
Virtual backgrounds: real-time deep semantic segmentation on mobile devices




Working from home was never more fun than these days of pandemic and lockdowns. We all stay connected with video conferencing, and, with obvious benefits of seeing friendly faces of our colleagues, we get all the drawbacks of exposing not-so-glamorous aspects of our work-from-home lives: messy rooms, opened drawers and piles of toys.

In this situation, many of us turned to virtual background feature of our video conferencing platforms. Creative choice of virtual background for your next meeting can put a smile on the face of your colleagues and lighten up your working day.

However, even with popular video conference platforms, virtual background implementations are not showing particularly high quality: they cut parts of our faces when we turn our head, and overall edge often looks not natural enough. Also, virtual background is a computationally heavy feature and is challenging to run on mobile devices.
Our engineers at Grid Labs like challenging problems, so they went about building a better virtual background model while making it fast enough for mobile devices.
Real-time video segmentation
Virtual background is built using computer vision technique called image segmentation. With image segmentation, each pixel of the image is mapped to a particular class. In case of the human face it can be background, hair, ears, nose, lips, etc...

People face segmentation is an important problem in computer vision with a multitude of applications in beauty industry and photo/video processing. Dealing with people segmentation is extra challenging. Unlike many objects with simple shapes like apples and bananas or more complex, but rigid cars and bicycles, the human body has a very complex and ever changing structure, where some parts of the body can have less predictable shapes, such as hair. For the realistic hair coloring or concealing the background of the room, coarse segmentation mask is insufficient. Additionally, many beauty and video streaming applications run on mobile devices or in web browsers, where powerful computing resources are not available. This makes it more challenging to achieve real-time performance.
In this blog, we will describe how we approached both those challenges and built a a system that can accurately segment a human body at over 30 fps on a mobile device.
A bit of a history
Segmentation algorithms started to evolve since 1980s. Initially, they were based on the discontinuity and similarity of pixel intensities in a particular locations. Discontinuity approach tried to partition an image based on an abrupt changes in pixel intensity and similarity approach is based on partitioning an image into regions that have similar pixel intensity. On of the important and successful application of those approaches is an edge detection. Canny Edge Detection was invented by John Canny in 1983 at MIT, treating edge detection as a signal processing problem. The key idea is that if you observe the change in intensity on each pixel in an image, it will be maximized on the object edges. In this simple image below, the intensity change only happens on the boundaries, making it easy to detect edges.


Since the Canny edge detector only focuses on local changes and it has no semantic understanding of the image content, it has limited accuracy.
Background Subtraction methods are used to detect foreground objects in video sequences. Most popular methods are based on Gaussian mixture models (GMM). We used four methods based on GMM: GMG, KNN, MOG, MOG2. However, many features of video sequence, such as visual noise, wind moving trees, rain, could affect the quality of those methods. Things like visual noise, swaying trees, rain can affect the quality of those methods.

Semantic image understanding is crucial for edge detection, that is why learning-based detectors leveraging machine learning or deep learning produce better results than canny edge detectors or background subtractors.

Our approach
In line with the recent success of convolutional neural networks (CNNs) for semantic segmentation, our human body segmentation methods are based on CNNs. However, most modern CNNs cannot run in real time even on powerful GPUs and may occupy large amount of memory. We are targeting real-time performance on mobile device, so we decided to apply well-known U-Net architecture to the body segmentation problem, knowing that it is both fast and compact enough to be used on a mobile device and browsers.
First of all, high quality segmentation require high quality ground truth data. We used tens of thousands of annotated images from MSCOCO segmentation competition. This dataset contains pixel-accurate locations of human bodies and a general background label, achieving a cross-validation result of 97% Intersection-Over-Union (IOU) of human annotator quality. It captures a wide spectrum of foreground poses and background settings. We also used PascalVOC, and supervise.ly with special preprocessing to improve the results.
In video segmentation we need to achieve frame-to-frame temporal continuity, which means that the segmentation masks should change smoothly from frame to frame. At the same time, we should account for temporal discontinuities when people suddenly appear in the camera's field of view. To train our model to robustly handle those cases, we perform data augmentation of each ground truth photo in several ways, and use it as a previous frame mask:
- Empty previous mask - Trains the network for cold-start, e.g. to work correctly for the first frame and new objects in scene. This also emulates the case of someone appearing in the camera's field of view.
- Affine-transformed ground truth mask - Minor transformations like those train the network to propagate information from the previous frame mask. Major transformations train the network to recognize and discard erroneous masks.
- Transformed image - we employ thin plate spline smoothing of the original image to emulate fast camera movements and rotations.
Our neural network architecture is based on popular U-Net architecture with a bunch of simplification and improvements, helping to achieve a high performance of the network inference while maintaining reasonable quality.
Our model, taking an image as an input should output an alpha-channel mask separating the subject (person in our case) from the background.

Original image

Alpha channel
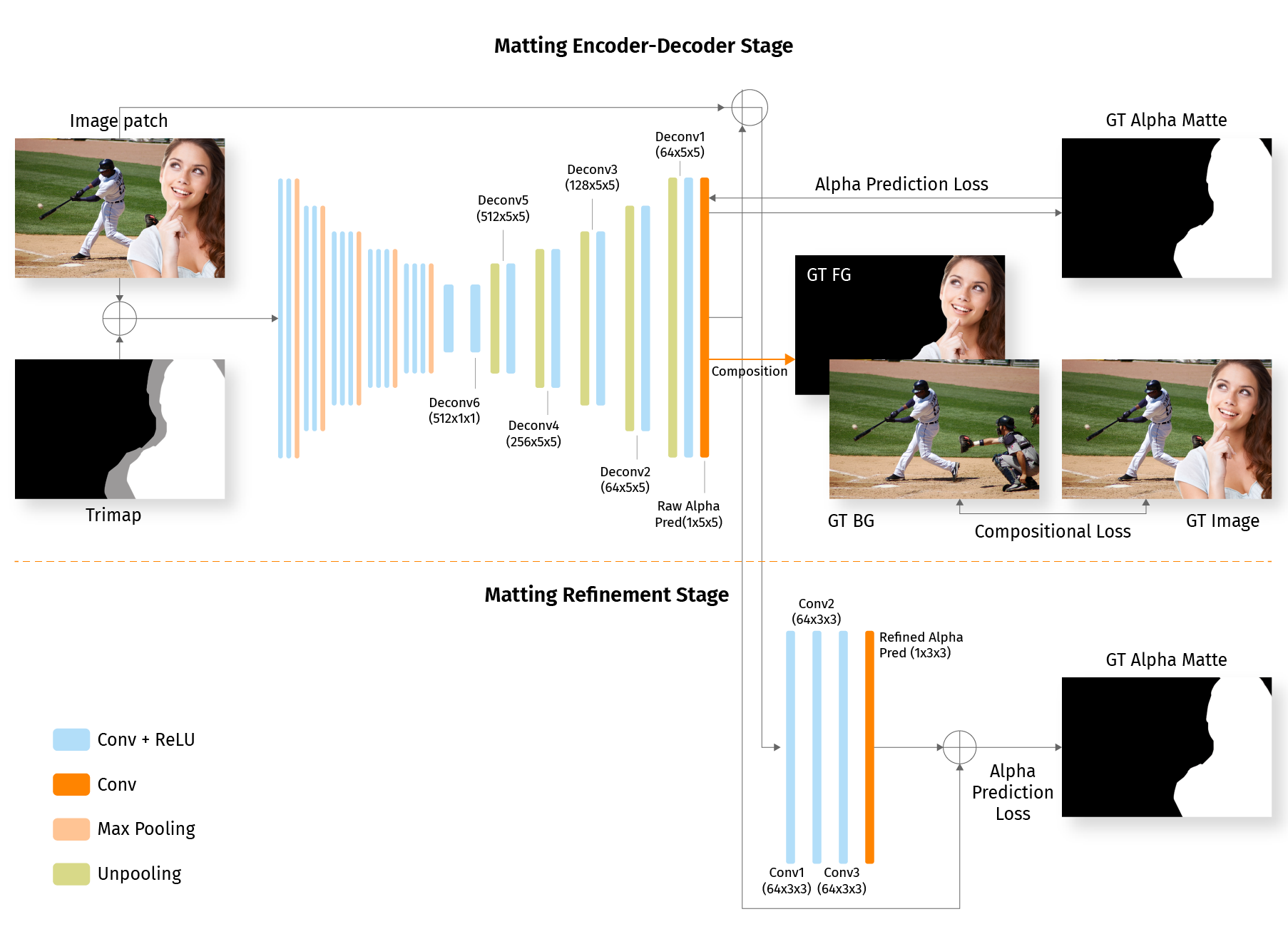
It it well-known that the key insight of the U-Net architecture is to employ skip connections to allow propagation some of the features extracted in earlier layers through the bottleneck layer. We improved base U-Net, mixing in two additional techniques from recent research papers: self-attention gates and spacial dropout.
- Self-attention gates help the network to highlight only the relevant activations during training where attention implemented at the skip connections suppresses activations in irrelevant regions, reducing the number of redundant features brought across. This reduces the computational resources wasted on irrelevant activations, providing the network with better generalization power.
- Spatial dropout which infers the attention map along the spatial dimension, and multiplies the attention map by the input feature map for adaptive feature refinement.
Additionally, we applied following improvements, targeted to optimize model performance:
- We use large convolution kernels with large strides of 4 and above to detect object features on the high-resolution RGB input frame. Convolutions for layers with a small number of channels (as it is the case for the RGB input) are comparably cheap, so using large kernels here has almost no effect on the computational costs.
- For speed gains, we aggressively downsample using large strides combined with skip connections to restore low-level features during upsampling. For our segmentation model this technique results in a significant improvement of 5% IOU compared to using no skip connections.
- Additionally, we optimized default bottlenecks. In the literature authors tend to squeeze channels in the middle of the network by a factor of four (e.g. reducing 256 channels to 64 by using 64 different convolution kernels). However, in our case we can can squeeze more aggressively using a factor of 16 or 32 without significant quality degradation.
- To refine and improve the accuracy of edges, we add several DenseNet layers on top of our network in full resolution similar to neural matting. This technique improves technical model quality metrics by mere 0.5% IOU, however perceptual quality of segmentation improves significantly.
After training our model for 250 epochs (8 hours on Nvidia GeForce RTX 2070 GPU) we achieve ~98% accuracy in segmentation.

Going Mobile
Running high quality segmentation model on mobile device requires some additional optimizations to achieve high FPS and smooth performance.
Naturally, image segmentation requires more computation than classification since it has to upsample image to original high-resolution spatial map. We have to employ following principles to keep inference time under control:
- Keep input image size as small as inference quality allows - this helps to significantly improve network latency. As a rule of the thumb, we can improve segmentation performance 4 times if if the size of input is halved.
- Downsample early when stacking convolution layers. Even with the same number of convolution layers, we can reduce the response time with strided convolution or pooling within early layers.
- Select input image dimensions which are multiple of 8, it allows for optimized implementations of convolutions .
- Grouping multiple operations to a single operation can improve performance quite a bit. For example, convolution followed by max pooling can be usually replaced by a strided convolution. Transpose convolution can also be replaced by resizing, followed by convolution.
- The GPU backend currently supports selected operations. The model will run fastest when containing only these operations; beware that unsupported GPU operations will automatically fall back to CPU.
- One of the most popular optimization technique is 8-bit quantization which allows to make speed-accuracy trade-off. TensorFlow Lite supports SIMD optimized operations for 8-bit quantized weights and activations. However, TensorFlow Lite is still in early stage of development and requires special tricks to make the best out of it. In particular, we had to dig deeper into details of TF and TF Lite implementation and make sure that out neural network can fully utilize TF Lite optimized kernels .
- We adopted some state-of-the-art blocks rather than using naive convolution blocks.
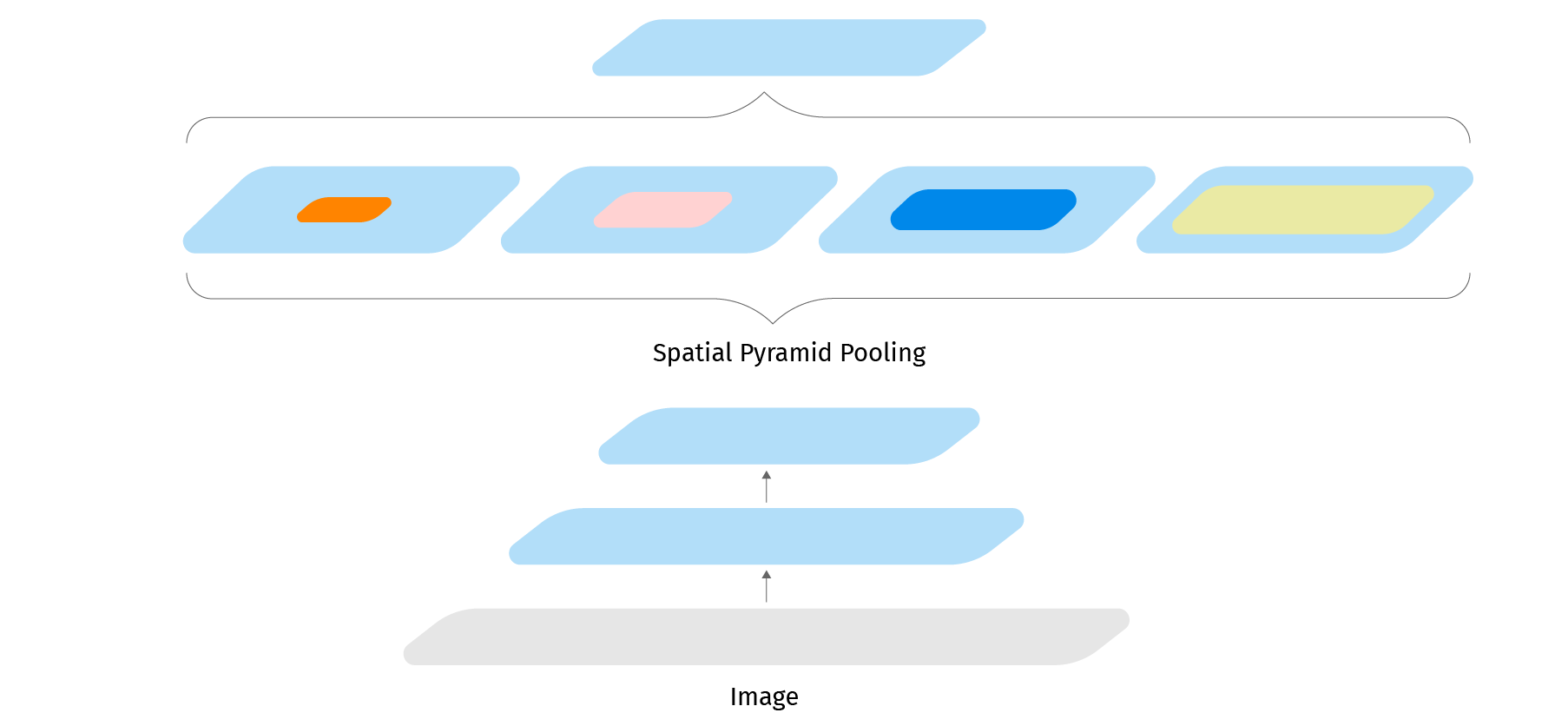
Atrous spatial pyramid pooling is a block which mimics the pyramid pooling operation with atrous convolution. We also substitute most of the convolution layers with efficient depthwise separable convolution layers. They are basic building blocks for DeepLab, MobileNetV1 and MobileNetV2 which are well optimized in Tensorflow Lite.
Model integration
When building a mobile application which relies on real-time video processing it is important to minimize the overhead of working with deep learning model. Naive implementations can lead to the situation when response time and FPS are dominated not be the model inference itself (e.g. segmentation), but by sending the frames to the model and rendering the results.
Converting the video stream consists of converting one frame at a time. Each frame is processed in 3 steps:(1) create a buffer of input bytes, (2) pass data to the model and (3) interpret the results to obtain the image mask. Lets consider each of those steps.
In our models, the process of generating the input data buffer is reduced to scaling the image to size expected by the model and ordering the normalized pixels into a vector from left to right from top to bottom.

Each pixel is represented by 3 floating point numbers: red, green and blue.
The model is producing a segmentation mask: a vector of floating point numbers in the range of 0 to 1 of the size equal to the number of the pixels in the original image following row-major order. Each number represents the probability that a pixel belong to a person, not to the background.
This segmentation mask is used to superimpose predefined image on the original image, and the alpha channel (transparency) of the background pixels follows the segmentation mask.
Selecting the model density
There is a natural trade-off between the model quality and segmentation performance. This dependency is non-linear and we can use experiments to identify a sweet spot
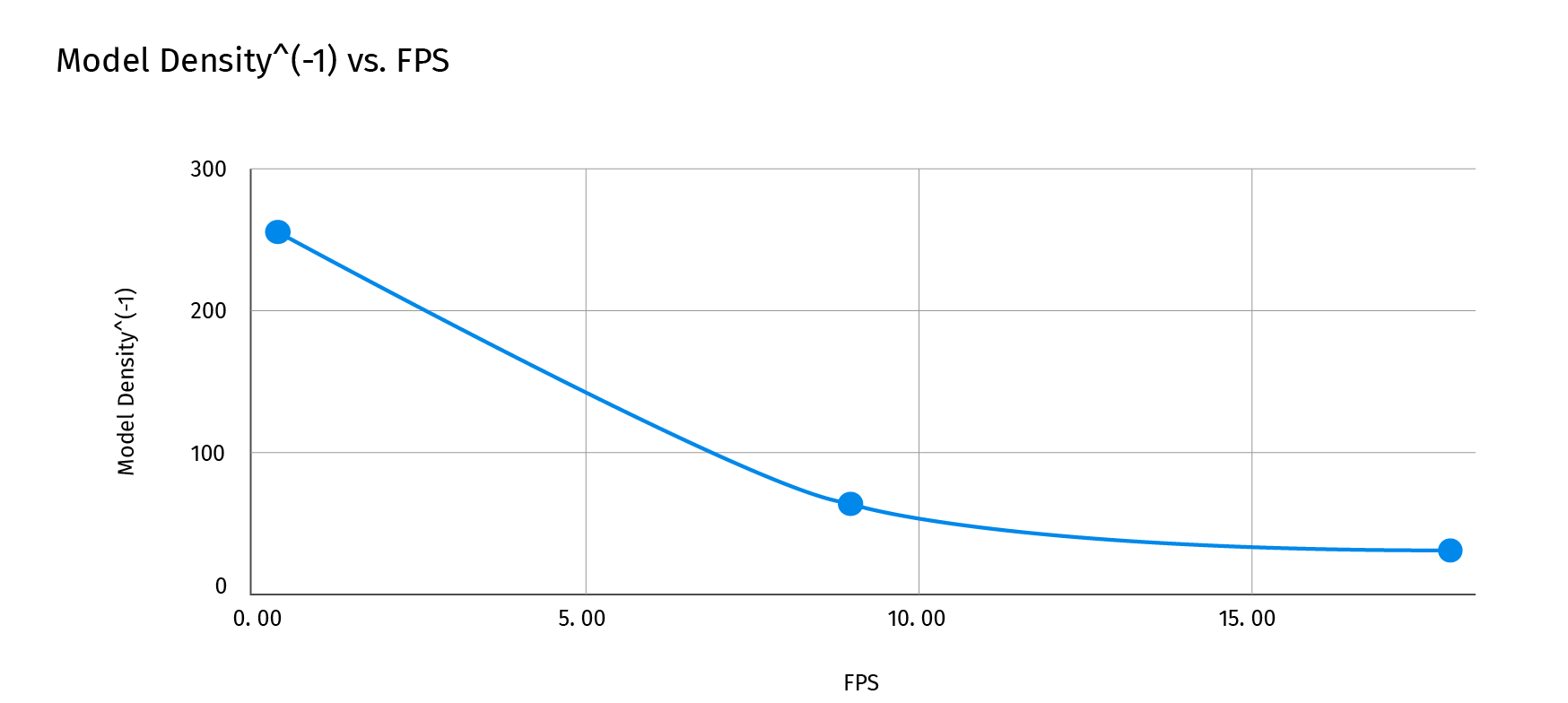
On the chart above, we see that when the size of the input matrix is reduced from 256x256 to 64x64, we get a 25x performance gain, Moving from 0.36 fps to 9 fps.

Additionally, Tensorflow library provides the ability to use native C and C ++ libraries for a lower-level process control. Moving to this lower-level implementation allows to gain up to 25% in FPS.
Some examples
Putting it all together, we are getting the near-real-time background removal on mobile devices:
 |
 |
 |
 |
 |
 |
 |
 |
Conclusion
In this blog post, we described the approach and implementation for near real time video segmentation on mobile devices. We trained a high quality segmentation model and We achieved comfortable 10 FPS even on the mid-range smartphones. For high end smartphones our model is pushing 25-30 FPS.
Deep learning CV models are taking mobile world by storm, and we are very excited with the opening possibilities.
As usual, we at Grid Labs would always love to hear from you and appreciate your comments and feedback.