
Building a reverse image search engine with convolutional neural networks

Mr and Mrs. Smith are a regular middle-class couple in the process of remodeling and redecorating their home. After a long and tireless search on Pinterest and other lifestyle websites, they finally found a concept for their new interior decoration plans. The only issue was that actually finding and buying these products online was extremely frustrating, due to the limitations of e-commerce product discovery.
Using the text search engine, the Smiths tried to describe the lifestyle products they fell in love with, but could never find the right items in the search results. Filtering the catalog by product category and manually searching was both extremely time consuming, and not successful. After several similar experiences on a few other e-commerce sites, the Smiths gave up and had to consider either browsing a bunch of brick-and-mortar stores or not pursuing their concept at all.
Retailers are becoming more aware of how these negative customer experiences hurt their sales revenue and turn people away from their sites. In particular, retailers are zeroing in on the limitations of text based search. Even if you have a very clear idea of what you’re looking for, it can be difficult to describe some types of products accurately. This is especially true for decor and lifestyle products, as certain features or elements of these products are unique, and can be hard to meaningfully describe in a search bar.
One of our customers that offers decor and lifestyle products was facing this exact problem. They were reporting that many of their stocked items were not being found via text based search. Because of this, they were getting very low conversion rates in their online store. Wanting to boost their sales, our client was interested in enabling their customers to search for products using images, rather than just text.
This idea involves people who want to decorate their house finding design concepts online from sites such as Pinterest, then using the photos they find to automatically match items from a catalog. Our client also wanted to have the ability to recommend products to customers that shared similar features such as color, shape, or pattern to their sample images. This would provide a good method of upselling, and additionally allow the search engine to be more useful by actually finding products that customers were looking for.
Powering the solution with Convolutional Neural Networks
Our solution was to build a reverse search engine that would be powered by a convolutional neural network. In recent years, deep learning has made incredible improvements in the ability to recognize different types of objects by using convolutional neural networks. This extends to being able to recognize objects independently of their position, viewpoint, or background.
A standard approach would involve taking a pre-trained model that could find similar objects using metrics like Euclidean Distance. However, that method would not be effective for this type of project, because the same object rotated to a different angle or against a different background would produce different results. We needed to develop a solution that would be able to recognize similar objects, as well as be able to provide visual recommendations.
The figure below demonstrates how our Reverse Search Engine works. The left panel shows the photo input from which the objects need to be extracted for identification. This is achieved by using a feature vector from ImSeNet, enabling a search to be conducted for similar products from an appropriate category.
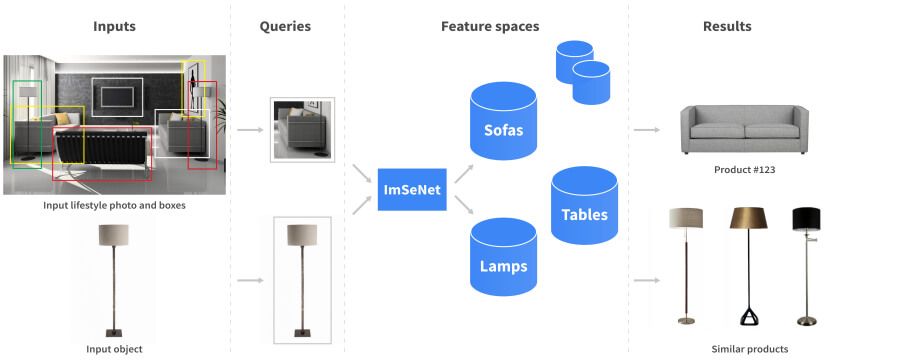
The visual search recommendation system needs to be able to retrieve a similar image from a catalog (usually an object against a white background) based on images of objects in varying environments (such as lifestyle photos) uploaded by the user. This task is highly complex because the query image object can be of a different size, orientation, or shot against different types of backgrounds or in varied lighting conditions. This can be seen with the three different images of chairs in Figure 2 below.

The entire solution is comprised of the following related parts:
- Learning similarity metric
- Network architecture
- Training dataset
- Evaluation metrics
- Results
Establishing the learning similarity metric
There are numerous approaches that can be used to perform a visual similarity search. Some build the feature representation based on different types of descriptors of the images, and use the Compressed Histogram of Gradients (CHoG) or Vector of Locally Aggregated Descriptors (VLAD) methods or complex combinations of patterns and colors. Other types of solutions rely on the ability to automatically learn, in order to produce the features directly end-to-end from the input image.
The learning similarity metric is needed to produce embedding, such that the distance metric between the query image and its original object image is smaller than the same query image and any other original object image in a feature space.
For neural network training, we use a triplet of three images: query, positive and negative images (q, p, n). This is achieved by:
L = Σ Lp (q, p) + ΣLn(q,n)
The triplet loss function consists of two penalties - Lp penalizes a positive pair if the distance metric is too big, and Ln penalizes a negative pair if the distance metric is less than the margin.
There are a few variants of the final triplet loss function, which are described in detail in several recent papers:
- Learning Visual Similarity for Product Design with Convolutional Neural Networks
- Deep Learning Based Large Scale Visual Recommendation and Search for E-Commerce
- Improved Deep Metric Learning with Multi-class N-pair Loss Objective
In our work, we use the variant:
L = 1/n Σ max(0, m + Dp - Dn)
Where Dp is the Euclidean Distance between q and p, and Dn is the Euclidean Distance between q and n.
This formula works when Dp is too small and Dn is higher than m, in which case Dp - Dn < 0 is negative, and the final loss will be 0. This results in a beneficial learning process for the network. In other cases, if the loss is not 0, we need to minimize it. This involves minimizing Dp and maximizing Dn, which makes our network learn the similarity between images. The margin parameter (m) for fine tuning training can take different values, but takes vector normalization into consideration, which affects that hyperparameter.
Making the margin can produce problems of instability or divergence. If the margin is too small, it can make learning too slow, or collapse for all products. We chose m = 1 because it makes the feature space more stable. One option is to use the loss function, which is also called a contrastive or hinge loss, as it has a different role, as detailed here:

Neural network architecture
The most efficient way to compute and minimize contrastive loss is to use a Siamese Neural Network. Siamese Neural Network architecture contains two or more identical networks with shared parameters and weights. Subnetworks are used to process multiple inputs, then their output is combined using a different module. This network is used for direct training of the problem we are trying to solve, but it cannot be used to resolve all problems, as we can only train it to determine the similarity of the three images.
Under the hood, our Siamese Neural Network uses a Convolution Neural Network (CNN). If you are not familiar with CNNs, you can refer to this link. CNNs are used to process images, and consist of three layers: convolution, pooling, and rectifications. CNNs in recent years have become very good at tasks such as object classification and detection.
In our work, we experimented with a lot of different architecture types. These architecture types can be separated in two ways. One is the original existing CNN architecture type (let’s call it a pre-trained CNN), which uses pre-trained weights on Imagenet, while the second is an assembly of small pre-trained CNNs.
There are currently many different CNN architectures. We had some restrictions on which ones were viable, as we wanted to use a pre-trained model. We ultimately decided on the use of Keras, as it has some pre-trained CNN architectures that are compatible with Tensorflow.
| Model | size | Top-1 accuracy | Top-5 accuracy | parameters | depth |
| Xeception | 88 MB | 0.79 | 0.945 | 22910480 | 126 |
| VGG16 | 528 MB | 0.715 | 0.901 | 138357544 | 23 |
| VGG19 | 549 MB | 0.727 | 0.91 | 143667240 | 26 |
| ResNet50 | 99 MB | 0.759 | 0.929 | 25636712 | 168 |
| InceptionV3 | 92 MB | 0.788 | 0.944 | 23851784 | 159 |
| InceptionResNetV2 | 215 MB | 0.804 | 0.953 | 55873736 | 572 |
We chose Xception, InceptionV3, and InceptionResNetV2 for comparison purposes, and used them without a top layer, i.e. the last layer would be a dense layer. We then introduced a shallow layer to be able to extract low-level details from the image.
A CNN can be thought of as a features identifier, with each new layer being trained to determine more high-level features. Using an image of a ship as an example, the first layer is only able to detect curves or some lines, while the next layer is able to detect a combination of curves. As you go deeper, CNN is able to recognize the mast, the ship’s sails, and finally the whole ship.
It was our assumption that this parallel combination of low and high-level features would produce superior results. We also experimented with a large number of different parameters, such as regularization, activation functions, batch normalization, etc. Later, we will describe how it is possible to evaluate the accuracy of the network.
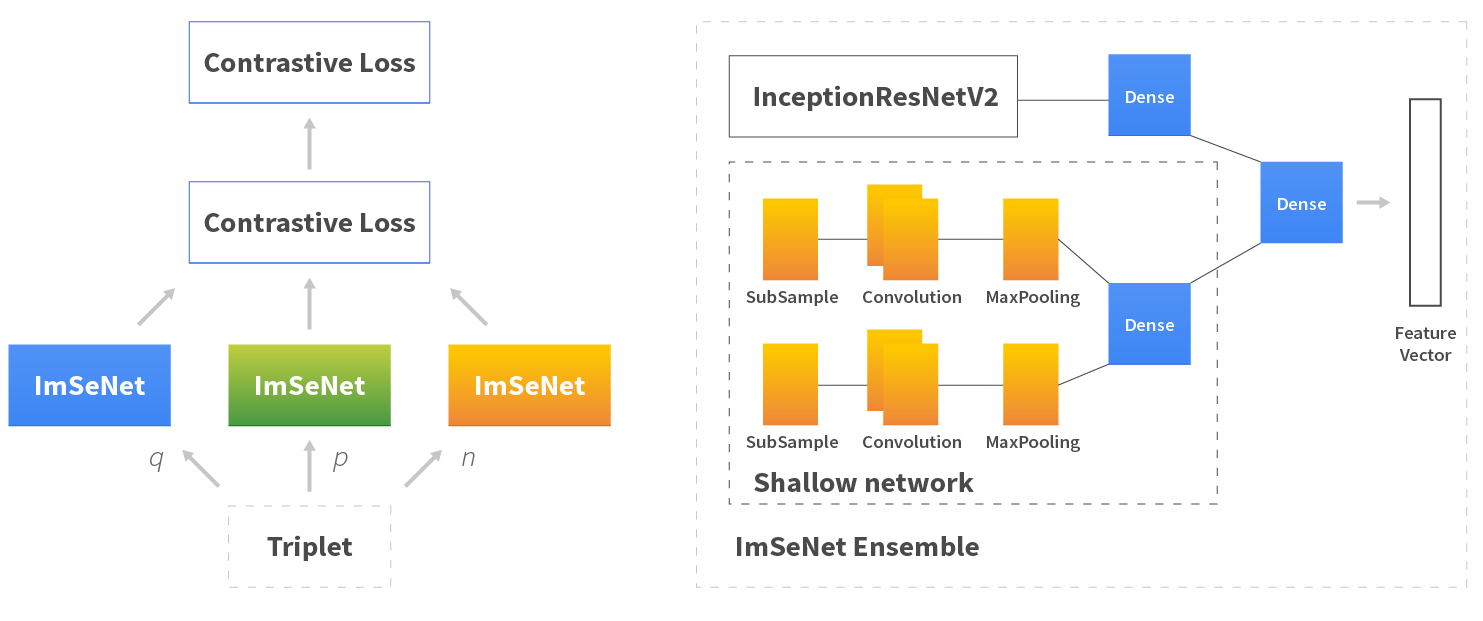
The final important question is: do we need to freeze the pre-trained CNN and re-train only the last layer, the last N layers, or the whole network? To answer this, we needed to choose the correct dimension space. We tried multiple dimensions - {256, 512, 1536, 2048}. We also needed to avoid the classical problem, The Curse of Dimensionality, in order to not lose any unique features of the product that would be necessary to distinguish it.
Creating a training dataset
Training the network requires query, positive, and negative images. A query image is an image of a product within a random scene that we refer to as a lifestyle image. A product image is an image of that product against a white background with no other objects in the scene. The negative image is a product image of any other product within the same product category.
There are several different types of negative images. This includes in-class negative images, which teach the network to pay attention to low-level nuanced differences, like material or texture. Another type is out-of-class negative images, which train the network to pay attention to shapes and colors.
When working with an existing retail customer, you already have access to the structured data that can help you collect the training dataset. Otherwise, it can be difficult to collect positive pairs and hard, negative examples.
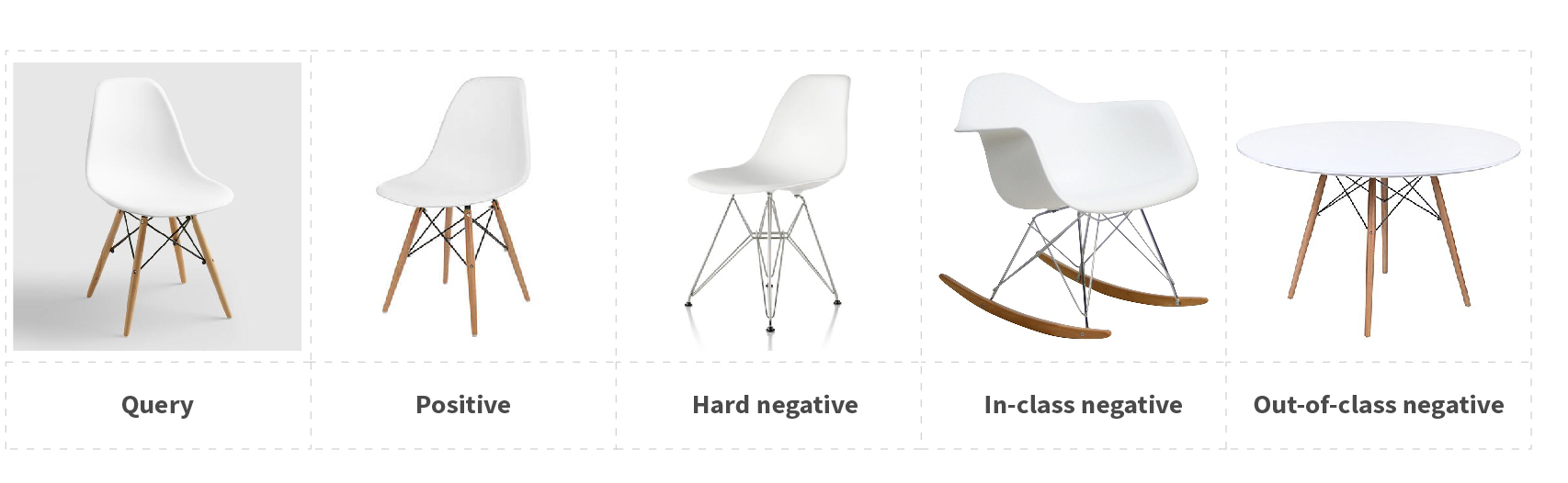
In some instances, we have access to several images of a single product. If we're lucky, at least one of the images will be a lifestyle image with a non-white background. In that case, it is possible to use it as a positive pair and collect the triplet in that way: <q - product #123 lifestyle image, p - product #123 white background image, n - product # != 123 white background image >.
Another problem involves how unsuitable images can be filtered out, such as where only a small part of the product is visible in the image, i.e. a single chair leg. To address this, we used object detection. This is because when you are processing a product’s images, you know its category or label. If object detection finds an object with an appropriate label, it means the image contains the desired product. Object detection helps the search to only recognize the target object from an image that may contain several different objects, as shown in Figure 1.
Images without a white background are marked as lifestyle images and used as a query in a triplet. For that, we build a histogram of the pixel’s color for each image. For each positive pair, we use 10 to 15 in-class negative images and 1 to 3 out-of-class negative images. Some negative images are not truly hard negative examples as we can choose random products from the same category.
The process can then be further improved after the network has been initially trained by re-using images to build hard negative examples. For each positive pair, 100 to 1000 similar products can be selected using the trained network. Random augmentation of the query can then be used to extend the training dataset by performing actions such as image flipping, rotation, blurring, cropping, adding noise, or randomizing pixels.
Evaluation metrics
We also developed a series of metrics to help evaluate the results and accuracy of the network training process. The first we named absolute_accuracy. This metric shows how many Dp < Dn that we are trying to minimize. However, this metric can only calculate the accuracy of each triplet whereas we want to be able to find exactly the right product among thousands of others.
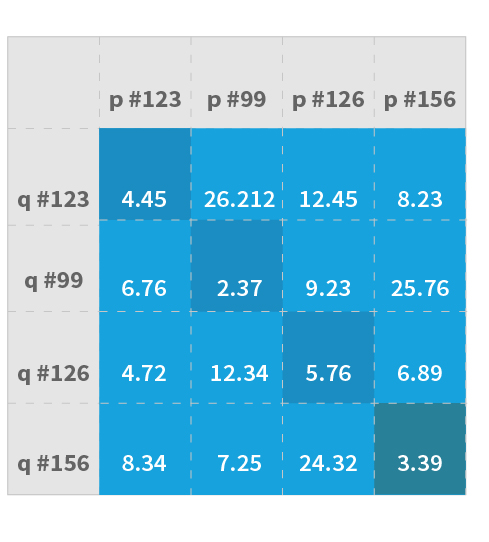
The next metrics developed were distance_accuracy and distance_accuracy_top_3 (Figure 7). Here, we take N products of the same category and build a distance matrix q × p. A diagonal element is a q and p image of the product. The model processes each image and vectorizes it. From that vectorization, two values are created, P and Q, so images that have similar P and Q values will also look similar. Metrics that indicate good results show that images that have been determined to be similar will have numerically small differences between the P and Q values.
This type of metric gives a more realistic result for the actual accuracy of our model because the real challenge is to find an exact or very similar product to the query image among many other products from the same category. Each row of the distance matrix consists of the distances between the query image and other validation images from the same category where the diagonal element is the exact product for that query image. We then calculate it for n objects to determine the level of accuracy.
Finally, we selected two original candidates: InceptionResNetV2 and ImSeNet (Figure 5). We couldn’t rely only on evaluation metrics, which is why we also used images not from the customer catalog and checked the results manually to further assess the quality of the models.
Results
Our final decision was to use just the triplet network with pure InceptionResNetV2. We discovered that the neural network effectively learned to overcome the challenges posed by different backgrounds and lighting levels. And even for rotated objects or partially obscured objects, the network performed well. We achieved a great result using state-of-the-art algorithms.
One of the unresolved problems was the ability to say definitively that if the distance between the P and Q values was larger than a set value, then the two products were not considered to be similar. This is a difficult problem to solve because sometimes we need to use an image containing objects that we don’t have any similarities for but still want to try and find the closest match.

Future improvements
The following investigations could be undertaken to further improve the accuracy of the search results:
- Use 3D object models to produce a much bigger training dataset.
- The neural network could be trained to ignore different backgrounds for the same product. The way to achieve this is to use object segmentation, where a mask is applied and the object extracted from the background. The risk however with using object segmentation is that there is a high risk when using it of corrupting the product image itself, such as cutting off some parts of the object.
Conclusion
Just like our customer, many other retailers are also finding that their text based search engines are not sufficient for accurate product searches and are looking to image search and more capable recommendation engines for improved product discoverability. Additionally, the advance of mobile technologies has led to new use-cases like customers being able to take pictures of products that they want to buy with their smartphones and being able to search with the image. This is a development that retailers are keen to capitalize on.
Companies face the challenge of finding a suitable image search model, training it, then applying it to other mobile applications or integrating it with third-party services. These services include the ability to search for products within a category, search across different categories, search for further uses of a product, and search for similar products from other retailers.
Our solution of using catalog data, a special training pipeline, and training Siamese CNN to produce embedding of product images for different categories could also be applied effectively for other companies. This is especially true for use cases where it would be beneficial to have a model that can be used for categories or products that were not a part of the training of the model.
In this project, we experimented with a large number of different architectures and parameters. We don’t claim to have found the absolutely most optimized system because this task would require a huge amount of computational resources. The system could be further improved by using a larger training set, which would allow for continued advances in optimization. Overall, as image search becomes more and more common, companies will need to adopt reverse search engines similar to the one we developed or risk being left behind.
Vladislav Isaev