
Tiered machine learned ranking improves relevance for the retail search

Online retailers operating large catalogs are always looking to improve the quality of their product discovery functionality. Keyword search and category browse experience powered by their search engine is a first stage of sales funnel where fast and relevant search results can produce delightful and seamless shopping experience leading to higher conversion rates.
Traditional search engines rely on matching words in the queries to words in the products, and making ranking decisions based on frequency of the matches. Search relevance engineers spend a lot of time tuning ranking formulae to carefully balance the value of words matching in different attributes, making decisions like “match in brand field is twice as important than match in category field” or “partial match in product name is 5 times less important than full match”. They also take into account business signals, such as price, margins, sales, inventory, etc...
Even when ranking formulae is well-tuned, in many search sessions customers are using broad words, such as “jeans” or “shirt” or “Ralph Lauren” which match many products equally well. There is simply not enough information about shopping intent in the query to make a good ranking decision. At the same time, customer behavior data on the site provides a trove of information on what products customers are really interacting with when searching for particular phrases.
Using machine learning, we can use this information to automatically devise optimal ranking formulae which will also self-learn and adapt to changes in customer behavior. This approach, known as learning-to-rank (aka LTR), is a de-facto standard ranking feature in modern retail search systems. However, because of high computational complexity of ML models, it can only be applied to dozens or hundreds of top search results, limiting its potential.
In this blog post, we will describe a tiered learning-to-rank approach which allows us to work around this limitation.
First, lets review how learning-to-rank is implemented in popular open source engines (Solr and Elasticsearch)
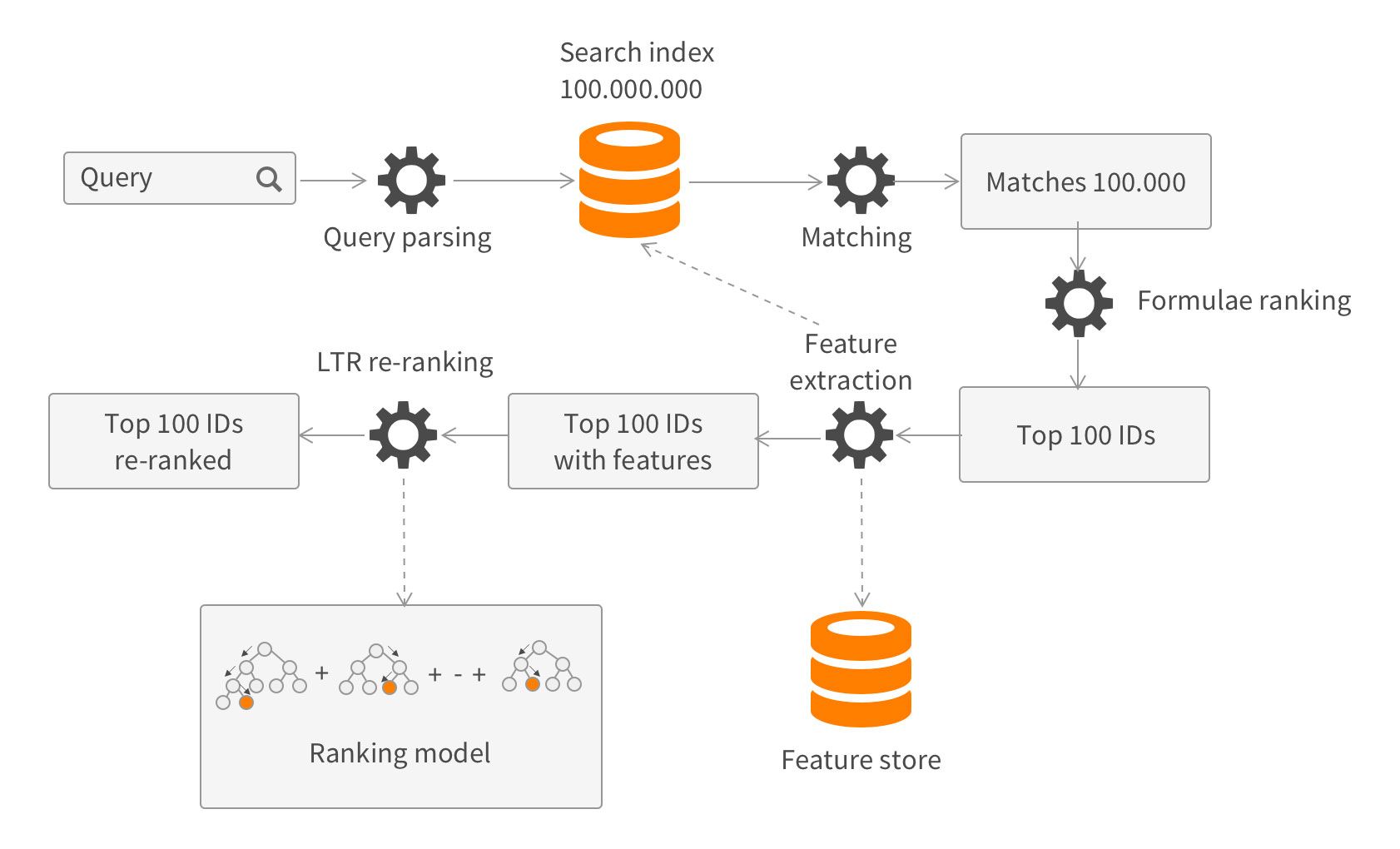
Search query is sweeping through the search index, producing candidate matches. Every match is scored according to ranking formulae and collected into priority queue to find the top best matches. Without learning-to-rank, those top matches are returned to the customer. With learning-to-rank, collected top matches are re-scored according to the ranking model. Ranking model require features, which are data points fueling decisions made by the model. Features can be as simple as a value of particular product attribute or as complex as a result of search subquery which has to be separately executed. Ranking model takes into account all those features to re-score the top N products which are returned to the customer.
As you can see, from a performance standpoint the feature extraction and ranking phases can be quite intensive and their complexity directly depends on how many products they have to examine and rank. This is fine to dozens and hundreds, but not for thousands or millions. This is why you can’t run full LTR model against all matching products - feature extraction and ranking will be way too slow.
In some search systems, re-ranking is happening not inside search engine, but in a dedicated microservice or even a third party system. Still, this doesn’t change the fact that only the top few dozen results get re-sorted by the machine learning algorithm. It also adds serialization and wiring overhead to the system.
What if we are looking to run LTR ranking against all the products which are matching the query? Our goal is to surface products which are relevant from LTR perspective but can be missed by convenient ranking formulae. We still can do it, yet for performance reasons, the model should be pretty simple, so it can be used to quickly score every matching product.
This way, we will have a two-tier ranking system. Our first tier of ranking will quickly evaluate every matching product with a simple model and find top N best matches, while the more sophisticated second tier model will take its time to exhaustively re-rank those matches to promote most relevant results.
Let's review a practical case study of application of this technique to online commerce search.
If we look at learn-to-rank as a machine learning problem, we are trying to predict a correct ranking (order) of the products based on the query features q, and product’s features d. In other words, we are trying to learn the ranking function f(q,d) which will estimate a product's relevance score for the query.
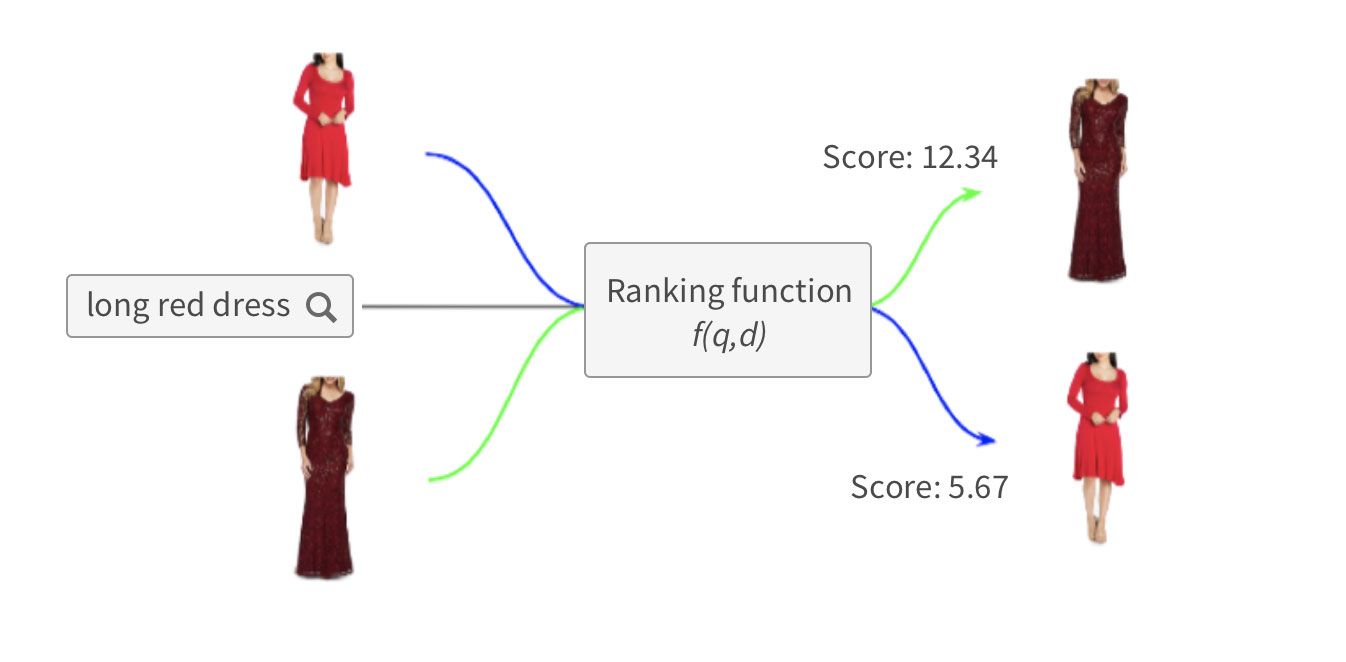
As with any supervised learning problem, we will need some sort of ground truth about the relevance of particular products for particular query. Such ground truth can be based on expert judgement, or on crowdsourcing, but by far the most practical way of obtaining the ground truth signal is to use customer behavior as a proxy to relevance.
Generally, there are three approaches used in learning-to-rank models: pointwise, pairwise and listwise.
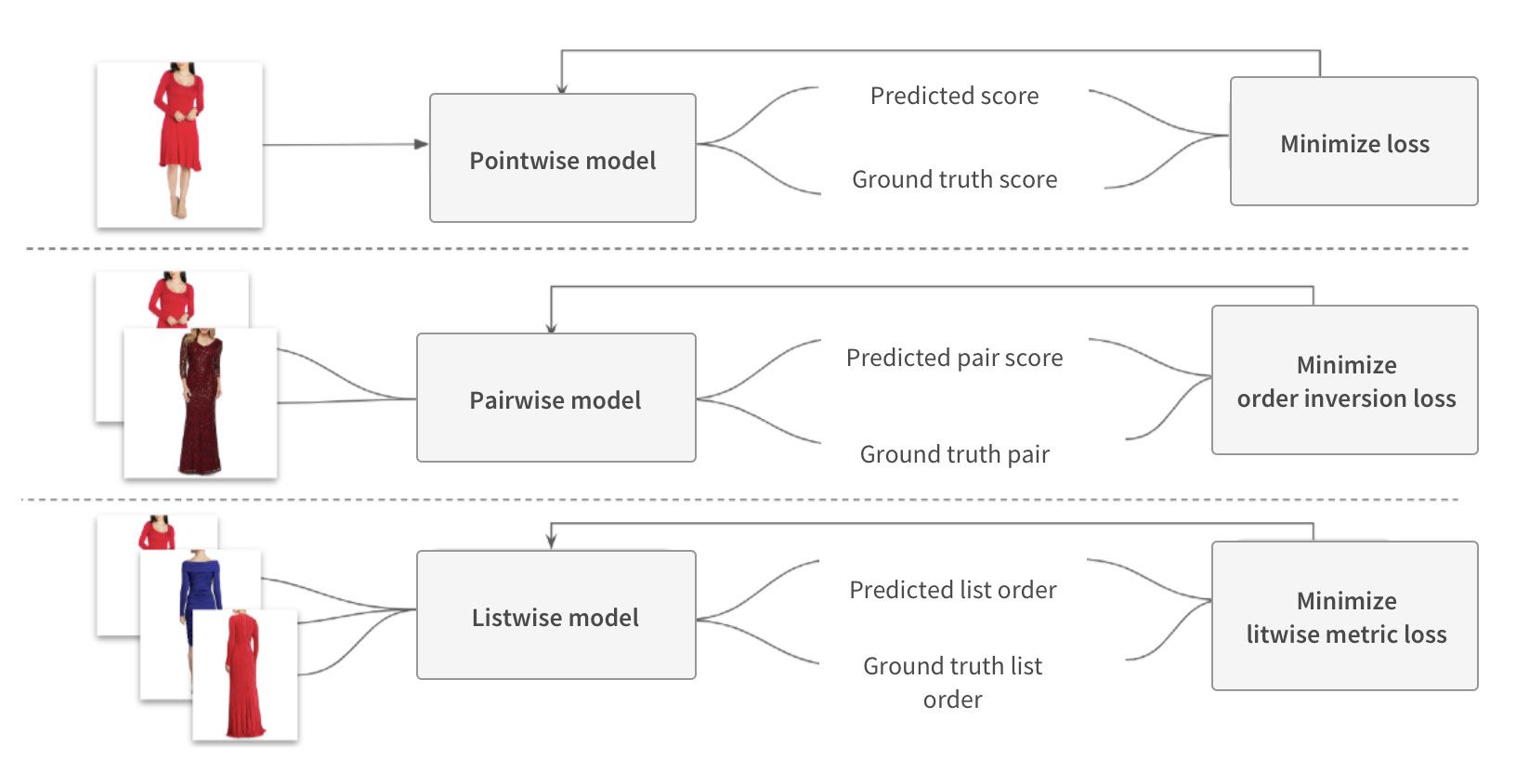
The pointwise approach is trying to directly predict relevance score, pairwise approach predicts relative order of two candidate products, while listwise approach deals with a whole list of products at once.
As usual in machine learning tasks, before we do any training we need to vectorize our data - e.g. convert our queries and documents to vectors, matrices or tensors.
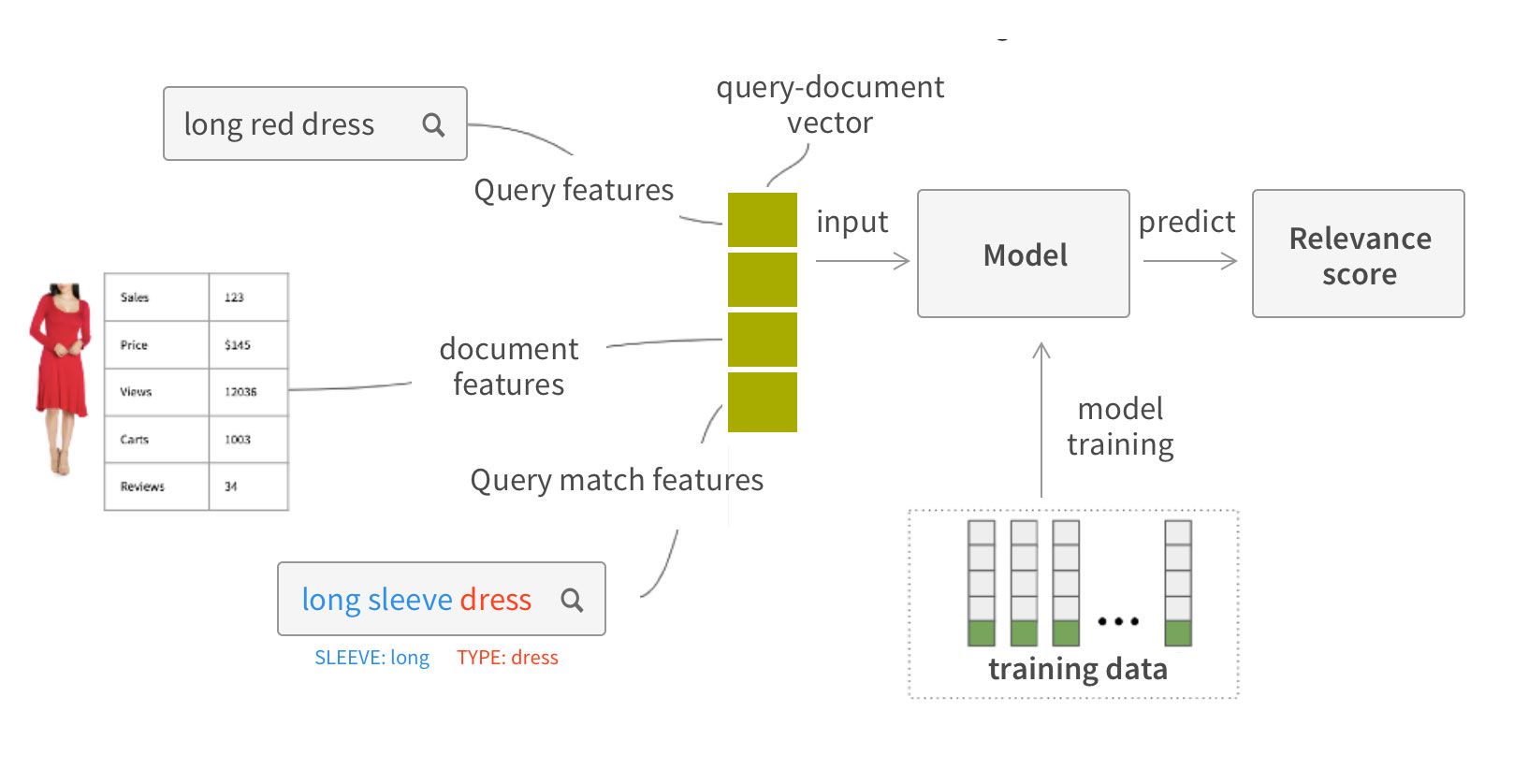
In general, we will have 3 kinds of features:
- query features, which can be as simple as number of words in query or as complex as deep learning word or sentence embedding.
- document features, which in our e-commerce case can be things like price, units sold, sales, popularity, number of views, number of reviews, newness, etc…
- query-document features - those are features which represent how well document matches the query. There are numerous techniques to engineer those features, and we will discuss some of them here.
Let’s assume we have following dataset capturing our queries and their relationships with discovered products:
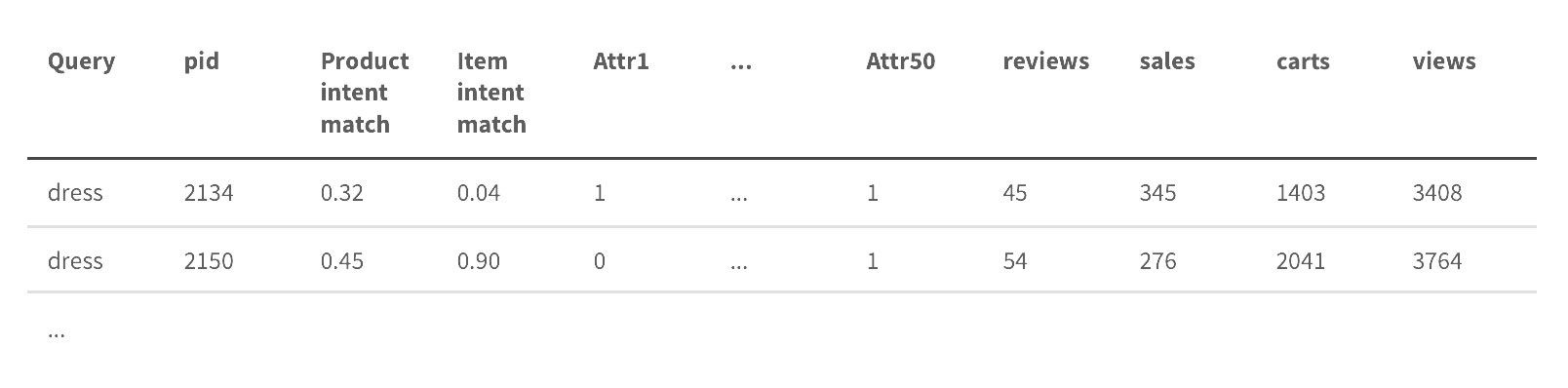
In this dataset we introduce a bunch of query-document features
- Based on the intent classification model, we can capture the probability of this item’s product type as predicted by query intent model. E.g. If the product type of this product is “jeans” and the customer is searching for “dress” this score will be low. Same approach is applied to more granular “item type”
- We analyze attribute-level matches and capture if query is matched to one of the product attributes by search engine. We encode those match patterns with one-hot encoding, e.g. if our attributes are (Brand, Types, Occasion, Size, Color) then (0,1,0,0,1) will denote that there was a match in Type and Color fields.
- We scale all product-level features (sales, views, etc…) to normal distribution using box-cox transformation and standard scaler, as our ML model expects normally distributed features.
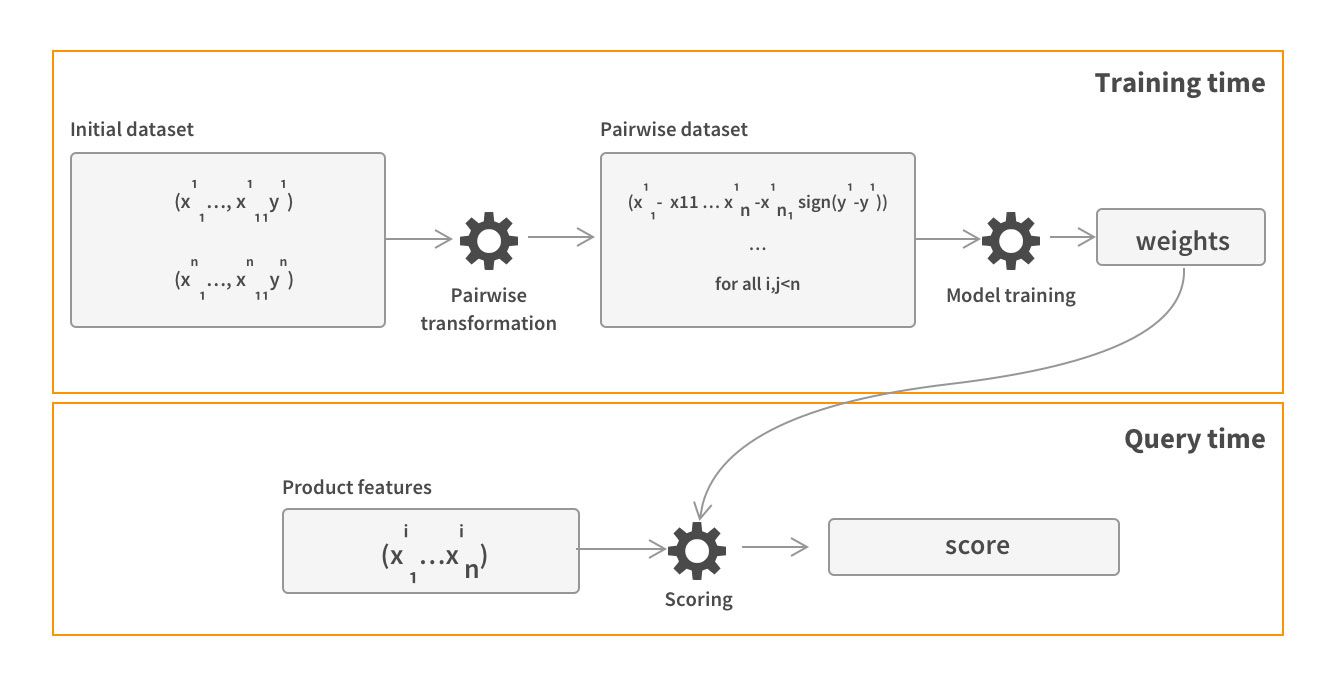
Now, we need to develop and train a model which can be used by the search engine to directly score the matching products. To achieve that we will use a neat trick of pairwise linear transformation. For mathematically inclined, we can refer to the original article.
To the rest of us, the main idea can be described as follows:
- For each query, we generate pairs of products which were interacted with after searching this query
- We linearly transform their corresponding features to get “delta-features”, which describe the differences between products for document features, and differences between ways how products match queries for query-document features.
- We define a training target to reflect a judgement on which of the products in the pair is more relevant for the query.
- We train the linear model to predict the target, obtaining the weights for the delta-features
- … and here is the the neat trick: As the model is linear and transformation is linear, we can still use the learned delta-feature weights on the original features to predict the score which will still correctly order the products in the pairs. This allow to use learned weights directly in search engine.
Before we can proceed, we should figure out how to create a learning target, aka relevance judgement. In general, there is a separate art and science behind relevance judgement model. Researchers and practitioners are devising different kinds of learning targets from clickstream data, from just simply counting clicks on products to sophisticated models which incorporate post-click behavior.
Here, we will consider the following simple technique for generating relevance judgement. We will group all events by the query and will define relevance score as
S = log(clicks) * carts / clicks.
This formula takes into account general attractiveness of the document in the result as log(clicks), as well as add-to-cart ratio as indicator of relevance.
Now, let’s look at the example of pairwise transformation. We will start with the following simple dataset.
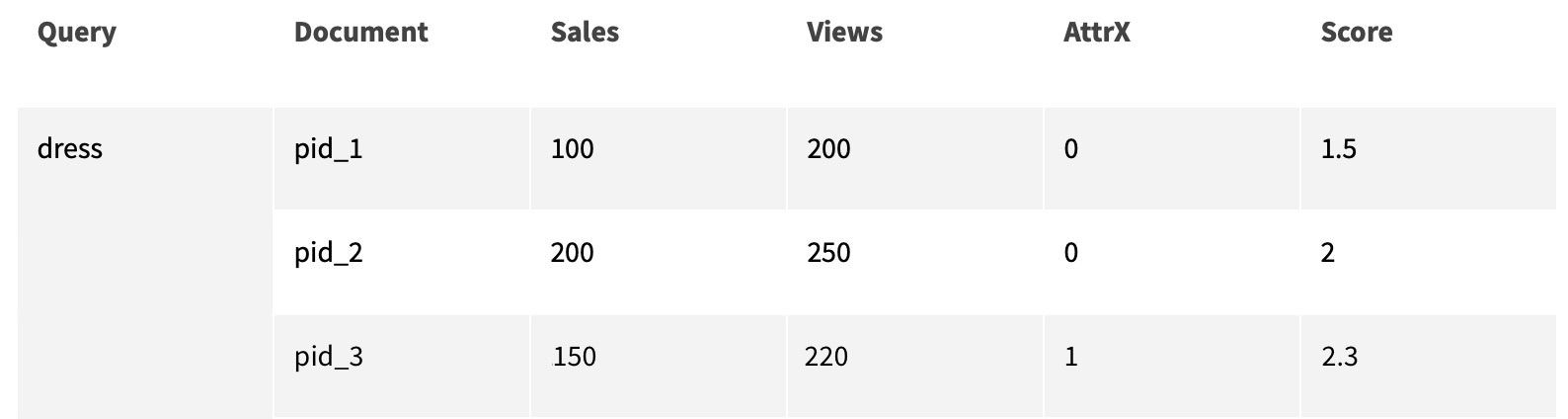
First, we generate pairs of products from it, encode differences between their features and create binary and float prediction targets.
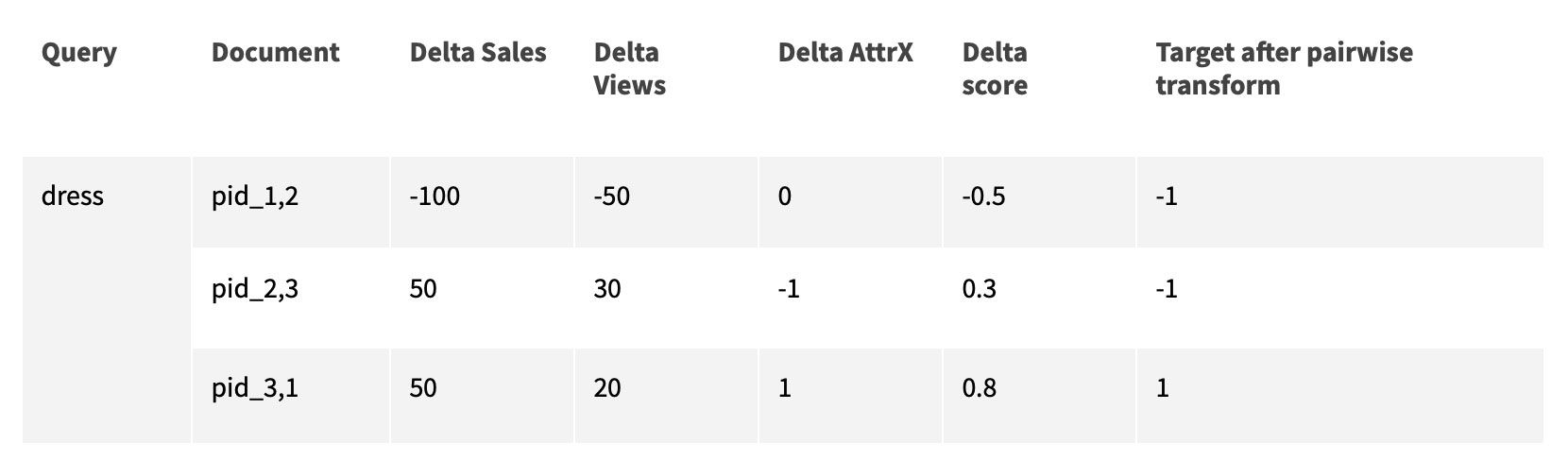
Target after pairwise transformation shows which product in pair of products is considered more relevant for the query - first (1) or second (-1), based on score.
Next, we train a popular collection of "usual suspects" of linear models: logistic regression, linear regression, linear SVM. Resulting weights are transferred to rank products in the search results. In order to evaluate the quality of the model, we used following search quality technical metrics:

We define “binary target” as a simple relevance metric which indicates whether a product was added to cart after the query. We consider products which are never added to cart as irrelevant for the query.
“Float target” is calculated as a score normalized for the maximum score within the query, and is used as a proxy for relevance when calculating NDCG and precision metrics.
For precision metrics, following diagram explains it visually:
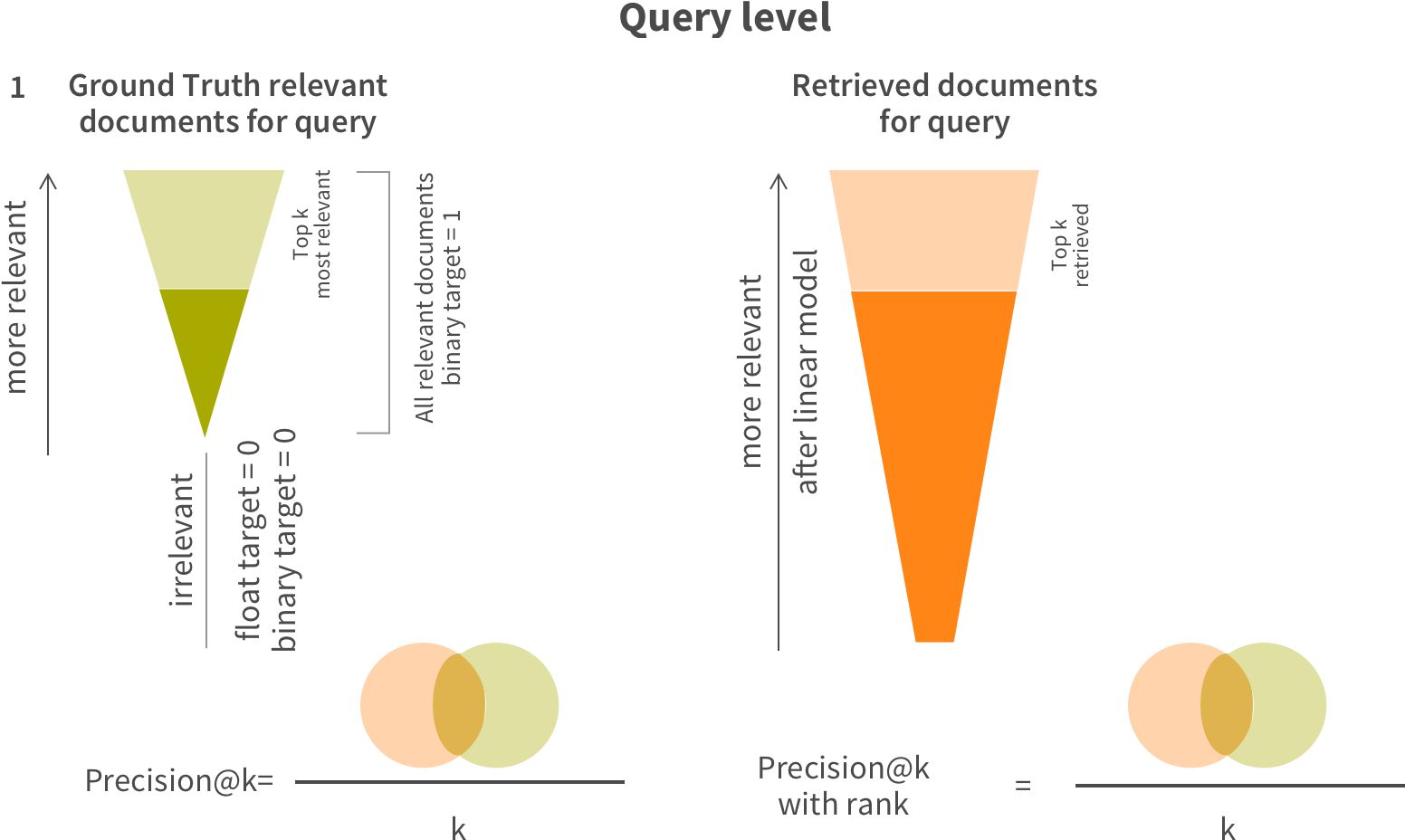
After evaluation of the model results we selected logistic regression as a winning model. Other more complicated models didn’t show substantial uplift compared to logistic regression on our dataset.
We compared our metrics with a baseline of standard search results (without existing LTR resorting of first few pages) and observed a massive uplift in all metrics:
- NDCG@48 improved by 32%, while NDCG@12 improved by 50%
- Precision improved by 20-35%
- Ranked precision@12 improved by 52%
This means that new model is much better than a baseline in predicting attractive and relevant products and pushing those products to first pages of search results.
Conclusion
In this blog post, we made a case and described a practical approach to building a tiered learn-to-rank search system which can extend the coverage of machine learned ranking to the whole set of matching products, not only to the first few pages of the results. Because of the linear nature of the model this can happen without significant impact on search performance. As a result, larger number of relevant products are pushed to the top few pages by the search engine where ranking can be further optimized by more sophisticated algorithms.
If you are interested in search quality and learning-to-rank and want to have a discussion with us, don't hesitate to reach out!