
Semantic query parsing with Lucidworks Fusion: Key to understanding search queries


Semantic query parsing is a powerful technique to improve relevance of the search results. It has proven especially successful when a search solution deals with semi-structured data, such as e-commerce product catalog, customer profiles, or real estate listings.
While we have covered the core engine structure of the solution in the Semantic query parsing blueprint, let’s also dive into the technical work related to managing infrastructure, ingesting the data, exposing APIs, and organizing a query pipeline. In this blog post, we describe the architecture of an end-to-end semantic query parsing solution based on Lucidworks Fusion search platform. The Fusion search engine takes care of many mundane search implementation concerns, allowing customers to focus on achieving best relevance of results.
What is Lucidworks Fusion?
Lucidworks Fusion is a full-fledged search and artificial intelligence (AI) platform based on Apache Solr and Apache Spark. It has a cloud-native microservices architecture orchestrated by Kubernetes. It can be deployed on K8s engine, either in the cloud or on-premises, and is available as a PaaS. Lucidworks Fusion offers a fundamental integration framework for search applications, as well as a large number of valuable services, components, connectors, and APIs, which simplify and accelerate the development.
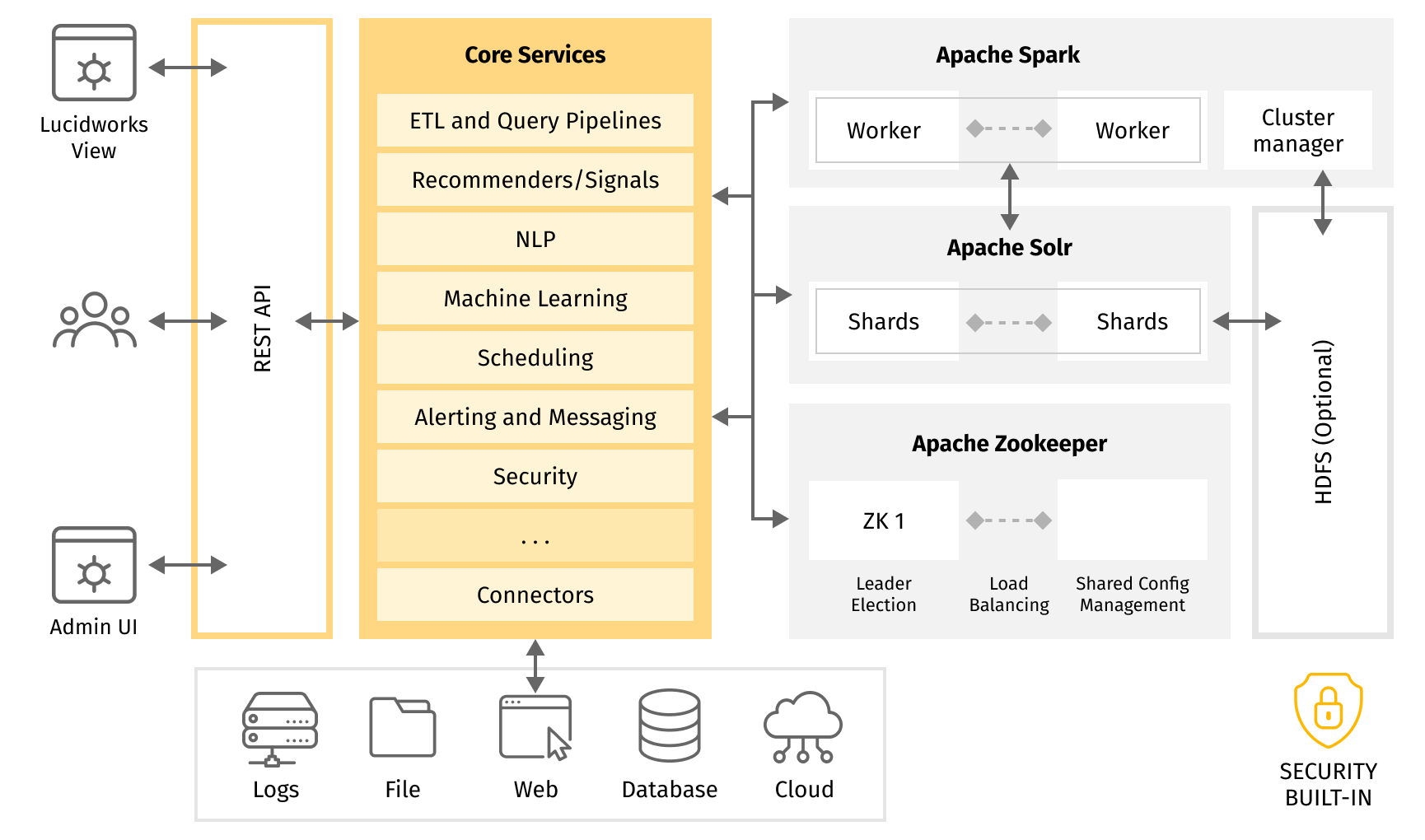
![[1]](https://upload.wikimedia.org/wikipedia/commons/a/a5/Lucidworks-fusion-architecture.png){kind=link}
If you use Endeca, check out How to replatform Endeca rules to Solr and Fusion release notes, so you have a complete picture in mind.
Focus on features, not infrastructure when approaching search
When developing search solutions, there is always a choice between a custom-built and a platform-based approach. While the custom approach provides ultimate flexibility, the platform-based solution is able to accelerate speed to market and typically gives better efficiency.
We can illustrate it in the following example. Let's consider a common search flow diagram (a very simplified version) and evaluate where exactly Lucidworks Fusion platform capabilities accelerate the solution compared to a custom-built implementation:
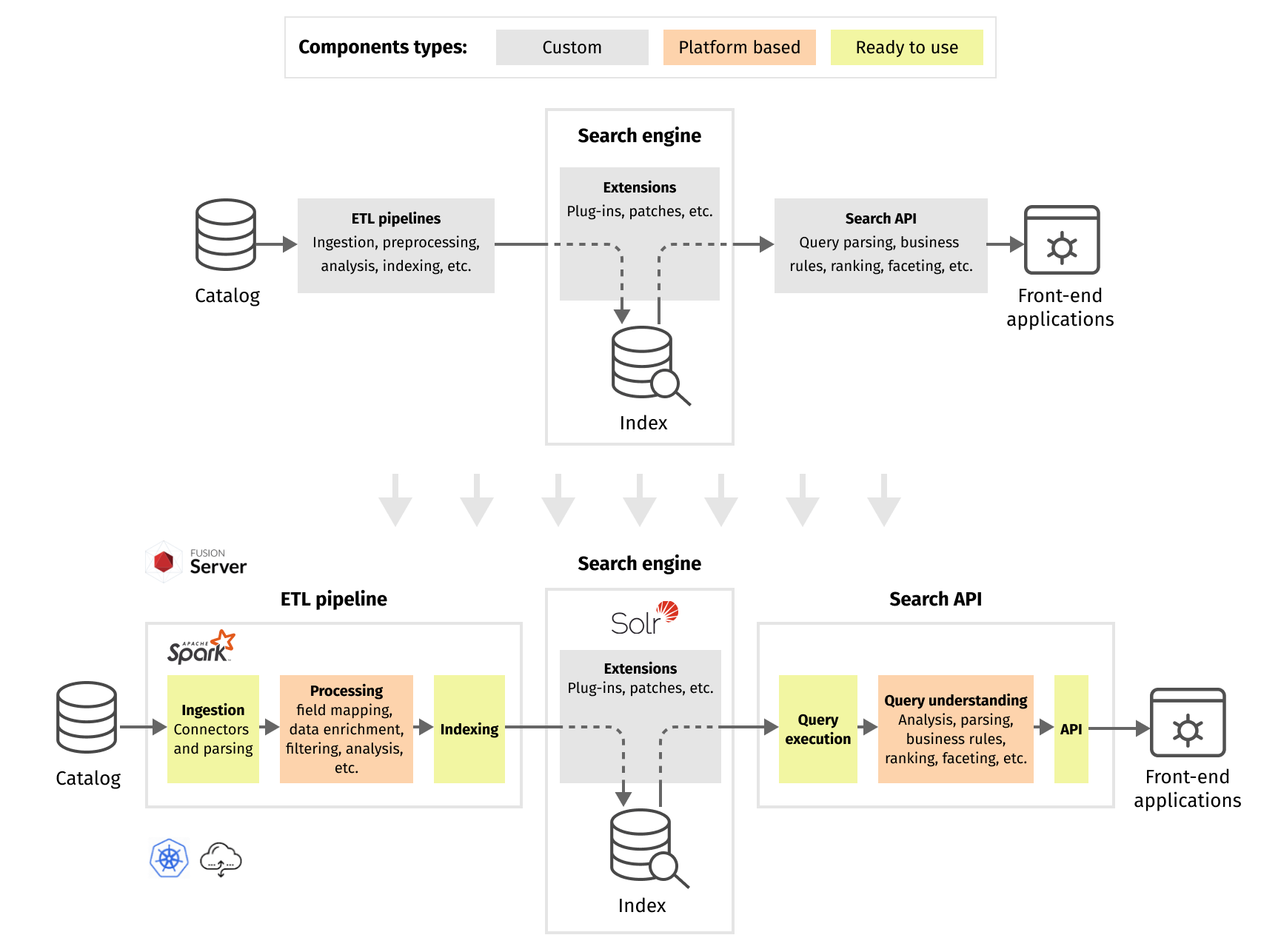
A search system usually consists of index-time and query-time components. Index-time components are focused on extracting, processing, enriching, and indexing the data, while query-time components are concerned with interpreting the query, retrieving and ranking search results.
When using Lucidworks Fusion, the platform handles the routine process of data ingestion and prepared data indexing completely. Fusion platform fully manages Solr and Spark clusters and provides the framework and interfaces for the ingestion and indexing pipeline. Core intelligence of the search solution is implemented via custom data processing components, which implement domain-specific data analysis and other business logic. Fusion platform provides the ability to plug in, chain, and configure those custom components using configuration parameters and code interfaces.
In some rare cases, very specific and complex requirements lead to a bunch of low-level modifications to the Solr service and Lucene search library. Those modifications are available through Solr extensions and patches, which can be plugged into Fusion as well. However, such customizations require additional integration and maintenance efforts and generally should be avoided.
At the heart of any search system lies the query processing pipeline. It is responsible for:
- Interpreting the natural language query.
- Enriching it with additional data and converting it into a low-level boolean retrieval representation.
- Ranking instructions which can be executed by search engine.
Fusion provides a query pipeline framework that allows configuring and chain query processing components, passing the query context and parameters between them. This allows us to build fairly sophisticated query processing pipelines without writing a lot of boilerplate request processing and context management code.
Finally, the Fusion external API helps integrate front-end applications with the query processing pipeline.
Semantic query parsing with Fusion
Now, it's time to map the semantic query parsing blueprint to the components and capabilities of the Fusion platform.
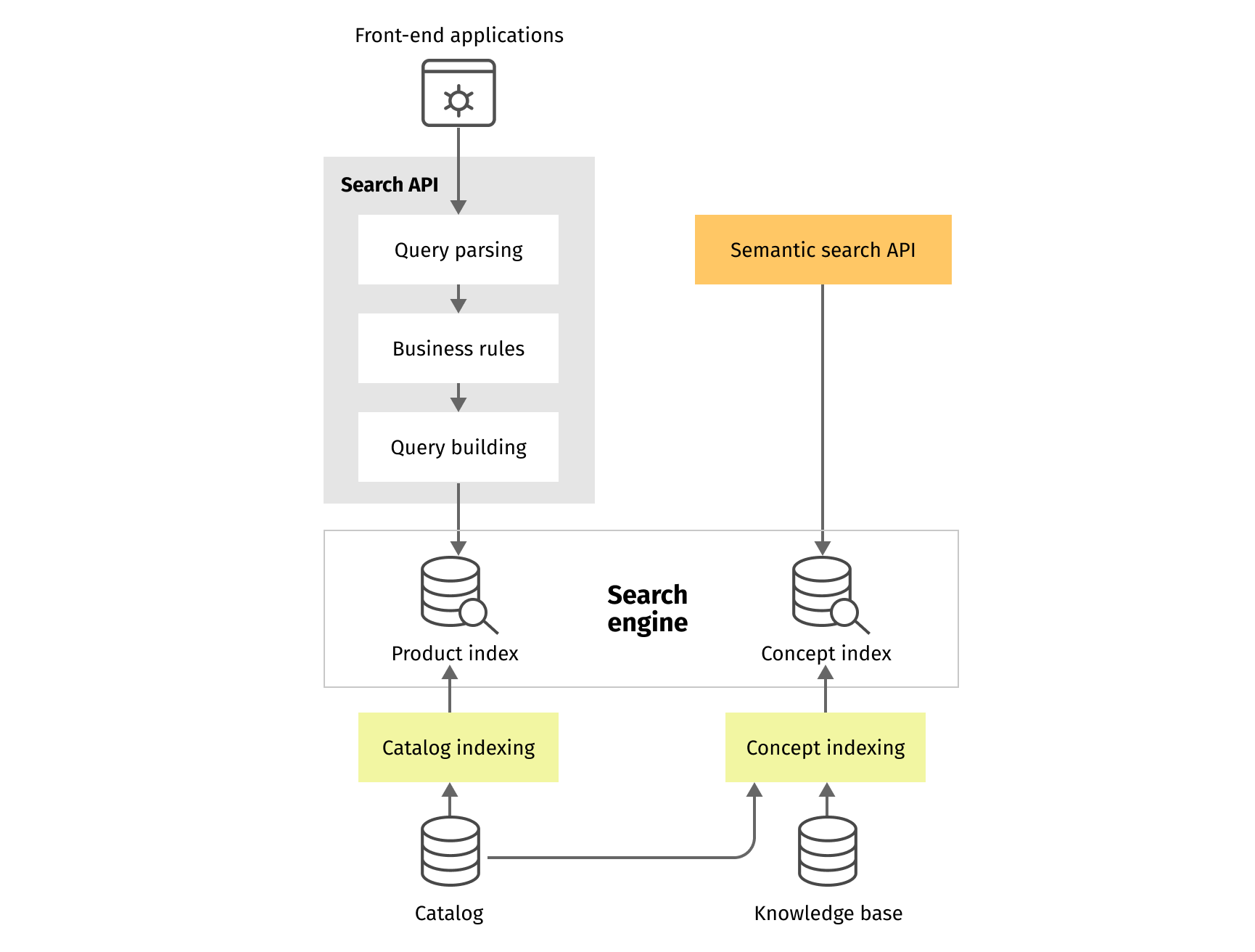
In this blog post, we will not focus on general product catalog indexing and full Search API features, such as faceting, filtering, business rules, autocomplete, etc. Fusion provides out-of-the-box components to cover many of those concerns. Let’s assume that the product index has been prepared, and consider specifics of semantic query parsing and multi-stage search.
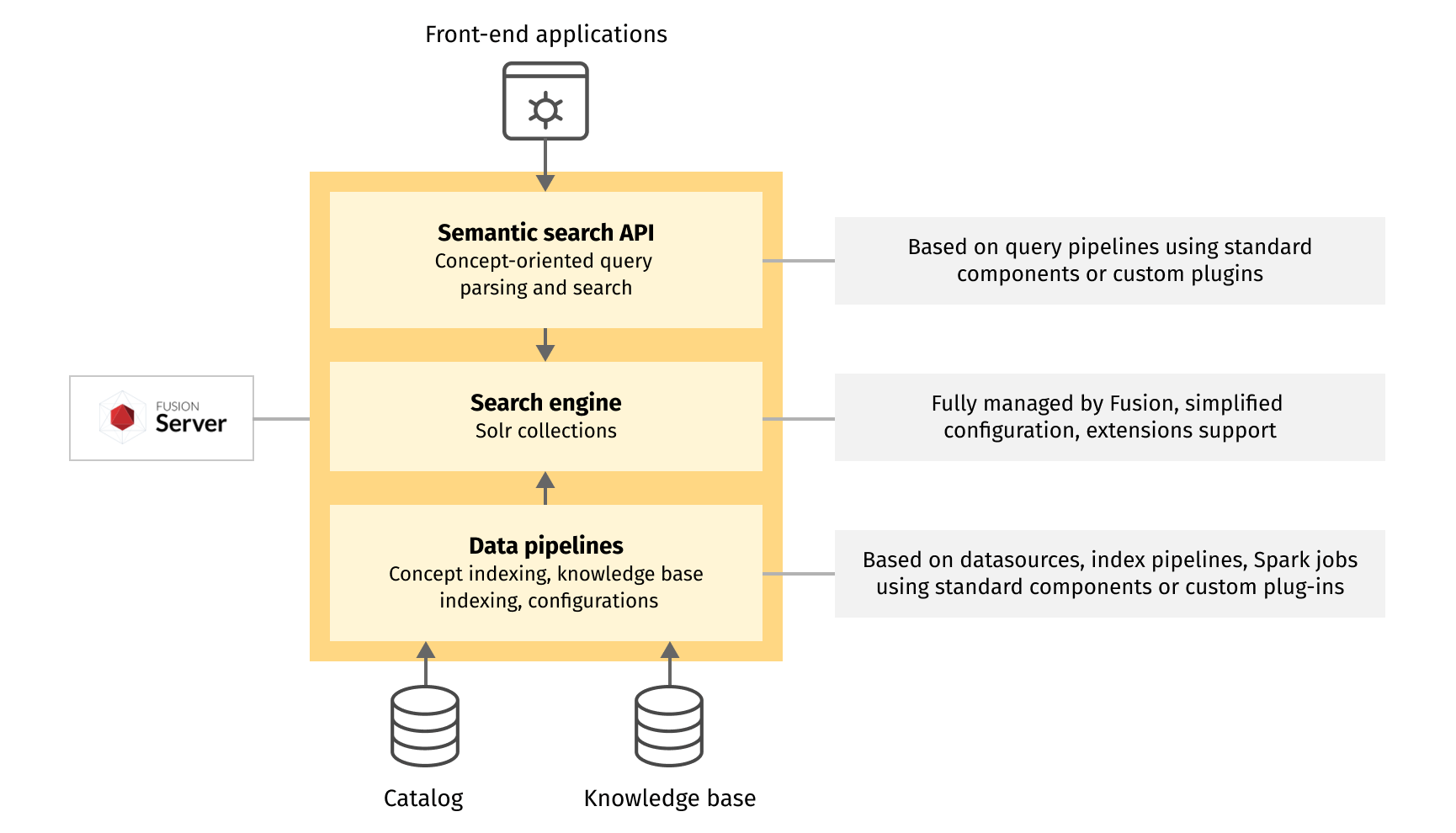
Semantic search implementation contains three main steps:
- Semantic data ingestion and indexing: preparation of concept index and additional semantic information based on a search configuration. It will be based on extra collections, index pipelines, and Spark jobs.
- Concept-oriented query parsing: representation of the initial search phrase as a semantic query graph. This step will be a part of a query pipeline.
- Concept-oriented search, which includes transformation of semantic query graph to a search engine query and multi-stage search. It will also be part of the query pipeline.
Semantic data pipelines
Semantic data, in our context, contains all domain-specific information and configurations, used in query understanding workflow, and consists of several independent indexes:
- Concept index contains implicit or explicit concepts extracted from the indexed products and the knowledge base.
- Auxiliary semantic indexes contain additional semantic information like linguistics, comprehension patterns, and scoring configuration.
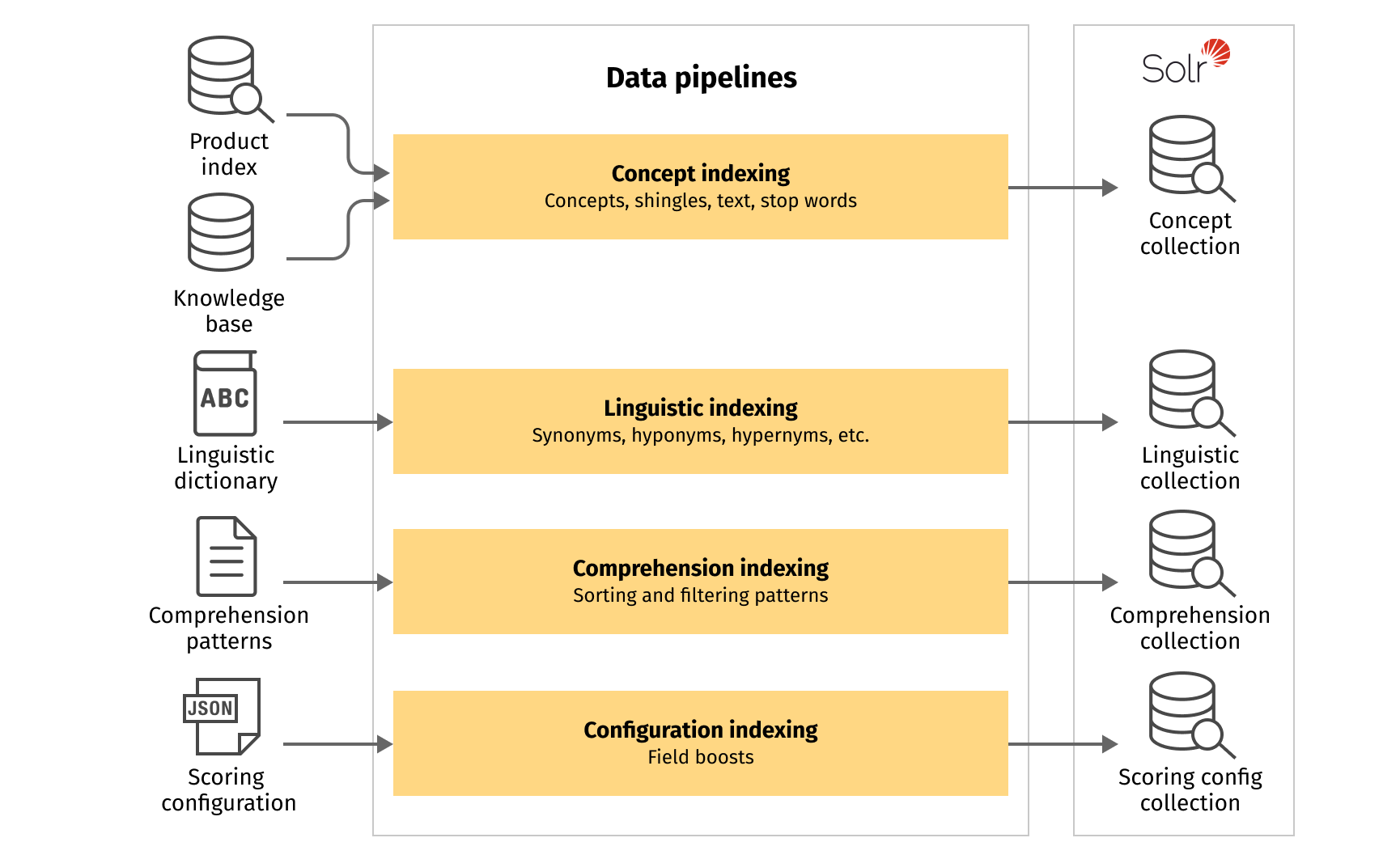
Auxiliary semantic indexes
Structure of indexing pipelines for the auxiliary semantic indexes can be pretty simple. For each index, we need to perform the following steps:
- Create a corresponding collection.
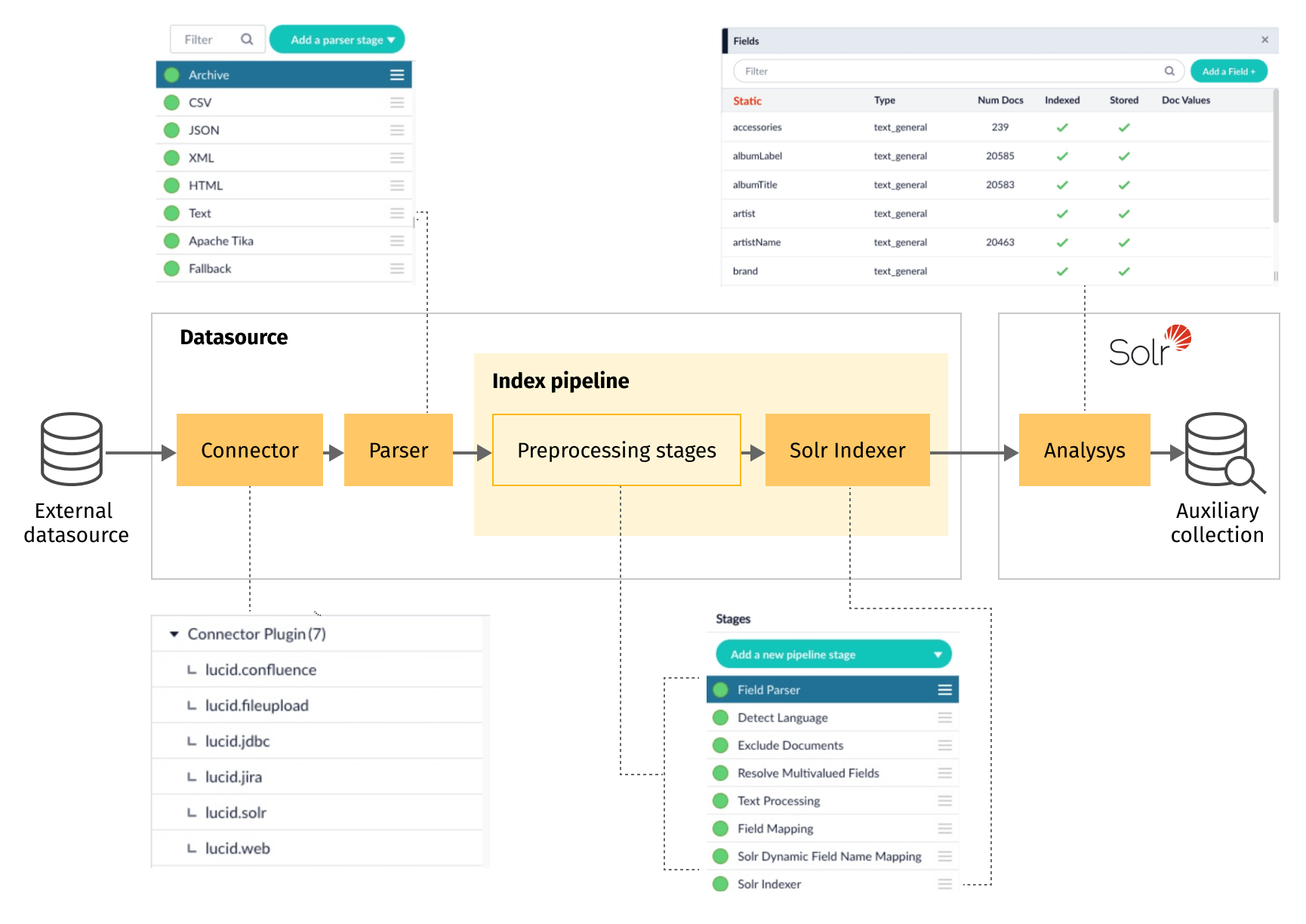
- Configure an appropriate connector to the data source, process depends on where data is stored, e.g., file, cloud storage, database, other index, etc.
- Implement or configure an existing parser for the data format, e.g., plain text, json, csv, xml, etc.
- Implement index pipeline with “Solr Indexer” stage and, if necessary, with some data preprocessing stages before.
Concept index
Structure of the concept indexing flow is more complicated than we used for the auxiliary semantic collections indexing. We can’t build it using standard index pipelines only because it is based both on the product index and the knowledge base. Also, we need to use additional processing inside a pipeline.
It is convenient to organize this process as a Spark job. We can implement our job using Java, Scala, or Python and deploy it to the Fusion platform. The job will:
- Retrieve documents from the product index and the knowledge base.
- Extract attributes from them.
- Perform preprocessing or filtering for extracted values if necessary.
- Pass them to concept collection as a part of the following indexing pipeline steps.
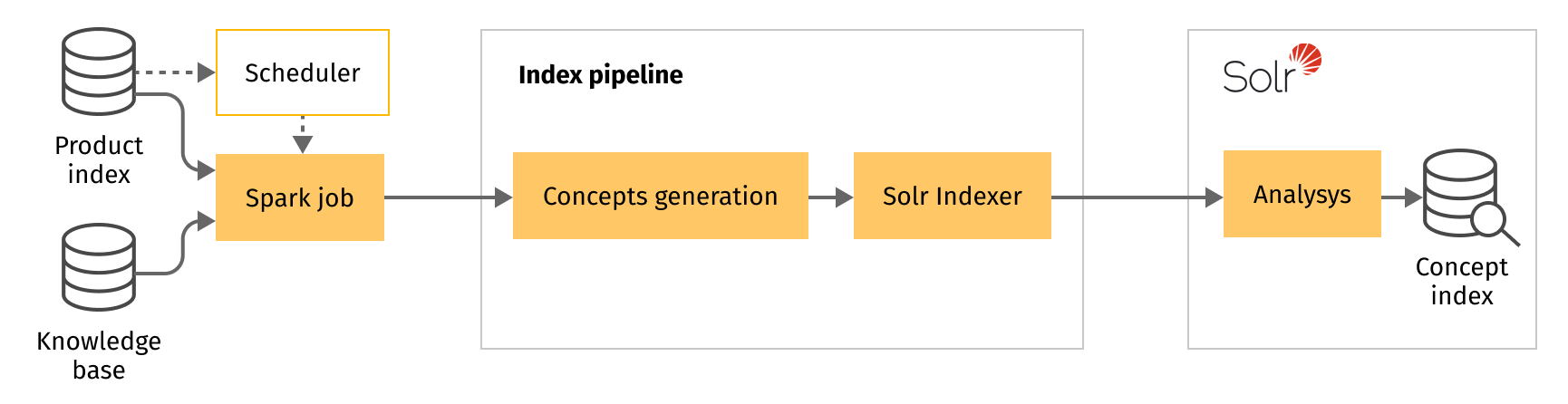
Index pipeline helps to separate data ingestion logic from concept extraction and concept indexing parts of code, keeping your code neat and to the point.
Сoncept reindexing can be configured to launch right after product indexing job completion or once per week in case the catalog is not changed frequently. Alternatively, it can be part of a full reindexing process.
The logic responsible for the transformation of raw product attributes to the concept documents can be implemented using the custom JavaScript stage or deploying a Java-based plugin using Index Stage SDK. Latter is a preferable option as it provides more convenient configuration compared to JavaScript, which requires embedding all parameters in the script code directly.
For example, let’s take a look at a cURL request [3] which creates a small index pipeline with custom JavaScript stage:
curl -u admin:password1 -X POST -H 'Content-type: application/json' -d '{
"id" : "eventsim",
"stages" : [ {
"type" : "date-parsing",
"sourceFields" : [ "ts", "registration" ],
"dateFormats" : [ ],
"defaultTimezone" : "UTC",
"defaultLocale" : "en"
}, {
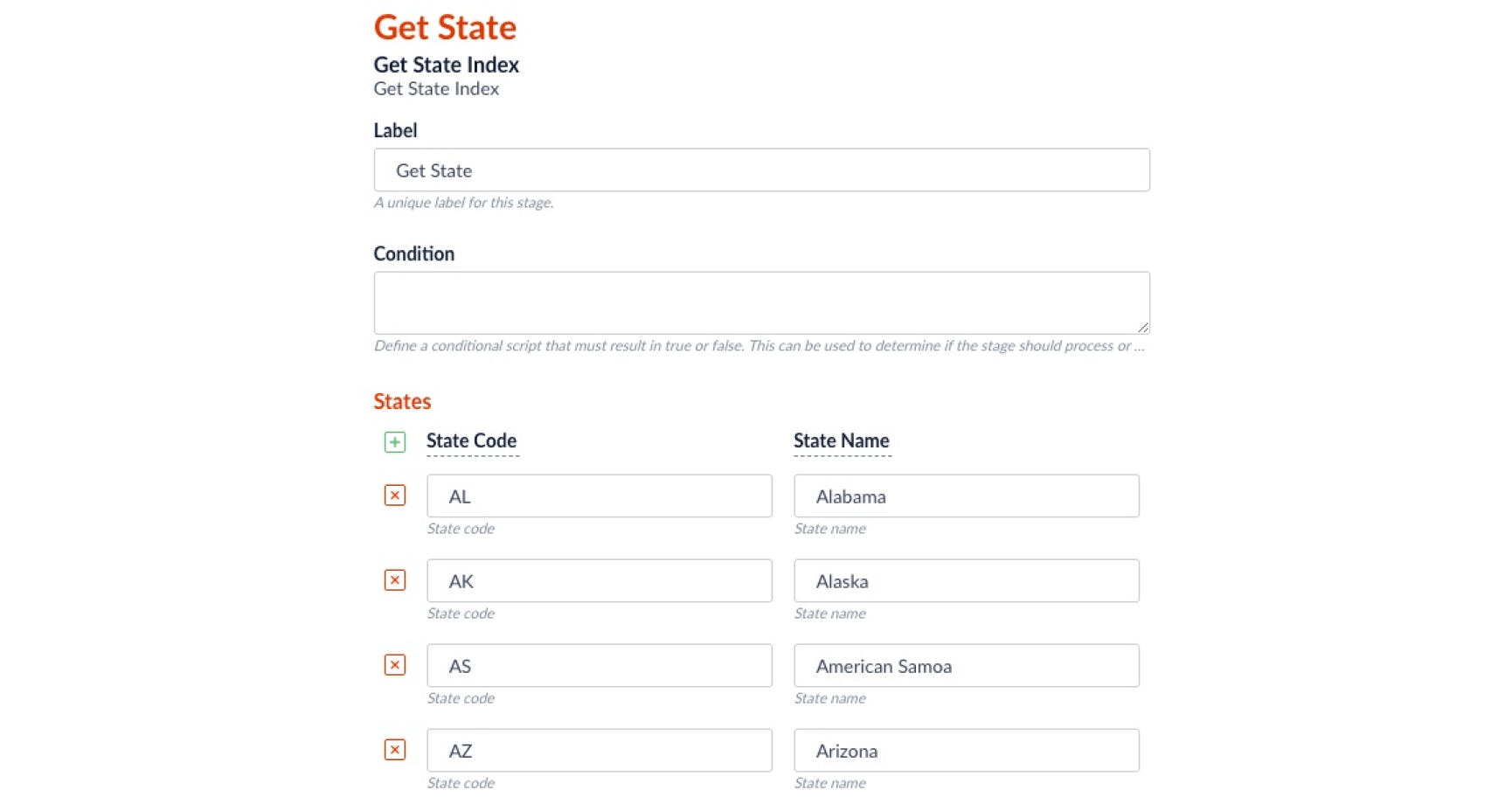
"type" : "javascript-index",
"script" : "function(doc) {\n var states = {\"AL\": \"Alabama\",\"AK\": \"Alaska\",\"AS\": \"American Samoa\", //... and all other state codes in this manner};\nvar loc = \"\";\nvar idx = 0;\nvar abbr = \"\";\nvar state = \"\";\nif (doc.hasField(\"location\")) {\n \tloc = doc.getFirstFieldValue(\"location\");\n \tidx = loc.lastIndexOf(\",\");\n \tif(idx > 0) {\n \t abbr = loc.substr(idx + 2, 2);\n state = states[abbr];\n doc.addField(\"state\", abbr);\n }\n}\nreturn doc;\n}",
"label" : "Get State"
}, {
"type" : "solr-index",
"enforceSchema" : true,
"dateFormats" : [ ],
"params" : [ ]
}]}' http://fusion-host:6764/api/apps/analytics/index-pipelines
and compare it with the a similar one but with the custom indexing stage implemented via Index Stage SDK:
curl -u admin:password1 -X POST -H 'Content-type: application/json' -d '{
"id" : "eventsim",
"stages" : [ {
"type" : "date-parsing",
"sourceFields" : [ "ts", "registration" ],
"dateFormats" : [ ],
"defaultTimezone" : "UTC",
"defaultLocale" : "en"
}, {
"type" : "get-state-index-stage",
"pluginStageType": "get-state-index-stage",
"states": {
"AL": "Alabama",
"AK": "Alaska",
"AS": "American Samoa",
"AZ": "Arizona",
"AR": "Arkansas",
"CA": "California",
//... and all other state codes in this manner
},
"label" : "Get State"
}, {
"type" : "solr-index",
"enforceSchema" : true,
"dateFormats" : [ ],
"params" : [ ]
}]}' http://fusion-host:6764/api/apps/analytics/index-pipelines
In Fusion UI, this stage will look like:
Concept-oriented query parsing
The next step is construction of a query pipeline, which represents concept-oriented query parsing workflow. This pipeline will be responsible for the following operations:
- Initial transformation of the search phrase to the semantic query graph representation.
- Graph enrichment with spelling corrections, linguistics, comprehensions, compounds, and other available semantic information.
- Concept tagging where we identify fields in which we can find particular parts of the query.
- Path scoring ranks of alternative query interpretations, represented as graph paths.
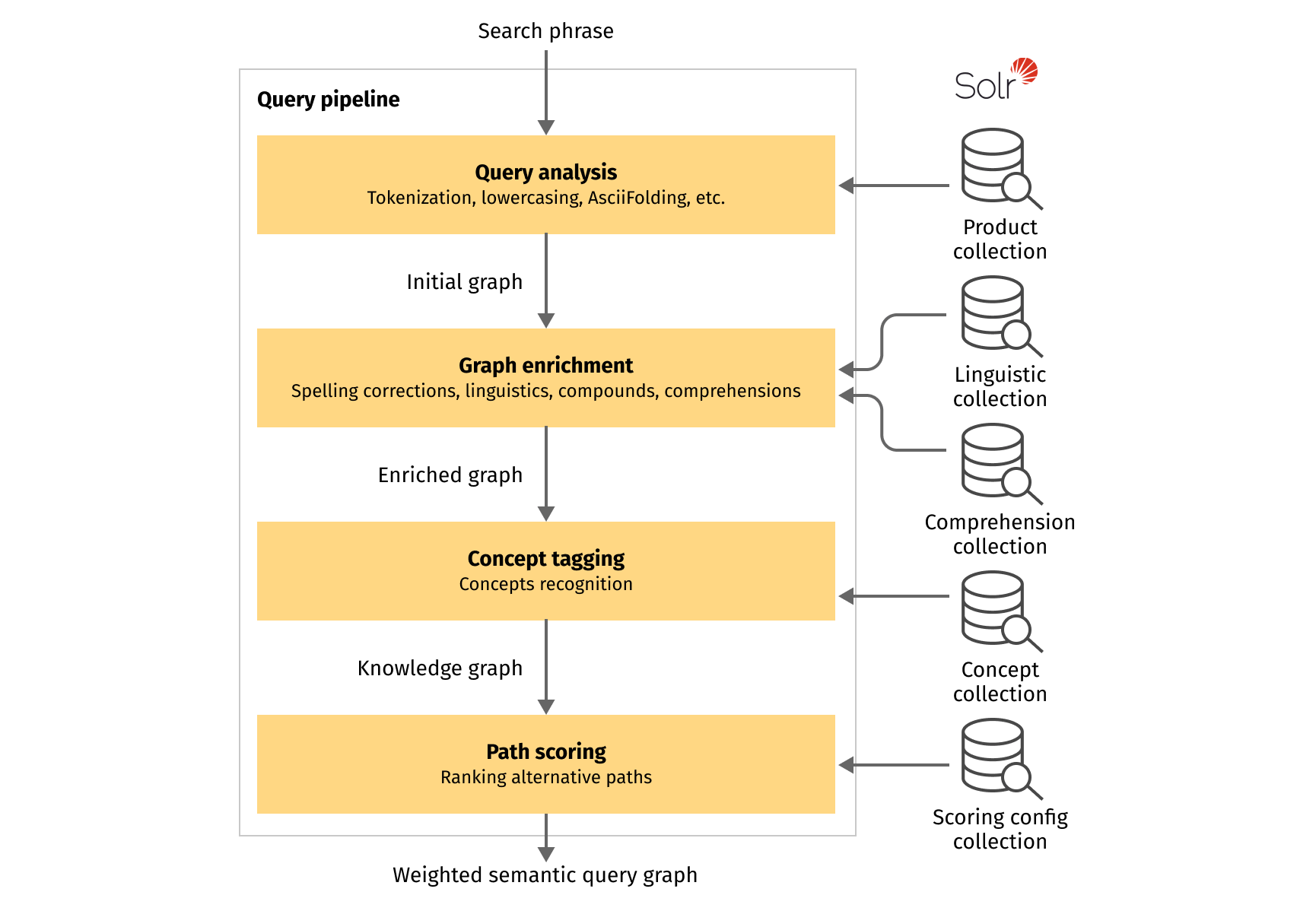
From the Fusion platform point of view, query understanding workflow is just a regular query pipeline, in which each step is a separate query stage. Like in index pipeline, stage in query pipeline can be implemented using JavaScript stage or Java and Query Stage SDK (more preferable). From the query stage, we have access to internal Lucidworks Fusion APIs, which allow us to communicate with existing collections and retrieve the data points required for the particular query understanding step.
We perform the same query analysis as for the product index and build the initial graph. After that, the graph goes as a context object through the stages of the query pipeline where it is enriched, transformed, and cleaned. Final query graph will represent all our hypotheses about possible interpretations of each piece of the initial search phrase, and for each hypothesis we can estimate how probable it is compared to others.
Concept-oriented search: multi-stage approach
One of the common techniques to achieve a good balance between precision and recall in search results is a multi-stage search workflow. In this workflow, we are gradually relaxing search query interpretations until we are able to find good results. In other words, we start from a full text search match with minor normalizations and gradually apply more aggressive normalizations to its parts.
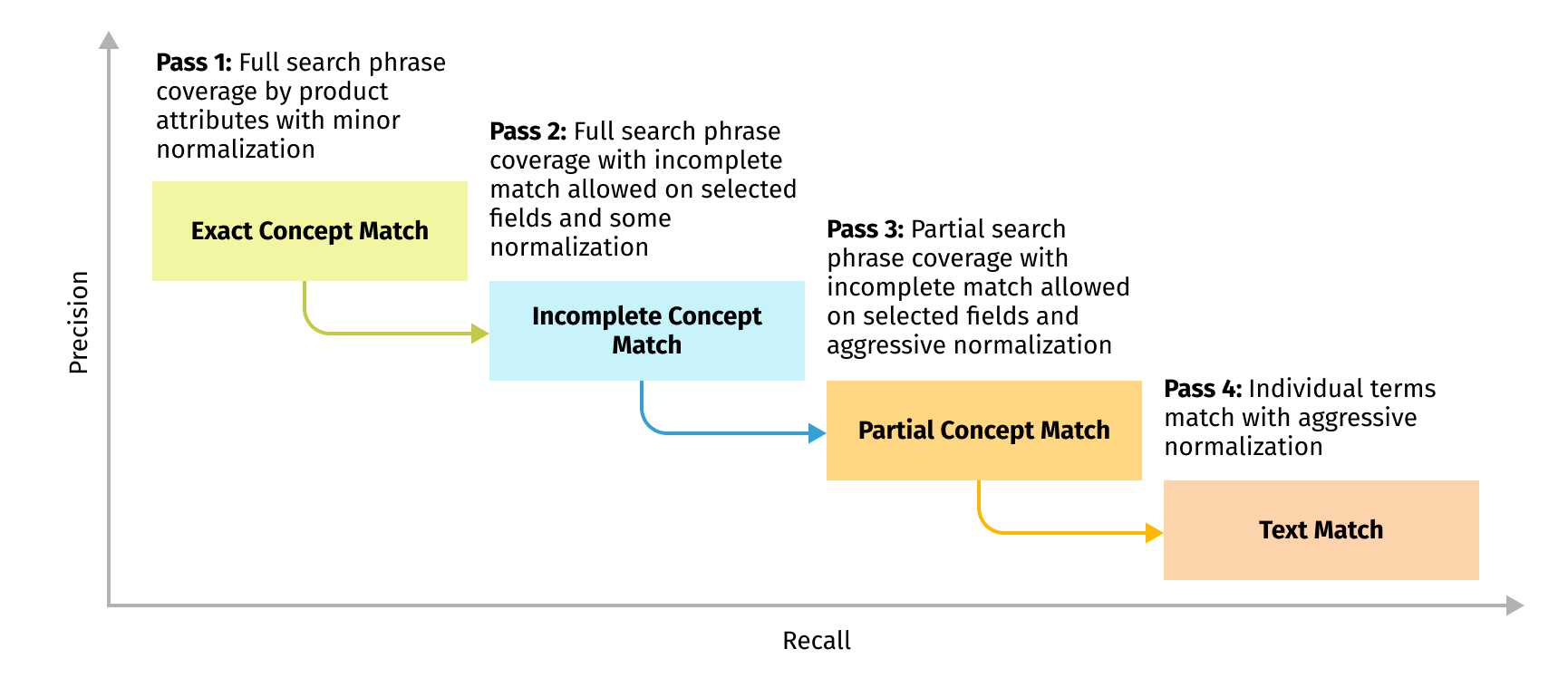
Each search stage dictates its own configuration of fields participating in the stage and types of matches and normalizations allowed. We perform query understanding according to the configuration and build a semantic query graph. This graph is later used to build the actual Solr query that Lucidworks Fusion executes against the main index.
To implement this efficiently, we need to run query understanding and query building pipelines several times with different configurations.
Luckily, Fusion allows us to achieve this separation and reuse with “call pipeline” query stage:
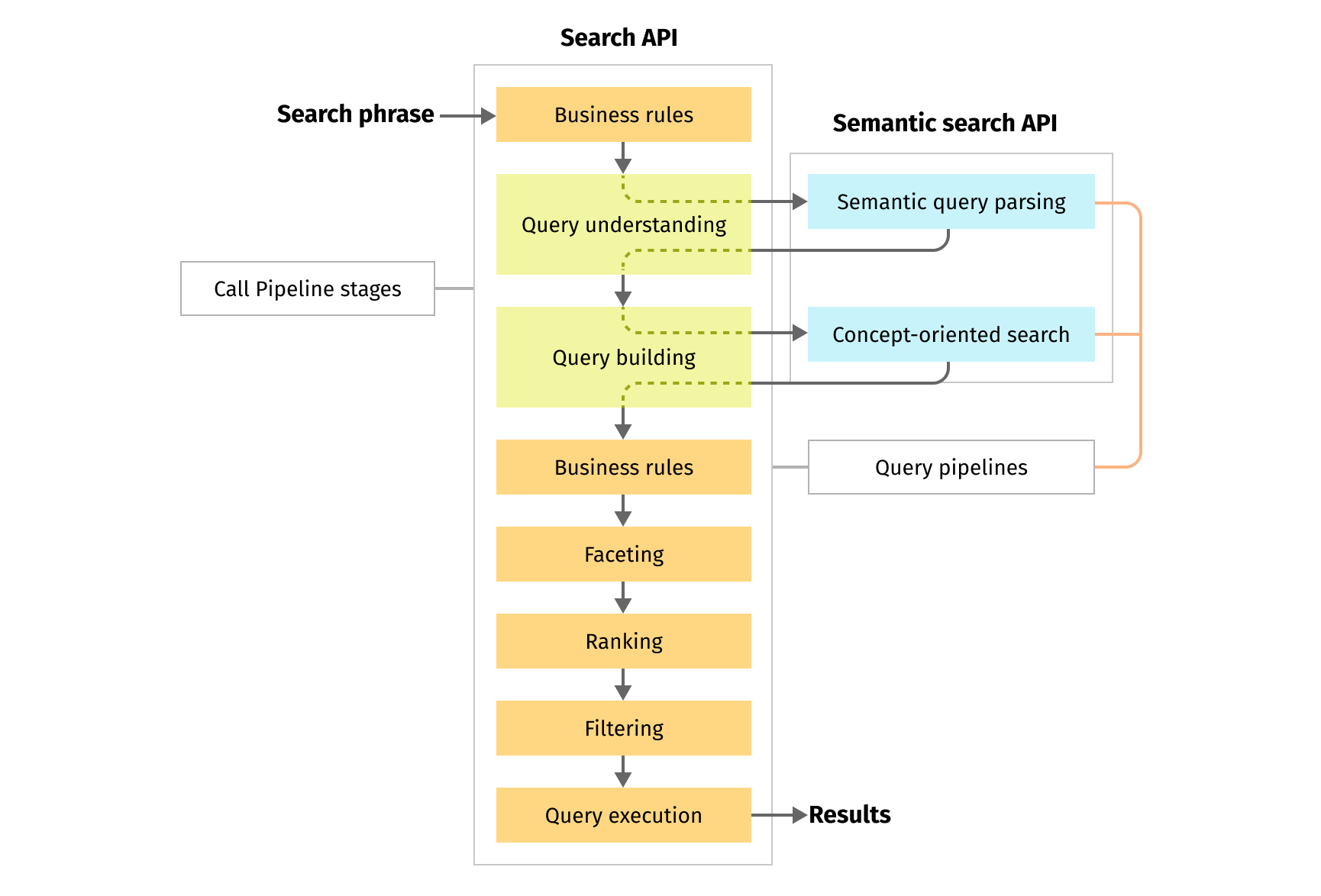
“Call pipeline” stage allows us to encapsulate and reuse query understanding and query building parts of the pipeline in every search stage as well as implement interactions between stages inside the pipeline.
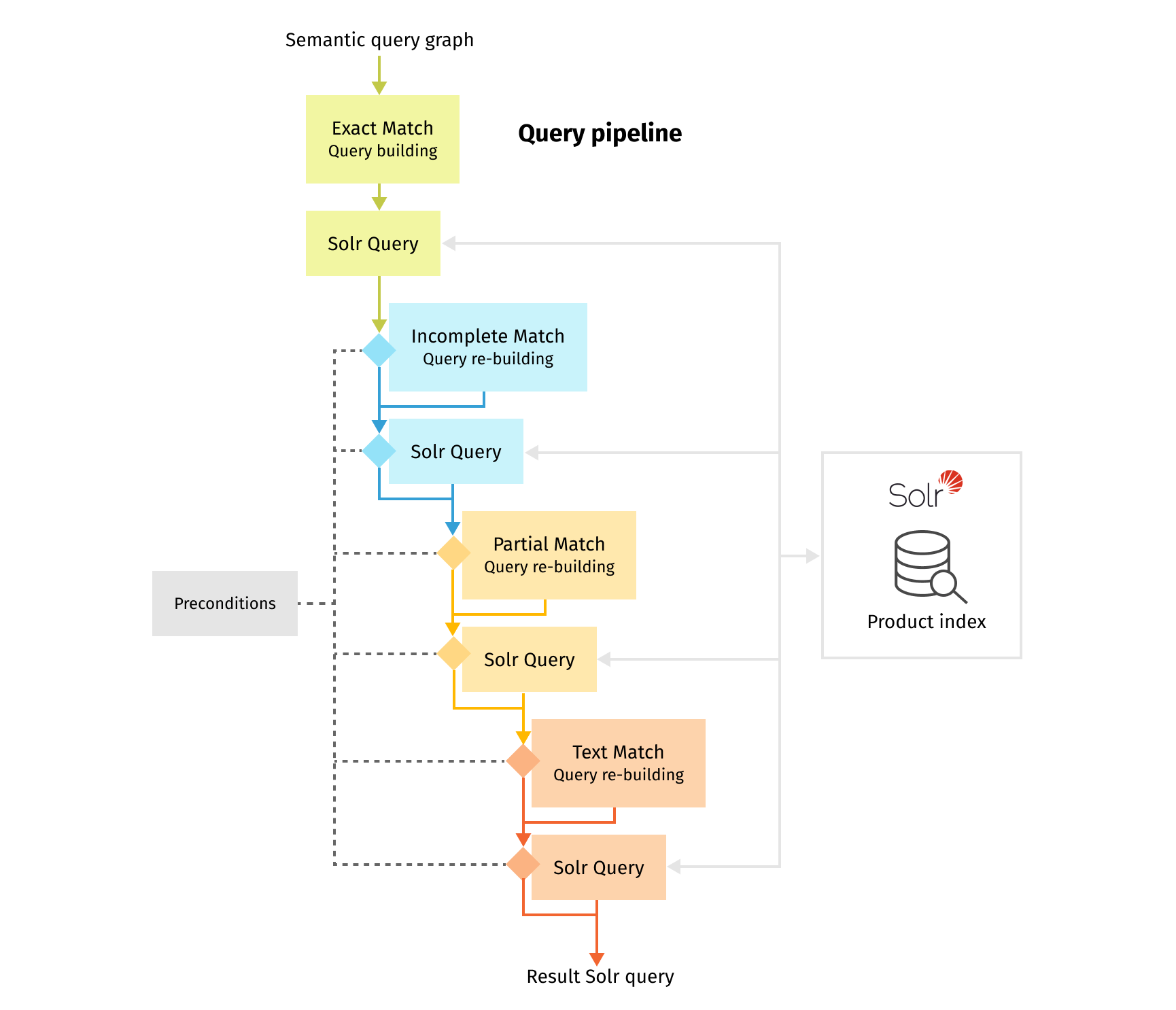
Query building
Now, let's look into the process of converting our query interpretation to a Solr query. Each particular graph converting step is implemented as a separate Fusion query pipeline stage in the same way as for query understanding. It can be completely separate stages (Java-based plugins or scripts if you prefer JavaScript) or stages based on the same code with configuration specifying which parts of the semantic query graph should be used for the particular stage.
Let’s consider a simple search phrase like “m olive shirt dress” and its possible graph representation to better understand the query building process.
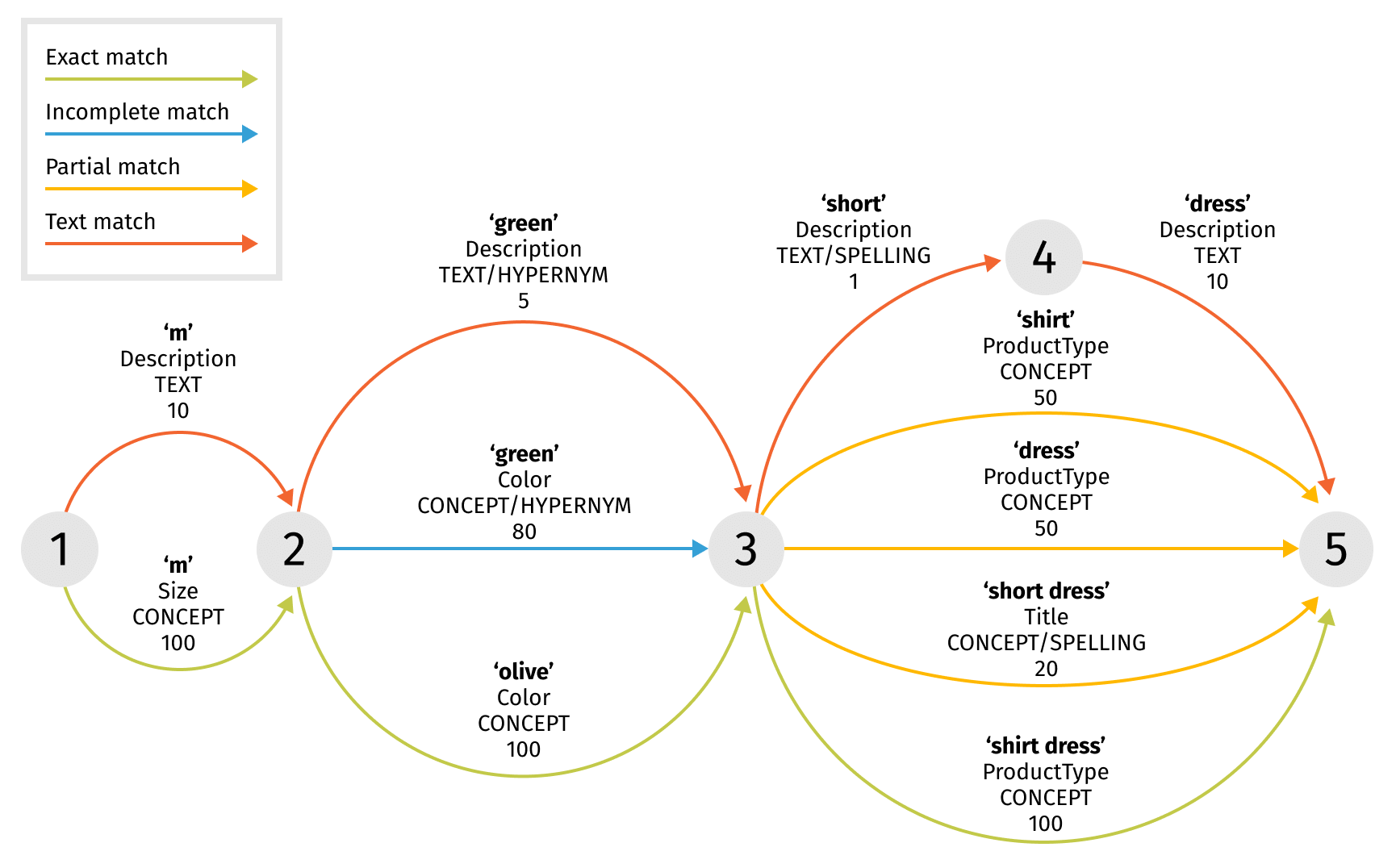
For each search stage, we will use only allowed graph edges to build a search query:
- Exact match – full search phrase is covered by product attributes like size, color, and product type.
- Incomplete match – full search phrase is covered by product attributes, but we suggest a more general color “green” which is hypernym for initially more strict “olive”.
- Partial match – we assume that the user could make a typo and mean “short” instead of “shirt”, so we can try to find a “short dress”. Also, we can try to omit some original terms and search just for “shirt” or “dress” instead of “shirt dress”.
- Text match – here we use all the hypotheses we have, i.e. we are trying to match individual terms in product descriptions using hypernym and spelling correction
As you can see, every subsequent stage allows for more relaxed matches, increasing recall at the expense of precision.
Staged search
Let’s consider a simple scenario, where we want to implement multi-stage search with exit criteria by the number of products found, i.e. if we have found enough items, we can return these results, otherwise we should switch to a more relaxed query interpretation and try again.
Each such search stage represents an interconnected pair of query pipeline stages:
- Custom query stage, which encapsulates Solr query building logic.
- Standard “Solr Query” stage, which sends the request to the search engine.
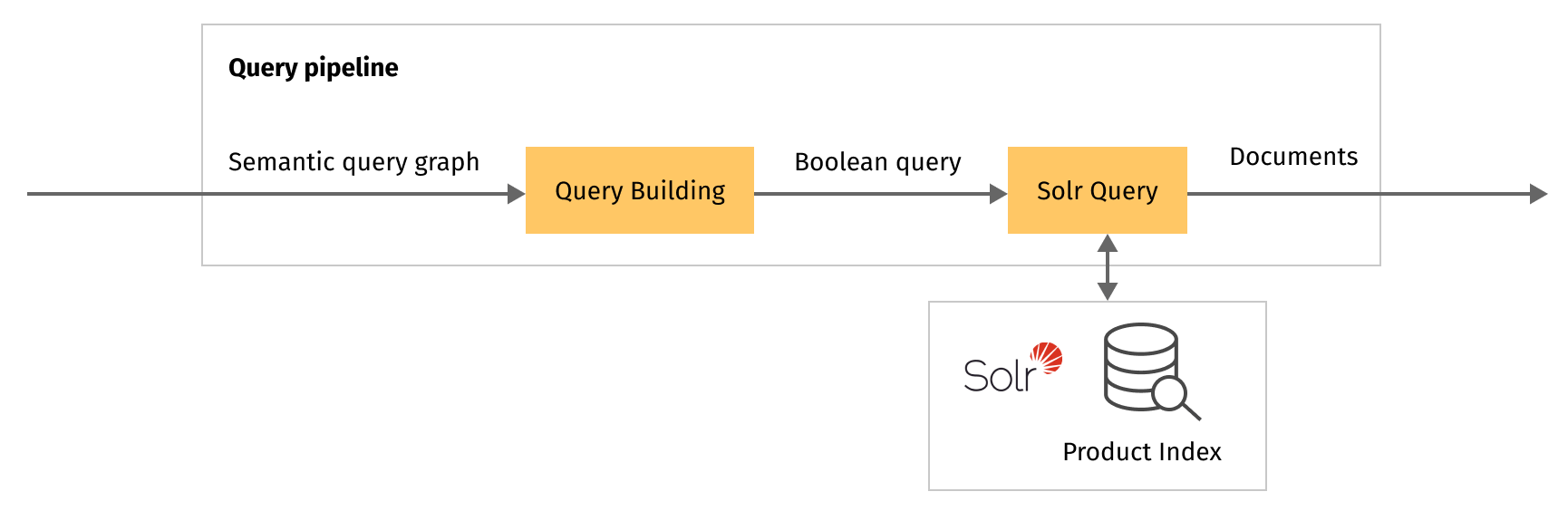
Fusion allows setting a condition for all pipeline stages that determines whether the stage is run or skipped. We can use this mechanism to control the search flow. For each request to the search engine, we have the number of items matched in the response. So, after each block of query understanding, query building and query execution, we can check the precondition to return the result or follow to the next stage.
Adding a UI to look at the results
Even if the search application is a backend service for a frontend, it is always a good idea to have a simple UI to look at the search results. Lucidworks Fusion provides an easy way to create such a UI. Lucidworks App Studio is a collection of software and resources that helps to quickly build feature-rich search apps[3]. Out of the box it provides a lot of components to visualize such search features as faceting, filtering, sorting, typeahead, highlights, etc. We can easily integrate it with our Search API. The only thing we need to do is to create a query profile associated with the main query pipeline and to configure App Studio to use this query profile.
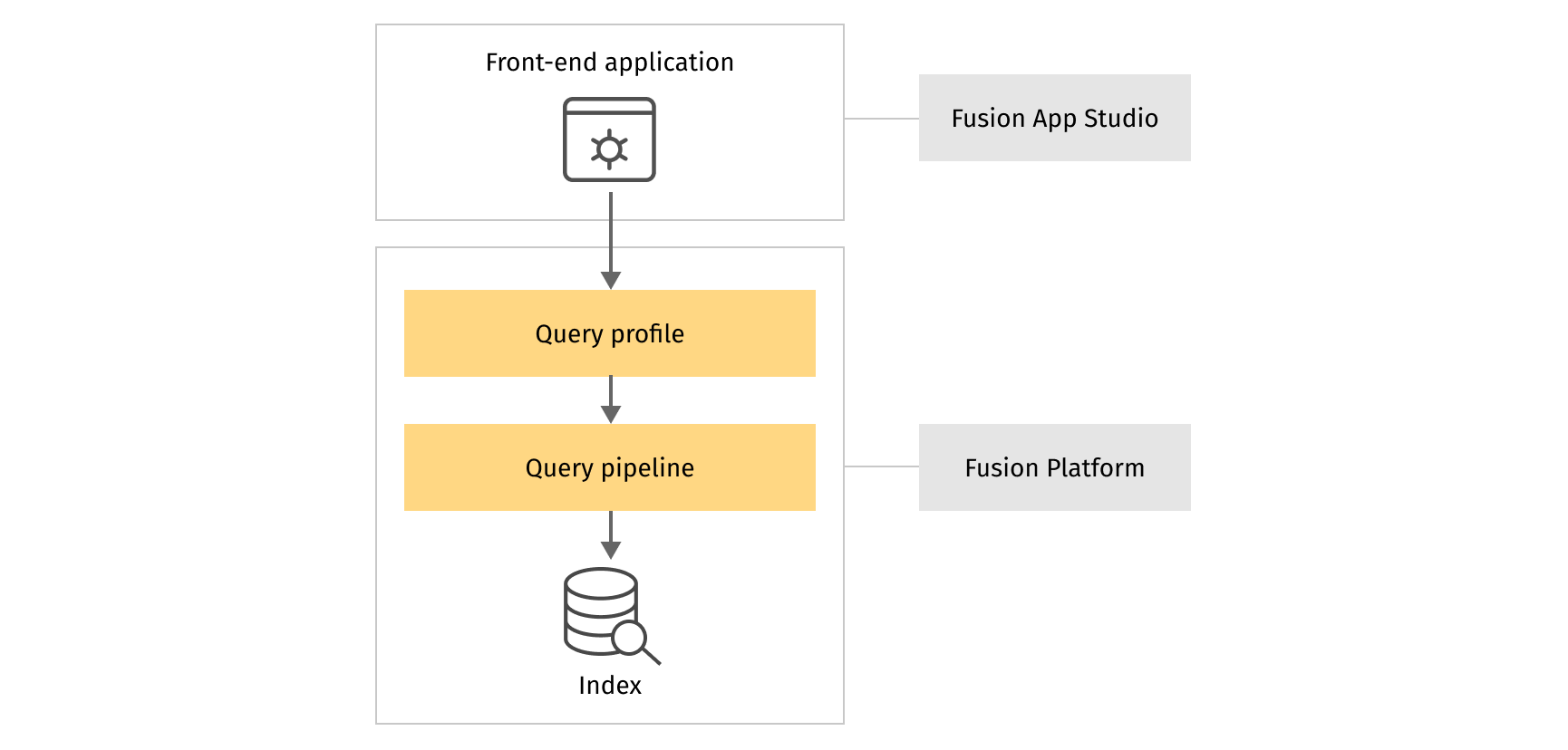
At this point, we have the search flow completely implemented within Fusion platform, from the connector to the datasource with product catalog to the front-end application which interacts with customers. No third-party service was necessary apart from cloud or on-premise resources for deploying Fusion platform itself, everything was implemented using Lucidworks Fusion capabilities only.
Comparing semantic query parsing to default Fusion search
Once we have all pipelines configured, it would be pretty interesting to compare the technique of semantic query parsing with default Fusion search pipeline [3] and see if we have the improvements.
For this comparison, we will consider a small catalog containing about 14,000 passenger tires from different brands and with various specifications. For the visualization, we created an application based on Fusion App Studio and connected it to our query pipeline via query profile as was described in [3].
Let’s assume that a customer is looking for a set of tires with section width 155 and rim diameter R13, while all other parameters do not matter. So what will the customer see in the result set in case of the regular Fusion search implementation?
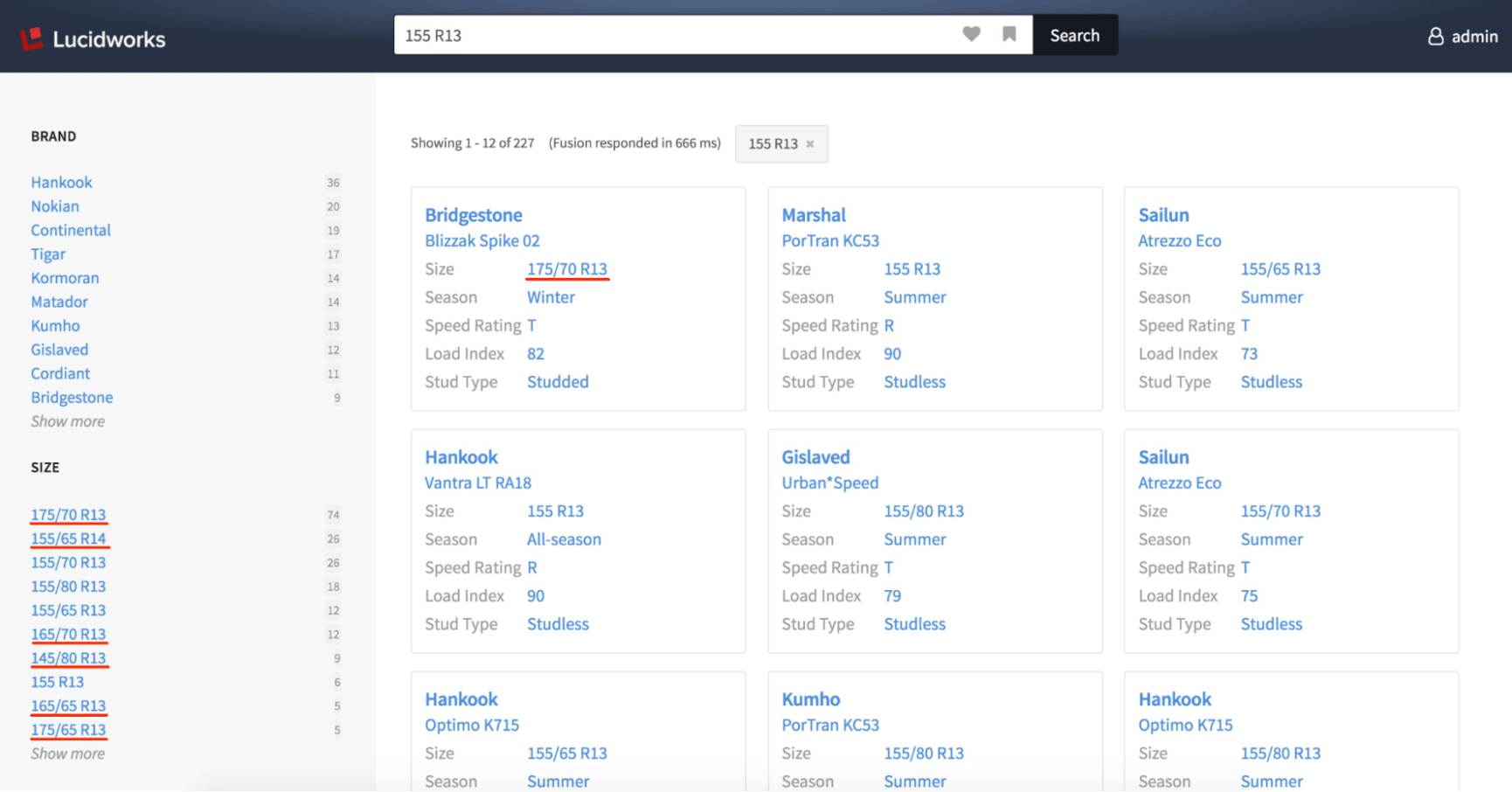
First of all, we see that the result set contains tires with rim diameter 14 and section widths 175, 165, 145, etc, as we clearly see looking at the size facet. Further we notice the tire with section width 175 on the top of the result set. And finally, only 2 from 6 tires with exact size “155 R13” are present on the first page. Recall of this approach is quite good, as all relevant tires are found, but precision can be significantly improved.
Let’s look at the concept-oriented search results for the same query:
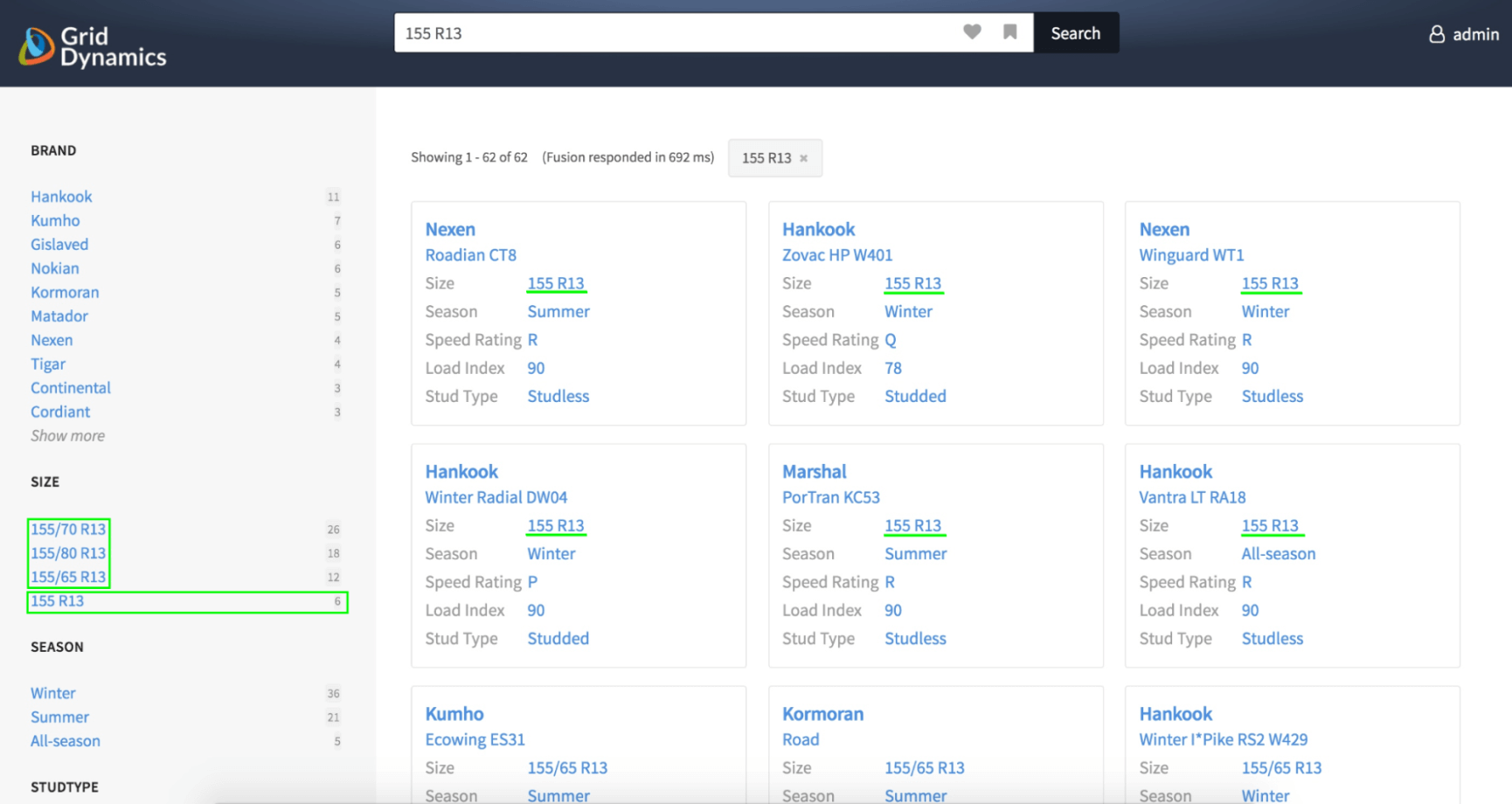
Now the result set looks much better. We retrieved tires with section width 155 only. Moreover, all 6 tires with exact size “155 R13” are placed on the top of the result set, i.e. these products got a higher score than others. Let’s look at the semantic graph for this query.
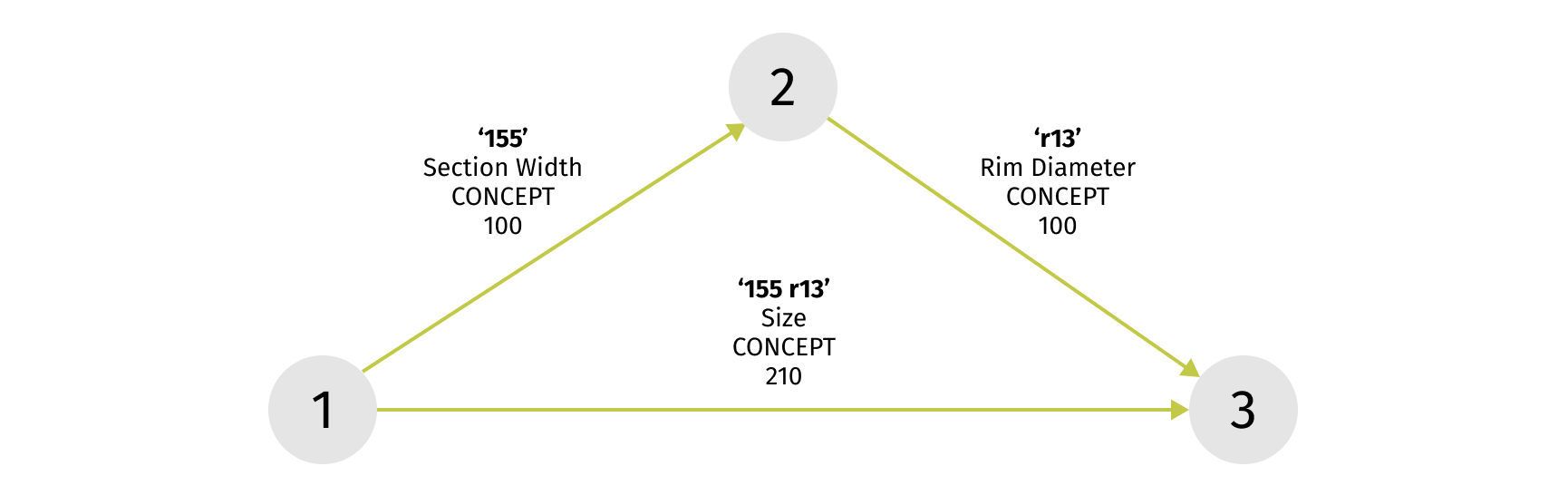
This query representation lets us understand the results we got. Semantic query parsing detected that token “155” means section width, token “r13” means rim diameter. But it also found that the combination of these tokens is the exact size value in our catalog and boosted this hypothesis in the final Solr query. So that’s why we got higher scores for the top 6 tires in our result set.
To learn how semantic search’s impact helps business beyond searching, we recommend reading the Boosting product discovery with semantic search article.
Combining semantic query parsing with Lucidworks Fusion: conclusion
In this blog post, we described the practical approach to implementing semantic query parsing technique on Fusion platform. We showed how Fusion platform allows you to focus on the core search algorithms while taking care of a lot of boilerplate concerns such as data integration and query pipelining.
Combining semantic query parsing technique and Fusion platform, we can bring relevant results to the customers even faster with higher quality. Additionally, to reduce search abandonment, retailers use machine learning and artificial intelligence to personalize and improve customer journey without sacrificing performance. More details are available at Driving differentiation in e-commerce marketplace search.
Happy searching!
References
- Lucidworks Fusion Architecture
- Semantic query parsing blueprint
- Guy Sperry (2020), Fusion in Action, Version 5, Manning Publications
{kind=link}