
Semantic query parsing blueprint




These days, when machine learning-based result ranking becomes a de-facto standard for e-commerce search implementations, it still relies on the high quality of the matching. No matter how sophisticated your ML ranking algorithm is, if relevant products are not retrieved from the search index, it will not be able to surface them to the first page. Similarly, if irrelevant products are retrieved, ML ranking can bury them to the last pages of the results, yet they still impact the quality of the facets and will surface when results are sorted by price or newness.
In the blog post "Boosting product discovery with the semantic search" we explored some approaches to achieve high-quality matches. In this blog post, we will describe a practical blueprint of building a concept-oriented query parser based on open source search engines, such as Solr or Elasticsearch.
Query parsing
Mainstream modern search engines are essentially "token machines" and are based on the boolean retrieval paradigm. Boolean search engines model documents as a collection of fields that contain terms.
Before a search query can be executed by a search engine, it has to be converted into a combination of elementary queries which are requesting search engine to match a particular term in a particular field. For example, the query "gucci dress" has to be converted into something like
Brand:"gucci" AND Type:"dress" OR Title:"gucci dress"
This process is called "query parsing" and often search engines are supplied with a bunch of alternative query parsers, designed to deal with large full-text documents like articles or webpages.

However, standard query parsers fall short when it comes to e-commerce.
Matching queries to product data
The e-commerce search system has to deal with semi-structured product data, where product data contains both structured attributes and free text titles and descriptions:
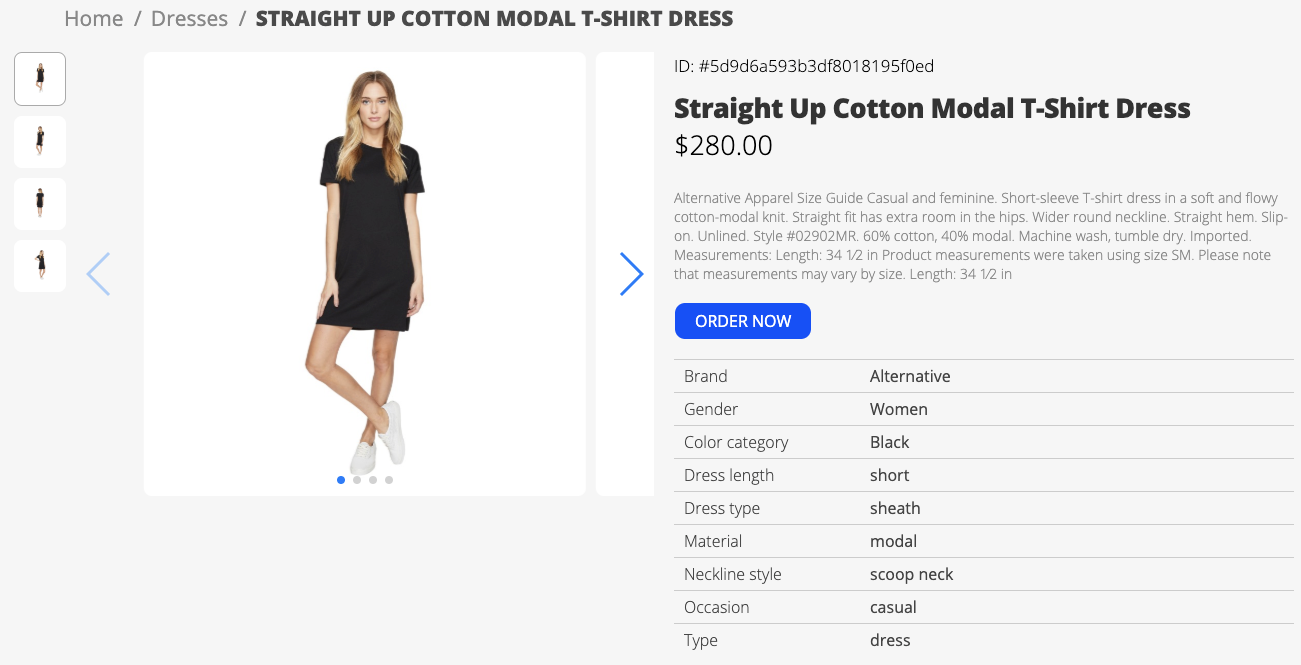
If we look at the most popular customer queries, they usually can be easily mapped to combinations of product attributes:

For such queries, which typically dominate the search query logs, product relevance largely depends on the way how the query can be interpreted and matched to the product data. Let's consider a few examples:
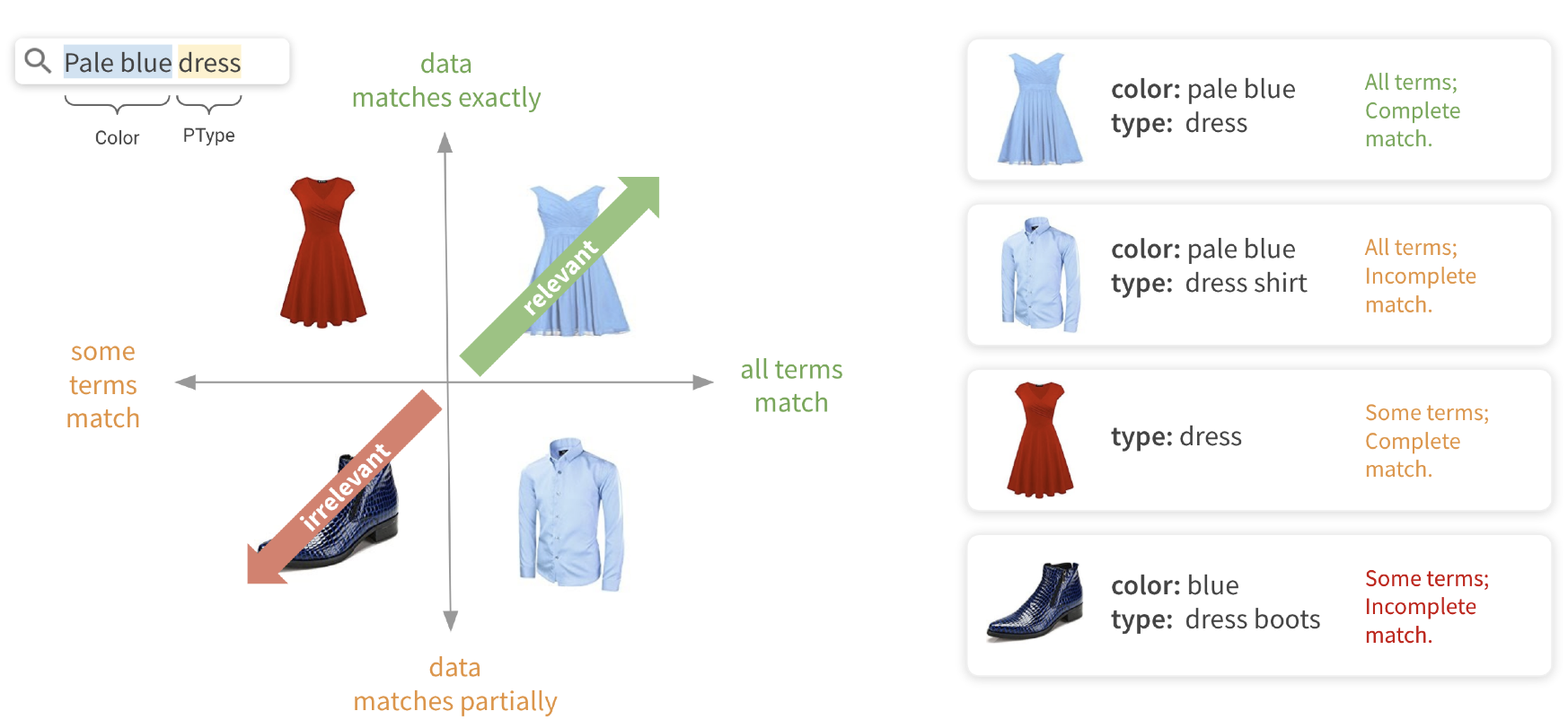
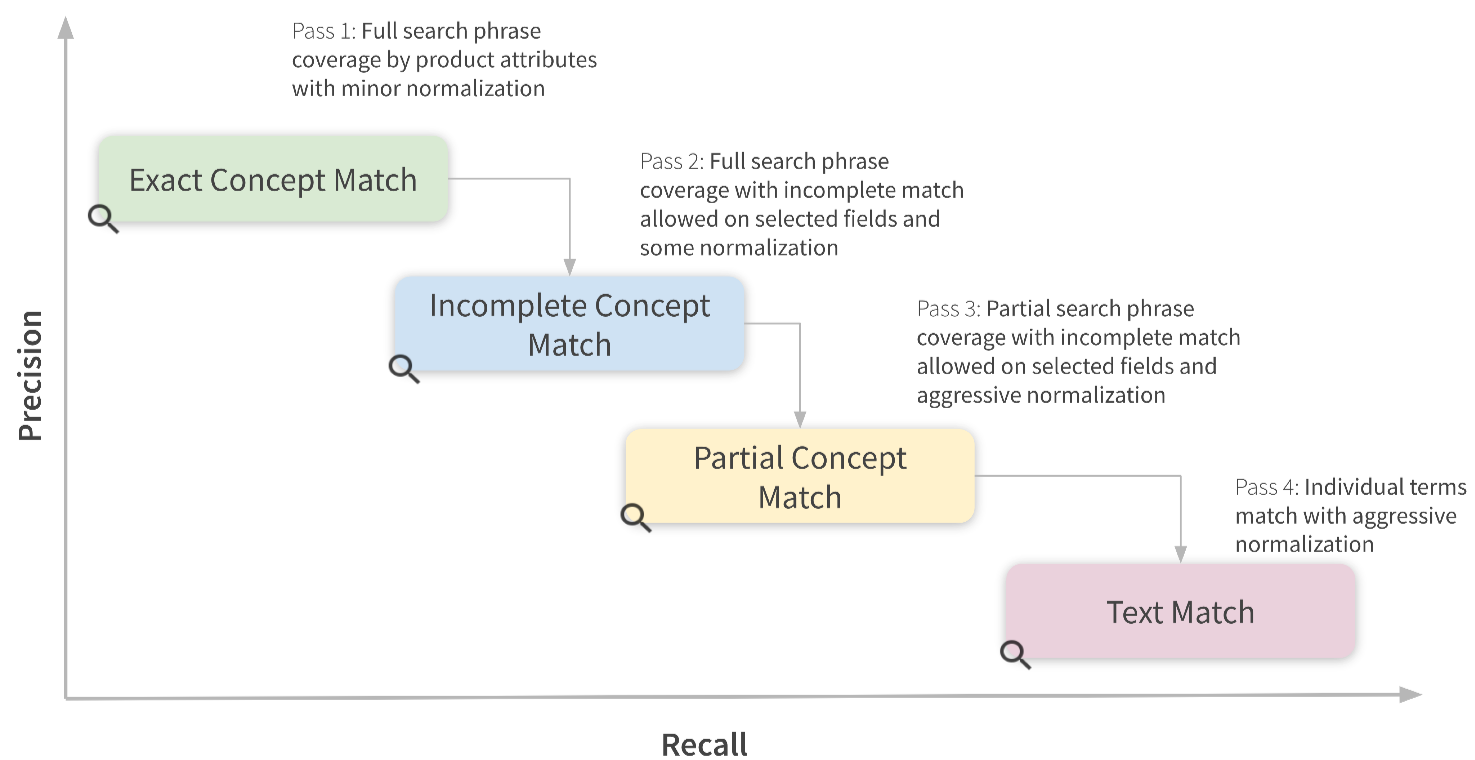
The ideal scenario is represented by the top right corner of the diagram, where all terms from the query successfully and exactly match the corresponding attributes within data. This exact match scenario typically indicates the highest quality match and generally leads to relevant results.
However, in many scenarios query terms match incompletely, meaning that only a part of the corresponding field matches. This indicates a weaker match and the corresponding product should be penalized in the ranking of the result set. Still, if all query terms were matched, such products may still be highly relevant
Another possible scenario is the best partial match, which represents the situation when not all query concepts were matched in the data, but those that did were matched exactly. Even though we couldn’t capture all intents of the user, if we got key attributes such as product type correctly, we are likely to find the relevant results.
The last scenario is the partial match — a situation when we could only match parts of the query terms in the data through a pure textual match. Unless we have strong collocated matches in the important fields like title, it is very unlikely to produce high-quality results.
Match things, not strings
All the scenarios described above can be easily handled by a concept-oriented search. By concept, we understand a semantically atomic sub-phrase, which loses its meaning if further split into terms. For example, the concept “santa claus” loses its meaning when divided into “santa” and “claus”. Concepts are also field-specific, e.g. they may mean different things in a different context. For example, the sub-phrase “house of cards” has a different meaning in the phrase “a boy building a house of cards” and “The house of cards poster”.
The concept-oriented search mission is to be able to recognize and respect “concepts” in queries and data. To identify and tag concepts, we can leverage two main data sources: catalog data and domain-specific knowledge base. Many concepts are implicitly available in the product data and can be automatically extracted from it.
The knowledge base contains explicit concepts which are connected into graph structure and maintained manually or semi-automatically.
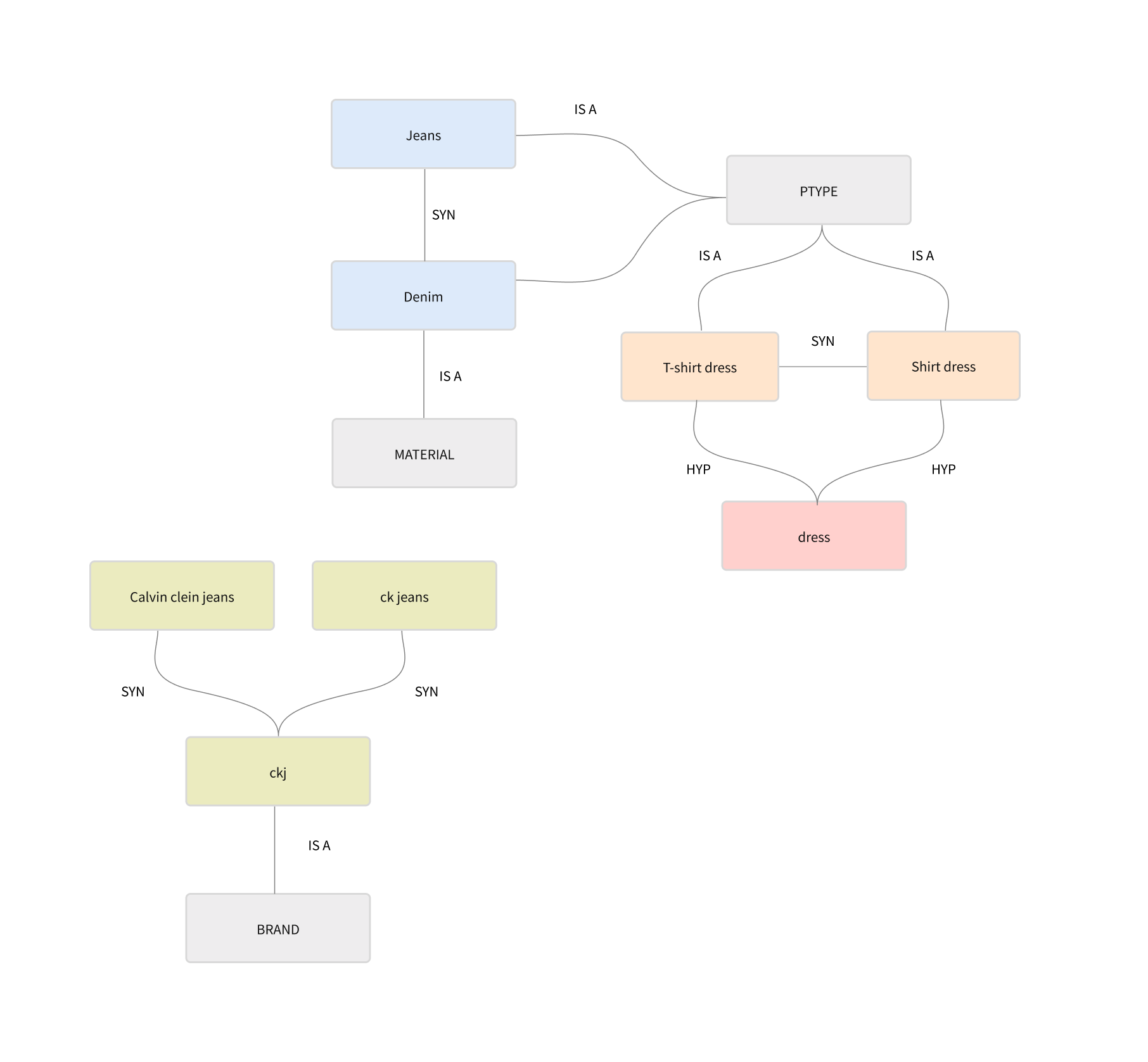
Both data sources can be converted into the concept index and used to recognize concepts at both query and index time.
The concept-oriented query parser should support a flexible configuration which allows us to select what attributes will be searched, what normalizations can be applied to achieve the match, and what types of matches are allowed. This allows a tightly controlled balance between precision and recall in the search results.
Such flexible precision control allows us to organize a multi-stage search, where we can start the search flow with strictest match conditions and gradually relax them in subsequent index sweeps until the best quality results are found.
Concept-oriented query parser
Our goal is to create a query parser well-suited for online commerce needs, capable of dealing with semistructured data common for e-commerce products. We will deal with data tokenization, normalization, spelling correction, concept tagging, query expansion, and many other steps to achieve high-quality query interpretation which will help the search engine to retrieve the most relevant results.
To implement all this step cleanly, efficiently, and transparently, we need to have a good abstraction to represent and visualize intermediate steps of data processing. We will use a semantic graph as such an abstraction.
A semantic graph is a graph where each node represents a position within a token stream and edges represent metadata about the corresponding token stream span.

The semantic query graph above describes multiple alternative interpretations of the query "the tall blablabla navy shirt dress". Each interpretation is represented as a different path in the graph.
The main information about the query interpretation is carried around by the graph edges, which can have different types to represent variety of metadata. In this particular example we have the following types of edges:
- Unrecognized (marked by red edge) – an unknown term
- Concept (marked by © – a recognized term from the indexed documents or the knowledge base, exact match in a field
- Shingle - a recognized collocation of terms, incomplete match in the field.
- Text - recognized individual tokens inside a particular field
- SW - the term is recognized as a stopword
Please note that “shirt” + “dress” has a parallel edge “shirt dress” and is an example of an ambiguous query, allowing alternative interpretations that can be evaluated through a disjunction.
We will process the query using a pipeline of steps. Each step will be responsible for an individual task. Every stage will accept a semantic graph as an input, modify it by adding or removing nodes and edges, and then pass the resulting graph to a subsequent step in a pipeline.
Why is graph abstraction so useful for our query analysis tasks? Here are some of the reasons:
- Graph representation naturally supports many alternative interpretations of the same token or token span
- Graph edges can carry arbitrary metadata related to tokens and token spans as graph edges
- Graph representation decouples processing steps in a pipeline
- The graph can be easily visualized for debugging and explanation purposes
- ... Graphs are just cool!
Query analysis with the semantic graph
Let’s consider an example of the analysis of the following query
m geen crew neck shirt under $20
Tokenization
On the initial step, the graph has only one edge which represents a full search phrase. At this stage, we will perform the initial query analysis, such as ASCII folding and tokenization. Each token can represent a word, a number, and size. In many cases, it is a good idea to have domain-specific tokenizers which are aware of units, dimensions, monetary values, and sizes

Spelling correction
Spelling correction helps to deal with tokens that do not exist in the catalog or the knowledge base and try to correct them to something search system and understand. There are many approaches to implement spelling correction, from the basic edit distance search to the advanced ML-based language models.
Spelling correction produces an alternative interpretation of the search terms, which we can conveniently visualize using query graph:
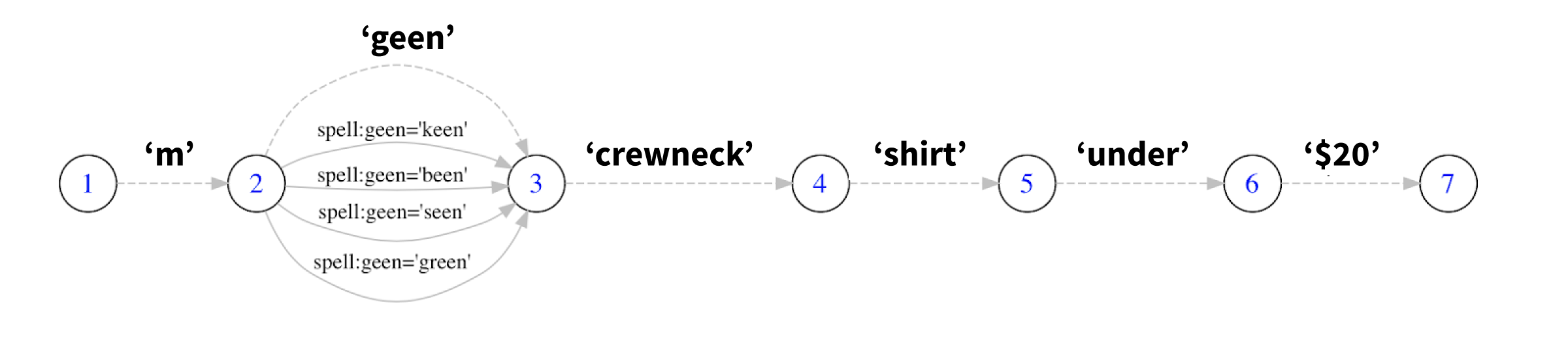
As you can see, one of the spelling hypothesis is to correct "geen" to "green".
Compounds
There are many concepts that allow different possible spellings which are space-separated, hyphenated, or glued in a single word. The compound word step takes care of normalizing compound words into their canonical concept. Results are added as alternative token span interpretation spanning several tokens.

crewneck recognized as crewneck and crew neck
Linguistics
Our knowledge base allows us to perform query expansion, e.g. enrich the query with alternative interpretations of query terms based on synonyms, hypernyms, and other types of domain-specific data. In our case, we can expand the term "green" with its hyponym, "olive".
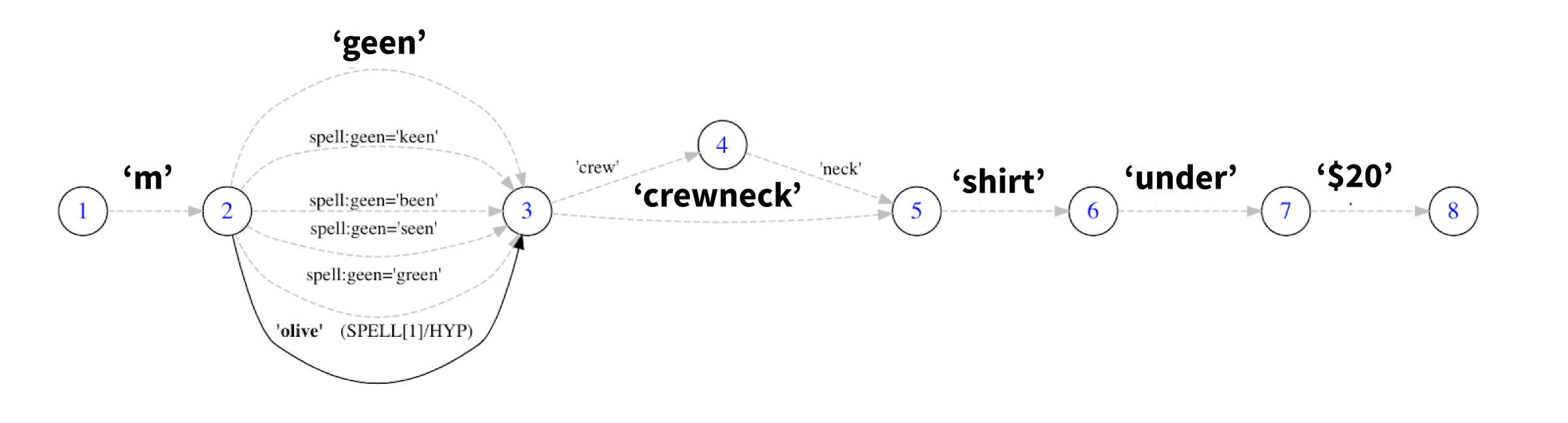
Concept tagging
Concept tagging is the main step in the concept-oriented query parsing pipeline. Here we take all the possible token spans and, using the concept index, trying to match them to recognized concepts from the catalog or the knowledge base. Results will be naturally ambiguous as the same term or set of terms can be found in many different fields with a different confidence. Our query graph representation allows us to conveniently store and visualize all this information.
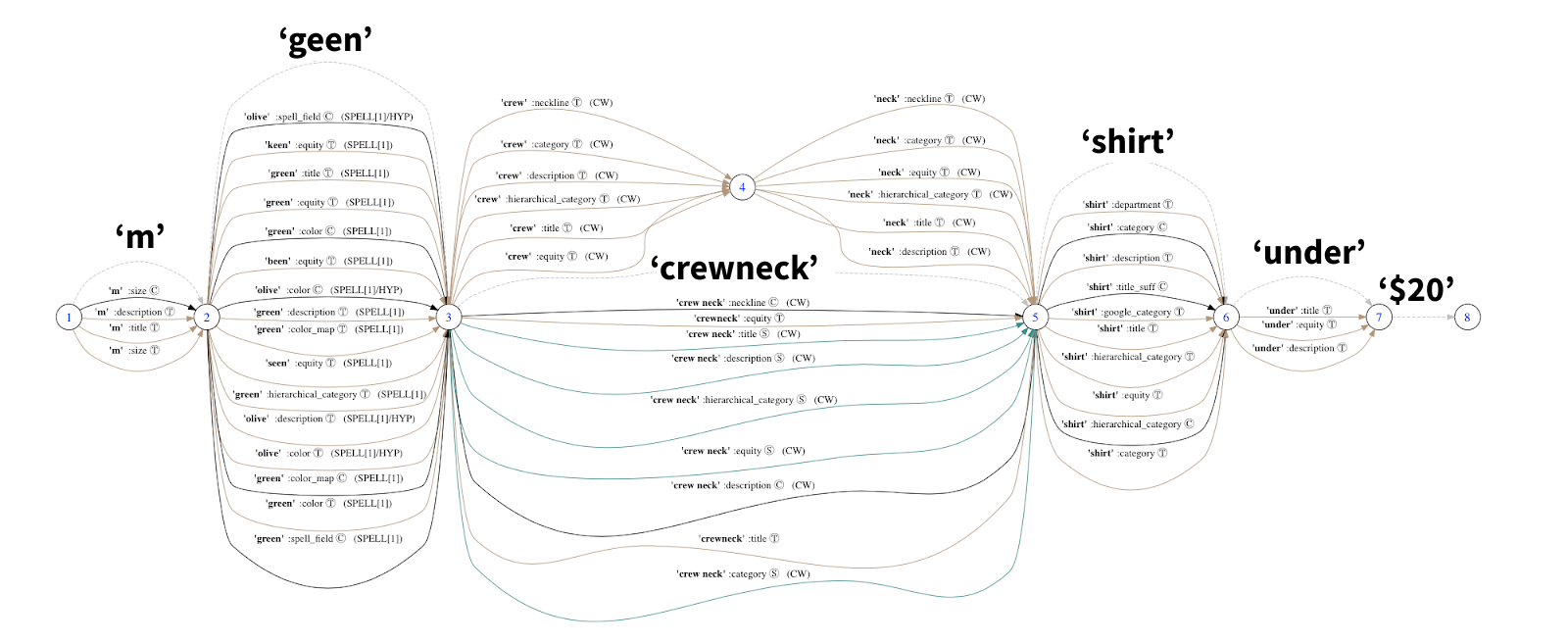
Ambiguity resolution
A search phrase can contain a token span which can be interpreted in several different ways. This ambiguity can come from several sources
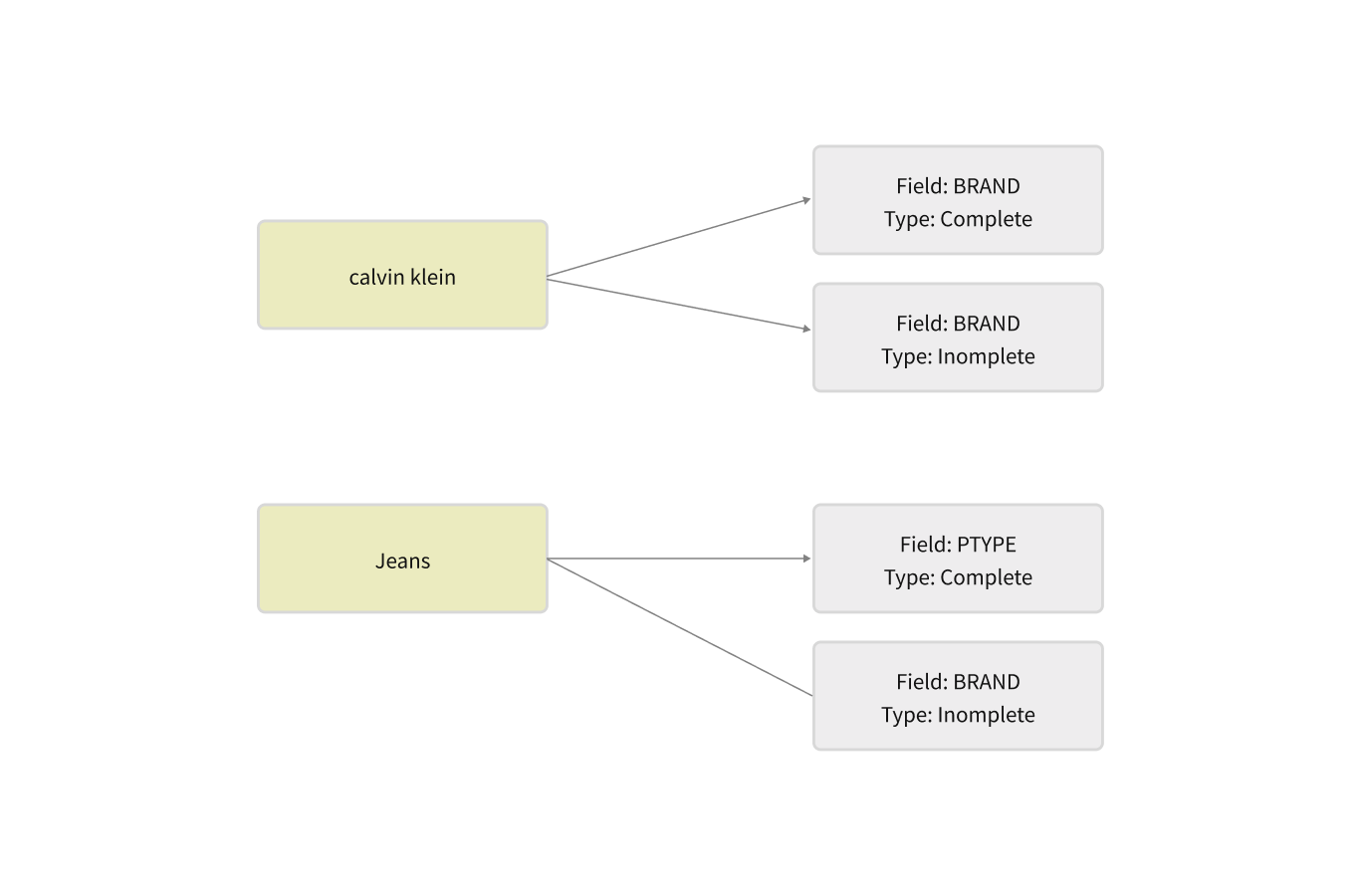
- genuine ambiguity. In some cases, there are exist alternative interpretations of the query. For example, the query "calvin klein jeans" can be interpreted both as search for "jeans" by brand "calvin klein" or search for "calvin klein jeans" brand.
- alternative interpretations. Many terms, like in the query "long sleeve dress", can accidentally match in a different fields with different quality of the match. The term "dress" can match in multiple ways. It can be a product type, a style, as in "dress shoes", or a part of the product name and description.
The ambiguity resolution step is filtering the query graph and removing interpretations which are likely to be the accidental concept or token matches. It uses information about field importance to properly rank alternative interpretations and cut off those edges which correspond to weaker matches. For example, if a token stream can be represented as a single multi-token concept, we can remove an individual token matches from the graph.
Comprehension
Comprehension is a part of the phrase which should not be directly matched on attributes in the index. Typically, there is several common phrases customers use to refine their intent. Examples would be "jeans under $50", "new summer dresses", "best selling watches". Those phrases should not be matched to the index directly. They have to be detected and converted to an appropriate filter or boosting factor. Graph abstraction provides a convenient way of detecting such comprehensions:
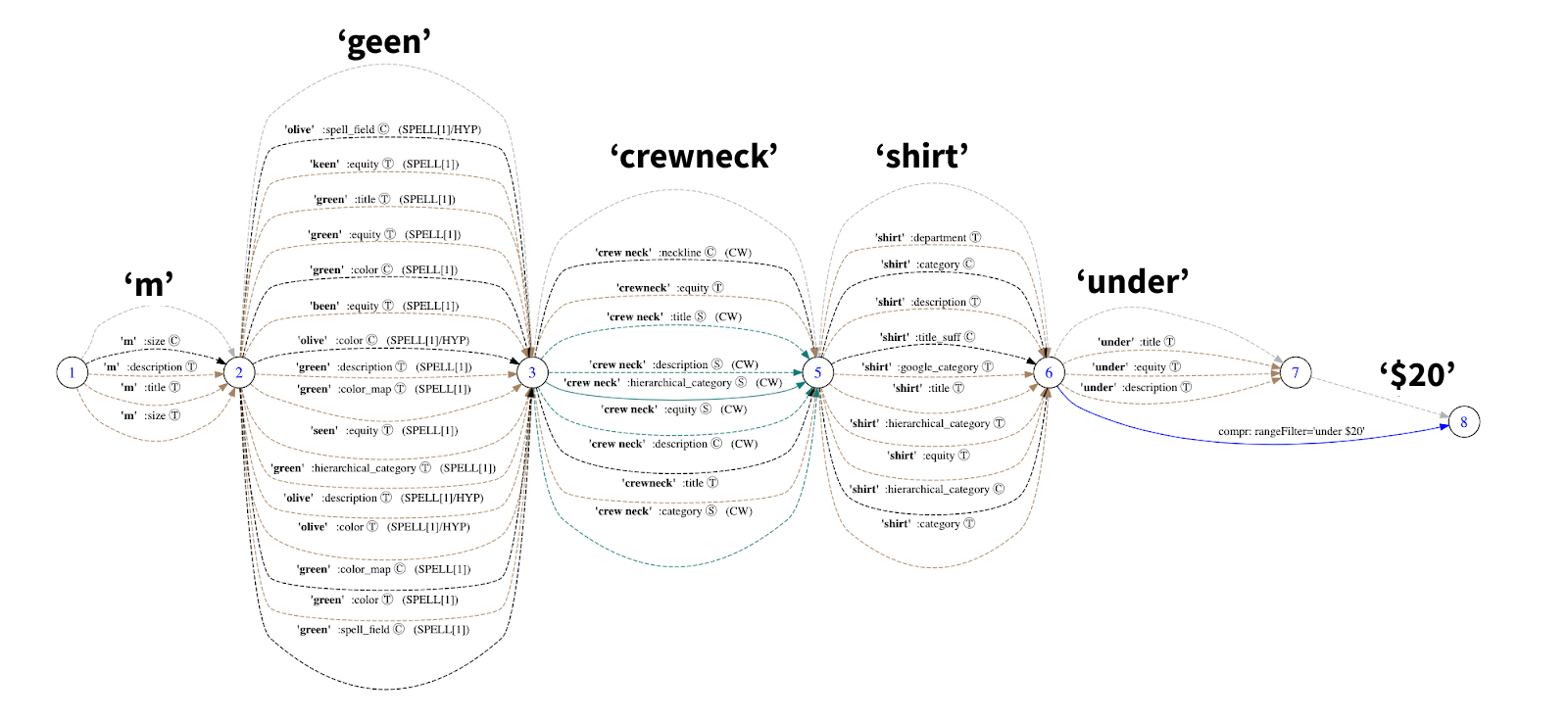
Concept grouping
At this stage, we group concepts and tokens which provide alternative terms for the same field. This way, it is more convenient to create a boolean query for the search engine.
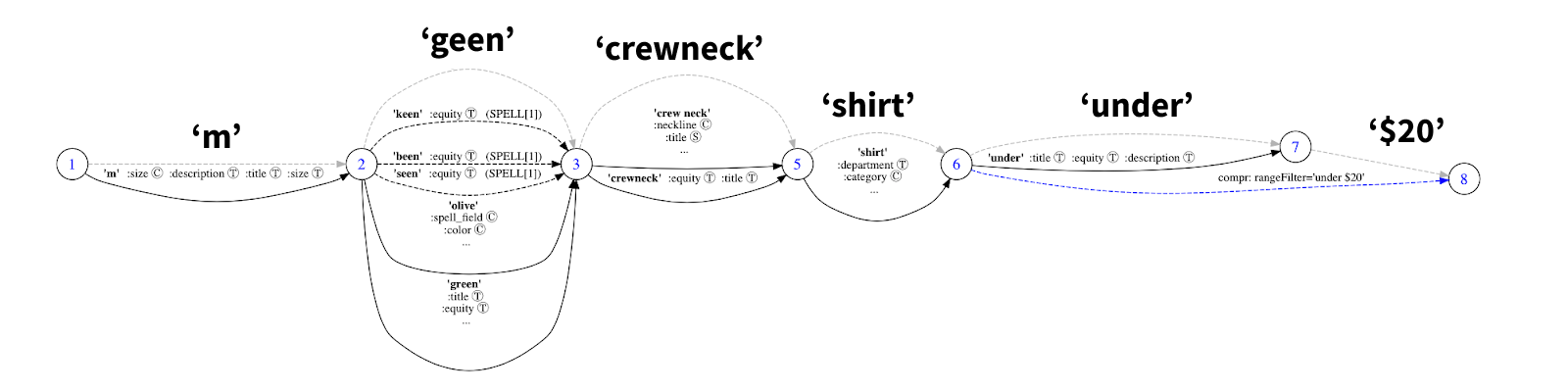
Finally, our interpretation graph is ready to be converted into a boolean query that the search engine can execute.
Integration
Despite a large variety of search ecosystems implemented in the industry, they typically have the following key elements:
- Font-end applications that are responsible for user experiences across channels and devices
- Search API that is responsible for handling keyword search and category browse requests. This API can be a monolith service or a facade in front of a group of micro-services. It is responsible for query parsing, business rules evaluation, formulating the query to the search engine and post-processing, enriching, and converting the search engine results.
- The data pipeline is responsible for full and incremental indexing of the catalog data in the search engine.
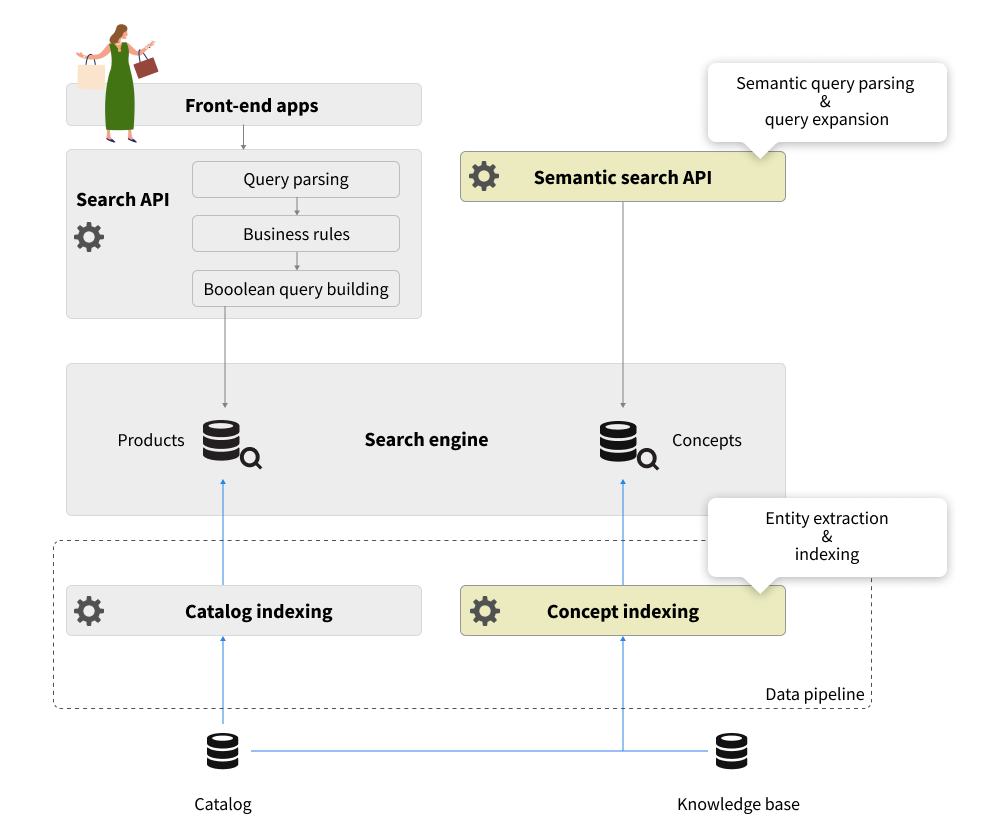
Integration of semantic query parsing requires two components added to the search ecosystem:
- Concept indexing job is a part of the data pipeline which is using the catalog data and the knowledge base as primary data sources to extract and index concepts and collocations/shingles in the concept index.
- Semantic Search API is responsible for query understanding, e.g. converting the query into the semantic query graph representation, and following all the processing steps described above.
Internally, Semantic Search API can use the query analysis capabilities of the search engine to assist in particular query analysis steps.
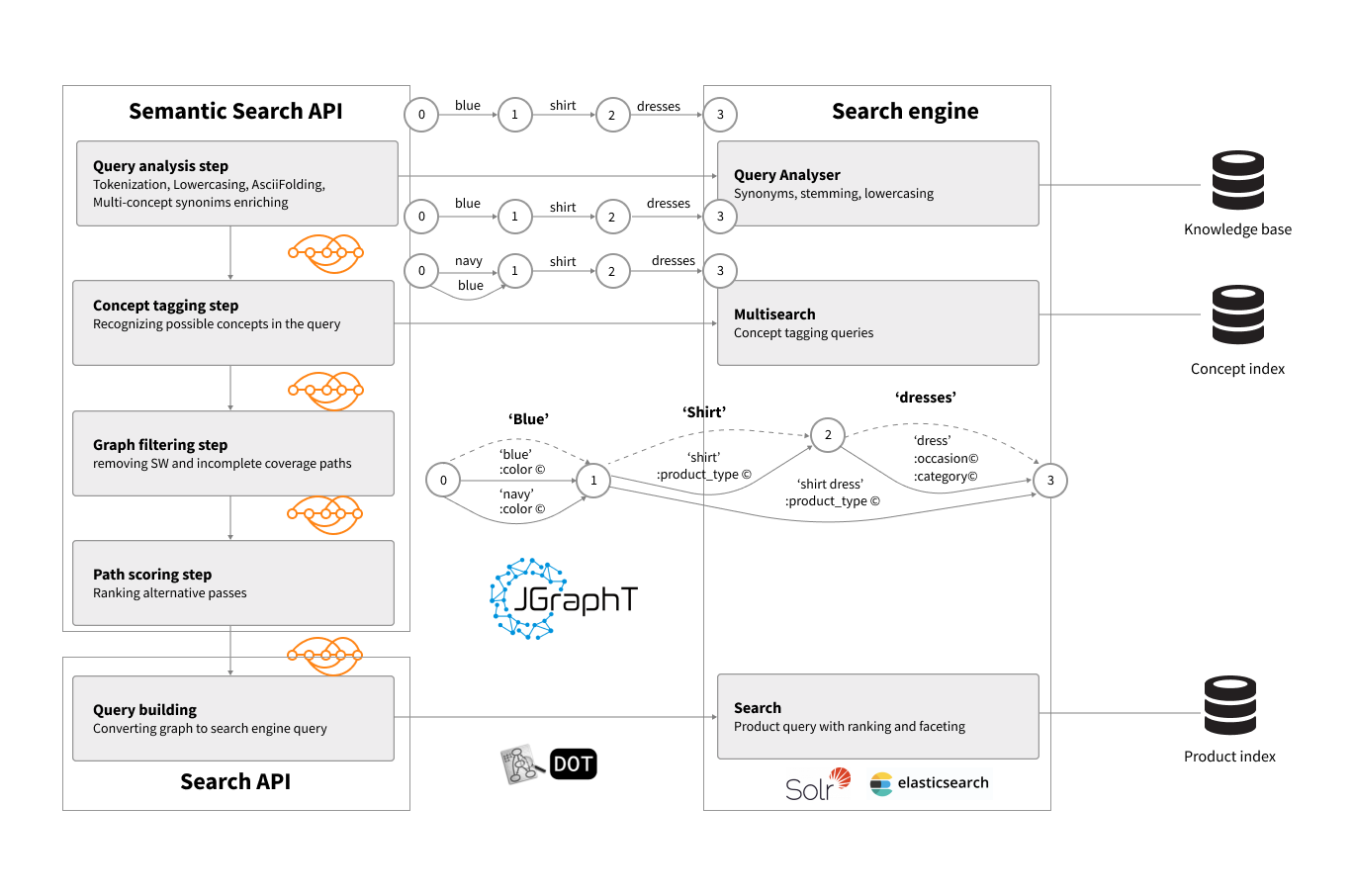
In this example, query analysis chains that can be configured in the Solr or Elasticsearch help with the initial steps of query analysis, and the concept index is queried using multi-search functionality to perform the concept tagging.
The resulting query graph can be transferred back to the Search API and converted into the actual boolean search query which will be executed against the product index. The search API query processing pipeline should take care of organizing multi-stage search, as well as other processing steps such as the execution of business rules, search results enrichment, and re-ranking using learn-to-rank models.
Conclusion
In this blog post, we described the essential technique of semantic query parsing. This technique can be integrated straightforwardly into an existing open source-based search ecosystem and produces strong practical results when dealing with the most popular "head" and "torso" e-commerce queries. In provides a strong foundation for matching relevant results which enables the collection of high-quality clickstream data for ML-based ranking models.
Happy searching!