is better represented as a categorical data, since it contains a fixed and relatively limited number of options to select from.
For query vectorisation, we will use the popular fasttext library. It will represent (or embed) our search query as a matrix of 100-dimensional vectors, each vector representing a word in our query. Vectors in this matrix will be consumed by LSTM one-by-one, producing an internal representation of the query semantics within LSTM’s hidden state.
For applied filters, we will allow the model to learn how to represent them as vectors during training. This is how we will approach it:

We will define a matrix of all possible filter values assuming 100-dimensional representation of filter value. This matrix will initially be filled by random vectors. However, in the process of training, each filter’s vector will be updated to be more helpful in final prediction. This will result in filters with similar meaning having similar vectors, thus building a semantic vector space for filters and filter values.
Putting the two vectorisation strategies together, we will arrive at the following scheme:
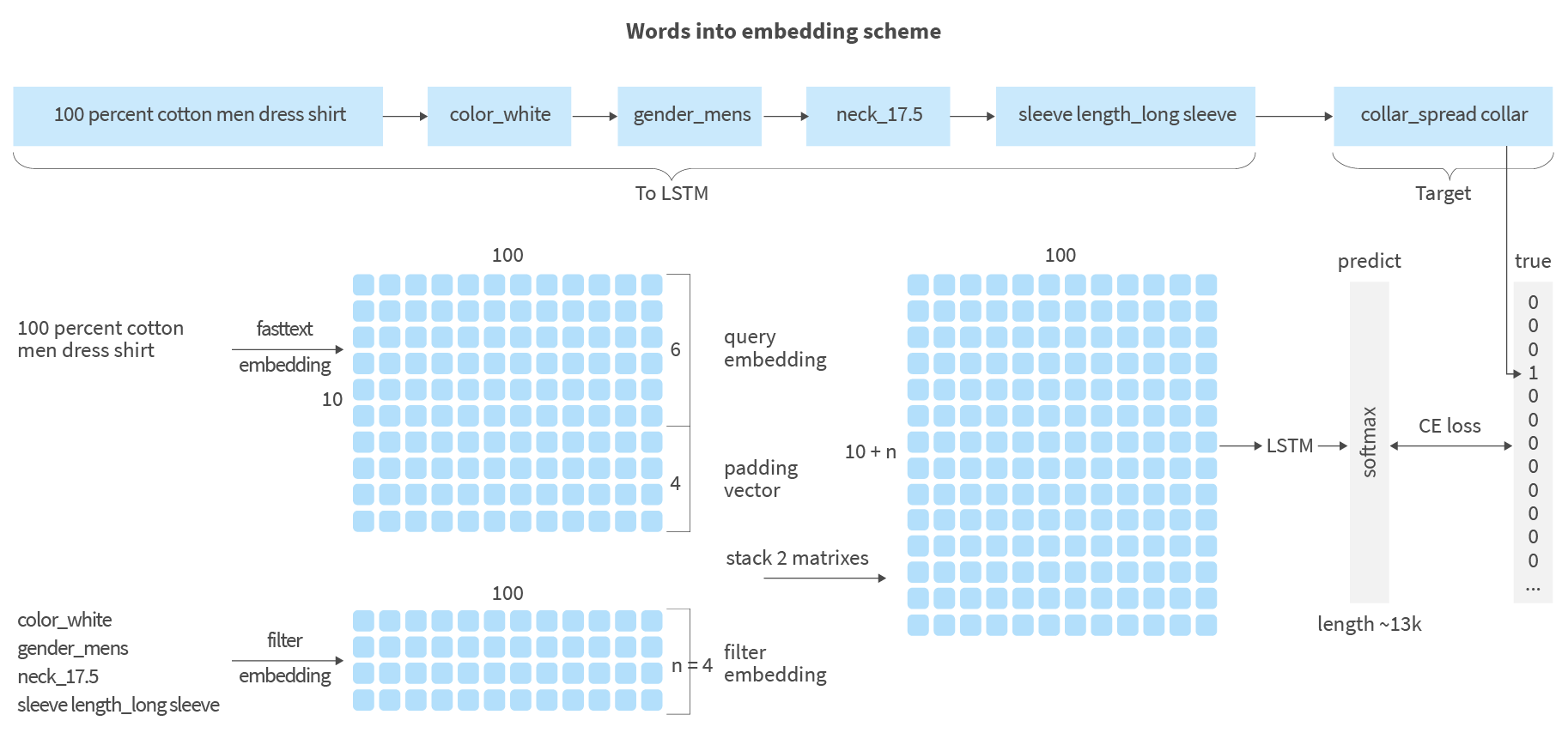
We will concatenate word embeddings with filter embeddings in the single matrix and push rows of this matrix through LSTM one-by-one letting LSTM build an internal representation of the whole query and applied filters sequence. The LSTM output vector will go through fully connected layers, trying to predict the next applied filter as a simple one-hot encoded value.
After the facet selection model training is complete, it will start producing recommendations for facet selection and order, like this:
Query: golden pendant
Recommended facets: price_range, chain_length, metal_color
Interestingly enough, the model can capture variations in customer behavior depending on the filters applied. For example, consider the query “nike”, with applied filter product_type:shirts_tops model predicts different next most valuable filter depending on gender refinement. For men's products, the next predicted filter is subproduct_type, such as t-shirt or polo shirt, while for women products it predicts sales and promotions as the next most useful filter.
To evaluate the quality of the facet selection model, we collected facet clicks for 10,000 most popular queries and calculated an NDCG metric which shows how likely customers are to click on the facet or facet value depending on its position on the facet list and the position of the value within the facet. Against a manually tuned facet ranking, we showed 8-10% uplift in this metric, while for value ranking the uplift was in the range of 15-20%.
The facet selection model can be integrated in multiple ways:
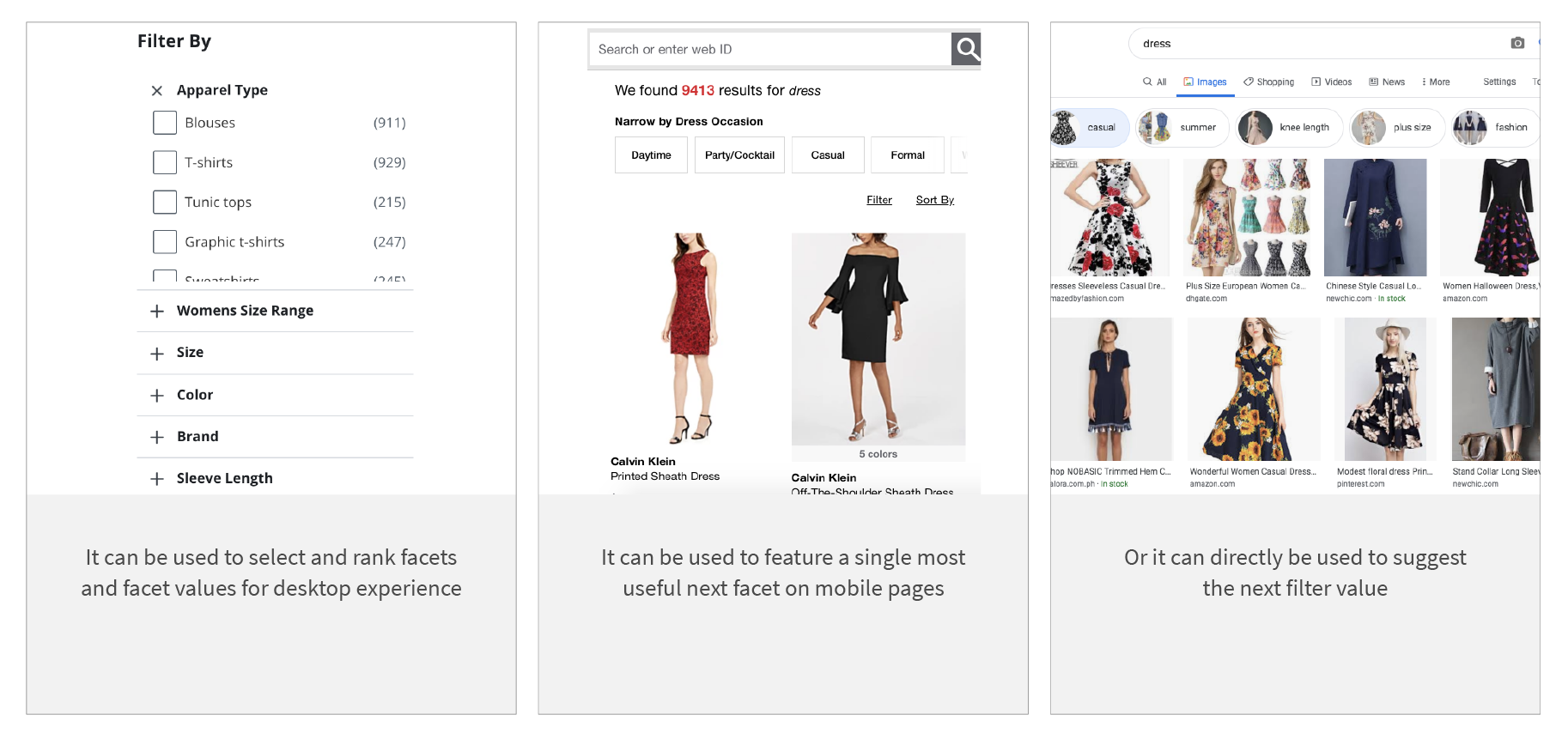
Conclusion
In this blog post, we talked about the problem of selecting the most relevant facets for online retailers and how to use deep learning to select and rank facets depending on customer behavior.
We believe that deep learning has a bright future in search applications, and many more powerful features can be easily implemented using the modern natural language processing models.
If you are interested in faceted navigation and would like to discuss this blog post with the authors, don’t hesitate to reach out.