
Using Augmented Reality in Interior & Property Design



Ever tried to stretch your imagination and picture how your bedroom would look like with that new lovely wallpaper? What about new tiles for a bathroom? Sounds like a tedious task, especially as you go through dozens of design options, combine and compare them. Well, no more! Modern augmented reality powered by deep learning allows you to take a picture of your room and visualize it with a new wall paint, wallpaper, tile or floor.
At Grid Labs, we like to take a stab at interesting problems like that and find approaches to solve them. In this blog post, we will report on how to build a system which is able to take a photo of your room and a texture of desired wallpaper or paint and magically produce a visualization of your room in a new style.
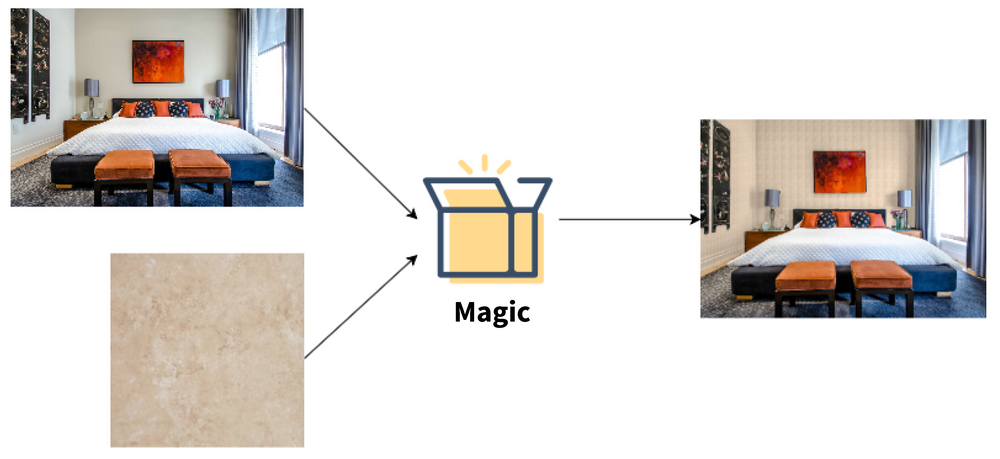
Truth to be told, there is no real magic in this solution, but there is quite a bit of pretty cool image processing and deep learning, so read on!
Unraveling the Magic
So, how do we achieve the magical experience in the picture above? The main idea is that we will have to analyse the image and distinguish walls from the rest of the room. We also have to understand the perspective of the room in order to correctly project our texture and, to make things look real, we will have to transfer shades from original image to simulated one.
All this processing comprises a full room processing pipeline:
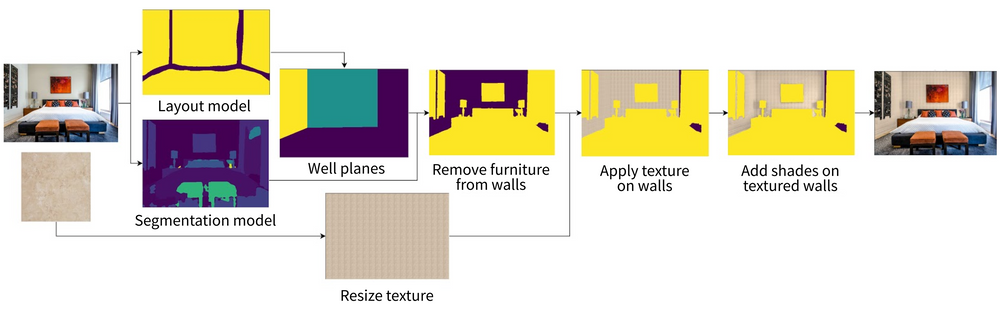
- Read Inputs - images of the room and the texture
- Recognize Room Layout - recognize main room features and give us the image perspective.
- Segment the Room - this is the main workhorse of the whole system. We should distinguish walls from the furniture, decor, curtains, windows and other possible room elements.
- Locate wall planes - this is where we identify what parts of the picture will be substituted with our texture.
- Prepare the mask for wall planes - here we refine our wall planes to exclude elements of furniture and decor.
- Resize texture image - it should have natural size so we have to use some perception of depth to do it right.
- Apply texture on walls - here we replicate the texture and apply perspective.
- Transfer shades from original image onto textured walls - things are looking unnatural without shades, so we need to retain them from the original image.
- Replace original walls with new walls and render the final visualization!
Now, let's look at those steps in more detail
Making sense of the room picture: Layout and Segmentation models

To correctly apply the texture to the walls we have to consider two critical pieces of data: room layout and room segmentation. We will use separate deep learning models for those concerns:
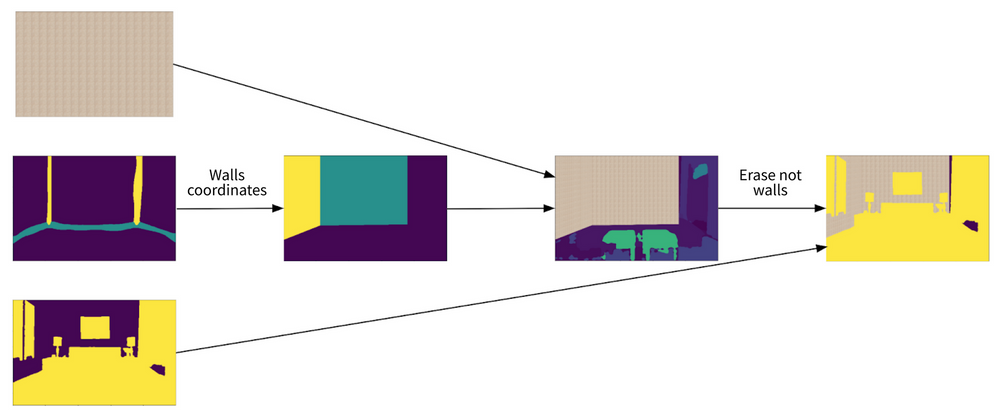
- Layout model produces the heatmap with wall edges. This allows us to estimate the position and the perspective of separate wall planes in the image and apply texture on them.
- Segmentation model returns a mask showing where objects like windows and furniture are located, as well as walls. This allows us to distinguish walls from different objects and erase the items from textured wall planes.
Layout model
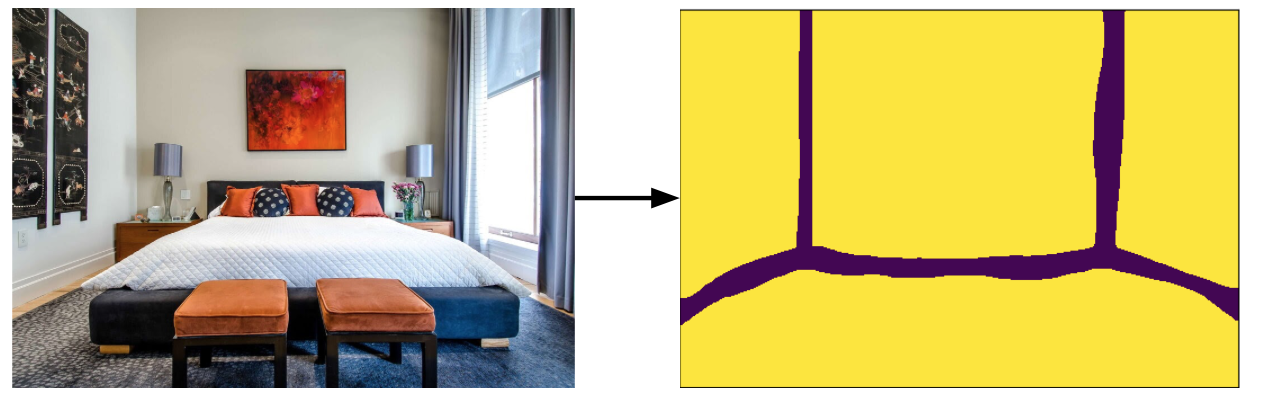
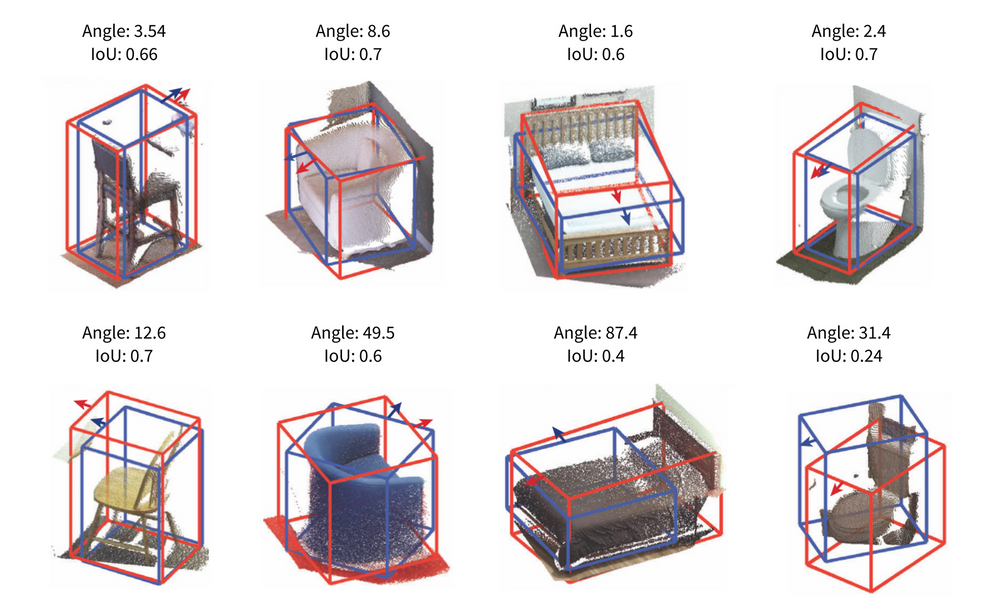
For layout detection we employed a model described in a paper called Physics Inspired Optimization on Semantic Transfer Features: An Alternative Method for Room Layout Estimation which was presented at CVPR 2017. Model was trained on the LSUN dataset. The authors claim that they achieved mIOU of 0.75 on validation set for layout estimation problem. Also metrics such as pixel error (ratio of mislabelled pixels to all pixels) and corner error (euclidean distance between estimated coordinates and ground truth) are reported to beat state of the art models of that time. IOU stands for intersection over union, which is a metric defining how well we cover pixels of ground truth layout of the room. Below you can see a few examples of ground truth bounding boxes (blue), predicted bounding boxes (red) and corresponding IOU in each case.
Segmentation model
For the room segmentation task we evaluated a number of available models
| Model | Dataset | MoU | Pix Acc |
| DeepLab ResNet200 | ADE20K | 0.48 | 0.82 |
| ResNet50-dilated + PPM decoder | ADE20K | 0.42 | 0.8 |
| DeepLab Resnet101 | COCO | 0.39 | 0.67 |
Models were pre-trained on two datasets - ADE20K and COCO. ADE20K consists of scene-centric images with 150 semantic categories which include stuff like sky, road, grass, and discrete objects like person, bed, etc. COCO has 180 classes.
To compare the models’ performance we used two key metrics - MoU and Pixel Wise Accuracy. As those metrics are averaged across all classes in the corresponding datasets, we can compare segmentation efficiency of these models.
State of the art model DeepLab with ResNet200 backbone trained on ADE20K shows the best results. The second model with Pyramid Pooling Module has lower metrics and DeepLab model arrives a distant third. Consequently, we chose two models pretrained on ADE20K.
Transferring texture
We can apply our textures as is or in a tiled mode. To obtain the natural looking size of the texture representing tiles we have to scale our input image appropriately. There are models which could estimate a depth of the room, but here we decided to take a shortcut and made our textures 20 times smaller than the image of the room to get roughly 30x30 cm (12x12 inch) tile size. We can also double the size of the tiles as needed for visualization.

Applying the texture
The general process of applying texture on walls is displayed in the image below. The output of the Layout model gave us the heatmap with detected wall edges (room layout). This room layout is used to calculate the coordinates of wall planes. First, we took contours of wall edges and formed wall planes. We used heuristics to approximate the corners of these wall planes. After it, to fill the gap between adjacent walls, the average distance between walls’ contours was calculated. This average distance then was used to find the room corner. Once wall places were found, we transferred texture on them using homography projection. In the last step, the output mask of the Segmentation Model was used to remove furniture and decor from textured wall planes.
Transferring shadows
Images without shadows look flat and unnatural. In order to achieve a more natural look of the image, we need to add light and shadows to our textured walls. The key technique to do this is to consider HSV representation of the original image. The V channel (sometimes called B) is responsible for the pixel blackness which correlates with the shades intensity.
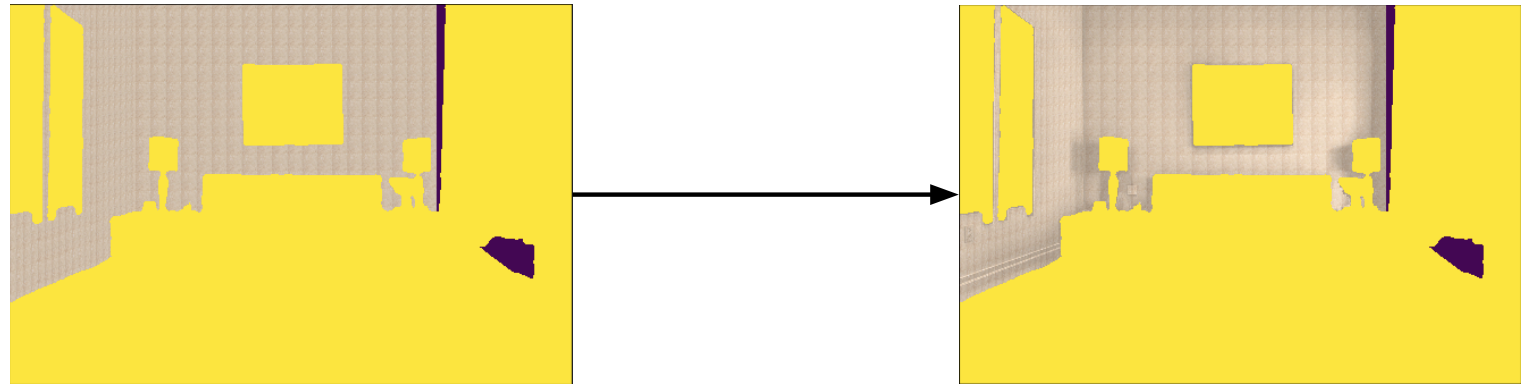
The basic approach to transferring shadows is the following:
- For each wall on the original image we calculate its average pixel blackness
- For every pixel of individual wall in original image we calculate a difference between blackness of this pixel and average blackness of the wall
- For each individual pixel of texture that we intent to apply we perform shifting of blackness channel by the blackness delta amount from the corresponding pixel in the original image
This approach produces pretty smooth results (picture above), but it has some important flaws worth mentioning. When dealing with walls with strong patterns (say stripes), the blackness from darker parts of the pattern is transferred as if it was a shadow. To fix this problem, we tried several techniques:
- V-channel shift capping: We limit a v-channel to a particular number. If a larger shift is required, cut off at threshold. This resulted in unnatural shades and did not fix the problem
- Clustering: We cluster pixels in the original wall according to the blackness channel, then shift the blackness channel relative to the means of the clusters. This results in defects in clustering visible in the geometry of shades
- Pattern detection: If too many pixels require large shifts from their value, we can consider the original wall heavily patterned and disable shadow application. This approach, while being simplest, delivers best results in practice.


Performance
Because the data pipeline we use is pretty long, our original solution was suffering from the performance issues. We looked at 40 seconds to 2 minutes of image processing time which was clearly not acceptable for the real customers. Layout and Segmentation networks were the top offenders. We employed some of the techniques to optimize the performance of the pipeline
- We cache Layout and Segmentation model results as customers are likely to try several design ideas with the same room
- We tuned the size of the input images. While this cost us some of the precision, we managed to substantially cut inference time.
- Running models on GPU
Those measures allowed to cut inference time to 1-2 seconds per image which is already good enough for the real time use.
Examples
We compared the results of our model with a leading commercially available product and can see that our model produces comparable results quality:


In this example we can see how different models work with shades and lighting.


Conclusion
In our blog post, we described a practical solution to a core of room visualisation system which can power your agmented reality application. As we continue working on our models, we see a lot of opportunities to expand the system features and improve the quality and performance, such as training our own segmentation model and depth perception model, as well as applying NN optimizations to improve inference times.
Meanwhile, if you are interested in adding computer vision and image analytics to your application, don’t hesitate to reach out!