
Transforming Business Process Automation with Retrieval-Augmented Generation and LLMs


In today's competitive business environment, automation of business processes, especially document processing workflows, has become critical for companies seeking to improve efficiency and reduce manual errors. Traditional methods often struggle to keep up with the volume and complexity of the tasks, while human-led processes are slow, error-prone, and may not always deliver consistent results.
Large Language Models (LLMs) like OpenAI GPT-4 have made significant strides in handling complex tasks involving human-like text generation. However, they often face challenges with domain-specific data. LLMs are usually trained on broad (publicly available) data, and while they can provide general answers, their responses might be inaccurate when it comes to specialized knowledge. They might also generate outputs that appear reasonable but are essentially hallucinations — plausible-sounding but false pieces of information. Moreover, companies often have vast amounts of domain-specific data tucked away in documents but lack the tools to utilize this information effectively.
Here's where Retrieval-Augmented Generation (RAG) steps in. RAG offers an exciting breakthrough, enabling the integration of domain-specific data in real time without the need for constant model retraining or fine-tuning. It stands as a more affordable, secure, and explainable alternative to general-purpose LLMs, drastically reducing the likelihood of hallucination.
In this blog post, we'll explore the application of RAG across various domains and scenarios, emphasizing its advantages. We'll also dive into the architecture of RAG, break it down into building blocks, and provide guidance on how to construct automated document processing workflows.
Join us as we navigate the transformative impact of Retrieval-Augmented Generation and Large Language Models on business process automation.
Retrieval-Augmented Generation in practice
In the sphere of artificial intelligence, the RAG approach stands out as a powerful technique, combining the precision of information retrieval with the sophistication of text generation. This synergy leads to a suite of unique capabilities enabling RAG-powered applications to offer accurate, contextually relevant, and dynamic responses. Let's explore these functionalities and delve into their practical applications in various business use cases within the supply chain, finance, insurance, and retail domains.
RAG in supply chain
In this subsection, we'll emphasize the transformative effect of RAG on the supply chain landscape and explore several business use cases, as depicted in Figure 1. We will discuss each of these and clarify the challenges that RAG addresses.
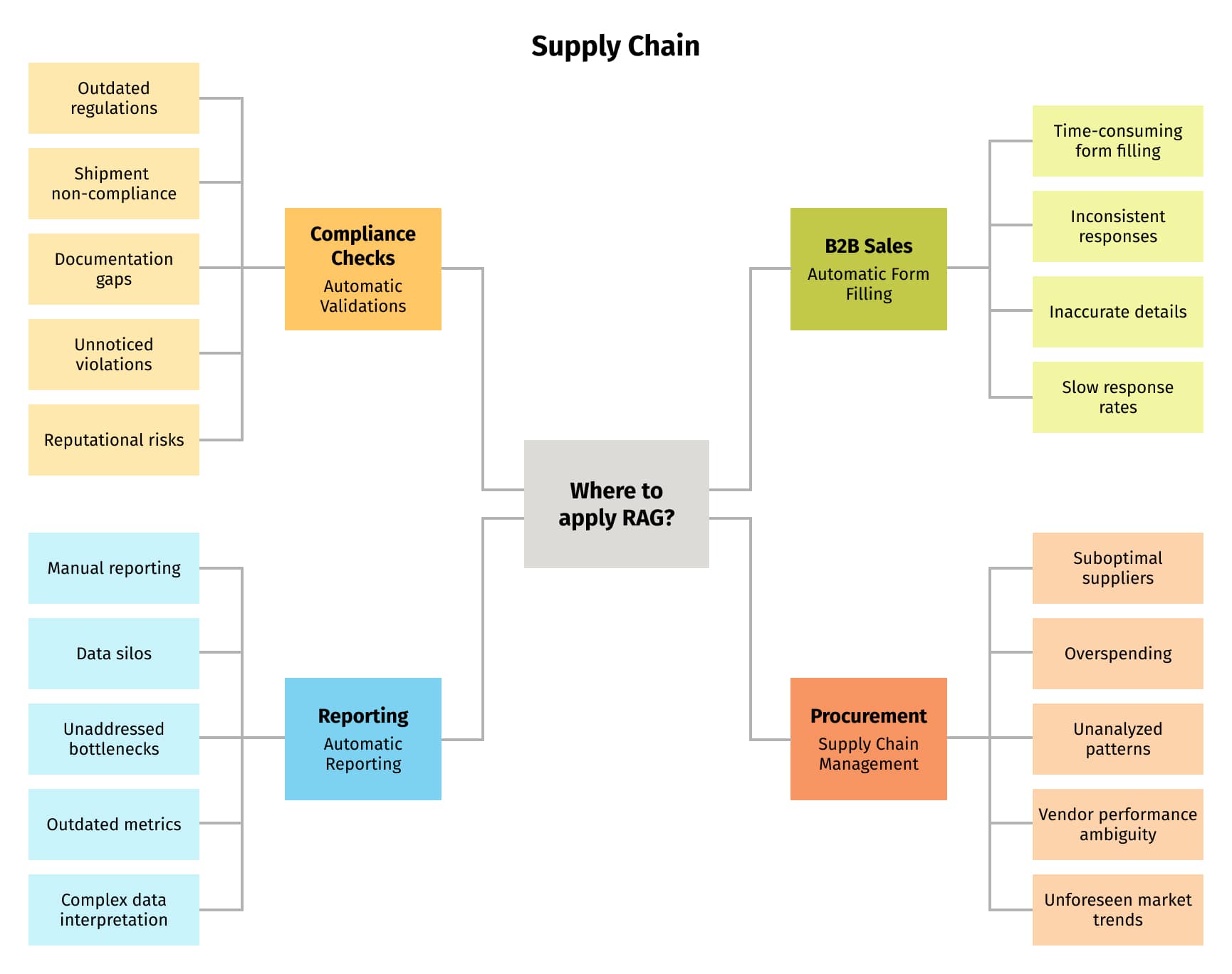
Compliance checks: Automatic validations
RAG's fact verification and compliance validation functionalities make it a valuable asset in the legal and compliance domains. When dealing with legal documents or regulatory requirements, RAG can cross-reference information from trusted sources, contributing to the creation of accurate legal documents. Its fact-checking ability ensures that the information presented aligns with legal standards, minimizing the risk of errors and enhancing overall compliance.
A multinational company exports electronic goods globally. Using RAG, the company accesses up-to-date trade regulations for each destination. Before dispatching a shipment, RAG validates it against these regulations and auto-generates the necessary documentation. Any non-compliance triggers real-time alerts. This automation reduces errors, speeds up shipment processes, cuts costs from non-compliance penalties, and ensures a positive global reputation.
B2B sales: Automatic form filling
In the B2B sales process, responding to Requests for Proposals (RFPs) or Requests for Information (RFIs) can be time-consuming. Utilizing RAG, companies can auto-populate these forms by retrieving relevant product details, pricing, and past responses. RAG ensures consistency, accuracy, and speed in generating responses, streamlining the sales process, reducing manual efforts, and improving the chances of winning bids by promptly addressing client needs.
The Grid Dynamics Intelligent Document Processing Starter Kit demonstrates how LLMs and RAG can be used to generate responses to RFPs based on general company information and product specifications. It offers a tangible example of the power and versatility of these technologies in action.
Procurement recommendations: Supply chain management
For optimal procurement decisions, accurate recommendations are key. Using RAG, organizations can analyze past purchasing patterns, vendor performance, and market trends to automatically generate tailored procurement recommendations. RAG's insights ensure better supplier choices, cost savings, and risk mitigation, guiding businesses toward strategic purchasing and fostering stronger vendor partnerships.
A large manufacturer could leverage RAG to optimize its raw material sourcing strategy. By processing years of procurement data, RAG can identify which suppliers consistently meet quality standards, deliver on time, and offer competitive prices. This allows the manufacturer to prioritize partnerships with high-performing vendors and potentially negotiate better terms. Such a proactive approach, powered by RAG, ensures the manufacturer maintains a steady supply of quality raw materials, reducing production downtimes and fostering a more efficient supply chain.
Reporting: Automated reports
In today's complex supply chains, leveraging multifaceted data is paramount. RAG dives deep into a plethora of internal documents, including real-time inventory logs, past purchase orders, vendor correspondence, and shipment histories. Drawing from these diverse sources, RAG auto-generates intricate supply chain reports. These reports spotlight vital performance metrics, unveil potential bottlenecks, and suggest areas for refinement. Through RAG's automated reporting, businesses gain enriched insights, fostering agile decision-making, enhanced operational efficiencies, and bolstered supply chain robustness.
A global retailer looking to optimize its supply chain for the holiday season can utilize RAG to process vast datasets from past seasons, including sales data, inventory levels, and supplier delivery times. RAG then compiles a detailed report that not only highlights how the retailer performed in previous years but also predicts potential challenges for the upcoming season. Equipped with this report, the retailer can adjust its strategies in advance, ensuring smooth operations, meeting customer demand more effectively, and maximizing profits.
RAG in retail
In this segment, we'll delve into the possible applications of RAG within retail, showcasing various business scenarios, as illustrated in Figure 2. We'll elaborate on each scenario, highlighting the specific challenges that RAG overcomes in retail.
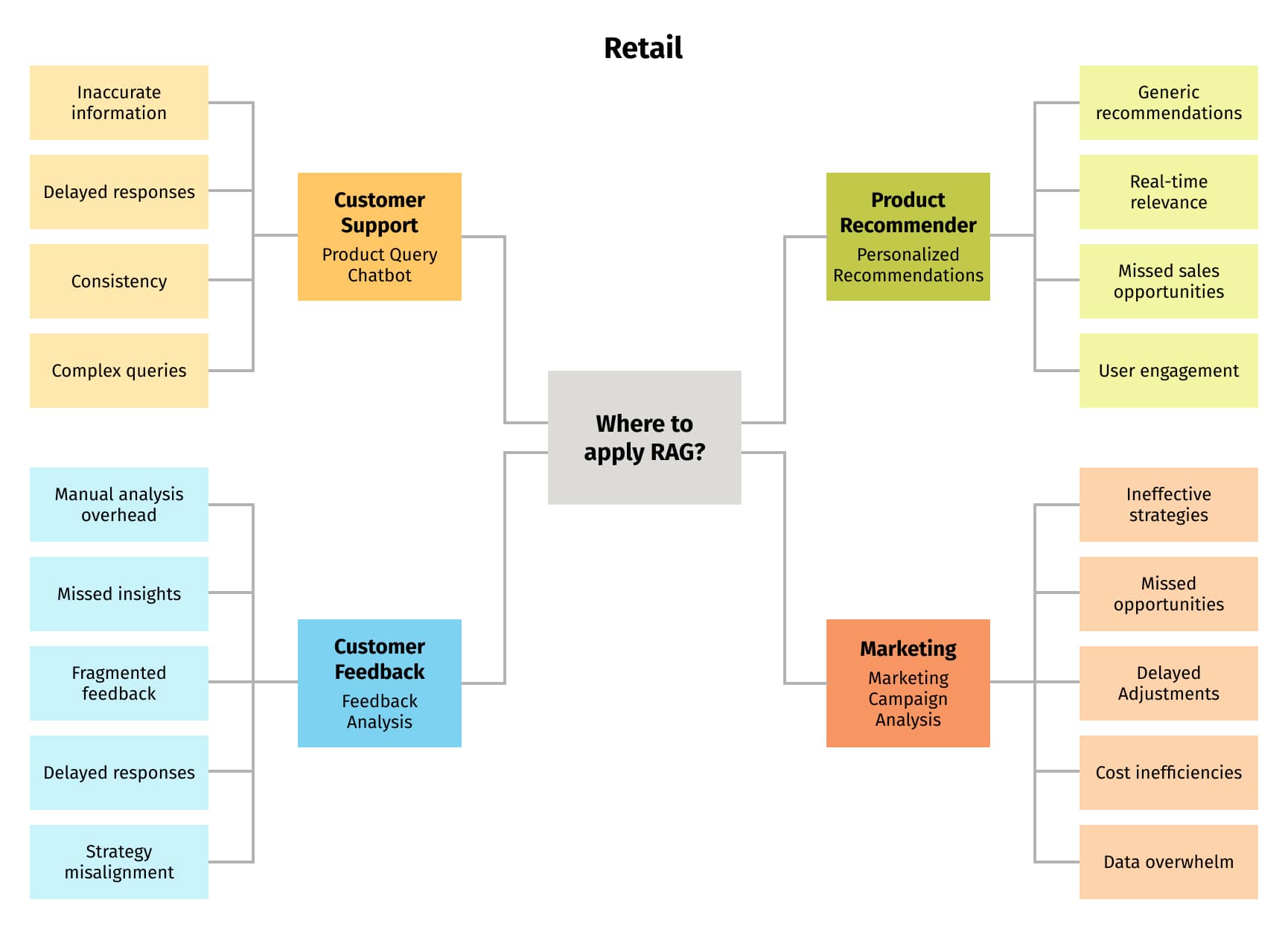
Customer support: Product query chatbot
Utilizing RAG, retailers can empower chatbots to fetch specific product details from vast databases in near real-time, enhancing customer queries' responsiveness and accuracy. This not only streamlines customer support but also ensures precise product information is relayed, leading to improved customer satisfaction and shopping experiences.
Consider an online fashion retailer with thousands of products listed. A customer might inquire about the fabric details of a particular dress. A RAG-powered chatbot can immediately pull the specific fabric composition and care instructions from the product listing, providing the customer with detailed information within seconds. Such immediate and accurate responses can instill confidence in customers, encouraging them to finalize their purchases and return to the retailer for future shopping needs, prolonged browsing sessions, and higher conversion rates, all achieved through RAG's data synthesis and real-time response capabilities.
Customer feedback: Feedback analysis
By delving deep into comments, reviews, and ratings, RAG synthesizes a holistic view of customer sentiments. It auto-generates detailed reports highlighting prevalent preferences and discernible pain points. With such insights at their fingertips, retailers can make informed adjustments to products, services, or strategies, ensuring a more attuned and enhanced shopping experience for their clientele.
Imagine an online store that has recently launched a new product line. By utilizing RAG, the store can aggregate feedback from various channels, interpret the sentiment, and identify if there are recurrent issues or praises about particular product features. The store can then either address the concerns or capitalize on the positives, leading to more satisfied customers and potentially increased sales.
Marketing: Marketing campaign analysis
In retail marketing, understanding campaign performance is extremely important. RAG offers a robust solution by diving deep into past campaign data, intertwining it with customer feedback and observed sales trends. By dissecting this information, RAG crafts detailed insights into which strategies truly resonate and which channels drive maximum engagement. Furthermore, it identifies potential gaps or areas of improvement in past campaigns. Retailers equipped with these insights are better positioned to refine their future marketing endeavors, ensuring they capture their audience's attention and foster lasting customer relationships.
Consider a retail brand that has run multiple marketing campaigns over the past year across various channels, from social media promotions to email newsletters. By deploying RAG, the brand can auto-generate a comprehensive analysis, capturing metrics like customer engagement, click-through rates, and sales conversion ratios. Such data-driven insights allow the brand to identify its most lucrative marketing strategies, adjust budget allocations, and tailor future campaigns to maximize ROI.
Product recommender: Personalized recommendations
RAG harnesses customer data, including past purchases and browsing history, to understand individual preferences. It dynamically generates tailored product suggestions aligned with user interests. As users interact in real time, recommendations adjust accordingly. The result? Enhanced user engagement, prolonged browsing sessions, and higher conversion rates, all achieved through RAG's data synthesis and near real-time response capabilities.
Imagine an online skincare retailer that offers a variety of products, from moisturizers to sunscreens. A user who previously purchased a moisturizer for dry skin logs back in a few months later. Utilizing RAG's capabilities, the site immediately suggests a compatible hydrating serum or perhaps a winter care skincare set. This kind of tailored recommendation not only meets the specific needs of the user but also encourages them to explore more products, thus enhancing their overall shopping experience and increasing sales opportunities for the retailer.
RAG in finance and insurance
In this section, we'll describe how RAG can be utilized within the finance domain, detailing various business scenarios, as highlighted in Figure 3. For each scenario, we'll shed light on the specific problems that RAG resolves within the world of finance.
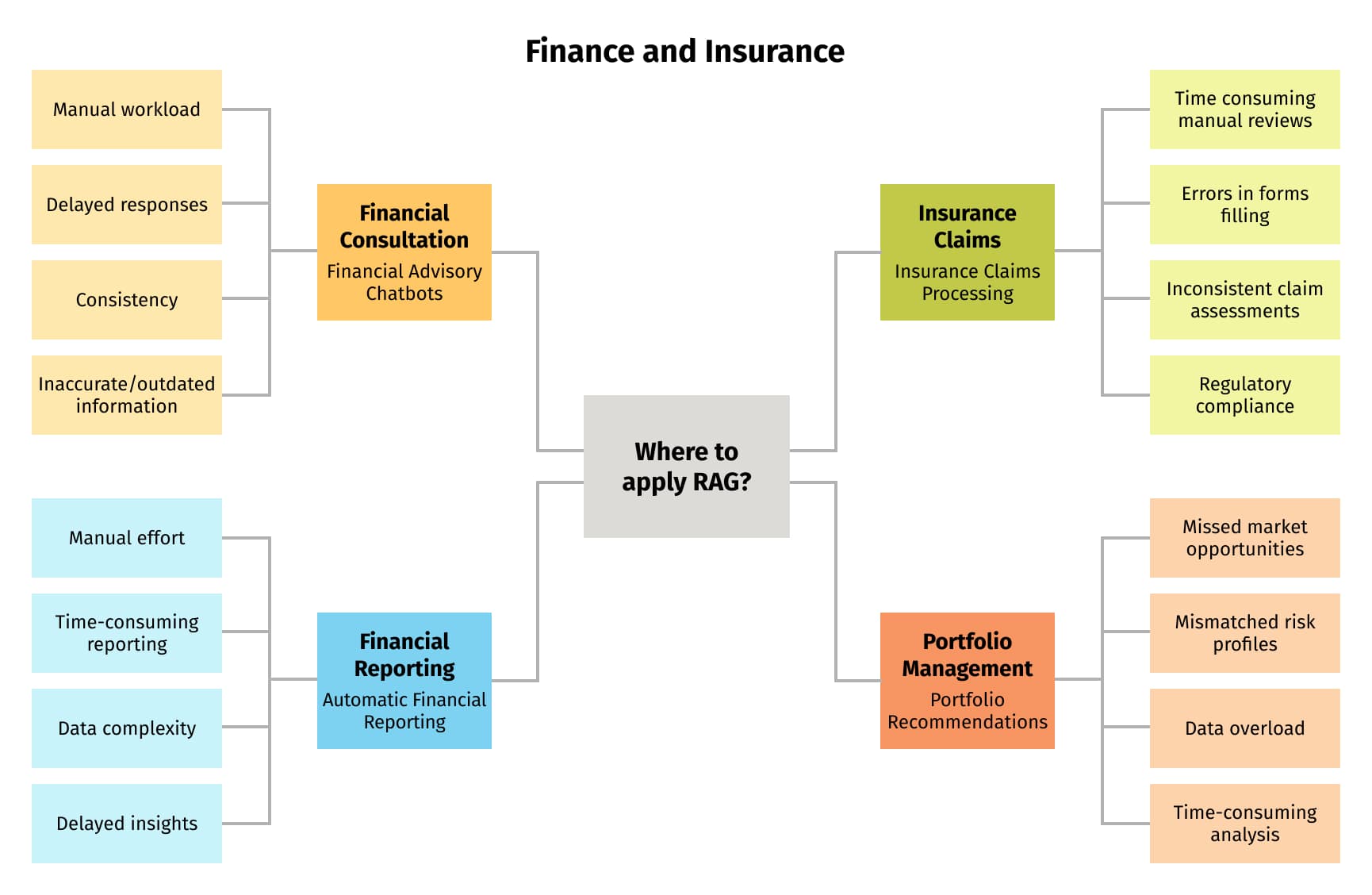
Financial consultation: Financial advisory chatbots
In the dynamic world of finance, clients frequently seek insights on investment tactics, market projections, and intricate financial products. To cater to this, financial institutions can employ RAG to automate the response mechanism, pulling accurate information from comprehensive financial databases. This ensures clients receive tailored advice grounded in up-to-date data and expert analyses. Consequently, the process not only elevates the client experience by offering rapid and precise answers but also optimizes the advisory function, making it more efficient and data-driven.
Take the scenario of a major bank that offers investment advisory services. A high-net-worth client, looking to diversify their portfolio, uses the bank's chat interface to inquire about potential investment opportunities in emerging markets. With RAG-powered chatbots, the system instantly combs through a plethora of global economic reports, past performance metrics of emerging market funds, and current geopolitical trends. It then provides the client with a detailed analysis of potential investment avenues, highlighting risks and rewards, all in near real-time. Such immediate and insightful feedback not only positions the bank as a trusted advisor but also fosters client loyalty, as they feel catered to with high precision and responsiveness.
Insurance claims: Automatic insurance claims processing
Insurance claims often involve sifting through extensive documentation and data. RAG can be utilized to quickly retrieve relevant policy details, claim histories, and regulatory guidelines when processing a claim. It can generate preliminary assessments, flag potential fraudulent activities based on historical patterns, or auto-populate forms with relevant details, streamlining the claim approval process and ensuring consistency and accuracy.
Consider a car insurance company that receives thousands of claims daily, especially after natural calamities like storms or floods. The manual processing of these claims can be both time-consuming and prone to errors. By implementing RAG, as soon as a policyholder submits a claim, the system can instantly fetch the policy details, compare the claim with previous ones, and even provide an immediate tentative evaluation based on existing policy guidelines and historical claim data. This rapid response not only expedites the claim processing but also significantly enhances the customer experience, especially during stressful post-accident scenarios.
Financial reporting: Automatic financial reporting
The financial world is filled with complex data, ranging from individual transactions to broad economic trends. Navigating this maze and presenting concise insights is extremely important for stakeholder comprehension and informed decision-making. RAG steps in as a transformative tool for this purpose. By accessing and analyzing vast data sets, RAG can distill complex financial narratives into coherent, digestible reports. Stakeholders, armed with these clear summaries, are better positioned to make strategic decisions. Through this automation, financial reporting becomes not only efficient but also consistently accurate and timely.
Consider a multinational corporation with numerous subsidiaries across the globe. Each month, the corporation has to consolidate and review financial data from all these entities to present to its board of directors. Manually curating this data and drafting reports can be a tedious and error-prone task. However, with RAG, the moment financial data gets updated in the central system, it fetches relevant data points from various sources, compares them against past performances, and incorporates macroeconomic indicators. The result is an automatically generated comprehensive financial report that highlights trends, potential concerns, and areas of growth. This empowers the board to understand the company's financial health at a glance and strategize accordingly, while also ensuring compliance and accuracy in reporting.
Enhanced portfolio management: Portfolio recommendations
Portfolio management is a delicate dance of balancing risks and returns, influenced by many factors. RAG emerges as a vital tool in this realm. By delving into past transaction histories, gauging current market dynamics, and understanding individual investor risk appetites, RAG can craft optimized portfolio strategies. These strategies, rooted in comprehensive data analysis, offer tailored recommendations or necessary adjustments for investors. As a result, investment portfolios become more aligned with market opportunities and individual financial goals. With RAG's capabilities, both novice and seasoned investors gain a data-driven edge in wealth maximization.
Imagine an investor in their mid-40s aiming for diversification and maximum returns to meet their early retirement goals. Over time, they've built a portfolio comprising various stocks, bonds, and other assets. However, with the unpredictability of global markets, they're uncertain about the optimal strategy to adopt. Using a platform powered by RAG, their financial advisor can swiftly assess past investment decisions, current market dynamics, and the investor's risk profile. RAG then provides a rebalanced portfolio recommendation, advising on which assets to retain, potential sectors for new investments, and the ideal bond-stock mix. This timely, tailored advice not only streamlines the decision-making process but also positions the portfolio for future growth, closely aligning with the investor's early retirement aspirations.
Case study: RFP processing with RAG
Now that we’ve explored various industry applications, it’s time to see RAG in action. This case study delves into how RAG can be used for creating an application designed to automate the intricacies of document processing, focusing primarily on composing and filling out responses for an RFP.
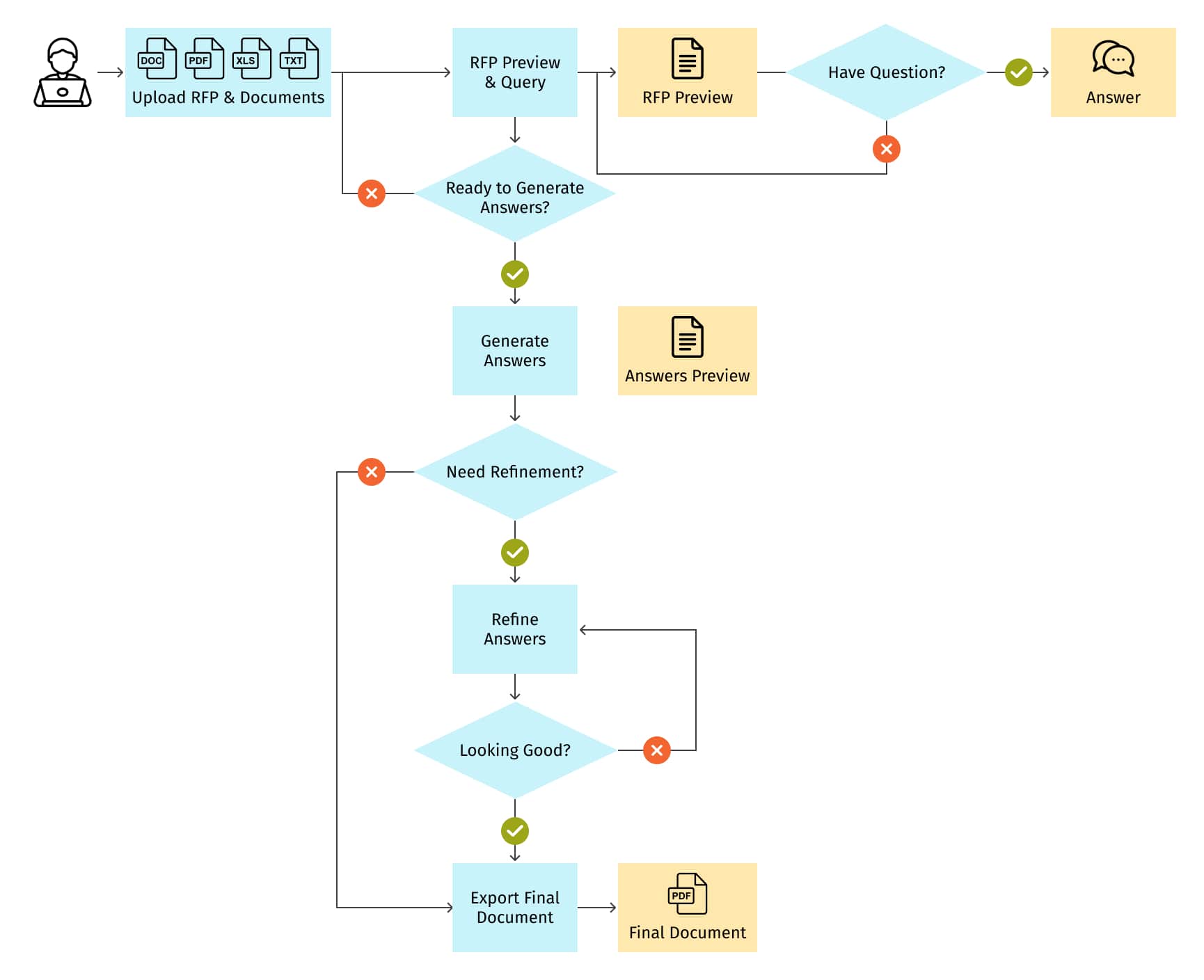
Step 1: Uploading RFP and supplementary documents
As depicted in Figure 4, the workflow begins with a user uploading the RFP file and supplementary documents, which may include product details, company information, and so forth. These documents can vary in format, spanning from PDFs and Excel sheets to Word documents, plain text files, etc.
Step 2: Previewing RFP and posing queries
Upon uploading, users can preview the RFP and pose queries related to the content. Questions can range from seeking a summary of the RFP to more nuanced inquiries like understanding the primary concerns of the RFP.
Step 3: Receiving recommendations from RAG
The application, harnessing the power of RAG, offers insightful recommendations to enhance the likelihood of winning the RFP bid.
Step 4: Activating automatic answer generation
After preview and initial queries, users can opt to activate the automatic answer generation feature. This function identifies all the questions and requirements outlined in the RFP and crafts corresponding responses.
Step 5: Answer preview and modification
Once generated, users are presented with a preview of the question-answer pairs, granting them the autonomy to select and modify any answers they find unsatisfactory.
Step 6: Answer refinement phase
This leads to the answer refinement phase. Here, users can provide a prompt or directive on how they envision the answer, and the integrated RAG with LLM will regenerate the response accordingly. If satisfied with the refinement, users can save their selections and progress to the subsequent stages.
It's worth noting that while the workflow offers the efficiency of full automation, users retain the flexibility to assess and adjust intermediate outcomes, provide feedback via textual prompts, and repeat and revisit any phase as desired.
Step 7: Exporting the finalized RFP
The culminating step in this workflow is the exportation of the finalized RFP, filled with tailored answers, primed for submission to the RFP issuer.
This case study exemplifies how RAG can revitalize the traditional RFP process, eliminating inefficiencies like manual form filling, inconsistent responses, and inaccuracies, all while dramatically reducing response times. More details about this application can be found here.
Assembling RAG flows: From basic building blocks to valuable use cases
You’ve no doubt realized the value and potential of RAG by now, and might be wondering how to get started with it in your organization. One of the key strengths of RAG is its modularity. Its foundational building blocks can be assembled in various configurations, allowing businesses to craft custom solutions suited to their specific needs. Before diving deep into the individual building blocks, let’s understand how these components can be cohesively integrated to form valuable RAG flows and use cases.
- Identify the business challenge or objective: Start by pinpointing the specific challenge or objective you want to address. Whether it's enhancing customer support through chatbots, streamlining financial reporting, or optimizing portfolio management, having a clear goal will guide your RAG assembly process.
- Select the right data sources: For RAG to deliver accurate, relevant results, you must feed it the right data. Identify the databases, repositories, or knowledge bases that contain the information relevant to your challenge.
- Configure the retrieval mechanism: Decide how you want RAG to fetch information. Should it scan entire documents, or focus on summaries? How many sources should it refer to? This step involves fine-tuning the 'Retrieval' aspect of RAG.
- Optimize the generation model: With the right data in hand, the next step is to ensure RAG processes and presents it effectively. This involves configuring the 'Generation' aspect of the model, tailoring it to produce clear, concise, and contextually relevant outputs.
- Implement feedback loops: No system is perfect from the get-go. Incorporate mechanisms to gather user feedback, allowing for continuous improvement of the RAG system. This ensures the system remains relevant and accurate over time.
- Iterate and refine: RAG's modular nature means it's highly adaptable. As business needs change or as more data becomes available, revisit and refine your RAG configurations to ensure maximum value.
In the upcoming sections, we'll delve deeper into the architecture of RAG and its building blocks, providing insights into how each one functions and how they can be optimized for best results.
Architecture of Retrieval-Augmented Generation
Understanding RAG architecture is key to fully harnessing its benefits and potential. The process essentially consists of two primary components: The Retriever and the Generator, which together form a seamless flow of information processing. This process is displayed below:
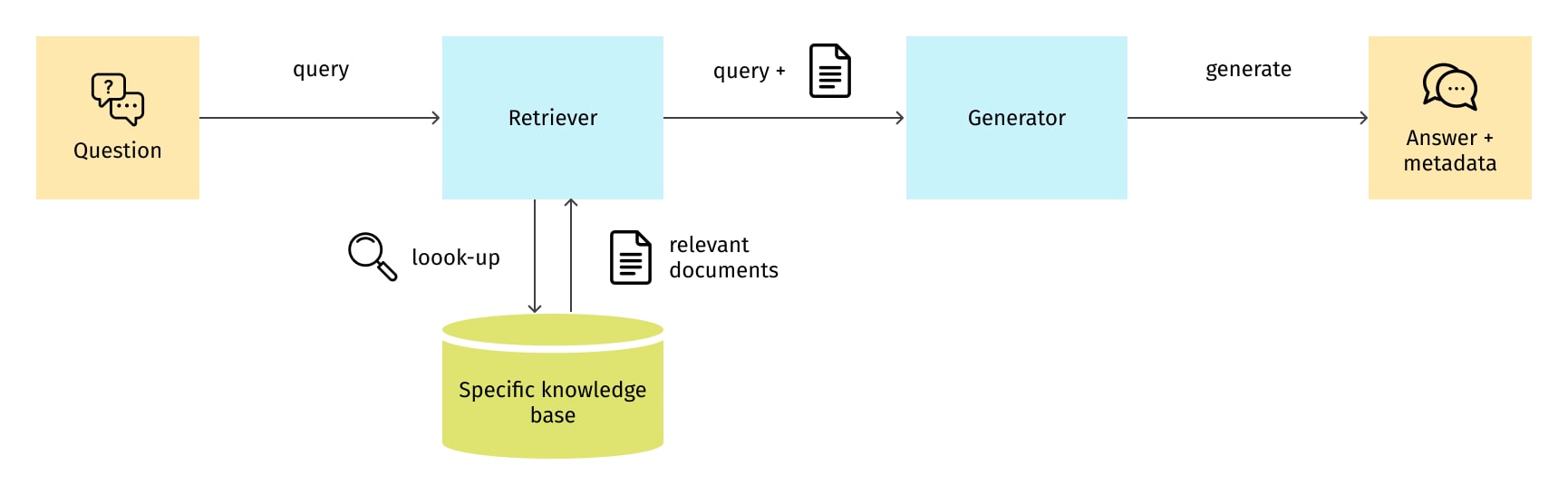
Retriever
The Retriever's role is to fetch relevant documents from the data store in response to a query. The Retriever can use different techniques for this retrieval, most notably Sparse Retrieval and Dense Retrieval.
Sparse Retrieval has traditionally been used for information retrieval and involves techniques like TF-IDF or Okapi BM25 to create high-dimensional sparse vector representations of documents. However, this approach often requires exact word matches between the query and the document, limiting its ability to handle synonyms and paraphrasing.
On the other hand, Dense Retrieval transforms both the query and the documents into dense lower-dimensional vector representations. These vector representations, often created using transformer models like BERT, RoBERTa, ELECTRA, or other similar models, capture the semantic meaning of the query and the documents, allowing for a more nuanced understanding of language and more accurate retrieval of relevant information.
Generator
Once the Retriever has fetched the relevant documents, the Generator comes into play. The Generator, often a model like GPT, Bard, PaLM2, Claude, or open-source LLM from Hugging Face, takes the query and the retrieved documents, and generates a comprehensive response.
Orchestrating RAG processes
The foundational RAG process we discussed previously can be refined and orchestrated into a comprehensive automated workflow, culminating in a holistic business solution, as illustrated in Figure 6:
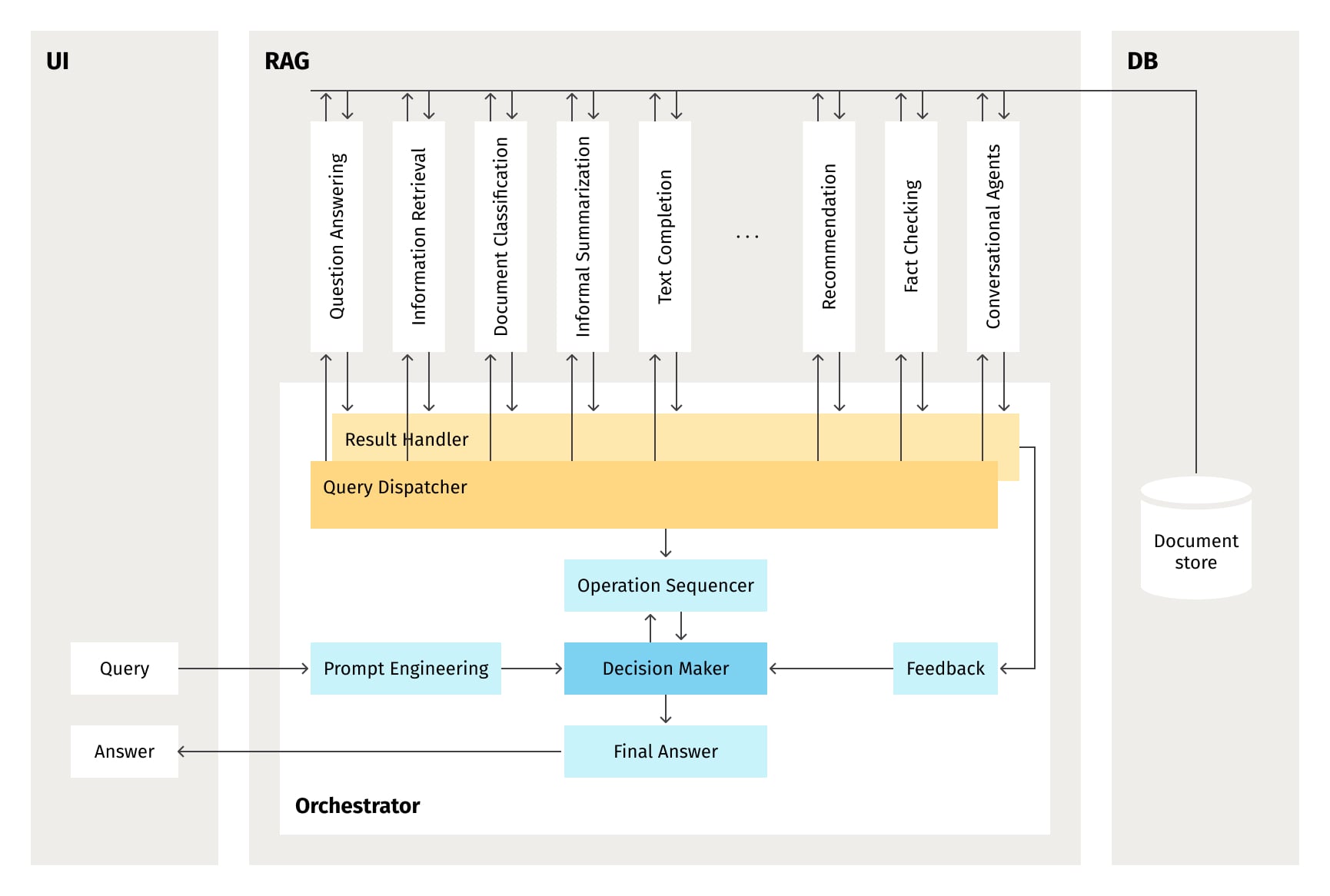
RAG operations
This orchestrated process can combine various RAG operations:
- Question answering: Extracts relevant details for a query and produces a concise answer.
- Information retrieval: Scours a corpus to fetch relevant data or documents based on a query.
- Document classification: Categorizes a document into specific labels using the fetched context.
- Information summarization: Generates a summary from identified relevant details.
- Text completion: Completes text using the extracted context.
- Recommendation: Offers context-based suggestions or advice for a provided prompt.
- Fact checking: Validates or fact-checks a statement using evidence from a corpus.
- Conversational agents: Chatbots or virtual assistants use RAG for informed dialogue responses.
Orchestrator components
To seamlessly blend these operations into automated solutions, we need an orchestrator with the following components:
- Prompt engineering: Interprets UI queries, creates fitting prompts based on the RAG operation, and forwards them to the decision maker.
- Decision maker: Analyzes inputs/outputs to determine subsequent steps. For example, document classification may influence subsequent extraction methods. It then sends decisions and prompts to the operation sequencer.
- Operation sequencer: Dictates the sequence of operations. Ensures the workflow progresses coherently and efficiently, aligned with the automation process's objectives. Interacts with the decision maker and query dispatcher.
- Query dispatcher: Routes queries to designated RAG operations, ensuring the right module processes each query in a timely manner.
- Result handler: Manages results from each RAG operation, which might include storing, logging, or pre-processing them for the next steps. It synchronizes with the feedback integrator.
- Feedback integrator: Uses previous RAG operation outputs to guide the next operation, serving as a continuous enhancement loop. Post-analysis, it forwards these results to the decision maker.
The process flow
In this subsection, we will compile all the steps and building blocks of the RAG process flow, as shown in Figure 7:
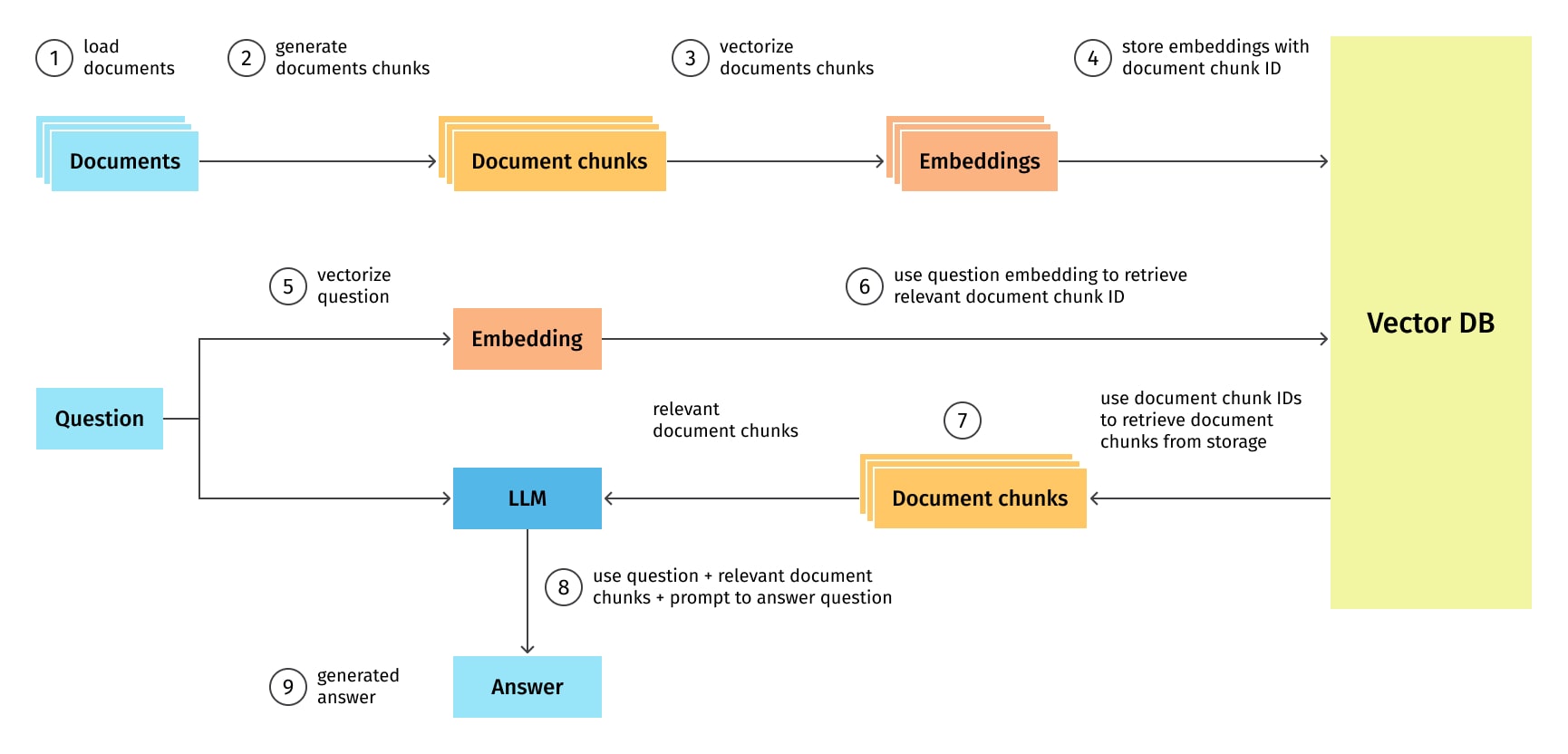
- Document loading: The initial step involves loading the documents from a data storage, text extraction, parsing, formatting and cleaning as part of the data preparation for the document splitting.
- Document splitting: Next, documents are broken down into small manageable segments, or chunks. Strategies may range from fixed-size chunking to content-aware chunking, which understands the structure of the content and splits accordingly.
- Text embedding: Next, these chunks are transformed into vector representations, or embeddings, using techniques such as Word2Vec, GloVe, BERT, RoBERTa, and ELECTRA. This step is essential for the semantic comprehension of the document chunks.
- Vector store: The generated vectors, each associated with a unique document chunk ID, are stored in a vector store. Here, the stored vectors are indexed for efficient retrieval. Depending on the vector store used, this could involve creating search trees or hash tables, or mapping vectors to bins in a multi-dimensional space.
- Query processing: When a query is received, it is also converted into a vector representation using the same technique as in the third 'Text embedding' step.
- Document retrieval: The Retriever, using the query's vector representation, locates and fetches the document chunks that are semantically most similar to the query. This retrieval is performed using similarity search techniques.
- Document chunk fetching: The relevant document chunks are then retrieved from the original storage using their unique IDs.
- LLM prompt creation: The retrieved document chunks and the query are combined to form the context and the prompt for the LLM.
- Answer generation: In the final step, the LLM generates a response based on the prompt, thus concluding the RAG process.
Constructing the RAG pipeline: Essential building blocks
In this section, we will delve into the best practices for implementing each building block in the RAG process flow, providing additional elaboration to ensure a more comprehensive understanding.
Document loading
Text data, the raw material for LLMs, can come in many forms, ranging from unstructured plain text files (.txt), rich documents like PDF (.pdf) or Microsoft Word (.doc, .docx), data-focused formats such as Comma-Separated Values (.csv) or JavaScript Object Notation (.json), web content in Hypertext Markup Language (.html, .htm), documentation in Markdown (.md), or even programming code written in diverse languages (.py, .js, .java, .cpp, etc.), and many more. The process of preparing and loading these varied sources for use in a LLM often involves tasks like text extraction, parsing, cleaning, formatting, and converting to plain text.
Among the tools that assist in this process, LangChain stands out. This popular framework is widely recognized in the field of LLM application development. What sets it apart is its impressive ability to handle more than 80 different types of documents, making it an extremely versatile tool for data loading. LangChain's data loaders are comprehensive, including Transform Loaders that are used to convert different document formats into a unified format that can be easily processed by LLMs. Additionally, it supports Public Dataset Loaders, which provide access to popular and widely-used datasets, as well as Proprietary Dataset or Service Loaders, which enable integration with private, often company-specific, data sources or APIs.
Document splitting
The process of document splitting begins once the documents are successfully loaded, parsed, and converted into text. The core activity in this stage involves segmenting these texts into manageable chunks, a procedure also known as text splitting or chunking. This becomes essential when handling extensive documents. Given the token limit imposed by many LLMs (like GPT-3's approximate limit of 2048 tokens), and considering the potential size of documents, text splitting becomes indispensable. The chosen method for text splitting primarily depends on the data's unique nature and requirements.

Even if the process of dividing these documents into smaller, manageable segments seems straightforward, this process is filled with intricacies that could significantly impact subsequent steps. A naive approach is to use fixed chunk size, but if we do that, we can end up with part of one sentence in one chunk and another in another chunk, as shown in Figure 8. When we come to question answering, we won’t have the right information in either chunk because it is split apart.
As such, it is crucial to consider semantics when dividing a document into chunks. Most document segmentation algorithms operate on the principle of chunk size and overlap. Below, in Figure 9, is a simplified diagram that depicts this principle. Chunk size, which can be measured by character count, word count, or token count, refers to each segment's length. Overlaps permit a portion of text to be shared between two adjacent chunks, operating like a sliding window. This strategy facilitates continuity and allows a piece of context to be present at the end of one chunk and at the beginning of the next, ensuring the preservation of semantic context.

Fixed-size chunking with overlap is a straightforward approach that is often favored due to its simplicity and computational efficiency. Besides fixed-size chunking, there are more sophisticated 'content-aware' chunking techniques:
- Sentence splitting: Various approaches exist for sentence chunking, including naive splitting (splitting on periods and new lines), using Natural Language Toolkit (NLTK), or using the Python library, spaCy. Both NLTK and spaCy are robust libraries for Natural Language Processing (NLP) that offer efficient ways to split text into sentences. Some advanced tools use smaller models to predict sentence ends, and use these points for segment divisions.
- Recursive chunking: This method divides the input text into smaller chunks in a hierarchical and iterative manner. It uses different separators or criteria until the desired chunk size or structure is achieved.
- Specialized chunking techniques: For structured and formatted content like Markdown and LaTeX, specialized chunking techniques intelligently divide the content based on its structure and hierarchy, producing semantically coherent chunks.
When deciding on chunk size, if the common chunking approaches do not fit your use case, a few pointers can guide you toward choosing an optimal chunk size:
- Preprocessing your data: Ensure data quality before determining the best chunk size for your application. For example, if your data has been retrieved from the web, you might need to remove HTML tags or specific elements that just add noise.
- Selecting a range of chunk sizes: Once your data is preprocessed, choose a range of potential chunk sizes to test. This choice should take into account the nature of the content, the embedding model to use, and its capabilities (e.g. token limits). The objective is to find a balance between preserving context and maintaining accuracy.
- Evaluating the performance of each chunk size: With a representative dataset, create the embeddings for the chunk sizes you want to test. Run a series of queries, evaluate quality, and compare the performance of the various chunk sizes. This process will most likely be iterative.
In conclusion, there's no one-size-fits-all solution to document splitting, and what works for one use case may not work for another. This section should help provide an intuitive understanding of how to approach document chunking for your specific application.
Text embedding
Following the document splitting process, the text chunks undergo a transformation into vector representations that can be easily compared for semantic similarity. This 'embedding' encodes each chunk in such a way that similar chunks cluster together in vector space.

Vector embeddings constitute an integral part of modern machine learning (ML) models. They involve mapping data from complex, unstructured forms like text or images to points in a mathematical space, often of lower dimensionality. This mathematical space, or vector space, enables efficient calculations, and crucially, the spatial relationships in this space can capture meaningful characteristics of the original data. For instance, in the case of text data, embeddings capture semantic information. Text that conveys similar meaning, even if worded differently, will map to close points in the embedding space.
To illustrate, the sentences "The cat chases the mouse" and "The feline pursues the rodent" might have different surface forms, but their semantic content is quite similar. A well-trained text embedding model would map these sentences to proximate points in the embedding space.
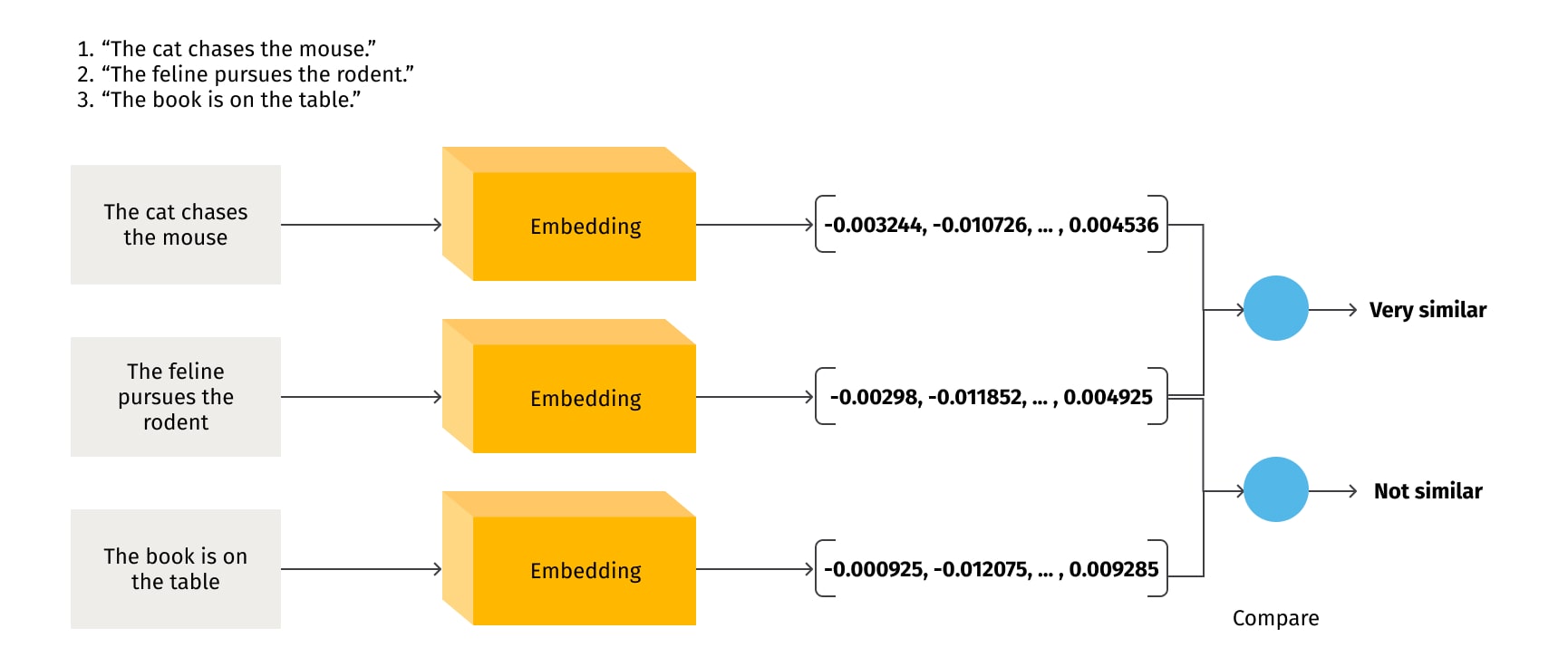
The visualization of text embeddings can provide intuitive insight into how this works. In a two- or three-dimensional representation of the embedding space, similar words or sentences cluster together, indicating their semantic proximity. For example, embeddings of 'dog', 'cat', 'pet' might be closer to each other than to the embedding of 'car', as depicted in Figure 12.
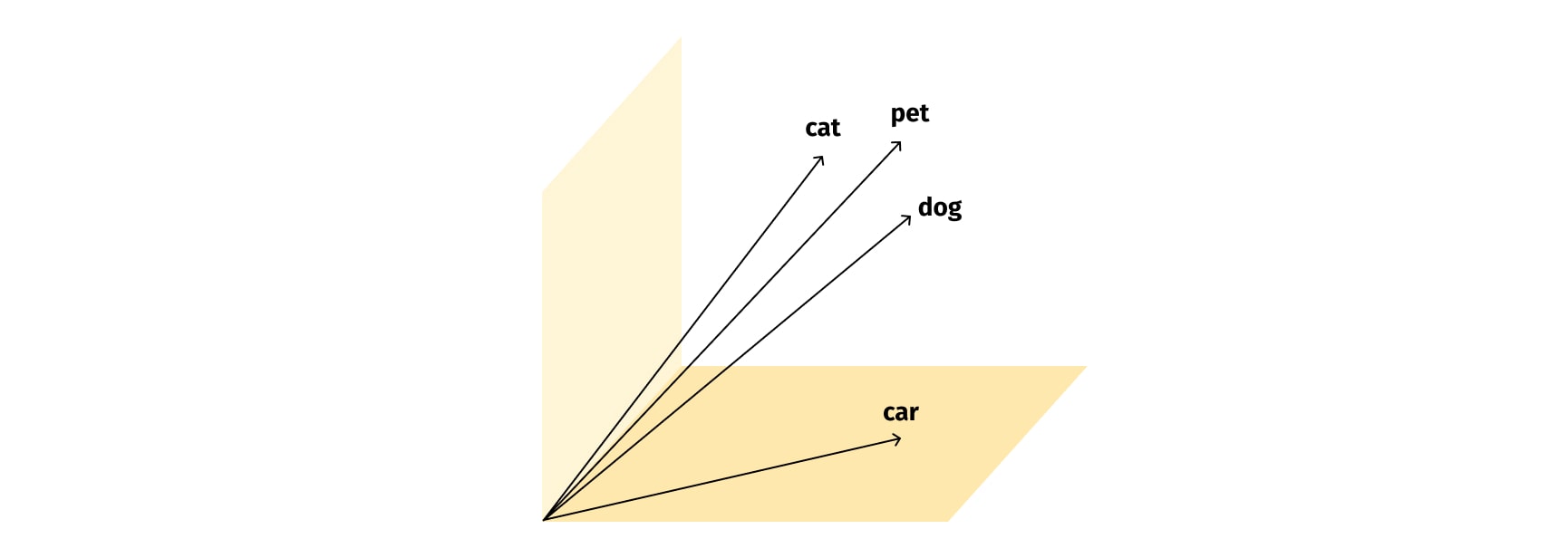
Producing these embeddings involves sophisticated ML models. Initially, models like Word2Vec and GloVe made strides by learning word-level embeddings that captured many useful semantic relationships. These models essentially treated words in isolation, learning from their co-occurrence statistics in large text corpora.
The current state-of-the-art has moved towards transformer-based models like BERT, RoBERTa, ELECTRA, T5, GPT, and their variants, which generate context-aware embeddings. Unlike previous models, these transformers take into account the whole sentence context when producing the embedding for a word or sentence. This context-awareness allows for a much richer capture of semantic information and ambiguity resolution.
For instance, the word 'bank' in "I sat on the bank of the river", and "I deposited money in the bank" has different meanings, which would be captured by different embeddings in a transformer-based model. Such transformer-based models are central to the latest advances in NLP, including RAG. In RAG, transformer-based models are utilized to retrieve relevant information from a large corpus of documents (the 'retrieval' part) and use it to generate detailed responses (the 'generation' part). The high-quality embeddings produced by transformer models are essential to this process, both for retrieving semantically relevant documents and for generating coherent and context-appropriate responses.
Vector store
After documents are segmented into semantically meaningful chunks and subsequently converted into vector space, the resulting embeddings are stored in a vector store. Vector stores are unique search databases designed to enable vector searches and handle storage and certain facets of vector management. Essentially, a vector store is a database that allows straightforward lookups for similar vectors. Efficient execution of a RAG model requires an effective vector store or index to house transformed document chunks and their associated IDs.The choice of a vector store depends on numerous variables, such as data scale and computational resources. Some noteworthy vector stores are:
- FAISS: Developed by Facebook AI, FAISS is a library renowned for efficiently managing massive collections of high-dimensional vectors as well as performing similarity search and clustering in high-dimensional environments. It incorporates advanced methods aimed at optimizing memory usage and query duration, leading to proficient storage and retrieval of vectors, even when handling billions of vectors.
- SPTAG: A product of Microsoft, SPTAG is a library tailored for high-dimensional data. It provides a variety of index and search algorithm types, balancing between precision and speed according to specific requirements.
- Milvus: Milvus, an open-source vector database, has earned considerable esteem in the disciplines of data science and ML. Its robust functionality for vector indexing and querying, harnessed through cutting-edge algorithms, facilitates rapid retrieval of comparable vectors, even in the context of extensive datasets. A contributing factor to Milvus' acclaim is its compatibility with established frameworks such as PyTorch and TensorFlow, enabling a smooth transition into extant ML workflows.
- Chroma: Chroma is an open-source lightweight in-memory vector database, specifically tailored to facilitate the creation of LLM applications for developers and organizations across all scales. It provides an efficient, scalable platform for the storage, search, and retrieval of high-dimensional vectors. A key factor in Chroma's broad appeal is its versatility. With options for both cloud and on-premise deployment, it caters to varying infrastructure needs. Furthermore, its support for diverse data types and formats enhances its utility across an array of applications.
- Weaviate: Weaviate is a robust, open-source vector database designed for either self-hosting or fully managed services. This versatile platform offers organizations an advanced solution for managing and handling data with an emphasis on high performance, scalability, and accessibility. Regardless of the chosen deployment strategy, Weaviate presents comprehensive functionality and flexibility to accommodate a diverse array of data types and applications. An important characteristic of Weaviate is its ability to store both vectors and objects, making it conducive for applications that require the amalgamation of different search techniques, such as vector-based and keyword-based searches.
- Elasticsearch: This is a distributed, RESTful search, and analytics engine that efficiently stores and searches high-dimensional vectors. Its scalability and capability to handle vast data volumes make it suitable for large-scale applications.
- Pinecone: Profiled in early 2021, Pinecone is a cloud-based, managed vector database specifically designed to streamline the development and deployment of large-scale ML applications for businesses and organizations. Contrary to many prevalent vector databases, Pinecone utilizes proprietary, closed-source code. The robust support it offers for high-dimensional vector databases renders Pinecone appropriate for a diverse range of applications including similarity search, recommendation systems, personalization, and semantic search. It also boasts a single-stage filtering capability. Furthermore, its capacity to perform real-time data analysis makes it an optimal choice for threat detection and cyberattack monitoring in the cybersecurity sector. Pinecone also facilitates integration with a variety of systems and applications, including but not limited to Google Cloud Platform, Amazon Web Services (AWS), OpenAI, GPT-3, GPT-3.5, GPT-4, ChatGPT Plus, Elasticsearch, Haystack, and others.
By selecting the correct text embedding technique and vector store, it's possible to establish an efficient and effective system for indexing document chunks. Such a system enables the quick retrieval of the most relevant chunks for any query, which is a vital step in RAG.
In the next section, we explore the process of managing incoming queries and retrieving the most relevant chunks from the index.
Document retrieval
The retrieval process is an integral part of any information retrieval system, such as the one used for document searching or question answering. The retrieval process starts when a query is received, and it is transformed into a vector representation using the same embedding model used for document indexing. This results in a semantically meaningful representation of the user's question which can subsequently be compared with the chunk vectors of documents stored in the index, also known as the vector store.
The primary objective of the retrieval is to return relevant chunks of documents that correspond to the received query. The specific definition of relevance depends on the type of retriever being used. The retriever does not need to store documents; its sole purpose is to retrieve the IDs of relevant document chunks, thereby aiding in narrowing down the search space by identifying chunks likely to contain relevant information.
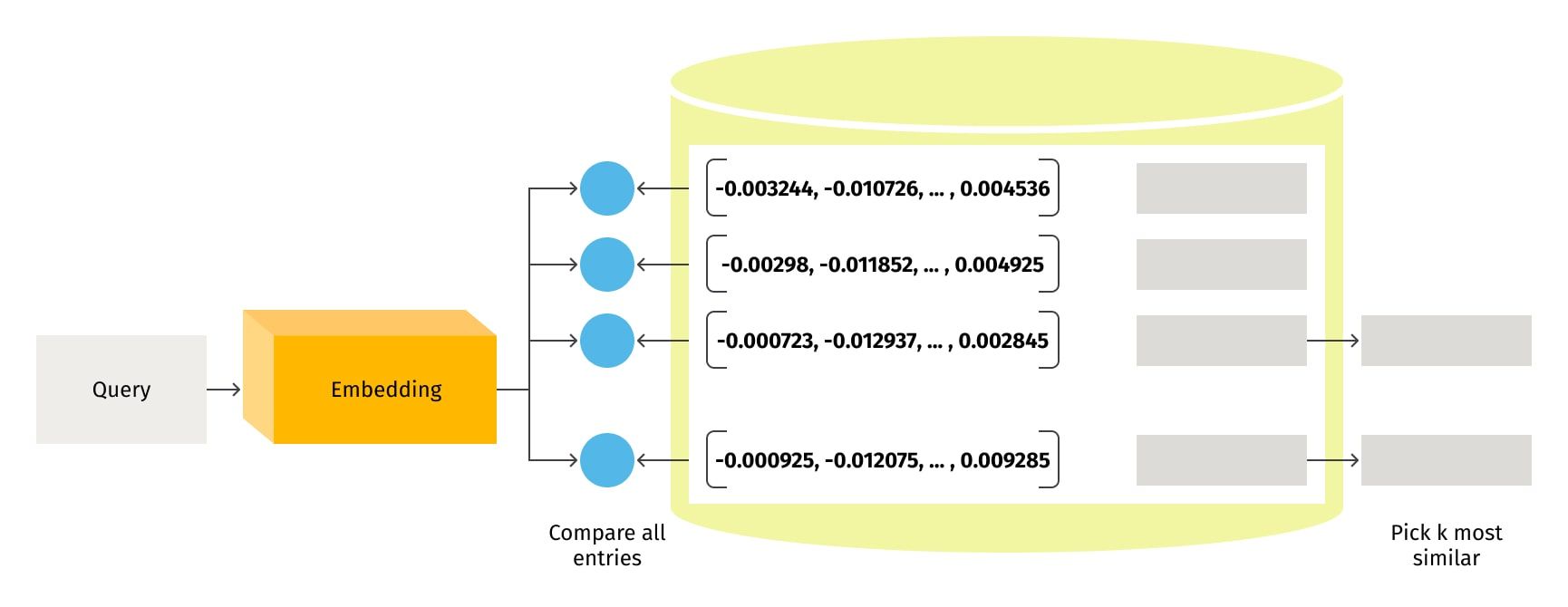
Different types of search mechanisms can be employed by a retriever. For instance, a ‘similarity search’ identifies documents similar to the query based on cosine similarity. Another search type, the maximum marginal relevance (MMR), is useful if the vector store supports it. This search method ensures the retrieval of documents that are not only relevant to the query but also diverse, thereby eliminating redundancy and enhancing diversity in the retrieved results. In contrast, the ‘similarity search’ mechanism only takes semantic similarity into account.
RAG also utilizes a similarity score threshold retrieval method. This method sets a similarity score threshold and only returns documents with a score exceeding that threshold. During the search for similar documents, it is common to specify the top 'k' documents to retrieve using the 'k' parameter.
There's another type of retrieval known as self-query or LLM-aided retriever. This type of retrieval becomes particularly beneficial when dealing with questions that are not solely about the content that we want to look up semantically but also include some mention of metadata for filtering. The LLM can effectively split the query into search and filter terms. Most vector stores can facilitate a metadata filter to help filter records based on specific metadata. In essence, LLM-aided retrieval combines the power of pre-trained language models with conventional retrieval methods, enhancing the accuracy and relevance of document retrieval.
One more significant retrieval method incorporates compression, which aims to reduce the size of indexed documents or embeddings, thereby improving storage efficiency and retrieval speed. This process involves the Compression LLM examining all documents and extracting the most relevant ones for the final LLM. Though this technique involves making more LLM calls, it also aids in focusing the final answer on the most crucial aspects. It's a necessary trade-off to consider. Compression in retrieval is particularly crucial when dealing with large document collections. The choice of compression method depends on a variety of factors, including the specific retrieval system, the size of the document collection, available storage resources, and the preferred balance between storage efficiency and retrieval speed.
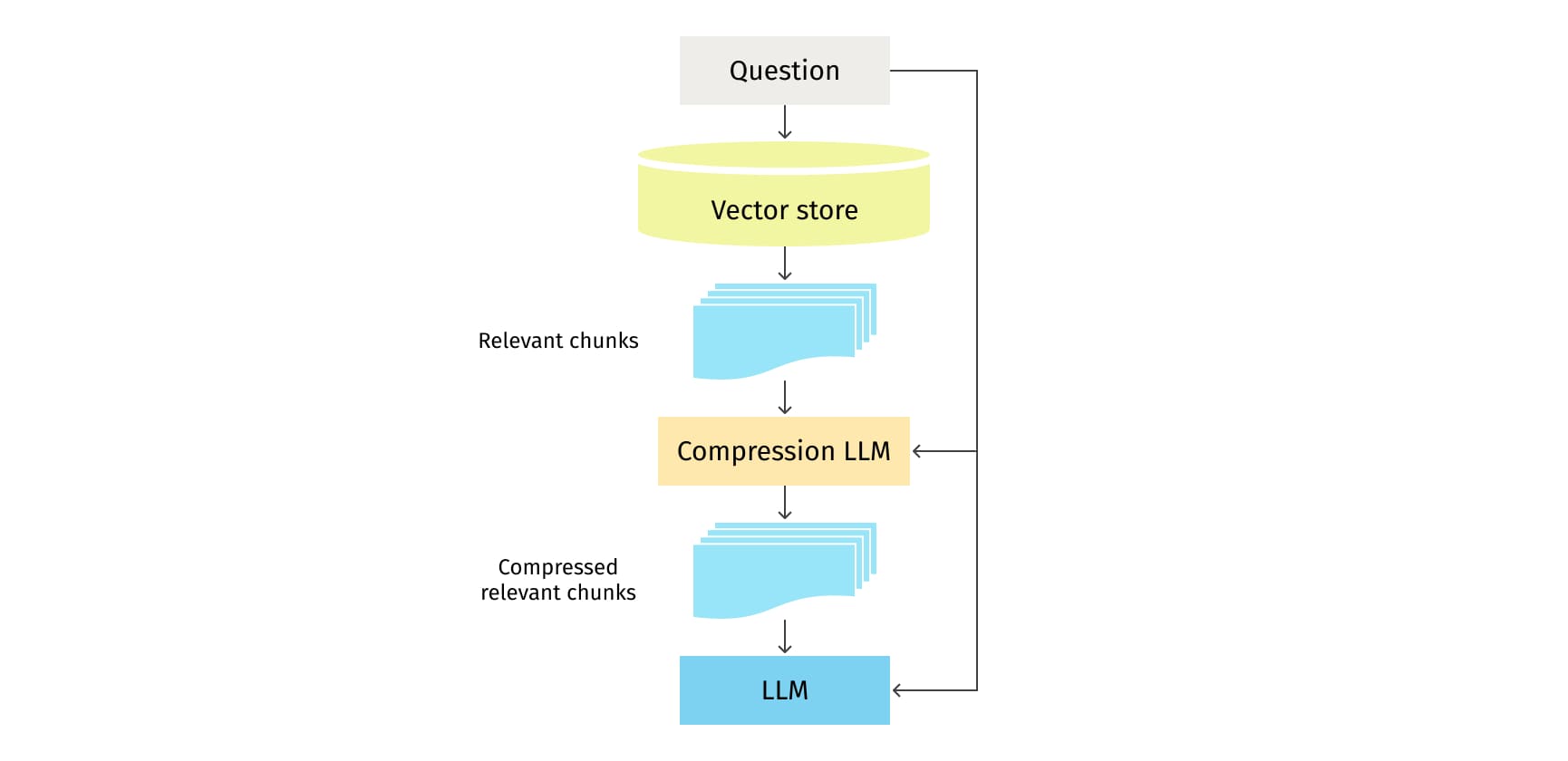
It is also worth noting that other retrieval methods exist that don't involve a vector database, instead using more traditional NLP techniques, such as Support Vector Machines (SVM) and Term Frequency-Inverse Document Frequency (TF-IDF). However, these methods are not commonly used for RAG.
Answer generation
In the final phase, the document chunks identified as relevant are used alongside the user query to generate a context and prompt for the LLM. This prompt (Figure 15), which is essentially a carefully constructed question or statement, guides the LLM in generating a response that is both relevant and insightful.
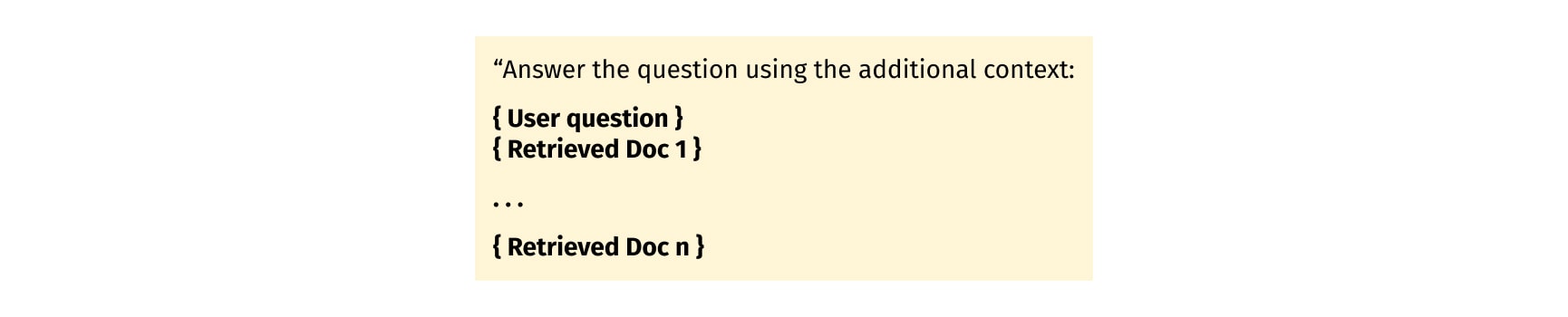
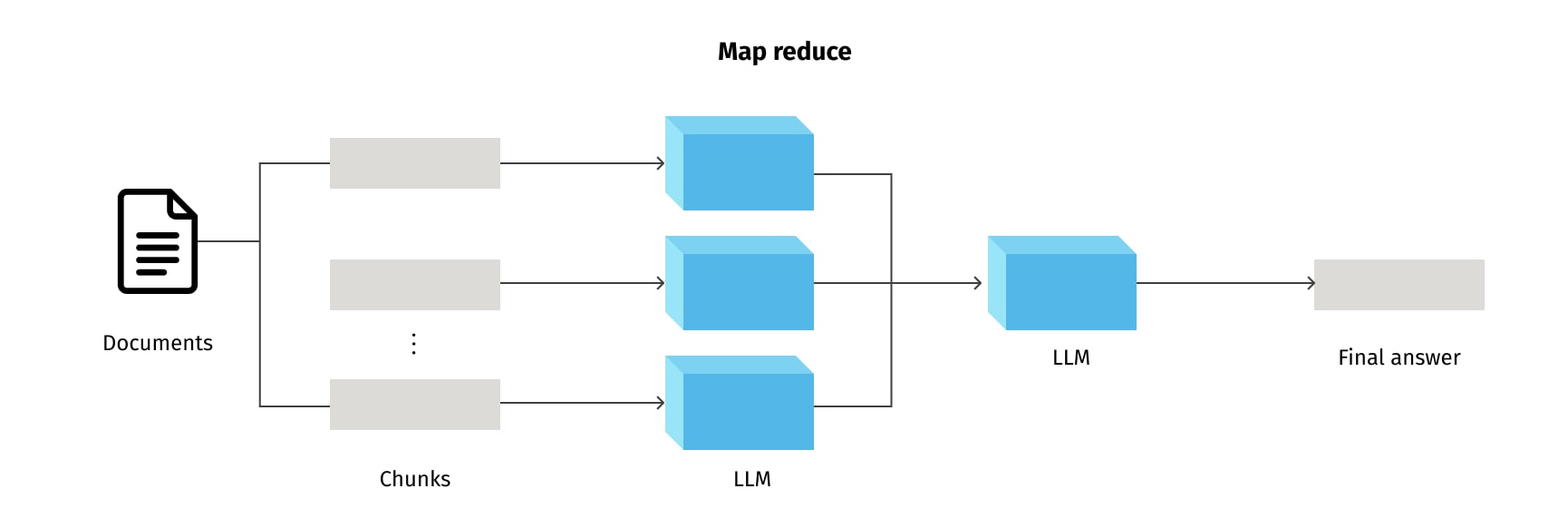
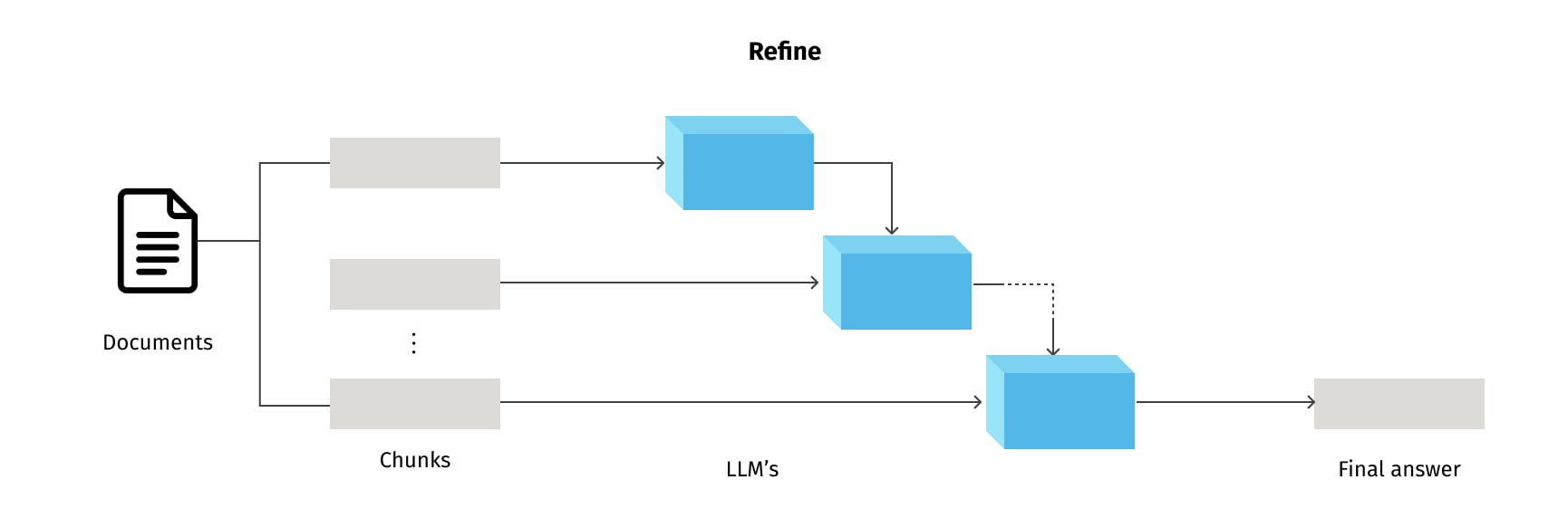
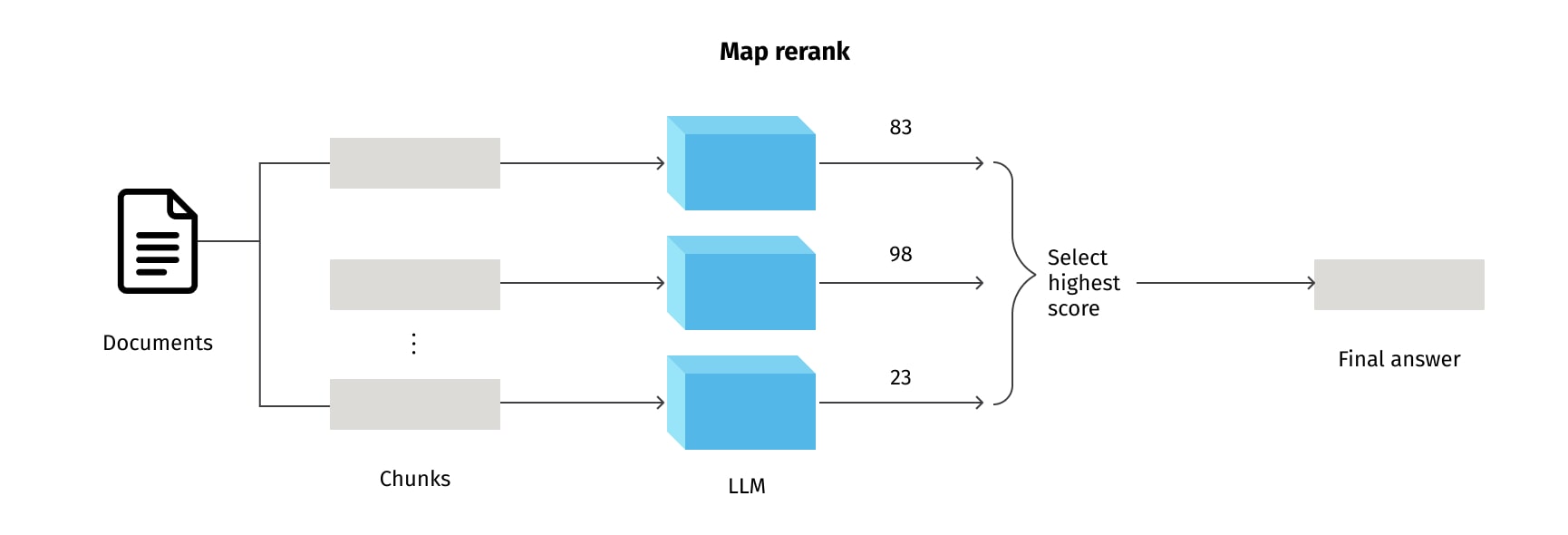
By default, we funnel all the chunks into the same context window within a single LLM call. In LangChain, this approach is known as the “Stuff” method, and it is the simplest form of question-answering. It follows a straightforward approach, where a prompt is processed, and an answer is immediately returned based on the LLM understanding. The "Stuff" method does not involve any intermediate steps or complex algorithms, making it ideal for straightforward questions that demand direct answers. However, a limitation emerges when dealing with an extensive volume of documents, as it may become impractical to accommodate all of them within the context window, potentially resulting in a lack of depth when confronted with complex queries. Nevertheless, there are a few different methods to get around the issue of short context windows, such as: “Map-reduce”, “Refine”, and “Map-rerank”.
The Map-reduce method, inspired by the widely embraced parallel processing paradigm, works by initially sending each document separately to the language model to obtain individual answers. These individual responses are then combined into a final response through a final call to the LLM. Although this method entails more interactions with the language model, it has the distinct advantage of processing an arbitrary number of document chunks. This method proves particularly effective for complex queries as it enables simultaneous processing of different aspects of a question, thus generating more comprehensive responses. However, this method is not without its drawbacks. It tends to be slower and, in certain cases, may yield suboptimal results. For instance, the absence of a clear answer based on the given chunk of the document may arise due to the fact that responses are based on individual document chunks. Hence, if relevant information is dispersed across two or more document chunks, the necessary context might be lacking, leading to potential inconsistencies in the final answer.
The Refine method follows an iterative approach. It refines the answer by iteratively updating the prompt with relevant information. It is particularly useful in dynamic and evolving contexts, where the first answer may not be the best or most accurate.
The Map-rerank method is a sophisticated method that ranks the retrieved documents based on their relevance to the query. This method is ideal for scenarios where multiple plausible answers exist, and there is a need to prioritize them based on their relevance or quality.
Each mentioned method has its own advantages and can be chosen based on the desired level of abstraction for question-answering. In summary, the different chain types of question-answering provide flexibility and customization options for retrieving and distilling answers from documents. They can be used to improve the accuracy and relevance of the answers provided by the language model.
The successful interplay of all these steps in the RAG flow can lead to a highly effective system for automating document processing and generating insightful responses to a wide variety of queries.
Conclusion: The benefits of Retrieval-Augmented Generation and Large Language Models
The adoption of business process automation has notably increased, largely attributed to its ability to boost efficiency, minimize mistakes, and free up human resources for more strategic roles. However, the effective incorporation and utilization of domain-specific data still pose considerable challenges. RAG and LLMs provide an efficient solution to these challenges, offering several key benefits:
Real-time data integration
Unlike traditional models that require constant retraining and fine-tuning to incorporate new data, RAG facilitates real-time data integration. As soon as a new document enters the system, it becomes available as a part of the knowledge base, ready to be utilized for future queries.
Reduced costs
The retraining of large models with new data can be computationally expensive, time-consuming and costly. RAG circumvents this issue by indexing and retrieving relevant information from the document store, significantly reducing both computational costs and time.
Enhanced security
In conventional LLMs, sensitive data often has to be included in the training phase to generate accurate responses. In contrast, RAG keeps sensitive data in the document store, never exposed directly to the model, enhancing the security of the data. Additionally, access restrictions to documents can be applied in real-time, ensuring restricted documents aren't available to everyone, something that fine-tuning approaches lack.
Greater explainability
One of the key advantages of RAG is its explainability. Each generated response can be traced back to the source documents from which the information was retrieved, providing transparency and accountability — critical factors in a business context.
Reduction in hallucination
Hallucination, or the generation of plausible but false information, is a common issue with general-purpose and fine-tuned LLMs that have no clear distinction between “general” and “specific” knowledge. RAG significantly reduces the likelihood of hallucination as it relies on the actual documents in the system to generate responses.
Overcoming context size limitations
LLMs usually have a context size limitation, with most allowing around 4000 tokens per request. This limitation makes it challenging to provide a large amount of data. However, RAG circumvents this issue. The retrieval of similar documents ensures only relevant ones are sent, allowing the model to rely on virtually unlimited data.
Ready to harness the power of RAG and LLMs in your organization? Get in touch with us to start the discovery and POC phases now.