
Understanding search query intent with deep learning


Online retailers are always looking for ways to provide delightful and frictionless shopping experience to their customers. Product discovery, powered by search and category browsing, stays at the top of the sales funnel and has the highest impact in converting visitors to customers. At the same time, modern customers are not that easy to impress. Customers of the new AI age expect search systems to understand their shopping intent, even if their search queries are not very specific.
In this blog post we will talk about under-specified queries and how deep learning NLP models help employ customer engagement data to provide relevant results and improve e-commerce revenue per session.
Underspecified queries
In approximately 30%-40% of the sessions customers start their search journey with very broad queries like “mens clothes”, “nike” or “handbags” which provide very limited information about their actual shopping intent. Some of those queries, like “mens clothes”, match literally half of the catalog, and nothing in the search query itself can help the search system to determine in what order should the products be ranked. Should we show jeans at the top or dress shirts? Or perhaps t-shirts?
Another example of the same problem is term ambiguity.
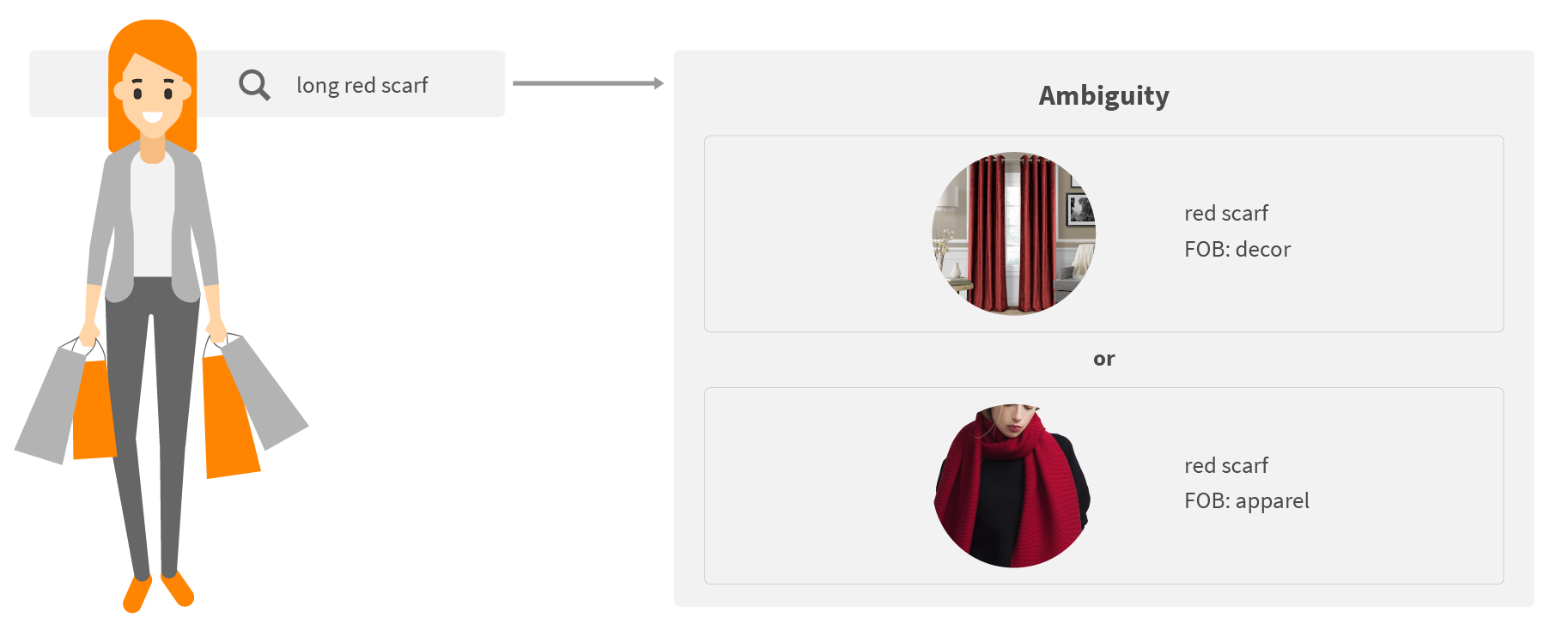
When a customer is looking for a scarf, does she mean a style of the curtain in home decor or an item type in apparel? Of course, we can interpret the query to show results for both terms but this will definitely lead to showing lots of irrelevant results and thus generate customer frustration.
Traditionally, merchandisers have employed business rules to deal with this ambiguity, either by promoting a particular product type, their best-sellers or high-margin products. However, such rules are pretty hard to maintain and scale to all possible scenarios. We should be able to do better than that.
What we are looking for is a way to employ customer engagement data to resolve ambiguity in search phrases. By analysing customer search sessions with information about the products they eventually added to the basket or purchased, we can “understand” that when customers are searching “nike” they most often mean t-shirts first, and then shoes. This intent understanding can help us rank search results accordingly or filter them to show only relevant product types.
However, as customer queries can come in endless variations, we need to be able to generalize across all those variations and still properly predict actual customer intent. This is where modern natural language processing models, powered by deep learning, can save the day.
Classifying customer intent with deep learning
In this blog post we will focus on classifying customer shopping intent by product type and subtype, which is arguably the most important piece of intent to understand.
From the clickstream data we will build a click model - a dataset containing search queries along with distribution of customer’s interaction with a particular product type or subtype. This distribution of customer interaction will depend on seasonality, query volume, numbers of clicks, adds to cart and checkouts for each particular query and product type.
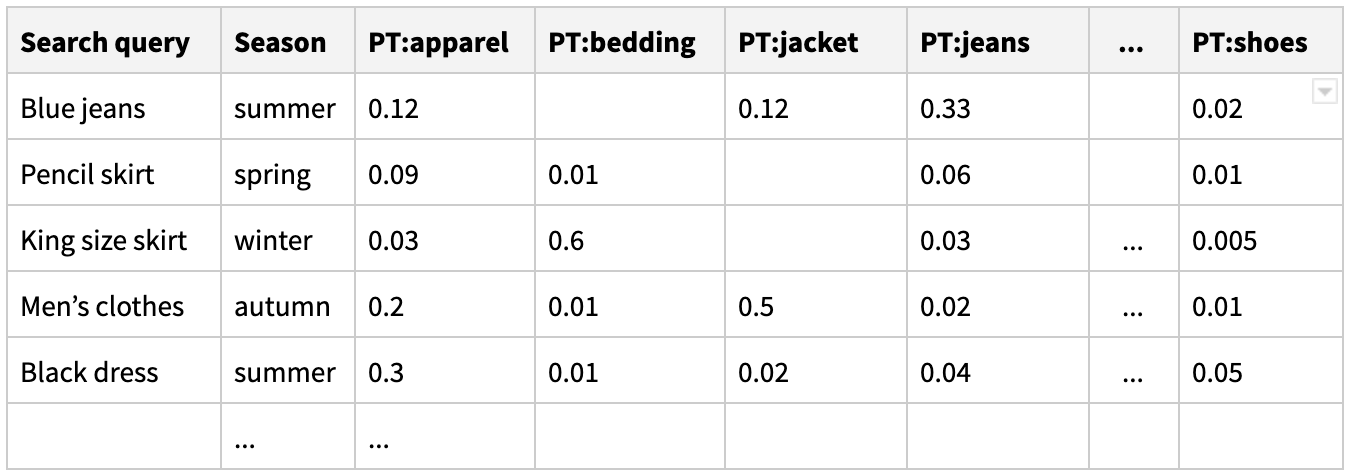
Our goal is to build a model which can predict proper product type distribution based on the search query and season. Product types getting the highest prediction score in the distribution will be recommended.
We will start by training a language model based on a large volume of unlabeled retail data. The language model will help represent our queries as semantic vectors, i.e. words with similar meaning will be clustered together in multi-dimensional vector space. This will greatly improve the quality of intent recognition. We will use a popular fasttext library to fine tune the word embedding model on all available data: search queries, product names and descriptions, reviews and attributes.
Once the fasttext language model is trained, it will be able to convert our search queries into matrixes where every word is represented by a 100-dimension vector:
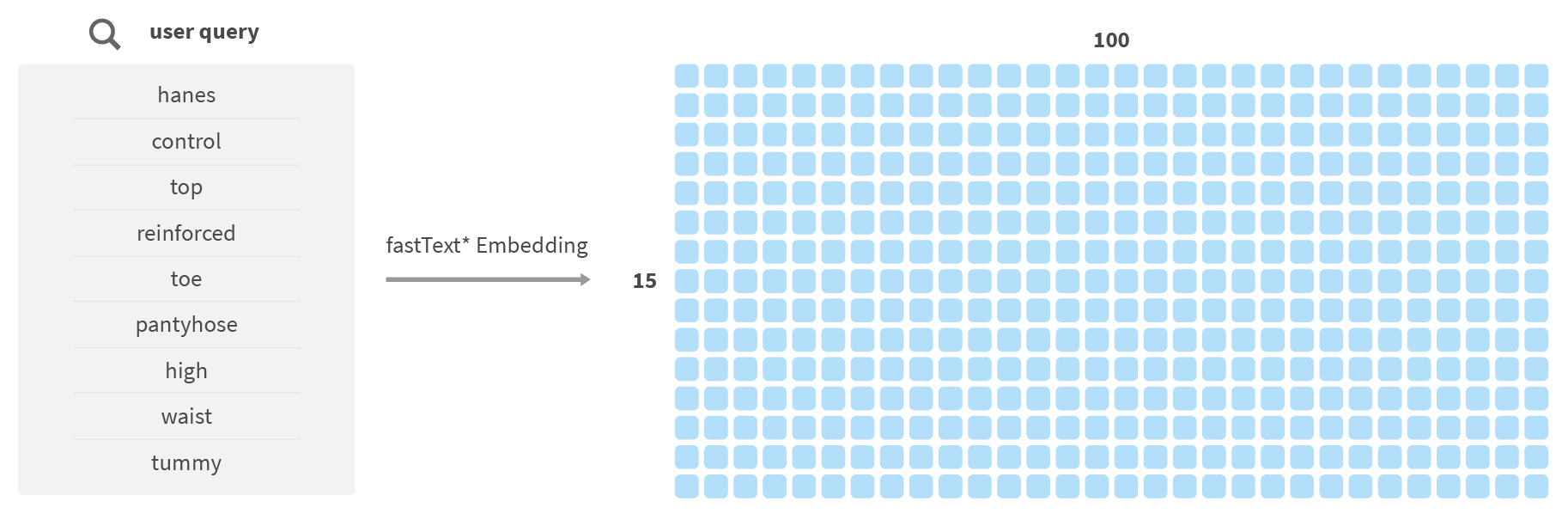
We will also concatenate the seasonality vector to our word embedding in the form of one-hot encoded season vector. With this encoding, winter will be represented as [1,0,0,0], spring as [0,1,0,0] and so on.
Now, we need to employ a deep neural network to learn the patterns in query matrixes and classify queries to appropriate intents, represented as labels in our dataset.
We will be using a one-dimensional convolutional neural network (CNN) to learn the patterns in word combinations contained in the queries. Here is a conceptual framework for 1D-CNN processing of a vectorised query:
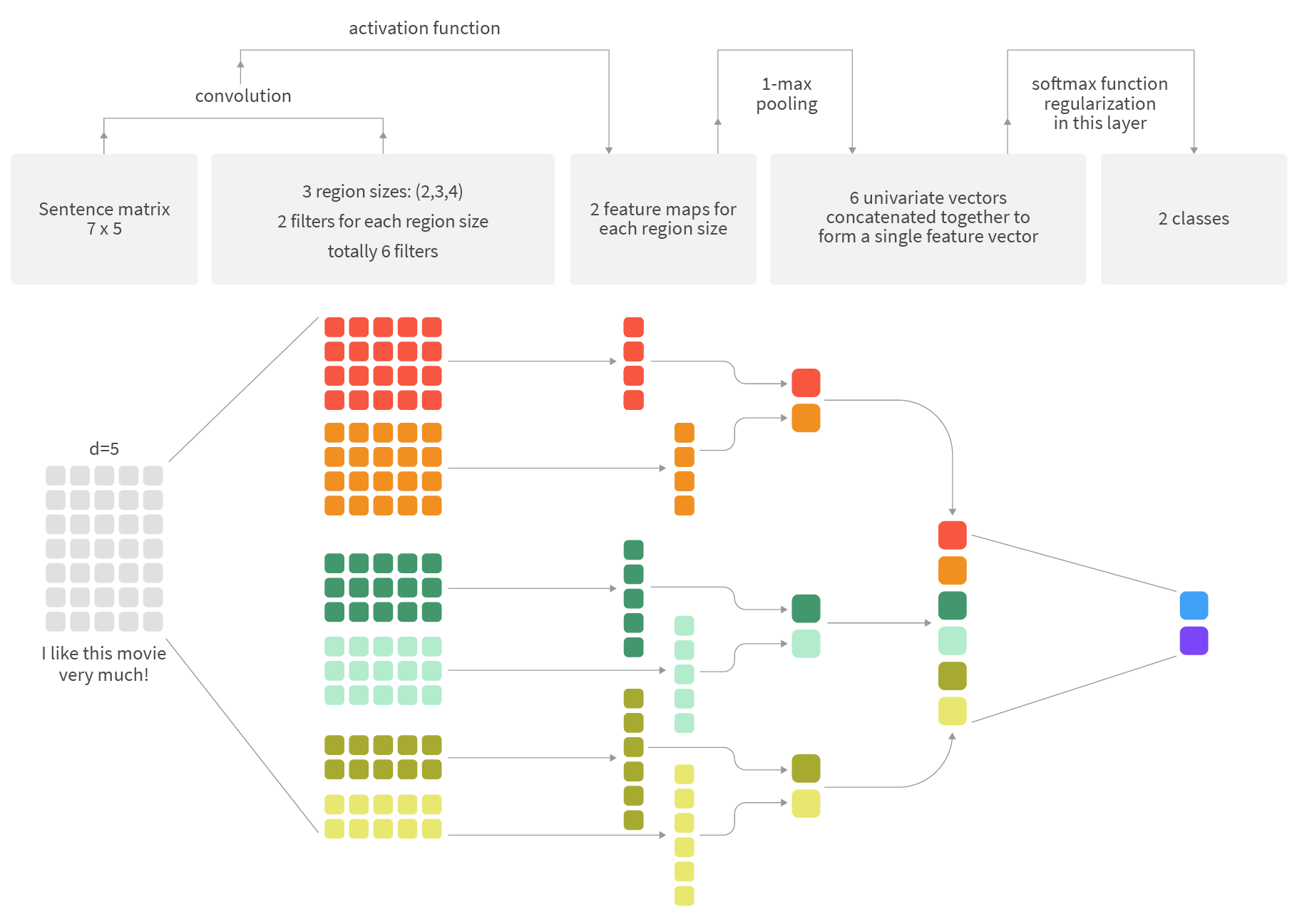
We have a matrix of word embeddings of a particular dimension, say 5 in this example. Every row of this matrix corresponds to a word in our query, up to a maximum supported query length. Shorter queries will be zero-padded to an appropriate length.
We will process this matrix using 3 different sizes of 1D convolutional filters: 4,3,2. For each size of the filter, we will choose 2 filters for the network, getting 6 filters to learn during training.
As we are dealing with 1D convolutions, our filters will produce feature maps as vectors of dimension (matrix_size - filter_size + 1), corresponding to all possible ways to position filter within the original matrix. Each feature map will be coarsed using “max pooling” to a single scalar to capture only the most salient feature.
Resulting coarsed feature maps from all the filter of all the sizes will be collected and concatenated into a single semantic feature vector which will represent the original query. This vector will be an input to the fully connected and soft max layers which will perform actual classification of the queries.
A real-life CNN will be very similar to this example and differs only in the size of word embeddings (100), a number of filters to be learned, also 100, and a number of labels to classify:
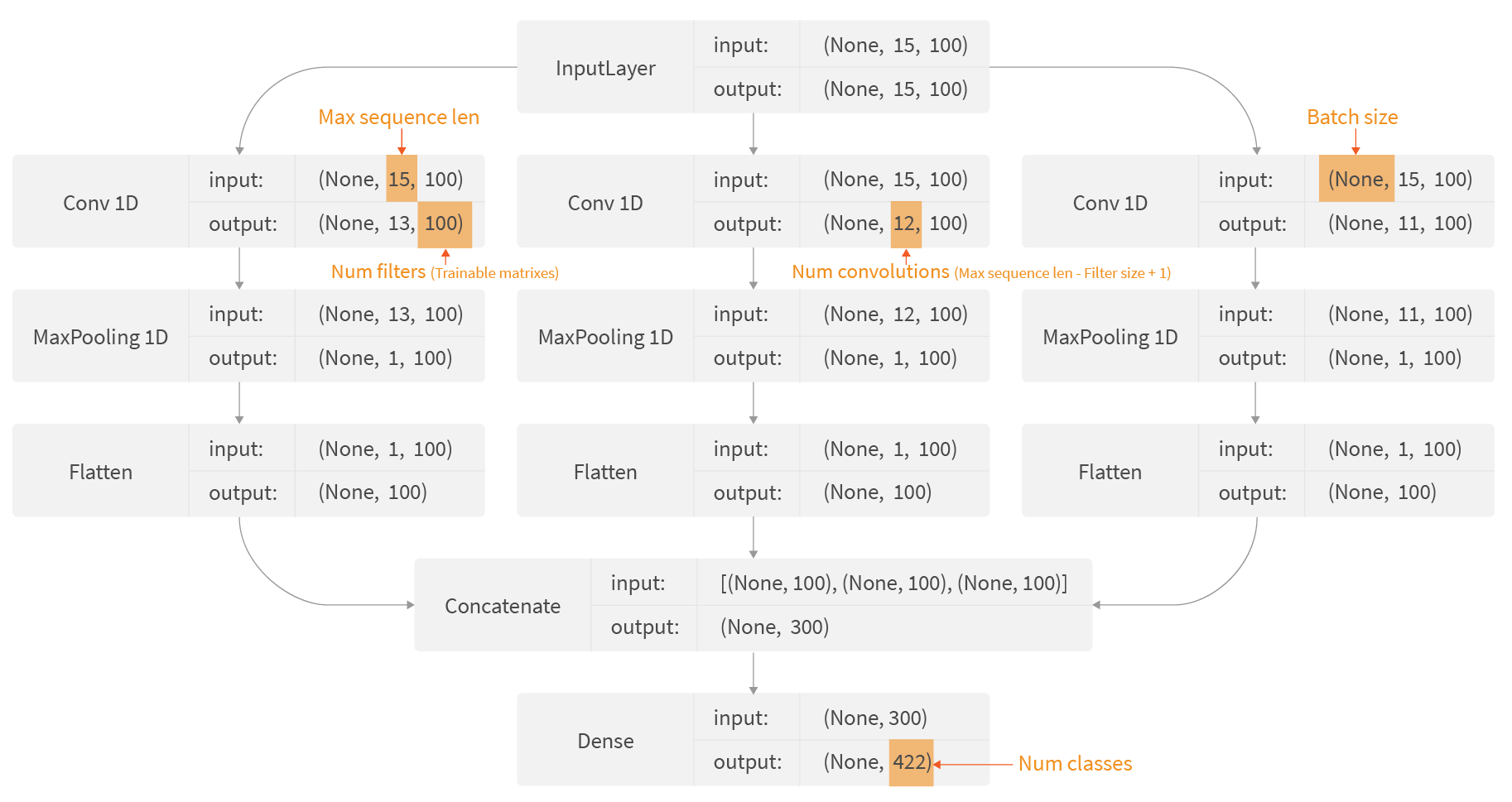
To evaluate the quality of the model we will use the accuracy@N metric, which estimates in what percentage of predictions we get a correct product/subproduct type within top N results. In our experience, even this relatively simple model achieves 70% accuracy in top-1 predictions and 92% in top-5 predictions. If we estimate the accuracy based on the actual volume of queries, e.g. without removing duplicates, we will get 83% for top-1 and 95% for top-5 predictions.
When we account for the seasonality signal, the model is able to predict that in autumn people searching for “nike” are most likely looking for hoodies, and in spring the same query shows a “running shoes” intent.
The intent understanding model can be integrated with search and browse experience in several ways:
- It can be used to boost or filter products on the search results page, thus producing higher precision search results and improving ranking
- It can be used to boost products in browsed categories by recognized session intent, based on search queries the customer used in the same session
- It can be used to recommend related categories and queries.
In our experience, integrating query intent understanding leads to a direct uplift of 2-5% in revenue per session, providing a solid ROI for a deep learning model training and integration.
Conclusion
In this blog post, we described a problem of underspecified and ambiguous queries, and how modern, deep learning-based, query intent understanding models can help tackle those queries in the most effective way so they can deliver precise and timely search results to customers.
Please do not hesitate to reach out if you are interested to learn more about search and natural language processing.
Happy searching!
If you wish to get more information on this subject or would like to contact the authors, please click here.